文章目录
- 前言
- 1. 训练
- 1.1 yolov5 的 yolov5m6
- 1.2 yolov5 的 yolov5l6
- 1.3 yolov8 的训练
- 结论:
前言
做了一个烟火识别,用了2W张图片,标注包括:fire,smoke 。在coco80类的模型上进行ft, 借此机会进行比较一下。
- yolov5 yolov5m6
- yolov5 yolov5l6
- yolov8 模型待定
图片共:20113 张 按8:1:1 区分train,val 和 test
数据集:
train: Scanning ‘/data_share/data_share/fire_smoke_iter20230720/firesmoketaobao/train.cache’ images and labels… 16090 found, 0 missing, 1019 empty, 0 corrupt: 100%|██████████| 16090/16090
val: Scanning ‘/data_share/data_share/fire_smoke_iter20230720/firesmoketaobao/val.cache’ images and labels… 2011 found, 0 missing, 123 empty, 0 corrupt: 100%|██████████| 2011/2011 [00:00<?,
1. 训练
1.1 yolov5 的 yolov5m6
所用命令:
python -m torch.distributed.launch --nproc_per_node=2 train.py --weights weights/yolov5m6_coco.pt --img 640 --epoch 500 --data fire_smoke.yaml --batch-size 24 --workers 8 --save-period 20
资源占用情况:
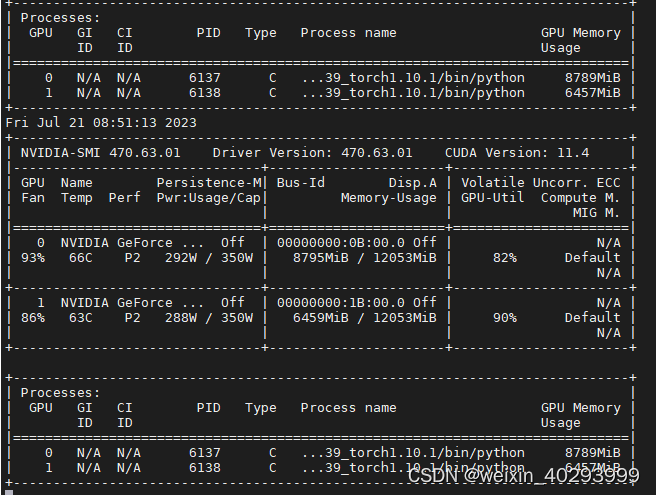
最终结果:
00%|██████████| 671/671 [02:05<00:00, 4.87it/s] 173/499 7.22G 0.02312 0.01991 0.005421 26 640: 1 00%|██████████| 671/671 [02:05<00:00, 5.35it/s]
Class Images Instances P R mAP50
all 2011 3236 0.81 0.76 0.825 0.556
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
174/499 7.22G 0.02303 0.01993 0.005404 16 640: 1
Class Images Instances P R mAP50
all 2011 3236 0.809 0.757 0.824 0.556
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
175/499 7.22G 0.02297 0.01974 0.005403 14 640: 1
Class Images Instances P R mAP50
all 2011 3236 0.808 0.758 0.823 0.556
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
176/499 7.22G 0.02281 0.02 0.005223 17 640: 1
Class Images Instances P R mAP50
all 2011 3236 0.807 0.759 0.823 0.555
Stopping training early as no improvement observed in last 100 epochs. Best resu lts observed at epoch 76, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `python tr ain.py --patience 300` or use `--patience 0` to disable EarlyStopping.
177 epochs completed in 6.973 hours.
Optimizer stripped from runs/train/exp5/weights/last.pt, 71.1MB
Optimizer stripped from runs/train/exp5/weights/best.pt, 71.1MB
Validating runs/train/exp5/weights/best.pt...
Fusing layers...
Model summary: 276 layers, 35254692 parameters, 0 gradients, 49.0 GFLOPs
Class Images Instances P R mAP50
all 2011 3236 0.815 0.75 0.829 0.559
fire 2011 1791 0.792 0.724 0.801 0.527
smoke 2011 1445 0.839 0.777 0.857 0.59
Results saved to runs/train/exp5
1.2 yolov5 的 yolov5l6
所用命令
nohup python -m torch.distributed.launch --nproc_per_node=2 train.py --weights weights/yolov5l6.pt --img 640 --epoch 500 --data fire_smoke.yaml --batch-size 24 --workers 8 --save-period 20 >yolov5l6.log 2>&1 &
相同的参数,large模型是比较吃显存的
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 26007 C ...39_torch1.10.1/bin/python 9325MiB |
| 1 N/A N/A 26008 C ...39_torch1.10.1/bin/python 8835MiB |
+-----------------------------------------------------------------------------+
Fri Jul 21 17:28:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.63.01 Driver Version: 470.63.01 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:0B:00.0 Off | N/A |
| 96% 69C P2 314W / 350W | 9331MiB / 12053MiB | 97% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... Off | 00000000:1B:00.0 Off | N/A |
| 88% 65C P2 309W / 350W | 8837MiB / 12053MiB | 90% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 26007 C ...39_torch1.10.1/bin/python 9325MiB |
| 1 N/A N/A 26008 C ...39_torch1.10.1/bin/python 8835MiB |
+-----------------------------------------------------------------------------+
然而它报错了:
版本信息:py39_torch1.10.1
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
30/499 7.79G 0.02661 0.02219 0.006819 11 640: 100%|██████████| 671/671 [02:58<00:00, 3.76it/s]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 84/84 [00:15<00:00, 5.35it/s]
all 2011 3236 0.805 0.742 0.816 0.536
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
31/499 7.79G 0.02635 0.02204 0.006999 47 640: 72%|███████▏ | 484/671 [02:08<00:50, 3.71it/s]WARNING:torch.distributed.elastic.agent.server.api:Received 1 death signal, shutting down workers
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 26007 closing signal SIGHUP
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 26008 closing signal SIGHUP
Traceback (most recent call last):
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/launch.py", line 193, in <module>
main()
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/launch.py", line 189, in main
launch(args)
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/launch.py", line 174, in launch
run(args)
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/run.py", line 710, in run
elastic_launch(
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 131, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 252, in launch_agent
result = agent.run()
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/elastic/metrics/api.py", line 125, in wrapper
result = f(*args, **kwargs)
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/elastic/agent/server/api.py", line 709, in run
result = self._invoke_run(role)
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/elastic/agent/server/api.py", line 843, in _invoke_run
time.sleep(monitor_interval)
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/site-packages/torch/distributed/elastic/multiprocessing/api.py", line 60, in _terminate_process_handler
raise SignalException(f"Process {os.getpid()} got signal: {sigval}", sigval=sigval)
torch.distributed.elastic.multiprocessing.api.SignalException: Process 25973 got signal: 1
(base) [jianming_ge@localhost fire_smoke_detect]$
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
166/499 7.81G 0.02208 0.01933 0.005174 15 640: 100%|██████████| 671/671 [02:59<00:00, 3.73it/s]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 84/84 [00:16<00:00, 5.00it/s]
all 2011 3236 0.815 0.755 0.819 0.558
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
167/499 7.81G 0.0221 0.01923 0.005168 19 640: 100%|██████████| 671/671 [03:00<00:00, 3.71it/s]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 84/84 [00:16<00:00, 5.00it/s]
all 2011 3236 0.813 0.757 0.82 0.558
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
168/499 7.81G 0.02198 0.01908 0.005147 19 640: 100%|██████████| 671/671 [03:00<00:00, 3.72it/s]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 84/84 [00:16<00:00, 5.11it/s]
all 2011 3236 0.815 0.756 0.82 0.558
Stopping training early as no improvement observed in last 100 epochs. Best results observed at epoch 68, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.
169 epochs completed in 9.309 hours.
Optimizer stripped from runs/train/exp7/weights/last.pt, 153.0MB
Optimizer stripped from runs/train/exp7/weights/best.pt, 153.0MB
Validating runs/train/exp7/weights/best.pt...
Fusing layers...
Model summary: 346 layers, 76126356 parameters, 0 gradients, 110.0 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 84/84 [00:20<00:00, 4.14it/s]
all 2011 3236 0.809 0.767 0.829 0.561
fire 2011 1791 0.787 0.745 0.804 0.532
smoke 2011 1445 0.831 0.788 0.855 0.59
由此可见,两个案子差不多~
1.3 yolov8 的训练
这是第一次用yolov8训练,还是有点小激动哦。
train: /data_share/data_share/fire_smoke_iter20230720/firesmoketaobao/train.txt
val: /data_share/data_share/fire_smoke_iter20230720/firesmoketaobao/val.txt
test: /data_share/data_share/fire_smoke_iter20230720/firesmoketaobao/test.txt
# number of classes
nc: 2
# class names
names: ['fire','smoke']
- 训练
cd /home/jianming_ge/workplace/zhongwaiyun/ultralytics-yolov8/ultralytics
yolo task=detect mode=train model=yolov8m.pt data=data/firesmoke.yaml batch=24 epochs=500 imgsz=640 workers=8 device='0,1' save_period=20
注意这里的 model=yolov8m.pt,需要下载,应该是下载到某个.cache 下或者哪里,
我把它放到当前路径下,发现还会下载:
作者说这不是一个bug,bug:https://github.com/ultralytics/ultralytics/issues/2698
@lucas-mior YOLOv8n is used for AMP checks prior to training start to decide whether to allow this training mode (as your console printout clearly displays). Your YOLOv8m model will train as normal.
Removing bug label. Please do not raise bug reports for questions.
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
108/500 5.59G 0.7987 0.7384 1.225 27 640: 100%|██████████| 671/671 [02:09<00:00, 5.17it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 84/84 [00:14<00:00, 5.95it/s]
all 2011 3236 0.804 0.761 0.821 0.571
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
109/500 5.59G 0.8037 0.7485 1.226 20 640: 100%|██████████| 671/671 [02:10<00:00, 5.15it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 84/84 [00:14<00:00, 5.85it/s]
all 2011 3236 0.803 0.762 0.821 0.571
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
110/500 5.6G 0.8024 0.7356 1.222 29 640: 100%|██████████| 671/671 [02:09<00:00, 5.18it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 84/84 [00:17<00:00, 4.82it/s]
all 2011 3236 0.803 0.759 0.82 0.571
Stopping training early as no improvement observed in last 50 epochs. Best results observed at epoch 60, best model saved as best.pt.
To update EarlyStopping(patience=50) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
110 epochs completed in 4.434 hours.
Exception in thread Thread-1:
Traceback (most recent call last):
File "/home/jianming_ge/miniconda3/envs/py39_torch1.10.1/lib/python3.9/threading.py", line 980, in _bootstrap_inner
Optimizer stripped from /home/jianming_ge/runs/detect/train9/weights/last.pt, 52.0MB
Optimizer stripped from /home/jianming_ge/runs/detect/train9/weights/best.pt, 52.0MB
Validating /home/jianming_ge/runs/detect/train9/weights/best.pt...
Model summary (fused): 218 layers, 25840918 parameters, 0 gradients, 78.8 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 84/84 [00:16<00:00, 5.03it/s]
all 2011 3236 0.792 0.754 0.821 0.574
fire 2011 1791 0.769 0.726 0.792 0.546
smoke 2011 1445 0.816 0.783 0.851 0.602
Speed: 0.2ms preprocess, 2.4ms inference, 0.0ms loss, 0.8ms postprocess per image
Results saved to /home/jianming_ge/runs/detect/train9
结论:
三个基本一致!没有明显的好坏之分