全文共1w余字,预计阅读时间约25~40分钟 | 满满干货(附代码案例),建议收藏!
本文目标:围绕Chat模型的Function calling功能进行更高层次的函数封装,并实现一个能够调用外部函数的多轮对话任务
写在前面:本文内容的复现过程,如果有条件的,建议使用gpt 4接口,输出稳定,gpt3.5不太稳定,但运行几次也能得到标准结果
如果存在Rate limit 报错,是OpenAI的速率限制,可以绑定信用卡后解除,以保证程序正常运行
代码下载地址
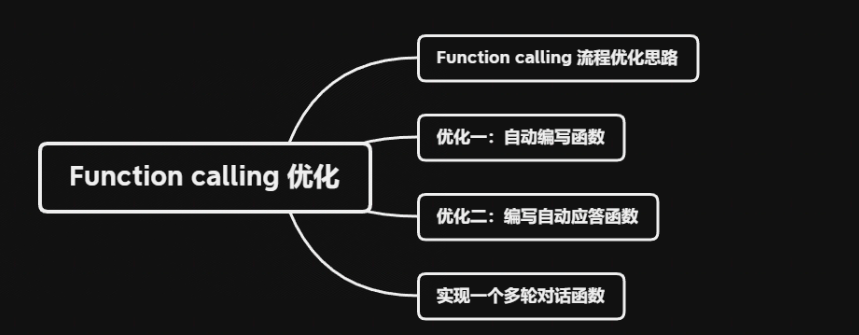
一、Function calling 流程优化思路
在大模型开发(十一):Chat Completions模型的Function calling功能详解中,已经详细解释了Function calling的用法,回顾一下其函数流程是这样的:
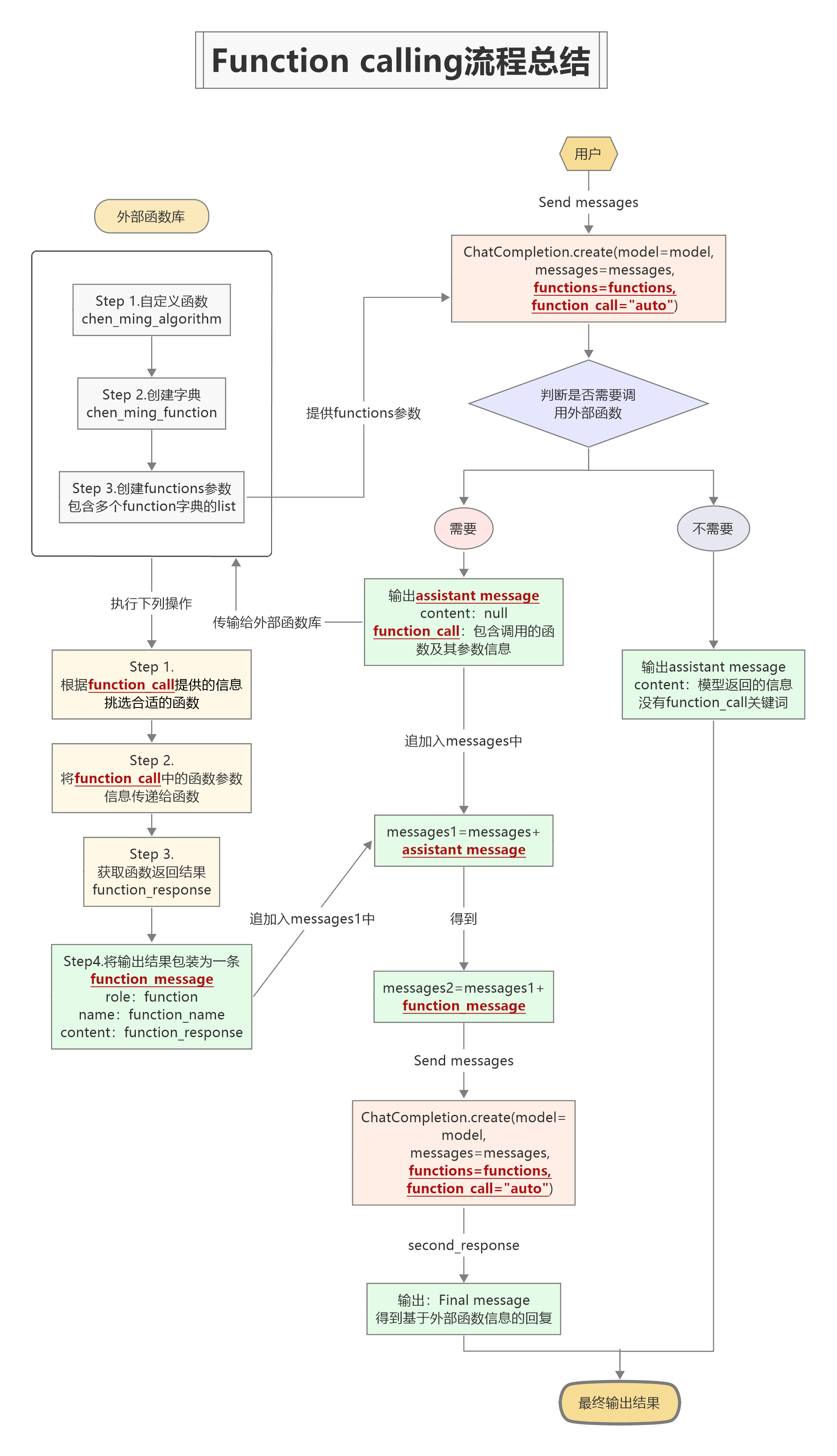
对于上述这种原始的Function calling实现流程而言,尽管过程清晰,但要完整跑通一个流程所涉及到的代码环节较多,在高频调用该功能的场景中,这个复杂的代码流程会极大程度影响使用和开发效率。因此,需要考虑如何对上述流程进行优化。
总的来说,优化的方向有两个:
- 优化functions参数的编写效率
比如之前写到的这个外部函数:
def calculate_algorithm(data):
"""
该函数定义了一种特殊的数据集计算过程
:param data: 必要参数,表示带入计算的数据表,用字符串进行表示
:return:函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象
"""
data = io.StringIO(data)
df_new = pd.read_csv(data, sep='\s+', index_col=0)
res = np.sum(df_new, axis=1) - 1
return json.dumps(res.to_string())
available_functions = {
"calculate_algorithm": calculate_algorithm,
}
calculate_function = {"name": "calculate_algorithm",
"description": "用于执行计算算法的函数,定义了一种特殊的数据集计算过程",
"parameters": {"type": "object",
"properties": {"data": {"type": "string",
"description": "执行计算算法的数据集"},
},
"required": ["data"],
},
}
functions = [calculate_function]
functions

在手动实现Function calling功能这个过程中,将外部函数信息输入到functions参数中的过程非常复杂,需要涉及到大量的JSON Schema编写过程,并且,如果函数库中包含大量函数,逐个编写JSON Schema会非常复杂。
因此**找到一种方法,大幅降低Chat模型读取外部函数的门槛,是非常有必要的。**例如当编写完calculate_algorithm(计算函数)后模型就能让大语言模型自动识别这个函数并创建相应的functions参数,而不用手动对其进行编写。
2、优化second response流程
在做交互需求的开发中,其实并不关心向大模型提问时中间有几次调用模型的过程,只希望在一次对话中快速完成需求,即无论是否进行外部函数调用,都希望能够在一次代码交互过程中完成对话任务。
因此完成对对话流程进行更高层次的封装,是非常有必要的。也就是说如果对话过程需要调用Function calling,能自动执行second response,并最终在一次对话中返回最终结果。
接下来就针对这两方面依次做一下优化。
二、优化一:自动编写函数
functions参数其实是非常一类高度结构化的参数,而参数中的核心信息其实都来源于函数本身:

因此,functions参数的编写其实本质上就是一个翻译的过程,将函数原始的说明信息翻译成functions参数要求的格式。
而对于大语言模型(LLMs)来说,它对JSON Schema格式的是非常熟悉的:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "请问什么是JSON Schema?"}
]
)
response.choices[0].message['content']
看下它的输出:
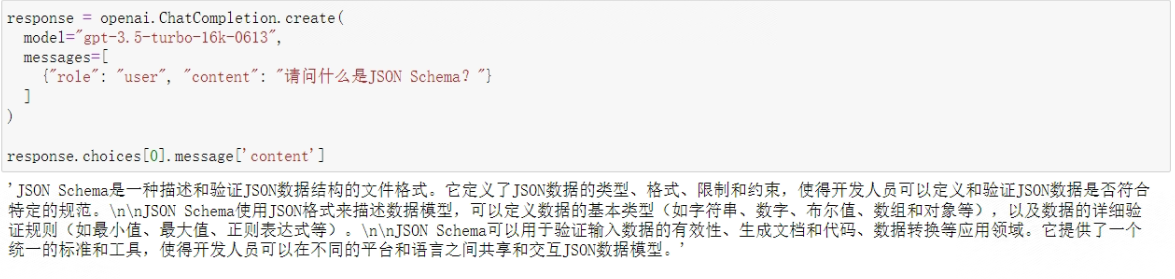
能够看出,Chat模型是具备JSON Schema相关知识储备的。由此不难判断,只要详细的编写每个函数的函数说明,并且通过合理的提示让模型理解functions参数结构,同时借助模型本身对JSON Schema的理解,是能够让Chat模型自主读取并创建函数的functions参数的。
尝试实现一下:
- Step 1:提取函数说明
首先通过inspect库中的getdoc方法来将函数说明提取为字符串,代码如下:
import inspect
function_description = inspect.getdoc(calculate_algorithm)
function_description
看下提取结果:

inspect库中包含了非常多用于辅助验证函数功能的函数,能够非常高效的执行获取函数参数、函数源码、函数说明等功能。
- Step 2: 测试是否能将函数参数格式转化成JSON Schema类型
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "以下是计算函数的函数说明:%s" % function_description},
{"role": "user", "content": "请帮我编写一个JSON Schema对象,用于说明计算函数的参数输入规范。输出结果要求是JSON Schema格式的JONS类型对象,不需要任何前后修饰语句。其中description部分请用中文"}
]
)
response.choices[0].message['content']
看下输出结果:
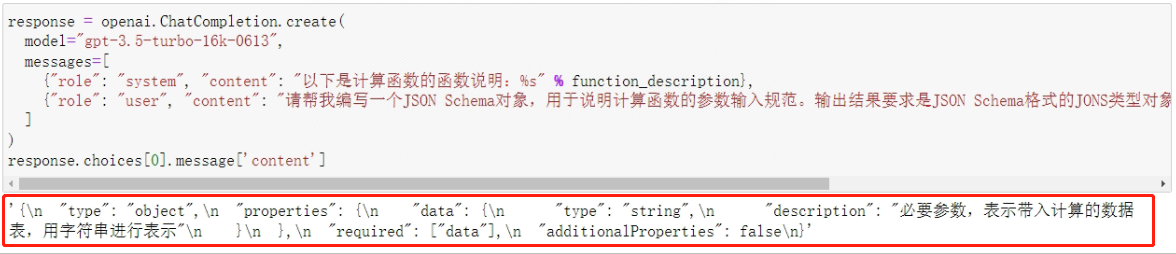
Chat函数的输出结果是JSON格式对象,通过json.loads方法将其转化为python对象,代码如下:
json.loads(response.choices[0].message['content'])
看下结果:
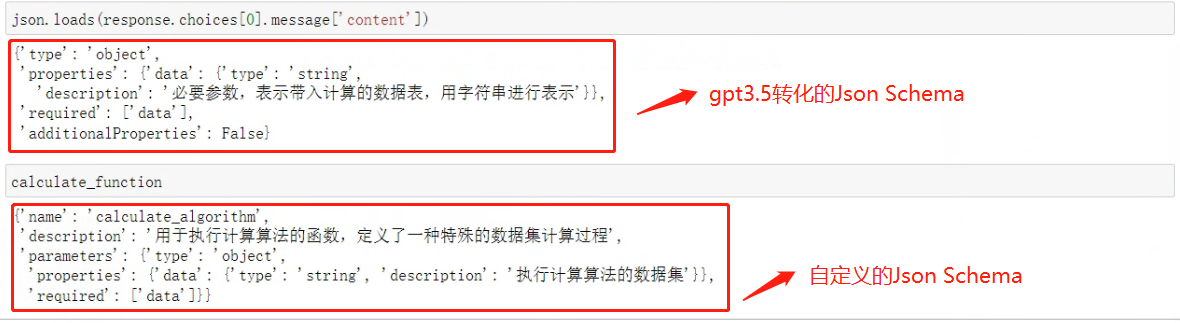
对比手动编写的结果,其实模型能够根据函数的参数说明正确识别计算函数的参数格式,并输出对应的JSON Schema对象。
'additionalProperties’关键词表示不存在另一种输入格式,这两个关键词对所描述的对象结构类型并没有任何影响。
- Step 3:编写自动编写functions参数函数
尝试通过合理的提示,让模型能够自动编写functions参数,以下是Chat模型提示过程,经测试gpt3.5使用Zero-shot输出极不稳定,所以使用Few-shot提示:
# 定义Few-shot提示
Q1_system_prompt = '以下是某函数说明:%s' % function_description
Q1_user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\
1.字典总共有三个键值对;\
2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\
3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\
4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\
5.输出结果必须是一个JSON格式的字典,且不需要任何前后修饰语句' % calculate_algorithm.__name__
A1_system_prompt = "测试算法函数,该函数定义了一种特殊的数据集计算过程\n:param data: 必要参数,要求字符串类型,表示带入计算的数据表\n:return:测试函数计算后的结果,返回结果为json字符串类型对象"
A1_user_prompt = "{'name': 'testg_algorithm', \
'description': '测试算法函数,该函数定义了一种特殊的数据集计算过程', \
'parameters': {'title': '测试算法函数参数', \
'type': 'object', \
'properties': {'data': {'description': '字符串类型的数据表', 'type': 'string'}}, \
'required': ['data']}}"
system_prompt = '以下是某函数说明:%s' % function_description
user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\
1.字典总共有三个键值对;\
2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\
3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\
4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\
5.输出结果必须是一个JSON格式的字典,且不需要任何前后修饰语句' % calculate_algorithm.__name__
然后带入模型:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
response.choices[0].message['content']
来看下最终的结果:
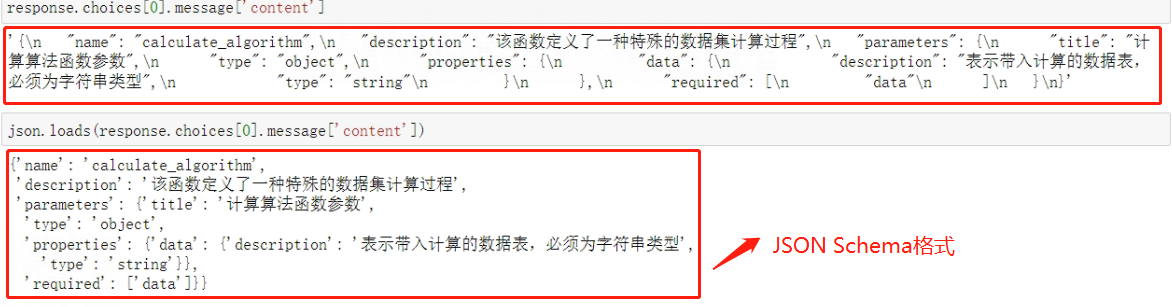
这个过程(按照格式输出文本语义理解的内容)对于大语言模型来说是非常简单的推理过程,在JSON Schema对象编写时,Few-shot效果会明显好于当前的Zero-shot过程。
- Step 4:高级函数封装
对上述流程进行更高层次的封装,编写一个自动输出functions参数的函数,代码如下:
def auto_functions(functions_list):
"""
Chat模型的functions参数编写函数
:param functions_list: 包含一个或者多个函数对象的列表;
:return:满足Chat模型functions参数要求的functions对象
"""
def functions_generate(functions_list):
# 创建空列表,用于保存每个函数的描述字典
functions = []
# 对每个外部函数进行循环
for function in functions_list:
# 读取函数对象的函数说明
function_description = inspect.getdoc(function)
# 读取函数的函数名字符串
function_name = function.__name__
Q1_system_prompt = '以下是某函数说明:%s' % function_description
Q1_user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\
1.字典总共有三个键值对;\
2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\
3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\
4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\
5.输出结果必须是一个JSON格式的字典,且不需要任何前后修饰语句' % calculate_algorithm.__name__
A1_system_prompt = "测试算法函数,该函数定义了一种特殊的数据集计算过程\n:param data: 必要参数,要求字符串类型,表示带入计算的数据表\n:return:测试函数计算后的结果,返回结果为json字符串类型对象"
A1_user_prompt = "{'name': 'testg_algorithm', \
'description': '测试算法函数,该函数定义了一种特殊的数据集计算过程', \
'parameters': {'title': '测试算法函数参数', \
'type': 'object', \
'properties': {'data': {'description': '字符串类型的数据表', 'type': 'string'}}, \
'required': ['data']}}"
system_prompt = '以下是某函数说明:%s' % function_description
user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\
1.字典总共有三个键值对;\
2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\
3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\
4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,类型为object,用于说明该函数的参数输入规范;\
5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_name
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "Q:" + Q1_system_prompt + Q1_user_prompt + "A:" + A1_system_prompt + A1_user_prompt },
{"role": "user", "content": 'Q:' + system_prompt + user_prompt}
]
)
functions.append(json.loads(response.choices[0].message['content']))
return functions
max_attempts = 3
attempts = 0
while attempts < max_attempts:
try:
functions = functions_generate(functions_list)
break # 如果代码成功执行,跳出循环
except Exception as e:
attempts += 1 # 增加尝试次数
print("发生错误:", e)
if attempts == max_attempts:
print("已达到最大尝试次数,程序终止。")
raise # 重新引发最后一个异常
else:
print("正在重新运行...")
return functions
上述代码把函数功能的主题封装在functions_generate这个内嵌函数中,然后外层函数主要控制报错时的处理流程:即如果函数执行时报错,三次内报错都会反复调用执行functions_generate,三次报错之后则会直接停止运行。这里之所以要设置多次报错仍然反复执行,是因为哪怕user_prompt中明确指出“只输出这个字典即可,前后不需要任何前后修饰或说明的语句”,但模型仍然可能会输出前后说明文字,此时是无法直接使用functions.append(json.loads(response.choices[0].message[‘content’]))来提取functions字典的,但这只是小概率事件,再次进行相同问题的提问,输出的结果大概率不会再包含前后修饰语句,functions_generate即可正常运行。
- Step 5:单个外部函数带入测试
先提取到JSON Schema格式的描述
functions_list = [calculate_algorithm]
functions = auto_functions(functions_list)
functions
输出如下:

接下来测试将其带入Chat模型,验证模型是否能顺利执行Function calling功能,代码如下:
# 创建一个DataFrame
df = pd.DataFrame({'x1':[1, 2], 'x2':[3, 4]})
# 函数输出的结构都必须是字符串类型才能够被大模型正常的识别
df_str = df.to_string()
df_str

messages=[
{"role": "system", "content": "数据集data:%s,数据集以字符串形式呈现" % df_str},
{"role": "user", "content": "请在数据集data上执行计算算法"}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=messages,
functions=functions,
function_call="auto",
)
response["choices"][0]["message"]
看下输出:

模型返回结果中存在function_call,则说明模型完成了外部模型的挑选,顺利执行了Function calling功能,也进而说明自动functions参数编写函数切实有效。
- Step 6:多个外部函数带入测试
接下来进一步测试,当添加多个外部函数时,auto_functions函数能否顺利的依次翻译这些函数说明,并组成functions列表,同时在多个函数情况下,模型能否根据实际对话需求智能选择外部函数,代码如下:
def smallC_algorithm(data):
"""
smallC算法函数,该函数定义了一种特殊的数据集计算过程
:param data: 必要参数,表示带入计算的数据表,用字符串进行表示
:return:smallC函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象
"""
df_new = pd.read_json(data)
res = np.sum(df_new, axis=1) + 1
return res.to_json(orient='records')
functions_list = [calculate_algorithm, smallC_algorithm]
functions = auto_functions(functions_list)
functions
看下输出结果:

在添加了smallC算法之后,auto-functions函数能够顺利输出正确结果,并且模型也能够根据不同的提示,智能筛选外部函数。
三、优化二:编写自动应答函数
针对第二个优化点:即将Function calling执行时的多轮对话封装在一个函数中。这里涉及到外部函数库字典创建,该字典要求一个键值对代表一个函数,每个键值对的Key表示函数名字符串,对应的Value表示对应的函数。
- Step 1:创建函数库字典
对于此前的functions_list里面包含的两个函数,可以使用如下方式创建这个函数库字典:
function_dict = {func.__name__: func for func in functions_list}
function_dict
看下输出:

- Step 2:构造函数
def run_conversation(messages, functions_list=None, model="gpt-3.5-turbo-16k-0613"):
"""
能够自动执行外部函数调用的Chat对话模型
:param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象
:param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象
:param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo-16k-0613
:return:Chat模型输出结果
"""
# 如果没有外部函数库,则执行普通的对话任务
if functions_list == None:
response = openai.ChatCompletion.create(
model=model,
messages=messages,
)
response_message = response["choices"][0]["message"]
final_response = response_message["content"]
# 若存在外部函数库,则需要灵活选取外部函数并进行回答
else:
# 创建functions对象
functions = auto_functions(functions_list)
# 创建外部函数库字典
available_functions = {func.__name__: func for func in functions_list}
# first response
response = openai.ChatCompletion.create(
model=model,
messages=messages,
functions=functions,
function_call="auto")
response_message = response["choices"][0]["message"]
# 判断返回结果是否存在function_call,即判断是否需要调用外部函数来回答问题
if response_message.get("function_call"):
# 需要调用外部函数
# 获取函数名
function_name = response_message["function_call"]["name"]
# 获取函数对象
fuction_to_call = available_functions[function_name]
# 获取函数参数
function_args = json.loads(response_message["function_call"]["arguments"])
# 将函数参数输入到函数中,获取函数计算结果
function_response = fuction_to_call(**function_args)
# messages中拼接first response消息
messages.append(response_message)
# messages中拼接函数输出结果
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
)
# 第二次调用模型
second_response = openai.ChatCompletion.create(
model=model,
messages=messages,
)
# 获取最终结果
final_response = second_response["choices"][0]["message"]["content"]
else:
final_response = response_message["content"]
return final_response
- Step 3:函数测试
messages = [
{"role": "system", "content": "数据集data:%s,数据集以字符串形式呈现" % df_str},
{"role": "user", "content": '请帮我介绍下data数据集'}]
run_conversation(messages = messages, functions_list = functions_list)
模型能够非常顺利的调用外部函数并围绕当前问题进行准确回答。至此,就完成了既定的Function calling功能执行过程的代码优化,通过借助run_conversation函数,只需设置messages和外部函数列表,即可让模型在回答时有选择性的选择外部函数进行回答,全程无需手动进行调整。
四、实现一个多轮对话函数
更进一步,在run_conversation基础之上,再封装一个可以执行多轮对话的函数,代码如下:
def chat_with_model(functions_list=None,
prompt="你好呀",
model="gpt-4-0613",
system_message=[{"role": "system", "content": "你是以为乐于助人的助手。"}]):
messages = system_message
messages.append({"role": "user", "content": prompt})
while True:
answer = run_conversation(messages=messages,
functions_list=functions_list,
model=model)
print(f"模型回答: {answer}")
# 询问用户是否还有其他问题
user_input = input("您还有其他问题吗?(输入退出以结束对话): ")
if user_input == "退出":
break
# 记录用户回答
messages.append({"role": "user", "content": user_input})
可以通过传入functions_list测试是否可以调用外部函数。
五、总结
本文首先概述了Function calling流程的优化思路,接着分别详细介绍了两种主要的优化方法:自动编写函数和编写自动应答函数。这两种优化方法可以显著提高Function calling的效率和实用性。最后,演示了如何实现一个多轮对话函数。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!