之前的博客中用shift ram做的均值滤波,那篇文章里讲了原理,在这里不进行重复。考虑到shift ram的深度有限,在处理高分辨率图片时可能会收到限制,所以这次采用FIFO来进行均值滤波。FIFO可以看成是一个先进先出的堆栈,有两个独立的读使能信号和写使能信号,每写入一个数据,写地址加一,每读出一个数据,读地址加一。FIFO的难点在于空信号和满信号的判断,这个可以参考网上其他的讲解原理,在进行仿真实验时可以直接调用IP核,比较方便。在通过3*3的滑动窗口对图像进行处理时,需要进行图像边界补充操作。之前用shift ram做均值滤波的那篇文章是在图像的边界进行补0,而这篇文章选择复制的方法进行边界补充。中值滤波和均值滤波大致代码相同,可以参考之前的均值滤波和中值滤波,对本文代码进行修改,实现中值滤波的功能。
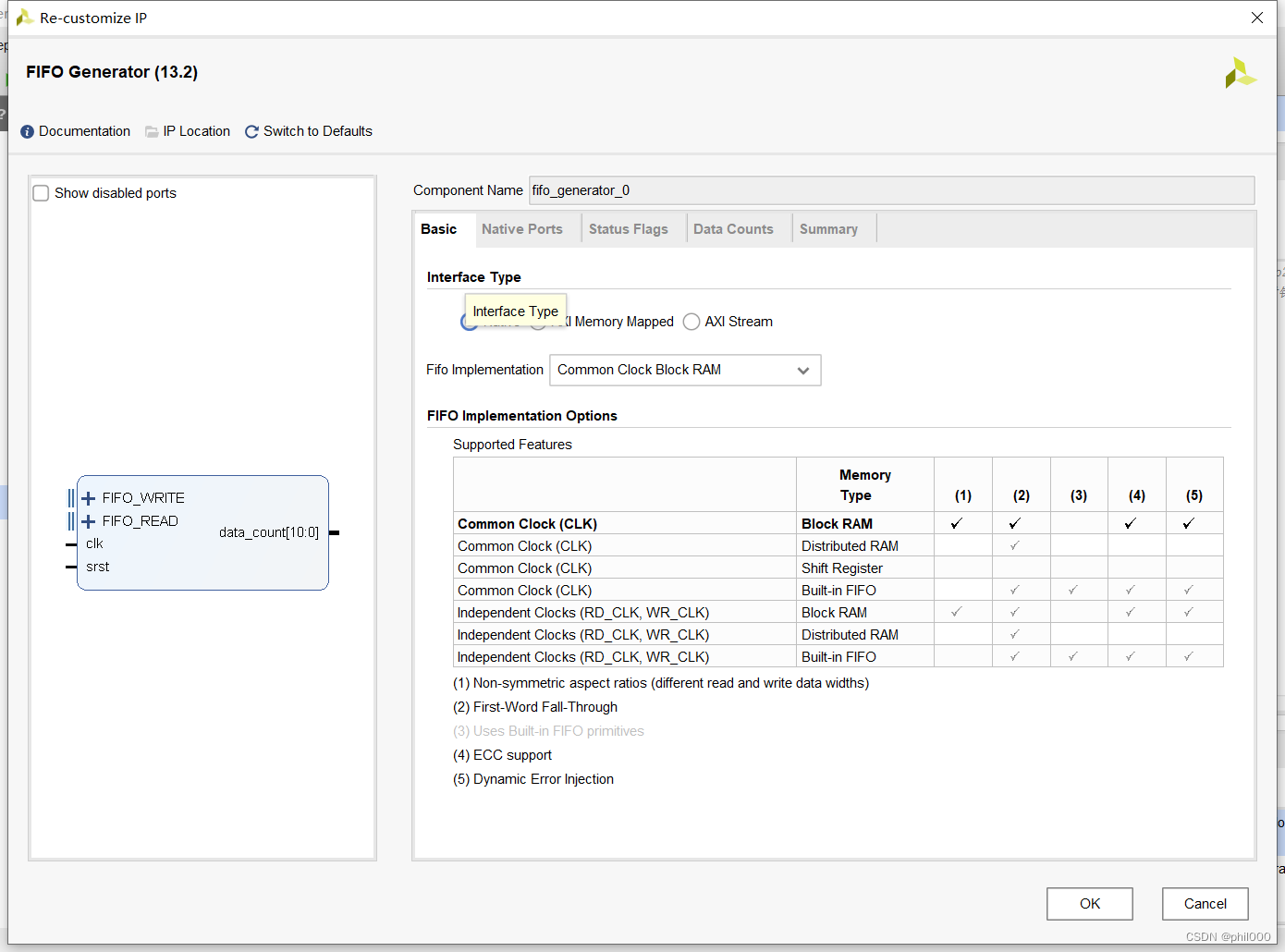
1、FIFO IP核设置
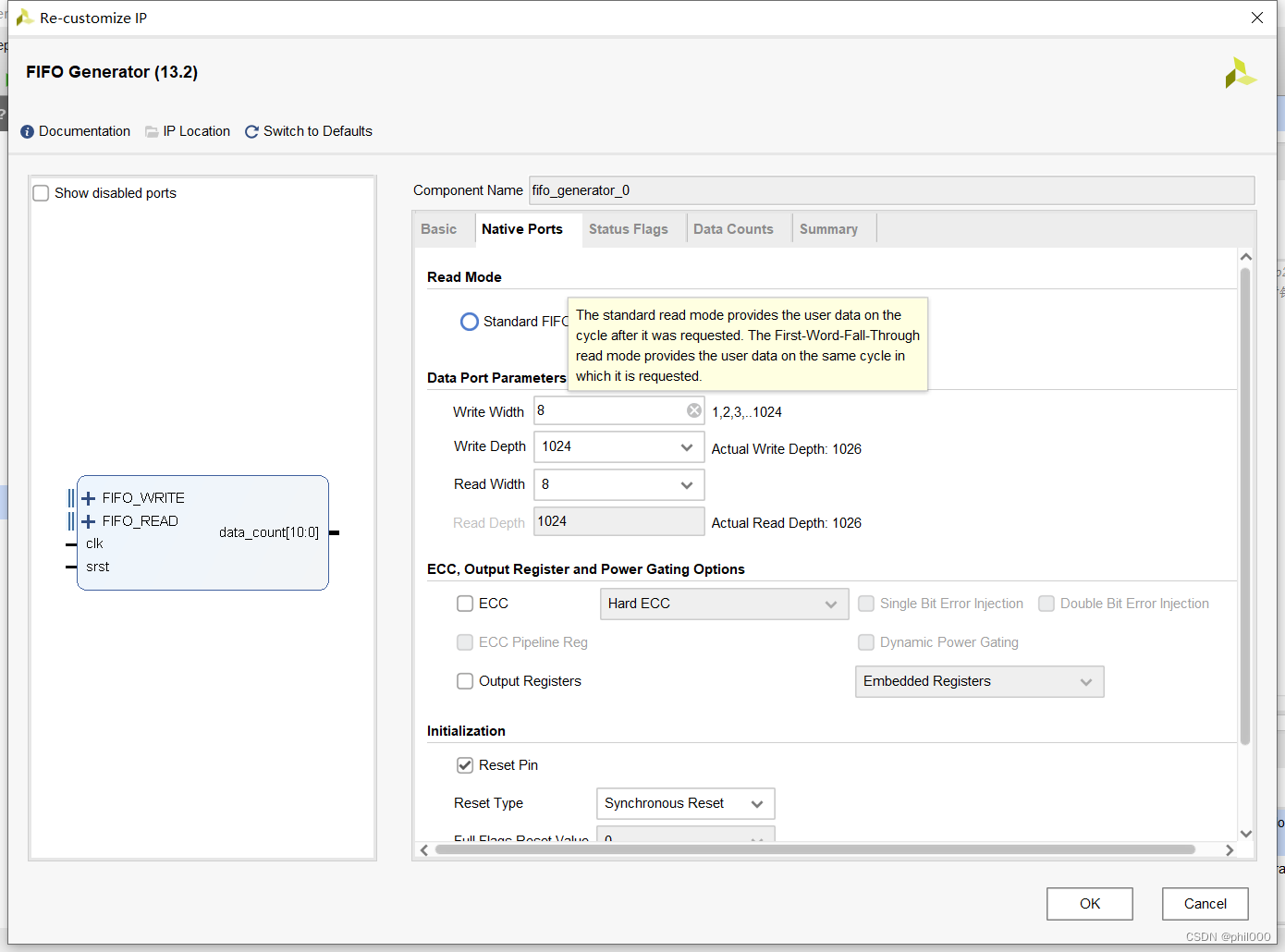
FIFO IP核的设置比较简单,要搞清楚两种Read Mode用什么区别。Standard FIFO模式,读出的数据会滞后读使能信号一个时钟周期;First Word Fall Through模式,第一个写入的数据将被提前读出来放在数据线上(也可以理解成放在寄存器里)。这两个模式都可以完成功能,只是在最后信号对齐上延迟的时钟周期不同,本文选择First Word Fall Through模式。数据的宽度和深度根据处理图片的大小更改即可,IP核配置如下:

2、边界复制
边界复制需要对图像的第一行、最后一行、第一列、最后一列进行复制。加入一个行计数器,在行计数器为1时,将row2_data复制给row1_data,来完成第一行的复制(row3_data代表输入图像的数据,row2_data代表前一行数据,row1_data代表前两行数据)。在图像最后一行数据输入完成后,将row2_data数据复制给row3_data,完成最后一行的复制。对列边界的复制在计算3*3矩阵每一行数据和的时候完成。加入一个列计数器,当列计数器为1时,将3*3矩阵的第一列的值用第二列代替,完成第一列的复制。当列计数器为640(图像宽度)时,将3*3矩阵的第二列的值用第三列代替,完成最后一列的复制。
3、代码
3*3矩阵生成模块
module generate_3_3(
input clk, //cmos video pixel clock
input rst_n, //global reset
//Image data prepred to be processd
input per_frame_vsync, //Prepared Image data vsync valid signal
input per_frame_href, //Prepared Image data href vaild signal
input per_frame_clken, //Prepared Image data output/capture enable clock
input [7:0] per_img_Y, //Prepared Image brightness input
//Image data has been processd
output matrix_frame_vsync, //Prepared Image data vsync valid signal
output matrix_frame_href, //Prepared Image data href vaild signal
output matrix_frame_clken, //Prepared Image data output/capture enable clock
output reg [7:0] matrix_p11, matrix_p12, matrix_p13,
output reg [7:0] matrix_p21, matrix_p22, matrix_p23,
output reg [7:0] matrix_p31, matrix_p32, matrix_p33
);
parameter [10:0] delay=11'd1310;
wire [7:0] row1_data;
wire [7:0] row2_data;
wire [7:0] row3_data;
wire [7:0] row1_data1;
wire [7:0] row2_data1;
wire row2_rd_en;
wire row1_rd_en;
wire row2_wr_en;
wire row1_wr_en;
wire [9:0] data_count1,data_count2;
reg [8:0] row_cnt;
reg per_frame_href_delay;
wire [7:0] fifo_in;
reg [delay-1:0] per_frame_href_dl;
reg [delay-1:0] per_frame_clken_dl;
reg [delay-1:0] per_frame_vsync_dl;
wire per_frame_href_;
wire per_frame_clken_;
wire per_frame_vsync_;
assign row2_rd_en=(per_frame_clken||per_frame_clken_)&&(data_count2==10'd640);
assign row1_rd_en=(per_frame_clken||per_frame_clken_)&&(data_count1==10'd640);
assign row2_wr_en=(per_frame_clken||per_frame_clken_);
assign row1_wr_en=(per_frame_clken||per_frame_clken_)&&(data_count2==10'd640);
assign row3_data=(per_frame_href_==1&&per_frame_href==0)?row2_data:per_img_Y; //在图像后面延时了一行行有效信号,在这一行把row2_data复制,实现在图像下方通过复制补边界的操作
assign row1_data=(row_cnt==1||row_cnt==0)?row2_data1:row1_data1; //在行计数等于1之前,将row2_data1的值给row1_data,实现在图像上方通过复制补一行边界
assign row2_data=row2_data1;
assign fifo_in=(row_cnt==480)?0:per_img_Y; //在图像最后一行的后面再向fifo中送入一行0,使fifo多工作一行,以便在图像的下方补一行边界
fifo_generator_0 u2 (
.clk(clk), // input wire clk
.srst(!rst_n), // input wire srst
.din(fifo_in), // input wire [7 : 0] din
.wr_en(row2_wr_en), // input wire wr_en
.rd_en(row2_rd_en), // input wire rd_en
.dout(row2_data1), // output wire [7 : 0] dout
.full(), // output wire full
.empty(), // output wire empty
.data_count(data_count2) // output wire [9 : 0] data_count
);
fifo_generator_0 u1 (
.clk(clk), // input wire clk
.srst(!rst_n), // input wire srst
.din(row2_data1), // input wire [7 : 0] din
.wr_en(row1_wr_en), // input wire wr_en
.rd_en(row1_rd_en), // input wire rd_en
.dout(row1_data1), // output wire [7 : 0] dout
.full(), // output wire full
.empty(), // output wire empty
.data_count(data_count1) // output wire [9 : 0] data_count
);
wire read_frame_href ;
wire read_frame_clken;
reg [1:0] per_frame_vsync_r;
reg [1:0] per_frame_href_r;
reg [1:0] per_frame_clken_r;
assign read_frame_href = per_frame_href_r[0] ;
assign read_frame_clken = per_frame_clken_r[0];
assign matrix_frame_vsync = per_frame_vsync_r[1];
assign matrix_frame_href = per_frame_href_r[1] ;
assign matrix_frame_clken = per_frame_clken_r[1];
//delay 2 clk
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
per_frame_vsync_r <= 0;
per_frame_href_r <= 0;
per_frame_clken_r <= 0;
end
else begin
per_frame_vsync_r <= { per_frame_vsync_r[0], per_frame_vsync_ };
per_frame_href_r <= { per_frame_href_r[0], per_frame_href_ };
per_frame_clken_r <= { per_frame_clken_r[0], per_frame_clken_ };
end
end
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
per_frame_href_dl<=0;
per_frame_clken_dl<=0;
per_frame_vsync_dl<=0;
end
else begin
per_frame_href_dl<={per_frame_href_dl[delay-2:0],per_frame_href};
per_frame_clken_dl<={per_frame_clken_dl[delay-2:0],per_frame_clken};
per_frame_vsync_dl<={per_frame_vsync_dl[delay-2:0],per_frame_vsync};
end
end
assign per_frame_href_=per_frame_href_dl[delay-1];
assign per_frame_clken_=per_frame_clken_dl[delay-1];
assign per_frame_vsync_=per_frame_vsync_dl[delay-1];
always @(posedge clk) begin
per_frame_href_delay<=per_frame_href_;
end
//行计数
always @(posedge clk or negedge rst_n) begin
if(!rst_n||~per_frame_vsync_)
row_cnt<=9'd0;
else if(~per_frame_href_delay&per_frame_href_) begin
if(row_cnt==9'd480)
row_cnt<=9'd1;
else
row_cnt<=row_cnt+1;
end
else
row_cnt<=row_cnt;
end
//generate the 3X3 matrix
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'h0;
end
else if(per_frame_href_||read_frame_href) begin
if(per_frame_clken_) begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data};
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
endmodule均值滤波模块
module mean_filter(
input clk,
input rst_n,
input per_frame_vsync,
input per_frame_href,
input per_frame_clken,
input [7:0] per_img_Y,
output post_frame_vsync,
output post_frame_href,
output post_frame_clken,
output [7:0] post_img_data
);
parameter [10:0] delay=11'd1310;
wire matrix_frame_clken;
wire matrix_frame_href;
wire matrix_frame_vsync;
wire [7:0] matrix_p11;
wire [7:0] matrix_p12;
wire [7:0] matrix_p13;
wire [7:0] matrix_p21;
wire [7:0] matrix_p22;
wire [7:0] matrix_p23;
wire [7:0] matrix_p31;
wire [7:0] matrix_p32;
wire [7:0] matrix_p33;
wire [7:0] img_data;
reg [11:0] add_p1;
reg [11:0] add_p2;
reg [11:0] add_p3;
reg [11:0] add_all;
reg [9:0] col_cnt;
generate_3_3 #(delay) u(
.clk(clk),
.rst_n(rst_n),
.per_frame_vsync(per_frame_vsync),
.per_frame_href(per_frame_href),
.per_frame_clken(per_frame_clken),
.per_img_Y(per_img_Y),
.matrix_frame_vsync ( matrix_frame_vsync ),
.matrix_frame_href ( matrix_frame_href ),
.matrix_frame_clken ( matrix_frame_clken ),
.matrix_p11 ( matrix_p11 ),
.matrix_p12 ( matrix_p12 ),
.matrix_p13 ( matrix_p13 ),
.matrix_p21 ( matrix_p21 ),
.matrix_p22 ( matrix_p22 ),
.matrix_p23 ( matrix_p23 ),
.matrix_p31 ( matrix_p31 ),
.matrix_p32 ( matrix_p32 ),
.matrix_p33 ( matrix_p33 )
);
//列计数
always @(negedge matrix_frame_clken or negedge rst_n) begin
if(!rst_n)
col_cnt<=10'd0;
else begin
if(col_cnt==640)
col_cnt<=10'd1;
else
col_cnt<=col_cnt+1;
end
end
//step1:add every href
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
add_p1<=12'd0;
add_p2<=12'd0;
add_p3<=12'd0;
end
else if(col_cnt==10'd1) begin
add_p1<=matrix_p12+matrix_p12+matrix_p13;
add_p2<=matrix_p22+matrix_p22+matrix_p23;
add_p3<=matrix_p32+matrix_p32+matrix_p33;
end
else if(col_cnt==10'd640) begin
add_p1<=matrix_p12+matrix_p13+matrix_p13;
add_p2<=matrix_p22+matrix_p23+matrix_p23;
add_p3<=matrix_p32+matrix_p33+matrix_p33;
end
else begin
add_p1<=matrix_p11+matrix_p12+matrix_p13;
add_p2<=matrix_p21+matrix_p22+matrix_p23;
add_p3<=matrix_p31+matrix_p32+matrix_p33;
end
end
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
add_all<=12'd0;
end
else begin
add_all<=add_p1+add_p2+add_p3;
end
end
assign img_data=add_all/9;
//延时2个像素时钟周期(4个系统时钟周期),因为对3*3矩阵内的数进行计算时,当每一行第二个像素送入时,我们计算的结果替代的是第一个像素的值
//所以输出的像素时钟比3*3矩阵输入的像素时钟延迟一个像素时钟周期,计算add_p1、add_p2、add_p3时延迟了一个系统时钟周期,计算add_all又延时了一个系统时钟周期
//计算出add_all总共延时了两个系统时钟周期即一个像素时钟周期,最后总共延时2个像素时钟周期,完成数据对齐
reg [3:0] post_frame_clken_dy;
reg [3:0] post_frame_href_dy;
reg [3:0] post_frame_vsync_dy;
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
post_frame_clken_dy<=4'd0;
post_frame_href_dy<=4'd0;
post_frame_vsync_dy<=4'd0;
end
else begin
post_frame_clken_dy<={post_frame_clken_dy[2:0],matrix_frame_clken};
post_frame_href_dy<={post_frame_href_dy[2:0],matrix_frame_href};
post_frame_vsync_dy<={post_frame_vsync_dy[2:0],matrix_frame_vsync};
end
end
assign post_frame_clken=post_frame_clken_dy[3];
assign post_frame_href=post_frame_href_dy[3];
assign post_frame_vsync=post_frame_vsync_dy[3];
assign post_img_data=post_frame_href?img_data:0;
endmodule4、结果图