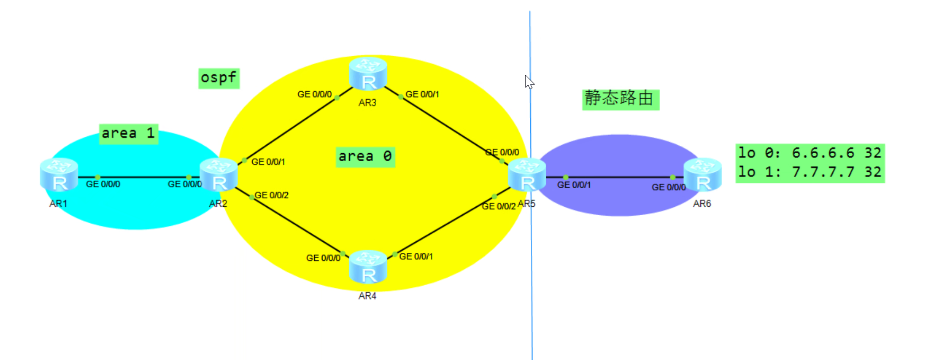
Alluxio技术分析
Alluxio: A Virtual Distributed File System
Alluxio主要解决的基于磁盘的分布式存储层性能低下的问题,通过alluxio提供的分布式内存来加速数据分析。
Alluxio的这种通过内存加速数据的想法其实是有明确的使用场景的:
- Immutable data:存储层的数据一旦写入,不可以变,例如存储引擎,hdfs,oss
- Deterministic job:任务能通过重试稳定重现,例如mapreduce,spark,presto,使用recomputation处理失效恢复。
- Locality based scheduling:任务调度基于数据的locality特性,如果不满足,就变成解决了磁盘IO问题,又陷入网络IO瓶颈。
- All data vs working set:底库数据集非常大,但是实际访问的数据差不多可以用内存装下;
- Program size vs data size:在大数据里面,类似的操作重复访问相同的数据,适合使用缓存技术来解决。
如果数据存储主要使用RAM,不太可能通过传统的多副本技术来解决节点故障的问题,在单副本的限制下,Alluxio引入了类似spark的lineage思路,有了lineage但是当recomputation链路太长效率还是太差,所以又引入了checkpoint机制,有了lineage和checkpoint,节点故障的情况下,如何高效调度多个任务的recomputation,Alluxio的论文基本上围绕上述3点展开。
总结一下上面提到的3个技术,后面详细介绍这3个关键技术点:
- lineage技术解决节点失效后recomputation的问题
- checkpoint机制解决lineage链路太长效率低的问题
- 资源调度策略解决recomputation的资源调度的效率和公平问题
三大关键技术
1. lineage技术
1.1 背景
目标工作负载特性
- 不可变数据:数据一旦写入就不可变,因为主要的底层存储系统(如HDFS)只支持追加操作
- 确定性作业:许多框架,如MapReduce和Spark,在作业中使用recomputation进行容错,并要求用户代码具有确定性。在同样的假设下提供了基于lineage的恢复,非确定性框架仍然可以使用复制将数据存储在Alluxio中
- 基于Locality的调度:许多计算框架基于局部性调度作业,以最小化网络传输,因此读取可以是数据本地的
- 所有数据与工作集:尽管整个数据集很大,必须存储在磁盘上,许多应用程序的工作集适合内存
- 程序大小与数据大小:在大数据处理中,相同的操作会重复应用于海量数据。因此,在许多情况下,复制程序比复制数据要便宜得多
1.2 lineage的实现
lineage的原理非常简单,因为alluxio对外提供的是文件/block操作接口,所以alluxio内部维护了一个计算框架下面文件生成的关系,简称为lineage,如果计算框架运行到某个节点失败了,当前操作的文件基本就丢失了,所以这里根据之前保存的文件生成的关系,重做任务,把任务恢复到故障前的状态。下面是个简单的例子:

上述的spark job通过读取文件A,加工后生成文件B,在生成B之前,记录lineage信息L,这个lineage信息被持久化到alluxio的master,当B丢失的时候,能够通过A和L信息重新计算出B。L的操作通过下面2个接口实现:

数据量比较多的情况下,记录lineage的job信息的数据量会很多,所以,alluxio支持对lineage信息做垃圾收集,alluxio会在一个lineage record做完checkpoint,例如持久化上面的B文件的信息之后,就可以删除L信息。
2.Checkpoint算法
Alluxio缺乏类似spark任务运行的上下文,但是Alluxio的任务相对较短并且连续运行,所以累积的lineage是非常多的,所以在没有checkpoint的情况下需要很长的重新计算时间,因此checkpoint对Alluxio的性能至关重要。
首先,alluxio的checkpoint必须是在后台以一个比较低的优先级运行,这样可以避免对当前的任务有影响。其次需要有一个比较好的checkpoint算法来决定checkpoint的频率和时机。因此Allxio对checkpoint算法有3个基本要求:
- Recomputation 时间是有边界的,不能无限长,在像Alluxio这样的长时间运行系统中,lineage链可能会增长很长,因此checkpoint算法应该提供一个在发生故障时重新计算数据所需时间的界限。请注意,限定重新计算时间也会占用用于重新计算的计算资源。
- Checkpoint的时候,能够持久化热点文件。例如一个被多次join的事实表(一张会被多个Job用来join或者参与计算的表需要被持久化)。
- 避免checkpoint 临时文件。大数据工作负载会产生大量临时数据,超过70%的数据在一天内被删除,甚至不包括随机数据,理想的算法可以避免检查这些数据的大部分。
为了达到上述目标,alluxio设计了一个叫做edge的边缘算法。首先,边缘检查点对lineage图的edge(叶)进行检查(因此得名)。其次,它包含优先级,有利于检查高优先级文件而不是低优先级文件。最后,该算法只缓存可以放入内存的数据集,以避免同步检查点检查,这会降低磁盘写入速度。为了理解这个算法,需要首先理解并不是checkpoint刷文件的频率越高越好,举了一个例子:假设异步checkpoint保存每个文件,一个lineage 链条,A1 A2…A6,当A6被生成,可能A1和A2才被checkpoint到持久层,如果故障发生,A3到A6的数据都需要重新计算,导致重新计算时间越长。edge算法的思路是把lineage记录的文件,根据他们的生成关系组织成一个DAG,优先checkpoint 边缘(edge,所以叫edge算法)上的文件,算法实现如下:
- Edge算法对文件的关系建模,构建一个DAG,节点就是文件,A生成B就构建一个A到B的边。
- 优先级一样的情况下,算法首先checkpoint DAG的边缘,也就是叶子节点上的文件
- 优先checkpoint高优先级的文件。
- Edge算法只checkpoint能放到内存的数据,避免checkpoint文件太大,会导致checkpoint时间太长,降低刷盘效率。
下面有一个例子可以用来理解edge算法:

- 2个任务生成了A1和B1 2个文件,算法checkpoint 这2个文件A1和B1
- 当这2个文件被checkpoint,A3,B4,B5成为叶子节点,checkpoint A3,B4,B5文件,
- 最后A6和B9成为叶子节点,checkout 把A6和B9持久化。
Checkpoints 热点文件
Alluxio 根据文件使用的频率给文件一个权重,并使用LFU策略来淘汰内存的数据(这个是在worker节点做的)。这个策略可以覆盖在DAG中有一些点,因为频繁被读取,点被重复创建导致他的边非常多,这些点代表的文件会被高优先级checkpoint。
作者通过分析yahoo的spark集群,统计文件被访问的频率,发现文 件的访问符合zipf分布(对于CDN的内容管理,有一个基本定律,就是大家常说对于内容的访问遵循80/20原则,也就是20%的内容,会占有80%的访问量。),所以作者认定访问次数大于2次的就是高优先级的文件,Alluxio可以通过master来配置threshold,作者使用上述的workload测试,86%的checkpoint 的文件是叶子节点,余下的非叶子节点,checkpoint上述优先级高的文件。
LFU策略:LFU算法的基本思想和所有的缓存算法一样,都是基于locality假设(局部性原理),也就是如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。LFU是基于这种思想进行设计:一定时期内被访问次数最少的页,在将来被访问到的几率也是最小的。
**实现原理:**LFU将数据和数据的访问频次保存在一个容量有限的容器中,当访问一个数据时:
- 该数据在容器中,则将该数据的访问频次加1。
- 该数据不在容器中,则将该数据加入到容器中,且访问频次为1。
当数据量达到容器的限制后,会剔除掉访问频次最低的数据。下图是一个简易的LFU算法示意图:

上图中的LFU容器是一个链表,会动态地根据访问频次调整数据在链表中的位置,方便进行数据的淘汰,可以看到,在第四步时,因为需要插入数据F,而淘汰了数据E。
处理大文件

为什么不checkpoint大文件,作者对Facebook的maprecude任务处理的文件大小分布做了调研,得到下面的结论和优化方案:
- 可以把所有文件(除了特别大的数据集)都缓存到内存中,96%的MR 任务的文件可以放到他的内存中。
- 对文件的访问周期性突发高峰,在高峰期,checkpoint的叶子节点会把DAG拆的散,一旦高峰期过去,edge算法开始checkpoint其他非叶子节点的文件,因此大部分在内存中的文件都可以在被内存挤占出之前被checkpoint。
- 如果在内存中的高优先级文件还没有被checkpoint,alluxio checkpoint可以变成同步的,避免recompute有一个长的lineage链条。
- 除了特别大的文件,大部分数据有时间被checkpoint,文件还没有被checkpoint写入持久化存储,就被从内存挤占的概率很小。
3.资源调度策略
在大部分情况下,系统会有足够的资源做recomputation,简单处理就是使用一个静态的调度策略,固定部分资源做recomputation,但是这样会限制集群的可用性,为了介绍alluxio的调度策略设计原则,作者定义了alluxio调度希望达到的3个要求:
- 兼容优先级。如果job有优先级,recomputation能够兼容这个优先级。例如,如果低优先级Job请求文件,则recomputation对高优先级Job的影响应最小。但是,如果高优先级Job稍后请求该文件,则recomputation Job的重要性应该增加。
- Resource sharing:如果没有recomputation任务,则整个集群资源应用于正常工作
- 避免级联recomputation:当节点失效或发生故障,可能会出现多个文件丢失的情况,recomputation如果不考虑数据的依赖,可能会导致递归Job启动。
为了兼容优先级,作者首先介绍了基于优先级的调度策略,他的算法思想是:
- 首先给所有的recomputation任务默认最低优先级,因为他们对其他Job的影响最小。
- 通过优先级继承来处理不同任务之间对文件的依赖问题。
举例说明,有3个spark任务J1,J2, J3,他们的优先级递增,这3个任务由于节点故障丢失了2个文件F1,F2,需要重新计算的任务为R1和R2,然后J2需要依赖F2作为输入

before:
因为F2的recomputation 任务R2优先级比J2低,所以先跑J2,而J2把资源都用尽了,这样R2得不到资源,J2就会被block。
after:
采用了优先级继承之后,因为J2请求F2,alluxio增加R2的优先级为P2,如图(a)所示,又因为F2晚些会被J3读到,所以R2继承J3优先级,R2优先级为P3,如图(b)所示,经过继承,R2优先执行。
上述调度策略考虑了优先级,并解决了层次关系导致的任务block的问题,但是没有考虑公平的原则,所以作者进一步提出了Fair Sharing Based Scheduler。
**公平共享调度策略(**Fair Sharing Based Scheduler)
核心思想是在上述调度策略上通过依赖层次增加公平调度原则,举例说明如下:

J1,J2,J3的资源调度权重分别为W1,W2,W3,其中WR是提供给故障恢复使用,其最小共享单元为1。当节点失效:
- 所有需要recompute的任务均分WR,在上面的例子中R2和R3立即执行,分享权重为1。上图1。
- 当一个任务请求lost的文件,请求文件的这个job的权重转移到recomputation的任务,上面例子中,因为J2要求F2,F2丢失需要R2 recomputation,所以J2从W2中分出a的权重,自己得到(1-a)权重资源,而R2分得a的权重。上图2.
- J3也需要F2作为输入,所以J3也从W3分出a,自己得到(1-a),R2又从W3得到a。上图3
- 当R2完成之后,J2和J3恢复之前的份额W2,W3。上图4.
这个方案能满足我们的目标,兼容优先级和公平,当没有任务请求lost的文件的时候,大家分享recomputation设定的资源WR,当job有丢失的文件的时候,recomputation job分到的资源相应增加。因为增加的份额来自请求的job,不会对现有的正常任务有影响。
Recomputation顺序
Recomputing一个文件,可能会要求先Recomputing他依赖的其它文件,这样程序会被递归调用导致效率低下,所以alluxio需要决定重建文件的顺序,并做调度。
为了检测哪些文件需要被recompted,alluxio使用DAG来管理需要被重建的文件,在DAG中的每个点是一个文件,父节点表示自节点依赖的文件,这个 DAG是前面提到的维护lineage关系的DAG的一个子图。
为了构建这个图,workflow manager使用DFS深度优先遍历算法来遍历目标文件,出发点是丢失的文件,直到碰到的文件已经在存储层中存在,DFS访问的节点必须recomputation。可以首先并行重新计算DAG中没有丢失父节点的节点。当节点的所有子节点都可用时,可以重新计算其余节点。workflow manager调用reousrce manager并执行这些任务,以确保recomputation所有缺失的数据。