序:
在开发过程中,在值班解决客服问题时,在分析定位别人写的业务代码问题时,重点是不是自己写的代码,只看到了数据库中落库最终数据,并不知道业务逻辑问题发生时数据库表中当时数据情况?如果能知道当时数据情况,就能更准,更快的定位到问题,可能大家对这种说法还是比较迷惑,举几个例子来分析 。
-
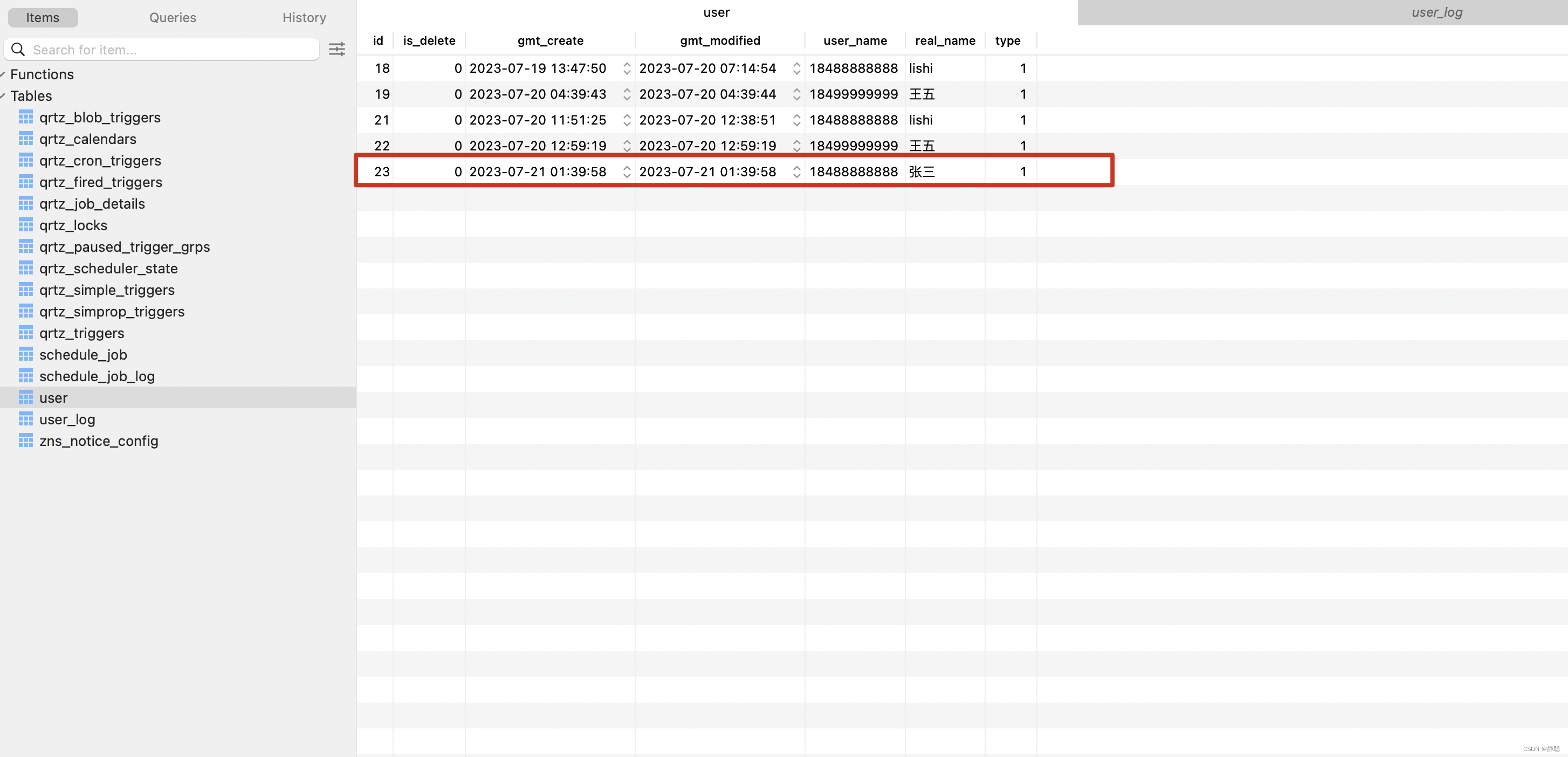
在user表中有一条id为23的记录,这条记录什么时候由哪一块代码插入的呢?有人想,为什么我要去找这条数据插入时的业务代码呢?比如,注册时需要发短信,你只看到了用户注册时插入用户表的数据,但用户没有收到短信,当然99%的用户是能收到短信的,偶尔出现一个用户没有收到短信的情况,此时需要查找用户注册时的日志并找询出没有发送短信的原因,恰好这块业务逻辑代码并非你所写,如果要准确的找到问题,可能需要到代码中寻寻觅觅,费时费力,还不一定准确,当然还有另一种场景,用户参加活动后会收到奖金,其他用户都能正常收到奖金,唯独某个用户没有收到, 这个用户为什么没有收到奖金呢?因此需要找到发送奖金时的代码逻辑,代码并非你所写,那该怎么办呢?在代码中寻寻觅觅,想找到奖金发送时lt_user_account表的插入逻辑,又发现代码中所有的实体插入都用了MyBatis Plus的XXXMapper.insert(XXX)方法,在业务上,可能有注册,签到,参加活动,分享好友,好友推荐等等都会用户发送奖金,业务这么复杂,代码又不好找,新人找问题,真是太难了。 不要过多的纠节表名和字段名,这都是我随意取的
-
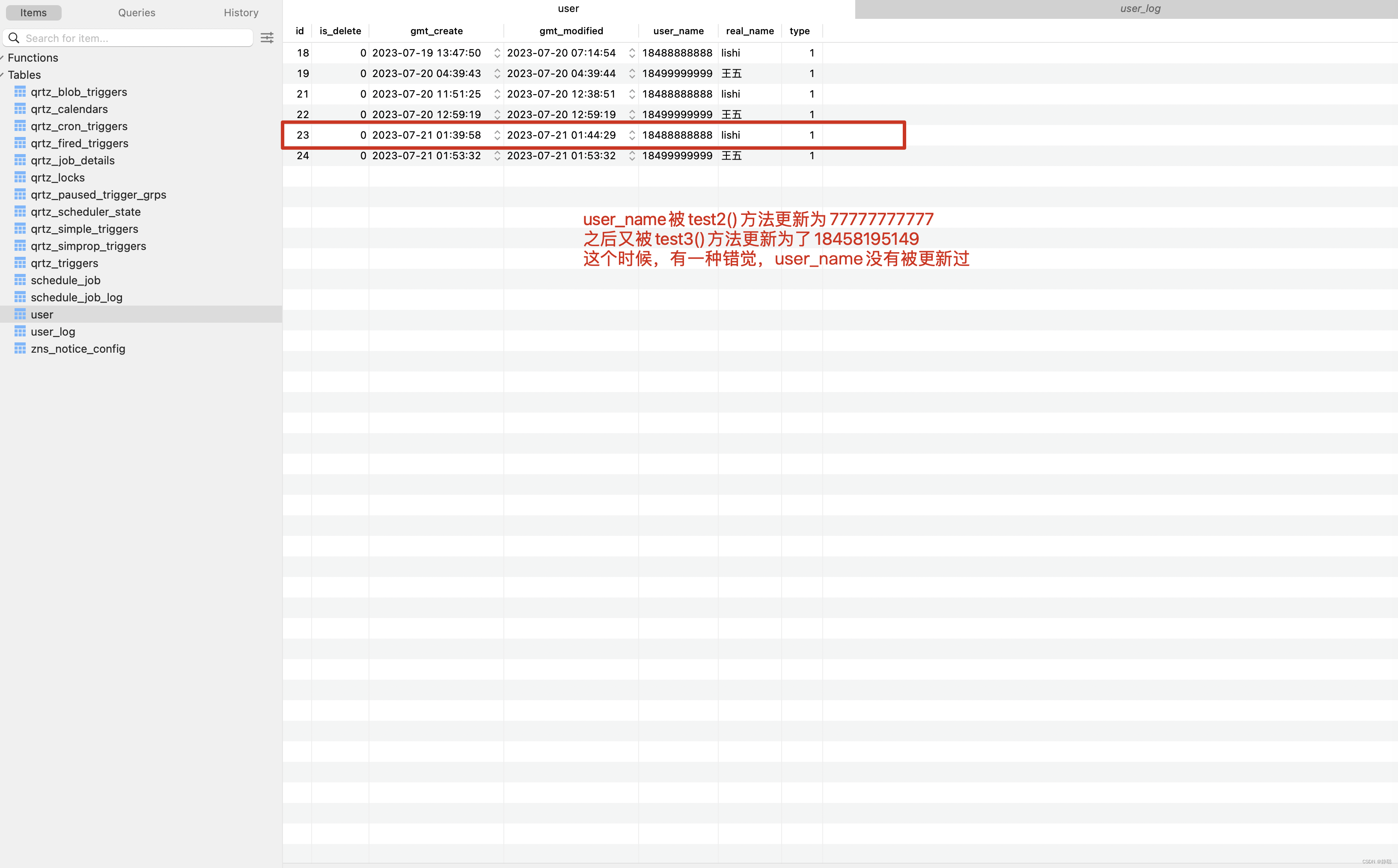
数据库表中user这张表。 执行了下面第一张图的 test2() 方法中,明显我将userName字段更新为 7777777777,但为什么还是18488888888,原因在test3()方法和test2()方法被同时调用,两个方法在执行这一行代码时【 User userPhone = userPhoneDao.selectUserById(23l);】,都查询到了userName为18488888888,realName为张三
此时test2()方法执行了如下SQL:
update user set is_delete = 0, gmt_create = ‘2023-7-21 1:39:58’, user_name = ‘7777777777’, real_name = ‘张三’, type = 1 ,gmt_modified = now() where id = 23, 将user_name_en更新为了7777777777
但test3()方法在test2()方法之后的极短的时间内又执行了如下SQL:
update user set is_delete = 0, gmt_create = ‘2023-7-21 1:39:58’, user_name = ‘18488888888’, real_name = ‘lishi’, type = 1 ,gmt_modified = now() where id = 23
因此数据库中最终存储的是user_name为 “18488888888”,real_name为 “lishi”,明显感觉user_name已经被更新为了7777777777,但最终数据库中real_name的数据还是18488888888的情况,当微服务比较多,并且业务逻辑比较复杂时,这种偶现的问题是极难定位的。
-
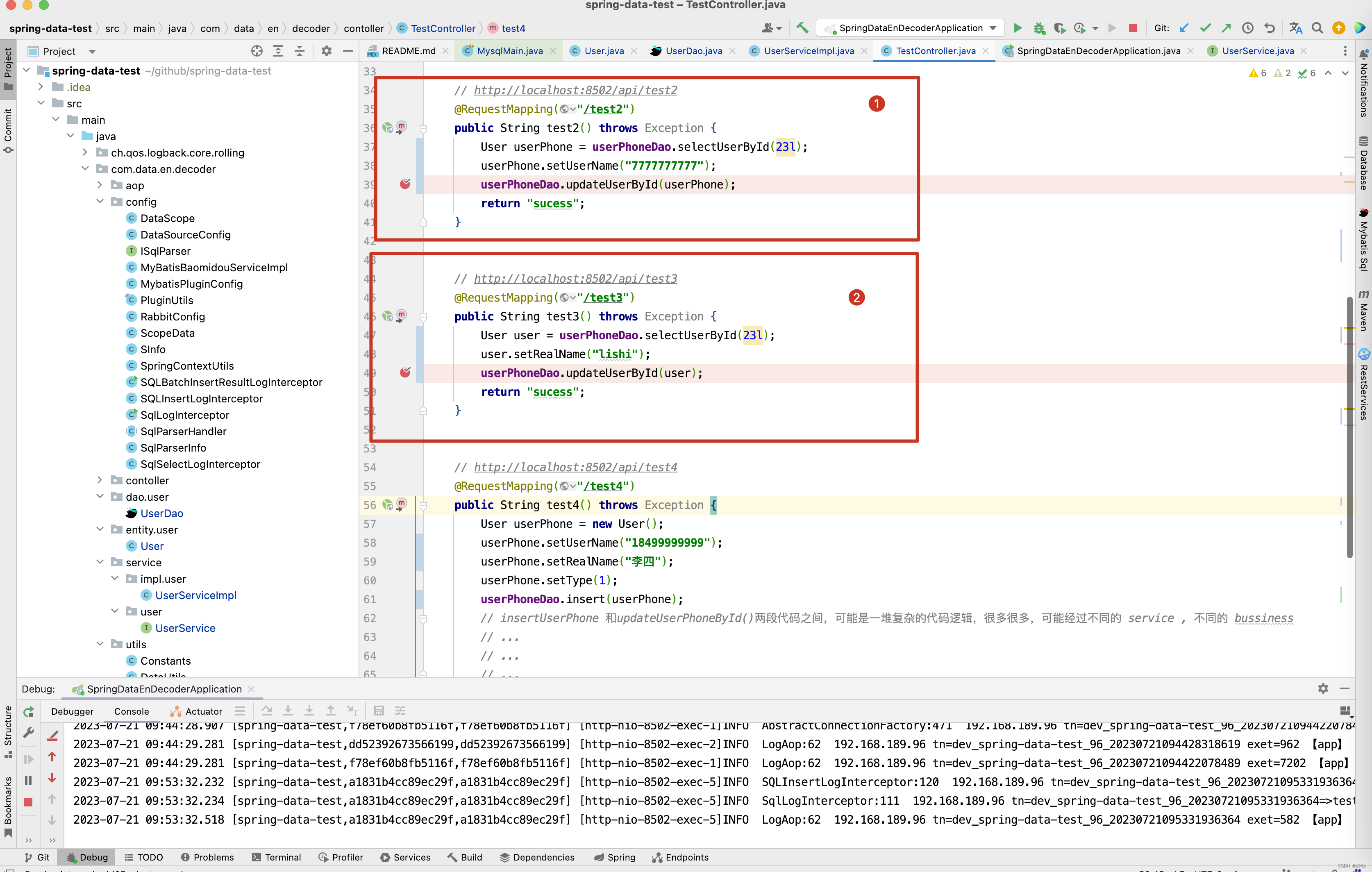
接下来看另一个例子,在下图中,test4()方法中,如果只看前半段insertUser()方法,明显 realName为 李四,但数据库中存储的却是王五,这是为什么呢 ? 假如在insertUser()和updateUserById()方法之间存在一段很长且复杂的业务逻辑代码,最终将realName更新为了王五,但是你只看到了insert()这一部分的逻辑代码,开发者自己可能也觉得莫名其妙,测试小伙伴会追问,前端界面上自己注册时输入的用户名realName是李四,但为什么存储的却是王五,恰好下面
… 复杂的业务逻辑
public void updateUserPhoneTest(User userPhone) {
userPhone.setRealName(“王五”);
userDao.updateUserById(userPhone);
}

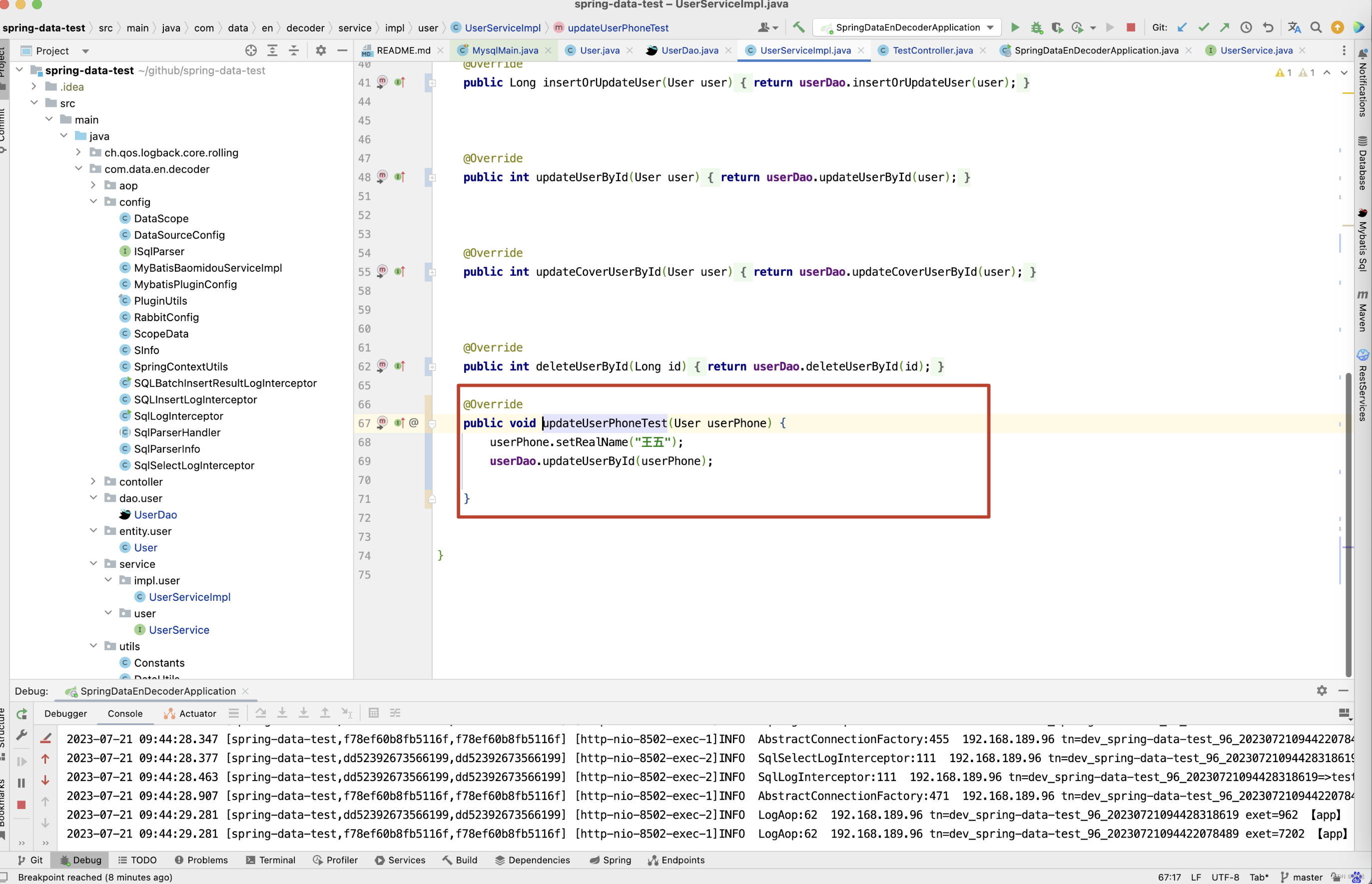
上面这几个例子是我们开发中经常遇到的问题,如果没有一种好的定位问题的方式,开发人员很难快速,准确的定位到问题原因,这也是我开发数据库字段变更监控平台的主要原因,话不多说,先来看看插入操作,在平台上记录了什么东西,当业务系统进行增删改查操作时,平台会采集到业务系统的SQL日志以及当时的日志TraceId,并在平台上会解析采集到的SQL,生一张和原业务系统表名一样,并且以_log为后缀的表,表结构如下。
CREATE TABLE 原业务表名_log ( id int(11) DEFAULT NULL, gmt_create datetime DEFAULT NULL COMMENT '创建时间', gmt_modified datetime DEFAULT NULL COMMENT '更新时间', c_name varchar(32) DEFAULT NULL COMMENT '列名', c_value text COMMENT '列值', o varchar(8) DEFAULT NULL COMMENT '操作类型,I 插入操作,U 更新操作', log_no text COMMENT '日志编号,数据变更时日志TraceId', KEY idx_id_c_name (id,c_name) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
表中每个字段的含义如下:
- id : 原业务表中的主键字段
- gmt_create : SQL执行时的时间
- gmt_modified : 更新时间,目前没有太大意义
- c_name : 原业务表中字段名
- c_value :原业务表中字段值,目前都是var类型存储
- o : 操作类型,当前SQL是插入还是更新操作,I 插入操作,U 更新操作
- log_no : 日志编号, SQL操作时日志的TraceID
可能大家理解起来还是比较抽象,比如执行下面代码逻辑,向user表中插入一条记录。
// http://localhost:8502/api/test1
@RequestMapping("/test1")
public String test1() throws Exception {
User user = new User();
user.setUserName("18488888888");
user.setRealName("张三");
user.setType(1);
userPhoneDao.insert(user);
return "sucess";
}
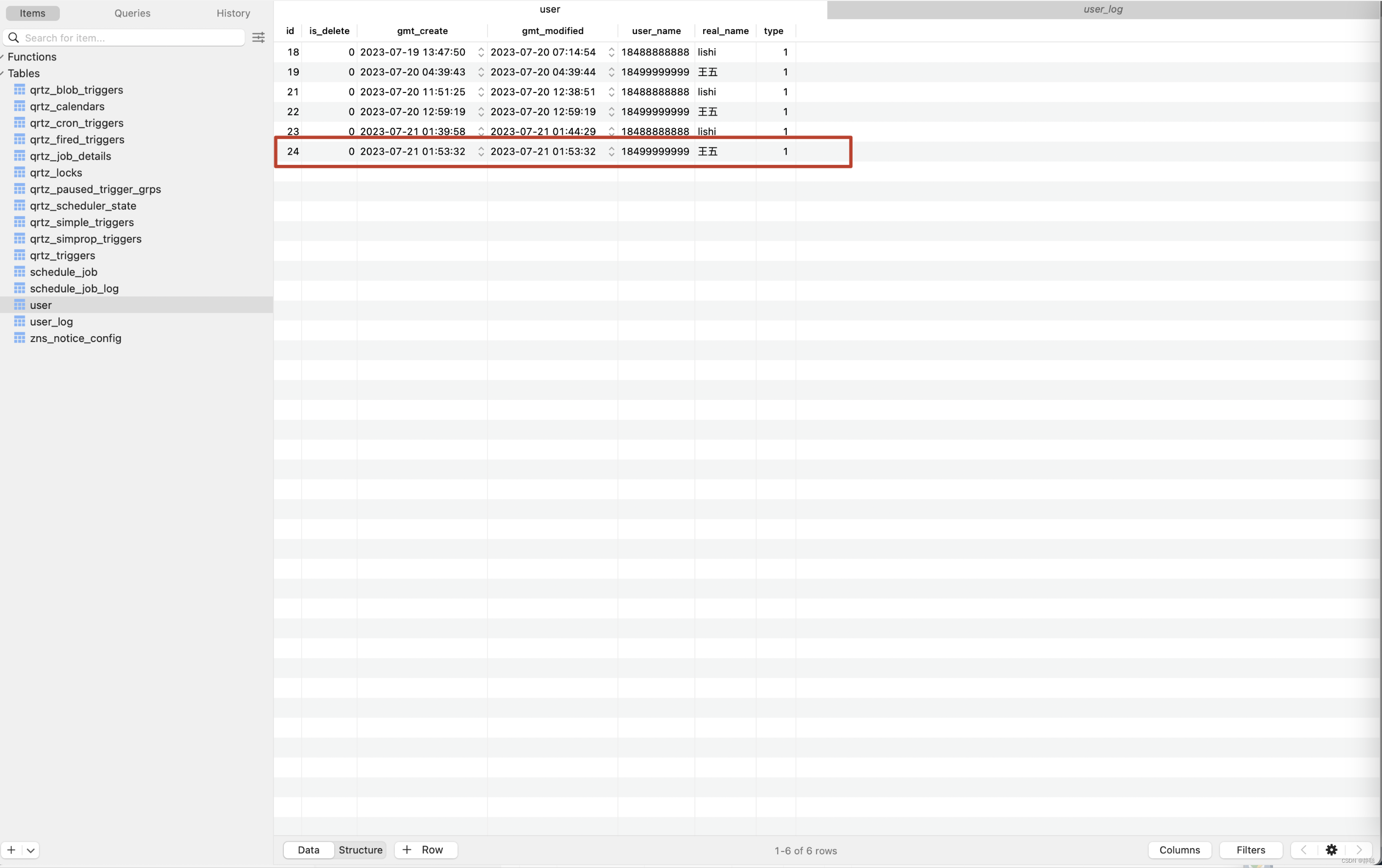
数据库中的记录如下,向数据库中插入了一条id为25的记录。
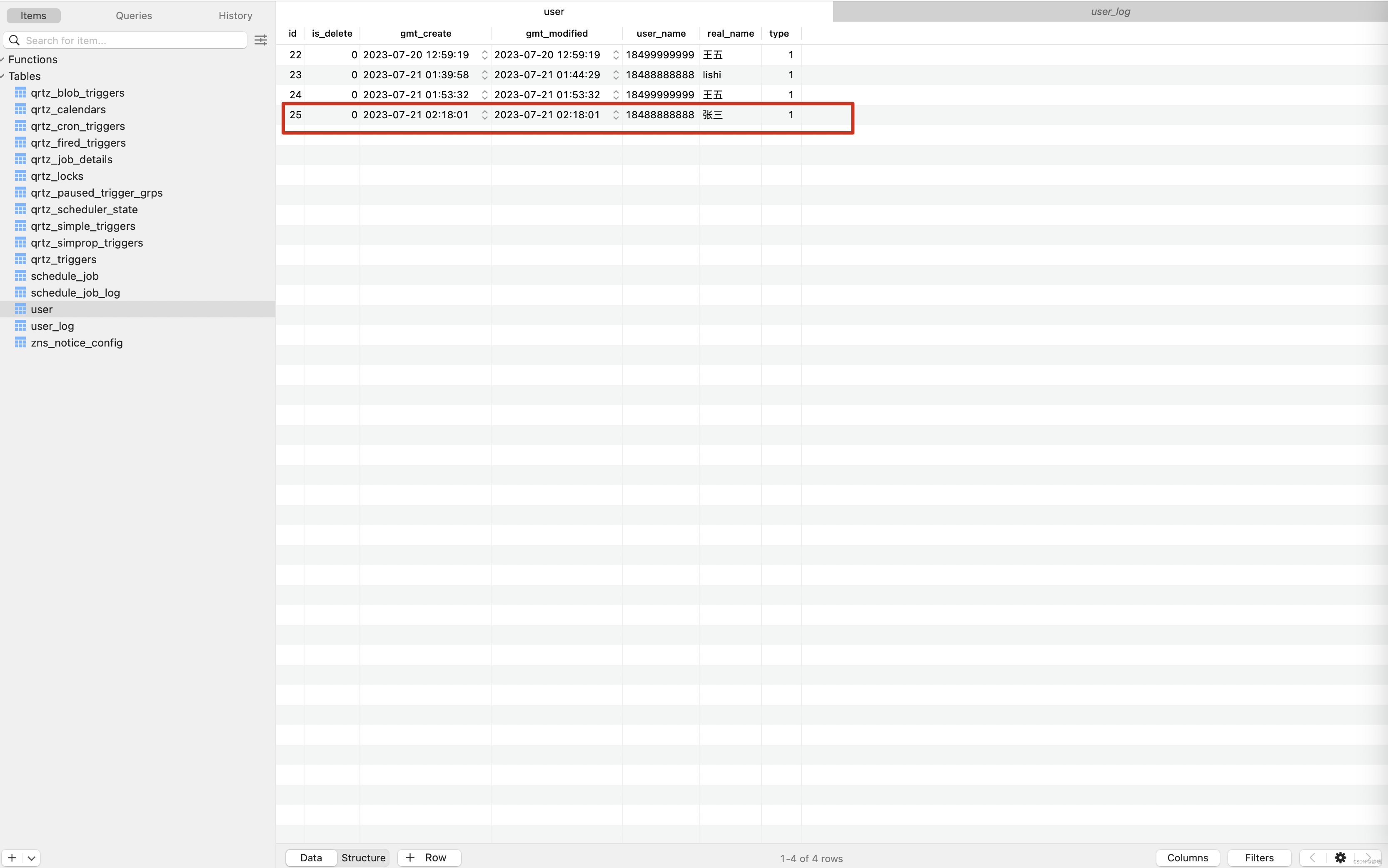
那在平台上记录的内容是什么呢 ? 首先会在我们平台上创建一张user_log表,user为原表名,_log 为表的默认后缀,当然默认后缀也是可以自己定义的。
CREATE TABLE user_log ( id int(11) DEFAULT NULL, gmt_create datetime DEFAULT NULL COMMENT '创建时间', gmt_modified datetime DEFAULT NULL COMMENT '更新时间', c_name varchar(32) DEFAULT NULL COMMENT '列名', c_value text COMMENT '列值', o varchar(8) DEFAULT NULL COMMENT '操作类型,I 插入操作,U 更新操作', log_no text COMMENT '日志编号,数据变更时日志TraceId', KEY idx_id_c_name (id,c_name) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;

通过日志的TraceId立即能找到属于哪个环境,哪个项目,哪台机器,从哪个方法执行插入操作的,当然有人会想,你的TraceId为什么是这样的呢? 有兴趣可以去看看 4.工作中日志打印 这篇博客,这里就不再赘述了,是不是顿时感觉很方便了,接下来看第二个例子场景分。
在test2(),test3()方法中的 userPhoneDao.updateUserPhoneById(userPhone) 这一行代码之前打上断点。
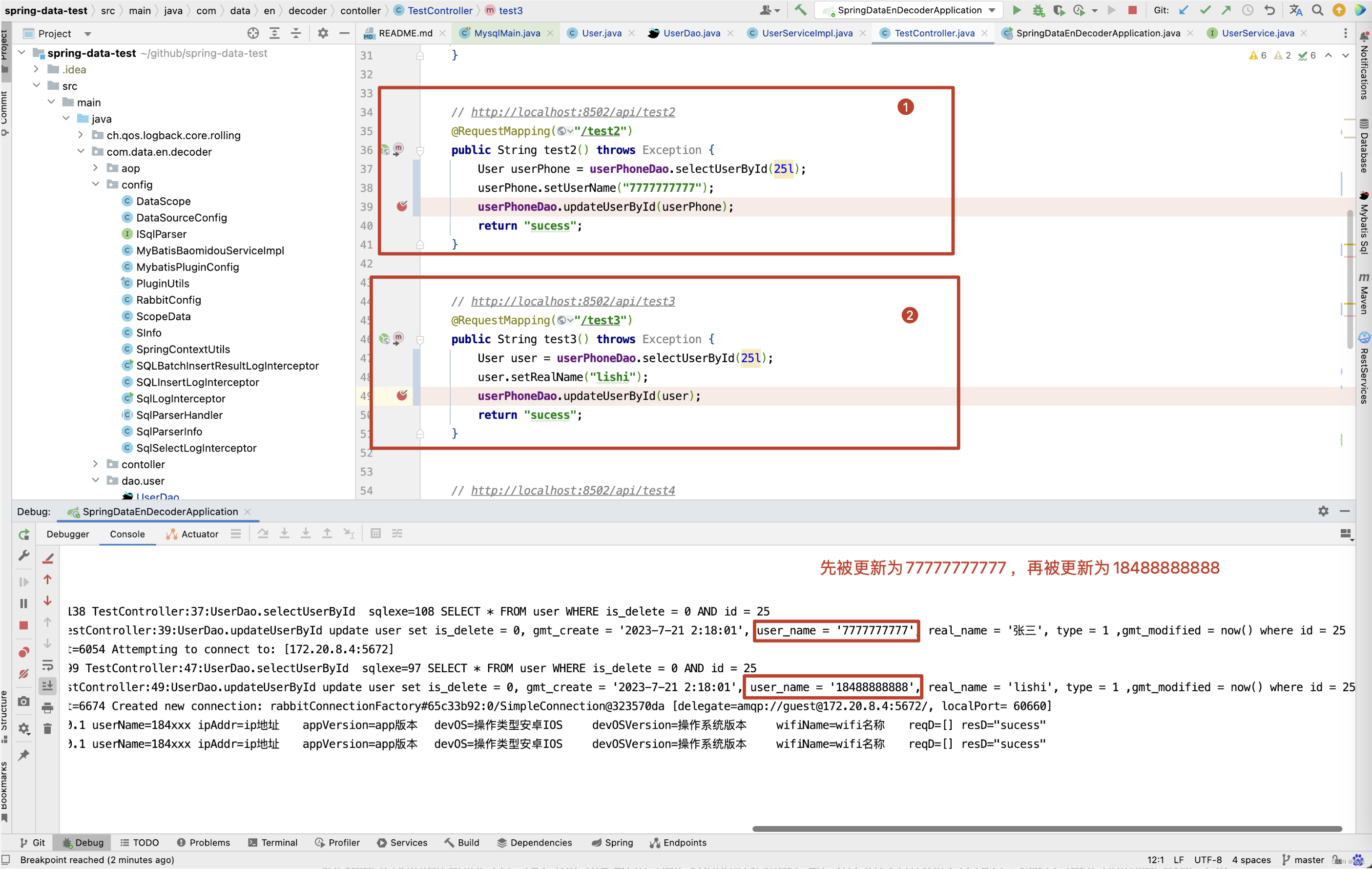
先访问http://localhost:8502/api/test2,再访问http://localhost:8502/api/test3,此时断点会停留在test2()方法中。
在Idea中连续按F9,此时日志打印的内容如下
2023-07-21 10:26:42.660 [spring-data-test,1135b9f4c0be7952,1135b9f4c0be7952] [http-nio-8502-exec-1]INFO SqlSelectLogInterceptor:111 192.168.189.96 tn=dev_spring-data-test_96_20230721102642521927=>test2:TestController exet=138 TestController:37:UserDao.selectUserById sqlexe=108 SELECT * FROM user WHERE is_delete = 0 AND id = 25 2023-07-21 10:26:48.651 [spring-data-test,569a9cf434bd62ff,569a9cf434bd62ff] [http-nio-8502-exec-2]INFO SqlSelectLogInterceptor:111 192.168.189.96 tn=dev_spring-data-test_96_20230721102648552718=>test3:TestController exet=99 TestController:47:UserDao.selectUserById sqlexe=97 SELECT * FROM user WHERE is_delete = 0 AND id = 25 2023-07-21 10:26:48.563 [spring-data-test,1135b9f4c0be7952,1135b9f4c0be7952] [http-nio-8502-exec-1]INFO SqlLogInterceptor:111 192.168.189.96 tn=dev_spring-data-test_96_20230721102642521927=>test2:TestController exet=6041 TestController:39:UserDao.updateUserById update user set is_delete = 0, gmt_create = '2023-7-21 2:18:01', user_name = '7777777777', real_name = '张三', type = 1 ,gmt_modified = now() where id = 25 2023-07-21 10:26:48.744 [spring-data-test,569a9cf434bd62ff,569a9cf434bd62ff] [http-nio-8502-exec-2]INFO SqlLogInterceptor:111 192.168.189.96 tn=dev_spring-data-test_96_20230721102648552718=>test3:TestController exet=192 TestController:49:UserDao.updateUserById update user set is_delete = 0, gmt_create = '2023-7-21 2:18:01', user_name = '18488888888', real_name = 'lishi', type = 1 ,gmt_modified = now() where id = 25
此时平台中记录的内容是什么呢? user_name从18488888888变更为7777777777,再由7777777777变更为18488888888的过程 。

接下来看test4()方法中的例子。
// http://localhost:8502/api/test4
@RequestMapping("/test4")
public String test4() throws Exception {
User userPhone = new User();
userPhone.setUserName("18499999999");
userPhone.setRealName("李四");
userPhone.setType(1);
userPhoneDao.insert(userPhone);
// insertUserPhone 和updateUserPhoneById()两段代码之间,可能是一堆复杂的代码逻辑,很多很多,可能经过不同的 service , 不同的 bussiness
// ...
// ...
// ...
userPhoneService.updateUserPhoneTest(userPhone);
return "sucess";
}
在test4()方法中先调用insertUser()方法插入了user对象,在updateUserPhoneTest()内部,被其他人的代码更新了realName的数据。 updateUserPhoneTest()方法的内部实现如下
public void updateUserPhoneTest(User userPhone) {
userPhone.setRealName("王五");
userDao.updateUserById(userPhone);
}
调用 http://localhost:8502/api/test4,查看日志记录。
2023-07-21 10:40:46.277 [spring-data-test,1bbeb8ef0b92c1df,1bbeb8ef0b92c1df] [http-nio-8502-exec-7]INFO SQLInsertLogInterceptor:120 192.168.189.96 tn=dev_spring-data-test_96_20230721104045919183=>test4:TestController exet=358 TestController:61:UserDao.insert INSERT INTO user ( user_name, real_name, type ) VALUES ( '18499999999', '李四', 1 ) | insert_id=27 2023-07-21 10:40:46.278 [spring-data-test,1bbeb8ef0b92c1df,1bbeb8ef0b92c1df] [http-nio-8502-exec-7]INFO SqlLogInterceptor:111 192.168.189.96 tn=dev_spring-data-test_96_20230721104045919183=>test4:TestController:66=>updateUserPhoneTest:UserServiceImpl exet=359 UserServiceImpl:69:UserDao.updateUserById update user set user_name = '18499999999', real_name = '王五', type = 1 ,gmt_modified = now() where id = 27
从日志中,可以看出,先向数据库中插入了一条id=27的记录,然后再执行更新操作,接下来看平台上记录的内容是什么 ?
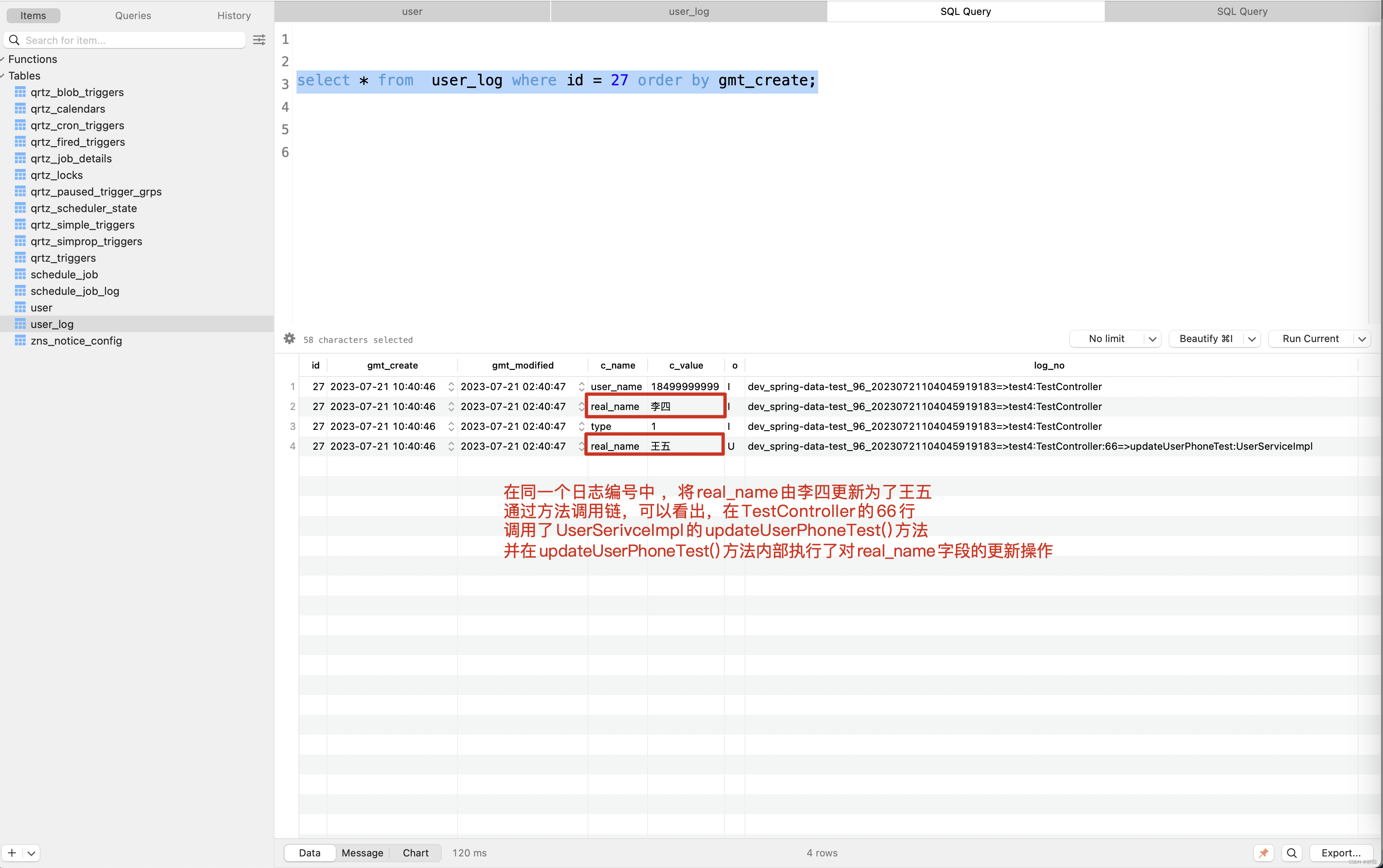
当然啦,有人会想,我知道是updateUserPhoneTest()方法中执行了更新real_name的操作,那我知道在updateUserPhoneTest()的哪一行调用的不? 当然,你想到的我当然想到了,请看日志 。
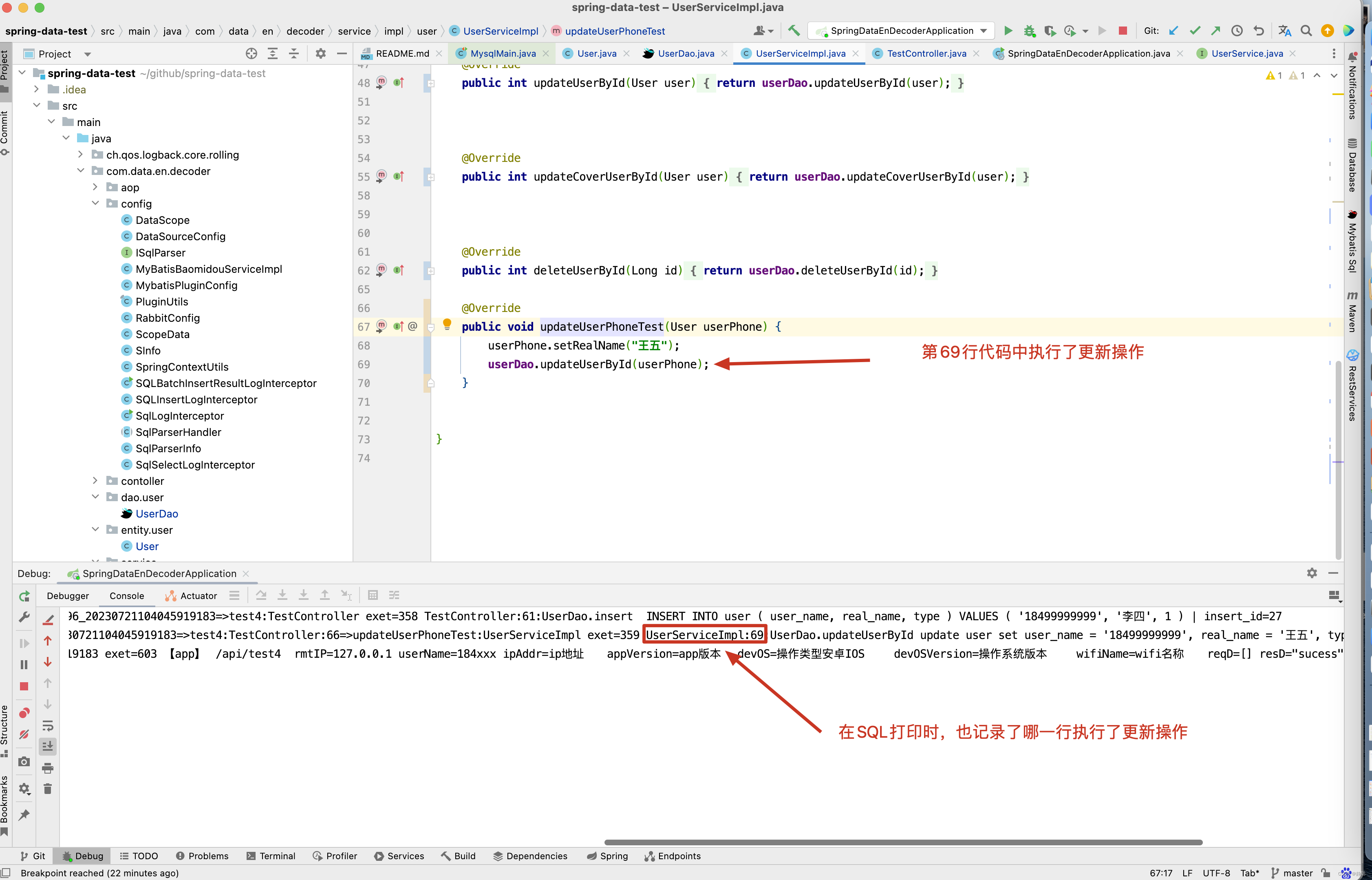
关于日志打印这一块,有兴趣还是去看4.工作中日志打印, 这篇博客中做了详细的分析,这里就不再赘述 。
通过上述三个简单的例子,虽然说业务逻辑有些迁强,但是作为一线开发人员,肯定会意识到他存在的价值,这里我并非是王婆卖瓜,自卖自夸,本来这个平台是为公司新来小伙伴研发,想让他们定位问题更方便,更快的去熟悉业务,但研发出来以后,没想到我自己都用得不亦乐乎,以致于整个后端小伙伴都在频繁的使用,我自己更是对它爱不释手了,昨天发现技术主管在定位一个这样的问题,在10几天前,有一个运营小伙伴将活动的配置修改了,但现在他发现之前改的配置又被修改回去了,通过这个平台,很快的找到了问题,10几天前,这个运营小伙伴和另一个运营小伙伴打开的相同活动编辑页面,其中一个小伙伴保存了数据,离开了页面,但另一个小伙伴在保存数据时,将前端回显的数据覆盖了前一个运营小伙伴的数据,很快问题就真相大白,当然,还有一种情况,就是在日志中寻找SQL日志,但运营小伙伴也不记得10几天前是哪一天了,如果让技术定位问题,只能估计出一个大概的时间,再在那些时间段内进行寻找,当然在一个系统之内还是比较方便的,但如果是微服务中某段代码不小心覆盖了运营配置,如果没有平台记录,那问题就变得更加扑朔迷离了。
接下来,我们来看一个我们测试环境活动的生命周期过程 。
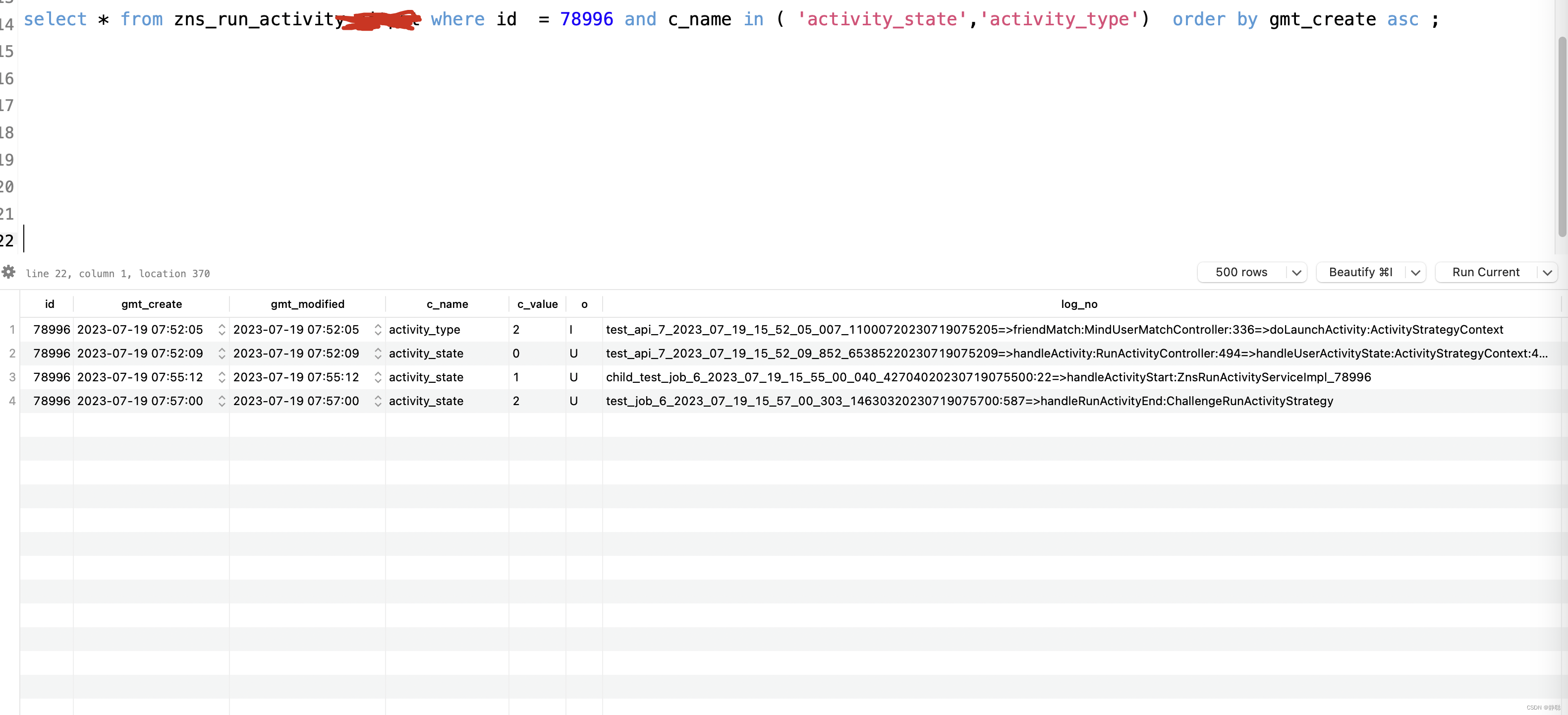
首先这张表有很多的字段,为了帮助大家理解,随便弄了activity_type和activity_state两个字段来分析。
| id | gmt_create | gmt_modified | c_name | c_value | o | log_no |
|---|---|---|---|---|---|---|
| 78996 | 2023-07-19 07:52:05 | 2023-07-19 07:52:05 | activity_type | 2 | I | test_api_7_2023_07_19_15_52_05_007_11000720230719075205=>friendMatch:MindUserMatchController:336=>doLaunchActivity:ActivityStrategyContext |
| 78996 | 2023-07-19 07:52:09 | 2023-07-19 07:52:09 | activity_state | 0 | U | test_api_7_2023_07_19_15_52_09_852_65385220230719075209=>handleActivity:RunActivityController:494=>handleUserActivityState:ActivityStrategyContext:460=>handleUserActivityState:ChallengeRunActivityStrategy |
| 78996 | 2023-07-19 07:55:12 | 2023-07-19 07:55:12 | activity_state | 1 | U | child_test_job_6_2023_07_19_15_55_00_040_42704020230719075500:22=>handleActivityStart:ZnsRunActivityServiceImpl_78996 |
| 78996 | 2023-07-19 07:57:00 | 2023-07-19 07:57:00 | activity_state | 2 | U | test_job_6_2023_07_19_15_57_00_303_14630320230719075700:587=>handleRunActivityEnd:ChallengeRunActivityStrategy |
id为原业务表zns_run_activity的字段id, gmt_modified这个字段目前没有什么业务含义因此不做分析,先来分析第一行数据的业务含义
| id | gmt_create | gmt_modified | c_name | c_value | o | log_no |
|---|---|---|---|---|---|---|
| 78996 | 2023-07-19 07:52:05 | 2023-07-19 07:52:05 | activity_type | 2 | I | test_api_7_2023_07_19_15_52_05_007_11000720230719075205=>friendMatch:MindUserMatchController:336=>doLaunchActivity:ActivityStrategyContext |
之前声明过gmt_create为SQL执行时间,而他的操作类型是I,表示的是插入操作,因此可以得出结论,在2023-07-19 07:52:05这个时间点,对zns_run_activity执行了插入操作,再来分析test_api_7_2023_07_19_15_52_05_007_11000720230719075205=>friendMatch:MindUserMatchController:336=>doLaunchActivity:ActivityStrategyContext这一行日志的含义,首先日志的TraceId为test_api_7_2023_07_19_15_52_05_007_11000720230719075205,而friendMatch:MindUserMatchController:336=>doLaunchActivity:ActivityStrategyContext 的含义是在MindUserMatchController类的friendMatch()方法的366行,调用了ActivityStrategyContext的doLaunchActivity()方法,并在doLaunchActivity()方法中执行了对zns_run_activity表的插入操作。接下来分析第二行数据的业务含义。
| id | gmt_create | gmt_modified | c_name | c_value | o | log_no |
|---|---|---|---|---|---|---|
| 78996 | 2023-07-19 07:52:09 | 2023-07-19 07:52:09 | activity_state | 0 | U | test_api_7_2023_07_19_15_52_09_852_65385220230719075209=>handleActivity:RunActivityController:494=>handleUserActivityState:ActivityStrategyContext:460=>handleUserActivityState:ChallengeRunActivityStrategy |
首先看一下原表activity_state的字段含义:活动状态:0表示未开始,1表示进行中,2表示已结束,-1表示活动已取消,可以看出,在RunActivityController的handleActivity()方法的494行调用了ActivityStrategyContext的handleUserActivityState()方法,并且在handleUserActivityState()方法的460行,调用了ChallengeRunActivityStrategy的handleUserActivityState()方法,并在handleUserActivityState()方法的内部更新了zns_run_activity的activity_state字段为0,日志编号以test_api_7开头,代表含义是zns_run_activity的插入和activity_state字段的初始化都是在 test环境,api项目,并且服务器的IP以7结尾的机器上,接下来看第三行数据的业务含义。
| id | gmt_create | gmt_modified | c_name | c_value | o | log_no |
|---|---|---|---|---|---|---|
| 78996 | 2023-07-19 07:55:12 | 2023-07-19 07:55:12 | activity_state | 1 | U | child_test_job_6_2023_07_19_15_55_00_040_42704020230719075500:22=>handleActivityStart:ZnsRunActivityServiceImpl_78996 |
通过日志编号可以看出,在时间为2023-07-19 07:55:12,测试环境,job定时任务,服务器IP以6结尾的机器上,在ZnsRunActivityServiceImpl的handleActivityStart()方法内,将活动状态更新为进行中,当然会有人好奇,以child开头,什么意思呢?在业务平台,如果是子线程或线程池执行的代码,会在日志编号前加上child。接下来看第4行日志的业务含义。
| id | gmt_create | gmt_modified | c_name | c_value | o | log_no |
|---|---|---|---|---|---|---|
| 78996 | 2023-07-19 07:57:00 | 2023-07-19 07:57:00 | activity_state | 2 | U | test_job_6_2023_07_19_15_57_00_303_14630320230719075700:587=>handleRunActivityEnd:ChallengeRunActivityStrategy |
同样在2023-07-19 07:57:00这个时间点,测试环境,job定义任务,服务器IP以6结尾的机器上,ChallengeRunActivityStrategy类的handleRunActivityEnd()方法将activity_state更新为2,最终得出结论,是定时任务将活动结束掉。
聪明的你现在对这个平台的意义有一定理解了吧,之前开发的某个项目,3个queue,2个admin,2个job, 3个api 等等,这么多项目布署在不同的机器上,同一个项目,一天可能会产生多个日志文件,如果要查找某个问题,最坏可能需要将所有日志文件遍历一遍,如果不知道具体某天的话,那查找范围就更广了,当然有人会想,用elk查询不就能解决所有的问题不?第一,除非你将所有服务的日志都打印在一个topic中,当然查询就方便了,如果像我们公司某个项目有上千万的用户数据,一天产生的日志可能有40-50G,如果去查询日志,可能需要按天查询,如果无法知道数据的更新具体时间,即使有ELK去定位具体业务问题,也有一定麻烦,如果要查询的性能卓越,还需要多台大内存的机器,在几年之前,我搭建过ELK,当时就需要3台32G,4核的机器,这个配置,当时阿里云上需要每月2000元的投入,当然,我的这个平台绝对不需要那么高的投入,随便布署到一台测试机器上即可,性能低,最多只是处理延迟一些,还有另一种情况,当SQL书写不规范时,如下图所示。
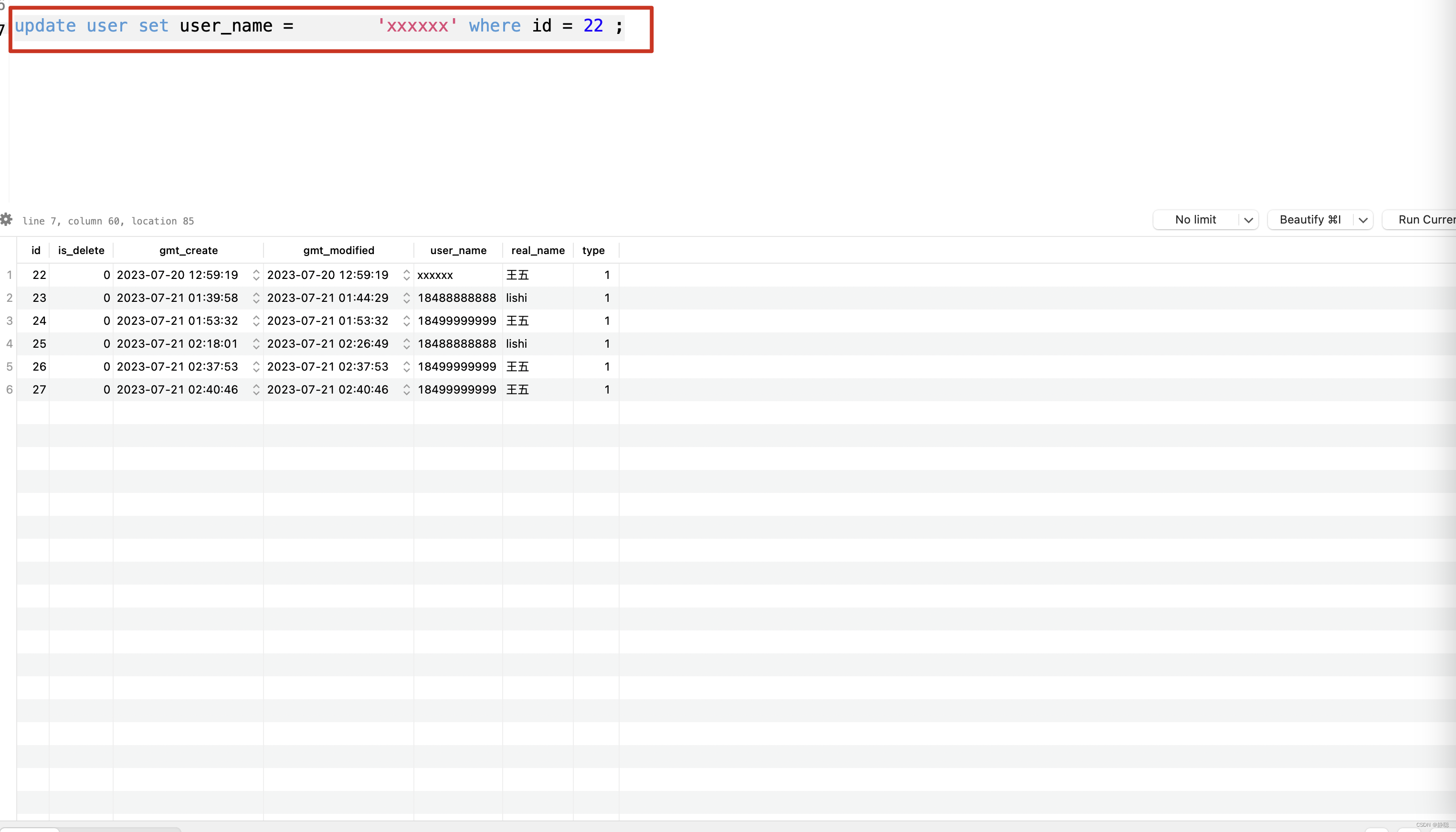
如果写的SQL如上图所示,user_name = ‘xxxxxx’,在等于后面有很多空格,你在日志中通过grep查询数据时, 你可能就不好写grep筛选条件了,如果这样写,cat all.log | grep “user_name = ‘xxxxxx’” | grep “id = 22”; 你可能就查询不到你需要的日志,而我们这个平台很好的解决这个问题。
在实际开发中,可能就写了下面一个非常简单的更新活动开始时间的操作。

但日志中却有一大串,当然公司项目的关键的信息被我隐藏了,只看一部分吧。 SQL如下图所示 。
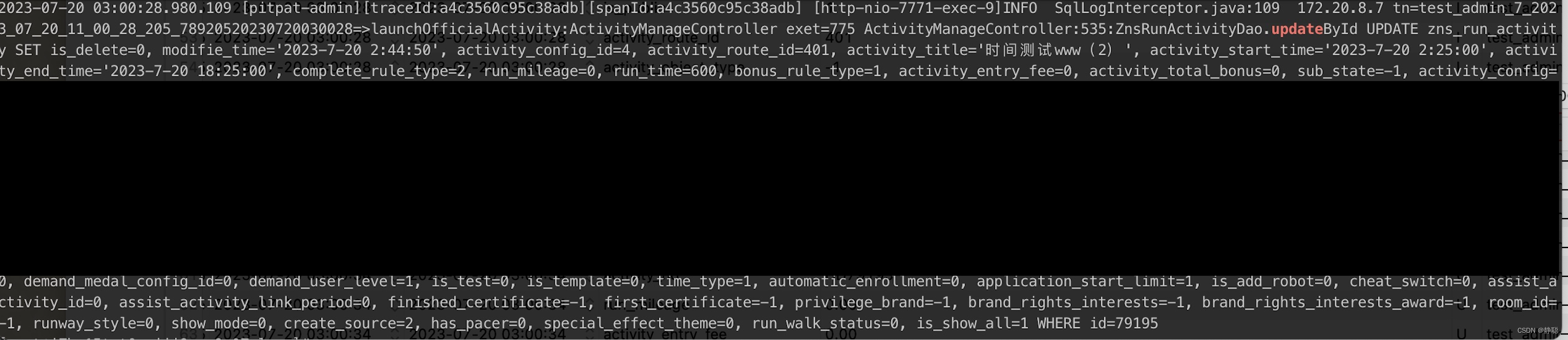
在实际开发中,可能只想更新activity_start_time='2023-7-20 2:25:00’这个字段,但使用了MyBatis Plus插件的updateById()方法,先查询出对象,然后再调用updateById()方法更新数据,此时SQL中有一大串无用的更新数据日志,对我们排查问题也有一定的干扰,而我们平台只对数据变更的字段做记录,因此也很好的解决了此类问题。
关于这个平台的好处就不多说了,接下来对这个平台的实现原理进行剖析,希望你不仅会用,还能移植到你们业务平台,加快技术定位问题的速度,将时间花在更有意义的事情上,而不是做着苦逼而繁锁的事情。
这个平台分数据采集端和数据解析端两个部分,采集部分可以直接从日志读取SQL也是可以的 ,考虑到时实性和日志分片等问题,因此就放弃了从SQL日志采集的想法,为了方便,在例子中我使用了RabbitMQ作为SQL采集的消息队列,当然SQL日志的打印也是使用了MyBatis拦截器来实现。 先来看第一个拦截器。
单条数据插入拦截器
第一个拦截器对StatementHandler的update()方法作拦截 。
- 先来看update的含义 : 用于通知 Statement 对象将 insert、update、delete 操作推送到数据库。
@Intercepts({@Signature(type = StatementHandler.class, method = "update", args = {Statement.class})})
public class SQLInsertLogInterceptor extends SqlParserHandler implements Interceptor {
@Value("${zns.config.rabbitQueue.sql_consumer}")
private String sql_consumer;
@Autowired
private RabbitTemplate rabbitTemplate;
public static final org.slf4j.Logger logger = LoggerFactory.getLogger(SQLBatchUpdateLogInterceptor.class);
@Override
public Object intercept(Invocation invocation) throws Throwable {
StatementHandler statementHandler = (StatementHandler) PluginUtils.realTarget(invocation.getTarget());
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 【注意1】
if (!SqlCommandType.INSERT.equals(mappedStatement.getSqlCommandType())) {
return invocation.proceed();
}
this.sqlParser(metaObject);
// 先判断是不是SELECT操作
BoundSql boundSql = (BoundSql) metaObject.getValue("delegate.boundSql");
String mapperdId = PSqlParseUtil.getMapperId(mappedStatement);
Configuration configuration = mappedStatement.getConfiguration();
Object result = invocation.proceed();
Object parameterObject = boundSql.getParameterObject();
Throwable throwable = new Throwable();
String sqlCommandTypePre = mapperdId + " ";
String peek0 = ServiceAop.peek();
// 【注意2】
// 下面这段代码逻辑,主要用于打印在 Service 中的哪一行代码调用了Mapper
if (StringUtils.isNotBlank(peek0)) {
StackTraceElement[] stackTraceElements = throwable.getStackTrace();
String classInfos[] = peek0.split(":");
int i = 0;
for (StackTraceElement stackTraceElement : stackTraceElements) {
i++;
if (stackTraceElement.getClassName().equals(classInfos[0]) && stackTraceElement.getMethodName().equals(classInfos[1])) {
String className = stackTraceElement.getClassName();
int lastIndexOf = className.lastIndexOf(".");
className = className.substring(lastIndexOf + 1);
sqlCommandTypePre = className + ":" + stackTraceElement.getLineNumber() + ":" + mapperdId + " ";
break;
}
if (i > 100) {
break;
}
}
}
sqlCommandTypePre = "" + sqlCommandTypePre + " ";
String sql = "";
try {
String originSql = SQLBatchUpdateLogInterceptor.showSql(configuration, boundSql);
MetaObject insertObject = SystemMetaObject.forObject(parameterObject);
// 【注意3】
// 拿到主键
String[] keyProperties = mappedStatement.getKeyProperties();
StringBuffer id = new StringBuffer();
for (int i = 0; i keyProperties.length; i++) {
String key = com.data.en.decoder.utils.StringUtils.colomn2JavaCode(keyProperties[i]);
String keyValue = insertObject.getValue(key) + "";
id.append(keyValue);
if (i keyProperties.length - 1) {
id.append("_");
}
}
sql = originSql + " | insert_id=" + id;
// 【注意4】 向消息队列中发送消息
SInfo sInfo = new SInfo(id.toString(), originSql, new Date(), ch.qos.logback.classic.Logger.inheritableThreadLocalNo.get(), Constants.suffix, System.nanoTime(),keyProperties);
rabbitTemplate.convertAndSend(sql_consumer, JSON.toJSONString(sInfo));
} catch (Exception e) {
log.error("SQLInsertInterceptor抛出异常", e);
}
logger.info(sqlCommandTypePre + sql);
} catch (Exception e) {
log.error("SQLInsertInterceptor抛出异常", e);
}
logger.info(sqlCommandTypePre + sql);
return result;
}
}
上面这段代码有4个注意点,也就是为什么我要这样写的原因。
【注意1】
为什么SQLInsertLogInterceptor的intercept()只对插入操作做处理呢? StatementHandler的update()方法不是对插入,更新,删除都可以拦截吗?因为存在批量插入和批量更新情况,对于批量插入,从parameterObject的实体中无法获取到所有对象的主键信息,而批量更新操作,比如你更新10条数据,只会在更新第一条数据时,会进入到SQLInsertLogInterceptor的update拦截器,对后面的9条无法拦截到,也无法获取到SQL日志信息,因此也需要用其他拦截器来处理更新操作。综合上述,SQLInsertLogInterceptor只对插入操作进行拦截 。
【注意2】
Throwable throwable = new Throwable();
String peek0 = ServiceAop.peek();
if (StringUtils.isNotBlank(peek0)) {
StackTraceElement[] stackTraceElements = throwable.getStackTrace();
String classInfos[] = peek0.split(":");
int i = 0;
for (StackTraceElement stackTraceElement : stackTraceElements) {
i++;
if (stackTraceElement.getClassName().equals(classInfos[0]) && stackTraceElement.getMethodName().equals(classInfos[1])) {
String className = stackTraceElement.getClassName();
int lastIndexOf = className.lastIndexOf(".");
className = className.substring(lastIndexOf + 1);
sqlCommandTypePre = className + ":" + stackTraceElement.getLineNumber() + ":" + mapperdId + " ";
break;
}
if (i > 100) {
break;
}
}
}
sqlCommandTypePre = "" + sqlCommandTypePre + " ";
这一段代码大家可能感觉到莫名其妙,为什么我要在拦截器中获取异常栈,然后再与 ServiceAop.peek();中的值进行比对,最终将类名与行号,追加到日志中。还是要看 4.工作中日志打印 这篇博客,在ServiceAop中存储了当前线程方法调用栈,因此只需要取出调用栈顶的类名和方法与异常栈进行比较,即可以获得Mapper()方法的调用行号,更方便定位问题。
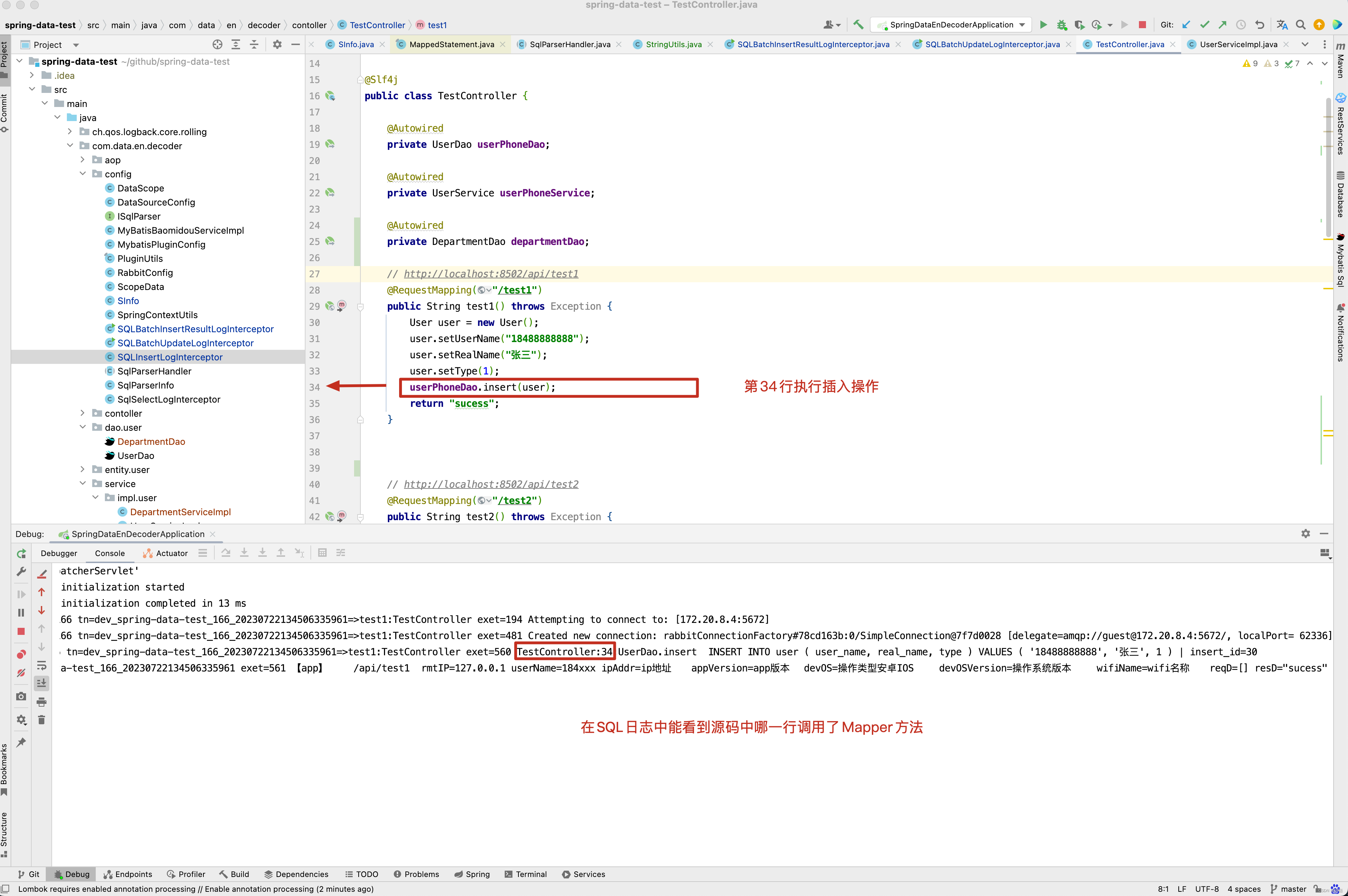
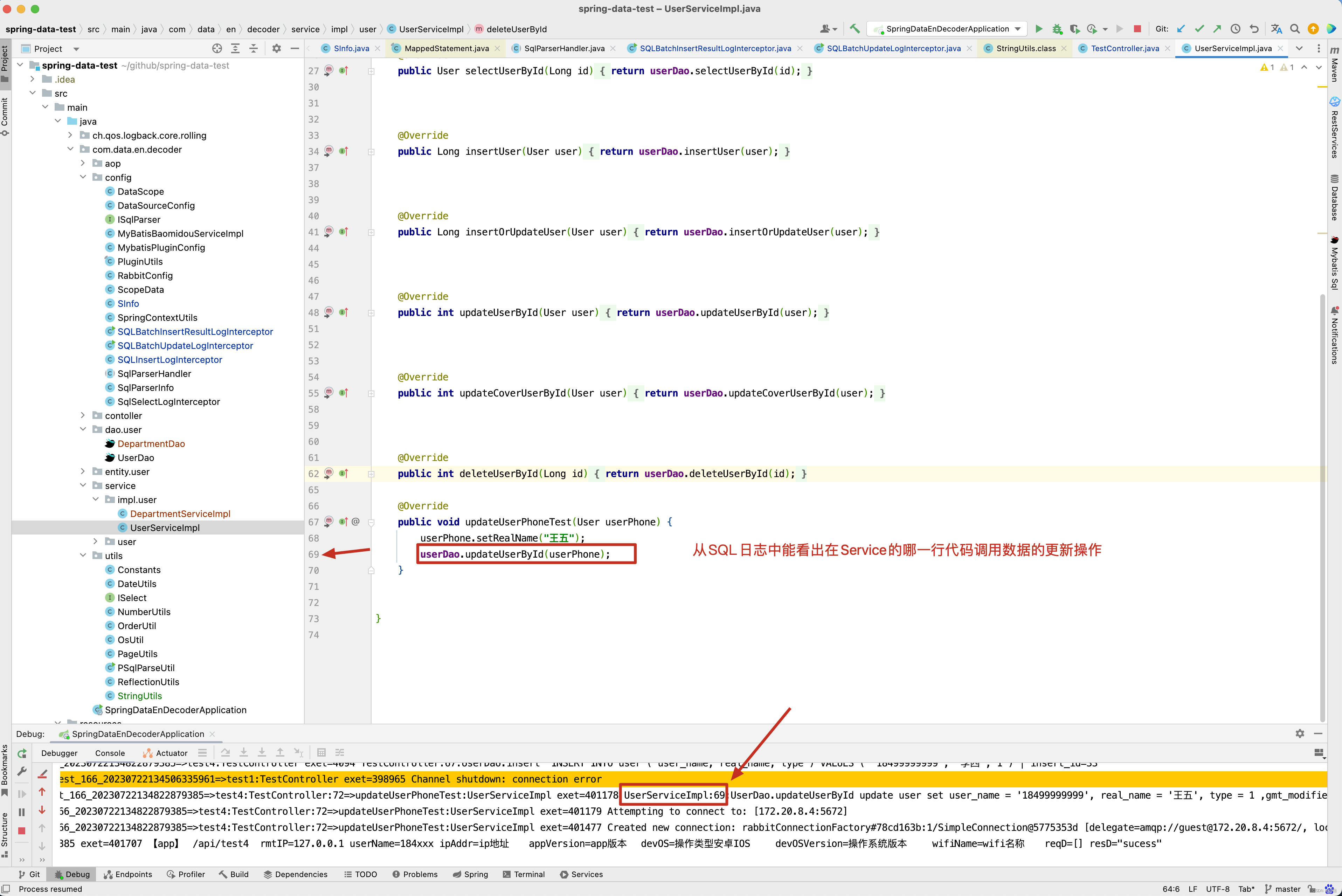
回顾之前的test4()方法 ,在UserServiceImpl.updateUserPhoneTest()方法中的第69行调用了userDao.updateUserById(userPhone) 进行更新user数据。
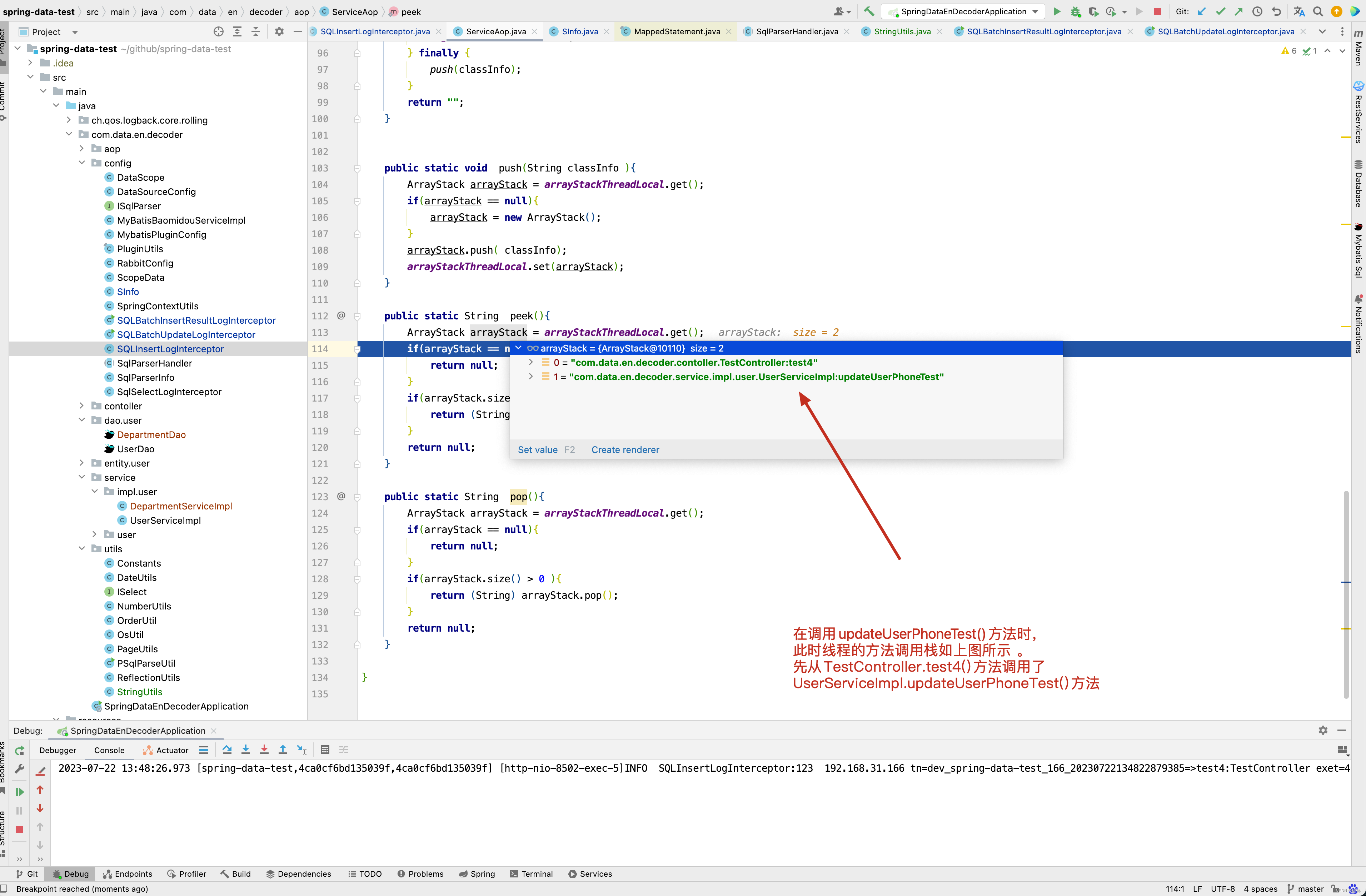
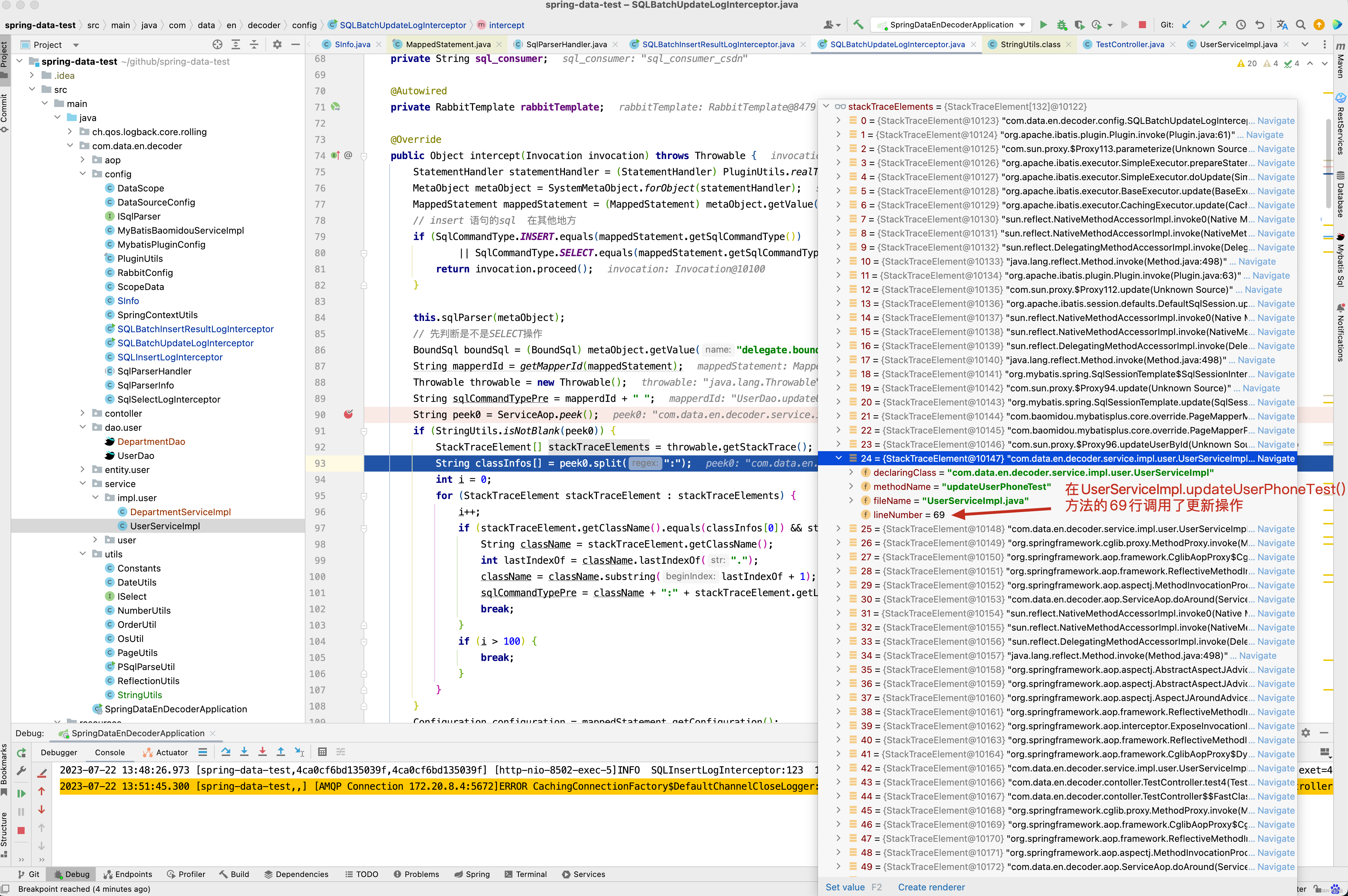
从SQL日志中看出哪一行代码插入或更新了数据 。
【注意3】
请看下面代码。
MetaObject insertObject = SystemMetaObject.forObject(parameterObject);
// 拿到主键
String[] keyProperties = mappedStatement.getKeyProperties();
StringBuffer id = new StringBuffer();
for (int i = 0; i keyProperties.length; i++) {
String key = com.data.en.decoder.utils.StringUtils.colomn2JavaCode(keyProperties[i]);
String keyValue = insertObject.getValue(key) + "";
id.append(keyValue);
if (i keyProperties.length - 1) {
id.append("_");
}
}
mappedStatement.getKeyProperties()获取到的内容就是<insert>配置的keyProperty属性,如下图所示。
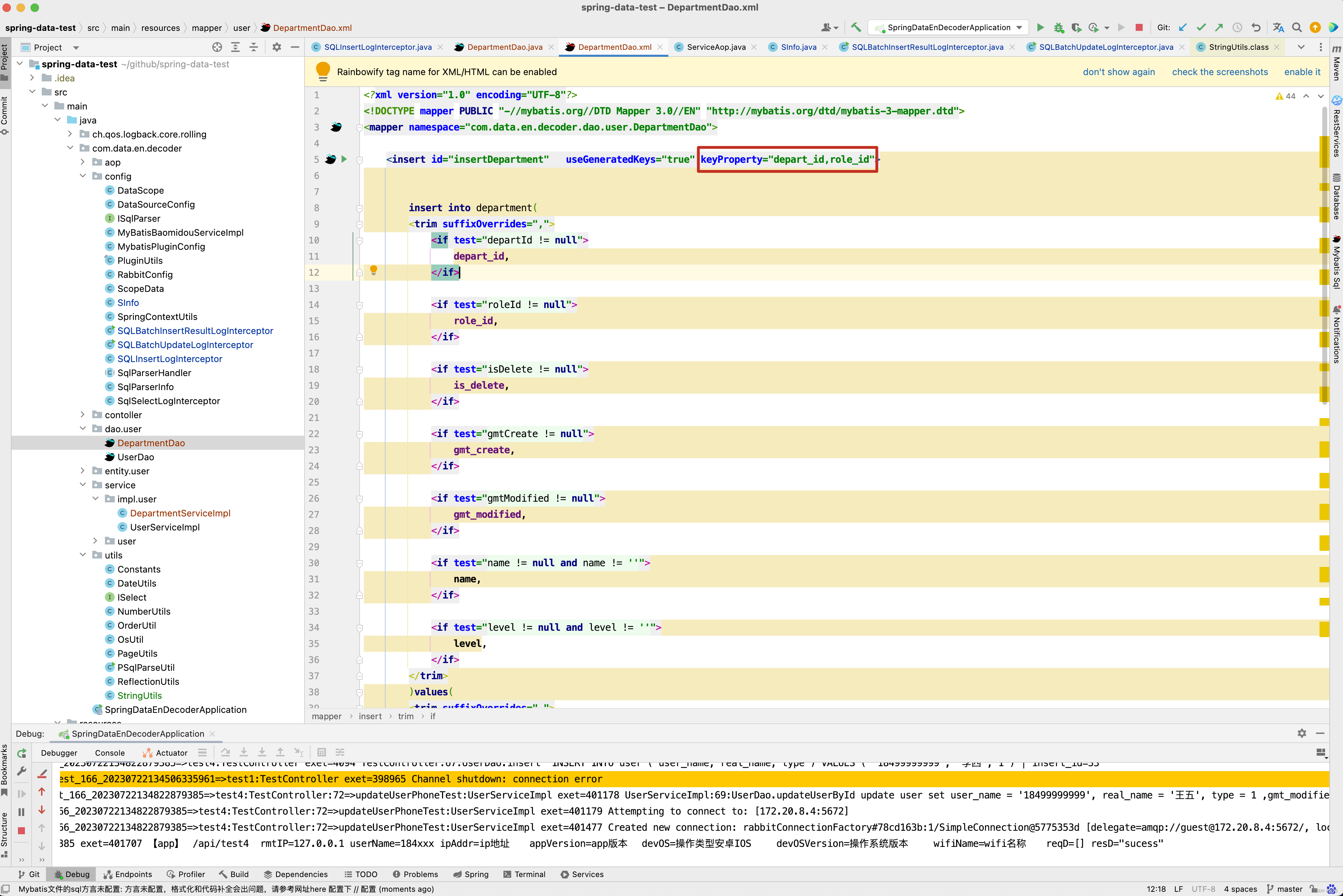
为什么要这么做呢?因为我们设计表时,不一定只有一个主键,可能存在多主键的情况,来看一个例子。
CREATE TABLE department ( depart_id bigint(20) NOT NULL COMMENT '主键,自增id', role_id int(20) NOT NULL COMMENT '主键2 ', is_delete tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除状态,1:删除,0:有效', gmt_create datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', gmt_modified datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后修改时间', name varchar(64) NOT NULL DEFAULT '', level varchar(64) NOT NULL DEFAULT '', PRIMARY KEY (depart_id,role_id) USING BTREE, KEY index_user_name_en (name) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表';
创建了一张部门表,他的主键分别是depart_id和role_id,对于这种情况,在我们平台上,id存储的内容为多个主键以_(下划线隔开)的一个复合字段。
TestController.java
// http://localhost:8502/api/test5
@RequestMapping("/test5")
public String test5() throws Exception {
Department department = new Department();
department.setDepartId(1111l);
department.setRoleId(2222l);
department.setName("研发");
department.setLevel("1");
departmentDao.insertDepartment(department);
return "sucess";
}
Department.java
@Data
@TableName("department")
public class Department implements java.io.Serializable {
//主键,自增id
@TableId(value = "depart_id")
private Long departId;
//主键2
@TableId(value = "role_id")
private Long roleId;
//是否删除状态,1:删除,0:有效
private Integer isDelete;
//创建时间
private Date gmtCreate;
//最后修改时间
private Date gmtModified;
private String name;
private String level;
}
DepartmentDao.java
<insert id="insertDepartment" useGeneratedKeys="true" keyProperty="depart_id,role_id
">
insert into department(
<trim suffixOverrides=",">
<if test="departId != null">
depart_id,
</if>
<if test="roleId != null">
role_id,
</if>
<if test="isDelete != null">
is_delete,
</if>
<if test="gmtCreate != null">
gmt_create,
</if>
<if test="gmtModified != null">
gmt_modified,
</if>
<if test="name != null and name != ''">
name,
</if>
<if test="level != null and level != ''">
level,
</if>
</trim>
)values(
<trim suffixOverrides=",">
<if test="departId != null">
#{departId},
</if>
<if test="roleId != null">
#{roleId},
</if>
<if test="isDelete != null">
#{isDelete},
</if>
<if test="gmtCreate != null">
#{gmtCreate},
</if>
<if test="gmtModified != null">
#{gmtModified},
</if>
<if test="name != null and name != ''">
#{name},
</if>
<if test="level != null and level != ''">
#{level},
</if>
</trim>
)
</insert>
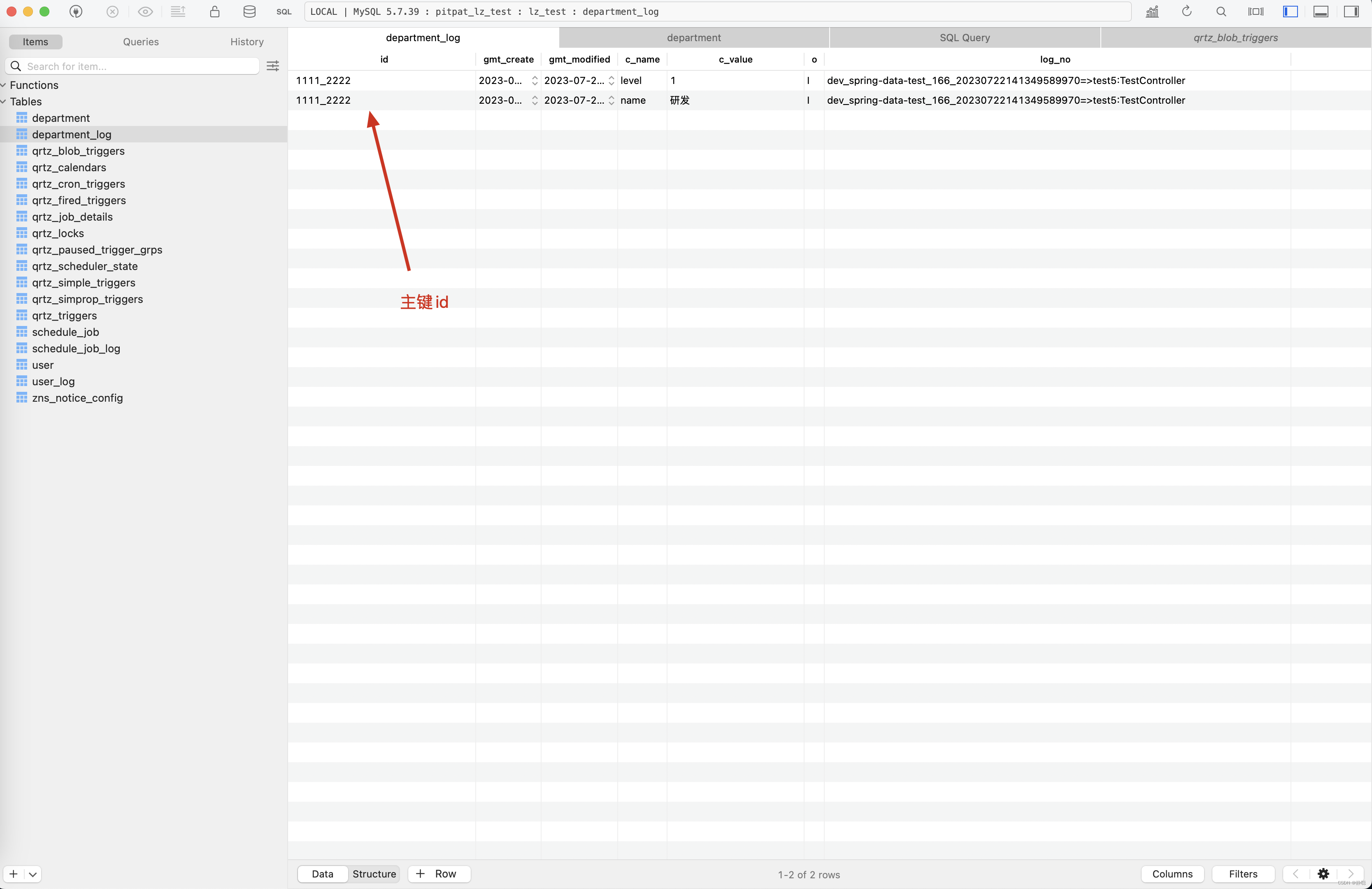
调用 http://localhost:8502/api/test5,查看执行结果 。

最终在我们平台上保存的数据是什么呢?
当然源码看到这里,有人可能产生疑问,如果是自增主键id,为什么我在mybatis的<insert useGeneratedKeys=“true” keyProperty=“id” > 上配置了keyProperty,MyBatis就将主键帮我们封装到我们对象中了呢? 其实这个问题很简单呢,直接在对象的setId()方法中打断点即可 。
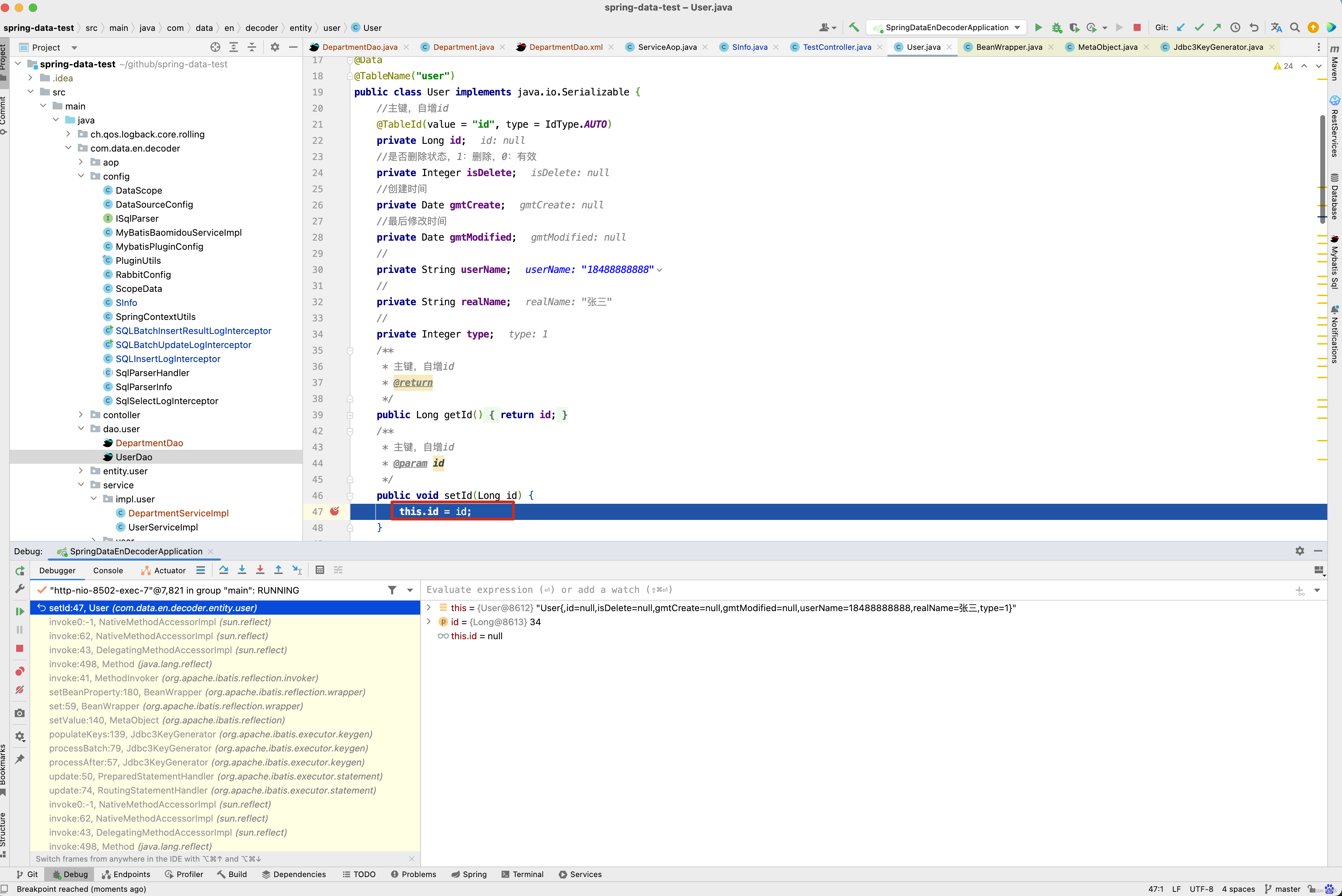
通过栈向上寻寻觅觅。
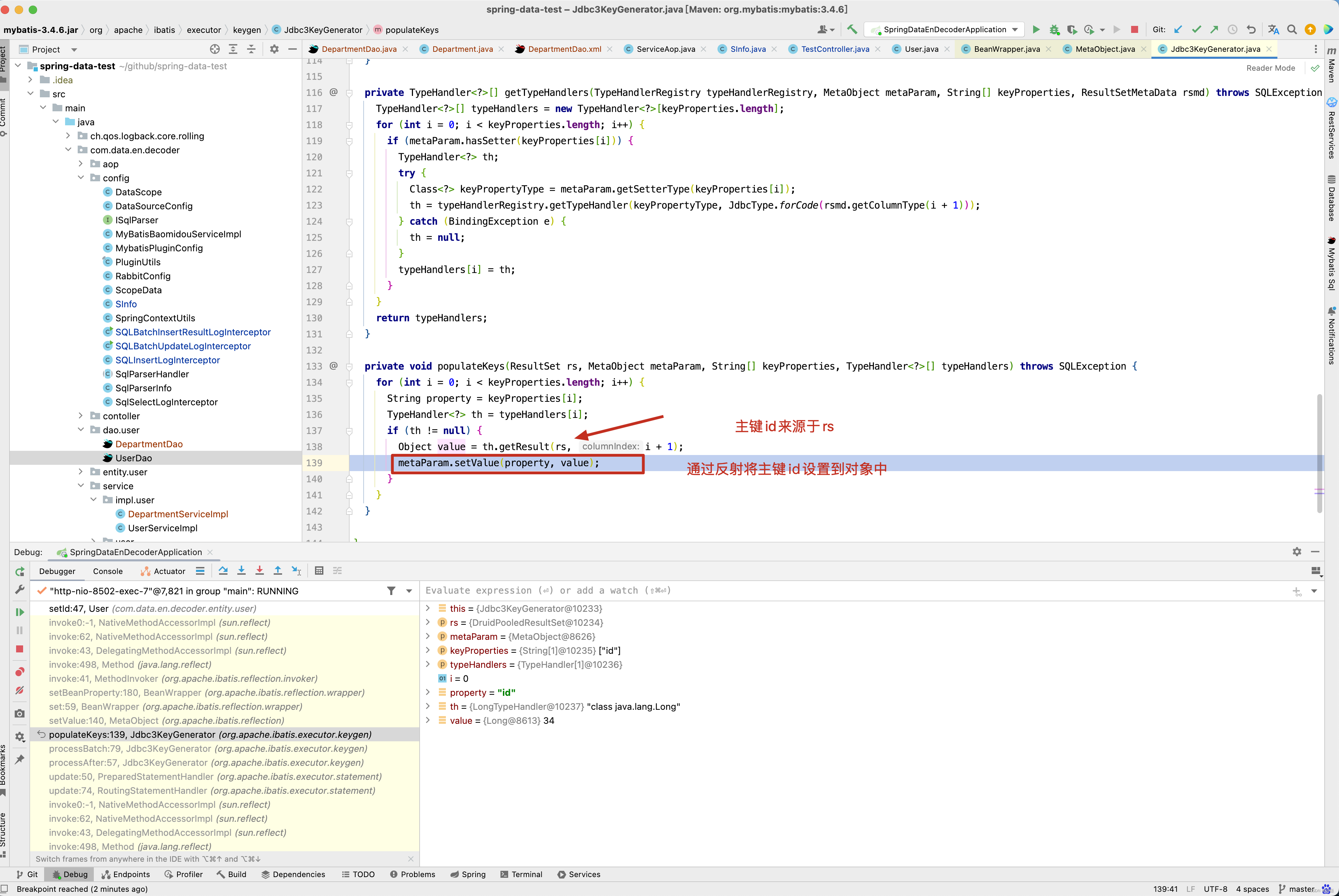
而ResultSet又来源于stmt.getGeneratedKeys(),如下图所示 。
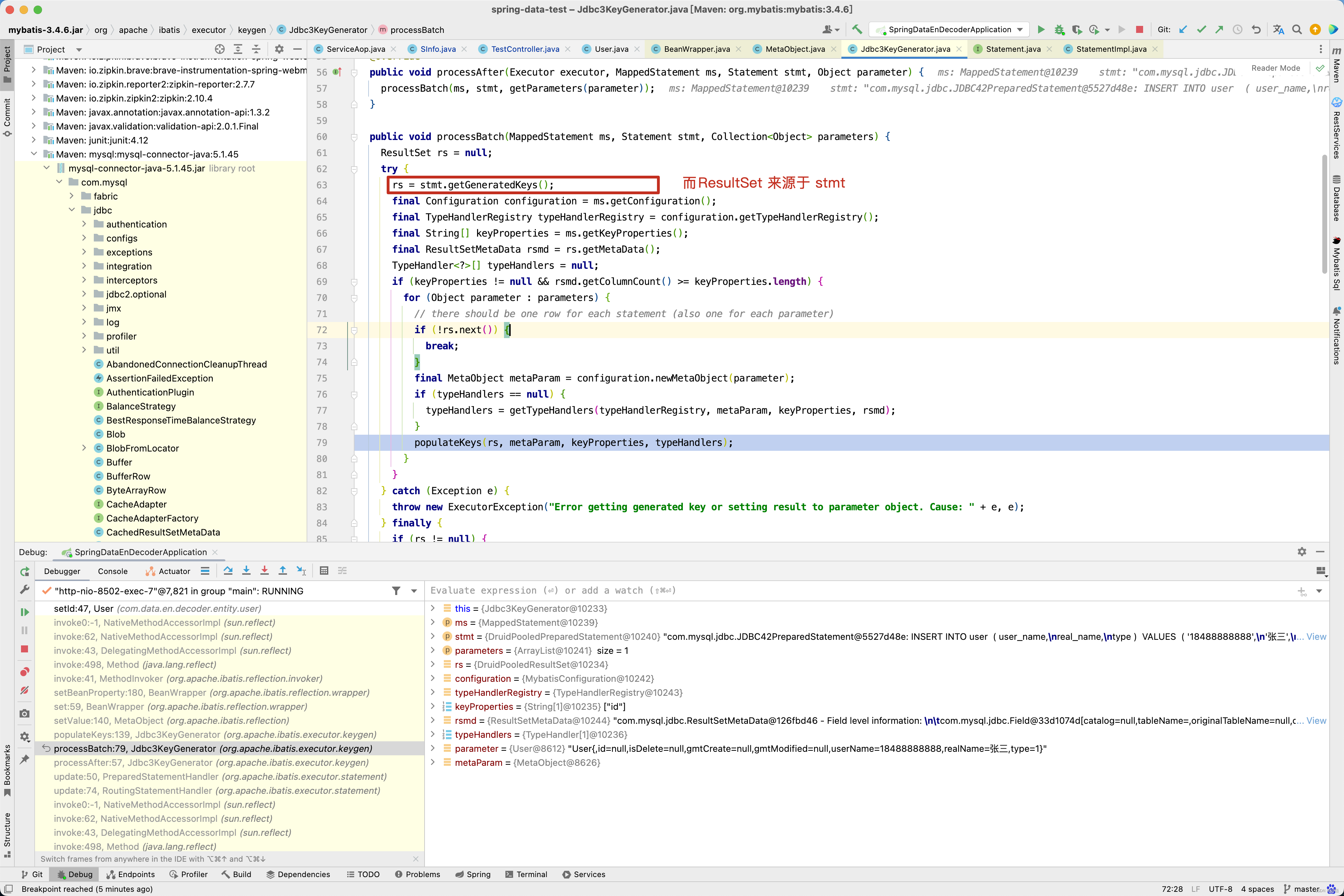
普通的JDBC代码也能拿到ResultSet对象,如下图所示 。
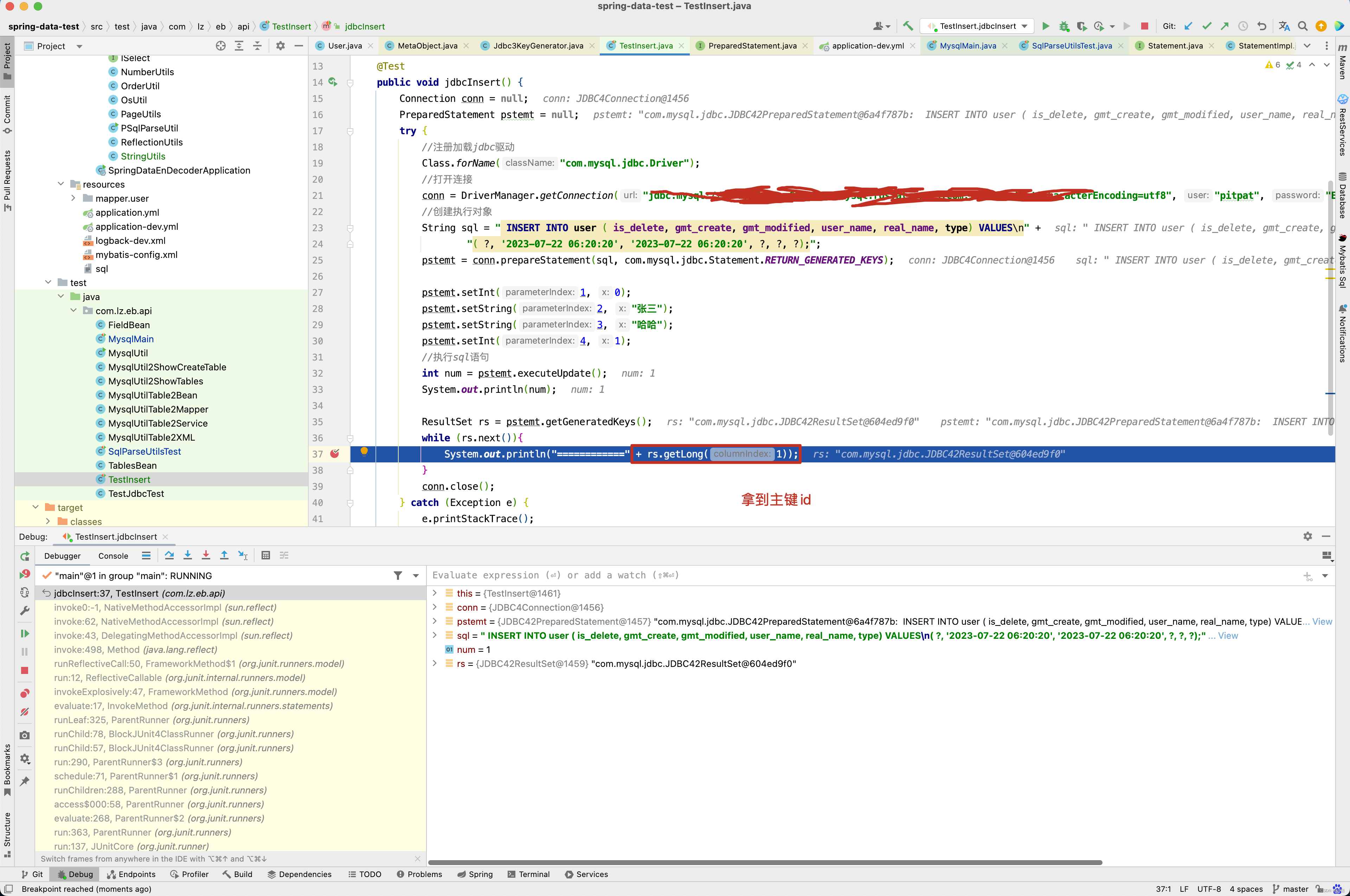
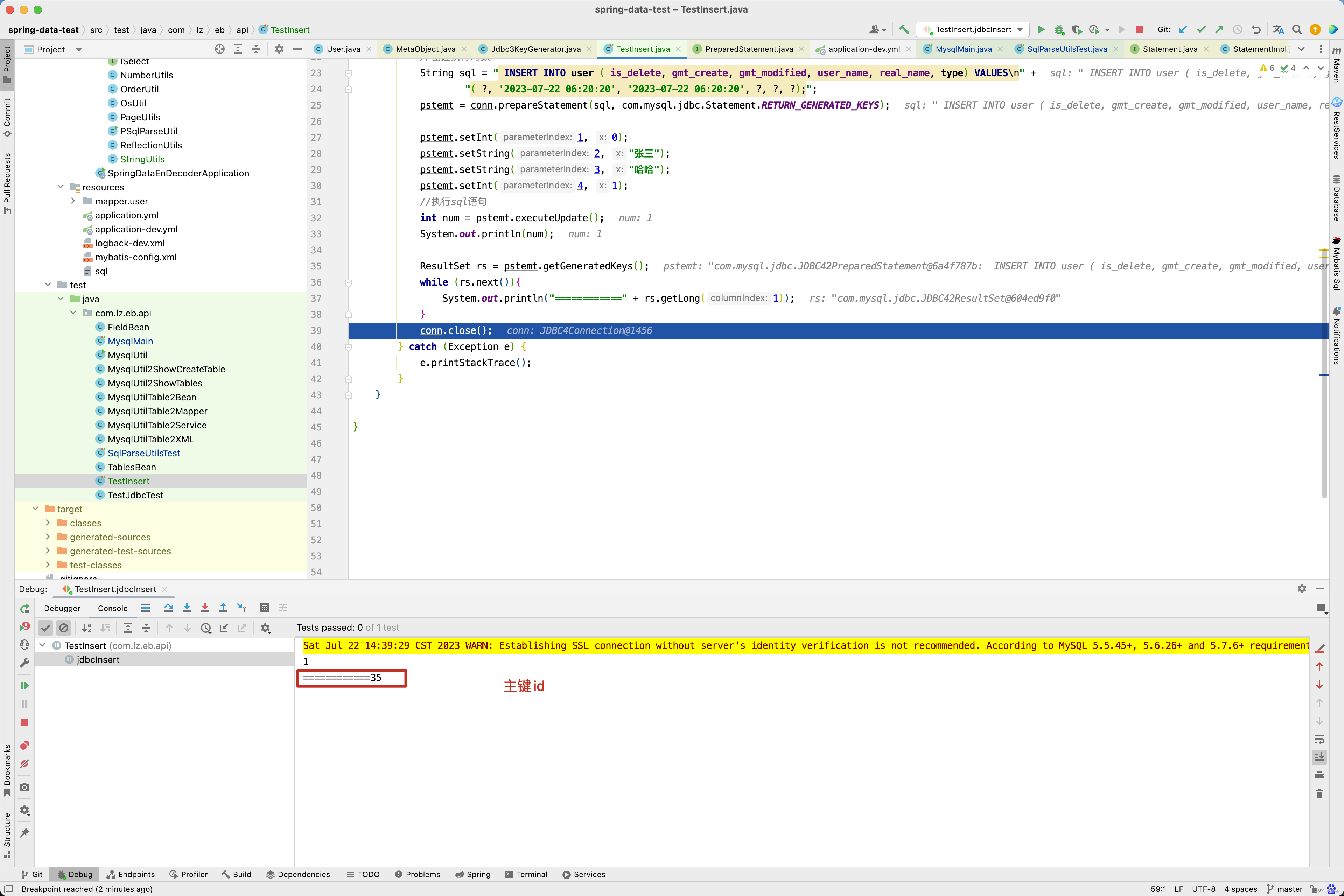
因此对于单条记录的插入操作回写主键id原理就很简单了,插入成功后, 从ResultSet获取到主键id,再获取到<insert />标签配置的keyProperty属性,再通过反射设置主键的值。
【注意4】
将数据封装成SInfo对象,并通过RabbitMQ发送出去,这里需要注意SInfo对象的含义。
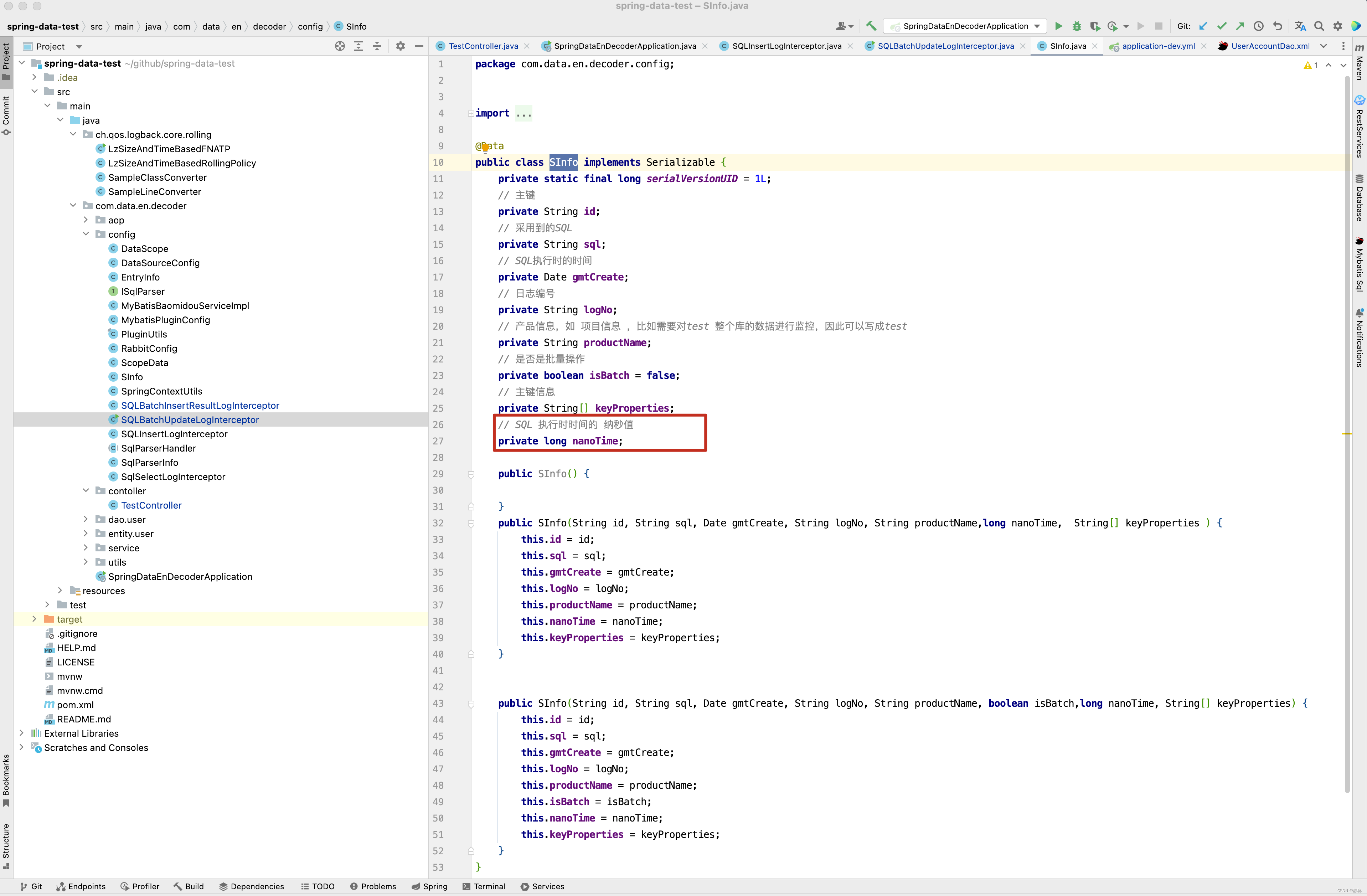
@Data
public class SInfo implements Serializable {
private static final long serialVersionUID = 1L;
// 主键
private String id;
// 采用到的原始SQL,在平台上解析SQL字段时需要
private String sql;
// SQL执行时的时间
private Date gmtCreate;
// 日志编号
private String logNo;
// 产品信息,如 项目信息 ,比如需要对test 整个库的数据进行监控,因此可以写成test
private String productName;
// 是否是批量操作
private boolean isBatch = false;
// 主键信息
private String[] keyProperties;
// SQL 执行时时间的 纳秒值
private long nanoTime;
}
关于SInfo对象中每个字段的用途,在后面的解析中再来分析 。
批量插入拦截器实现
单条数据的插入原理已经分析完毕,接下来看批量插入拦截器实现。
@Intercepts({@Signature(type = Executor.class, method = "flushStatements", args = {})})
public class SQLBatchInsertResultLogInterceptor extends SqlParserHandler implements Interceptor {
public static final org.slf4j.Logger logger = LoggerFactory.getLogger(SQLBatchUpdateLogInterceptor.class);
@Value("${zns.config.rabbitQueue.sql_consumer}")
private String sql_consumer;
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object result = invocation.proceed();
try {
Throwable throwable = new Throwable();
String sqlCommandTypePre = " ";
String peek0 = ServiceAop.peek();
if (StringUtils.isNotBlank(peek0)) {
StackTraceElement[] stackTraceElements = throwable.getStackTrace();
String classInfos[] = peek0.split(":");
int i = 0;
for (StackTraceElement stackTraceElement : stackTraceElements) {
i++;
if (stackTraceElement.getClassName().equals(classInfos[0]) && stackTraceElement.getMethodName().equals(classInfos[1])) {
String className = stackTraceElement.getClassName();
int lastIndexOf = className.lastIndexOf(".");
className = className.substring(lastIndexOf + 1);
sqlCommandTypePre = className + ":" + stackTraceElement.getLineNumber() ;
break;
}
if (i > 100) {
break;
}
}
}
if(result instanceof ArrayList && result!=null && ((ArrayList<?>) result).size() > 0 ){
List<BatchResult> results =(List<BatchResult> ) result;
for(BatchResult batchResult :results){
MappedStatement mappedStatement = batchResult.getMappedStatement();
String mapperdId = PSqlParseUtil.getMapperId(mappedStatement);
List<Object> list = batchResult.getParameterObjects();
for (Object l : list) {
try {
String sql = batchResult.getSql();
String toLowerSql = sql.toLowerCase().trim();
if (toLowerSql.startsWith("update")) { //如果是update开头的,则过滤掉
continue;
}
printBatchSql(mappedStatement,batchResult, l, sqlCommandTypePre + ":" + mapperdId);
} catch (Exception e) {
log.info("异常 ", e);
}
}
}
}
} catch (Exception e) {
log.error("SQLBatchInsertResultLogInterceptor方法处理异常异常",e);
}
return result;
}
public void printBatchSql( MappedStatement mappedStatement ,BatchResult batchResult , Object entity,String pre){
String originSql = batchResult.getSql();
Method[] methods = entity.getClass().getDeclaredMethods();
StringBuffer sqlColumn = new StringBuffer("(");
StringBuffer sqlValues = new StringBuffer("(");
// 拿到主键
String[] keyProperties = mappedStatement.getKeyProperties();
List<String> keyMethods = new ArrayList<>();
// 获取主键的方法名
for(String key : keyProperties){
String column = com.data.en.decoder.utils.StringUtils.colomn2JavaCode(key);
keyMethods.add("get"+column.substring(0, 1).toUpperCase() + column.substring(1));
}
List<String> keyValues = new ArrayList<>();
for (Method method : methods) {
StringBuffer error = new StringBuffer();
try {
String methodName = method.getName();
if (keyMethods.contains(methodName)) {
keyValues.add(method.invoke(entity) + "");
continue;
}
if (methodName.startsWith("get")) {
error.append("methodName = " + methodName);
Object o = method.invoke(entity);
if (o != null) {
error.append(", o = ").append(o);
String column = methodName.substring(3);
error.append(", column= " + column);
String db_column = toUnderScoreCase(column);
error.append(", db_column= " + db_column);
sqlColumn.append(" ").append(db_column).append(" ").append(",");
String parameterValue = SQLBatchUpdateLogInterceptor.getParameterValue(o);
error.append(", parameterValue= " + parameterValue);
sqlValues.append(" ").append(parameterValue).append(" ").append(",");
}
}
} catch (Exception e) {
log.error("SQLBatchInsertResultLogInterceptor异常实体内容为 " + JSONObject.toJSONString(entity) + ", error = " + error.toString(),e);
}
}
String sqlPre = originSql.substring(0, originSql.indexOf("("));
sqlColumn.deleteCharAt(sqlColumn.length() - 1);
sqlValues.deleteCharAt(sqlValues.length() - 1);
sqlColumn.append(")");
sqlValues.append(")");
StringBuffer id = new StringBuffer();
for (int i = 0; i < keyValues.size(); i++) {
id.append(keyValues.get(i));
if (i < keyProperties.length - 1) {
id.append("_");
}
}
StringBuffer sb = new StringBuffer();
sb.append(sqlPre).append(sqlColumn).append(" VALUES ").append(sqlValues);
String sql = pre+" " + sb + " | batch_insert_id=" +id;
SInfo sInfo = new SInfo(id.toString(), sb.toString(), new Date(), ch.qos.logback.classic.Logger.inheritableThreadLocalNo.get(), Constants.suffix,
true,System.nanoTime(),keyProperties);
rabbitTemplate.convertAndSend(sql_consumer, JSON.toJSONString(sInfo));
log.info(sql);
}
}
对于批量插入操作,整个拦截器源码实现原理就很简单了,难点是弄明白为什么使用Executor的flushStatements()方法拦截器呢?
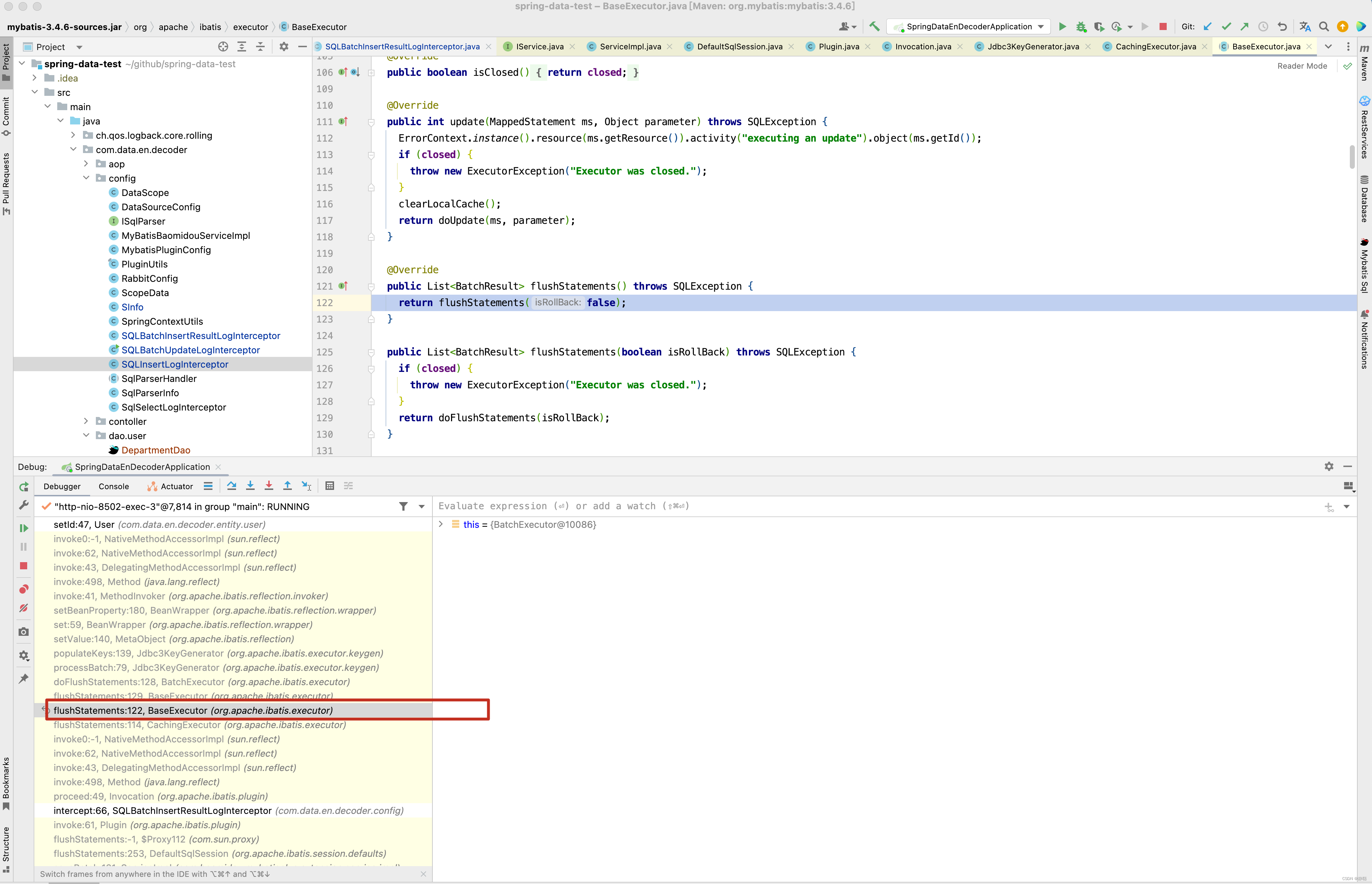
从源码的调用过程来看,批量插入操作并没有经过StatementHandler的update()拦截器。因此只能写Executor的flushStatements()拦截器,因为flushStatements这个拦截器在SQL执行之后,这时很难拿到boundSql以及方法的传入参数,但幸运的是,能从BatchResult对象中拿到parameterObjects对象,而parameterObject对象中,MyBatis已经将主键id设置到parameterObject对象中,因此只需要跟据对象自己组装SQL 再传入到数据库字段变更log平台即可。 批量保存User对象 。
// http://localhost:8502/api/test6
@RequestMapping("/test6")
public String test6() throws Exception {
User user1 = new User();
user1.setUserName("18188888888");
user1.setRealName("张三");
user1.setType(1);
User user2 = new User();
user2.setUserName("18288888888");
user2.setRealName("李四");
user2.setType(2);
User user3 = new User();
user3.setUserName("18388888888");
user3.setRealName("王五");
user3.setType(3);
List<User> users = new ArrayList<>();
users.add(user1);
users.add(user2);
users.add(user3);
userPhoneService.saveBatch(users);
return "sucess";
}
跟据对象信息,自己组装了三条SQL,通过消息队列发送到SQL采集平台 。
2023-07-22 15:26:55.528 [spring-data-test,03d4cf276d7bd5bb,03d4cf276d7bd5bb] [http-nio-8502-exec-1]INFO SQLBatchInsertResultLogInterceptor:179 192.168.31.166 tn=dev_spring-data-test_166_20230722152654923448=>test6:TestController exet=604 TestController:122:UserDao.insert INSERT INTO user ( user_name , type , real_name ) VALUES ( '18188888888' , 1 , '张三' ) | batch_insert_id=46 2023-07-22 15:26:55.529 [spring-data-test,03d4cf276d7bd5bb,03d4cf276d7bd5bb] [http-nio-8502-exec-1]INFO SQLBatchInsertResultLogInterceptor:179 192.168.31.166 tn=dev_spring-data-test_166_20230722152654923448=>test6:TestController exet=605 TestController:122:UserDao.insert INSERT INTO user ( user_name , type , real_name ) VALUES ( '18288888888' , 2 , '李四' ) | batch_insert_id=47 2023-07-22 15:26:55.529 [spring-data-test,03d4cf276d7bd5bb,03d4cf276d7bd5bb] [http-nio-8502-exec-1]INFO SQLBatchInsertResultLogInterceptor:179 192.168.31.166 tn=dev_spring-data-test_166_20230722152654923448=>test6:TestController exet=605 TestController:122:UserDao.insert INSERT INTO user ( user_name , type , real_name ) VALUES ( '18388888888' , 3 , '王五' ) | batch_insert_id=48
最终数据库中保存的数据如下:
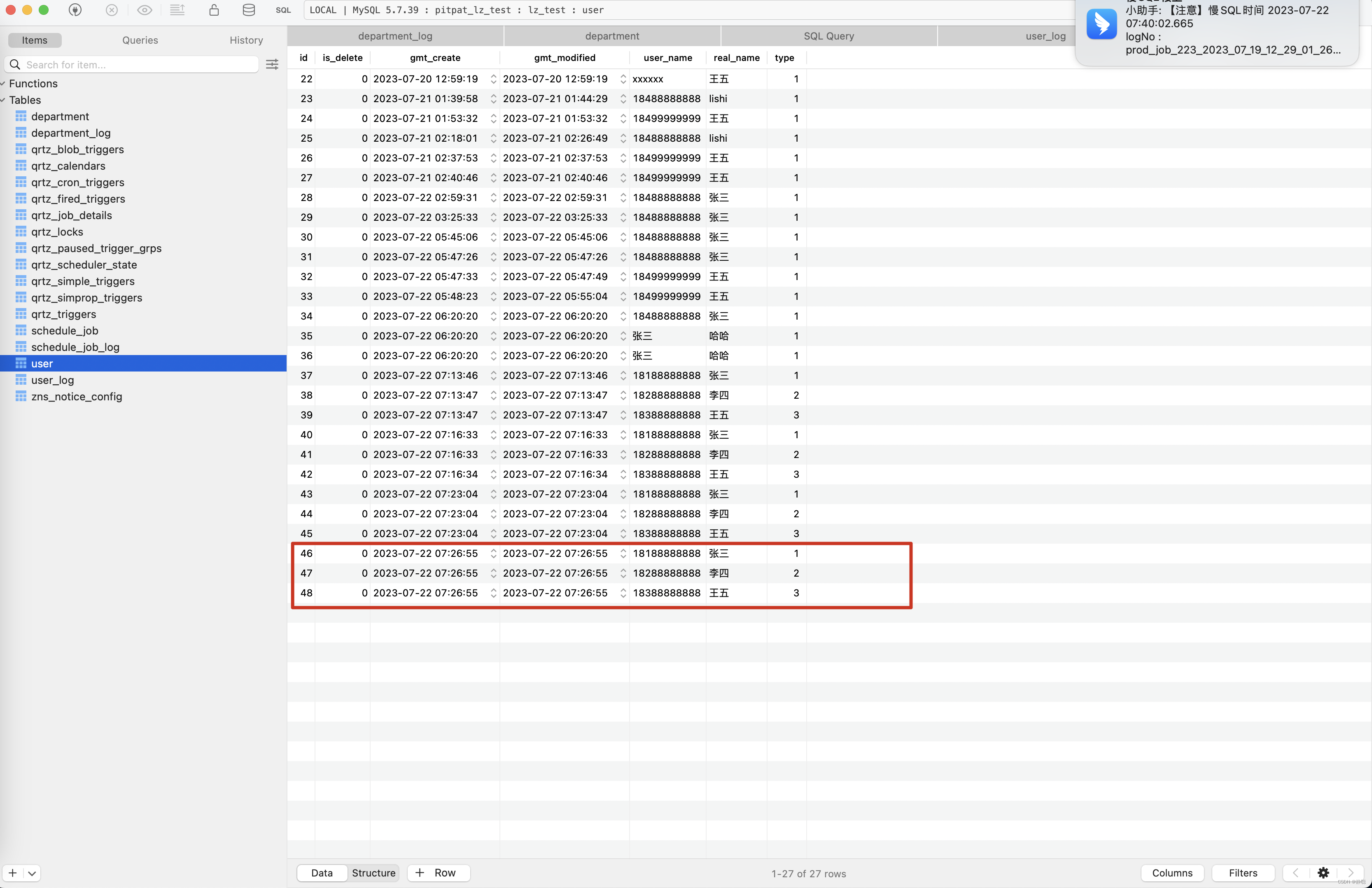
SQL采集平台的数据保存如下。

当然有些地方还是需要注意,SQLBatchInsertResultLogInterceptor只对批量插入做处理,对批量更新,单条数据的插入不做处理,当然对于批量插入操作主键id的设置原理和单条SQL执行的获取原理一样。
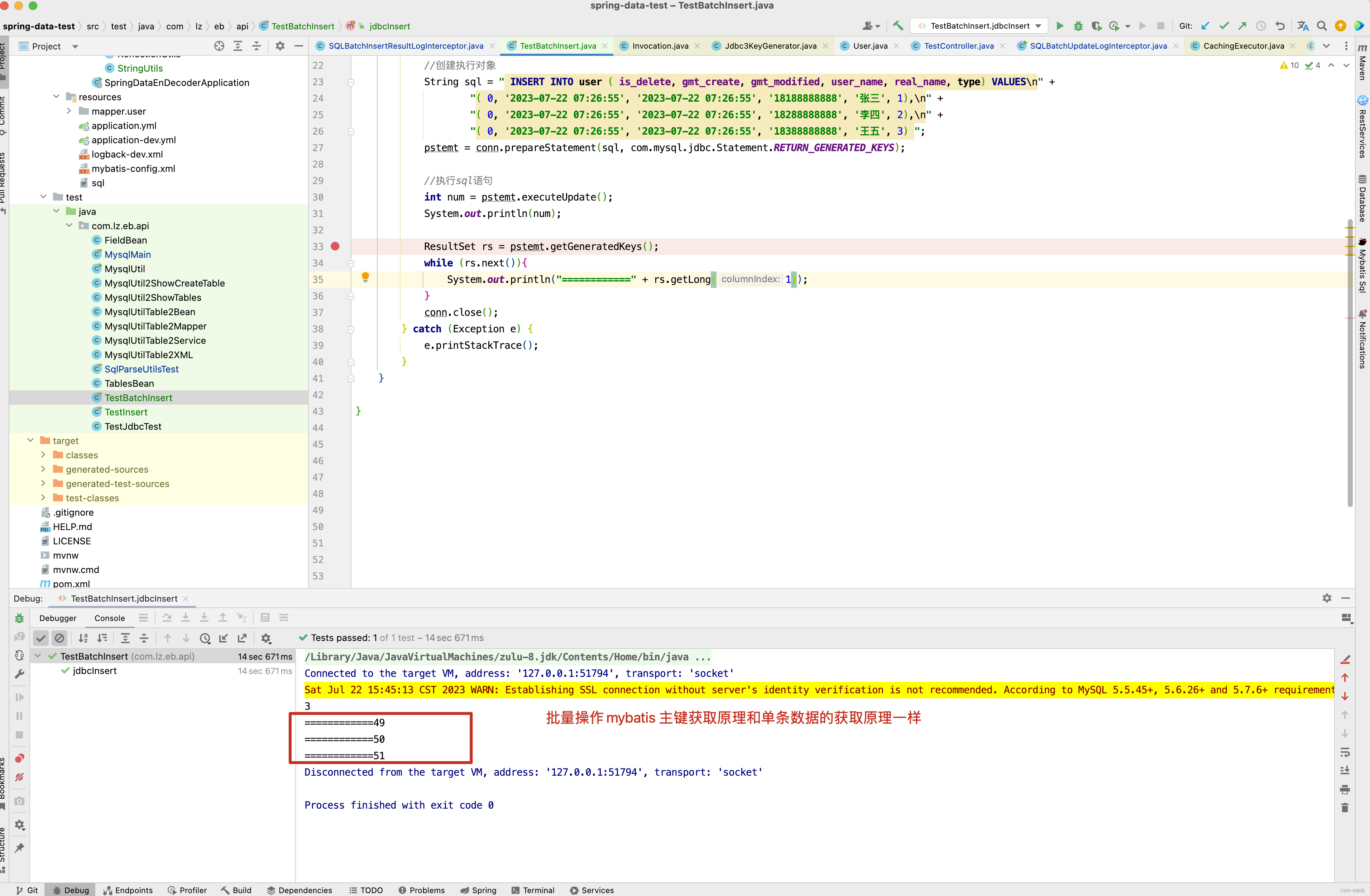
接下来看一个多主键批量插入操作的例子。
// http://localhost:8502/api/test7
@RequestMapping("/test7")
public String test7() throws Exception {
Department department1 = new Department();
department1.setDepartId(1111l);
department1.setRoleId(1111l);
department1.setName("研发1");
department1.setLevel("1");
Department department2 = new Department();
department2.setDepartId(2222l);
department2.setRoleId(2222l);
department2.setName("研发2");
department2.setLevel("2");
Department department3 = new Department();
department3.setDepartId(3333l);
department3.setRoleId(3333l);
department3.setName("研发3");
department3.setLevel("3");
List<Department> departmentList = new ArrayList<>();
departmentList.add(department1);
departmentList.add(department2);
departmentList.add(department3);
departmentService.saveBatch(departmentList);
return "sucess";
}
批量插入SQL日志如下 。
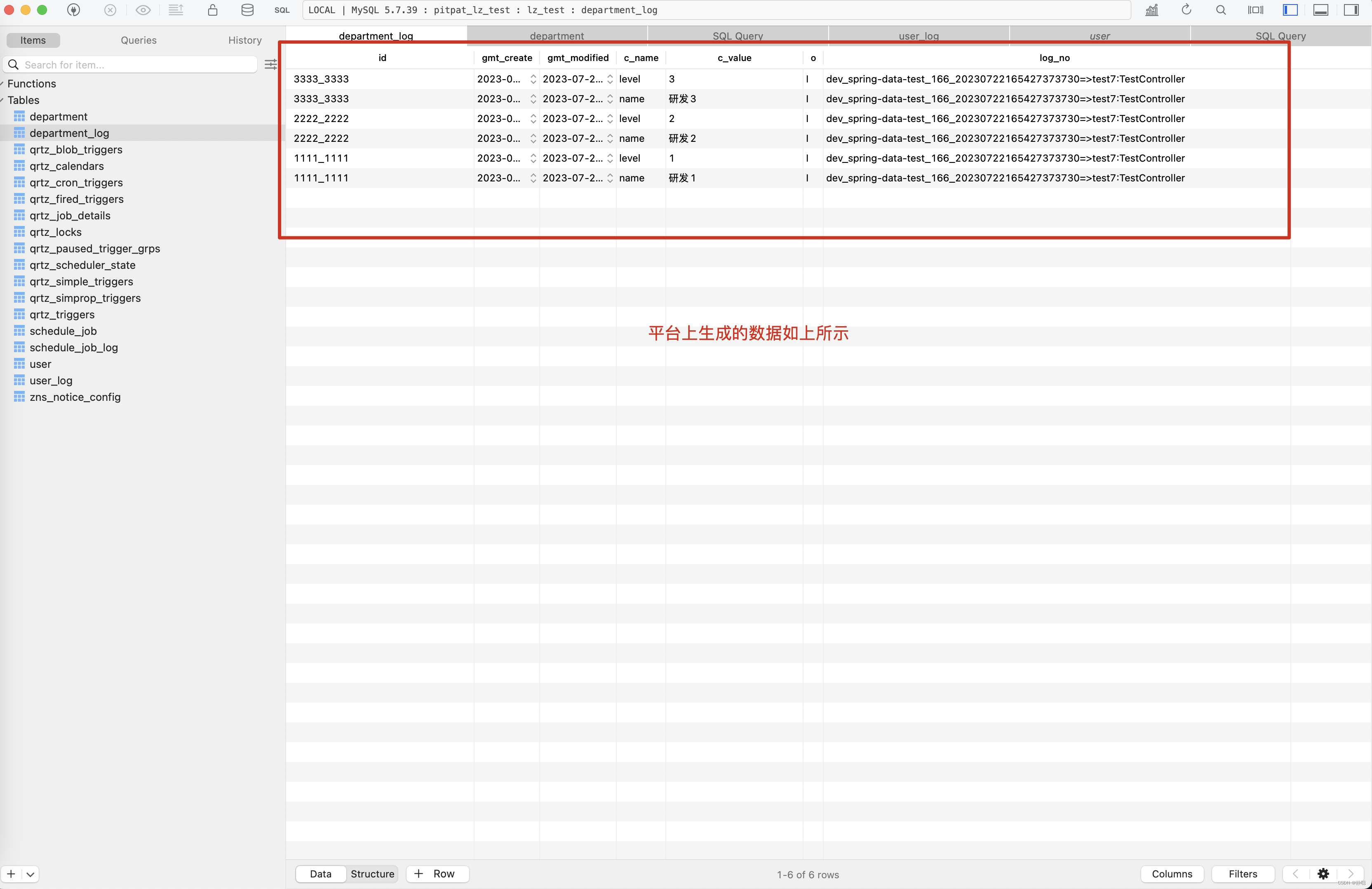
2023-07-22 16:50:09.342 [spring-data-test,67e98afd4ef97cbb,67e98afd4ef97cbb] [http-nio-8502-exec-1]INFO SQLBatchInsertResultLogInterceptor:196 192.168.31.166 tn=dev_spring-data-test_166_20230722164841051275=>test7:TestController exet=88291 TestController:159:DepartmentDao.insert INSERT INTO department ( level , name ) VALUES ( '1' , '研发1' ) | batch_insert_id=1111_1111 2023-07-22 16:50:09.344 [spring-data-test,67e98afd4ef97cbb,67e98afd4ef97cbb] [http-nio-8502-exec-1]INFO SQLBatchInsertResultLogInterceptor:196 192.168.31.166 tn=dev_spring-data-test_166_20230722164841051275=>test7:TestController exet=88293 TestController:159:DepartmentDao.insert INSERT INTO department ( level , name ) VALUES ( '2' , '研发2' ) | batch_insert_id=2222_2222 2023-07-22 16:50:09.344 [spring-data-test,67e98afd4ef97cbb,67e98afd4ef97cbb] [http-nio-8502-exec-1]INFO SQLBatchInsertResultLogInterceptor:196 192.168.31.166 tn=dev_spring-data-test_166_20230722164841051275=>test7:TestController exet=88293 TestController:159:DepartmentDao.insert INSERT INTO department ( level , name ) VALUES ( '3' , '研发3' ) | batch_insert_id=3333_3333
插入的数据如下

平台上生成的字段变更记录如下图所示 。
单条数据更新和批量更新拦截器实现
@Intercepts({@Signature(type = StatementHandler.class, method = "parameterize", args = {Statement.class})})
public class SQLBatchUpdateLogInterceptor extends SqlParserHandler implements Interceptor {
public static final org.slf4j.Logger logger = LoggerFactory.getLogger(SQLBatchUpdateLogInterceptor.class);
@Value("${zns.config.rabbitQueue.sql_consumer}")
private String sql_consumer;
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public Object intercept(Invocation invocation) throws Throwable {
StatementHandler statementHandler = (StatementHandler) PluginUtils.realTarget(invocation.getTarget());
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// insert 语句的sql 在其他地方
if (SqlCommandType.INSERT.equals(mappedStatement.getSqlCommandType())
|| SqlCommandType.SELECT.equals(mappedStatement.getSqlCommandType())) {
return invocation.proceed();
}
this.sqlParser(metaObject);
// 先判断是不是SELECT操作
BoundSql boundSql = (BoundSql) metaObject.getValue("delegate.boundSql");
String mapperdId = getMapperId(mappedStatement);
Throwable throwable = new Throwable();
String sqlCommandTypePre = mapperdId + " ";
String peek0 = ServiceAop.peek();
if (StringUtils.isNotBlank(peek0)) {
StackTraceElement[] stackTraceElements = throwable.getStackTrace();
String classInfos[] = peek0.split(":");
int i = 0;
for (StackTraceElement stackTraceElement : stackTraceElements) {
i++;
if (stackTraceElement.getClassName().equals(classInfos[0]) && stackTraceElement.getMethodName().equals(classInfos[1])) {
String className = stackTraceElement.getClassName();
int lastIndexOf = className.lastIndexOf(".");
className = className.substring(lastIndexOf + 1);
sqlCommandTypePre = className + ":" + stackTraceElement.getLineNumber() + ":" + mapperdId + " ";
break;
}
if (i > 100) {
break;
}
}
}
Configuration configuration = mappedStatement.getConfiguration();
String sql = showSql(configuration, boundSql);
logger.info(sqlCommandTypePre + sql);
SInfo sInfo = new SInfo(null, sql, new Date(), ch.qos.logback.classic.Logger.inheritableThreadLocalNo.get(), Constants.suffix,System.nanoTime(),mappedStatement.getKeyProperties());
rabbitTemplate.convertAndSend(sql_consumer, JSON.toJSONString(sInfo));
Object result = invocation.proceed();
return result;
}
}
批量数据更新拦截器代码的实现和单条数据插入拦截器原码基本一样,唯一区别就是拦截的方法不一样,批量更新拦截的方法是parameterize(),为什么呢? 因为批量更新时,调用的是BatchExecutor的doUpdate()方法,最终调用的是 handler.batch(stmt)方法进行批量更新数据。而单条数据更新调用的是SimpleExecutor的doUpdate(),最终调用的是handler.update(stmt) 进行单条数据更新,他们的共同特点都调用了 handler.parameterize(stmt)方法进行参数设置,对于单条数据插入,也会调用SimpleExecutor的doUpdate()方法,而方法的内部最终调用了handler.update(stmt)进行数据插入。
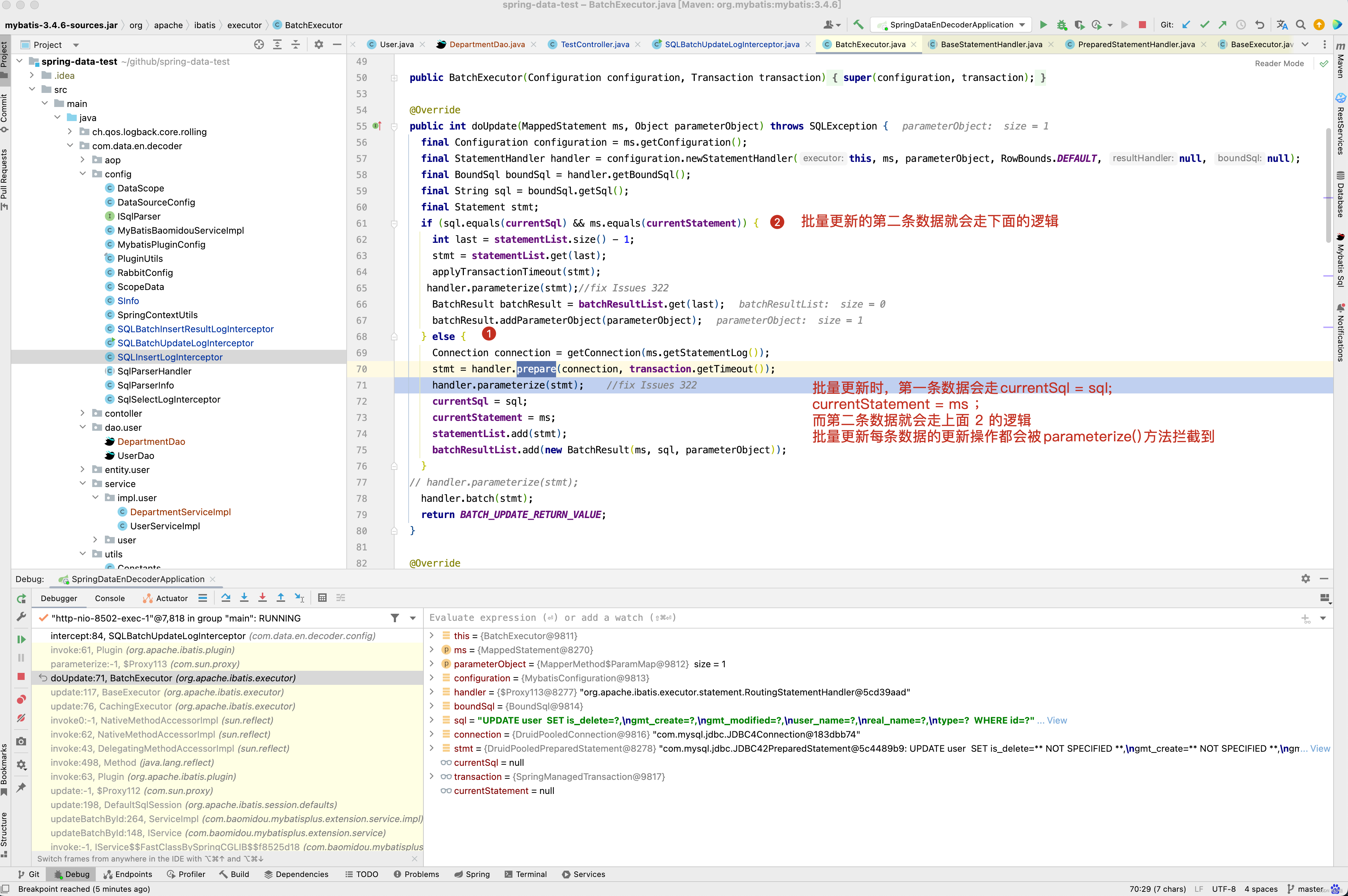
对于单条数据的插入和更新,都是会走StatementHandler的update()方法拦截器,并且也会走StatementHandler的parameterize()方法拦截器,当然,批量数据的更新目前只找到了StatementHandler的parameterize()方法拦截器,为了方便管理,对于批量数据更新和单条数据更新,目前使用的是StatementHandler的parameterize()方法拦截器,单条数据插入使用StatementHandler的update()拦截器。
先来看一个批量更新操作的例子。
// http://localhost:8502/api/test8
@RequestMapping("/test8")
public String test8() throws Exception {
User user1 = userPhoneDao.selectUserById(46l);
user1.setUserName("18199999999");
User user2 = userPhoneDao.selectUserById(47l);
user2.setUserName("18299999999");
User user3 =userPhoneDao.selectUserById(48l);
user3.setUserName("18399999999");
ListUser> users = new ArrayList>();
users.add(user1);
users.add(user2);
users.add(user3);
userPhoneService.updateBatchById(users);
return "sucess";
}
这个例子中,批量更新id为46,47,48的数据,之前的数据如下图所示 。
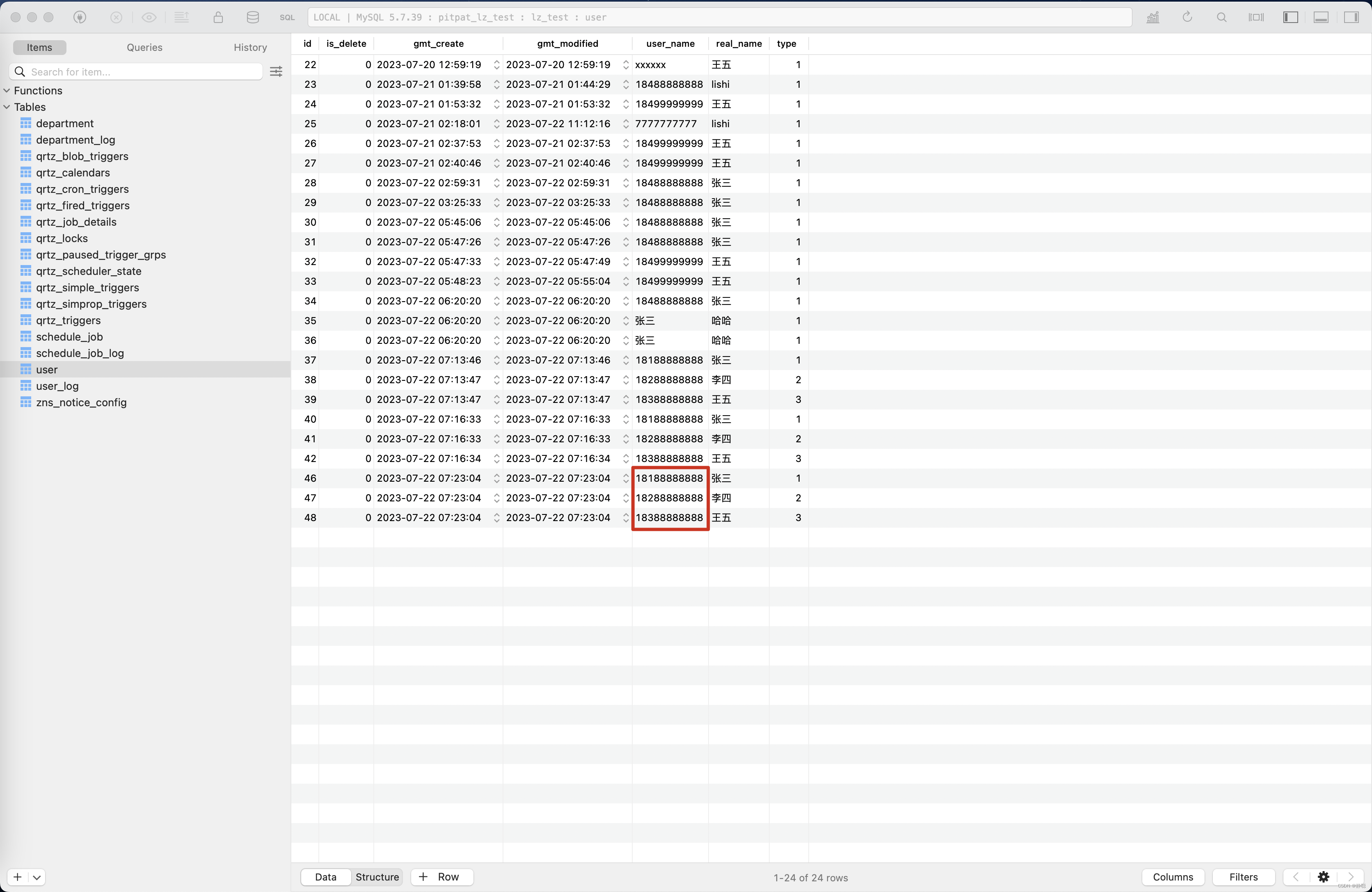
更新之后的数据如下图所示 。
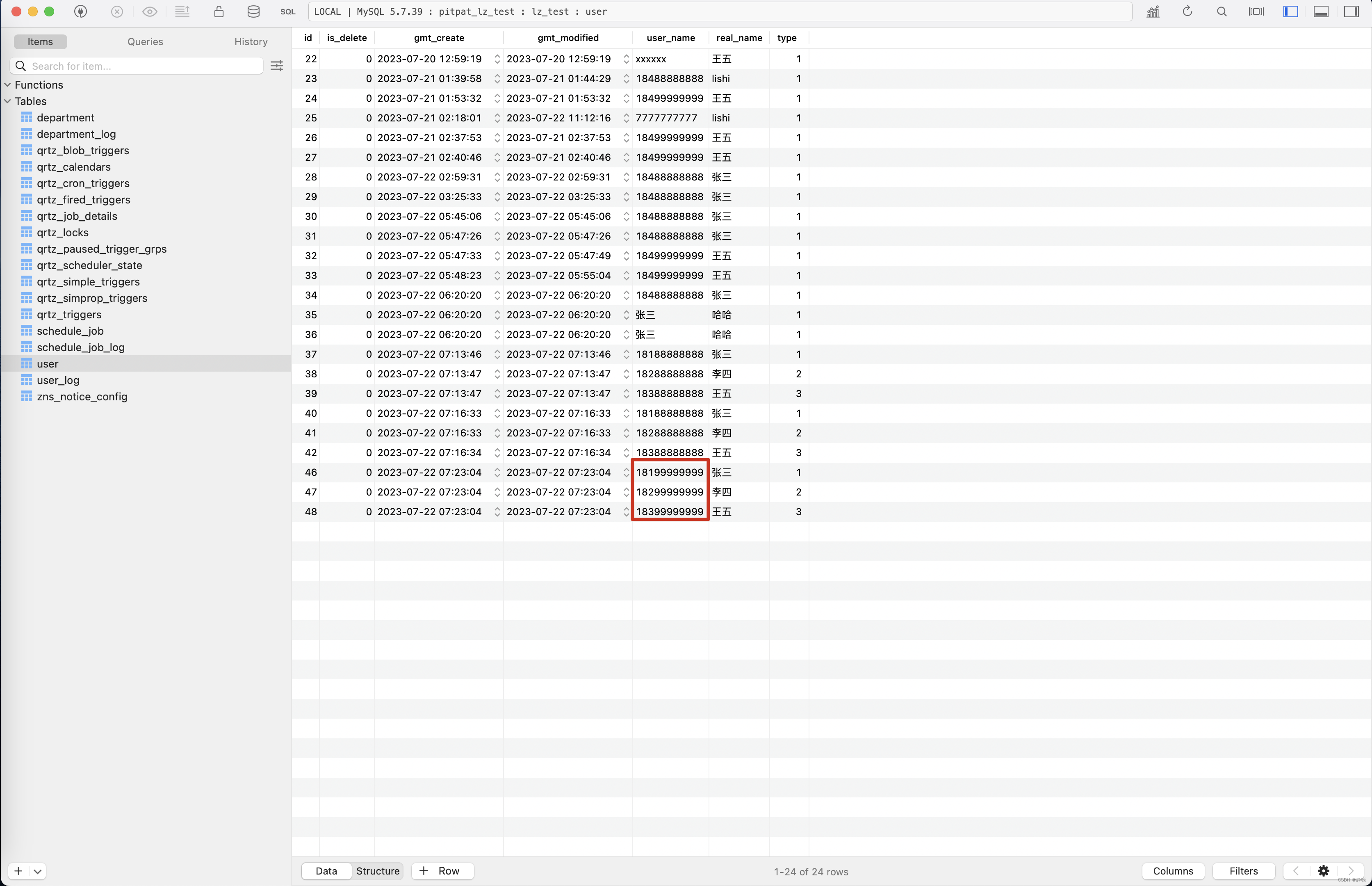
在数据库字段变更日志平台的记录又是怎样子的呢? 请看下图。
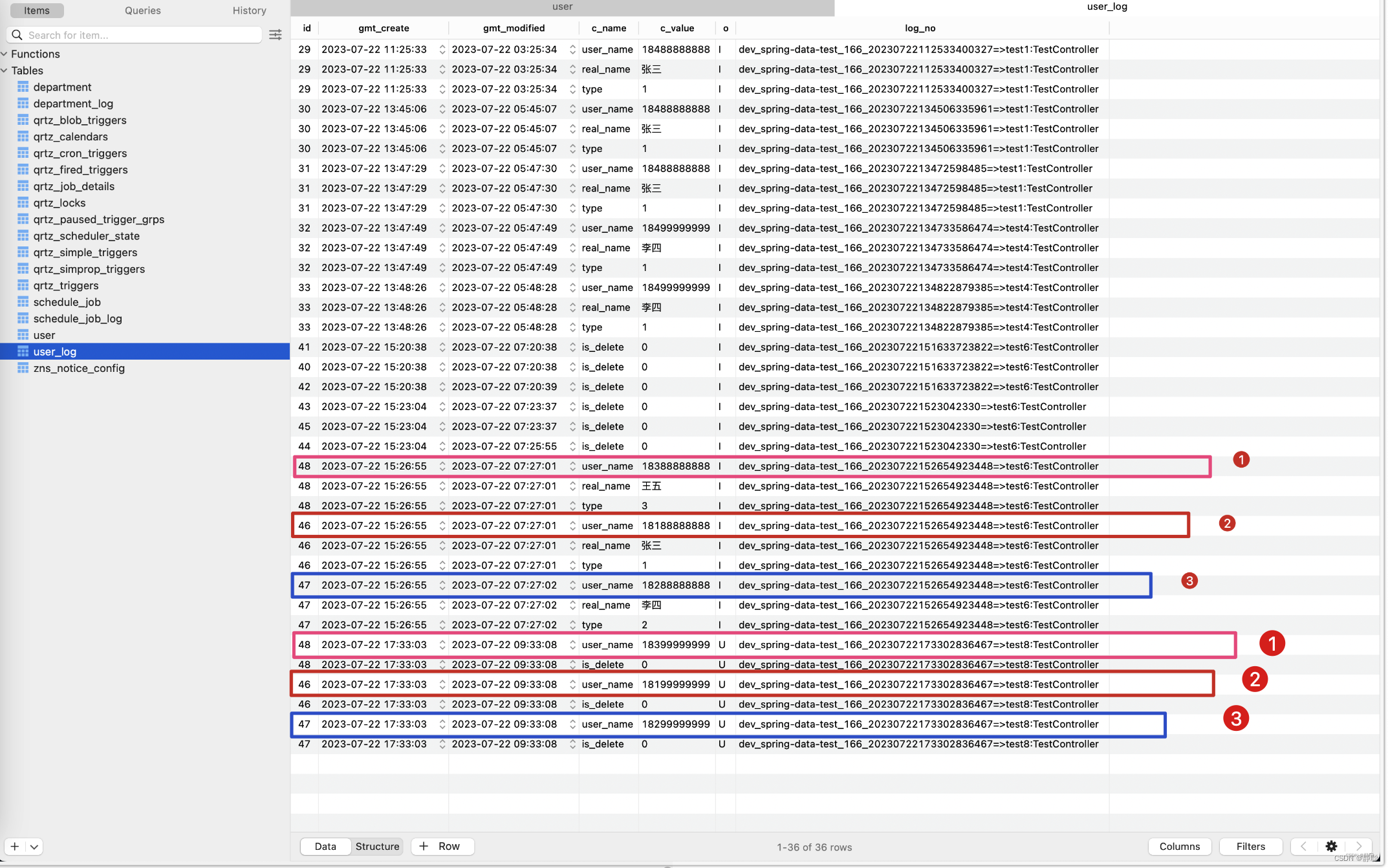
从平台上记录的结果来看,记录了每个字段变更的记录,并且都带上了日志编号 。
但大家发现没有?上面所有的插入和更新都是基于主键的,有时写SQL并不一定基于主键更新,当更新某个用户的账户金额,一般我们以userId作为更新条件,而不是以accountId作为更新条件。这种情况怎么办呢? 请先看下面例子。
###### TestController
// http://localhost:8502/api/test9
@RequestMapping("/test9")
public String test9() throws Exception {
userAccountDao.updateUserAccountByUserId(10,48);
return "sucess";
}
###### UserAccountDao.java
int updateUserAccountByUserId(@Param("account") Integer account, @Param("userId") Integer userId);
###### UserAccountDao.xml
<update id="updateUserAccountByUserId">
update user_account set account =#{account} where user_id = #{userId}
</update>
上述例子中SQL实际上为update user_account set account =10 where user_id = 48,大家发现没有?这种SQL经常用,更新用户金额一般使用userId作为更新条件,而非使用account表的Id作为更新条件。此时修改SQLBatchUpdateLogInterceptor拦截器,修改的代码如下加粗部分 :
@Intercepts({@Signature(type = StatementHandler.class, method = "parameterize", args = {Statement.class})})
public class SQLBatchUpdateLogInterceptor extends SqlParserHandler implements Interceptor {
public static final org.slf4j.Logger logger = LoggerFactory.getLogger(SQLBatchUpdateLogInterceptor.class);
@Value("${zns.config.rabbitQueue.sql_consumer}")
private String sql_consumer;
@Autowired
private RabbitTemplate rabbitTemplate;
public static final Set<String> includeBeanNames = new HashSet<>();
// 通过表名得到
public static final Map<String, String[]> tableNameKeyProperties = new HashMap<>();
@Override
public Object intercept(Invocation invocation) throws Throwable {
StatementHandler statementHandler = (StatementHandler) PluginUtils.realTarget(invocation.getTarget());
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// insert 语句的sql 在其他地方
if (SqlCommandType.INSERT.equals(mappedStatement.getSqlCommandType())
|| SqlCommandType.SELECT.equals(mappedStatement.getSqlCommandType())) {
return invocation.proceed();
}
this.sqlParser(metaObject);
// 先判断是不是SELECT操作
BoundSql boundSql = (BoundSql) metaObject.getValue("delegate.boundSql");
String mapperdId = getMapperId(mappedStatement);
Throwable throwable = new Throwable();
String sqlCommandTypePre = mapperdId + " ";
String peek0 = ServiceAop.peek();
if (StringUtils.isNotBlank(peek0)) {
StackTraceElement[] stackTraceElements = throwable.getStackTrace();
String classInfos[] = peek0.split(":");
int i = 0;
for (StackTraceElement stackTraceElement : stackTraceElements) {
i++;
if (stackTraceElement.getClassName().equals(classInfos[0]) && stackTraceElement.getMethodName().equals(classInfos[1])) {
String className = stackTraceElement.getClassName();
int lastIndexOf = className.lastIndexOf(".");
className = className.substring(lastIndexOf + 1);
sqlCommandTypePre = className + ":" + stackTraceElement.getLineNumber() + ":" + mapperdId + " ";
break;
}
if (i > 100) {
break;
}
}
}
Configuration configuration = mappedStatement.getConfiguration();
String sql = showSql(configuration, boundSql);
logger.info(sqlCommandTypePre + sql);
String[] keyProperties = mappedStatement.getKeyProperties();
// 批量更新,或非主键更新,此时keyProperties的值可能为空
if (keyProperties == null || keyProperties.length == 0) {
// 新建 MySQL Parser
SQLStatementParser parser = new MySqlStatementParser(sql);
parser.getExprParser();
// 使用Parser解析生成AST,这里SQLStatement就是AST
SQLStatement statement = parser.parseStatement();
// 使用visitor来访问AST
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statement.accept(visitor);
// 从visitor中拿出你所关注的信息
Collection<TableStat.Column> list = visitor.getColumns(); // 解析SQL
if (list != null && list.size() > 0) {
Iterator<TableStat.Column> iterable = list.iterator();
String tableName = iterable.next().getTable();
if (StringUtils.isNotEmpty(tableName)) {
String[] beanNames = includeBeanNames.toArray(new String[includeBeanNames.size()]);
keyProperties = getKeyProperties(beanNames, tableName);
if (keyProperties == null || keyProperties.length == 0) {
keyProperties = getKeyProperties(SpringContextUtils.applicationContext.getBeanDefinitionNames(), tableName);
}
// 已经拿到主键
if (keyProperties != null && keyProperties.length > 0) {
String newSql = sql.toUpperCase(); // 将SQL转化为大写
int index = newSql.indexOf("WHERE");
if (index > 0) {
String sqlPrefix = sql.substring(0, index); // SQL前缀
String sqlSuffix = newSql.substring(index + 5);
boolean containsPrimaryKey = true; //是否SQL中包含主键
for(String key :keyProperties){
boolean contains = containsPrimaryKey(sqlSuffix, key);
if(!contains){
containsPrimaryKey = false;
break;
}
}
Connection connection = null;
if(!containsPrimaryKey){ //如果不包含主键
Object object = realTarget(invocation.getArgs()[0]);
MetaObject metaObjectResult = SystemMetaObject.forObject(object);
if ("JDBC42PreparedStatement".equals(object.getClass().getSimpleName())) {
connection = (Connection) metaObjectResult.getValue("connection");
} else if ("DruidPooledPreparedStatement".equals(object.getClass().getSimpleName())) {
connection = (Connection) metaObjectResult.getValue("conn");
}
String subSql = "select * from (select * from " + tableName + " where " + sqlSuffix + ") a limit 200";
log.info("subSql = " + subSql);
try (java.sql.PreparedStatement stmt = connection.prepareStatement(subSql)) {
try (ResultSet rs = stmt.executeQuery()) {
while (rs.next()) {
StringBuffer sbSql = new StringBuffer(sqlPrefix).append(" ").append("where").append(" ");
for (int i = 0; i < keyProperties.length; i++) {
String k = keyProperties[i];
sbSql.append(k).append("=").append(rs.getObject(k));
if (i < keyProperties.length - 1) {
sbSql.append(" ").append("and").append(" ");
}
}
// 自己拼SQL
log.info("自己拼SQL 为 " + sbSql.toString());
SInfo sInfo = new SInfo(null, sbSql.toString(), new Date(), ch.qos.logback.classic.Logger.inheritableThreadLocalNo.get(), Constants.suffix, System.nanoTime(), keyProperties);
rabbitTemplate.convertAndSend(sql_consumer, JSON.toJSONString(sInfo));
}
}
}catch (Exception e) {
log.error(" getObject 异常", e);
}
}else{
SInfo sInfo = new SInfo(null, sql, new Date(), ch.qos.logback.classic.Logger.inheritableThreadLocalNo.get(), Constants.suffix, System.nanoTime(), keyProperties);
rabbitTemplate.convertAndSend(sql_consumer, JSON.toJSONString(sInfo));
}
}
}
}
}
} else {
SInfo sInfo = new SInfo(null, sql, new Date(), ch.qos.logback.classic.Logger.inheritableThreadLocalNo.get(), Constants.suffix, System.nanoTime(), keyProperties);
rabbitTemplate.convertAndSend(sql_consumer, JSON.toJSONString(sInfo));
}
Object result = invocation.proceed();
return result;
}
}
主要改动代码如上图加粗部分,如自己在XML中写一条update user_account set account =#{account} where user_id = #{userId} 这样的SQL,mappedStatement是无法获取主键信息的,因此需要解析SQL得到更新的表名,从Spring中容器中获取Mapper类的工厂Bean,再从工厂Bean中获取到Mapper类的Class信息,再找到Class类的所有实现接口的泛型类型是否有TableName注解,如果有TableName注解,取出TableName中的值与解析SQL得到的表名比对,如果相等,则找到了SQL中被更新的表名对应的实体类型,从实体类中取出属性中配置了TableId注解的value值即为表对应的主键。 拿到主键后,如果SQL where 关键字后面的内容有 “主键=” 的内容,则证明是基于主键更新的,直接将SQL传输到数据库字段变更监控平台即可,如update user_account set account =#{account} where user_id = #{userId} 这条SQL,user_account表的主键为id ,在where 语句后面没有 id = 字符串,是基于非主键更新,因此需要先查出主键id,再向平台中传输SQL日志,如这个例子中, 先执行select * from (select * from user_account where user_id = #{userId} ) a limit 200,先找到主键id的值, 再拼装出update user_account set account =#{account} where id= #{id} SQL传输到我们监控平台,但上面加了一个limit 200,当然200这个值是可以配置的,主要目的是,如果select * from user_account where user_id = #{userId} SQL 查询出的行比较多,如10万条,一次性加载那么多条数据对平台的压力也比较大,同时对于这种批量更新字段全部记录下来无意义,因此这个值可以根据自己业务情况去调整。
当然请看刚刚那个例子的执行效果 。
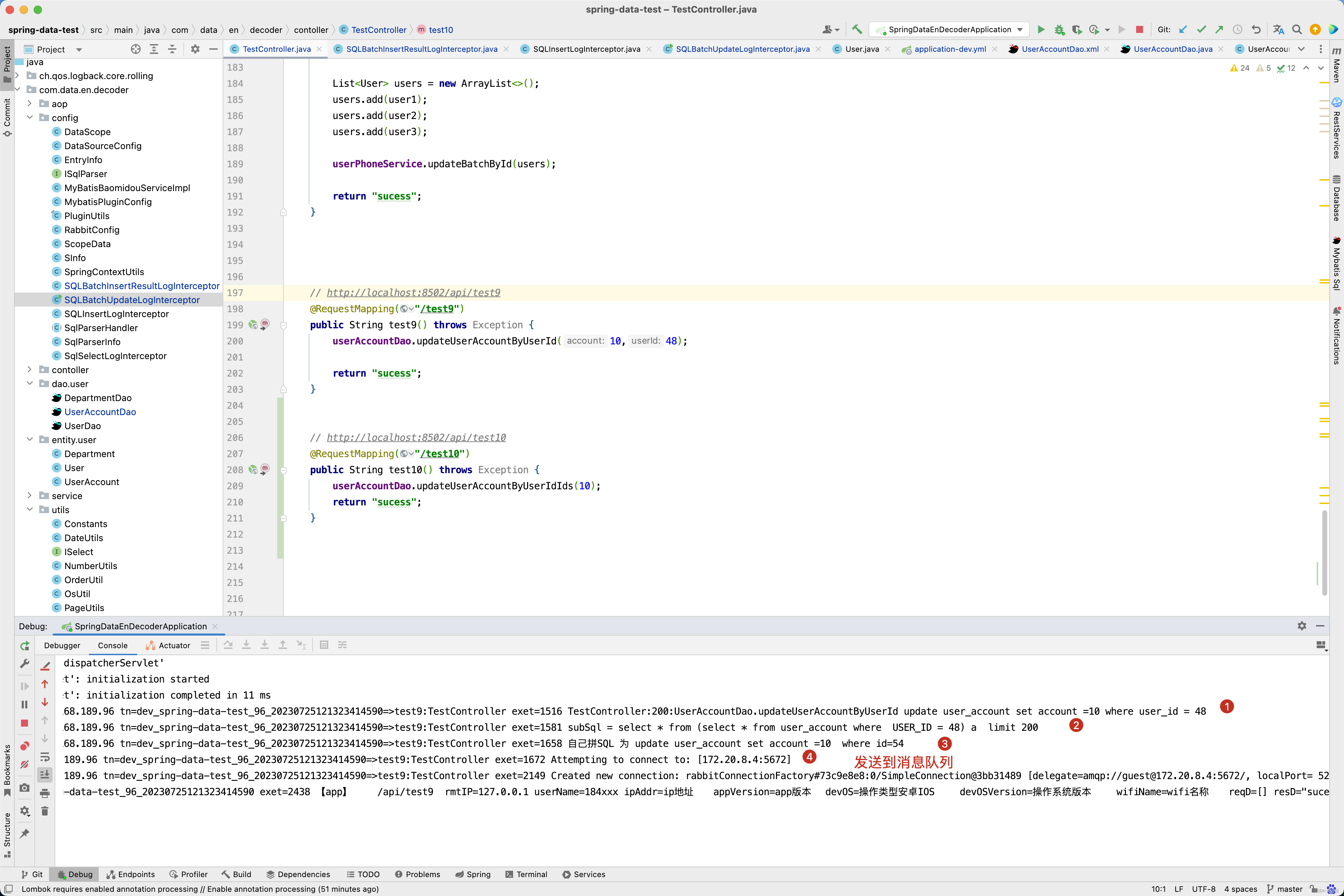
当然有人会想,我的SQL可能更加复杂一点,如 update user_account set account =#{account} where user_id in (select id from user where id in (46,47,48)), 你也能解决吗?
当然user_account的数据如下 。
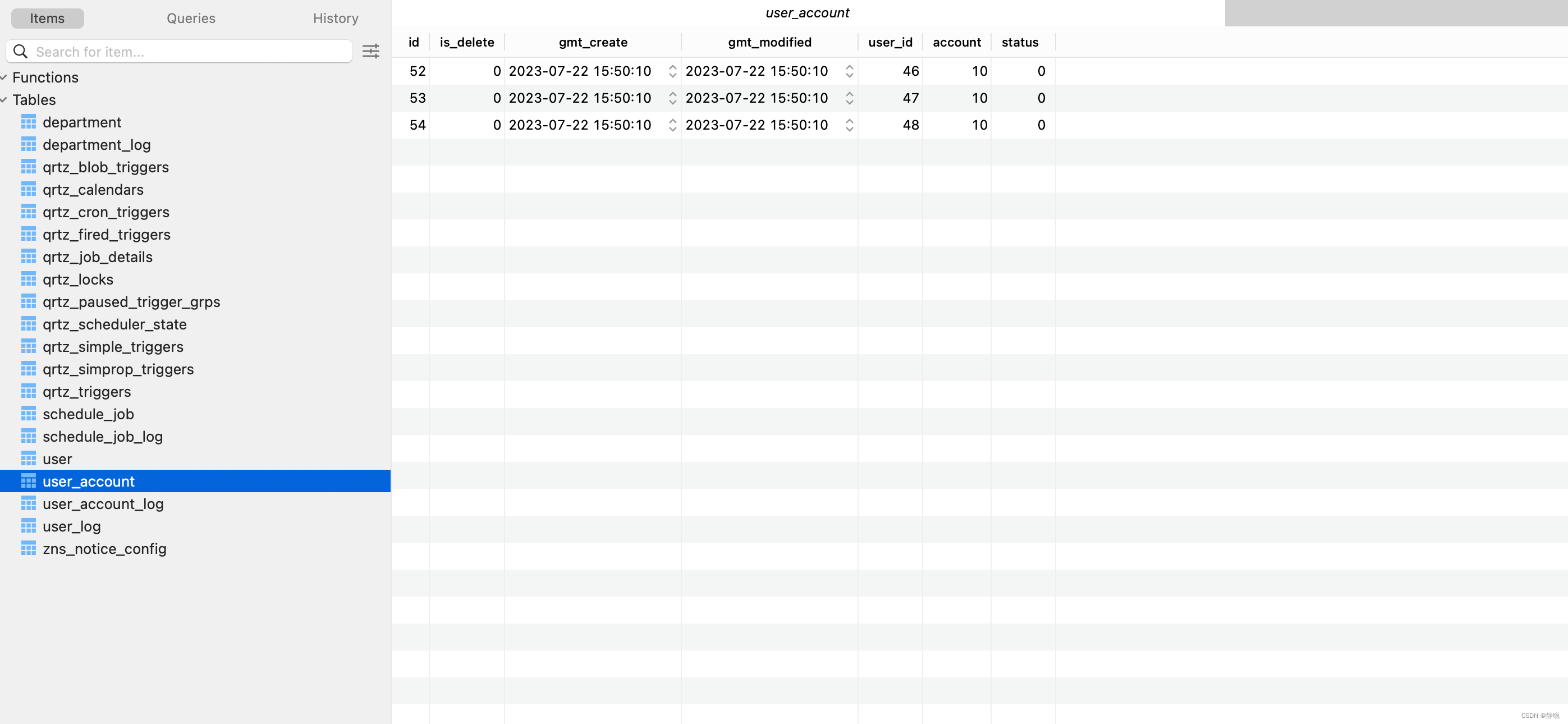
select id from user where id in (46,47,48)的执行结果如下。
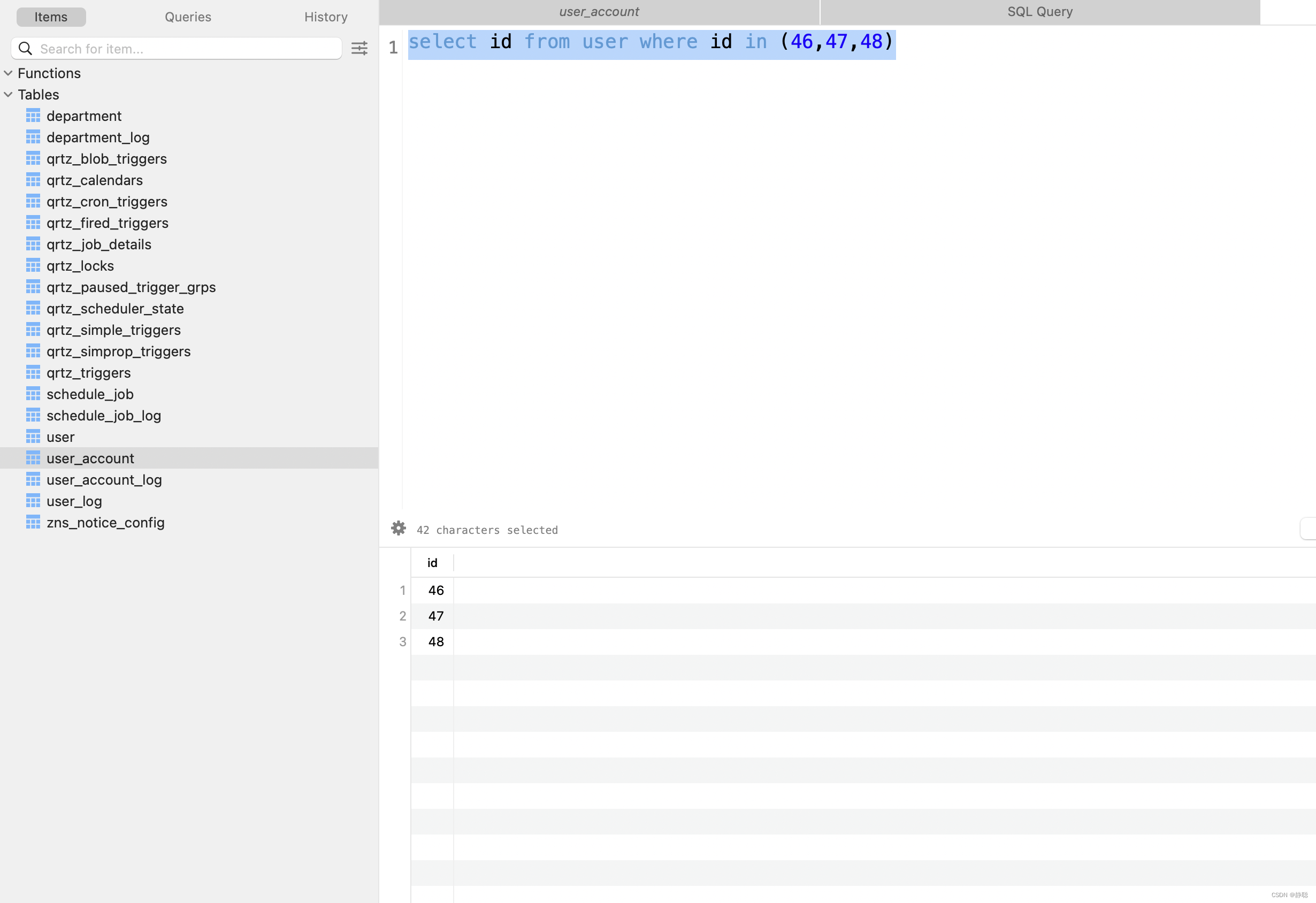
因此执行update user_account set account =#{account} where user_id in (select id from user where id in (46,47,48))这一条SQL传输到数据库字段变更记录平台的内容如下。
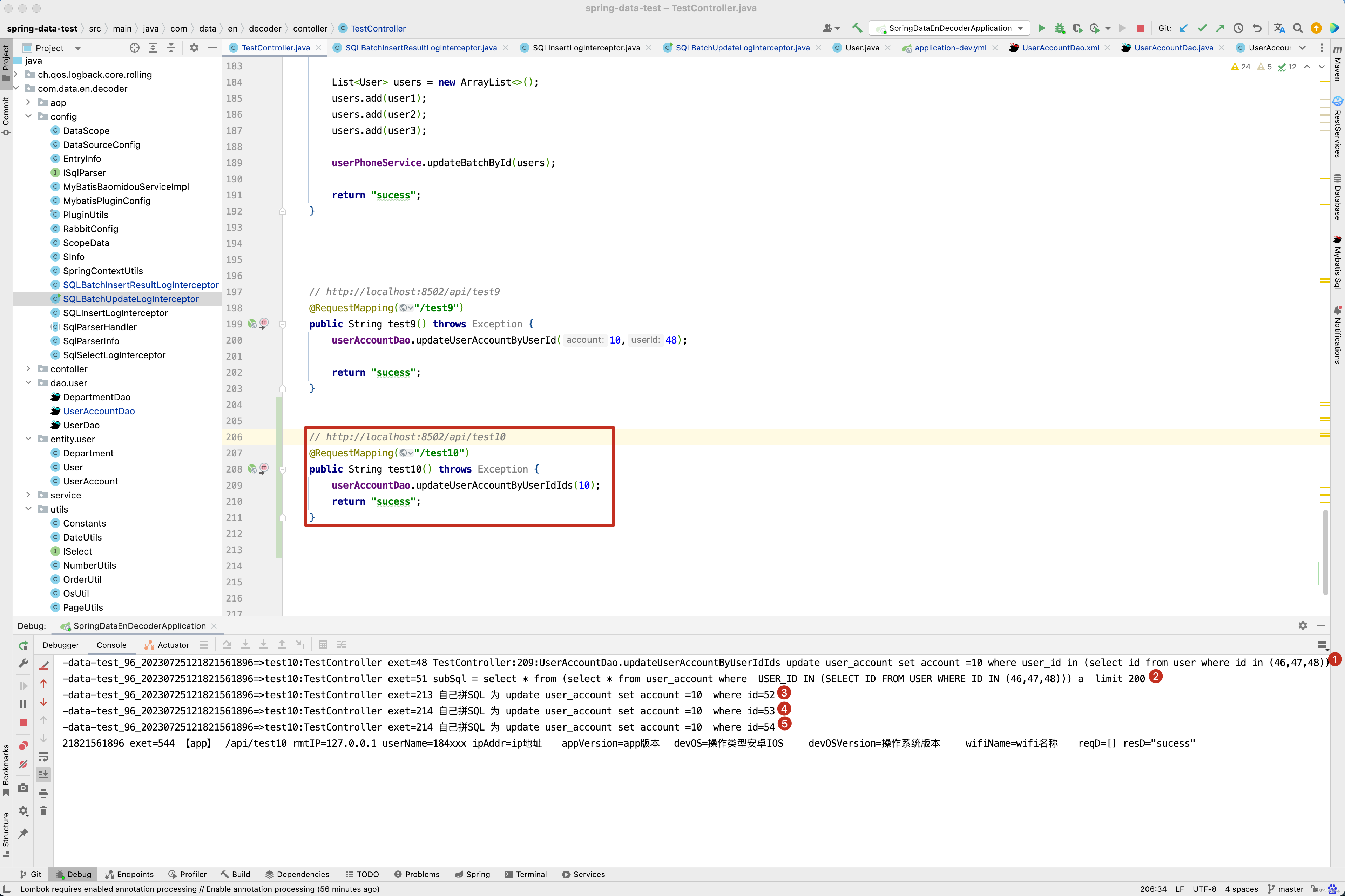
关于SQL采集部分的源码就分析到这里了,接下来看数据库字段变更监控平台代码实现。
数据库字段变更监控平台
在数据库字段变更记录平台的pom.xml文件中引入了一个jar包。
<dependency>
<groupId>com.lala.druid</groupId>
<artifactId>sql-value-parse</artifactId>
<version>3.0-SNAPSHOT</version>
</dependency>
当然,包源码地址为https://gitee.com/quyixiao/sql-value-parse.git,这个包有什么用呢?这个包的主要用途就是解析SQL,将SQL中字段和值解析出来。
public class Test {
public static String printSql (String sql){
// 新建 MySQL Parser
SQLStatementParser parser = new MySqlStatementParser(sql);
// 使用Parser解析生成AST,这里SQLStatement就是AST
SQLStatement statement = parser.parseStatement();
// 使用visitor来访问AST
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statement.accept(visitor);
// 从visitor中拿出你所关注的信息
Collection<TableStat.Column> list = visitor.getColumns();
List<Cell> header = new ArrayList<Cell>() {{
add(new Cell("tableName"));
add(new Cell("column"));
add(new Cell("select"));
add(new Cell("where"));
add(new Cell("join"));
add(new Cell("groupBy"));
add(new Cell("having"));
add(new Cell("attributes"));
add(new Cell("fullName"));
add(new Cell("primaryKey"));
add(new Cell("unique"));
add(new Cell("dataType"));
add(new Cell("value"));
}};
List<List<Cell>> body = new ArrayList<List<Cell>>();
for(TableStat.Column column: list){
List<Cell> cells = new ArrayList<Cell>();
cells.add(new Cell(column.getTable()));
cells.add(new Cell(column.getName()));
cells.add(new Cell(column.isSelect() + ""));
cells.add(new Cell(column.isWhere() +""));
cells.add(new Cell(column.isJoin() +""));
cells.add(new Cell(column.isGroupBy()+""));
cells.add(new Cell(column.isHaving()+""));
cells.add(new Cell(JSON.toJSONString(column.getAttributes())));
cells.add(new Cell(column.getFullName() +""));
cells.add(new Cell(column.isPrimaryKey() +""));
cells.add(new Cell(column.isUnique() +""));
cells.add(new Cell(column.getDataType() +""));
cells.add(new Cell(column.getValue() +""));
body.add(cells);
// System.out.println(JSON.toJSONString(column));
}
String a = new ConsoleTable.ConsoleTableBuilder().addHeaders(header).addRows(body).build().toString();
System.out.println(a);
return a;
}
@org.junit.Test
public void test1(){
String sql = "UPDATE user set username='张三' WHERE id = 69" ;
printSql(sql);
}
}
先来看UPDATE user set username=‘张三’ WHERE id = 69 这条SQL的解析。 从下图中可以看出,最终解析得到username=‘张三’, id = 69,而我们知道主键为id,从而得出结论此次SQL被更新的字段为username 。
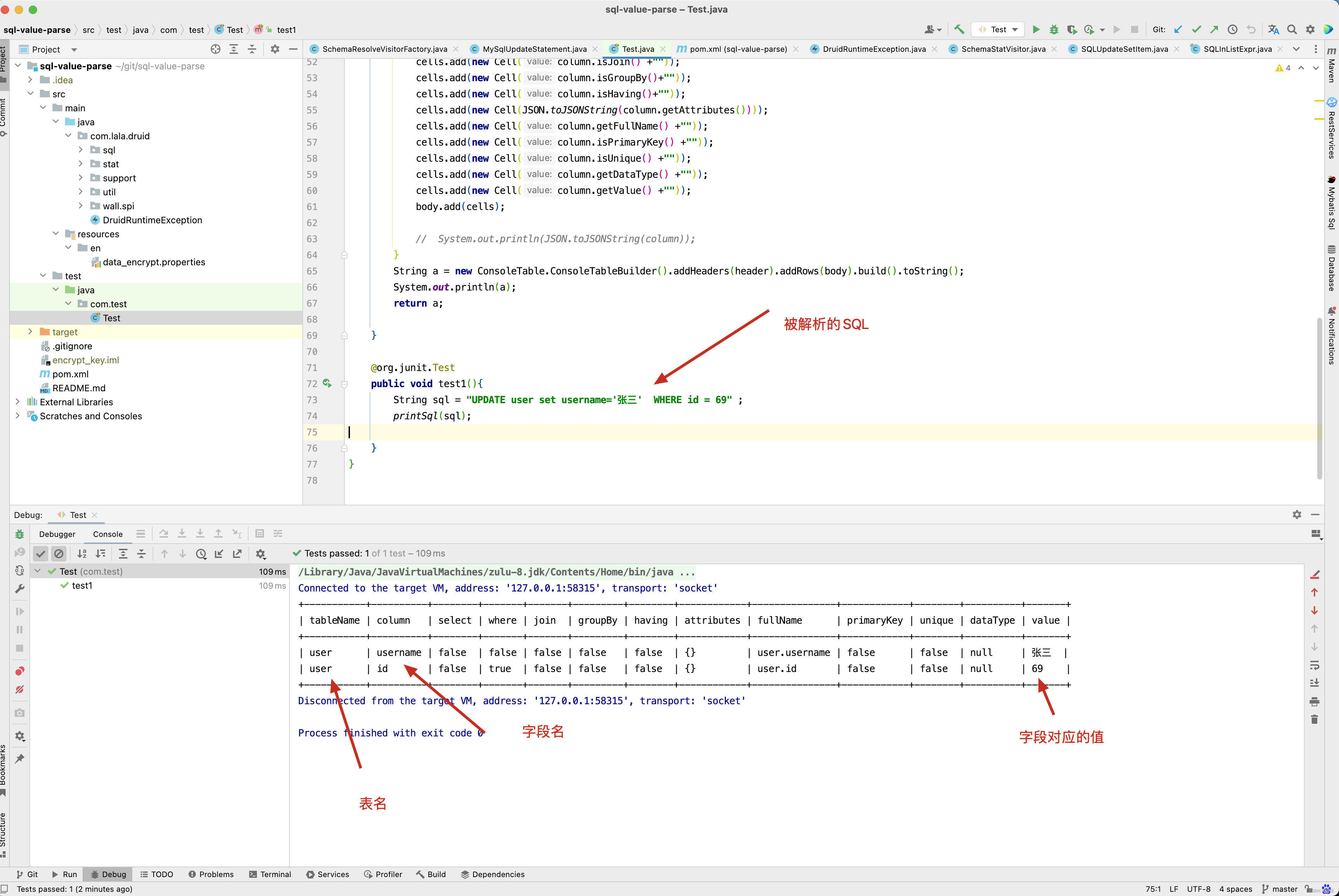
复杂的SQL也能正确解析,如UPDATE user set username=‘张三’, password = ‘123456’ WHERE id = 69 ,聪明的你可以拿着你们业务代码的SQL来偿试解析,肯定也是对的。
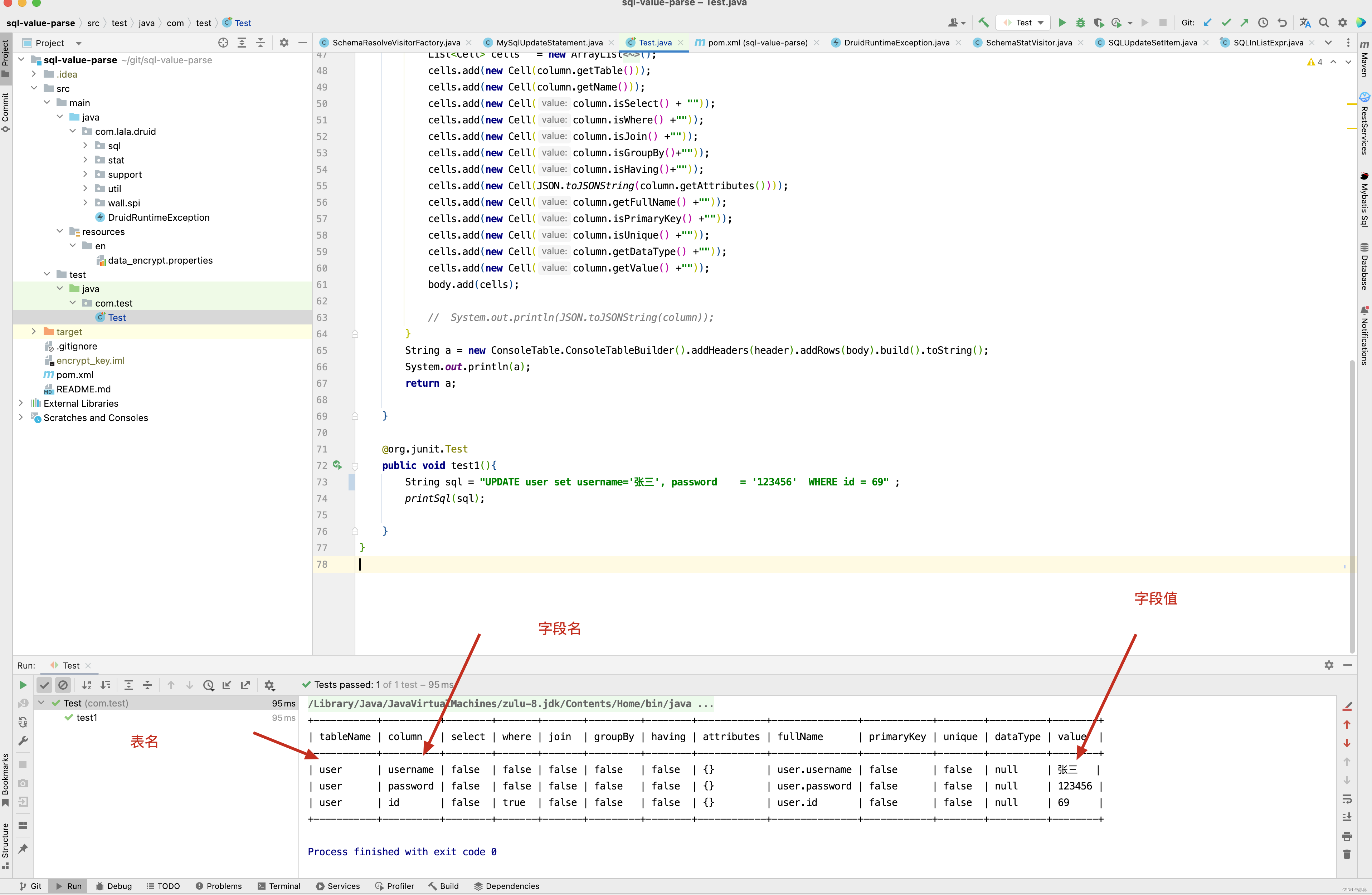
接下来看插入SQL的解析情况 。 如 INSERT INTO user_account ( is_delete, gmt_create, gmt_modified, user_id, account, status) VALUES
( 0, ‘2023-07-22 15:50:10’, ‘2023-07-22 15:50:10’, 48, 10, 0); SQL ,解析结果如下 。
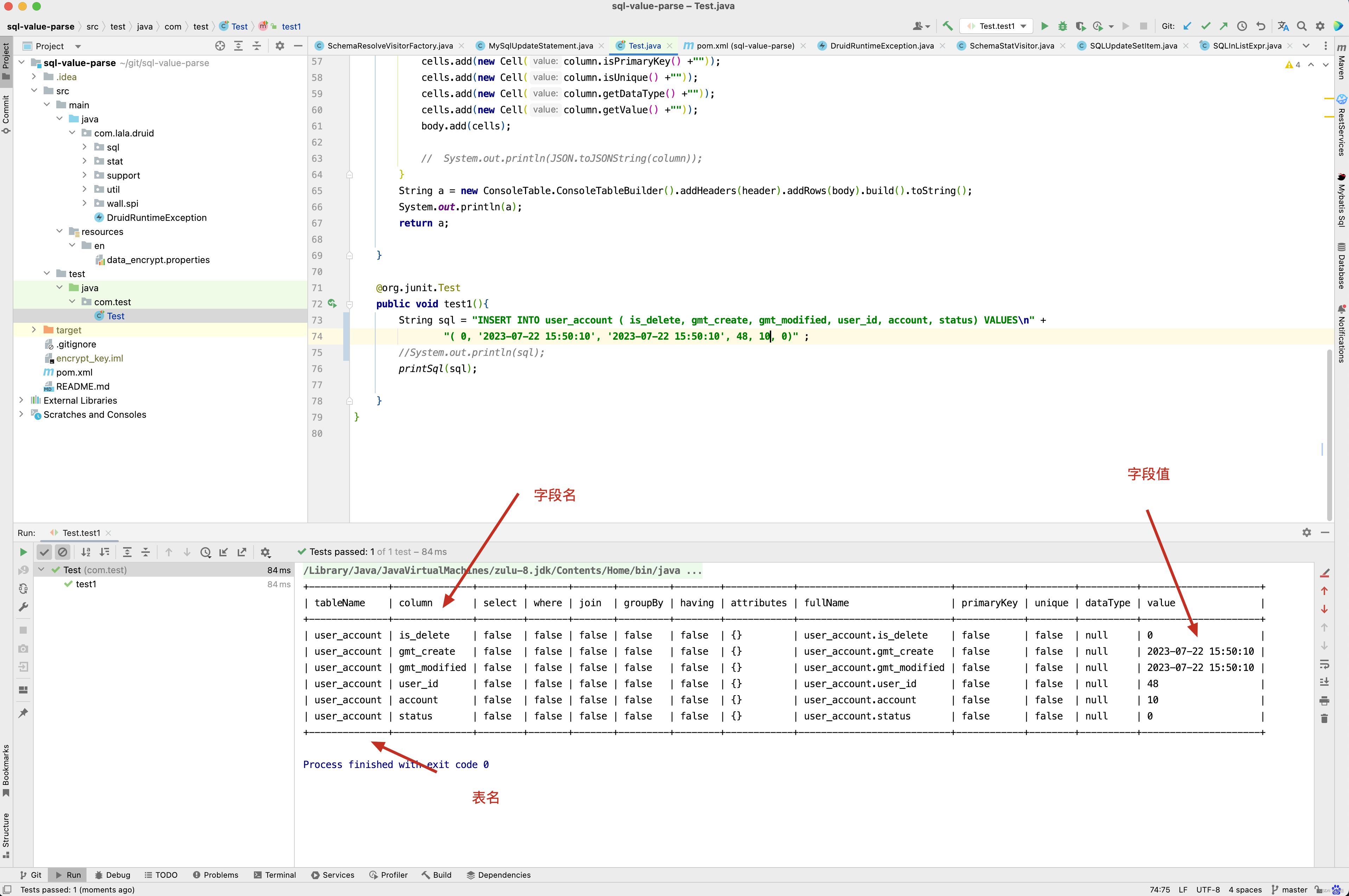
有了SQL解析包,接下来代码实现逻辑就简单了,当然这个SQL字段解析包是我修改druid包得到的,如果有兴趣可以自己去下载源码下来研究,这里就不做过多赘述。
消息队列消费采用到的SQL日志
@RabbitHandler
@RabbitListener(queues = "#{sqlConsumerQueue.name}", containerFactory = "sqlConsumerRabbitListenerContainerFactory")
public void receive(@Payload String jsonStr, @Header(AmqpHeaders.DELIVERY_TAG) long delivertTag, Channel channel) {
try {
OrderUtil.addLogNo();
SInfo sInfo = JSONObject.parseObject(jsonStr,SInfo.class );
znsNoticeConfigService.createOrUpdateTable(sInfo);
} catch (Exception e) {
log.error("BorrowProtocolListener receive error." + jsonStr, e);
}finally {
try {
channel.basicAck(delivertTag, true);
} catch (IOException e) {
log.error("消息确认异常 jsonStr = " + jsonStr, e);
}
OrderUtil.removeLogNo();
}
}
最终调用了createOrUpdateTable()方法对SQL的解析,数据比对和插入操作。
public void createOrUpdateTable(SInfo sqlInfo) {
String data_source = "";
try {
JdbcTemplate jdbcTemplate = SpringContextUtils.getBean(JdbcTemplate.class);
data_source = jdbcTemplate.getDataSource().getConnection().getCatalog();
} catch (SQLException e) {
log.error("异常", e);
}
// 第一步
// 新建 MySQL Parser
SQLStatementParser parser = new MySqlStatementParser(sqlInfo.getSql());
parser.getExprParser();
// 使用Parser解析生成AST,这里SQLStatement就是AST
SQLStatement statement = parser.parseStatement();
// 使用visitor来访问AST
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statement.accept(visitor);
// 从visitor中拿出你所关注的信息
Collection<TableStat.Column> list = visitor.getColumns();
if (list == null || list.size() == 0) {
log.info("createOrUpdateTable list 为空 " + JSON.toJSONString(sqlInfo));
return;
}
String tableName = "";
Map<String, String> columnMap = new HashMap<>();
List<String> ids = new ArrayList<>();
// 如果存在多个主键,需要先从SQL解析出来主键值先存储到columIds中
// 再用下划分分割
List<String> columIds = new ArrayList<>();
// 2.如果从业务端采集到的SQL时,调用MappedStatement的getKeyProperties()没有获得主键信息,则默认设置主键为id
String keys [] = sqlInfo.getKeyProperties();
if(keys == null || keys.length ==0){
keys = new String[]{"id"};
}
List<String> keyProperties = Arrays.asList(keys);
for (TableStat.Column column : list) {
tableName = column.getTable(); // 获取表名
if (keyProperties.contains(column.getName())) { // 去除主键id
String idStr = column.getValue() + "";
if (idStr.contains(",")) { // sql为 update zns_user set status = 1 where id in (10,20,30) 。如果id 以 , 分隔
String idString[] = idStr.split(",");
for (String idxx : idString) {
ids.add(idxx);
}
} else {
columIds.add(idStr);
}
} else {
// 本次非主键,插入或更新的字段及其值保存到columnMap中
if (column.getValue() != null && StringUtil.isNotBlank(column.getValue() + "")) {
columnMap.put(remove(column.getName()), column.getValue() + "");
}
}
}
// 如果是插入操作,在采集SQL时,主键就保存到了sqlInfo对象中。
// 如果是更新操作,主键值需要从更新中SQL中获取
if (sqlInfo.getId() != null) { // 插入操作
ids.add(sqlInfo.getId());
}else{ //更新操作
StringBuffer tempId = new StringBuffer();
// 表中存在多个主键的情况,主键之间以_分割
for(int i = 0 ; i < columIds.size() ;i ++){
tempId.append(columIds.get(i));
if(i < columIds.size() -1 ){
tempId.append("_");
}
}
ids.add(tempId.toString());
}
// 批量插入
for (String id : ids) {
if (StringUtil.isBlank(tableName) || StringUtil.isBlank(id)) {
log.info("createOrUpdateTable 表名或id为空 " + JSON.toJSONString(sqlInfo));
continue;
}
Node node = new Node(id, sqlInfo.getNanoTime(), tableName, sqlInfo, columnMap, data_source);
delay.put(node); //向延迟队列中添加节点信息
}
}
我们来逐一分析上面这个方法的用意 。
- 第一步解析SQL 。
- 将主键和非主键对应的键值分开,并将非主键信息存储到Map中去。
- 将主键和非主键Map加入到延迟队列中去。
大家可能感觉非常好奇,为什么我要将解析得到的数据放入到延迟队列中去? 而不是直接与数据库中的值进行比对,将变更的字段保存到数据库中即可。
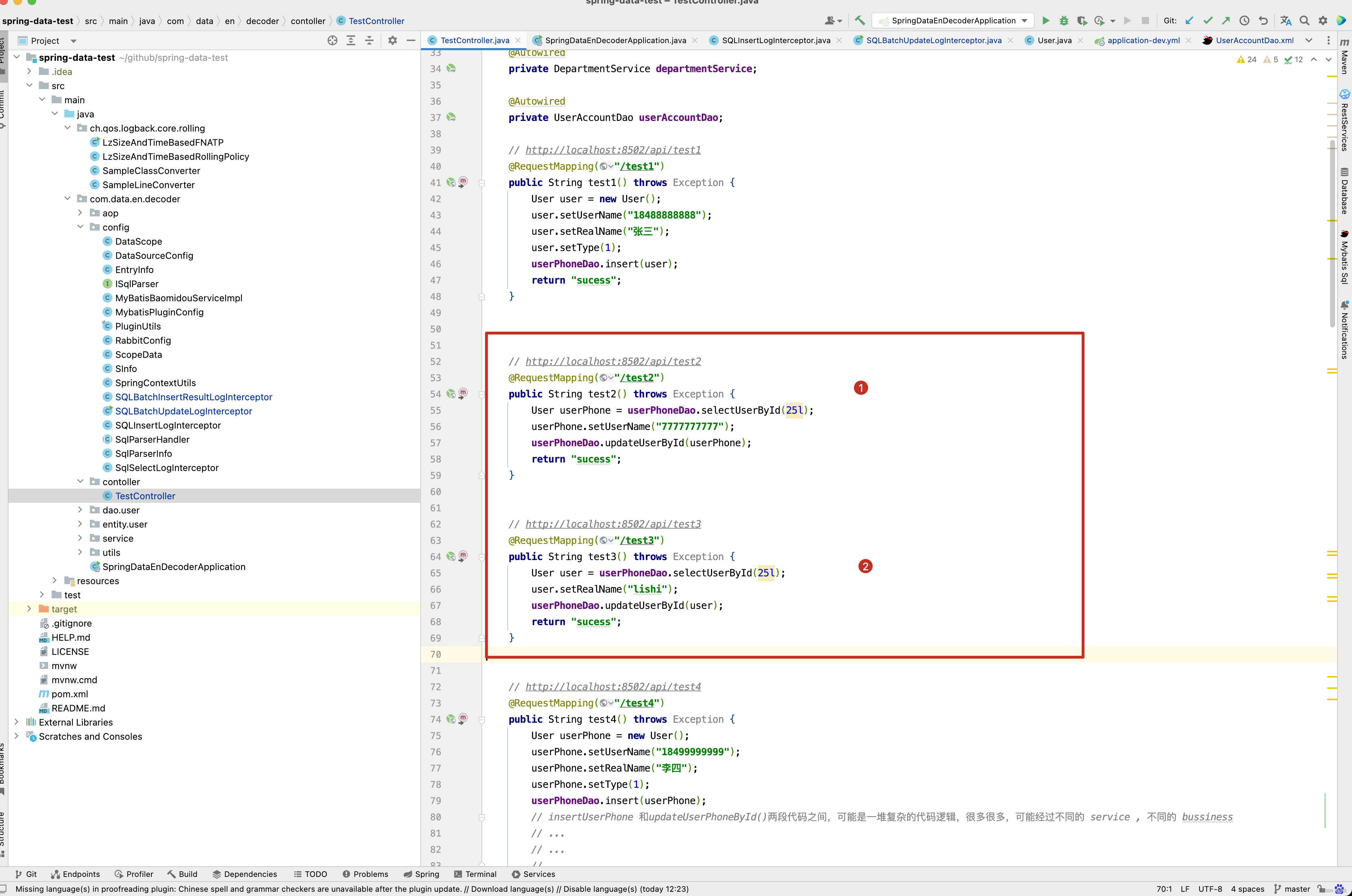
如上图中,test2()和test3()方法,假如几乎同时执行,但test2()方法执行更新语句比test3()方法执行更新语句要快几毫秒,这两条SQL的更新几乎同时被放入到消息队列中去,因为消息队列消费的无序性,可能存在test3()的更新语句比test2()先消费的情况,此时就出现记录数据不正确的情况,因此在SQL采集时,在SInfo对象中,添加了一个属性,如下图所示 ,SQL 执行时时间的纳秒值。
这个属性有什么用呢?请看延迟队列代码的实现逻辑 。
@Override
public void run() {
for (; ; ) {
try {
Node node = delay.take();
List<Node> nodes = new ArrayList<>();
nodes.add(node);
int spaceCount = 0;
for (int i = 0; i < 500; i++) {
Node pollNode = delay.poll();
if (pollNode != null) {
nodes.add(pollNode);
} else {
spaceCount++;
Thread.sleep(30);
}
if (spaceCount >= 3) {
break;
}
}
Map<String, List<Node>> mapNode = new HashMap<>();
for (Node n : nodes) {
List<Node> nodes1 = mapNode.get(n.getId() + "");
if (nodes1 == null) {
nodes1 = new ArrayList<>();
}
nodes1.add(n);
if (nodes1.size() > 1) {
Collections.sort(nodes1);
}
mapNode.put(n.getId() + "", nodes1);
}
if (mapNode.size() > 0) {
//在线程池执行之前,给计数器指定数值(与要执行代码的次数一致)也就是 mapNode.size()
CountDownLatch countDownLatch = new CountDownLatch(mapNode.size());
log.info("countDownLatch长度是" + mapNode.size());
for (Map.Entry<String, List<Node>> nodeEntry : mapNode.entrySet()) {
//模拟对数据信息进行二次处理
executor.submit(() -> {
try {
List<Node> nList = nodeEntry.getValue();
for (int i = 0 ;i < nList.size() ;i ++) {
Node n = nList.get(i);
insert(n.getTableName(), n.getId(), n.getSqlInfo(), n.getColumnMap(), n.getData_source(),i);
}
} catch (Exception e) {
log.error("CountDownLatch 内部异常", e);
} finally {
//每执行一次数值减少一
countDownLatch.countDown();
}
});
}
try {
//等待计数器归零
countDownLatch.await();
} catch (InterruptedException e) {
log.error(" countDownLatch.await() 异常", e);
}
}
} catch (Exception e) {
log.error("PostConstruct init 异常", e);
}
}
}
延迟队列take()到Node时,并不是立即执行,而是先收集一定量的Node数据,并将主键id相同的Node分组归类,将归类的数据依据nanoTime升序排序,再调用insert()方法,将变更的数据插入到数据库表中,这里有一点需要注意,DelayQueue 每次take()或poll()时,取到的都是时间最小Node,Node中保存有我们解析的SQL数据信息。
public void insert(String tableName, String id, SInfo sqlInfo, Map<String, String> columnMap, String data_source,int index ) {
tableName = remove(tableName);
tableName = tableName + "_" + sqlInfo.getProductName();
// 获取数据库中所有的表
if (map.size() == 0) {
String selectAllTable = "select table_name tableName FROM information_schema.TABLES WHERE table_schema = '" + data_source + "'";
log.info("=======selectAllTable======" + selectAllTable);
List<String> tables = znsNoticeConfigDao.selectListStringExeSql(selectAllTable);
for (String table : tables) {
map.put(table, 1);
}
}
Object tableInfo = map.get(tableName);
if (tableInfo == null) {
try {
// 如果表名不存在,则创建新表
String createTable = "CREATE TABLE " + tableName + " (\n" +
" id varchar(32) DEFAULT NULL,\n" +
" gmt_create datetime DEFAULT NULL COMMENT '创建时间',\n" +
" gmt_modified datetime DEFAULT NULL COMMENT '更新时间',\n" +
" c_name varchar(32) DEFAULT NULL COMMENT '列名',\n" +
" c_value text COMMENT '列值',\n" +
" o varchar(8) DEFAULT NULL COMMENT '操作类型',\n" +
" log_no text COMMENT '日志编号',\n" +
" KEY idx_id_c_name (id,c_name) USING BTREE\n" +
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4";
znsNoticeConfigDao.exeSql(createTable);
} catch (Exception e) {
log.error("创建表异常 " + JSON.toJSONString(sqlInfo), e);
} finally {
map.put(tableName, "1");
}
}
String o = sqlInfo.getId() == null ? "U" : "I";
String createTime = DateUtil.formatDate(sqlInfo.getGmtCreate(), DateUtil.DATE_TIME_PATTERN);
// 如果某些表数据量很大,并且不需要每条数据都保存,则可以使用随机的方式保存一定量的数据,方便查找问题
if (tableNameList.contains(tableName)) {
Random random = new Random();
int i = random.nextInt(1000);
if (i > 50) {
return;
}
}
log.info(tableName + " , id = " + id + ",o = " + o + ",logno = " + sqlInfo.getLogNo() + ",ignore table = " + (tableNameList.contains(tableName)) + ",i="+index);
// 有些不重要的表的插入数据,只保存一条数据即可
if ((sqlInfo.getId() != null && tableNameList.contains(tableName)) || sqlInfo.isBatch()) { //表示插入
StringBuffer sb = new StringBuffer("INSERT INTO " + tableName + " (id, gmt_create, gmt_modified, c_name, c_value, log_no,o) VALUES ");
sb.append(" (" + id + ", '" + createTime + "', now(), 'is_delete', '0', '" + sqlInfo.getLogNo() + "', '" + o + "')");
znsNoticeConfigDao.exeSql(sb.toString()); // 如果是插入,保存一条数据即可,可以节省大量的空间
} else {
// 查询出某张表每个字段的最新数据
String tableVoSql = " select c_name,c_value,gmt_create from ( select distinct(a.c_name ) tid, a.* from " + tableName + " a \n" +
" where id ='" + id + "' order by a.gmt_create desc ) tt \n" +
"group by tt.c_name ";
List<TableVo> tableVos = znsNoticeConfigDao.selectListTableVoExeSql(tableVoSql);
Map<String, String> tableMap = new HashMap<>();
for (TableVo tableVo : tableVos) {
tableMap.put(tableVo.getCName(), tableVo.getCValue());
}
StringBuffer sb = new StringBuffer("INSERT INTO " + tableName + " (id, gmt_create, gmt_modified, c_name, c_value, log_no,o) VALUES ");
boolean flag = false;
for (Map.Entry<String, String> data : columnMap.entrySet()) {
// gmt_create , gmt_modified,create_time ,modifie_time 这几个字段的变更没有意义,因此不存储
if ("gmt_create".equals(data.getKey()) || "gmt_modified".equals(data.getKey())
|| "create_time".equals(data.getKey()) || "modifie_time".equals(data.getKey()) || "id".equals(data.getKey())) {
continue;
}
String cValue = tableMap.get(data.getKey());
// 如果cValue为空或c_value 的值不相等,将发生变更的值保存到数据库中
if (StringUtil.isBlank(cValue) || !cValue.equals(data.getValue())) {
flag = true;
String value = data.getValue();
if (value.indexOf("'") >= 0) {
value = value.replaceAll("'", "''");
}
sb.append(" ('" + id + "', '" + createTime + "', now(), '" + data.getKey() + "', '" + value + "', '" + sqlInfo.getLogNo() + "', '" + o + "'),");
}
}
String b = sb.toString();
if (flag) {
b = b.substring(0, b.length() - 1);
znsNoticeConfigDao.exeSql(b);
}
}
}
上面这段代码看上去很多,但原理还是很简单的,首先检查原业务表名_log表是否存在,如果不存在,则创建该表。
CREATE TABLE 原业务表名_log ( id int(11) DEFAULT NULL, gmt_create datetime DEFAULT NULL COMMENT '创建时间', gmt_modified datetime DEFAULT NULL COMMENT '更新时间', c_name varchar(32) DEFAULT NULL COMMENT '列名', c_value text COMMENT '列值', o varchar(8) DEFAULT NULL COMMENT '操作类型,I 插入操作,U 更新操作', log_no text COMMENT '日志编号,数据变更时日志TraceId', KEY idx_id_c_name (id,c_name) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
再比对原业务库插入SQL或更新SQL的字段是否有变更,如果有,则创建插入语句,当然,有些表数据量大,并且并不需要监控其字段变更,那就随机的保存几条即可,也方便后面查询该表的数据何时插入。
当然,数据库字段变更记录平台到这里已经接近尾声,当然考虑到性能问题,我将每张表的数据按月分表,减少对平台的压力 ,定时任务代码如下
public void run() throws Exception {
JdbcTemplate jdbcTemplate = SpringContextUtils.getBean(JdbcTemplate.class);
String data_source = jdbcTemplate.getDataSource().getConnection().getCatalog();
String selectAllTable = "select table_name tableName FROM information_schema.TABLES WHERE table_schema = '"+data_source+"'";
List<String> tables = znsNoticeConfigDao.selectListStringExeSql(selectAllTable);
for(String table : tables){
if(ZnsNoticeConfigServiceImpl.tableNameDeleteList.contains(table) ||
ZnsNoticeConfigServiceImpl.tableNameList.contains(table)){
String currentMonth1 = DateUtil.formatDate(DateUtils.addDateDays(new Date(),-15), DateUtil.DATE_TIME_SHORT);
String sql = "delete from " + table + " where gmt_create < '" + currentMonth1 + "' ";
log.info("删除数据sql sql = " + sql);
znsNoticeConfigDao.exeSql(sql);
}
}
for (String table : tables) {
if (table.endsWith("_pitpat")) {
try {
String preMonth1 = DateUtil.formatDate(DateUtil.addMonths(DateUtil.getFirstOfMonth(new Date()), -1), DateUtil.DEFAULT_PATTERN_WITH_HYPHEN_);
String currentMonth1 = DateUtil.formatDate(DateUtil.getFirstOfMonth(new Date()), DateUtil.DATE_TIME_SHORT);
String preTableName = table + "_" + preMonth1;
if (!tables.contains(preTableName)) {
try {
String createTable = "CREATE TABLE " + preTableName + " (\n" + " id int(11) DEFAULT NULL,\n" + " gmt_create datetime DEFAULT NULL COMMENT '创建时间',\n" + " gmt_modified datetime DEFAULT NULL COMMENT '更新时间',\n" + " c_name varchar(32) DEFAULT NULL COMMENT '列名',\n" + " c_value text COMMENT '列值',\n" + " o varchar(8) DEFAULT NULL COMMENT '操作类型',\n" + " log_no text COMMENT '日志编号',\n" + " KEY idx_id_c_name (id,c_name) USING BTREE\n" + ") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4";
znsNoticeConfigDao.exeSql(createTable);
log.info("创建表 sql = " + createTable);
Thread.sleep(2000);
} catch (Exception e) {
log.error(" 表 " + preTableName + "创建异常", e);
}
}
String saveData = "insert into " + preTableName + " select * from " + table + " where gmt_create < '" + currentMonth1 + "' ";
znsNoticeConfigDao.exeSql(saveData);
log.info("保存数据sql = " + saveData);
String sql = "delete from " + table + " where gmt_create < '" + currentMonth1 + "' ";
log.info("删除数据sql sql = " + sql);
znsNoticeConfigDao.exeSql(sql);
} catch (Exception e) {
log.error("异常 table " + table, e);
}
}
}
}
这个代码很简单,就不再赘述了。
总结 :
到这里,数据库字段监控平台已经开发完毕 。结合之前的日志框架,几乎能监控到数据库表中每个字段的变更和代码行号之间的对应关系,查找问题的方便性就不言而喻了,聪明的你,发现这个平台存在什么隐藏的问题吗? 如果发现有,提问题给我,更希望能提供保贵的建议 ?
本文相关的git源码地址
https://gitee.com/quyixiao/pitpat_data_monitor.git
https://gitee.com/quyixiao/spring-data-test.git
https://gitee.com/quyixiao/sql-value-parse.git





![[Python] flask运行+wsgi切换生产环境+supervisor配置指南](https://img-blog.csdnimg.cn/0df4f0ff878c4a2b83ede2637f6cf659.png)


![ant design vue a-table表格中插入操作按钮(以switch开关 [a-switch]为例)](https://img-blog.csdnimg.cn/ac416a058ed94c1eb750ee89d0b1927d.png)