深度学习论文分享(五)DDFM: Denoising Diffusion Model for Multi-Modality Image Fusion
- 前言
- Abstract
- 1. Introduction
- 2. Background
- 2.1. Score-based diffusion models
- 2.2. Multi-modal image fusion
- 2.3. Comparison with existing approaches
- 3. Method
- 3.1. Fusing images via diffusion posterior sampling
- 3.2. Likelihood rectification for image fusion
- 3.2.1 Formulation of the likelihood model
- 3.2.2 Inference the likelihood model via EM algorithm
- 3.3. DDFM
- 3.4. Why does one-step EM work?
- 4. Infrared and visible image fusion
- 4.1. Setup
- 4.2. Comparison with SOTA methods
- 4.3. Ablation studies
- 5. Medical image fusion
- 6. Conclusion
- References
前言
论文原文:https://arxiv.org/abs/2303.06840
Title:DDFM: Denoising Diffusion Model for Multi-Modality Image Fusion
Authors:Zixiang Zhao1;2 Haowen Bai1 Yuanzhi Zhu2 Jiangshe Zhang1 Shuang Xu3 Yulun Zhang2 Kai Zhang2 Deyu Meng1 Radu Timofte2;4 Luc Van Gool2
1Xi’an Jiaotong University 2Computer Vision Lab, ETH Zurich ¨ 3Northwestern Polytechnical University 4University of Wurzburg
在此仅做翻译
Abstract
多模态图像融合的目的是将不同的模态结合在一起,产生融合的图像,这些图像保留了每种模态的互补特征,如功能亮点和纹理细节。为了利用强大的生成先验并解决基于gan的生成方法的训练不稳定和缺乏可解释性等挑战,我们提出了一种基于去噪扩散概率模型(DDPM)的新型融合算法。将融合任务表述为DDPM采样框架下的条件生成问题,并进一步划分为无条件生成子问题和极大似然子问题。后者是在一个层次贝叶斯方式与潜在变量建模,并通过期望最大化算法推断。通过将推理解集成到扩散采样迭代中,我们的方法可以生成具有自然图像生成先验和源图像跨模态信息的高质量融合图像。请注意,我们所需要的只是一个无条件的预训练生成模型,不需要微调。大量的实验表明,该方法在红外-可见光图像融合和医学图像融合中取得了良好的融合效果。代码将被发布。
1. Introduction
图像融合将多源图像的基本信息集成在一起,形成高质量的融合图像[29],包括数字[15,53]、多模态[45,57]和遥感[48,60]等多种源图像类型。该技术提供了更清晰的对象和场景表示,具有多种应用,如显著性检测[32]、对象检测[2]和语义分割[21]。在图像融合的不同子类别中,红外-可见光图像融合(IVF)和医学图像融合(MIF)在多模态图像融合(MMIF)中尤其具有挑战性,因为它们侧重于建模跨模态特征并保留来自所有传感器和模态的关键信息。具体来说,在IVF中,融合图像的目的是保留红外图像的热辐射和可见光图像的详细纹理信息,从而避免可见光图像对光照条件敏感和红外图像噪声和低分辨率的限制。而MIF可以通过融合多种医学成像模式来精确检测异常位置,从而辅助诊断和治疗[12]。
最近已经设计了许多方法来解决MMIF带来的挑战[20,51],生成模型[7,30]已被广泛用于模拟融合图像的分布并获得令人满意的融合效果。其中,基于生成对抗网络(Generative Adversarial Networks, GANs)的模型[26,27,25,20]占主导地位。如图1a所示,基于gan的模型的工作流程涉及一个生成器,该生成器创建包含源图像信息的图像,以及一个判别器,该判别器确定生成的图像是否与源图像处于相似的流形中。基于gan的方法虽然能够生成高质量的融合图像,但存在训练不稳定、缺乏可解释性和模式崩溃等问题,严重影响了生成样本的质量。此外,作为一个黑盒模型,gan的内部机制和行为难以理解,这给实现可控生成带来了挑战。
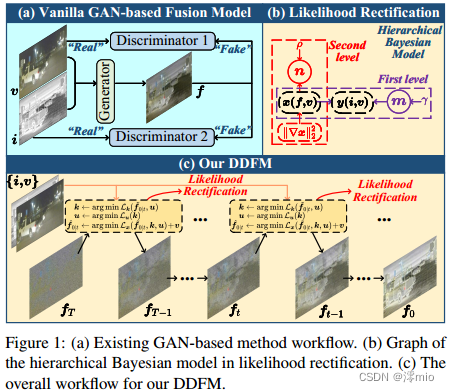
图1:( a )现有的基于gan的方法工作流。( b )层次贝叶斯模型的似然校正图。( c ) DDFM的整体工作流程。
最近,去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM)[9]引起了机器学习界的关注,它通过模拟将被噪声破坏的图像恢复为干净图像的扩散过程来生成高质量的图像。DDPM基于Langevin 扩散过程,通过一系列反向扩散步骤生成有希望的合成样品[35]。与GAN相比,DDPM不需要鉴别器网络,从而减轻了GAN中常见的训练不稳定和模式崩溃等问题。此外,它的生成过程是可解释的,因为它是基于去噪扩散来生成图像,可以更好地理解图像生成过程[44]。
因此,我们提出了一种去噪扩散图像融合模型(DDFM),如图1c所示。我们将条件生成任务描述为一个基于ddpm的后验抽样模型,该模型可以进一步分解为一个无条件生成扩散问题和一个极大似然估计问题。前者满足自然图像先验,后者通过似然校正来约束与源图像的相似度。与判别方法相比,利用DDPM对自然图像进行先验建模,可以更好地生成人工设计损失函数难以控制的细节,从而获得视觉上可感知的图像。DDFM作为一种生成方法,通过对DDPM输出进行似然校正,实现了无鉴别器融合图像的稳定可控生成。
我们的贡献分为三个方面:
•我们引入了一个基于ddpm的MMIF后验抽样模型,该模型由无条件生成模块和条件似然校正模块组成。融合图像的采样仅通过预训练的DDPM实现,无需微调。
•在似然校正中,由于显式地获得似然是不可实现的,我们将优化损失表述为一个涉及潜在变量的概率推理问题,该问题可以通过EM算法求解。然后将该方案集成到DDPM循环中,完成条件图像生成。
•对IVF和MIF任务的广泛评估表明,DDFM始终提供良好的融合结果,有效地保留了源图像的结构和细节信息,同时也满足了视觉保真要求。
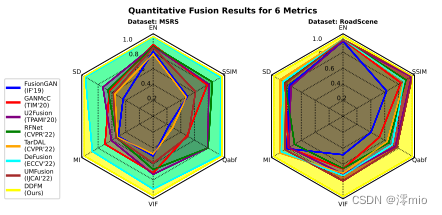
图2:DDFM(用黄色标记)在六个指标上优于MSRS[40]和RoadScene[46]上的所有其他方法。
2. Background
2.1. Score-based diffusion models
Score SDE formulation:扩散模型旨在通过反转预定义的前向过程来生成样本,该过程通过逐渐添加噪声将干净样本
x
0
x_0
x0转换为几乎高斯信号
x
T
x_T
xT。这个正向过程可以用伊藤随机微分方程(Ito Stochastic Differential Equation, SDE)来描述[38]
其中
d
w
dw
dw是标准维纳(Wiener)过程,
β
(
t
)
β(t)
β(t)是有利于方差保持SDE的预定义噪声表[38]。
这一正向过程在时间上可以逆转,但仍以SDE的形式存在[1]:

其中
d
ω
~
d\widetilde{\omega}
dω
对应于标准的维纳(Wiener)过程反向运行,唯一未知的部分
▽
x
t
l
o
g
p
t
(
x
t
)
\triangledown_{x_t}log_{p_t}(x_t)
▽xtlogpt(xt)可以建模为所谓的分数函数
s
θ
(
x
t
,
t
)
s_θ(x_t,t)
sθ(xt,t)用去噪分数匹配方法,该分数函数可以用以下目标进行训练[11,37]:
其中t均匀采样于
[
0
;
T
]
[0;T]
[0;T]和数据对
(
x
0
;
x
t
)
∼
p
0
(
x
)
p
0
t
(
x
t
∣
x
0
)
(x_0;x_t) \thicksim p_0(x)p_{0t}(xt|x0)
(x0;xt)∼p0(x)p0t(xt∣x0)。
Sampling with diffusion models:具体来说,无条件扩散生成过程从随机噪声向量
x
T
∼
N
(
0
;
I
)
x_T \thicksim N(0;I)
xT∼N(0;I),并根据Eq.(2)的离散化进行更新。或者,我们可以用DDIM方式来理解采样过程[35],其中分数函数也可以被认为是一个去噪器,在迭代
t
t
t时从任意状态
x
t
x_t
xt预测去噪后的
x
~
0
∣
t
\widetilde{x}_{0|t}
x
0∣t:

x
~
0
∣
t
\widetilde{x}_{0|t}
x
0∣t表示给定
x
t
x_t
xt的
x
0
x_0
x0的估计。根据Ho等人[9],我们使用相同的符号
α
t
=
1
−
β
t
α_t =1−β_t
αt=1−βt和
α
‾
t
=
∏
s
=
1
t
α
s
\overline{α}_t = \prod_{s=1}^tα_s
αt=∏s=1tαs。有了这个预测的
x
~
0
∣
t
\widetilde{x}_{0|t}
x
0∣t和当前状态
x
t
x_t
xt,
x
t
−
1
x_{t−1}
xt−1从下式更新
其中
z
∼
N
(
0
,
I
)
z \thicksim N(0,I)
z∼N(0,I)和
σ
~
t
2
\widetilde{σ}^2_t
σ
t2是方差,通常设为0。然后将采样后的
x
t
−
1
x_{t−1}
xt−1输入到下一个采样迭代中,直到生成最终图像
x
0
x_0
x0。关于这一采样过程的更多细节可以在补充材料或原始论文中找到[35]。
Diffusion models applications:最近,扩散模型得到了改进,生成的图像质量比以前的生成模型(如gan)更好[5,31]。此外,扩散模型可以被视为一个强大的生成先验,并应用于许多条件生成任务。扩散模型的一个代表性工作是稳定扩散,它可以根据给定的文本提示生成图像[33]。扩散模型也应用于许多低级视觉任务。例如,DDRM[14]在退化算子A的光谱空间中进行扩散采样,以重建观测y中缺失的信息。DDNM[50]与DDRM有着类似的思想,通过迭代地细化算子A的零空间来完成图像恢复任务。DPS[3]采用拉普拉斯近似计算后验抽样的对数似然梯度,能够处理许多有噪声的非线性反问题。在ΠGDM[36]中,作者使用很少的近似来使对数似然项易于处理,从而使其能够解决具有甚至不可微测量的逆问题。
2.2. Multi-modal image fusion
基于深度学习的多模态图像融合算法通过神经网络强大的拟合能力,实现了有效的特征提取和信息融合。融合算法主要分为两个分支:生成方法和判别方法。对于生成方法[26,23,27],特别是GAN家族,采用对抗性训练[7,28,30]来生成与源图像具有相同分布的融合图像。对于判别方法,基于自动编码器的模型[57,18,16,21,42,17,51]使用编码器和解码器提取特征并在高维流形上融合它们。算法展开模型[4,6,58,49,59]结合了传统的优化方法和神经网络,平衡了效率和可解释性。统一模型[46,52,45,54,13]避免了缺乏训练数据和特定任务的基础真值的问题。最近,融合方法与语义分割[39]和目标检测[20]等模式识别任务相结合,探索与下游任务的相互作用。采用自监督学习[19]来训练没有配对图像的融合网络。此外,预处理配准模块[47,10,43]可以增强对未配准输入图像的鲁棒性。
2.3. Comparison with existing approaches
与我们的模型最相关的方法是基于优化的方法和基于gan的生成方法。传统的基于优化的方法往往受到人工设计的损失函数的限制,这些损失函数可能不够灵活,无法捕获所有相关方面,并且对数据分布的变化很敏感。而结合自然图像先验可以提供额外的知识,不能单独由生成损失函数建模。然后,与可能出现不稳定训练和模式崩溃的基于gan的生成方法相比,我们的DDFM通过对源图像的生成过程进行校正,并在每次迭代中进行基于似然的细化,实现了更稳定和可控的融合。
3. Method
在本节中,我们首先提出了一种利用DDPM后验采样获得融合图像的新方法。然后,从建立好的图像融合损失函数出发,推导了无条件DDPM采样的似然校正方法。最后,我们提出了DDFM算法,该算法将层次贝叶斯推理的解嵌入到扩散采样中。此外,本文还将论证所提出算法的合理性。为简洁起见,我们省略了一些方程的推导,让有兴趣的读者参阅补充材料。值得注意的是,我们以IVF为例来说明我们的DDFM, MIF可以类似于IVF进行。
3.1. Fusing images via diffusion posterior sampling
我们首先给出模型公式的符号。红外、可见光和融合后的图像分别表示为 i ∈ R H W i\in\mathbb{R}^{HW} i∈RHW、 v ∈ R 3 H W v\in\mathbb{R}^{3HW} v∈R3HW和 f ∈ R 3 H W f\in\mathbb{R}^{3HW} f∈R3HW。
我们期望给定
i
i
i和
v
v
v的
f
f
f的分布,即
p
(
f
∣
i
,
v
)
p(f|i,v)
p(f∣i,v)可以建模,因此
f
f
f可以从后验分布中抽样得到。受Eq.(2)的启发,我们可以将扩散过程的反向SDE表示为:
分数函数,即
▽
f
t
l
o
g
p
t
(
f
t
∣
i
,
v
)
\triangledown_{f_t}log_{p_t}(f_t|i,v)
▽ftlogpt(ft∣i,v)的计算公式为:
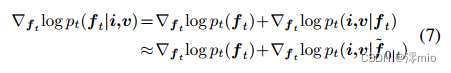
其中
f
~
0
∣
t
\widetilde{f}_{0|t}
f
0∣t是
f
0
f_0
f0给定
f
t
f_t
ft从无条件DDPM的估计。等式来源于贝叶斯定理,近似方程由[3]证明。
在Eq.(7)中,第一项表示无条件扩散抽样的得分函数,它可以很容易地由预训练的DDPM导出。在下一节中,我们将说明获取 ▽ f t l o g p t ( i , v ∣ f ~ 0 ∣ t ) \triangledown_{f_t}log_{p_t}(i,v|\widetilde{f}_{0|t}) ▽ftlogpt(i,v∣f 0∣t)的方法。
3.2. Likelihood rectification for image fusion
与传统的图像退化反问题y = A(x) + n不同,其中 x x x为真实图像, y y y为测量值, A ( ⋅ ) A(·) A(⋅)已知,我们可以显式地获得其后验分布。然而,在图像融合中, p t ( i , v ∣ f ~ t ) {p_t}(i,v|\widetilde{f}_{t}) pt(i,v∣f t)或 p t ( i , v ∣ f ~ 0 ∣ t ) {p_t}(i,v|\widetilde{f}_{0|t}) pt(i,v∣f 0∣t)是无法显式表达的。为了解决这个问题,我们从损失函数出发,建立了优化损失函数 l ( i , v , f ~ 0 ∣ t ) l(i,v,\widetilde{f}_{0|t}) l(i,v,f 0∣t)和概率模型的似然 p t ( i , v ∣ f ~ 0 ∣ t ) p_t(i,v|\widetilde{f} _{0|t}) pt(i,v∣f 0∣t)。为简洁起见,在第3.2.1节和第3.2.2节中, f ~ 0 ∣ t \widetilde{f} _{0|t} f 0∣t缩写为 f f f。
3.2.1 Formulation of the likelihood model
我们首先给出图像融合任务常用的损失函数[17,51,22,55]:
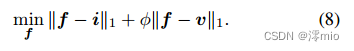
然后实现简单的变量替换
x
=
f
−
v
x=f - v
x=f−v和
y
=
i
−
v
y=i - v
y=i−v,得到
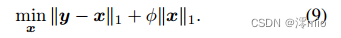
由于
y
y
y是已知的,
x
x
x是未知的,所以这个1范数优化方程对应于回归模型:
y
=
k
x
+
ϵ
y = kx+\epsilon
y=kx+ϵ, k固定为1。根据正则化项与噪声先验分布的关系,
ϵ
\epsilon
ϵ应为拉普拉斯噪声,
x
x
x受拉普拉斯分布支配。因此,以贝叶斯的方式,我们有:

式中
L
A
P
(
⋅
)
LAP(·)
LAP(⋅)为拉普拉斯分布。
ρ
ρ
ρ和
γ
γ
γ分别是
p
(
x
)
p(x)
p(x)和
p
(
y
∣
x
)
p(y|x)
p(y∣x)的尺度参数。
为了防止Eq.(9)中的“1-范数优化”,受[22,56]的启发,我们给出命题1:
命题1。对于服从拉普拉斯分布的随机变量(RV)
ξ
ξ
ξ,可以看作是正态分布的RV与指数分布的RV的耦合,其公式为:
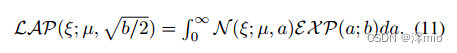
因此,Eq.(10)中的
p
(
x
)
p(x)
p(x)和
p
(
y
∣
x
)
p(y|x)
p(y∣x)可以重写为以下层次贝叶斯框架:

其中
i
=
1
,
.
.
.
,
H
i = 1,...,H
i=1,...,H和
j
=
1
,
.
.
.
,
W
j = 1,...,W
j=1,...,W.通过上述概率分析,可以将Eq.(9)中的优化问题转化为极大似然推理问题
此外,根据[22,39],还可以加入总变异惩罚项
r
(
x
)
=
∣
∣
▽
x
∣
∣
2
2
r(x) = ||\triangledown x||^2_2
r(x)=∣∣▽x∣∣22,使融合图像f更好地保留
v
v
v的纹理信息,其中
▽
\triangledown
▽为梯度算子。最终,概率推理问题的对数似然函数为:
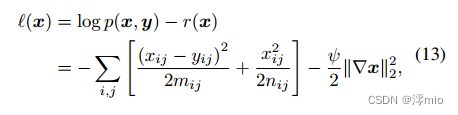
该层次贝叶斯模型的概率图如图1b所示。值得注意的是,通过这种方式,我们将优化问题Eq.(8)转换为概率模型Eq.(13)的最大似然问题。此外,与传统优化方法需要在Eq.(8)中手动指定调谐系数φ不同,我们模型中的φ可以通过推断潜在变量自适应更新,使模型能够更好地拟合不同的数据分布。本设计的有效性也在第4.3节的烧蚀实验中得到了验证。然后,我们将在下一节探讨如何推断它。
3.2.2 Inference the likelihood model via EM algorithm
为了解决Eq.(13)中的最大对数似然问题,可以看作是一个有潜在变量的优化问题,我们使用期望最大化(EM)算法来获得最优的
x
x
x。在
E
E
E步中,计算对数似然函数对
p
(
a
,
b
∣
x
(
t
)
,
y
)
p(a,b|x^{(t)},y)
p(a,b∣x(t),y)的期望,即所谓的
Q
Q
Q函数:
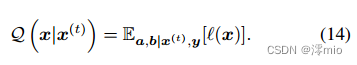
在
M
M
M步中,最优
x
x
x由下式得到:
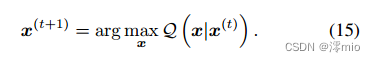
接下来,我们将展示每个步骤中的实现细节。
E-step。命题2给出了潜变量条件期望的计算结果,并推导出q函数的导数。
命题2。式(13)中潜在变量
1
/
m
i
j
1/m_{ij}
1/mij和
1
/
n
i
j
1/n_{ij}
1/nij的条件期望为:
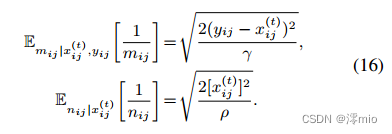
证明:


之后,
Q
Q
Q函数Eq.(14)推导为:
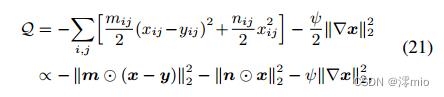
式中
m
i
j
m_{ij}
mij和
n
i
j
n_{ij}
nij分别表示式(16)中的
E
m
i
j
∣
x
i
j
(
t
)
,
y
i
j
[
1
/
m
i
j
]
E_{m_{ij}|x^{(t)}_{ij},y_{ij}}[1/m_{ij}]
Emij∣xij(t),yij[1/mij]和
E
n
i
j
∣
x
i
j
(
t
)
,
y
i
j
[
1
/
n
i
j
]
E_{n_{ij}|x^{(t)}_{ij},y_{ij}}[1/n_{ij}]
Enij∣xij(t),yij[1/nij]。
⊙
\odot
⊙是元素乘法。
m
m
m和
n
n
n是矩阵,每个元素分别为
m
i
j
\sqrt{m_{ij}}
mij和
n
i
j
\sqrt{n_{ij}}
nij。
M-step. 这里,我们需要求负
Q
Q
Q函数相对于
x
x
x的最小值,我们使用半二次分割算法来处理这个问题,即:
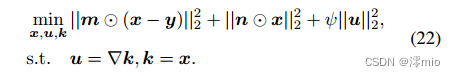
可进一步转化为以下无约束优化问题:
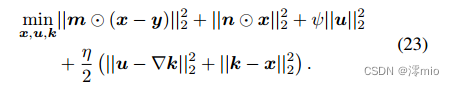
未知变量
k
,
u
,
x
k,u,x
k,u,x可以用坐标下降法迭代求解。
Update k: 这是一个反卷积问题.
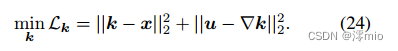
它可以通过快速傅里叶变换(fft)和逆傅里叶变换(ifft)算子有效地求解,且k的解为
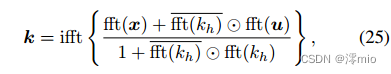
其中
⋅
~
\widetilde{\cdot}
⋅
是复数共轭形式。
Update u: 这是一个“双范数惩罚回归问题”,
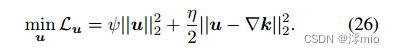
u的解是
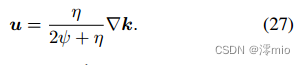
Update x:这是一个最小二乘问题,
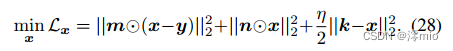
x的解是
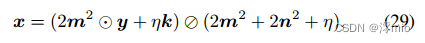
式中
⊙
\odot
⊙表示元素除法,f的最终估计值是

此外,Eq.(10)中的超参数
γ
γ
γ和
ρ
ρ
ρ也可以在从
x
x
x (Eq.(29))采样后通过

3.3. DDFM
概述。在第3.2节中,我们提出了一种从现有损失函数中获得分层贝叶斯模型并通过EM算法进行模型推理的方法。在本节中,我们介绍了我们的DDFM,其中推理解和扩散采样在给定i和v的相同迭代框架内集成,以生成 f 0 f_0 f0。该算法在算法1和图3中说明。
DDFM中有两个模块,无条件扩散采样(UDS)模块和似然校正(EM)模块。UDS模块提供自然图像先验,提高融合图像的视觉可信度。另一方面,EM模块负责通过可能性对UDS模块的输出进行校正,以保留源图像中的更多信息。

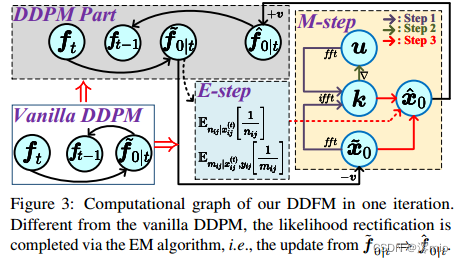
图3:我们的DDFM在一次迭代中的计算图。与传统的DDPM不同,似然校正是通过EM算法完成的,即从
f
~
0
∣
t
⇒
f
^
0
∣
t
\widetilde{f}_{0|t} \Rightarrow \hat{f}_{0|t}
f
0∣t⇒f^0∣t更新。
Unconditional diffusion sampling module.
在2.1节中,我们将简要介绍扩散采样。在算法1中,UDS(灰色部分)被划分为两部分,第一部分使用
f
t
f_t
ft估计
f
~
0
∣
t
\widetilde{f}_{0|t}
f
0∣t,第二部分同时使用
f
t
f_t
ft和
f
^
0
∣
t
\hat{f}_{0|t}
f^0∣t估计
f
t
−
1
f_{t−1}
ft−1。从Eq.(7)中基于分数的DDPM来看,预训练的DDPM可以直接输出当前的
▽
f
t
l
o
g
p
t
(
f
t
)
\triangledown_{f_t}log_{p_t}(f_t)
▽ftlogpt(ft),而
▽
f
t
l
o
g
p
t
(
i
,
v
∣
f
~
0
∣
t
)
\triangledown_{f_t}log_{p_t}(i,v|\widetilde{f}_{0|t})
▽ftlogpt(i,v∣f
0∣t)可以通过EM模块得到。
EM module. EM模块的作用是更新 f ~ 0 ∣ t ⇒ f ^ 0 ∣ t \widetilde{f}_{0|t} \Rightarrow \hat{f}_{0|t} f 0∣t⇒f^0∣t。在算法1和图3中,将EM算法(蓝色和黄色)插入到UDS(灰色)中。利用DDPM采样(第5行)产生的初步估计 f ~ 0 ∣ t \widetilde{f}_{0|t} f 0∣t作为EM算法的初始输入,得到 f ^ 0 ∣ t \hat{f}_{0|t} f^0∣t(第6-13行),这是经过似然校正的融合图像的估计。换句话说,EM模块将 f ~ 0 ∣ t \widetilde{f}_{0|t} f 0∣t整流到 f ^ 0 ∣ t \hat{f}_{0|t} f^0∣t以满足似然。
3.4. Why does one-step EM work?
我们的DDFM与传统EM算法的主要区别在于,传统方法需要多次迭代才能得到最优的x,即算法1中6-13行的操作需要多次循环。然而,我们的DDFM只需要EM算法迭代的一步,该算法被嵌入到DDPM框架中来完成采样。下面,我们给出提案3来证明其合理性.
命题3。一步无条件扩散采样与一步EM迭代相结合,相当于一步条件扩散采样。
证明:

4. Infrared and visible image fusion
在本节中,我们详细介绍了IVF task的大量实验,以证明我们的方法的优越性。更多的相关实验放在补充材料中。
4.1. Setup
Datasets and pre-trained model. 按照[20,19]的方案,在TNO[41]、RoadScene[46]、MSRS[40]和M3FD[20]四个测试数据集上进行, IVF实验。请注意,没有训练数据集,因为我们不需要对特定任务进行任何微调,而是直接使用预训练的DDPM模型。我们选择[5]提出的预训练模型,该模型在ImageNet[34]上进行训练。
Metrics. 我们在定量实验中采用熵(EN)、标准差(SD)、互信息(MI)、视觉信息保真度(VIF)、QAB=F和结构相似指数测度(SSIM) 6个指标对融合效果进行综合评价。指标的细节见[24]
Implement details. 我们使用一台带有NVIDIA GeForce RTX 3090 GPU的机器进行融合图像生成。所有输入图像归一化为[−1;1]。Eq.(23)中的 ψ \psi ψ η \eta η分别设为0.5和0.1。请参考补充资料,通过网格搜索进行选择 ψ \psi ψ和 η \eta η。

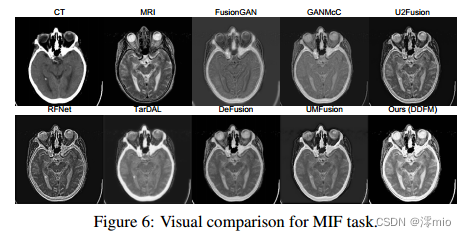
4.2. Comparison with SOTA methods
在本节中,我们将我们的DDFM与最先进的方法进行比较,包括基于gan的方法组:fusongan [26], GANMcC [27], TarDAL[20]和UMFusion [43];鉴别方法组:U2Fusion[45]、RFNet[47]、DeFusion[19]。
定性比较。我们在图4和图5中展示了融合结果的比较。我们的方法有效地结合了红外图像的热辐射信息和可见光图像的详细纹理信息。因此,位于光线昏暗环境中的物体被明显地突出,从而很容易将前景物体与背景区分开来。此外,以前由于低照度而不清晰的背景特征,现在有了清晰的边缘和丰富的轮廓信息,增强了我们对场景的理解能力。
定量比较。随后,使用前面提到的六个指标来定量比较融合结果,如表1所示。我们的方法在几乎所有指标上都表现出卓越的性能,证实了它对不同照明和物体类别的适用性。值得注意的是,MI、VIF和Qabf在所有数据集中的突出值表明,它能够生成符合人类视觉感知的图像,同时保持源图像信息的完整性。
4.3. Ablation studies
进行了大量的烧蚀实验,以证实我们的各种模块的可靠性。利用上述六个指标对实验组的融合性能进行评估,Roadscene测试集上的结果如表2所示。

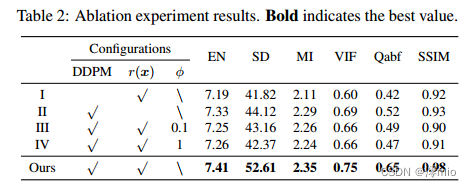

无条件扩散采样模块。我们首先验证了DDPM的有效性。在Exp. I中,我们消除了去噪扩散生成框架,只使用EM算法求解优化Eq.(8),得到融合图像。公平地说,我们使总迭代次数与DDFM保持一致。
EM模块。接下来,我们验证EM模块中的组件。在Exp. II中,我们删除了Eq.(13)中的总变异惩罚项r(x)。然后,我们去掉贝叶斯推理模型。如前所述,Eq.(8)中的φ可以在分层贝叶斯模型中自动推断出来。因此,我们手动设置φ为0.1 (Exp. III)和1 (Exp. IV),并使用ADMM算法来推断模型。
综上所述,表2的结果表明,没有一个实验组能够达到与我们的DDFM相媲美的融合结果,进一步强调了我们方法的有效性和合理性。
5. Medical image fusion
在本节中,我们进行了MIF实验来验证我们方法的有效性。
设置。我们从哈佛医学图像数据集[8]中选择50对医学图像进行MIF实验,包括MRI-CT、MRI-PET和MRI-SPECT的图像对。MIF任务的生成策略和评估指标与体外受精相同。
与SOTA方法的比较。定性和定量结果如图6和表3所示。很明显,DDFM在强调结构信息的同时保留了复杂的纹理,从而在视觉和几乎所有数值指标上都具有出色的性能。
6. Conclusion
提出了一种基于去噪扩散概率模型(DDPM)的生成式图像融合算法DDFM。生成问题分为无条件DDPM(利用图像生成先验)和最大似然子问题(保留源图像的跨模态信息)。我们使用层次贝叶斯方法对后者进行建模,并将其基于EM算法的解决方案集成到无条件DDPM中以实现条件图像融合。红外-可见光图像和医学图像的融合实验表明,该方法取得了良好的融合效果。
References
[1] Brian DO Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326,1982. 2
[2] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan MarkLiao. Yolov4: Optimal speed and accuracy of object detection.CoRR, abs/2004.10934, 2020. 1
[3] Hyungjin Chung, Jeongsol Kim, Michael T. McCann,Marc Louis Klasky, and Jong Chul Ye. Diffusion posteriorsampling for general noisy inverse problems. In ICLR, 2023.3, 6
[4] Xin Deng and Pier Luigi Dragotti. Deep convolutional neuralnetwork for multi-modal image restoration and fusion. IEEETrans. Pattern Anal. Mach. Intell., 43(10):3333–3348, 2021.3
[5] Prafulla Dhariwal and Alexander Nichol. Diffusion modelsbeat gans on image synthesis. Advances in Neural InformationProcessing Systems, 34:8780–8794, 2021. 3, 7
[6] Fangyuan Gao, Xin Deng, Mai Xu, Jingyi Xu, and Pier LuigiDragotti. Multi-modal convolutional dictionary learning.IEEE Trans. Image Process., 31:1325–1339, 2022. 3
[7] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, BingXu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville,and Yoshua Bengio. Generative adversarial nets. In NIPS,pages 2672–2680, 2014. 1, 3
[8] Harvard Medical website. http://www.med.harvard.edu/AANLIB/home.html. 8
[9] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020. 2
[10] Zhanbo Huang, Jinyuan Liu, Xin Fan, Risheng Liu, WeiZhong, and Zhongxuan Luo. Reconet: Recurrent correctionnetwork for fast and efficient multi-modality image fusion. InEuropean Conference on Computer Vision (ECCV), 2022. 3
[11] Aapo Hyvarinen and Peter Dayan. Estimation of non- ¨normalized statistical models by score matching. Journalof Machine Learning Research, 6(4), 2005. 2
[12] Alex Pappachen James and Belur V. Dasarathy. Medicalimage fusion: A survey of the state of the art. Inf. Fusion,19:4–19, 2014. 1
[13] Hyungjoo Jung, Youngjung Kim, Hyunsung Jang, NamkooHa, and Kwanghoon Sohn. Unsupervised deep image fusionwith structure tensor representations. IEEE Trans. ImageProcess., 29:3845–3858, 2020. 3
[14] Bahjat Kawar, Michael Elad, Stefano Ermon, and JiamingSong. Denoising diffusion restoration models. arXiv preprintarXiv:2201.11793, 2022. 3
[15] Hui Li, Kede Ma, Hongwei Yong, and Lei Zhang. Fast multiscale structural patch decomposition for multi-exposure image fusion. IEEETrans. Image Process., 29:5805–5816, 2020.1
[16] Hui Li, Xiao-Jun Wu, and Tariq S. Durrani. Nestfuse: Aninfrared and visible image fusion architecture based on nestconnection and spatial/channel attention models. IEEE Trans.Instrum. Meas., 69(12):9645–9656, 2020. 3
[17] Hui Li, Xiao-Jun Wu, and Josef Kittler. Rfn-nest: An end-toend residual fusion network for infrared and visible images.Inf. Fusion, 73:72–86, 2021. 3, 4
[18] Hui Li and Xiao-Jun Wu. Densefuse: A fusion approach toinfrared and visible images. IEEE Transactions on ImageProcessing, 28(5):2614–2623, 2018. 3
[19] Pengwei Liang, Junjun Jiang, Xianming Liu, and Jiayi Ma.Fusion from decomposition: A self-supervised decomposition approach for image fusion. In European Conference onComputer Vision (ECCV), 2022. 3, 6, 7, 8
[20] Jinyuan Liu, Xin Fan, Zhanbo Huang, Guanyao Wu, RishengLiu, Wei Zhong, and Zhongxuan Luo. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. InCVPR, pages 5792–5801. IEEE, 2022. 1, 2, 3, 6, 7, 8
[21] Risheng Liu, Zhu Liu, Jinyuan Liu, and Xin Fan. Searchinga hierarchically aggregated fusion architecture for fast multimodality image fusion. In ACM Multimedia, pages 1600–1608. ACM, 2021. 1, 3
[22] Jiayi Ma, Chen Chen, Chang Li, and Jun Huang. Infrared andvisible image fusion via gradient transfer and total variationminimization. Information Fusion, 31:100–109, 2016. 4
[23] Jiayi Ma, Pengwei Liang, Wei Yu, Chen Chen, Xiaojie Guo,Jia Wu, and Junjun Jiang. Infrared and visible image fusionvia detail preserving adversarial learning. Information Fusion,54:85–98, 2020. 3
[24] Jiayi Ma, Yong Ma, and Chang Li. Infrared and visible imagefusion methods and applications: A survey. InformationFusion, 45:153–178, 2019. 7
[25] Jiayi Ma, Han Xu, Junjun Jiang, Xiaoguang Mei, and XiaoPing (Steven) Zhang. Ddcgan: A dual-discriminator conditional generative adversarial network for multi-resolutionimage fusion. IEEE Trans. Image Process., 29:4980–4995,2020. 2
[26] Jiayi Ma, Wei Yu, Pengwei Liang, Chang Li, and Junjun Jiang.Fusiongan: A generative adversarial network for infrared andvisible image fusion. Information Fusion, 48:11–26, 2019. 2,3, 7, 8
[27] Jiayi Ma, Hao Zhang, Zhenfeng Shao, Pengwei Liang, andHan Xu. Ganmcc: A generative adversarial network withmulticlassification constraints for infrared and visible imagefusion. IEEE Trans. Instrum. Meas., 70:1–14, 2021. 2, 3, 7, 8
[28] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, ZhenWang, and Stephen Paul Smolley. Least squares generative adversarial networks. In Proceedings of the IEEE InternationalConference on Computer Vision, pages 2794–2802, 2017. 3
[29] Bikash Meher, Sanjay Agrawal, Rutuparna Panda, and AjithAbraham. A survey on region based image fusion methods.Information Fusion, 48:119–132, 2019. 1
[30] Mehdi Mirza and Simon Osindero. Conditional generativeadversarial nets. arXiv preprint arXiv:1411.1784, 2014. 1, 3
[31] Alexander Quinn Nichol and Prafulla Dhariwal. Improveddenoising diffusion probabilistic models. In ICML, pages8162–8171, 2021. 3
[32] Xuebin Qin, Zichen Vincent Zhang, Chenyang Huang, ChaoGao, Masood Dehghan, and Martin Jagersand. Basnet: ¨Boundary-aware salient object detection. In CVPR, pages7479–7489. Computer Vision Foundation / IEEE, 2019. 1
[33] Robin Rombach, Andreas Blattmann, Dominik Lorenz,Patrick Esser, and Bjorn Ommer. High-resolution image ¨synthesis with latent diffusion models. In Proceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition, pages 10684–10695, 2022. 3
[34] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy,Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, andLi Fei-Fei. Imagenet large scale visual recognition challenge.Int. J. Comput. Vis., 115(3):211–252, 2015. 7
[35] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoisingdiffusion implicit models. In ICLR, 2021. 2, 3
[36] Jiaming Song, Arash Vahdat, Morteza Mardani, and JanKautz. Pseudoinverse-guided diffusion models for inverseproblems. In International Conference on Learning Representations, 2023. 3
[37] Yang Song and Stefano Ermon. Generative modeling byestimating gradients of the data distribution. Advances inNeural Information Processing Systems, 32, 2019. 2
[38] Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-basedgenerative modeling through stochastic differential equations.In ICLR. OpenReview.net, 2021. 2
[39] Linfeng Tang, Jiteng Yuan, and Jiayi Ma. Image fusion inthe loop of high-level vision tasks: A semantic-aware realtime infrared and visible image fusion network. Inf. Fusion,82:28–42, 2022. 3, 4
[40] Linfeng Tang, Jiteng Yuan, Hao Zhang, Xingyu Jiang, andJiayi Ma. Piafusion: A progressive infrared and visible imagefusion network based on illumination aware. Inf. Fusion,83-84:79–92, 2022. 1, 6, 8
[41] Alexander Toet and Maarten A. Hogervorst. Progress in colornight vision. Optical Engineering, 51(1):1 – 20, 2012. 6, 8
[42] Vibashan VS, Jeya Maria Jose Valanarasu, Poojan Oza,and Vishal M. Patel. Image fusion transformer. CoRR,abs/2107.09011, 2021. 3
[43] Di Wang, Jinyuan Liu, Xin Fan, and Risheng Liu. Unsupervised misaligned infrared and visible image fusion viacross-modality image generation and registration. In IJCAI,pages 3508–3515. ijcai.org, 2022. 3, 7, 8
[44] Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tacklingthe generative learning trilemma with denoising diffusiongans. In ICLR, 2022. 2
[45] Han Xu, Jiayi Ma, Junjun Jiang, Xiaojie Guo, and HaibinLing. U2fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell., 44(1):502–518,2022. 1, 3, 7, 8
[46] Han Xu, Jiayi Ma, Zhuliang Le, Junjun Jiang, and XiaojieGuo. Fusiondn: A unified densely connected network forimage fusion. In AAAI Conference on Artificial Intelligence,AAAI, pages 12484–12491, 2020. 1, 3, 6, 8
[47] Han Xu, Jiayi Ma, Jiteng Yuan, Zhuliang Le, and Wei Liu.Rfnet: Unsupervised network for mutually reinforcing multimodal image registration and fusion. In CVPR, pages 19647–19656. IEEE, 2022. 3, 7, 8
[48] Shuang Xu, Jiangshe Zhang, Zixiang Zhao, Kai Sun, JunminLiu, and Chunxia Zhang. Deep gradient projection networksfor pan-sharpening. In CVPR, pages 1366–1375. ComputerVision Foundation / IEEE, 2021. 1
[49] Shuang Xu, Zixiang Zhao, Yicheng Wang, Chunxia Zhang,Junmin Liu, and Jiangshe Zhang. Deep convolutional sparsecoding networks for image fusion. CoRR, abs/2005.08448,2020. 3
[50] Wang Yinhuai, Yu Jiwen, and Zhang Jian. Zero shot image restoration using denoising diffusion null-space model.arXiv:2212.00490,2022. 3
[51] Hao Zhang and Jiayi Ma. Sdnet: A versatile squeeze-anddecomposition network for real-time image fusion. Int. J.Comput. Vis., 129(10):2761–2785, 2021. 1, 3, 4
[52] Hao Zhang, Han Xu, Yang Xiao, Xiaojie Guo, and Jiayi Ma.Rethinking the image fusion: A fast unified image fusionnetwork based on proportional maintenance of gradient andintensity. In AAAI, pages 12797–12804. AAAI Press, 2020. 3
[53] Xingchen Zhang. Deep learning-based multi-focus imagefusion: A survey and a comparative study. IEEE Transactionson Pattern Analysis and Machine Intelligence, 2021. 1
[54] Yu Zhang, Yu Liu, Peng Sun, Han Yan, Xiaolin Zhao, and LiZhang. IFCNN: A general image fusion framework based onconvolutional neural network. Inf. Fusion, 54:99–118, 2020.3
[55] Zixiang Zhao, Haowen Bai, Jiangshe Zhang, Yulun Zhang,Shuang Xu, Zudi Lin, Radu Timofte, and Luc Van Gool.Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. CoRR, abs/2211.14461,2022. 4
[56] Zixiang Zhao, Shuang Xu, Chunxia Zhang, Junmin Liu, andJiangshe Zhang. Bayesian fusion for infrared and visibleimages. Signal Processing, 177, 2020. 4
[57] Zixiang Zhao, Shuang Xu, Chunxia Zhang, Junmin Liu, Jiangshe Zhang, and Pengfei Li. DIDFuse: Deep image decomposition for infrared and visible image fusion. In InternationalJoint Conference on Artificial Intelligence, IJCAI, pages 970–976, 2020. 1, 3
[58] Zixiang Zhao, Shuang Xu, Jiangshe Zhang, Chengyang Liang,Chunxia Zhang, and Junmin Liu. Efficient and model-basedinfrared and visible image fusion via algorithm unrolling.IEEE Trans. Circuits Syst. Video Technol., 32(3):1186–1196,2022. 3
[59] Zixiang Zhao, Jiangshe Zhang, Shuang Xu, Zudi Lin, andHanspeter Pfister. Discrete cosine transform network forguided depth map super-resolution. In Proceedings of theIEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR), pages 5697–5707, June 2022. 3
[60] Zixiang Zhao, Jiangshe Zhang, Shuang Xu, Kai Sun, LuHuang, Junmin Liu, and Chunxia Zhang. FGF-GAN: Alightweight generative adversarial network for pansharpeningvia fast guided filter. In ICME, pages 1–6. IEEE, 2021. 1