文章目录
- 3.1、线性回归
- 3.1.1、PyTorch 从零实现线性回归
- 3.1.2、简单实现线性回归
3.1、线性回归
线性回归是显式解,深度学习中绝大多数遇到的都是隐式解。
3.1.1、PyTorch 从零实现线性回归
%matplotlib inline
import random
import torch
#d2l库中的torch模块,并将其用别名d2l引用。d2l库是《动手学深度学习》(Dive into Deep Learning)这本书的配套库,包含了一些自定义的函数和工具,以及对PyTorch库的包装和扩展。
from d2l import torch as d2l
生成数据集及标签
def synthetic_data(w,b,num_examples):
"""生成 y = Xw + b + 噪声"""
X = torch.normal(0,1,(num_examples,len(w)))
#创建一个大小为(num_examples, len(w))的张量X,并使用均值为0,标准差为1的正态分布对其进行初始化。这个张量代表输入特征,其中 num_examples 是样本数量,len(w) 是特征向量的长度。
y = torch.matmul(X,w) + b
y += torch.normal(0, 0.01, y.shape)
#预测值y中添加一个均值为0,标准差为0.01的正态分布噪声,以增加模型的随机性和泛化能力。
return X, y.reshape((-1,1))
#预测值y通过reshape方法被转换成一个列向量
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features, labels = synthetic_data(true_w,true_b,1000)
print('features:',features[0],'\nlabel:',labels[0])
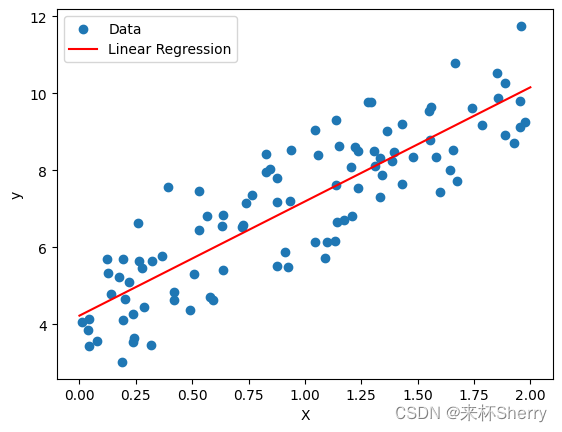
d2l.set_figsize()#设置图表尺寸
d2l.plt.scatter(features[:,1].detach().numpy()
,labels.detach().numpy(),1);
d2l.plt.scatter(,,),使用d2l库中的绘图函数来创建散点图。这个函数接受三个参数:
features[:,1].detach().numpy() 是一个二维张量features的切片操作,选择了所有行的第二列数据。detach()函数用于将张量从计算图中分离,numpy()方法将张量转换为NumPy数组。这样得到的是一个NumPy数组,代表散点图中的x轴数据。
labels.detach().numpy() 是一个二维张量labels的分离和转换操作,得到一个NumPy数组,代表散点图中的y轴数据。
1 是可选参数,用于设置散点的标记尺寸。在这里,设置为1表示每个散点的大小为1个点。
这里为什么要用detach()?
尝试去掉后结果是不变的,应对某些pytorch版本转numpy必须这样做。
def data_iter(batch_size, features, labels):
num_examples = len(features)
#创建一个包含0到num_examples-1的整数列表,表示样本索引。
indices = list(range(num_examples))
#随机打乱样本索引的顺序,样本是随机读取的,没有特定顺序。
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
# 根据当前批次的起始索引,创建一个包含当前批次样本索引的张量。min(i + batch_size, num_examples)确保最后一个批次的大小不超过剩余样本数量。
batch_indices = torch.tensor(
indices[i:min(i + batch_size,num_examples)])
# 使用生成器返回当前批次的特征和标签。
yield features[batch_indices],labels[batch_indices]
batch_size = 10
for X,y in data_iter(batch_size, features, labels):
print(X,'\n',y)
break
小插叙,synthetic_data()返回值中X敲成了小写,直接导致后面矩阵乘法形状对不上,找了半天错误。
yield 预备知识:
当一个函数包含
yield语句时,它就变成了一个生成器函数。生成器函数用于生成一个序列的值,而不是一次性返回所有值。每次调用生成器函数时,它会暂停执行,并返回一个值。当下一次调用生成器函数时,它会从上次暂停的地方继续执行,直到遇到下一个yield语句或函数结束。
定义初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
定义模型
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b #X, w进行矩阵乘法
定义损失函数
def squared_loss(y_hat,y): #(预测值,真实值)
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) **2 / 2
这就是数据是张量的好处,
M S E ( y , y ′ ) = ∑ i = 1 n ( y i − y i ′ ) 2 n MSE(y,y') = \frac{\sum_{i=1}^n(y_i-y_i')^2}{n} MSE(y,y′)=n∑i=1n(yi−yi′)2
明明是含有求和操作的数学公式,在张量面前形同虚设,代码实现是这么简单。就像在写标量公式一样。
定义优化算法
def sgd(params, lr, batch_size):#一个包含待更新参数的列表,学习率,每个小批次中的样本数量)
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -=lr * param.grad / batch_size
param.grad.zero_()
为什么执行的减法而不是加法?
梯度的负方向
优化算法是怎么跟损失函数合作来完成参数优化?
优化函数没有直接使用损失值,但通过使用损失函数和反向传播计算参数的梯度,并将这些梯度应用于参数更新,间接地优化了模型的损失。梯度下降算法利用了参数的梯度信息来更新参数,以使损失函数尽可能减小。
优化算法(例如随机梯度下降)是怎么拿到损失函数的梯度信息的?
损失函数梯度完整的说是 loss关于x,loss关于y的梯度 ,搞清楚这个概念就不难理解了【初学时,我误解成了
损失值的梯度和x,y的梯度是两个概念,显然后者是非常不准确的表述】,损失函数梯度就在 sgd的params中。l = loss(net(X, w, b), y) l.sum().backward()#此时损失函数梯度【关于w,b的梯度】存在w.grad,b.grad中 sgd([w,b], lr, batch_size) #使用参数梯度更新参数
param.grad.zero_()在这里有什么意义?谁会干扰梯度的求解?如果在循环的下一次迭代中不使用
param.grad.zero_()来清零参数的梯度,那么参数将会保留上一次迭代计算得到的梯度值,继续沿用该梯度值来求解梯度。就是说上次for循环的param会对下次param的梯度求解产生影响,所以才要清空梯度。
训练过程
#超参数
lr =0.03 #学习率(learning rate),控制每次参数更新的步幅大小。
num_epochs = 3 #数据集的扫描次数,即要重复训练模型的次数。
net =linreg #表示模型,这里使用了一个名为linreg的线性回归模型。
loss = squared_loss#表示损失函数,这里使用了一个名为squared_loss的均方损失函数。
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X 、y 的小批量损失
#l形状是 (batch_size, 1),非标量
l.sum().backward()
sgd([w,b], lr, batch_size) #使用参数梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b),labels)
print('epoch ',epoch+1,'loss ',float(train_l.mean()))
epoch 1 loss 0.032808780670166016 epoch 2 loss 0.00011459046800155193 epoch 3 loss 5.012870315113105e-05加
with torch.no_grad()有什么意义,毕竟没有backward()操作?对于
with torch.no_grad()块,在 PyTorch 中禁用梯度追踪和计算图的构建。在该块中执行的操作不会被记录到计算图中,因此不会生成梯度信息。其作用是告诉 PyTorch 不要跟踪计算梯度,这样可以节省计算资源。简单说,就是计算损失值的张量运算不会记录到计算图中,因为没必要,而且不建立计算图,求损失值更快了。
代码存在的小问题
最后一批次可能不足
batch_size,sgd 执行param -=lr * param.grad / batch_size取平均是有问题的,修改后:sgd([w,b], lr,min(batch_size, X.shape[0])) #使用参数梯度更新参数
比较真实参数与训练学到的参数评估训练成功程度
print('w的估计误差:',true_w - w.reshape(true_w.shape))
print('b的估计误差:',true_b - b)
w的估计误差: tensor([-6.1035e-05, 2.5797e-04], grad_fn=<SubBackward0>) b的估计误差: tensor([0.0018], grad_fn=<RsubBackward1>)
3.1.2、简单实现线性回归
生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2,-3.4])
true_b = 4.2
#d2l 的人造数据集函数
features, labels = d2l.synthetic_data(true_w, true_b,1000)
读取数据集
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个Pytorch数据迭代器"""
#PyTorch提供的一个用于封装多个张量数据的数据集对象,*data_arrays用于将数据数组解包为多个参数。
#*data_arrays解包等价于 dataset = data.TensorDataset(features, labels)
dataset = data.TensorDataset(*data_arrays)
#PyTorch提供的一个用于批量加载数据的迭代器
return data.DataLoader(dataset, batch_size, shuffle= is_train)
batch_size = 10
data_iter = load_array((features,labels), batch_size)
#iter() 函数将数据迭代器转换为迭代器对象,而 next() 函数用于获取迭代器的下一个元素。
next(iter(data_iter))
解包操作(见 python 预备知识)
星号
*在dataset = data.TensorDataset(*data_arrays)中的作用是将元组或列表中的元素解包,并作为独立的参数传递给函数或构造函数。这样可以更方便地传递多个参数。迭代器使用(见 python 预备知识)
iter()函数的主要目的是将可迭代对象转换为迭代器对象,以便于使用next()函数逐个访问其中的元素。
使用框架预定好的层
from torch import nn
#线性回归就是一个简单的单层神经网络
#一个全连接层,它接受大小为 2 的输入特征,并输出大小为 1 的特征。
net = nn.Sequential(nn.Linear(2,1))
初始化模型参数
#net[0] 表示模型中的第一个层,weight权重参数,正态分布初始化
net[0].weight.data.normal_(0,0.01)
#第一层加入偏差
net[0].bias.data.fill_(0)
实例化损失函数
loss = nn.MSELoss()
实例化优化算法( SGD)
#net.parameters() 返回一个迭代器,该迭代器包含了模型中所有可训练的参数。
trainer = torch.optim.SGD(net.parameters(),lr=0.03)
训练过程
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features),labels)
print(f'epoch {epoch+1}, loss {l:f}')
关于输出格式,最后一个明显最好
print('epoch ',epoch+1,',loss ',l) #epoch 1 ,loss tensor(9.9119e-05, grad_fn=<MseLossBackward0>) print('epoch ',epoch+1,',loss ',float(l))# epoch 1 ,loss 9.872819646261632e-05 print(f'epoch {epoch+1}, loss {l:f}') # epoch 1, loss 0.000099还可以自定义保留有限小数位
print(f'epoch {epoch+1}, loss {l:.4f}')# 保留4位。

![[linux]VI编辑器常用命令](https://img-blog.csdnimg.cn/78cb23d3548c4f7088aec996738ed977.png)