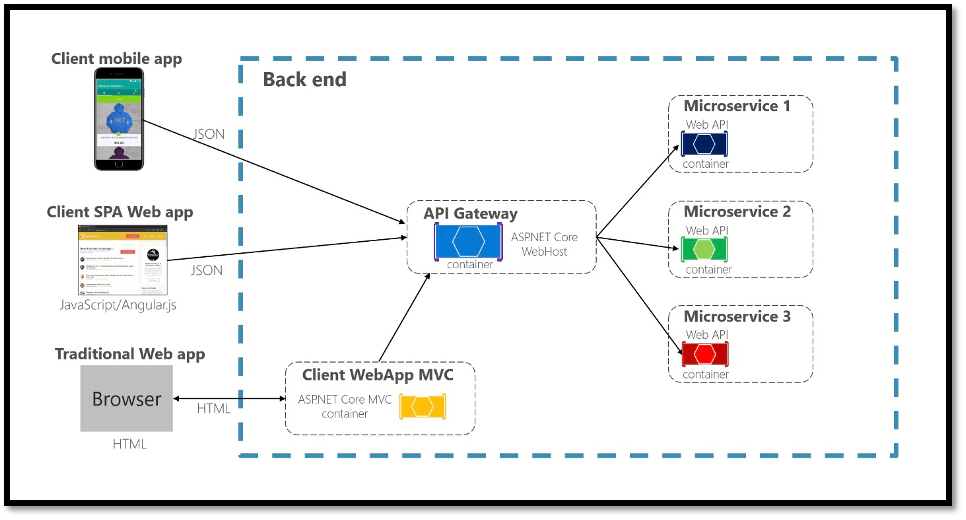
文章目录
- Consistency-guided Meta-Learning for Bootstrapping Semi-Supervised Medical Image Segmentation
- 摘要
- 本文方法
- 实验结果
Consistency-guided Meta-Learning for Bootstrapping Semi-Supervised Medical Image Segmentation
摘要
医学成像取得了显著的进步,但通常需要大量高质量的注释数据,这些数据耗时且成本高昂。为了减轻这种负担,半监督学习作为一种潜在的解决方案引起了人们的关注。在本文中,我们提出了一种用于自引导医学图像分割(MLB-Seg)的元学习方法,这是一种解决半监督医学图像分割挑战的新方法。
- 首先涉及在一小组干净标记的图像上训练分割模型,以生成未标记数据的初始标签。
- 为了进一步优化这个自举过程,我们引入了一个逐像素权重映射系统,该系统可以动态地为初始化的标签和模型自己的预测分配权重。这些权重是使用元过程确定的,该过程优先考虑损失梯度方向更接近干净数据的像素,这是基于一小组精确注释的图像。
- 为了促进元学习过程,我们还引入了一种基于一致性的伪标签增强(PLE)方案,该方案通过集成来自相同输入的各种增强版本的预测来提高模型自身预测的质量。
- 为了提高通过对单个输入的多次增强得到的权重图的质量,我们在PLE方案中引入了一个平均教师。该方法有助于降低权重图中的噪声,稳定权重图的生成过程。
代码地址
本文方法
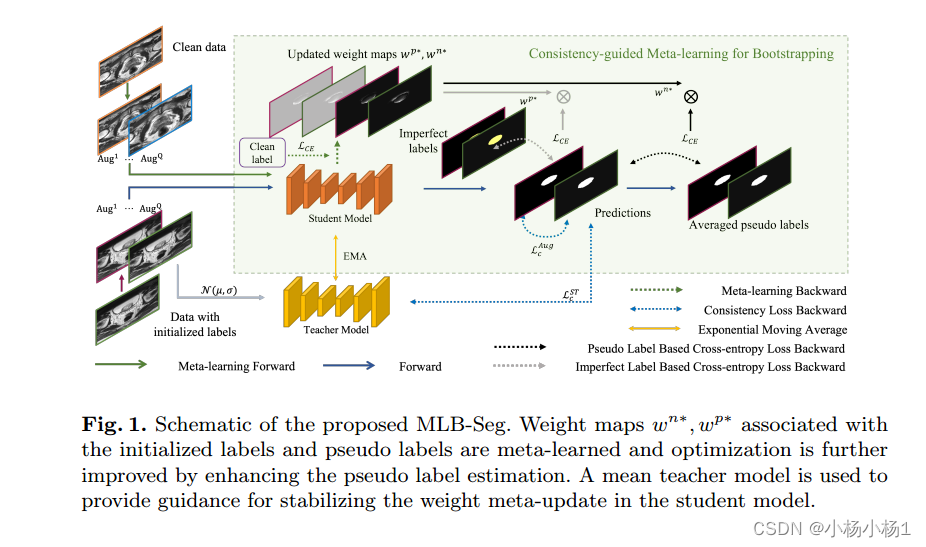
- 首先使用基线模型估计所有未标记数据的标签,该模型是在干净数据上训练的
- 利用学习者自己的预测(即伪标签),从干净集学习并自我引导
目标为:
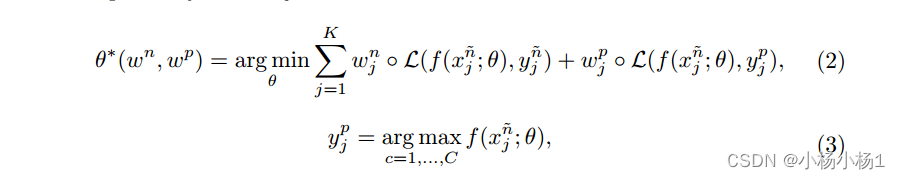
交叉熵损失
要达到这个目标:
步骤1:基于Sn和当前权重映射集更新θt+1。接下来,在训练步骤t中,我们计算θt+1以接近最优θ∗(wn, wp)如下:
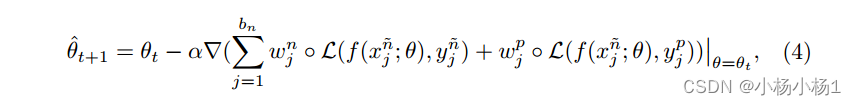
步骤2:在干净的训练数据上,通过最小化元目标函数中的标准交叉熵损失,生成基于Sc和θt+1的元学习权映射wn∗,wp∗:
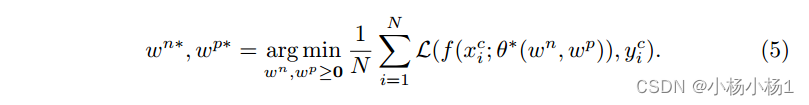
这里我们将wn /p中的每个元素都限制为非负,以防止潜在的不稳定训练。这样的元学习过程产生的权重图可以更好地平衡初始化和伪标签的贡献,从而减少错误像素带来的负面影响。为了减少计算开销,我们只在一个小的干净标签数据集S c上应用wn/pj的一步梯度下降。
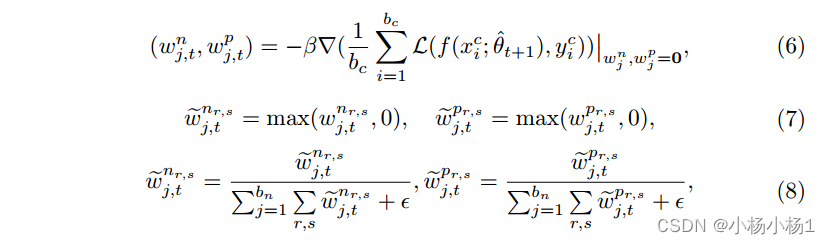
步骤3:使用元学习的权重映射在空间上调制逐像素的损失以更新θt+1
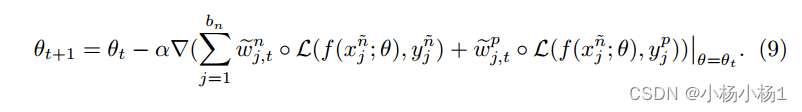
为了生成更可靠的伪标签,我们提出了基于一致性的伪标签增强(PLE)方案,该方案在相同输入的增强版本之间强制一致性。
单独使用PLE可能会导致性能下降,因为权重图中的噪声会增加。这种不稳定性会在随后的训练迭代中加剧。为了在元学习过程中解决这一问题,我们建议使用具有一致性损失的平均教师模型
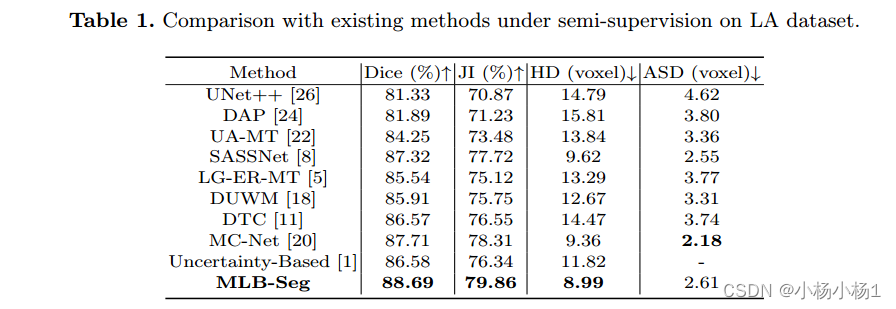
实验结果