Hadoop 之 Spark 配置与使用
- 一.Spark 配置
- 1.Spark 下载
- 2.单机测试环境配置
- 3.集群配置
- 二.Java 访问 Spark
- 1.Pom 依赖
- 2.测试代码
- 1.计算 π
- 三.Spark 配置 Hadoop
- 1.配置 Hadoop
- 2.测试代码
- 1.统计字符数
一.Spark 配置
环境说明
| 环境 | 版本 |
|---|---|
| Anolis | Anolis OS release 8.6 |
| Jdk | java version “11.0.19” 2023-04-18 LTS |
| Spark | 3.4.1 |
1.Spark 下载
Spark 下载
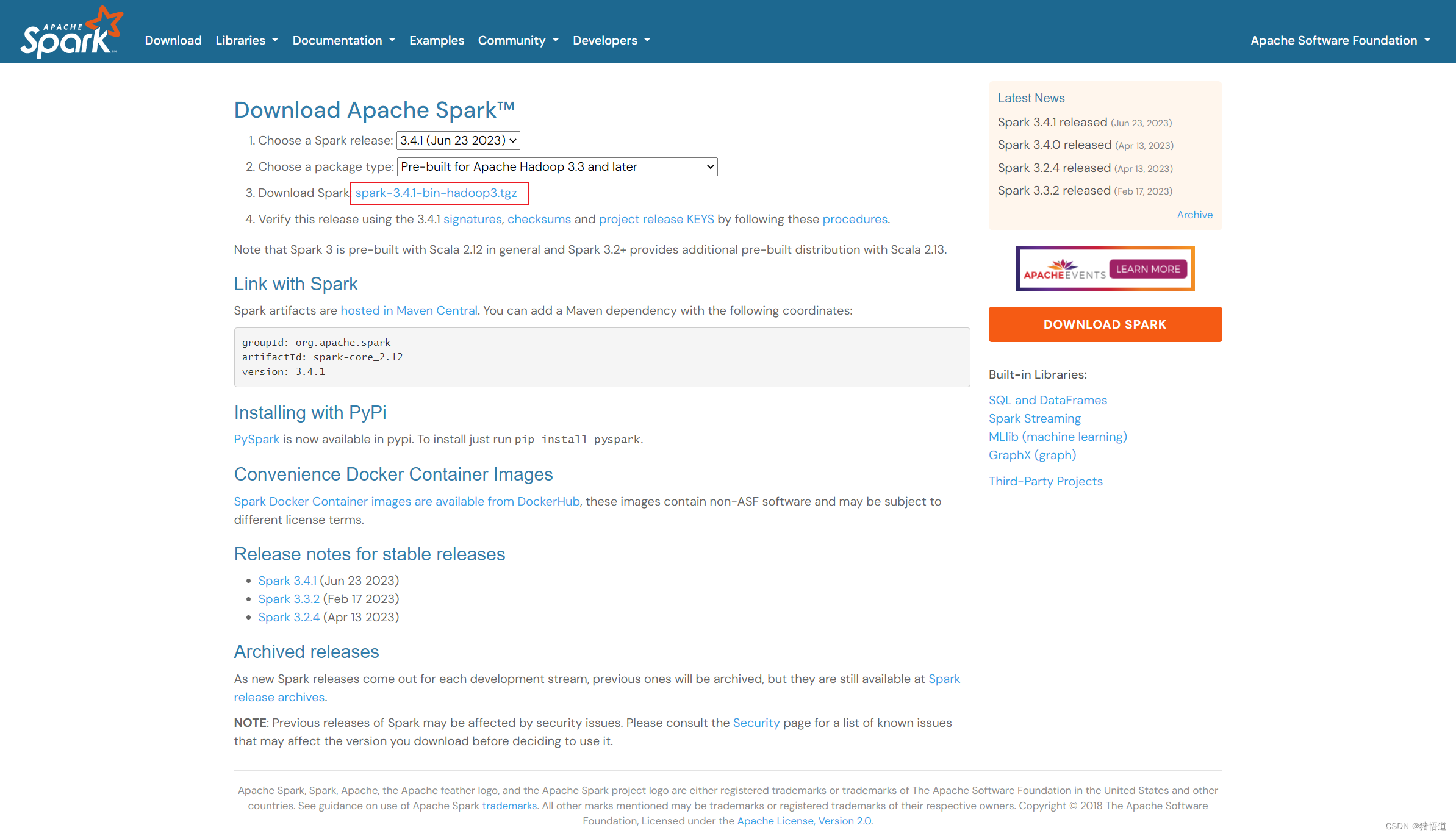
2.单机测试环境配置
## 1.创建目录
mkdir -p /usr/local/spark
## 2.解压 sprak 到指定目录
tar -zxvf spark-3.4.1-bin-hadoop3.tgz -C /usr/local/spark/
## 3.进入安装目录(可将解压后文件夹重命名为 spark 即可)
cd /usr/local/spark/spark-3.4.1-bin-hadoop3/
## 4.修改环境变量并更新
echo 'export SPARK_HOME=/usr/local/spark/spark-3.4.1-bin-hadoop3' >> /etc/profile
echo 'PATH=${SPARK_HOME}/bin:${PATH}' >> /etc/profile
source /etc/profile
## 5.复制 spark 配置
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
## 6.测试
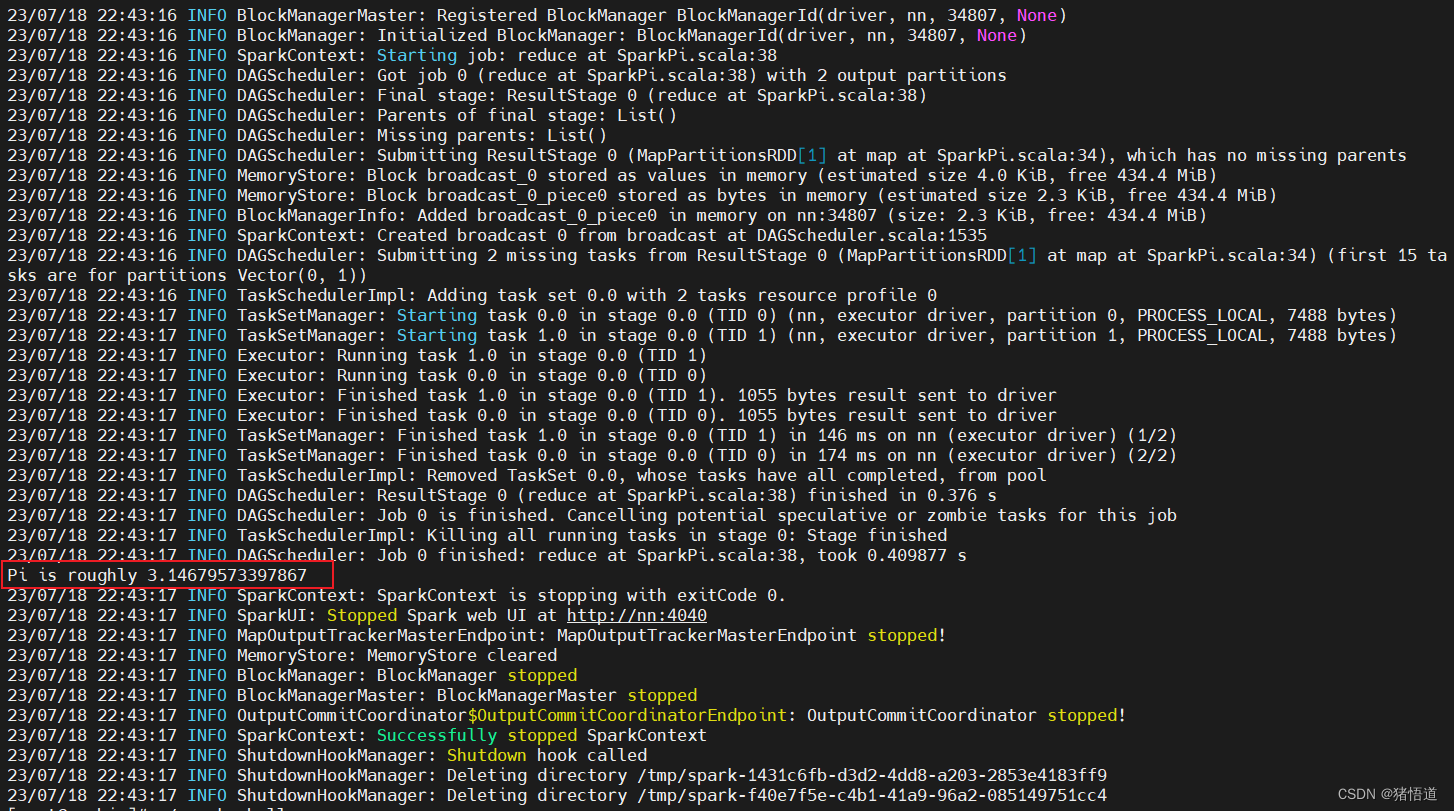
cd $SPARK_HOME/bin
./run-example SparkPi
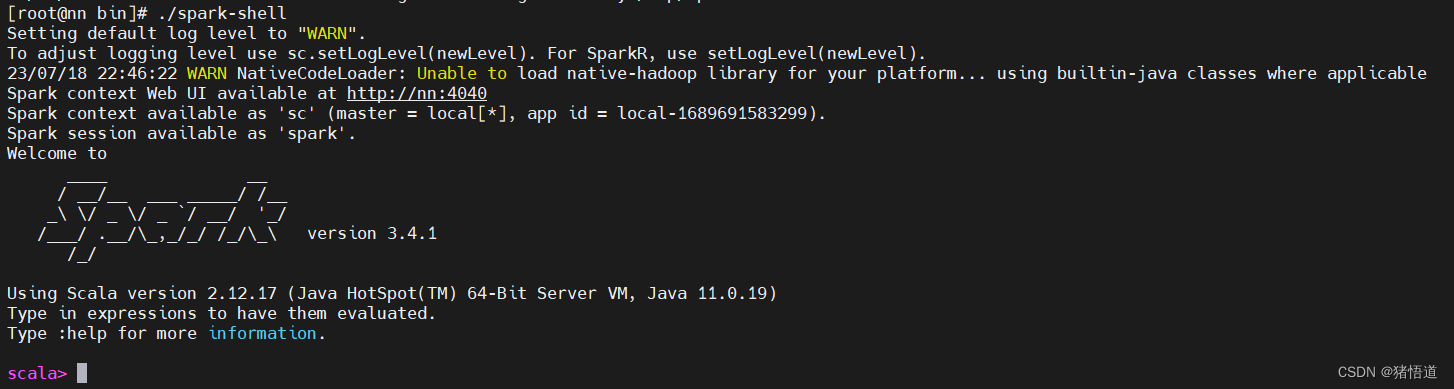
## 1.启动
./spark-shell
UI访问:控制打印地址为虚拟机域名,Windows 未添加 Host 解析,直接通过IP地址访问
## 1.停止
scala> :quit
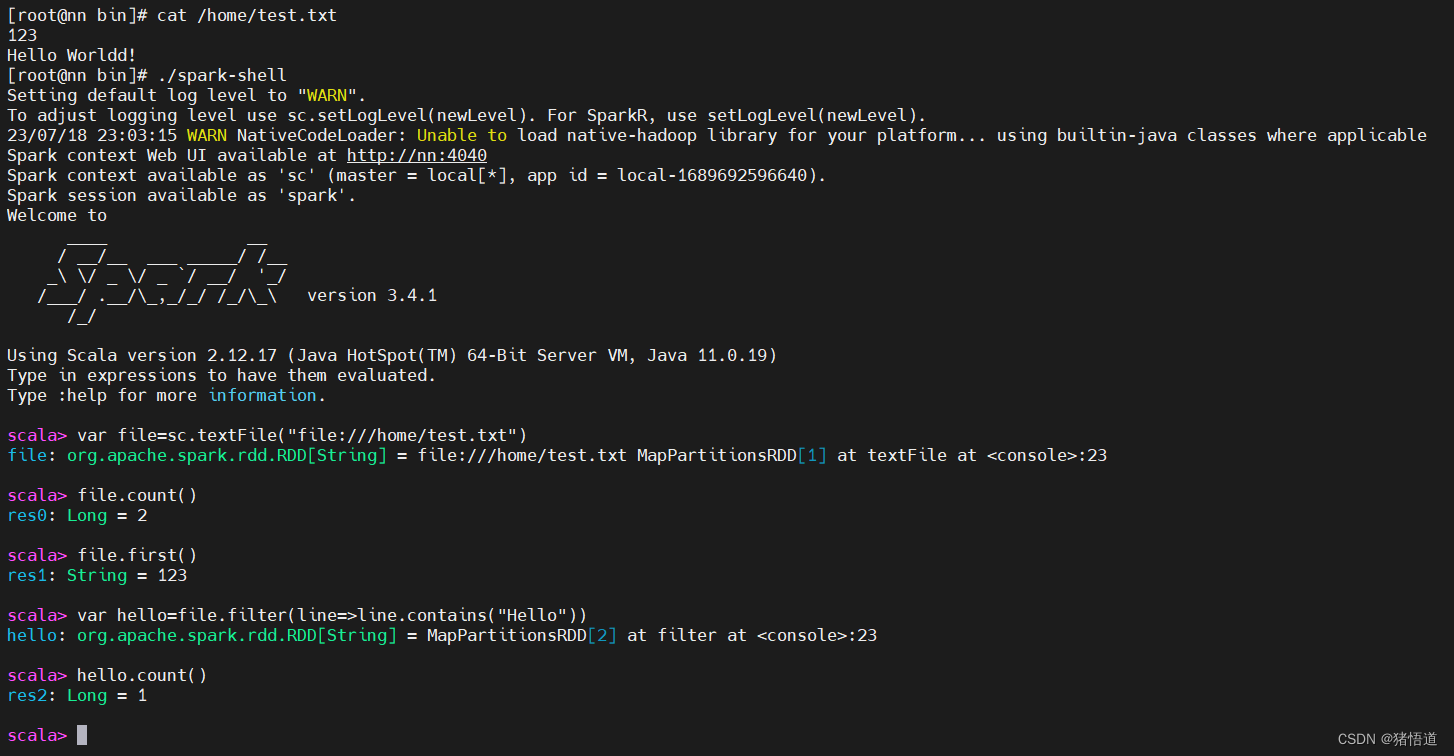
## 1.交互分析
cd $SPARK_HOME/bin
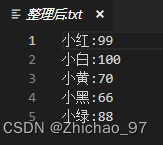
cat /home/test.txt
./spark-shell
## 2.取文件
var file=sc.textFile("file:///home/test.txt")
## 3.打印行数和第一行信息
file.count()
file.first()
## 4.过滤
var hello=file.filter(line=>line.contains("Hello"))
hello.count()
3.集群配置
| 域名 | 地址 | 类别 |
|---|---|---|
| nn | 192.168.1.6 | master |
| nd1 | 192.168.1.7 | slave |
| nd2 | 192.168.1.8 | slave |
同单机配置,在 nd1 、nd2 部署 spark,并设置环境变量(也可利用 scp 命令将住节点下配置好的文件拷贝到从节点)
## 1.修改 nn 配置(此处旧版本为 slave)
cd $SPARK_HOME/conf
cp workers.template workers
vim workers
## 2.添加主从节点域名
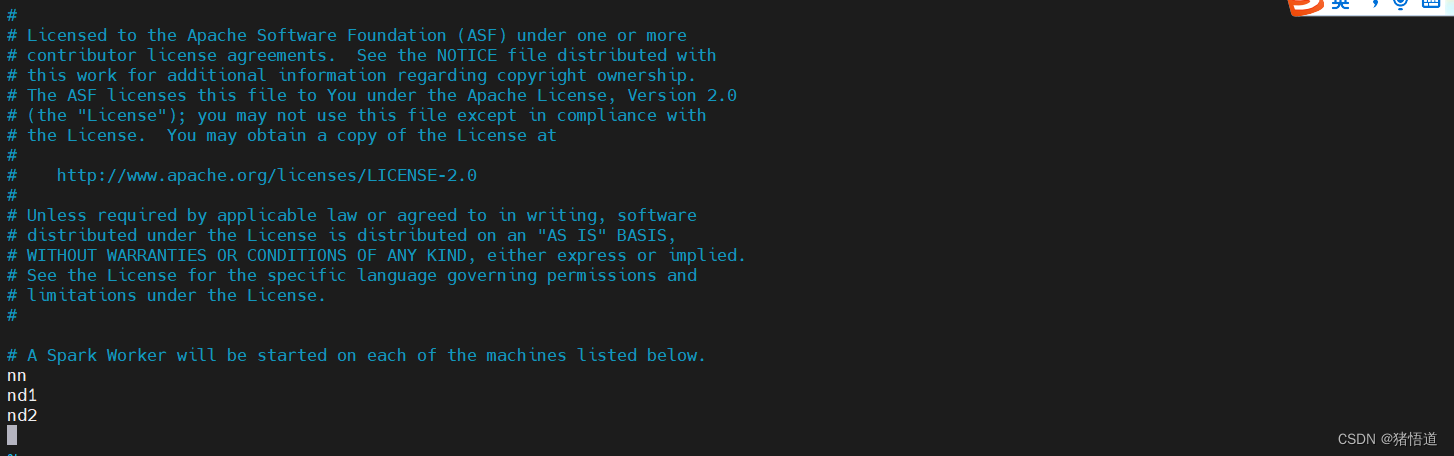
echo 'nn' >> workers
echo 'nd1' >> workers
echo 'nd2' >> workers
## 3.保存并将配置文件分发到 nd1、nd2
scp workers root@nd1:$SPARK_HOME/conf/
scp workers root@nd2:$SPARK_HOME/conf/
## 4.增加 spark 配置
echo 'export JAVA_HOME=/usr/local/java/jdk-11.0.19/' >> spark-env.sh
echo 'export SPARK_MASTER_HOST=nn' >> spark-env.sh
echo 'export SPARK_MASTER_PORT=7077' >> spark-env.sh
## 5.将配置分发到 nd1、nd2
scp spark-env.sh root@nd1:$SPARK_HOME/conf/
scp spark-env.sh root@nd2:$SPARK_HOME/conf/
workers 文件配置内容如下
## 1.修改 host 将本机域名与IP地址绑定
vim /etc/hosts
## 2.启动
cd $SPARK_HOME/sbin/
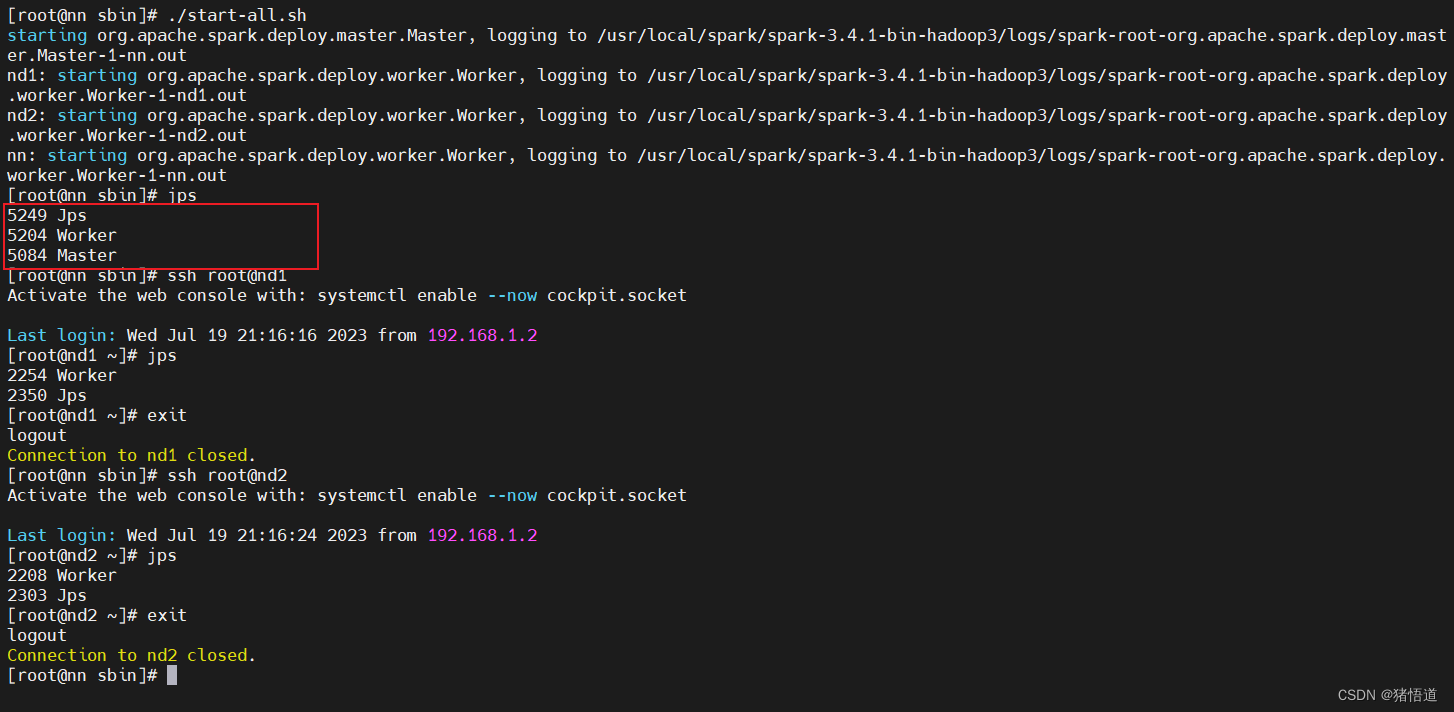
./start-all.sh
## 3.停止
./stop-all.sh
Host 配置

启动日志
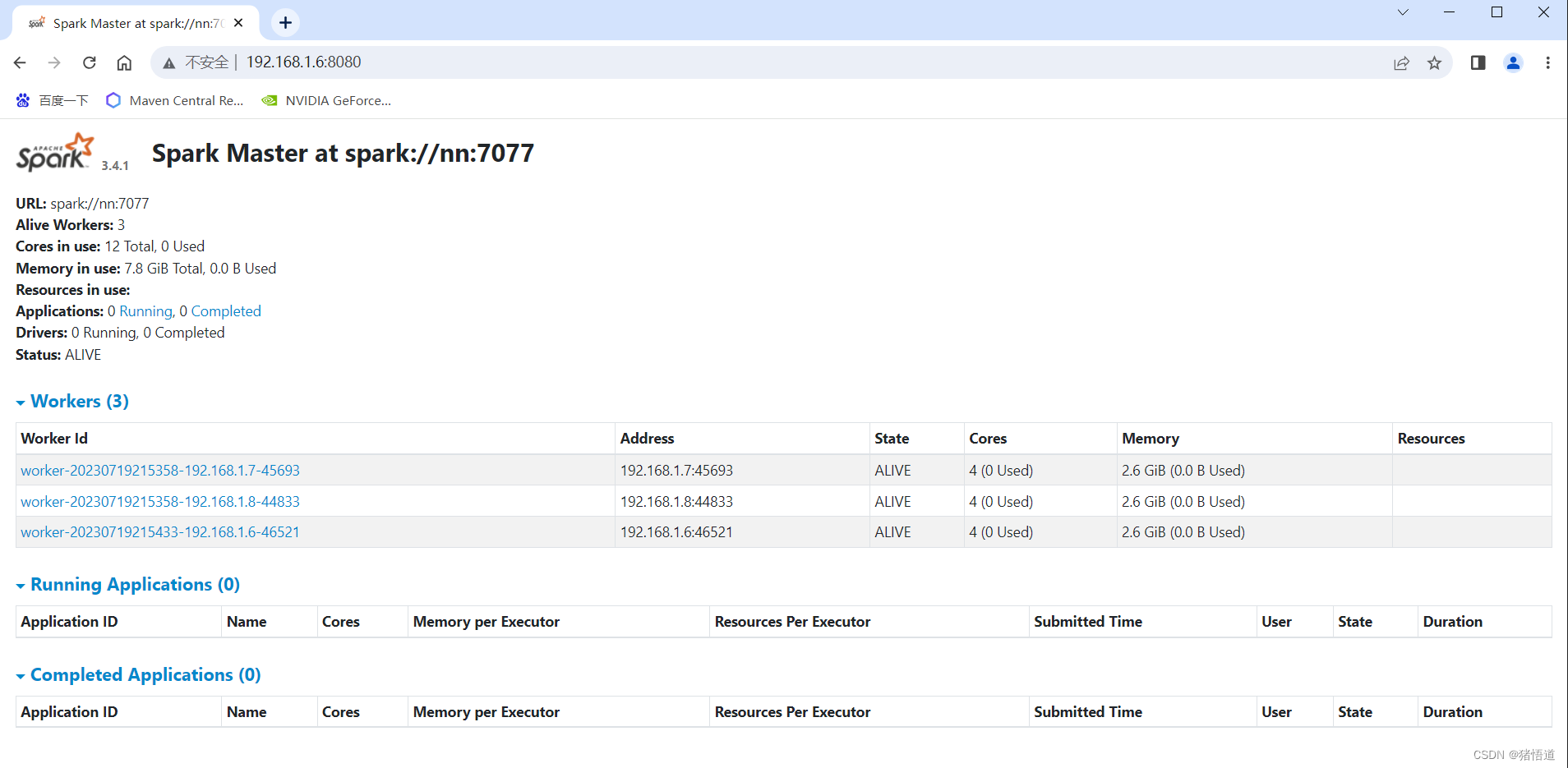
查看集群 UI:http://192.168.1.6:8080/
二.Java 访问 Spark
当前测试环境为 VM Ware 虚拟机,本地为 WIN 10 IDEA
调试问题记录:
- Spark 回调本机超时,Win 防火墙未关闭,端口不通
- Lamdba 语法 cannot assign instance of java.lang.invoke.SerializedLambda,本地 Jdk 版本和 Spark 集群环境 Jdk 版本要一致
- String Serialized 序列化问题,Java 依赖包和 Spark Jar 包版本要一致
- Jdk 版本过高,某些类解析提示 unnamed,可以在 IDEA 启动命令配置上:–add-exports java.base/sun.nio.ch=ALL-UNNAMED
- 域名 由于虚拟机原因,本机存在虚拟网卡,虚拟机内访问本地会通过域名(默认本地主机名)访问,要注意服务回调端口绑定的地址是虚拟网卡地址还是真实网卡地址,并将该地址配置配置到虚拟机的 Hosts | Linux 配置域名解析 vim /etc/hosts

1.Pom 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.1</version>
</dependency>
</dependencies>
<build>
<finalName>mySpark</finalName>
</build>
</project>
2.测试代码
1.计算 π
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import static org.apache.spark.sql.functions.col;
/**
* @author Administrator
*/
public class SparkApp {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf()
.setAppName("MySpark")
//远程连接时需要将本地包分发到 worker 否则可能报错: cannot assign instance of java.lang.invoke.SerializedLambda
.setJars(new String[]{"E:\\IdeaProjects\\spark-demo\\target\\mySpark.jar"})
.setMaster("spark://192.168.1.6:7077");
JavaSparkContext jsc = new JavaSparkContext(conf);
getPi(jsc);
}
/**
* 计算 pi
* 即(0,1)随机数落在 1/4 圆占单位正方形的概率 => (1/4 * (Pi*1^2))/(1^2) => Pi/4 = count/numSamples
*/
public static void getPi(JavaSparkContext jsc){
int numSamples = 1000000;
List<Integer> l = new ArrayList<>(numSamples);
for (int i = 0; i < numSamples; i++) {
l.add(i);
}
//统计命中数
long count = jsc.parallelize(l).filter(i -> {
double x = Math.random();
double y = Math.random();
return x*x + y*y < 1;
}).count();
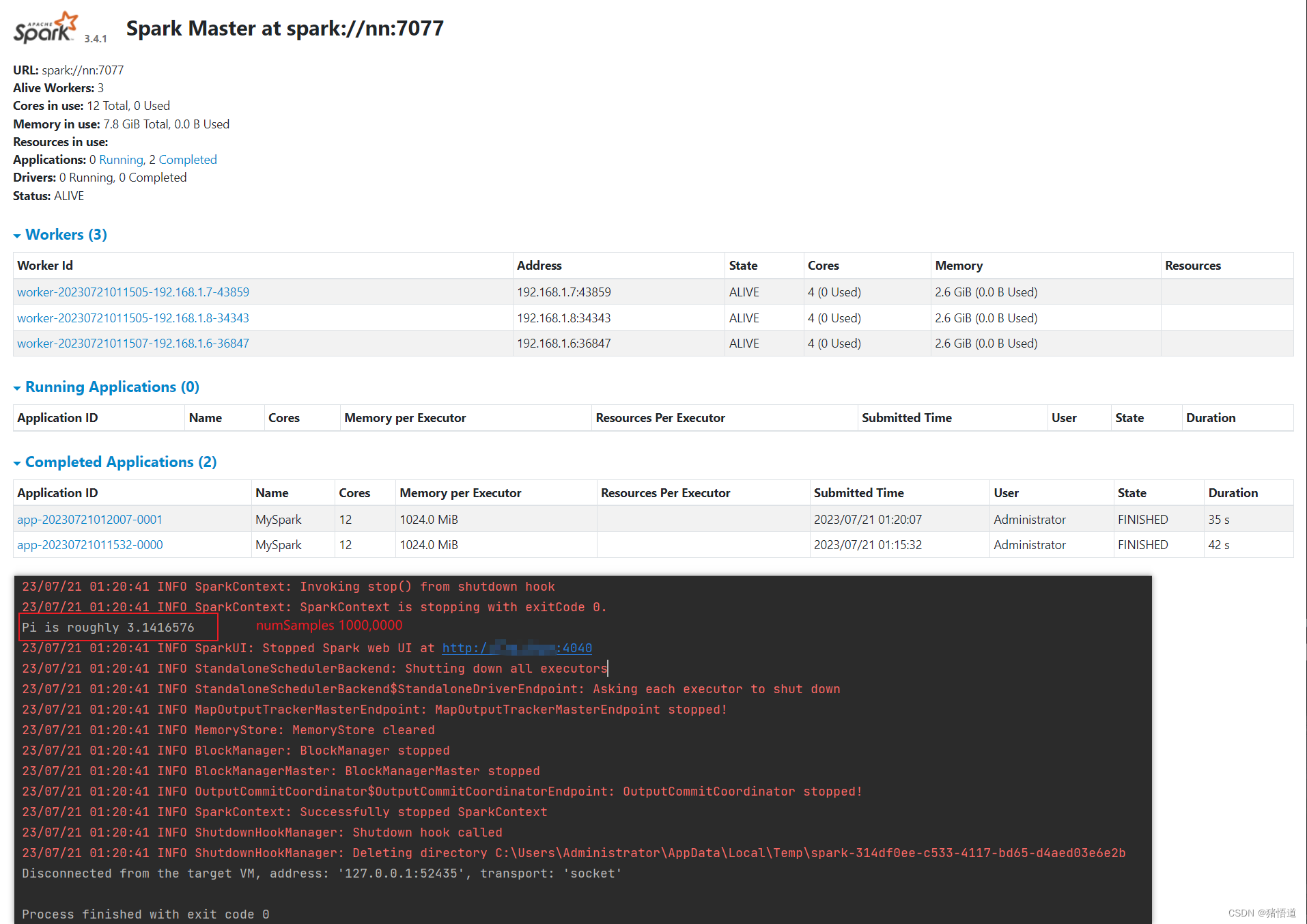
System.out.println("Pi is roughly " + 4.0 * count / numSamples);
}
}
三.Spark 配置 Hadoop
1.配置 Hadoop
## 1.停止 spark 服务 修改主节点 spark 配置(基于前面教程搭建的 Hadoop 集群)
echo 'export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.3.6/etc/hadoop' >> $SPARK_HOME/conf/spark-env.sh
## 2.启动 Hadoop 服务
$HADOOP_HOME/sbin/start-all.sh
## 3.启动 Spark 服务
$SPARK_HOME/sbin/start-all.sh
## 4.查看 Hadoop 文件
hadoop fs -cat /log/test.txt

2.测试代码
1.统计字符数
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* @author Administrator
*/
public class SparkApp {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf()
.setAppName("MySpark")
//远程连接时需要将本地包分发到 worker 否则可能报错: cannot assign instance of java.lang.invoke.SerializedLambda
.setJars(new String[]{"E:\\IdeaProjects\\spark-demo\\target\\mySpark.jar"})
.setMaster("spark://192.168.1.6:7077");
JavaSparkContext jsc = new JavaSparkContext(conf);
dataFrame(jsc);
}
/**
* DataFrame API examples
*/
public static void dataFrame(JavaSparkContext jsc){
// Creates a DataFrame having a single column named "line"
JavaRDD<String> lines = jsc.textFile("hdfs://192.168.1.6:9000/log/test.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
System.out.println(totalLength);
}
}