文章目录
- 1. 数据库分类与SQL分类
- 2. SQL的数据类型
- 3. DDL CURD
- 3.1 库的操作
- 3.2 表约束
- 3.3 表的操作
- 4 DML CURD
- 5. DQL (数据查询语言)
- 5.1 单表查询
- 5.2 聚合查询与分组查询
- 5.3 多表查询与外键约束
- 5.4 多表之间的连接查询
- 5.4.1左链接查询
- 5.4.2 右连接查询
- 5.4.3 内连接
- 5.4.4 全连接
- 5.5 多对多的表查询
- 6 查询对象数组
1. 数据库分类与SQL分类
-
数据库主要分为两类 :
关系型数据库和非关系型数据库; -
关系型数据库:MySQL、Oracle、DB2、SQL Server、Postgre SQL等;
- 关系型数据库通常我们会创建
很多个二维数据表; - 数据表之间相互关联起来,形成
一对一、一对多、多对多等关系 - 之后可以利用
SQL语句在多张表中查询我们所需的数据;
- 关系型数据库通常我们会创建
-
非关系型数据库:MongoDB、Redis、Memcached、HBse等;
- 非关系型数据库的英文其实是Not only SQL,也简称为
NoSQL; - 相当而言
非关系型数据库比较简单一些,存储数据也会更加自由(甚至我们可以直接将一个复杂的json对象直接塞入到数据库中);
- 非关系型数据库的英文其实是Not only SQL,也简称为
-
NoSQL是基于
Key-Value的对应关系,并且查询的过程中不需要经过SQL解析;
SQL语句的分类
DDL(Data Definition Language):数据定义语言;- 可以通过DDL语句对数据库或者表进行:创建、删除、修改等操作;
DML(Data Manipulation Language):数据操作语言;- 可以通过DML语句对表中的字段进行:添加、删除、修改等操作;
DQL(Data Query Language):数据查询语言;- 可以通过DQL从数据库中查询记录;(重点)
DCL(Data Control Language):数据控制语言;- 对数据库、表格的权限进行相关访问控制操作;
2. SQL的数据类型
-
MySQL支持的数据类型有:
数字类型,日期和时间类型,字符串(字符和字节)类型,空间类型和 JSON数据类型。 -
数字类型
- 整数数字类型:INTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT;
- 浮点数字类型:FLOAT,DOUBLE(FLOAT是4个字节,DOUBLE是8个字节)
- 精确数字类型:DECIMAL,NUMERIC(DECIMAL是NUMERIC的实现形式);
- 整数类型占用字节数
-
日期类型 :
YEAR以YYYY格式显示值- 范围 1901到2155,和 0000。
DATE类型用于具有日期部分但没有时间部分的值:- DATE以格式YYYY-MM-DD显示值 ;
- 支持的范围是 ‘1000-01-01’ 到 ‘9999-12-31’;
DATETIME类型用于包含日期和时间部分的值:- DATETIME以格式’YYYY-MM-DD hh:mm:ss’显示值;
- 支持的范围是1000-01-01 00:00:00到9999-12-31 23:59:59
TIMESTAMP数据类型被用于同时包含日期和时间部分的值:- TIMESTAMP以格式’YYYY-MM-DD hh:mm:ss’显示值;
- 但是它的范围是UTC的时间范围:‘1970-01-01 00:00:01’到’2038-01-19 03:14:07’
- DATETIME或TIMESTAMP 值可以包括在高达微秒(6位)精度的后小数秒一部分
- 如DATETIME表示的范围可以是’1000-01-01 00:00:00.000000’到’9999-12-31 23:59:59.999999’
-
字符串类型
CHAR类型在创建表时为固定长度,长度可以是0到255之间的任何值;- 在被查询时,会删除后面的空格;
VARCHAR类型的值是可变长度的字符串,长度可以指定为0到65535之间的值;- 在被查询时,不会删除后面的空格;
-
BLOB类型
- 用于存储大的二进制类型;
-
TEXT类型
- 用于存储大的字符串类型;
3. DDL CURD
3.1 库的操作
- 查看所有的数据库
SHOW DATABASES
- 使用某一个数据库
USE 数据库
- 查看当前正在使用的数据库
SELECT DATABASE()
- 创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名称
- 删除数据库
DROP DATABASE IF EXIT 数据库名称
- 修改数据库的字符集和排序规则
ALTER DATABASE bilibili CHARACTER SET = utf8 COLLATE = utf8_unicode_ci;
3.2 表约束
-
主键约束
PRIMARY KEY- 一张表中,我们为了区分每一条记录的唯一性,必须有一个字段是永远不会重复,并且不会为空的,这个字段就是主键:
- 主键是表中唯一的索引;
- 并且必须是
NOT NULL的,如果没有设置NOT NULL,那么MySQL也会隐式的设置为NOT NULL - 主键也可以是多列索引,
PRIMARY KEY(key_part, ...),我们一般称之为联合主键;
- 一张表中,我们为了区分每一条记录的唯一性,必须有一个字段是永远不会重复,并且不会为空的,这个字段就是主键:
-
唯一:
UNIQUE- 使用
UNIQUE约束的字段在表中必须是不同的,且不会重复的 UNIQUE索引允许NULL包含的列具有多个值NULL;
- 使用
-
不能为空:
NOT NULL- 某些字段我们要求用户必须插入值,不可以为空,这个时候我们可以使用 NOT NULL 来约束;
-
默认值:
DEFAULT- 某些字段我们希望在没有设置值时给予一个默认值,这个时候我们可以使用 DEFAULT来完成
-
自动递增:
AUTO_INCREMENT- 某些字段我们希望不设置值时可以进行递增,比如用户的
id,这个时候可以使用AUTO_INCREMENT来完成
- 某些字段我们希望不设置值时可以进行递增,比如用户的
-
外键约束
FOREIGN KEY(外键id) REFERENCES brand(被引用的id)

3.3 表的操作
- 查看所有的数据表
SHOW TABLES;
- 查看某一个表结构
DESC user;
- 创建数据表
CREATE TABLE IF NOT EXISTS `user`(
name VARCHAR(10),
age INT,
height DOUBLE
);
- 删除表
DROP TABLE IF EXISTS `user`
- 修改表名
ALTER TABLE `user` RENAME TO `t_user`
- 优化创建的user表
CREATE TABLE IF NOT EXISTS `user`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) UNIQUE NOT NULL,
sex INT DEFAULT(0),
tel VARCHAR(20)
);
- 表字段操作
# 1.添加一个新的列
ALTER TABLE `user` ADD `publishTime` DATETIME;
# 2.删除一列数据
ALTER TABLE `user` DROP `updateTime`;
# 3.修改列的名称
ALTER TABLE `user` CHANGE `publishTime` `publishDate` DATE;
# 4.修改列的数据类型
ALTER TABLE `user` MODIFY `id` INT
4 DML CURD
- 创建新表并实现基本的CURD
CREATE TABLE IF NOT EXISTS `t_products`(
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(20) UNIQUE NOT NULL,
description VARCHAR(200) DEFAULT '',
price DOUBLE DEFAULT 0,
publishTime DATETIME
);
-- 插入表数据
INSERT INTO `t_products` (title,description, price,publishTime) VALUES('huawei1000','描述华为',8000.0,'2012-11-9')
INSERT INTO `t_products` (title, description, price, publishTime) VALUES ('华为666', '华为666只要6666', 6666, '2166-06-06');
INSERT INTO `t_products` (title, description, price, publishTime) VALUES ('xiaomi666', 'xiaomi666只要6666', 6666, '2116-06-06');
-- 删除数据
-- 1. 删除表里面的所有数据
DELETE FROM `t_products`
-- 2. 根据条件来(id)删除语句
DELETE FROM `t_products` WHERE id=2
-- 修改数据表
-- 1. 修改表里面的所有数据
UPDATE `t_products` SET price=888;
-- 2.根据条件修改表里的数据
UPDATE `t_products` SET price=888 WHERE id=5;
-- 3.根据条件修改多个数据
UPDATE `t_products` SET price=999,description='xiaomi666只要999' WHERE id=5
-- 修改数据显示最新的更新时间,并把更新的时间也做一个记录
-- TIMESTAMP数据类型被用于同时包含日期和时间部分的值:
-- CURRENT_TIMESTAMP 记录当前的时间
ALTER TABLE `t_products` ADD `updataTime`
TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
5. DQL (数据查询语言)
- SELECT用于从一个或者多个表中检索选中的行(Record)。
- 查询的格式如下

5.1 单表查询
CREATE TABLE IF NOT EXISTS `products` (
id INT PRIMARY KEY AUTO_INCREMENT,
brand VARCHAR(20),
title VARCHAR(100) NOT NULL,
price DOUBLE NOT NULL,
score DECIMAL(2,1),
voteCnt INT,
url VARCHAR(100),
pid INT
);
-- 查询
-- 1.查询所有
SELECT * FROM `products`
-- 2. 查询指定的字段 price title brand
SELECT price, title,brand FROM `products`
-- 3 别名查询 as ,同时as关键字也是可以省略...
SELECT price as productsPrice, title productsTitle,brand FROM `products`
-- 条件查询-比较运算符
SELECT*FROM `products` WHERE price<1000
SELECT*FROM `products` WHERE price=939
SELECT*FROM `products` WHERE brand='小米'
-- 查询条件,逻辑运算符
-- 1. and 关键字与 && 一样
SELECT*FROM `products` WHERE brand='小米' AND price=939
-- 2. 逻辑或 or
SELECT*FROM `products` WHERE brand='华为' || price>=8000
-- 区间范围查询
-- 1. 关键字 BETWEEN AND
SELECT*FROM `products` WHERE price>=1000 && price<=2000
SELECT*FROM `products`WHERE price BETWEEN 1000 AND 2000
-- 枚举出多个结果,其中之一
SELECT*FROM `products` WHERE brand='小米' OR brand='华为'
SELECT*FROM `products` WHERE brand IN('小米','华为')
-- 模糊查询link 与特殊符号 % 与
-- 1. 查询title以v开头
SELECT * FROM `products` WHERE title LIKE 'v%';
-- 2.查询带M的title
SELECT * FROM `products` WHERE title LIKE '%M%';
-- 3.查询带M的title必须是第三个字符 (前面字符利用 _ )既下划线
SELECT * FROM `products` WHERE title LIKE '__M%';
-- 排序 ORDER BY
-- DESC:降序排列;
-- ASC:升序排列;
-- 1.价格小于1000 降序
SELECT * FROM `products` WHERE price < 1000 ORDER BY price ASC
-- 分页查询 用法[LIMIT {[offset,] row_count | row_count OFFSET offset}]
-- 1.limit 限制20条数据
SELECT * FROM `products` LIMIT 20
-- 2. OFFSET 偏移数据 (重第41条数据开始查询,查询20条)
SELECT * FROM `products` LIMIT 20 OFFSET 40
-- 另外一种写法:offset, row_count
SELECT * FROM `products` LIMIT 40, 20
5.2 聚合查询与分组查询
- 在分组查询中 如果
Group By查询到的结果添加一些约束,那么我们可以使用:HAVING。
-- 1. 计算华为手机的平均价格
SELECT AVG(price) FROM `products` WHERE brand='华为'
-- 2.所有手机的平均分数
SELECT AVG(score) FROM `products`
-- 3.手机中最低和最高分数
SELECT MAX(score) FROM `products`;
SELECT MIN(score) FROM `products`;
-- 4.计算总投票人数
SELECT SUM(voteCnt) FROM `products`;
-- 5.计算 华为手机的个数
SELECT COUNT(*) FROM `products` WHERE brand = '华为'
-- 6. 分组 GROUP BY
-- 6.1 对品牌进行分组
SELECT brand FROM `products` GROUP BY brand
-- 6.2 分组后查看最低和最高的手机价格
-- ROUND 保留的小数ROUND(AVG(price),2)
SELECT brand,MAX(price),MIN(price) FROM `products` GROUP BY brand
-- 6.3 分组查询后进行价格最大值的约束 HAVING
SELECT brand,MAX(price) AS priceMAX,MIN(price) AS priceMin FROM `products` GROUP BY brand HAVING priceMAX > 4000
5.3 多表查询与外键约束
- 外键存在时更新和删除数据解析
RESTRICT(约束):当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。NO ACTION:和RESTRICT是一致的,即如果存在从数据,不允许删除主数据。CASCADE:当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话:- 更新:那么会更新对应的记录;
- 删除:那么关联的记录会被一起删除掉;
SET NULL:当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话,将对应的值设置为NULL
-- 多张表的查询
CREATE TABLE IF NOT EXISTS `t_song`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
duration INT DEFAULT 0,
singer VARCHAR(10)
-- 外键约束 这里的意思是singer_id 是外键约束 约束需要引入brand这个表里面的id
-- singer_id INT,
-- FOREIGN KEY(singer_id) REFERENCES brand(id)
);
INSERT INTO `t_song` (name,duration,singer) VALUES('爸爸妈妈',100,'李荣浩')
INSERT INTO `t_song` (name,duration,singer) VALUES('戒烟',120,'李荣浩')
INSERT INTO `t_song` (name,duration,singer) VALUES('从前的那个少年',100,'李荣浩')
-- 2.创建歌手表
CREATE TABLE IF NOT EXISTS `t_singer`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10),
intro VARCHAR(200)
)
-- 插入数据
INSERT INTO `t_singer` (name, intro) VALUES ('五月天', '五月天,全亚洲代表性摇滚乐团。演出足迹踏遍美国,澳洲以及全亚洲地区.')
INSERT INTO `t_singer` (name, intro) VALUES ('李荣浩', '李荣浩,全亚洲代表歌曲制作。')
-- 3.修改歌曲表
ALTER TABLE `t_song` DROP `singer`;
ALTER TABLE `t_song` ADD `singer_id` INT;
多表查询
-- 4.为了品牌单独创建一张表并插入数据
CREATE TABLE IF NOT EXISTS `brands`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10) UNIQUE NOT NULL,
website VARCHAR(100),
worldRank INT
);
INSERT INTO `brands` (name, website, worldRank) VALUES ('华为', 'www.huawei.com', 1);
INSERT INTO `brands` (name, website, worldRank) VALUES ('小米', 'www.mi.com', 10);
INSERT INTO `brands` (name, website, worldRank) VALUES ('苹果', 'www.apple.com', 5);
INSERT INTO `brands` (name, website, worldRank) VALUES ('oppo', 'www.oppo.com', 15);
INSERT INTO `brands` (name, website, worldRank) VALUES ('京东', 'www.jd.com', 3);
INSERT INTO `brands` (name, website, worldRank) VALUES ('Google', 'www.google.com', 8);
-- 4.1外键约束
-- 为products表添加brand_id
ALTER TABLE `products` ADD `brand_id` INT
-- 为外键添加约束 并引用表brand中的id字段 REFERENCES brand(id)=>引用brands中的id
ALTER TABLE `products` ADD FOREIGN KEY (brand_id) REFERENCES brands(id);
-- 4.2 将products中的brand_id关联到brand中的id的值
UPDATE `products` SET `brand_id` = 1 WHERE `brand` = '华为';
UPDATE `products` SET `brand_id` = 4 WHERE `brand` = 'OPPO';
UPDATE `products` SET `brand_id` = 3 WHERE `brand` = '苹果';
UPDATE `products` SET `brand_id` = 2 WHERE `brand` = '小米';
-- 5. 外键约束的情况下修改
UPDATE `brands` SET id=100 WHERE id=1
-- 1451 - Cannot delete or update a parent row: a foreign key constraint fails (`music_db`.`products`, CONSTRAINT `products_ibfk_1` FOREIGN KEY (`brand_id`) REFERENCES `brands` (`id`)) 报错误
-- 6. 查看表中的外键
SHOW CREATE TABLE `products`
-- 7. 删除外键
ALTER TABLE `products` DROP FOREIGN KEY products_ibfk_1;
-- 8 添加外键,当外键删除或者更新时 引用应该删除或者更新
ALTER TABLE `products` ADD FOREIGN KEY (brand_id) REFERENCES brands(id)
ON UPDATE CASCADE
ON DELETE CASCADE;
UPDATE `brands` SET id=100 WHERE id=1
5.4 多表之间的连接查询
- 在查询数据时,因为数据存在多张表格中,因此要联合多表查询
- 比如 :
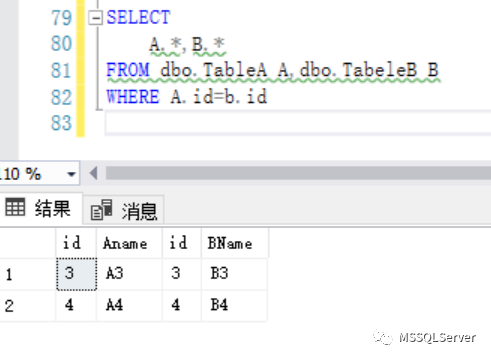
SELECT * FROM `products`, `brand`

- 这时会把两张表的数据全部查询出来 共计
648条数据, - 这就 会把第一张表中每一个条数据,和第二张表中的每一条数据结合一次;
- 这个结果我们称之为
笛卡尔乘积,也称之为直积,表示为X*Y; - 但是上面的查询结果多数是没有意义也不是我们需要的,因此这时就会采用
连接查询
5.4.1左链接查询
- 如果我们希望获取到的是左边所有的数据(以左表为主)
- 这个时候就表示无论左边的表是否有对应的brand_id的值对应右边表的id,左边的数据都会被查询出来;
- 完整写法是
LEFT [OUTER] JOIN,但是OUTER可以省略的

-- 3.左链接 LEFT [OUTER] JOIN "表" ON 连接条件
-- 这个时候就表示无论左边的表是否有对应的brand_id的值对应右边表的id,左边的数据都会被查询出来;
SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id=brands.id
-- 3.1 查询不为null有交集的数据
SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id = brands.id WHERE brands.id IS NOT NULL;
5.4.2 右连接查询
- 如果我们希望获取到的是右边所有的数据(以右表为主):
- 这个时候就表示无论左边的表中的brand_id是否有和右边表中的id对应,右边的数据都会被查询出来;
- 完整写法是
RIGHT [OUTER] JOIN,但是OUTER可以省略的;

SELECT * FROM `products` RIGHT JOIN `brands` ON products.brand_id=brands.id
5.4.3 内连接
- 上内连接是表示左边的表和右边的表都有对应的数据关联:
- 写法
CROSS JOIN或者JOIN都可以;
- 写法
SELECT * FROM `products` JOIN `brands` ON `products`.brand_id = `brands`.id
- where 写法内连接
SELECT * FROM `products`, `brand` WHERE `products`.brand_id = `brand`.id
- 上面SQL语句比较
- 内连接,代表的是在两张表连接时就会约束数据之间的关系,来决定之后查询的结果
- where条件,代表的是先计算出笛卡尔乘积,在笛卡尔乘积的数据基础之上进行where条件的帅选
5.4.4 全连接
- SQL规范中全连接是使用
FULL JOIN,但是MySQL中并没有对它的支持,我们需要使用UNION来实现:

(SELECT * FROM `products` LEFT JOIN `brands` ON `products`.brand_id = `brands`.id)
UNION
(SELECT * FROM `products` RIGHT JOIN `brands` ON `products`.brand_id = `brands`.id)
(SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id = brands.id WHERE brands.id IS NULL)
UNION
(SELECT * FROM `products` RIGHT JOIN `brands` ON products.brand_id = brands.id WHERE products.id IS NULL)
- 连接查询总结
-- 在查询到产品的同时,显示对应的品牌相关的信息,因为数据是存放在两张表中,所以这个时候就需要进行多表查询
-- //1. 这种默认做法会发生这个表的数据与另一个表的数据会相乘 得到 M*N的数据
SELECT * FROM `products`, `brands`;
-- 2.过滤查询
SELECT * FROM `products`, `brands` WHERE products.brand_id=brands.id;
-- 3.左链接 LEFT [OUTER] JOIN "表" ON 连接条件
-- 这个时候就表示无论左边的表是否有对应的brand_id的值对应右边表的id,左边的数据都会被查询出来;
SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id=brands.id
-- 3.1 查询不为null有交集的数据
SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id = brands.id WHERE brands.id IS NOT NULL;
-- 4. 右连接 RIGHT [OUTER] JOIN "表" ON 连接条件
-- 这个时候就表示无论左边的表中的brand_id是否有和右边表中的id对应,右边的数据都会被查询出来
SELECT * FROM `products` RIGHT JOIN `brands` ON products.brand_id=brands.id
-- 5. 内连接 CROSS JOIN或者 JOIN;
-- 5.1内连接效果和下面where查询效果一样的,但是做法确是不一样的
-- 5.1.1SQL语句一:内连接,代表的是在两张表连接时就会约束数据之间的关系,来决定之后查询的结果;
-- 5.1.2SQL语句二:where条件,代表的是先计算出笛卡尔乘积,在笛卡尔乘积的数据基础之上进行where条件的帅选
SELECT * FROM `products` JOIN `brands` ON `products`.brand_id = `brands`.id
SELECT * FROM `products`, `brands` WHERE `products`.brand_id = `brands`.id;
-- 6. 全连接
-- 6.1 SQL规范中全连接是使用FULL JOIN,但是MySQL中并没有对它的支持,我们需要使用 UNION 来实现
(SELECT * FROM `products` LEFT JOIN `brands` ON `products`.brand_id = `brands`.id)
UNION
(SELECT * FROM `products` RIGHT JOIN `brands` ON `products`.brand_id = `brands`.id)
(SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id = brands.id WHERE brands.id IS NULL)
UNION
(SELECT * FROM `products` RIGHT JOIN `brands` ON products.brand_id = brands.id WHERE products.id IS NULL)
5.5 多对多的表查询
参考文章-多对多解析
-- 1.多对多关系
-- 1.1. 创建学生表
CREATE TABLE IF NOT EXISTS `students`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
age INT
);
INSERT INTO `students` (name, age) VALUES('why', 18);
INSERT INTO `students` (name, age) VALUES('tom', 22);
INSERT INTO `students` (name, age) VALUES('lilei', 25);
INSERT INTO `students` (name, age) VALUES('lucy', 16);
INSERT INTO `students` (name, age) VALUES('lily', 20);
-- 1.2. 创建课程表
CREATE TABLE IF NOT EXISTS `courses`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
price DOUBLE NOT NULL
);
INSERT INTO `courses` (name, price) VALUES ('英语', 100);
INSERT INTO `courses` (name, price) VALUES ('语文', 666);
INSERT INTO `courses` (name, price) VALUES ('数学', 888);
INSERT INTO `courses` (name, price) VALUES ('历史', 80);
INSERT INTO `courses` (name, price) VALUES ('物理', 100);
-- 1.3. 学生选择的课程关系表
CREATE TABLE IF NOT EXISTS `students_select_courses`(
id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT NOT NULL,
course_id INT NOT NULL,
-- 外键约束
FOREIGN KEY (student_id) REFERENCES students(id) ON UPDATE CASCADE ON DELETE CASCADE,
FOREIGN KEY (course_id) REFERENCES courses(id) ON UPDATE CASCADE ON DELETE CASCADE
);
-- 2 选课情况
-- 2-1 why 选修了 英文和数学
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (1, 1);
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (1, 3);
-- 2-2 lilei选修了 语文和数学和历史
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (3, 2);
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (3, 3);
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (3, 4);
-- 3查询数据
-- 3.1 所有学生的选课情况(内连接) students_select_courses(内连接属性)
SELECT * FROM `students`
JOIN `students_select_courses` ON students.id= students_select_courses.student_id
JOIN `courses` ON students_select_courses.course_id=courses.id
-- 3.2 别名查询名称
SELECT
stu.name stuName , cou.name couName
FROM `students` stu
JOIN `students_select_courses` ON stu.id= students_select_courses.student_id
JOIN `courses` cou ON students_select_courses.course_id=cou.id
-- 3.3左链接
SELECT
stu.name stuName , cou.name couName
FROM `students` stu
LEFT JOIN `students_select_courses` ON stu.id= students_select_courses.student_id
LEFT JOIN `courses` cou ON students_select_courses.course_id=cou.id
-- 3.4 单个学生选择课程情况 (左连接可以保证,在学生没有选择课的情况也可以显示)
SELECT
stu.name stuName , cou.name couName
FROM `students` stu
LEFT JOIN `students_select_courses` ON stu.id= students_select_courses.student_id
LEFT JOIN `courses` cou ON students_select_courses.course_id=cou.id WHERE stu.id=1
-- 3.5 查询哪些学生没有选择课程
SELECT
stu.name stuName , cou.name couName
FROM `students` stu
LEFT JOIN `students_select_courses` ON stu.id= students_select_courses.student_id
LEFT JOIN `courses` cou ON students_select_courses.course_id=cou.id WHERE cou.id is NULL
-- 3.6查询哪些课程没有被学生选择
SELECT
stu.name stuName , cou.name couName
FROM `students` stu
RIGHT JOIN `students_select_courses` ON stu.id= students_select_courses.student_id
RIGHT JOIN `courses` cou ON students_select_courses.course_id=cou.id WHERE cou.id is NULL
6 查询对象数组
- 需求:在进行多表查询时,表1的数据将当成表2的数据子集
- 需求2:多表查询时,品牌信息表将单独放到一个对象中,并在商品表中显示
- 需求3:多表查询时,学习选课信息将放到数组对象中
JSON_OBJECT转对象JSON_ARRAYAGG和JSON_OBJECT多对多转数组
-- 1. 单表查询
SELECT * FROM `products` WHERE price>5000
-- 2. 多表查询
SELECT * FROM `products` LEFT JOIN `brands` ON products.brand_id=brands.id
WHERE price>5000
-- 3. 多表查询:品牌信息放到一个单独的对象中
-- 格式 JSON_OBJECT([key, val[, key, val] ...])
SELECT
products.id as pid,products.title as title,products.price as price,
JSON_OBJECT('id',brands.id,'name',brands.name,'website',brands.website) as brand
FROM `products` LEFT JOIN `brands` ON products.brand_id=brands.id
WHERE price>5000
-- 多对多查询
SELECT * FROM `students` as stu
LEFT JOIN `students_select_courses` as ssc ON ssc.student_id=stu.id
LEFT JOIN `courses` as cu ON ssc.course_id =cu.id WHERE cu.id IS NOT NULL
-- 多对多查询分组合并
-- JSON_ARRAYAGG 转为数组对象
SELECT
stu.id as id, stu.name as name, stu.age as age,
JSON_ARRAYAGG(JSON_OBJECT('id',cs.id,'name',cs.name,'price',cs.price)) as course
FROM `students` as stu
LEFT JOIN `students_select_courses` as ssc ON ssc.student_id=stu.id
LEFT JOIN `courses` as cs ON ssc.course_id =cs.id WHERE cs.id IS NOT NULL
GROUP BY stu.id