导包
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
创建RDD
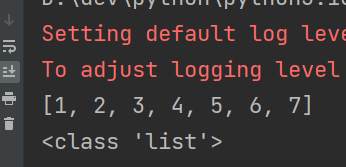
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7])
collect算子
rdd_list: list = rdd.collect()
print(rdd_list)
print(type(rdd_list))
reduce算子
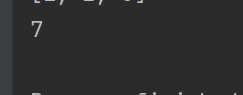
num = rdd.reduce(lambda a, b: a + b)
print(num)

take算子,取出前n个元素,返回list
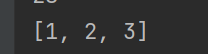
take_list = rdd.take(3)
print(take_list)
count算子,计数
num_count = rdd.count()
print(num_count)

saveAsTextFile算子
环境配置
os.environ["HADOOP_HOME"] = "D:/dev/hadoop-3.0.0"
conf.set("spark.default.parallelism", "1")
rdd.saveAsTextFile("D:/output")