论文标题:LoRA: Low-Rank Adaptation of Large Language Models
论文链接:https://arxiv.org/abs/2106.09685
论文来源:NVIDIA
一、概述
自然语言处理中的一个重要范式是在通用域数据上进行大规模预训练,然后在特定任务或域上适配。然而随着模型规模(比如GPT-3这样规模模型的出现)越来越大,对大模型的全参数微调变得更加困难,这在存储和部署上都非常具有挑战性。
目前的一些研究试图通过只微调一部分参数或为新任务学习外部模块来缓解这个问题。这样,我们只需要在进行每个任务时存储和加载少量的任务特定参数以及预训练模型,大大提高了部署时的操作效率。然而,现有的技术也存在一些问题,比如其通过扩展模型深度(adapter等方法)增加了推理延迟(inference latency),或者减少了模型可用的序列长度。更重要的是,这些方法通常无法达到微调baseline的效果,需要在效率和模型性能之间进行权衡。
我们的方法Low-Rank Adaptation (LoRA)灵感来源于一些前人的研究,即过度参数化的神经网络模型在训练后会呈现低秩特性,也就是说过度参数化的模型拥有一个很小的内在维度(low intrinsic dimension)。因此我们猜测,在模型微调适应的过程中权重的变化也具有“低秩”特性,这启发我们用低秩分解来表示权重的更新,而不是全参数训练。LoRA允许我们通过优化密集层(dense layer)在适应过程中的秩分解矩阵(rank decomposition matrices)来间接训练神经网络中的一些密集层,这个过程中保持预训练的参数不变,如下所示。以GPT-3 175B为例,我们证明了设置一个非常低的秩(也就是把下图中的设置成是1或2这样很小的值)就足够用来微调,虽然GPT-3的满秩高达12,288(也就是GPT-3的隐层维度),因此LoRA在存储和计算上是非常高效的。
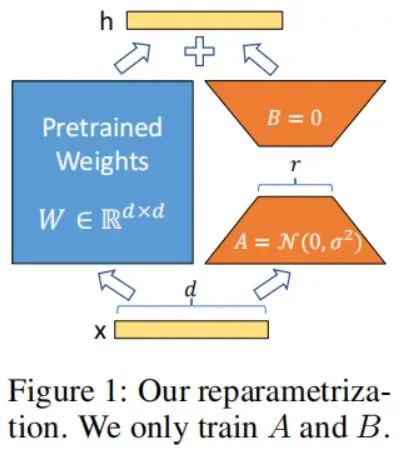
总体来说,LoRA有以下几个关键的优点:
①预训练模型在不同的下游任务上可以共享,我们可以为不同的任务构建多个相应的LoRA模块。我们可以冻结预训练模型,在切换任务时只需要替换上图中的矩阵和即可,这可以显著降低存储需求和任务切换的开销。
②当使用Adam等优化器时,LoRA使训练更高效,其将模型硬件要求的门槛降低了3倍,这是因为我们不需要计算预训练模型的梯度,也不需要维护其大多数参数的优化器状态,只需要优化插入的低秩矩阵的参数。
③低秩矩阵是线性的设计,这允许我们在部署时可以将可训练低秩矩阵与冻结的预训练模型权重合并,这与全参数微调的模型相比,不会引入推理延迟。
④LoRA与许多先前的方法是正交的,可以与其中的许多方法组合,例如prefix-tuning。
二、背景
在本文中,我们将Transformer模型的输出维度记作,使用来表示多头自注意力模块中的query/key/value/output密集层参数矩阵,用或者来表示预训练的权重矩阵,表示适应过程中梯度的累积更新,LoRA模块中的秩用表示。
对于一些下游任务(如摘要、机器阅读理解、NL2SQL等),在进行模型的全参数微调时,模型会被预训练权重初始化,然后按照梯度更新为以最大化下游任务数据上的条件概率:
❝ ❞
全参数微调在模型参数规模很大时在存储和部署上成本很高。在本文中,模型特定于任务的参数增量被使用更小规模的参数集来编码,也就是,这里的。寻找的过程也就变成了对的优化:
❝ ❞
三、方法
注意尽管在实验中我们只关注Transformer语言模型中的某些权重,但是LoRA适用于深度学习模型中的任何密集层。
低秩参数化的更新矩阵
一个神经网络包含许多执行矩阵乘法的密集层,这些层中的权重矩阵通常都是满秩的。当适应特定任务时,早先研究表明预训练语言模型在随机投影到较小的子空间后仍然可以高效地学习,或者说它们具有较低的内在维度或者内在秩。受此启发,我们假设在微调适应期间权重的更新也具有低的“内在秩”。对于一个预训练权重矩阵 ,微调时其权重更新为,我们通过将表示为一个低秩分解来限制这个更新过程,即,其中,,秩。在训练过程中,是冻结的,并不接收梯度更新,而和包含可训练参数。注意和都与相同的输入相乘,并且它们各自的输出向量按坐标求和。对于,我们修改后的前向传播为:
❝ ❞
前面的图1中说明了这个重参数化过程。我们对使用随机高斯矩阵初始化,对使用零矩阵初始化,因此在训练开始时为零。然后我们通过缩放,其中是一个常数,也就变成了:
❝ ❞
当使用Adam优化时,如果我们适当地缩放初始化,那么调整大致相当于调整学习率,这是因为反向传播时对和求导,以参数矩阵为例参数更新过程变成了:
❝ ❞
因此,我们简单地将设置为我们尝试的第一个,并不对其进行调优。这种缩放有助于减少我们在变化时需要重新调优超参数的需求。
LoRA方法是全参数微调的泛化。微调的一种更普遍的形式是训练预训练参数的一个子集。LoRA进一步地不要求在适应过程中权重矩阵的累积梯度更新具有满秩。这意味着当我们将LoRA应用于所有权重矩阵并训练所有偏置时,通过设置LoRA秩为预训练权重矩阵的秩,我们大致恢复了全参数微调的表达能力。换句话说,随着可训练参数的增加,LoRA的训练大致收敛到原始模型的训练,而基于adapter的方法收敛到MLP,基于prefix的方法收敛到无法处理长输入序列的模型。
LoRA不会引入额外推理延迟。在生产环境中部署时,我们可以明确计算并存储,并像往常一样执行推理。注意,和维度都是。当我们需要切换到另一个下游任务时,我们可以通过先减去恢复然后添加不同的,这是一个内存开销很小的快速操作。关键在于,这可以保证与微调模型相比,我们在推理期间不会引入任何额外延迟,这是由结构确定的。
将LoRA应用于Transformer
原则上,我们可以将LoRA应用于神经网络中的任何权重子集以减少可训练参数的数量。 在Transformer体系结构中,自注意力模块中有四个权重矩阵(, , , ),MLP模块中有两个。即使(或, )的输出维度通常被切片成注意力头,我们也将视为单个矩阵。在本文实验中我们限制仅对自注意力模块中的权重应用LoRA(实际上是只对和使用),冻结MLP模块(也就是说它们在下游任务中不被训练)。
LoRA方法 最重要的好处是内存和存储使用的减少。对于用Adam训练的大型Transformer,如果,由于我们不需要为大多数参数存储优化器状态,因此VRAM使用量减少了多达2/3。 在GPT-3 175B上,我们将训练期间的VRAM消耗从1.2TB降低到350GB。 当设置且仅适应query和value参数矩阵时,检查点大小约减少了10000倍(从350GB减少到35MB)。这允许我们用明显更少的GPU进行训练,并避免I/O瓶颈。 由于我们不需要计算绝大多数参数的梯度,与全参数微调相比,在GPT-3 175B上训练时,我们还观察到了25%的加速。
LoRA也有其局限性。如果合并和到中,会增加推理效率,但是会减少不同人物模块的灵活性。如果不合并,可以灵活地为不同任务动态选择模块,但推理效率可能会降低。
四、实验
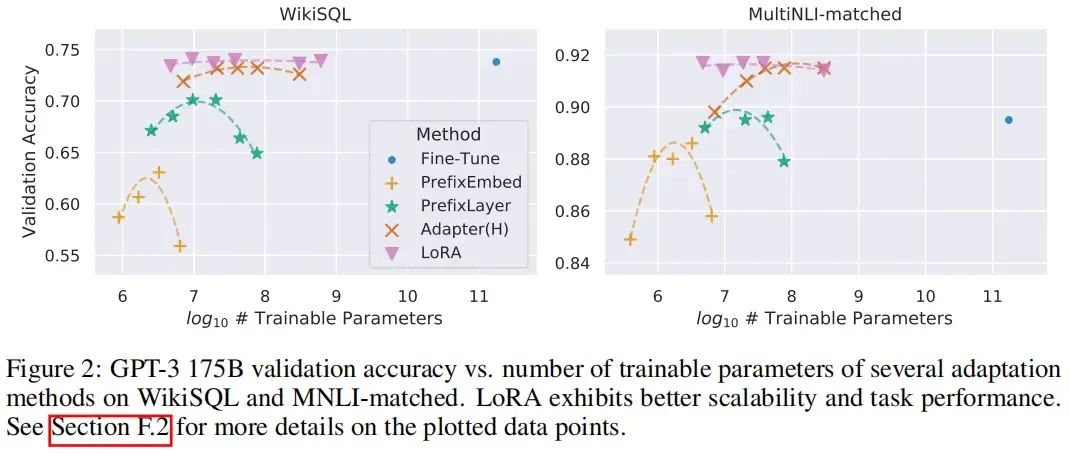
本文在RoBERTa、DeBERTa、GPT-2、GPT-3等模型上进行了实验,实验结果如下:
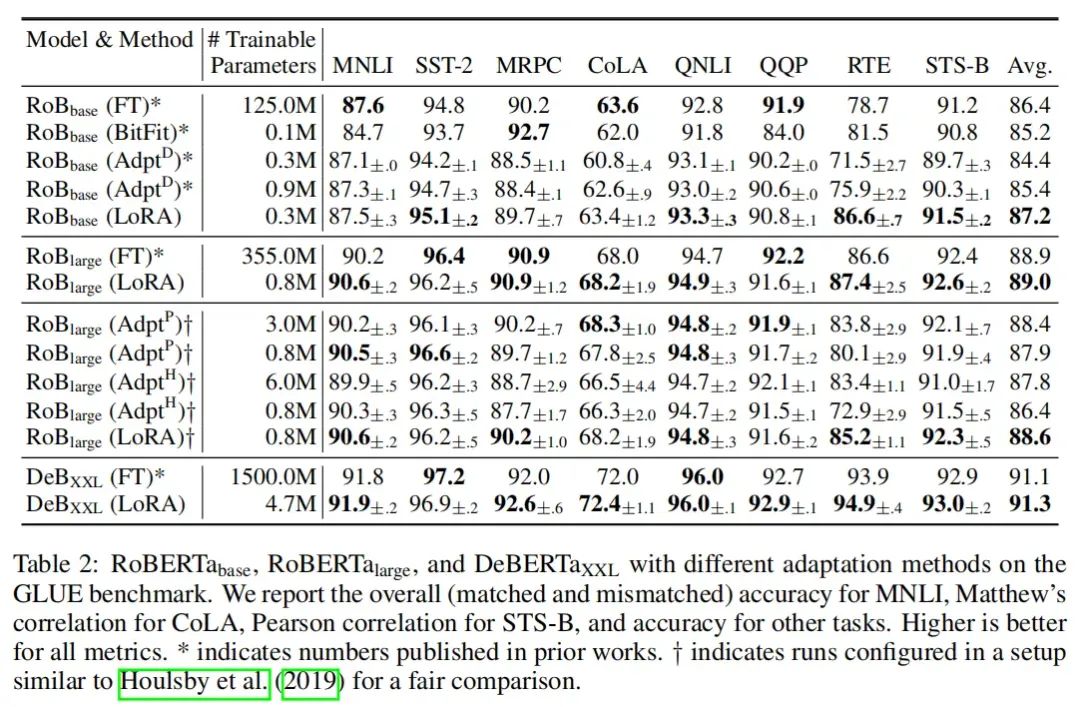
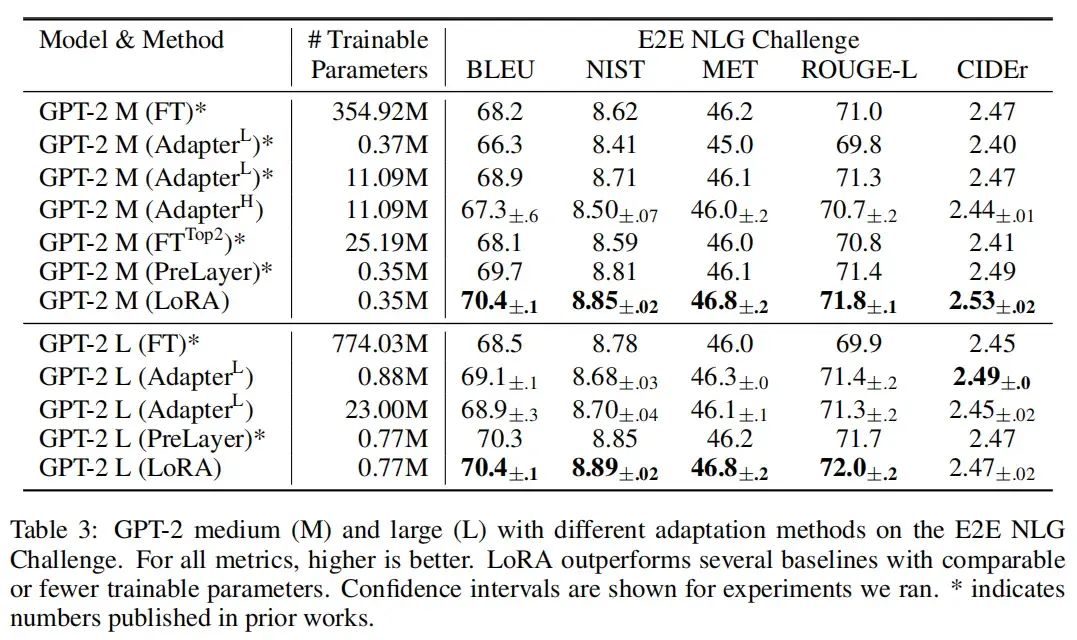
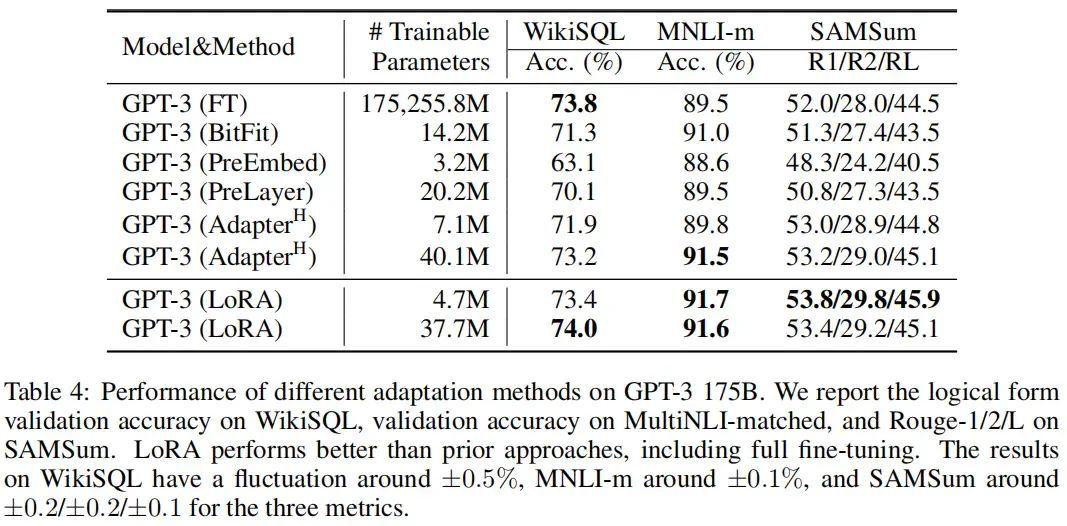
五、理论分析
我们希望进一步解释从下游任务中学习的低秩更新的属性。注意,低秩结构不仅降低了硬件需求的门槛,从而使我们能够并行运行多个实验,而且还使更新权重与预训练权重的相关性更具可解释性。我们在GPT-3 175B上进行了一系列实证研究,以回答以下问题:
①在参数预算约束下,我们应该适应哪些预训练Transformer中的权重子集以最大化下游任务的性能?
②“最优”适应矩阵确实低秩吗?如果是这样,实践中使用将秩设置成多少比较好?
③与有什么关系?与高度相关吗?(数学上,主要包含在的顶部奇异值方向中吗?)此外,与相对应的方向中,有多大?
我们相信,对问题②和③的回答可以阐明使用预训练语言模型进行下游任务的基本原理,这是自然语言处理中的一个关键主题。
我们应该对Transformer中的哪些矩阵使用LoRA?
给定有限的参数预算,哪种类型的权重应该被使用LoRA适应以获得下游任务的最佳性能效果?我们仅考虑自注意力模块中的权重矩阵。我们在GPT-3 175B上设置参数预算为18M(如果以FP16存储约需要35MB),这相当于(如果我们适应一种类型的注意力权重)或(如果我们适应两种类型),对于所有96层都是这样来设置。结果如下表所示。
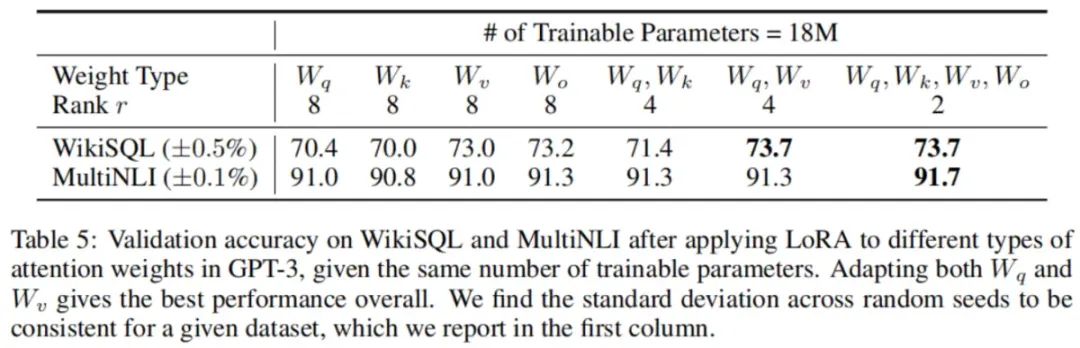
注意,将所有参数都适应在或中会导致性能显著降低,而适应和两者会产生最佳结果。这表明即使rank为4也可以在中捕获足够的信息。与使用更大的rank适应单个权重类型相比,适应更多权重矩阵是更合适的。
LoRA的最优秩是多少?
最优秩的设置
我们将注意力转向rank对模型性能的影响。我们适应仅、、,并进行比较。实验结果如下图所示:
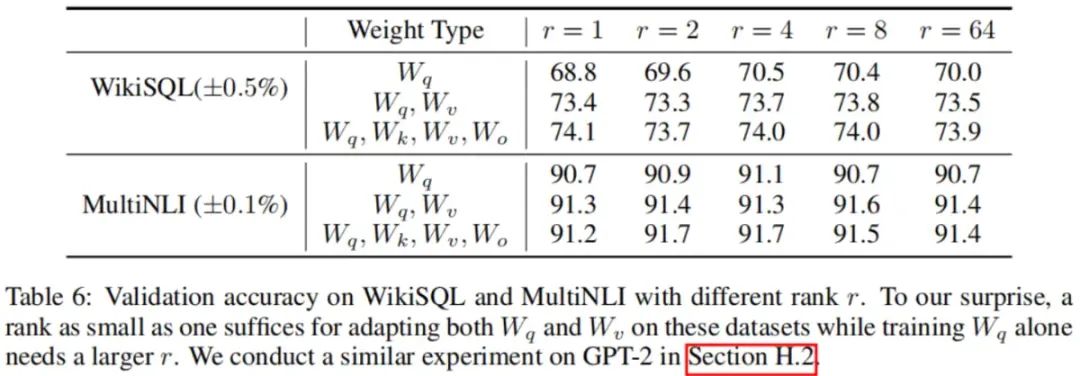
令我们惊讶的是,在这些数据集上,仅适应和时,rank为1就足够了,而仅训练需要更大的。实验结果表明增大不会覆盖更有意义的子空间,因此在使用LoRA时设置一个较小的即可。
不同rank之间子空间的相似度
给定和,它们分别是使用相同预训练模型学习得到的rank为8和64的适应矩阵。我们对它们进行奇异值分解,得到右奇异矩阵和。我们希望回答:当我们分别取的前个奇异向量和的前个奇异向量(其中,)生成的子空间时,这两个子空间有多大的重叠?我们用一种基于Grassmann距离的归一化子空间相似度来衡量:
❝ ❞
其中表示对应于前个奇异向量的多个列。
的值域在,其中1表示子空间完全重叠,0表示完全正交。参见下图中随着和的变化的变化情况。由于篇幅所限,我们仅查看第48层(总共96层),但结论对其他层同样成立。
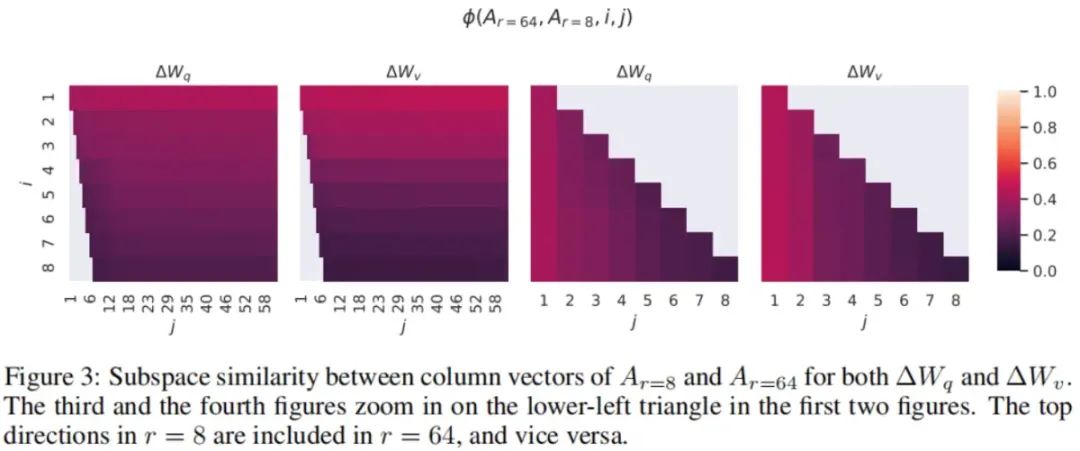
从上图中可以观察到一个重要的结果:
和的顶部奇异向量对应的方向有很大的重叠,而其他的方向则不相容。具体来说,和的(或者)在维度为1时共享一个子空间,其归一化相似度在0.5以上。这可以解释为什么在我们的之前的实验中的表现已经相当不错。
由于和都是用同一个预训练模型学习得到的,上图3表明和的靠前的奇异向量方向是最有用的,而其他方向可能大多包含了训练过程中累积的随机噪声。因此,适应矩阵确实具有非常低的秩。
不同随机种子之间子空间的相似度
我们进一步通过绘制在时两个随机种子(也就是初始化随机高斯矩阵时的随机种子)的归一化子空间相似度来确认这一点,结果如下图所示。与相比,似乎具有更高的“内在秩”,因为两次实验中共享的奇异值方向更多,这与我们在上表6中的观察到的结果一致。为了比较,我们还绘制了两个随机高斯矩阵的归一化子空间相似度,它们之间没有共享任何奇异值方向。

与的关系如何?
我们进一步研究和之间的关系。具体而言,是否与高度相关?(数学上,主要包含在的顶部奇异值方向中吗?)此外,与相对应的方向中,有多大?这可以阐明适应预训练语言模型的基本机制。
为了回答这些问题,我们通过计算,其中是的左/右奇异向量矩阵,将投影到的维子空间上。然后,我们比较和的Frobenius范数。作为比较,我们还通过将替换为或随机矩阵的前个奇异向量来计算。实验结果如下表所示。

我们从上表中得出几个结论:
①首先,与随机矩阵相比,与之间存在更强的相关性,表明放大了中已经存在的某些特征。
②其次,并不是重复中的靠前的奇异值方向,而是放大了中没有强调的方向。
③放大系数是相当大的:对于,它是。