这篇干货很硬,喜欢的小伙伴点个赞/收藏,持续更新!
文章目录
- 1.前言
- 1.1 GBM的介绍
- 1.2 GBM的应用
- 2. scikit-learn实战演示
- 2.1 分类问题
- 2.2 回归问题
- 3. GBM超参数
- 3.1 决策树数量(n_estimators)
- 3.2 样本数量(subsample)
- 3.3 特征数量(max_features)
- 3.4 学习率(learning_rate)
- 3.5 决策树深度(max_depth)
- 4.讨论
1.前言
1.1 GBM的介绍
梯度提升机(Gradient Boosting Machine,简称GBM)是一种强大的机器学习算法,它是集成学习的一种形式。GBM在解决分类和回归问题上表现优异,是数据科学领域中常用的算法之一。GBM通过组合多个弱学习器(通常是决策树)来构建一个强大的预测模型。训练过程采用梯度提升技术,逐步改进模型的预测能力。每一轮迭代中,新的弱学习器被训练来纠正前一轮模型的错误,以尽可能减少模型对数据的残差。最终,所有弱学习器的结果加权融合,得到最终的预测结果。
优点:
-
高预测准确性:GBM在许多数据集上表现出色,通常可以获得较高的预测准确性。
-
处理非线性关系:GBM能够很好地捕捉复杂数据中的非线性关系。
-
鲁棒性:GBM对于噪声和异常值相对较为鲁棒,它可以通过组合多个模型来减少单个模型的过拟合风险。
-
特征重要性评估:GBM可以提供每个特征的重要性评估,帮助理解数据中哪些特征对预测影响最大。
-
可扩展性:GBM可以适用于大规模数据集,并且在现代计算平台上可以高效实现。
缺点:
-
训练时间较长:相比于一些简单的线性模型,GBM的训练时间可能较长,特别是在复杂模型和大规模数据集上。
-
超参数调整:GBM的性能对于一些超参数(如学习率、树的数量等)较为敏感,需要仔细的调整和优化。
-
可能出现过拟合:如果不谨慎设置超参数或者训练集数据较小,GBM有可能出现过拟合,导致在新数据上表现不佳。
-
不适合高维稀疏数据:对于高维稀疏数据,GBM的表现可能不如一些专门针对此类数据设计的算法。
1.2 GBM的应用
-
金融领域:在金融领域,GBM广泛用于信用评分模型。通过分析客户的历史信用信息和其他相关特征,GBM可以预测客户的信用风险,帮助金融机构做出更明智的信贷决策。此外,GBM还可以用于股票价格预测,利用历史股票价格数据和市场指标,来预测未来股票价格的走势。
-
保险业:在保险行业,GBM可以用于风险评估和理赔预测。通过分析客户的个人信息、保险历史和其他风险因素,GBM可以评估客户的风险水平,并帮助保险公司制定适当的保险政策和定价。此外,GBM还可以预测保险索赔的概率,帮助保险公司更好地管理理赔流程。
-
电子商务:在电子商务中,GBM常用于推荐系统。通过分析用户的购买历史、浏览行为和其他行为特征,GBM可以为用户推荐个性化的产品或服务,提高用户的购买转化率和满意度。此外,GBM还可以预测广告点击率,帮助广告商优化广告投放策略。
-
医疗和生物科学:在医疗领域,GBM可以应用于疾病预测和诊断支持。通过分析患者的临床数据、医学影像和基因信息,GBM可以预测患者是否患有某种疾病,并提供辅助诊断的信息。此外,GBM还可以用于药物发现,通过分析药物分子和生物活性数据,来预测潜在的新药物候选。
-
社交网络:在社交网络中,GBM可以用于用户行为建模和社交关系分析。通过分析用户在社交网络中的互动行为和内容分享,GBM可以预测用户的兴趣和行为,为社交网络平台提供更个性化的服务和推荐。
-
自然语言处理:在自然语言处理领域,GBM可以用于情感分析和文本分类。通过分析文本中的情感和语义信息,GBM可以判断文本的情感倾向或者将文本分类到不同的类别中,例如新闻分类、垃圾邮件识别等。
-
工业和制造:在工业领域,GBM可以应用于设备故障预测和质量控制。通过分析设备的传感器数据和工艺参数,GBM可以预测设备是否会出现故障,并提前采取维修措施。此外,GBM还可以用于质量控制,帮助检测生产过程中的缺陷和不良品。
-
能源和环境:在能源和环境领域,GBM可以应用于能源消耗预测和气候模式预测。通过分析能源消耗的历史数据和影响因素,GBM可以预测未来的能源需求,有助于能源规划和管理。此外,GBM还可以用于气候模式预测,帮助预测天气变化和自然灾害风险。
-
交通和物流:在交通和物流行业,GBM可用于交通流量预测和路况评估。通过分析历史交通数据和道路条件,GBM可以预测未来的交通流量和路况,帮助交通管理部门优化交通调度和规划。
2. scikit-learn实战演示
GradientBoostingRegressor和GradientBoostingClassifier是Python中scikit-learn库中梯度提升机(Gradient Boosting Machine,GBM)的两个主要类。
GradientBoostingRegressor是scikit-learn中用于回归问题的梯度提升机类。它用于解决连续型目标变量的预测问题。通过拟合一系列的回归树(决策树用于回归任务),GBM可以对数据中的非线性关系进行建模,并产生连续型的预测结果。例如,可以使用GradientBoostingRegressor来预测房屋价格、销售量等连续性目标变量。
GradientBoostingClassifier是scikit-learn中用于分类问题的梯度提升机类。它用于解决离散型目标变量的预测问题,将样本划分到不同的类别中。在训练过程中,GBM使用决策树作为弱学习器,来对类别进行预测。例如,可以使用GradientBoostingClassifier来进行垃圾邮件识别、肿瘤类型分类等分类任务。
2.1 分类问题
创建数据集,生成一个包含1000个样本和20个特征的合成分类数据集。其中有15个特征是有信息量的特征,5个特征是冗余的特征。
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
print(X.shape, y.shape)
# (1000, 20) (1000,)
构建模型,10折交叉,重复3次
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score, RepeatedStratifiedKFold
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
model = GradientBoostingClassifier()
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
print('Mean Accuracy: %.3f (%.3f)' % (np.mean(n_scores), np.std(n_scores)))
# Mean Accuracy: 0.899 (0.030)
二分类数据预测
from sklearn.datasets import make_classification
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
model = GradientBoostingClassifier()
model.fit(X, y)
row = [0.2929949, -4.21223056, -1.288332, -2.17849815, -0.64527665, 2.58097719, 0.28422388, -7.1827928, -1.91211104, 2.73729512, 0.81395695, 3.96973717, -2.66939799, 3.34692332, 4.19791821, 0.99990998, -0.30201875, -4.43170633, -2.82646737, 0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])
# Predicted Class: 1
2.2 回归问题
创建数据集
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
print(X.shape, y.shape)
# (1000, 20) (1000,)
构建模型,10折交叉,重复3次
from numpy import mean, std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score, RepeatedKFold
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
model = GradientBoostingRegressor()
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
# MAE: -62.440 (3.259)
模型预测
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
model = GradientBoostingRegressor()
model.fit(X, y)
row = [0.20543991, -0.97049844, -0.81403429, -0.23842689, -0.60704084, -0.48541492, 0.53113006, 2.01834338, -0.90745243, -1.85859731, -1.02334791, -0.6877744, 0.60984819, -0.70630121, -1.29161497, 1.32385441, 1.42150747, 1.26567231, 2.56569098, -0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0])
# Prediction: 37
3. GBM超参数
梯度提升(Gradient Boosting)是通过组合多个弱学习器(通常是决策树)来构建一个强大的预测模型。在梯度提升算法中,有一些关键的超参数需要设置,以影响模型的性能和训练过程。以下是梯度提升算法的一些重要超参数,这里只演示最常用的5个。
| 超参数 | 描述 |
|---|---|
| n_estimators | 集成中弱学习器(通常是决策树)的数量。更多的学习器可能导致过拟合,较少的学习器可能导致欠拟合。 |
| learning_rate | 控制每个弱学习器对模型的贡献。较小的学习率使得每个学习器的权重调整更小,有助于提高模型的鲁棒性,但可能需要更多的迭代。较大的学习率可能导致过拟合。 |
| max_depth | 决策树的最大深度,用于控制弱学习器(决策树)的复杂度。较大的最大深度允许决策树更多的分支,可能导致过拟合。较小的最大深度有助于防止过拟合。 |
| min_samples_split | 决策树节点分裂所需的最小样本数。增加该值可降低模型复杂度,减少过拟合的可能性。 |
| min_samples_leaf | 叶子节点所需的最小样本数。增加该值可降低模型复杂度,减少过拟合的可能性。 |
| subsample | 控制每个弱学习器在训练时所使用的样本比例。取值小于1.0时,表示使用部分样本进行训练,有助于降低方差,增加模型的泛化能力。 |
| max_features | 决定每个决策树节点在分裂时考虑的特征数量。 |
这些超参数在梯度提升机中非常重要,影响模型的复杂度、拟合性能以及泛化能力。在调参时,需要根据具体的数据集和问题选择合适的超参数取值,以获得最优的模型性能。
### 总模版,后续
from numpy import mean, std, arange
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score, RepeatedStratifiedKFold
from sklearn.ensemble import GradientBoostingClassifier
from matplotlib import pyplot
# 获取数据集
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# 获取待评估的模型列表
# ——————————————————
# 替换内容,直接复制每小段超参数建模示例进来运行即可
# ——————————————————
# 使用交叉验证评估给定模型
def evaluate_model(model, X, y):
# 定义评估过程
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 评估模型并收集结果
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# 获取数据集
X, y = get_dataset()
# 获取待评估的模型列表
models = get_models()
# 评估模型并存储结果
results, names = list(), list()
for name, model in models.items():
# 评估模型
scores = evaluate_model(model, X, y)
# 存储结果
results.append(scores)
names.append(name)
# 输出性能评估结果
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# 绘制模型性能箱线图进行对比
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.xlabel('Sample Ratio')
pyplot.ylabel('Accuracy')
pyplot.title('Gradient Boosting Performance Comparison')
pyplot.show()
3.1 决策树数量(n_estimators)
指定构建的弱学习器的数量,也称为迭代次数。更多的迭代次数会增加模型的复杂度,但可能会导致过拟合。该参数默认100,这里演示10 到 5,000 的变化。
# 获取待评估的模型列表
def get_models():
models = dict()
# 定义不同树数量
n_trees = [10, 50, 100, 500, 1000, 5000]
for n in n_trees:
models[str(n)] = GradientBoostingClassifier(n_estimators=n)
return models

3.2 样本数量(subsample)
控制每个弱学习器在训练过程中所使用的样本比例。取值小于1.0时,表示使用部分样本进行训练,这样可以降低方差,增加模型的泛化能力。
# 获取待评估的模型列表
def get_models():
models = dict()
# 探索不同的样本比例,从10%到100%,步长为10%
for i in arange(0.1, 1.1, 0.1):
key = '%.1f' % i
models[key] = GradientBoostingClassifier(subsample=i)
return models

3.3 特征数量(max_features)
决定每个决策树节点在分裂时考虑的特征数量。它可以影响模型的随机性,较小的值可能有助于增加模型的多样性,较大的值可能增加拟合性能。
# 获取要评估的模型列表
def get_models():
models = dict()
# 探索特征数量从1到20
for i in range(1, 21):
models[str(i)] = GradientBoostingClassifier(max_features=i)
return models

3.4 学习率(learning_rate)
每个弱学习器对模型的贡献,也称为学习率。较小的学习率会使得每个学习器的权重调整较小,有助于提高模型的鲁棒性,但可能需要更多的迭代次数。
# 获取要评估的模型列表
def get_models():
models = dict()
# 定义要探索的学习率
learning_rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for rate in learning_rates:
key = '%.4f' % rate
models[key] = GradientBoostingClassifier(learning_rate=rate)
return models

3.5 决策树深度(max_depth)
决策树的最大深度,用于控制弱学习器(决策树)的复杂度,默认为3。较大的最大深度允许决策树更多的分支,可能导致过拟合。较小的最大深度有助于防止过拟合。
# 获取要评估的模型列表
def get_models():
models = dict()
# 定义要探索的树深度范围
for depth in range(1, 11):
models[str(depth)] = GradientBoostingClassifier(max_depth=depth)
return models

4.讨论
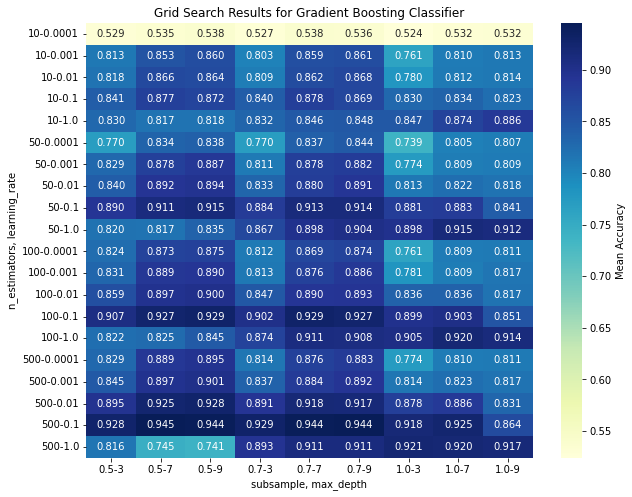
这里将n_estimators,subsample,learning_rate,max_depth四个参数组合做了个热图,也能大致了解哪个指标对结果的影响更大。
梯度提升是指一类可用于分类或回归预测建模问题的集成机器学习算法。集成是根据决策树模型构建的。一次将一棵树添加到集合中,并进行拟合以纠正先前模型产生的预测错误。这是一种称为 boosting 的集成机器学习模型。使用任意可微损失函数和梯度下降优化算法来拟合模型。这使得该技术被称为“梯度增强”,因为随着模型的拟合,损失梯度被最小化,就像神经网络一样。