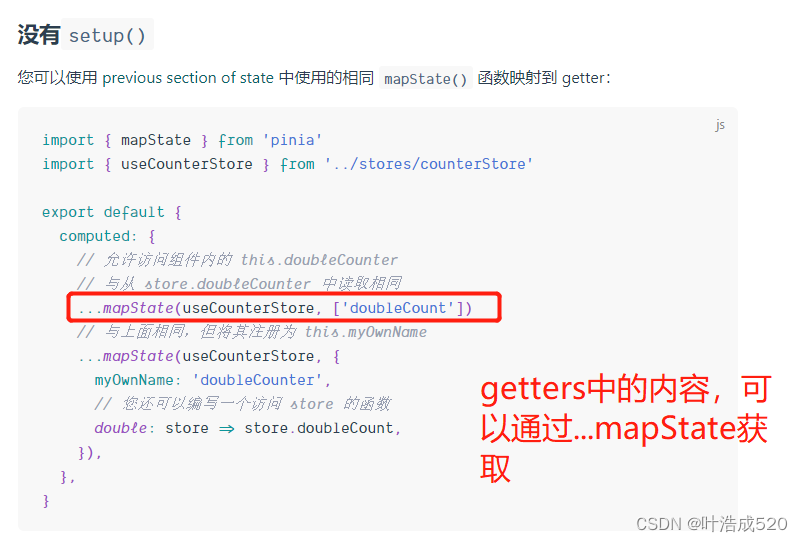
水善利万物而不争,处众人之所恶,故几于道💦
目录
一、默认分区规则
1. 从集合中创建RDD - makeRDD
2. 读取外部存储系统创建RDD - textFile
二、指定分区规则
1. 从集合中创建RDD指定分区 - makeRDD
2. 读取外部存储系统创建RDD指定分区 - textFile
一、默认分区规则
spark中有三种创建RDD的方式:从集合中创建(parallelize和makeRDD)、从外部存储系统的数据集创建(textFile)、从其他RDD的转换创建。创建的时候分区可以不指定,他会有一个默认的分区规则,那这个默认的分区规则是什么呢?下面就以makeRDD和textFile为例进行分析。
1. 从集合中创建RDD - makeRDD
从集合中创建RDD时,默认的分区规则是分配给应用的CPU核数,也就是创建SparkConf对象时,设置的setMaster参数。

综上所述:如果通过集合创建RDD,默认的分区规则是:分配给应用的CPU核数,如果local[*]是这台机器的CPU个数就是分区数,local只有一个分区
2. 读取外部存储系统创建RDD - textFile
读取外部文件创建RDD的话,默认的分区规则是min(分配给应用的cpu核数,2)

二、指定分区规则
1. 从集合中创建RDD指定分区 - makeRDD
// 创建SparkConf并设置App名称及运行模式
val conf: SparkConf = new SparkConf().setAppName("SparkCoreStudy").setMaster("local[*]")
// 创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
// 指定3个分区,实际输出3个分区 0分区->1, 1分区->2, 3分区->3 4
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),3)
// 指定4个分区,实际输出4个分区 0分区->1 , 1分区->2 , 2分区->3 , 3分区->4 5
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,5),4)
// 指定5个分区,实际输出5个分区 0分区->1 , 1分区->2 , 2分区->3 , 3分区->4 , 4分区->5
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,5),5)
// 指定3个分区,实际输出3个分区 0分区-> a , 1分区-> b c , 2分区-> d e
val rdd: RDD[String] = sc.makeRDD(List("a","b","c","d","e"),3)
rdd.saveAsTextFile("F:\\IdeaProjects\\spark\\output")
// 关闭连接
sc.stop()
集合中创建RDD,指定分区数是多少,实际就分几个区。除了分几个区后,我们还关心每个分区中数据怎么存放。

通过跟踪代码,我们发现切片的具体过程是:用集合的长度和分区数进行运算然后求出一个分区的下标范围(这个范围是前闭后开的),然后将集合中这个下标范围的数据放到这个分区中。
根据集合长度和分区数的具体计算逻辑是:
起始位置下标 = (分区号*集合长度)/分区数
结束位置下标 = ((分区号+1)*集合长度)/分区数
说明:分区号和分区数不一样,分区号是分区的编号,从0号分区开始,分区数是你指定的几个分区。
例如:集合长度为5,我指定3个分区,那么
0号分区的起始位置下标=(0*5)/3=0,结束位置下标=(1*5)/3=1 => [0,1)
1号分区的起始位置下标=(1*5)/3=1,结束位置下标=(2*5)/3=3 => [1,3)
2号分区的起始位置下标=(2*5)/3=3,结束位置下标=(3*5)/3=5 => [3,5)
2. 读取外部存储系统创建RDD指定分区 - textFile
在textFile方法中,第二个参数minPartitions,表示最小分区数,是最小,不是实际的分区个数,实际几个分区会通过要读取的文件总大小和最小分区数进行计算得出。
// 创建SparkConf并设置App名称及运行模式
val conf: SparkConf = new SparkConf().setAppName("SparkCoreStudy").setMaster("local[*]")
// 创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
sc.textFile("F:\\IdeaProjects\\spark\\input\\19b.txt",5).saveAsTextFile("F:\\IdeaProjects\\spark\\output")
// 关闭连接
sc.stop()
上述代码中,读取的本地文件的大小为19字节,最小分区数是5,则实际输出7个分区。

通过源码的追踪,发现读取外部文件的实际分区是:剩余待切片的大小/目标大小,结果是否大于1.1,如果大于1.1则切一片,起始位置是0,结束位置是0+goalSize,然后再根据剩余的判断,如果不大于1.1,则再单独切一片就行了。注意实际读取的时候是TextInputFormat中的getRecordReader方法,但是这个方法使用LineRecordReader方法读,它是一行一行读的,停不住,也就是说读到这一行,这一行都会被读完,从而放到一个分区里面
例如:文件大小为19字节,我指定5个分区,那么
goalSize = 19/5 = 3 也就是说3个字节一片
| 分区 | 切片规划(切片区间) | 剩余切片大小 | 是否>1.1 |
|---|---|---|---|
| 0 | [0,0+3] | 19-3=16 | 16/3 - 是 |
| 1 | [3,3+3] | 16-3=13 | 13/3 - 是 |
| 2 | [6,6+3] | 13-3=10 | 10/3 - 是 |
| 3 | [9,9+3] | 10-3=7 | 6/3 - 是 |
| 4 | [12,12+3] | 7-3=4 | 4/3 - 是 |
| 5 | [15,15+3] | 4-3=1 | 1/3 - 否 |
| 6 | [18,18+1] | 只要不大于1.1不管剩下多少都是一个切片 | |