在上一篇博文中,博主已经整理了扩散模型(Diffusion Model,DDPM,GLIDE,DALLE2,Stable Diffusion)的基本原理,后续不再赘述其细节。作为一个最近被讨论热烈的方向,很自然地,它也被引入到各个任务中进行改造、改装和应用。
本文将整理扩散模型在诸多任务上的实施方案和效果讨论,包括其用于目标检测、图像分割、连贯故事合成、视频生成、3D场景生成和推理、多语言扩展、多模态扩展等任务。
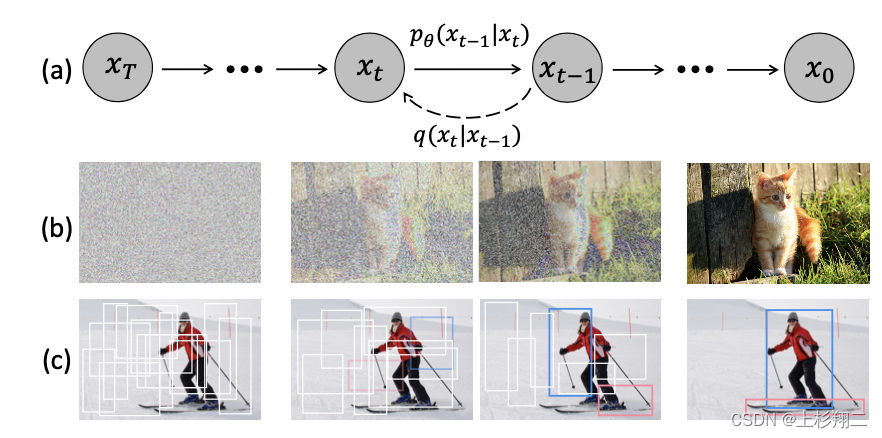
DiffusionDet: Diffusion Model for Object Detection
扩散模型到目标检测任务。作者的motivation来自于,传统的目标检测模型要么固定一些目标候选框后实施回归和分类,要么如DETR一样学习learnable的对象,但是否存在更加简洁的方法,在无需给模型任何先验就能完成识别呢?
具体的做法是将目标检测任务视为从一个噪声框到目标框的去噪扩散过程(noise-to-box),即
- 训练阶段,真实目标框不断扩散到随机噪声分布中,使得模型从中学习到这一噪声建模过程。
q
(
z
t
∣
z
0
)
=
N
(
z
t
∣
(
α
)
z
0
,
(
1
−
α
)
I
)
q(z_t|z_0)=N(z_t|\sqrt(\alpha)z_0,(1-\alpha)I)
q(zt∣z0)=N(zt∣(α)z0,(1−α)I)
然后噪声框中的RoI特征会被送入backbone模型进行编码(如ResNet、Swin Transformer等),编码后的特征会送入解码器中预测出无噪的真实目标框,即边界框的位置生成。
L t r a i n = 1 2 ∣ ∣ f θ ( z t , t ) − z 0 ∣ ∣ 2 L_{train}=\frac{1}{2}||f_{\theta}(z_t,t)-z_0||^2 Ltrain=21∣∣fθ(zt,t)−z0∣∣2 - 推理阶段,模型反转噪声框,将一组随机生成的目标框通过不断反向扩散为最终的预测结果。
这种设计的优势在于:
- 动态框设计,通过使用随机噪声框,使得DiffusionDet可以将训练和评估进行解耦。
- 逐步的扩散模型的灵活性能够适应对精度和速度有不同要求的检测场景。
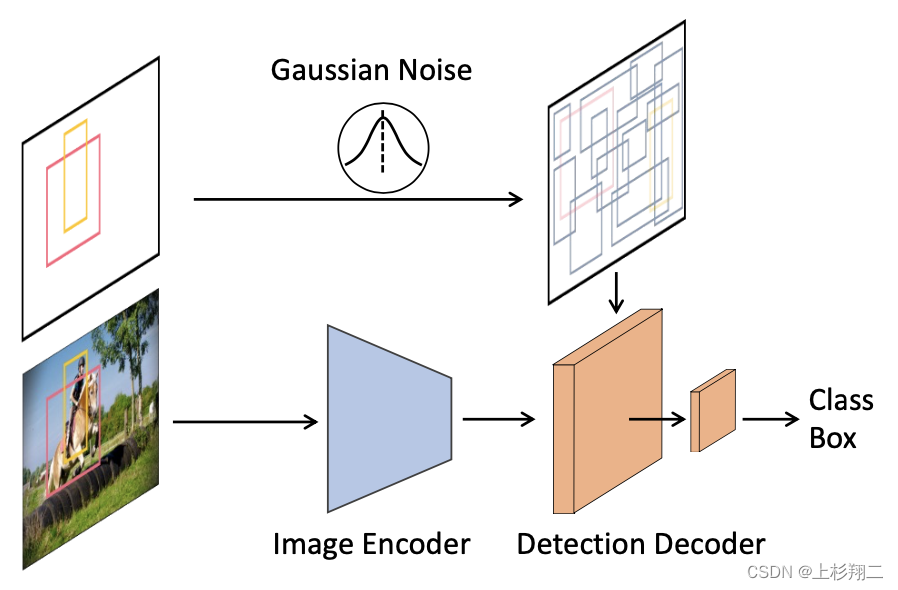
训练和推理的伪代码如下,
def train_loss(images, gt_boxes):
"""
images: [B, H, W, 3]
gt_boxes: [B, *, 4]
# B: batch
# N: number of proposal boxes
"""
# 编码图像特征
feats = image_encoder(images)
# Pad gt_boxes to N,不同图像可能目标框数量不一样,需要padding
pb = pad_boxes(gt_boxes) # padded boxes: [B, N, 4]
# 信号放缩
pb = (pb * 2 - 1) * scale
# 扩散T步
t = randint(0, T) # time step
eps = normal(mean=0, std=1) # 加入噪声: [B, N, 4]
pb_crpt = sqrt( alpha_cumprod(t)) * pb +
sqrt(1 - alpha_cumprod(t)) * eps #alpha用于控制噪声尺度
# 预测
pb_pred = detection_decoder(pb_crpt, feats, t)
# 计算loss
loss = set_prediction_loss(pb_pred, gt_boxes)
return loss
def infer(images, steps, T):
"""
images: [B, H, W, 3]
# steps: number of sample steps
# T: number of time steps
"""
# 编码图像特征
feats = image_encoder(images)
# 随机噪声框: [B, N, 4]
pb_t = normal(mean=0, std=1)
# uniform sample step size
times = reversed(linespace(-1, T, steps))
# 逐步反扩散,[(T-1, T-2), (T-2, T-3), ..., (1, 0), (0, -1)]
time_pairs = list(zip(times[:-1], times[1:])
for t_now, t_next in zip(time_pairs):
# Predict pb_0 from pb_t,从0到t
pb_pred = detection_decoder(pb_t, feats, t_now)
# Estimate pb_t at t_next,从t到t+1
pb_t = ddim_step(pb_t, pb_pred, t_now, t_next)
# Box renewal,更新目标框
pb_t = box_renewal(pb_t)
return pb_pred
paper:https://arxiv.org/abs/2211.09788
code:https://github.com/ShoufaChen/DiffusionDet
Label-Efficient Semantic Segmentation with Diffusion Models
有了检测,自然不会少了分割任务。作者的动机在于DDPM等扩散模型已经被证明拥有良好的生成、复原能力,那么其是否也可以用做于语义分割的领域,特别是在标记数据稀缺的情况下。
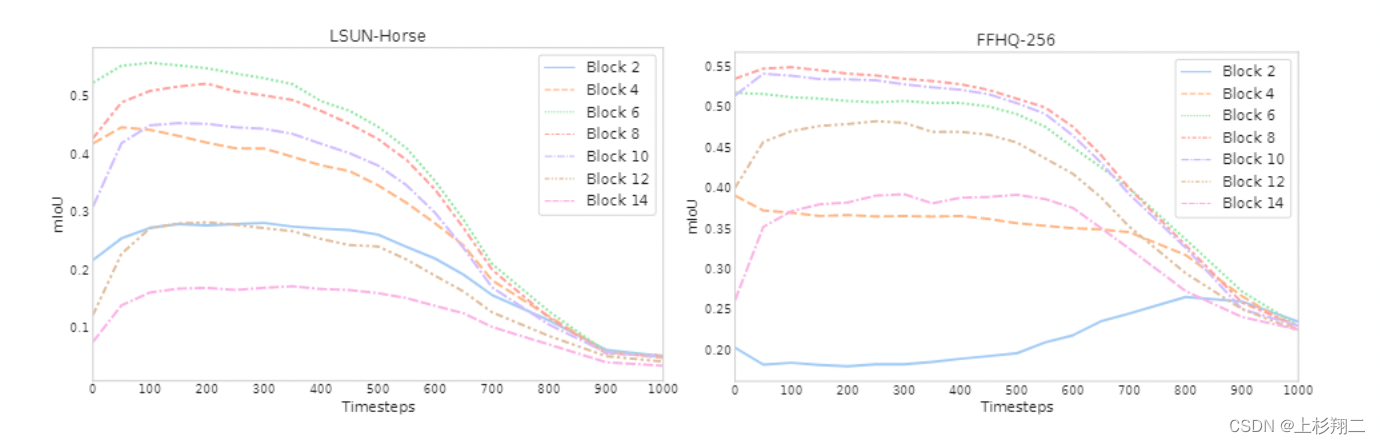
首先如上图所示,作者先研究中逆扩散过程中的中间层UNet在语义捕捉上的能力。左图和右图分别是在LSUN Horse和FFHQ-256数据集上训练的DDPM模型,横轴为噪声预测器 θ ( x t , t ) θ(x_t,t) θ(xt,t)在不同t时刻产生的表示,并分别手动将每个像素分配给语义类中的一个,计算平均IoU,即该图刻画了产生特征的IoU随不同的块和扩散步骤的变化,以测试DDPM所生成的像素级表示是否有效地捕获了有关语义的信息。
结论是,DDPM能够在生成的过程中提取高层次的语义信息,特别是时间步早期通常没有什么信息、而Unet解码器的中间层的信息最为丰富。中间DDPM激活的潜在有效性意味着它们可以作为密集预测任务的图像表示,因此使用DDPM提取特征,并研究这些特征可能捕获的语义信息对下游任务来说更为适用。
基于此,作者的模型结构如下图所示。
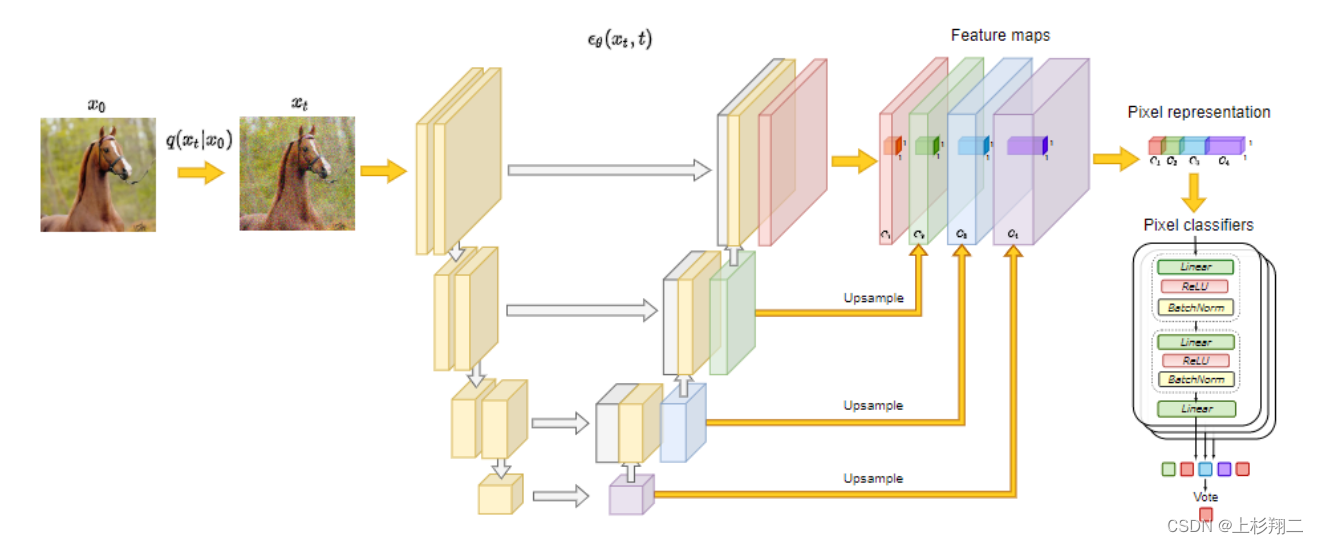
具体来说,先以无监督的方式训练扩散模型DDPM,然后使用它的Unet组建提取像素级特征。
- 扩散模型提取像素级表示。如图前半部分先对不同block中进行特征抽取并上采样,concat之后作为像素级的图像表征。此处送入的图像由少部分的有标注数据和大量的无标注数据组成。
- 然后送入一组MLP的分类器中去,然后预测每个像素的语义标签完成分割任务即可。
paper:https://arxiv.org/abs/2112.03126
code:https://github.com/yandex-research/ddpm-segmentation

Synthesizing Coherent Story with Auto-Regressive Latent Diffusion Models
既然扩散模型如stable diffusion模型能够根据文本配图了,那么它是否能按照句子的描述生成一系列故事化的图片呢?连贯视觉故事合成,旨在合成一系列符合句子描述的图像。
如上图所示的多帧图像,其不光要保证图像质量,还需要保证画面的连贯性,这就要模型需要同时考虑到历史时刻的描述和场景、外观。研究者提出了自回归潜在扩散模型(auto-regressive latent diffusion model, AR-LDM),以实现更好的跨帧一致性,模型结构如下图:
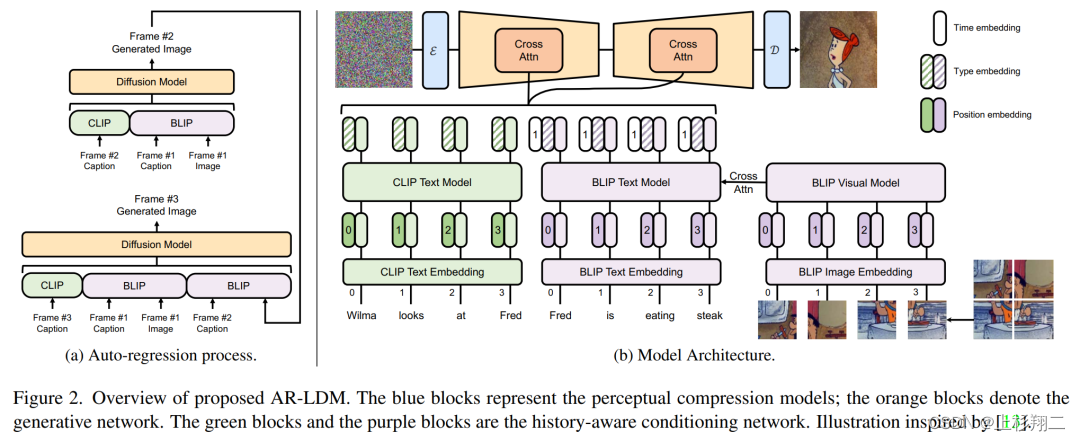
具体来说,AR-LDM利用自回归的方式逐帧生成多张图像,且对于每一帧,模型同时受到当前描述的和历史描述和图像作为指导。如上图左侧,第二帧的生成图像将被输入到第三帧图像的生成过程中,具体的生成模型细节主要有,
- 模型输入为CLIP抽取当前描述特征、BLIP抽取历史描述特征、BLIP抽取历史图像特征。其中CLIP使用文本编码器、BLIP则文本和视觉都会使用,其中BLIP 使用视觉语言理解和生成任务与大规模过滤干净的 Web 数据进行预训练。以下公式可以更为清晰的理解输入, c ’ j = C L I P ( c j ) , 直 接 得 到 特 征 c’_j=CLIP(c_j),直接得到特征 c’j=CLIP(cj),直接得到特征 m < j = [ B L I P ( c 1 , x ’ 1 ) ; … ; B L I P ( c j − 1 , x ’ j − 1 ) ] , 得 到 历 史 时 刻 的 特 征 m_{<j}=[BLIP(c_1,x’_1);…;BLIP(c_{j-1},x’_{j-1})],得到历史时刻的特征 m<j=[BLIP(c1,x’1);…;BLIP(cj−1,x’j−1)],得到历史时刻的特征 ϕ j = [ c ’ j + c t y p e ; m < j + m t y p e + m < j t i m e ] , 结 合 t i m e 、 t y p e 进 行 拼 接 \phi_j=[c’_j+c^{type};m_{<j}+m^{type}+m^{time}_{<j}],结合time、type进行拼接 ϕj=[c’j+ctype;m<j+mtype+m<jtime],结合time、type进行拼接
- 然后拼接得到的特征,将在潜在空间中执行正向和反向扩散过程。在这个过程中,像素中冗余的语义和无意义信息将被消除。即在扩散过程中使用潜在表示 z = ϵ ( x ) z=\epsilon(x) z=ϵ(x)代替像素,最终图像生成可以用 D(z) 进行解码。 z 0 [ j ] ~ p θ ( z 0 [ j ] ϕ j ) z^{[j]}_0 ~~ p_{\theta}(z^{[j]}_0 \phi_j) z0[j]~ pθ(z0[j]ϕj) x ’ j = D ( z 0 [ j ] ) x’_j=D(z^{[j]}_0) x’j=D(z0[j])
paper:https://arxiv.org/pdf/2211.10950.pdf
MagicVideo: Efficient Video Generation With Latent Diffusion Models
既然能生成多张连续图片,那么Diffusion Models能直接生成视频吗?听起来很cool,但具体实施起来十分困难,主要有以下几点原因:
- Data scarcity。如何构建视频-文本描述对的大规模数据集。想要用一句话描述视频内容并不容易,而且视频中可能存在多个场景,而其中大多数帧不会提供有用的信息。
- Complex temporal dynamics。如何处理视频中的复杂信息。除了局部信息外,视频还带有视觉动态信息,这比图像更难学习。但添加不同帧之间的时间信息后,对视频内容进行建模变得非常具有挑战性。而对于视频生成来说,帧之间的连续性要求是非常高的。
- High computation cost。一个短的视频每秒包含大约 30 帧,因此单个视频片段中就将有数百数千个帧,对于模型来说,处理这种长距离生成需要大量的计算资源。
因此,这些限制也迫使最近基于扩散的模型生成低分辨率视频,然后应用超分辨率来提高视觉质量。然而,即使是这个技巧也不足以降低巨大的计算复杂度,那么如何得到一个高质量且时间一致的生成模型呢?作者们提出一个MagicVideo模型,其使用预训练的变分自动编码器在潜在空间中生成视频,其模型结构如下图所示,
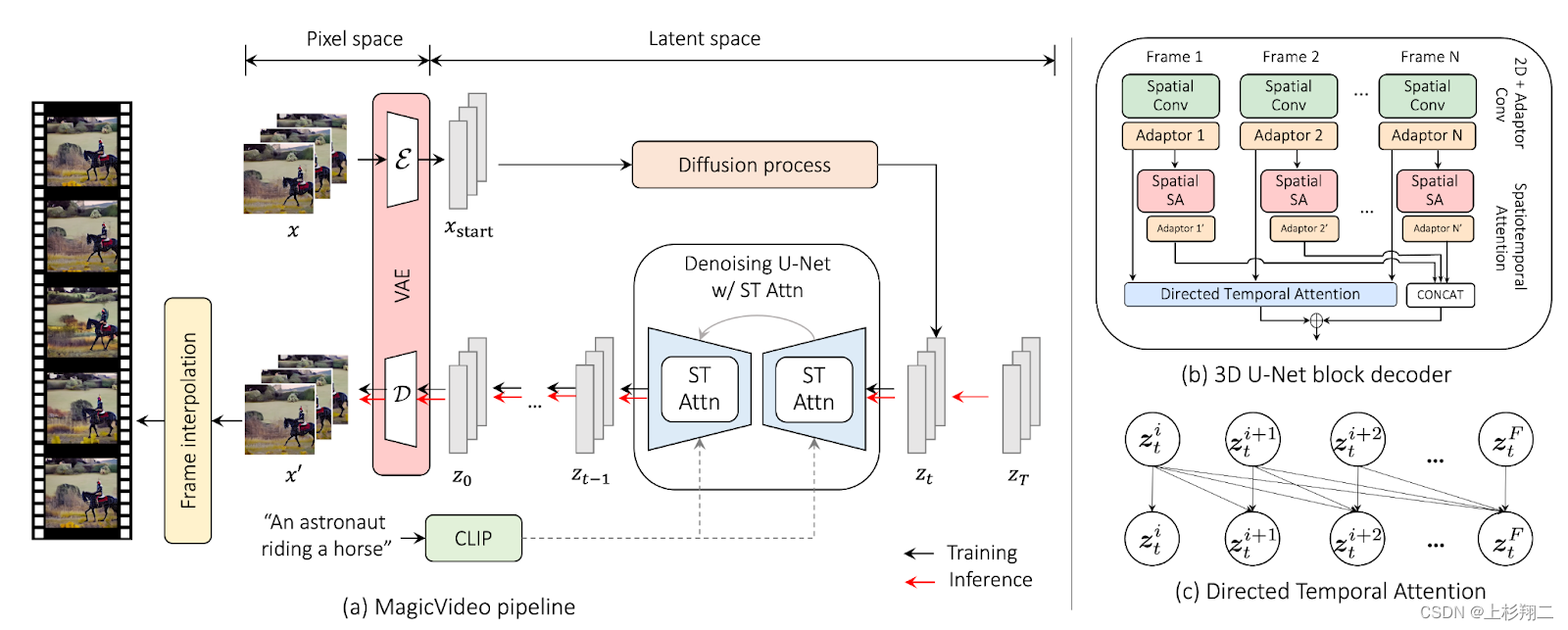
应对这几个挑战,MagicVideo 首先使用 2D 卷积而不是 3D 卷积来克服视频文本配对数据集的问题。而且时间计算运算符与 2D 卷积运算一起使用,以处理视频中的空间和时间信息。此外,使用 2D 卷积使 MagicVideo 能够使用文本到图像模型的预训练权重。 然后使用 directed自注意力模块学习帧间关系以解决帧间一致性问题。具体来说,如上图,
- 扩散过程和Diffusion类似。在训练阶段,时间步 t 将从 [0, T] 中随机采样,输入视频帧通过扩散过程被逐步加入噪声,然后同样使用U-Net解码器用于重建视频帧,此处是2D卷积。而在推理阶段,随机采样一个高斯噪声,并重复T次去噪过程, 然后将去噪的潜在向量 z 送入 VAE 解码器并转换为 RGB 像素空间。
- 时空注意 (ST-Attn) 模块的结构。 其中ST-Attn 中使用的时空注意力S-Attn和T-Attn,且T-Attn部分使用directed自注意力直接学习帧间的依赖关系。 z t = S A t t n ( z t − 1 ) + T A t t n ( z t − 1 ) z_t=SAttn(z_{t-1})+TAttn(z_{t-1}) zt=SAttn(zt−1)+TAttn(zt−1) S A t t n = C r o s s A t t n ( L N ( M H S A ( L N ( z t − 1 ) ) ) ) SAttn=CrossAttn(LN(MHSA(LN(z_{t-1})))) SAttn=CrossAttn(LN(MHSA(LN(zt−1)))) A t = S o f t m a x ( Q t K t T / d ⋅ M ) A_t=Softmax(Q_tK_t^T/\sqrt{d}\cdot M) At=Softmax(QtKtT/d⋅M)
paper:https://arxiv.org/abs/2211.11018
website:https://magicvideo.github.io/
RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation
来自Adobe。既然可以生成视频了,那么换个角度继续它能应对3D场景的生成和推理吗?那么尝试将3D结构引入到传统的2D diffusion中试试吧。
如下图所示。同样是利用前向和后向过程的图像去噪架构,它仅使用单眼 2D 图像的监督下进行训练,在每个去噪步骤中生成并渲染场景的中间三维表示。
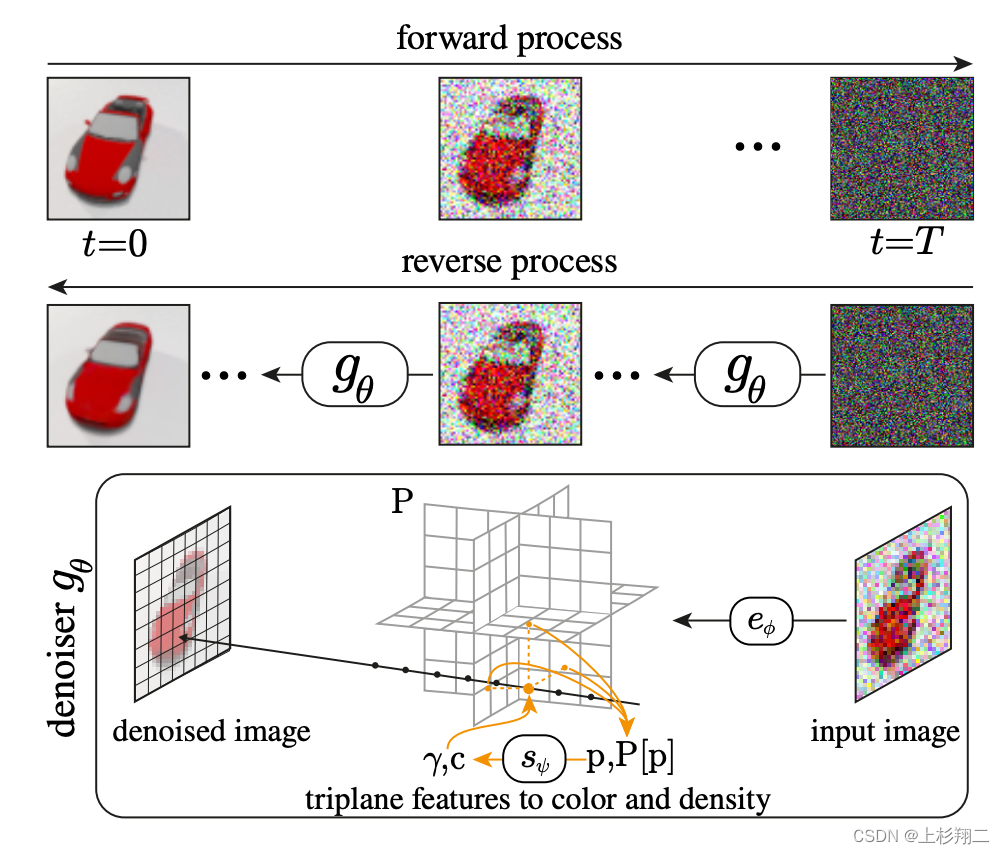
具体来说,RenderDiffusion模型将原本2D diffusion下的decoder的架构变为3D表示之间的加噪和去噪,然后再通过体积渲染获得去噪后的3D图像。
- Image Diffusion Model。如图的上半部分,流程和DDPM一致,其中逆扩散过程预测t=0的图像。
- 3D-Aware Denoiser。引入潜在的3D表示,渲染得到3D图像,分为triplane encoder和triplane renderer 来编码和渲染。
- 3D Reconstruction。与现有的 2D 扩散模型不同,RenderDiffusion 是从 2D 图像重建 3D 场景。其中denoising step t r t_r tr的选择可以控制保真度和泛化性。
paper:https://arxiv.org/pdf/2211.09869.pdf
code:https://github.com/Anciukevicius/RenderDiffusion
AltDiffusion
AltDiffusion模型的主要贡献是将Stable Diffusion扩展到中文中,来自智源研究院,其不仅更能理解中文语义、还能生成更具中国画的绘画风格。
AltDiffusion使用AltCLIP作为text encoder,然后基于 Stable Diffusion 在WuDao 和 LAION 数据集上训练中英双语的Diffusion模型和支持9种语言的多语AltDiffusion-m9模型。具体模型细节还没有被披露出,AltDiffusion模型中比较重要的AltCLIP模型结构如下图,
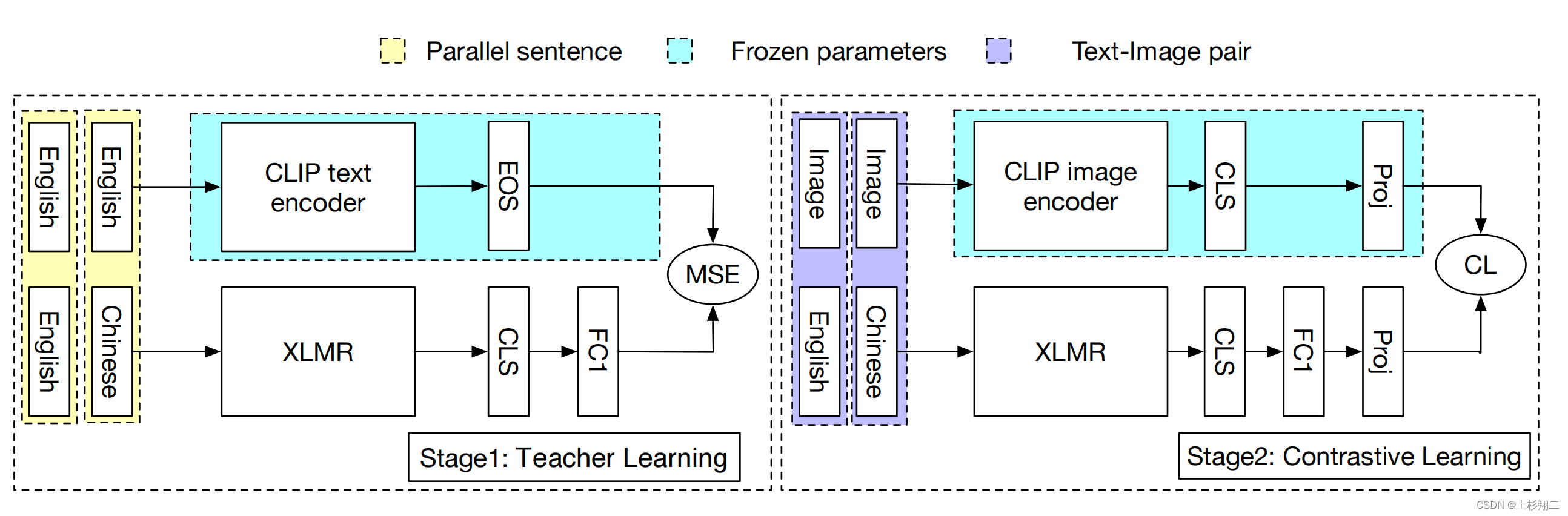
分为两个阶段,
- stage1: teacher learning。在平行知识蒸馏阶段,其他语言的表征的将于CLIP的英文表征对齐,以将文本编码器更换为多语言文本编码器 XLMR。这个阶段只需要多语言平行语料。
- stage2: contrastive learning。使用少量的中-英图像-文本对(一共约2百万)来训练XLMR文本编码器以更好地适应图像编码器,以学习多语言图文表征。
基于AltCLIP,类似于其他的Diffusion结构训练得到AltDiffusion。
- AltDiffusion:https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion
- HuggingFace:https://huggingface.co/spaces/BAAI/bilingual_stable_diffusion
- AltCLIP:https://github.com/FlagAI-Open/FlagAI/examples/AltCLIP
- paper:https://arxiv.org/abs/2211.06679
Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
多语言之后呢?既然这么多任务都可以使用Diffusion进行尝试,于是,SHI Labs提出Versatile Diffusion(VD)直接提供一种统一模型去处理:文本到图像、图像到文本生成、图像编辑等多功能扩散模型。
一个关键问题是多功能框架如何需要面向不同任务,这往往需要设计不同模型,因此Versatile Diffusion提出将现有的单流扩散管道扩展为多流网络,这样就能在一个统一的模型中处理文本到图像、图像到文本、图像编辑和文本变体。具体模型结构如下所示,
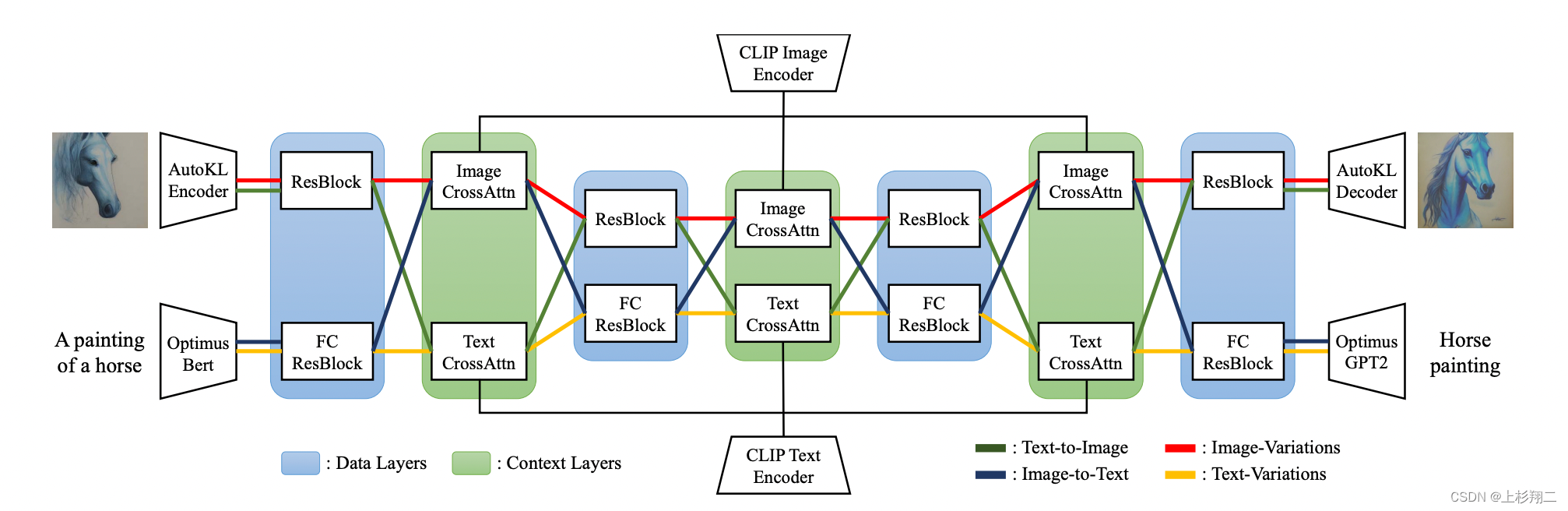
单流扩散时和Stable Diffusion类似,基于UNet,使用CLIP/Bert作为Context的条件输入。为了统一多流任务,VD包含以下三个部分,
- Diffuser:采用带有cross-attention的UNet网络。即在文到图生成任务下,采用图片UNet和文本的cross-attention上下文;在图到图生成任务下,采用图片的UNet和图片的cross-attention上下文,如上图所示不同颜色的线。
- VAE:图像使用Stable Diffusion相同的Autoencoder-KL,文本使用Bert编码、GPT2解码。
- Context encoder:图像和文本都基于CLIP。
paper:https://arxiv.org/pdf/2211.08332.pdf
code:https://github.com/SHI-Labs/Versatile-Diffusion