Java中的对象字节流是通过ObjectInputStream和ObjectOutputStream类来实现的。这两个类提供了将对象转换为字节流和将字节流转换为对象的方法。
要将一个对象转换成字节流,你需要先创建一个ObjectOutputStream对象,然后使用它的writeObject()方法将对象写入输出流中
// 创建输出流
OutputStream outputStream = new FileOutputStream("object.dat");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
// 写入对象
MyObject obj = new MyObject();
objectOutputStream.writeObject(obj);
// 关闭流
objectOutputStream.close();在这段代码中,我们创建了一个名为"object.dat"的文件输出流,然后创建了一个ObjectOutputStream对象。我们将一个自定义的MyObject对象写入了输出流中,使用writeObject()方法来实现。
如果你想将字节流转换回对象,你可以使用ObjectInputStream类
// 创建输入流
InputStream inputStream = new FileInputStream("object.dat");
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
// 读取对象
MyObject obj = (MyObject) objectInputStream.readObject();
// 关闭流
objectInputStream.close();在这段代码中,我们创建了一个名为"object.dat"的文件输入流,并通过ObjectInputStream类读取了对象字节流。在读取对象之后,我们需要将其强制转换回适当的类型(这里是MyObject)。
需要注意的是,要将一个对象转换为字节流,该对象的类必须实现Serializable接口。这个接口标记了类是可序列化的,这样对象才能被正确地转换为字节流以及从字节流转换回对象。
此外,你还要确保读取字节流的顺序和写入字节流时的顺序是一致的,否则可能会导致反序列化错误。
java序列化和反序列化的定义和优点
Serialization(序列化):将java对象以一连串的字节保存在磁盘文件中的过程,也可以说是保存java对象状态的过程。序列化可以将数据永久保存在磁盘上(通常保存在文件中)。
deserialization(反序列化):将保存在磁盘文件中的java字节码重新转换成java对象称为反序列化。
优点:
- 实现了数据的持久化,通过序列化可以把数据持久地保存在硬盘上(磁盘文件)。
- 利用序列化实现远程通信,在网络上传输字节序列。
序列化要求:
实现序列化的类对象必须实现了Serializable类或Externalizable类才能被序列化,否则会抛出异常。
实现java序列化和反序列化的三种方法:
现在要对student类进行序列化和反序列化,遵循以下方法:
方法一:若student类实现了serializable接口,则可以通过objectOutputstream和objectinputstream默认的序列化和反序列化方式,对非transient的实例变量进行序列化和反序列化。
方法二:若student类实现了serializable接口,并且定义了writeObject(objectOutputStream out)和
readObject(objectinputStream in)方法,则可以直接调用student类的两种方法进行序列化和反序列化。
方法三:若student类实现了Externalizable接口,则必须实现readExternal(Objectinput in)和writeExternal(Objectoutput out)方法进行序列化和反序列化。
JDK类库中的序列化步骤:
第一步:创建一个输出流对象,它可以包装一个输出流对象,如:文件输出流。
ObjectOutputStream out = new ObjectOutputStream(new fileOutputStream("E:\\JavaXuLiehua\\Student\\Student1.txt"));第二步:通过输出流对象的writeObject()方法写对象
out.writeObject("hollo word");
out.writeObject("happy")JDK中反序列化操作:
第一步:创建文件输入流对象
ObjectInputStream in = new ObjectInputStream(new fileInputStream("E:\\JavaXuLiehua\\Student\\Student1.txt"));第二步:调用readObject()方法
String obj1 = (String)in.readObject();
String obj2 = (String)in.readObject();为了保证正确读取数据,对象输出流写入对象的顺序与对象输入流读取对象的顺序一致。
Student类序列化和反序列化演示:
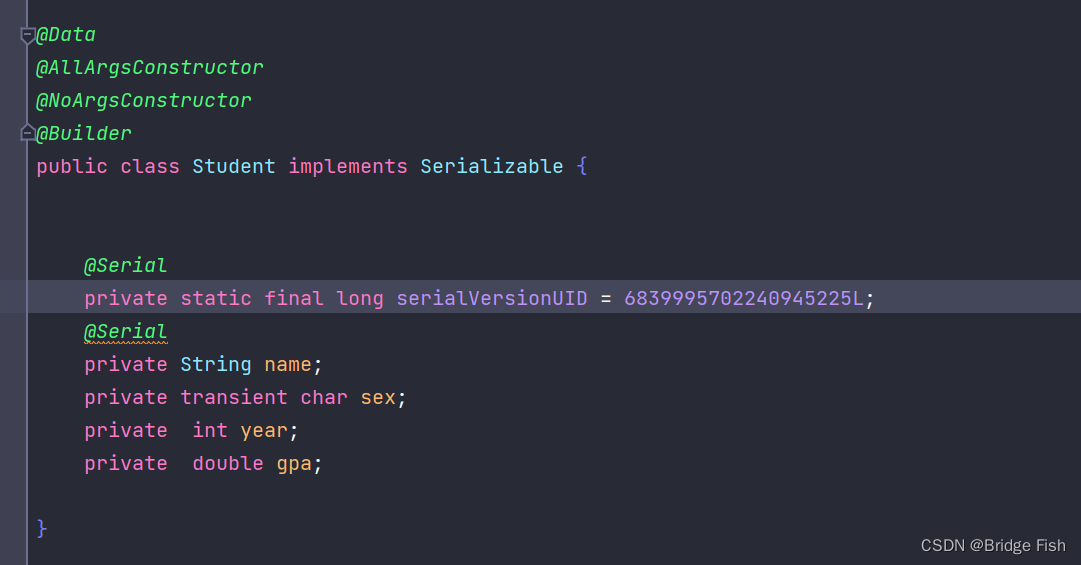
1.先创建一个继承了serializable类的student类
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serial;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class Student implements Serializable {
@Serial
private String name;
private char sex;
private int year;
private double gpa;
}
我这里用了Lombok插件,可以减少实体类冗长代码和快速生成set get方法,如有不了解的,可以参考另外一篇文章IDEA必装插件:Lombok通过注解消除实体类冗长代码以及快速生成实体的set方法的GenerateAllSetter_Bridge Fish的博客-CSDN博客
把Student类的对象序列化到txt文件(D:\\AAAAAAAAAAAA\\Student1.txt)中,并对文件进行反序列化:
import java.io.*;
public class UserStudent {
public static void main(String[] args) throws IOException {
Student st = new Student("Tom",'M',20,3.6); //实例化student类
//判断Student1.txt是否创建成功
File file = new File("D:\\AAAAAAAAAAAA\\Student1.txt");
if(file.exists()) {
System.out.println("文件存在");
}else{
//否则创建新文件
file.createNewFile();
}
try {
//Student对象序列化过程
FileOutputStream fos = new FileOutputStream(file);
ObjectOutputStream oos = new ObjectOutputStream(fos);
//调用 ObjectOutputStream 中的 writeObject() 方法 写对象
oos.writeObject(st);
oos.flush(); //flush方法刷新缓冲区,写字符时会用,因为字符会先进入缓冲区,将内存中的数据立刻写出
fos.close();
oos.close();
//Student对象反序列化过程
FileInputStream fis = new FileInputStream(file);
//创建对象输入流
ObjectInputStream ois = new ObjectInputStream(fis);
//读取对象
Student st1 = (Student) ois.readObject(); //会抛出异常(类找不到异常)
System.out.println("name = " + st1.getName());
System.out.println("sex = " + st1.getSex());
System.out.println("year = " + st1.getYear());
System.out.println("gpa = " + st1.getGpa());
ois.close();
fis.close();
}catch (ClassNotFoundException e){
e.printStackTrace();
}
}
}查看txt文件,结果如下:
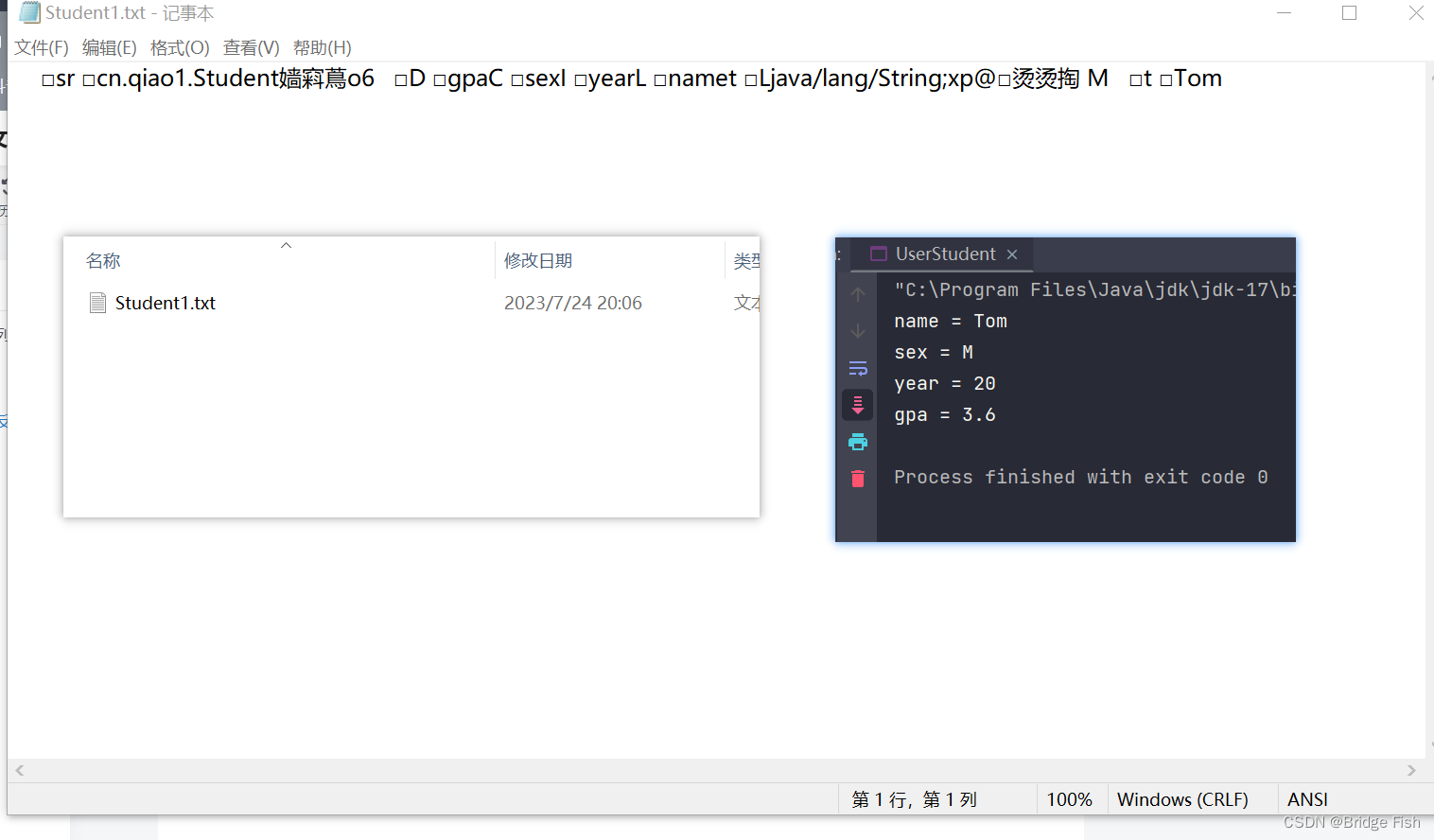
可以看出其中的内容是不容易阅读的,只能通过反序列化读取。
transient关键字
transient关键字表示有理的,被修饰的数据不能进行序列化
private transient char sex; //被transient关键字修饰,不参与序列化运行结果
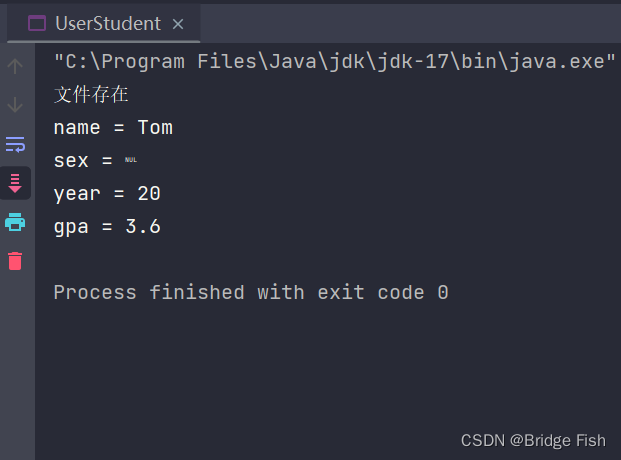
此时可以看见,被transient关键字修饰的变量sex并没有被序列化,返回了空值。
Externalizable接口实现序列化与反序列化
Externalizable接口继承Serializable接口,实现Externalizable接口需要实现readExternal()方法和writeExternal()方法,这两个方法是抽象方法,对应的是serializable接口的readObject()方法和writeObject()方法,可以理解为把serializable的两个方法抽象出来。Externalizable没有serializable的限制,static和transient关键字修饰的属性也能进行序列化。
复制对象student命名为student1,在里面重写writeExternal()方法和readExternal()方法,如下:
FileOutputStream fos1 = new FileOutputStream(file1);
ObjectOutputStream oos1 = new ObjectOutputStream(fos1);
//调用 ObjectOutputStream 中的 writeObject() 方法 写对象
oos1.writeObject(st); //会自动执行重写的writeExternal()方法FileInputStream fis1 = new FileInputStream(file1);
//创建对象输入流
ObjectInputStream ois1 = new ObjectInputStream(fis1);
//读取对象
//会自动执行readExternal()方法
Student1 st1 = (Student1) ois1.readObject(); //会抛出异常(类找不到异常)虽然student1类里的sex属性被static或transient修饰,但依旧被序列化
文件存在
name = Tom
sex = M
year = 20
gpa = 3.6idea小技巧
在使用IntelliJ IDEA开发工具进行Java开发时,默认情况下,IDEA会使用随机分配的动态序列化ID来进行对象的序列化。这是为了避免在对象发生变化时引发序列化ID不匹配的问题。
如果先进行对象的序列化,再对对象的类进行修改,则原本类中默认的serialVersionUID发生了变化,即读取到的对象的序列化版本号与当前类的序列化版本号不一致,再对对象进行反序列化时,会抛出异常:java.io.InvalidClassException
通过使用自定义的序列化ID,你可以更好地控制对象的序列化和反序列化过程,并增强程序的稳定性。这样,你就可以确保使用了固定的序列化ID来序列化你的对象。
但是,需要注意的是,如果你在自定义序列化ID时不小心导致了不匹配,可能会导致反序列化失败或意外的结果。因此,在进行自定义序列化ID时,请确保进行谨慎和适当的测试。
自定义生成
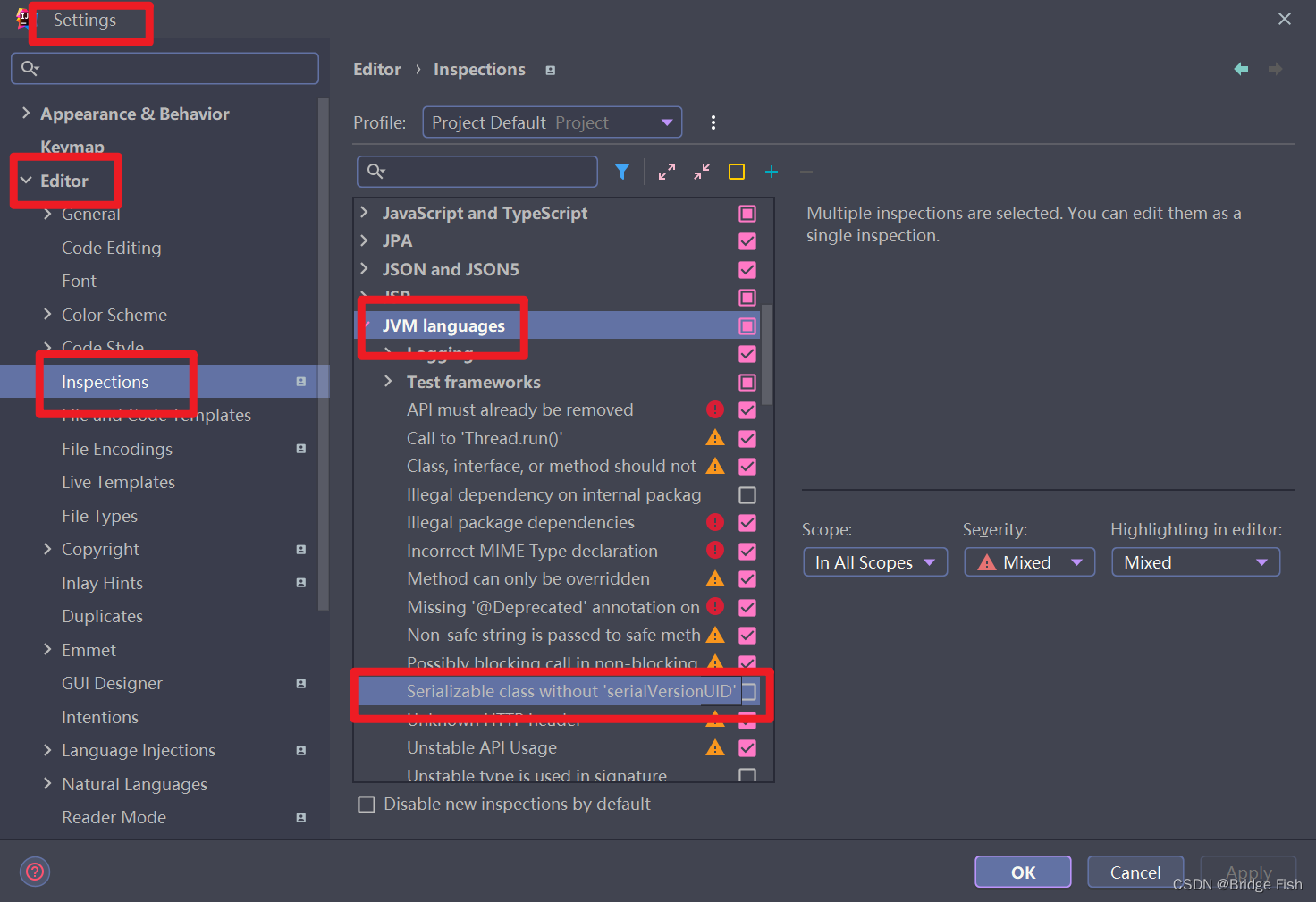
打上对勾确定
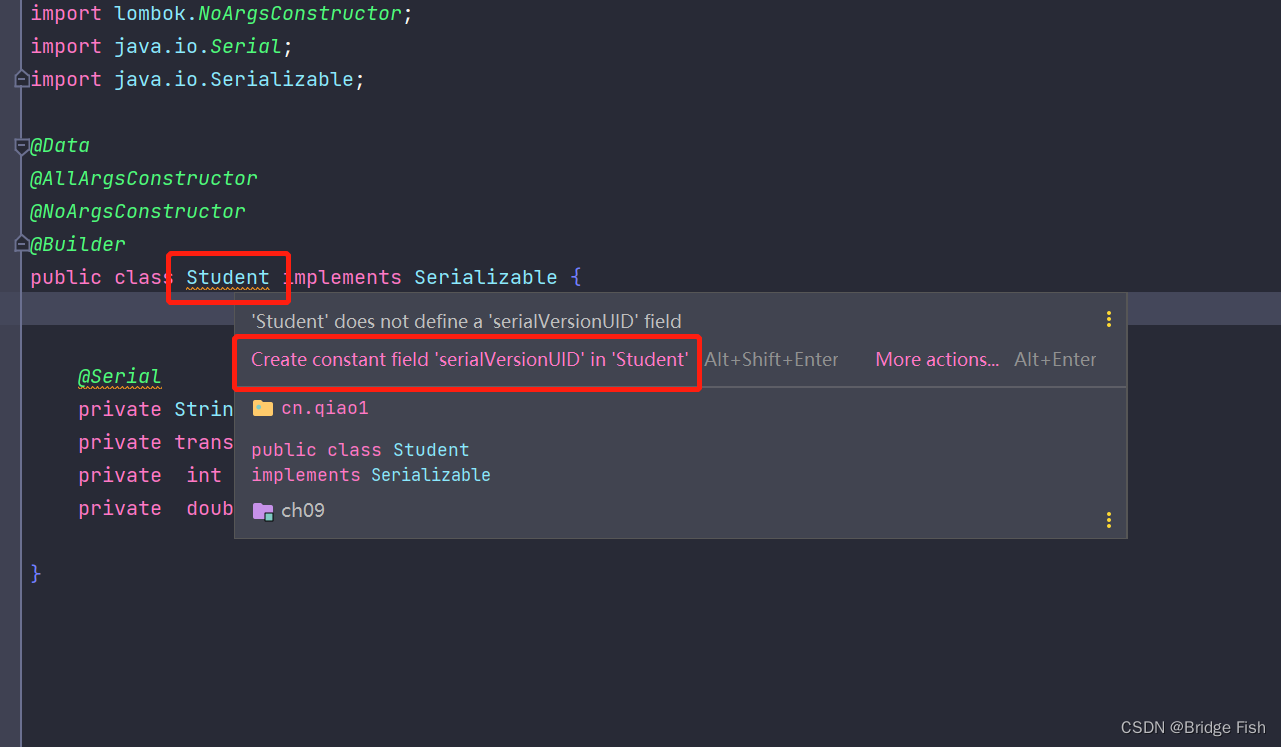
如何修改序列化id即可