TensorRT学习笔记
前情提要:TensorRT 模型优化与推理:从零到一,激活GPU的力量:使用TensorRT优化和执行深度学习模型,你的TensorRT入门指南
本篇将会介绍TensorRT下的模型量化与CUDA并行计算编程的介绍。
TensorRT模型量化
模型量化是一种用于深度学习模型优化的技术,将深度学习模型中的参数(例如权重和偏置)从浮点数转换成整数或者定点数的过程。其主要目标是将模型中的参数从32位浮点数(FP32)降低到更低精度的格式,如8位整数(INT8)或16位浮点数(FP16)。这样做可以减少模型的存储和计算成本,从而达到模型压缩和运算加速的目的。如int8量化,让原来模型中32bit存储的数字映射到8bit再计算(范围是[-128,127])。
模型量化操作可以带来三个主要的好处:
- 减少模型大小:使用更少的位来表示模型的权重可以显著减小模型的大小,从而使模型占用更少的内存和磁盘空间。例如,将模型从FP32转换为INT8可以将模型的大小减小四倍。
- 加速推理:更小的模型意味着在进行前向传播(即,进行预测)时需要处理更少的数据。此外,一些硬件(如GPU和专用AI加速器)提供了专门的硬件支持,可以在单个操作中处理多个低精度数值。这两个因素都可以显著提高模型的推理速度,访问一次32位浮点型可以访问4次int8整型数据。
- 减少资源消耗:更小的模型不仅可以提高处理速度,还可以减少所需的能源消耗。这对于在资源受限的环境中运行模型(如移动设备和嵌入式系统)尤为重要。
这种优势也是以牺牲一些模型精度为代价的,因为在量化过程中,可能会丢失一些精度信息。在许多情况下,这种精度损失是可以接受的,因为它对模型的总体性能影响很小。然而,在一些高精度要求的应用中,量化可能会导致性能下降。所以量化校准是一个关键步骤,目标是找到一个理想的映射,将32位浮点数值转换为低精度的数值(如INT8),同时尽可能地保留模型的精度。
模型量化算法介绍
常见的模型量化算法有:
- 熵校准:熵校准是一种动态校准算法。熵校准方法的主要思想是找到一个最佳的量化阈值,使得量化后的数据分布(用INT8表示)与原始数据分布(用FP32表示)的Kullback-Leibler (KL) 散度最小。在统计学中,KL散度是一种衡量两个概率分布差异的指标。因此,这种方法的目标是使量化后的数据分布尽可能接近原始的数据分布。
- 最小最大值校准:这种方法相对更为直观和简单。因为它直接使用校准数据集中的最小值和最大值作为量化阈值。换句话说,最小值被映射为INT8的最小值(例如-128),最大值被映射为INT8的最大值(例如127)。这种方法的优点是计算速度快,但可能无法在所有情况下都获得最佳性能。
- 参数化校准:这种方法会在量化过程中优化模型的参数,参数化校准会在量化过程中进行优化,尽可能使量化后的模型输出与原始模型的输出保持接近。在进行参数化校准时,我们会对每一层的参数进行微调,以最小化量化误差。但是,因为它需要对每个参数进行优化,可以更精确地控制量化误差,所以导致了它的计算量相对较大。在对精度要求很高的场景中,参数化校准可能是最佳的选择。在某些应用中,这种方法可能会产生比熵校准或最小最大值校准更好的结果。
- 百分比截断校准(Percentile Calibration):百分比截断校准是一种针对有噪声或异常值的数据的校准方法。这种方法首先会计算所有数据的分布,然后找到一个阈值,使得超过这个阈值的数据仅占所有数据的一个很小的百分比(比如1%或0.1%)。然后,这些被认为是噪声或异常值的数据会被忽略,而其他的数据则会被用来计算量化参数。百分比截断校准的优点是它可以在处理有噪声或异常值的数据时保持较高的精度。然而,它的缺点是可能会丢失一些重要的信息,特别是当这些被认为是噪声或异常值的数据实际上对模型的预测结果有重要影响时。百分比截断校准适用于数据中存在较多噪声或异常值的场景。
在本案例中,我们将主要介绍TensorRT下熵校准与最小最大值校准的C++编码,这两种校准方法都需要准备一些数据用于在校准时执行推理,以统计数据的分布情况。这些数据称为校准数据集,是量化过程的关键一环。通过这个数据集,TensorRT可以理解数据分布,并据此决定如何最好地将权重和激活从浮点数缩减到低精度表示。TensorRT为了优化模型的加载速度,可以将校准表保存为.cache文件。当我们在TensorRT中进行INT8量化时,首次运行的过程中会使用校准数据集进行校准,生成一个校准表。这个校准表会被保存到一个.cache文件中,用于后续的模型加载和推理。
设计校准缓存表有两个主要优点:
- **加速模型加载:**在首次运行时,校准过程可能需要一些时间。但是,一旦生成了校准表并保存为.cache文件后,我们在后续的模型加载时,就可以直接加载这个.cache文件,而无需再次进行校准。这样可以大大加速模型的加载速度。
- **确保一致性:**在保存了校准表之后,无论何时加载模型,都会使用相同的量化参数,这样可以确保推理的一致性。
需要注意的是,这个.cache文件是和原始模型以及校准数据集密切相关的。也就是说,只有当模型和校准数据集都没有变化时,才能使用同一个.cache文件。如果模型或者校准数据集发生了变化,就需要重新进行校准,并生成新的.cache文件。
在准备校准数据集时,**一般数据需要有代表性,即需要符合最终实际落地场景的数据。**如果校准数据集不能代表最终的实际应用数据,那么量化过程可能会导致模型的精度损失。实际应用中一般准备500-1000个数据用于量化(具体的数量可能需要根据你的模型和应用来进行调整)。例如,如果你的模型是用来处理图像的,那么校准数据集中就需要包含各种各样的图像,包括各种不同的场景、照明条件、目标对象等。
TensorRT实现最大最小值校准
在 TensorRT 中,可以通过实现 IInt8EntropyCalibrator2 接口或 IInt8MinMaxCalibrator 接口来执行熵校准或最小最大值校准,并且需要实现几个虚函数方法:
getBatch()方法:用于提供一批校准数据;readCalibrationCache()和writeCalibrationCache()方法:实现缓存机制,以避免在每次启动时重新加载校准数据。
在build.cu代码中实现了 IInt8MinMaxCalibrator 接口,用于对 INT8 模型进行离线静态校准(你可以替换IInt8EntropyCalibrator2换成熵校准进行结果对比)。
// 定义校准数据读取器
// 如果要用entropy的话改为:IInt8EntropyCalibrator2
class CalibrationDataReader : public IInt8MinMaxCalibrator
{
....
}
- 构造函数需要传递的参数包括数据目录、数据列表和BatchSize。数据目录是存放校准数据的文件夹路径,而数据列表是含有校准数据文件名称的列表。传递这些参数的目的是为了告诉校准器校准数据的位置以及处理数据的批次大小。在构造函数中,还会根据模型的需求,初始化输入张量的维度和大小,并在设备上分配相应的内存。这是因为这些信息是TensorRT进行推理计算所必需的。
CalibrationDataReader(const std::string& dataDir, const std::string& list, int batchSize = 1)
: mDataDir(dataDir), mCacheFileName("weights/calibration.cache"), mBatchSize(batchSize), mImgSize(kInputH* kInputW)
{
// 设置网络输入的尺寸
mInputDims = { 1, 3, kInputH, kInputW };
// 计算输入的元素总数
mInputCount = mBatchSize * samplesCommon::volume(mInputDims);
// 初始化CUDA预处理环境,为图像大小分配空间
cuda_preprocess_init(mImgSize);
// 在设备上为批处理数据分配空间
cudaMalloc(&mDeviceBatchData, kInputH * kInputW * 3 * sizeof(float));
// 加载校准数据集文件列表
std::ifstream infile(list);
std::string line;
while (std::getline(infile, line))
{
sample::gLogInfo << line << std::endl;
mFileNames.push_back(line);
}
// 计算总批次数量
mBatchCount = mFileNames.size() / mBatchSize;
std::cout << "CalibrationDataReader: " << mFileNames.size() << " images, " << mBatchCount << " batches." << std::endl;
}
getBatch()方法的任务是为校准过程提供一批数据。这个方法需要将当前批次的校准数据从磁盘读取到CPU内存中,然后复制到GPU设备内存中。这个过程对应的是深度学习模型的前向传播过程,也就是从输入层开始,依次通过各个隐藏层,最后达到输出层。
bool getBatch(void* bindings[], const char* names[], int nbBindings) noexcept override
{
// 检查是否还有更多批次的数据
if (mCurBatch + 1 > mBatchCount)
{
return false;
}
// 每个图像的偏移量
int offset = kInputW * kInputH * 3 * sizeof(float);
for (int i = 0; i < mBatchSize; i++)
{
int idx = mCurBatch * mBatchSize + i;
std::string fileName = mDataDir + "/" + mFileNames[idx];
cv::Mat img = cv::imread(fileName);
int new_img_size = img.cols * img.rows;
if (new_img_size > mImgSize)
{
mImgSize = new_img_size;
cuda_preprocess_destroy(); // 如果新图像的大小超过之前的内存空间,释放之前的内存
cuda_preprocess_init(mImgSize); // 并重新分配适应新图像的内存
}
// 使用GPU处理输入图像,并把结果写入到设备内存
process_input_gpu(img, mDeviceBatchData + i * offset);
}
for (int i = 0; i < nbBindings; i++)
{
if (!strcmp(names[i], kInputTensorName))
{
// 把设备内存的地址绑定到输入张量
bindings[i] = mDeviceBatchData + i * offset;
}
}
// 更新当前批次索引
mCurBatch++;
return true;
}
readCalibrationCache()方法的目标是从缓存文件中读取校准缓存。这个方法会返回一个指向缓存数据的指针和缓存数据的大小。如果没有缓存数据,则返回nullptr。在这里,校准缓存是一个重要的概念。为了提高模型推理的速度,我们通常会将校准过程的结果保存下来,这样在下次进行推理时就无需再次进行校准,而是直接读取保存的校准缓存,从而提高推理的效率。
const void* readCalibrationCache(std::size_t& length) noexcept override
{
// 清空校准缓存
mCalibrationCache.clear();
// 以二进制形式打开缓存文件
std::ifstream input(mCacheFileName, std::ios::binary);
input >> std::noskipws;
// 如果文件状态良好,即文件可读且没有其他错误
if (input.good())
{
// 从输入流中拷贝数据到校准缓存
std::copy(std::istream_iterator<char>(input), std::istream_iterator<char>(),
std::back_inserter(mCalibrationCache));
}
// 获取缓存数据的大小
length = mCalibrationCache.size();
// 如果有缓存数据,则返回指向缓存数据的指针;否则返回 nullptr
return length ? mCalibrationCache.data() : nullptr;
}
writeCalibrationCache()方法则是将校准缓存写入到缓存文件中。需要将缓存数据指针和缓存数据的大小传递给文件输出流,并将其写入到缓存文件中。这个过程实际上是保存校准过程的结果,以便下次可以直接读取并使用。
// writeCalibrationCache() 将校准缓存写入到缓存文件中
// 在该方法中,需要将缓存数据指针和缓存数据的大小传递给文件输出流,并将其写入到缓存文件中
void writeCalibrationCache(const void* cache, std::size_t length) noexcept override
{
// 将校准缓存写入到文件中
std::ofstream output(mCacheFileName, std::ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
}
在具体的业务代码中,首先会检查当前平台是否支持 INT8 推理。如果不支持,则会打印出警告信息,并将模型的推理精度设置为 FP16 模式。这是为了保证在不支持 INT8 的平台上,模型依然可以进行推理。否则,将创建一个 CalibrationDataReader 类型的对象 calibrator,并将其设置为 INT8 校准器。然后,将 INT8 模式标志设置到配置对象 config 中。
// 检查当前平台是否支持 INT8 推理
if (!builder->platformHasFastInt8())
{
// 如果不支持 INT8 推理,则打印警告信息并将引擎设置为 FP16 模式
sample::gLogInfo << "设备不支持int8." << std::endl;
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
else
{
// 如果支持 INT8 推理,创建一个 CalibrationDataReader 对象,并将其设置为 INT8 校准器
auto calibrator = new CalibrationDataReader(calib_dir, calib_list_file);
// 为配置对象设置 INT8 模式标志
config->setFlag(nvinfer1::BuilderFlag::kINT8);
// 设置 INT8 校准器
config->setInt8Calibrator(calibrator);
}
完整代码
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "logger.h"
#include "common.h"
#include "buffers.h"
#include "cassert"
#include "utils/config.h"
#include "utils/preprocess.h"
#include "utils/types.h"
// 定义校准数据读取器, 最大最小值校准
// 如果要用熵校准entropy的话改为:IInt8EntropyCalibrator2
class CalibrationDataReader : public nvinfer1::IInt8MinMaxCalibrator
{
private:
std::string mDataDir;
std::string mCacheFileName;
std::vector<std::string> mFileNames;
int mBatchSize;
nvinfer1::Dims mInputDims;
int mInputCount;
float *mDeviceBatchData { nullptr };
int mBatchCount;
int mImgSize;
int mCurBatch{0};
std::vector<char> mCalibrationCache;
private:
void load_dataClassFile(const std::string& filepath)
{
std::ifstream ifile(filepath);
std::string Line;
while (std::getline(ifile, Line))
{
sample::gLogInfo << Line << std::endl;
mFileNames.push_back(Line);
}
mBatchCount = mFileNames.size() / mBatchSize;
std::cout << "CalibrationDataReader: " << mFileNames.size()
<< " images, " << mBatchCount << " batches." << std::endl;
}
public:
// 构造函数需要传递的参数包括数据目录、数据列表、BatchSize。
// 通常会根据模型的需求,初始化输入张量的维度和大小,并在设备上分配相应的内存。
CalibrationDataReader(const std::string& dataDir, const std::string& filepath, int batchSize = 1)
: mDataDir(dataDir), mCacheFileName("weights/calibration.cache"),
mBatchSize(batchSize), mImgSize(kInputH * kInputW)
{
mInputDims = {1, 3, kInputH, kInputW};
mInputCount = mBatchSize * samplesCommon::volume(mInputDims);
cuda_preprocess_init(mImgSize);
cudaMalloc(&mDeviceBatchData, kInputH * kInputW * 3 * sizeof(float));
load_dataClassFile(filepath);
}
int32_t getBatchSize() const noexcept override
{
return mBatchSize;
}
bool getBatch(void* bindings[], const char *names[], int nbBindings) noexcept override
{
if (mCurBatch + 1 > mBatchCount)
{
return false;
}
int offset = kInputW * kInputH * 3 * sizeof(float);
for (int i = 0; i < mBatchSize; i++)
{
int idx = mCurBatch * mBatchSize + i;
std::string filename = mDataDir + "/" + mFileNames[idx];
cv::Mat image = cv::imread(filename);
int new_img_size = image.cols * image.rows;
if (new_img_size > mImgSize)
{
mImgSize = new_img_size;
cuda_preprocess_destroy();
cuda_preprocess_init(mImgSize);
}
process_input_gpu(image, mDeviceBatchData + i * offset);
}
for (int i = 0; i < nbBindings; i++)
{
if (!strcmp(names[i], kInputTensorName))
{
bindings[i] = mDeviceBatchData + i * offset;
}
}
mCurBatch++;
return true;
}
const void* readCalibrationCache(std::size_t& length) noexcept override
{
mCalibrationCache.clear();
std::ifstream input(mCacheFileName, std::ios::binary);
input >> std::noskipws;
if (input.good())
{
std::copy(std::istream_iterator<char>(input), std::istream_iterator<char>(),
std::back_inserter(mCalibrationCache));
}
length = mCalibrationCache.size();
return length ? mCalibrationCache.data() : nullptr;
}
void writeCalibrationCache(const void *cache, std::size_t length) noexcept override
{
std::ofstream output(mCacheFileName, std::ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
}
};
int main(int argc, char** argv)
{
if (argc != 4)
{
std::cerr << "请输入onnx文件位置: ./build/[onnx_file] [calib_dir] [calib_list_file]" << std::endl;
return -1;
}
// 命令行获取onnx文件路径、校准数据集路径、校准数据集列表文件
char* onnx_file = argv[1];
char* calib_dir = argv[2];
char* calib_list_file = argv[3];
// ========== 1. 创建builder:创建优化的执行引擎(ICudaEngine)的关键工具 ==========
// 在几乎所有使用TensorRT的场合都会使用到IBuilder
// 只要TensorRT来进行优化和部署,都需要先创建和使用IBuilder。
std::unique_ptr<nvinfer1::IBuilder> builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
std::cerr << "Failed to create build" << std::endl;
return -1;
}
std::cout << "Successfully to create builder!!" << std::endl;
// ========== 2. 创建network:builder--->network ==========
// 设置batch, 数据输入的批次量大小
// 显性设置batch
const unsigned int explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
std::unique_ptr<nvinfer1::INetworkDefinition> network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cout << "Failed to create network" << std::endl;
return -1;
}
// 创建onnxparser,用于解析onnx文件
std::unique_ptr<nvonnxparser::IParser> parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
// 调用onnxparser的parseFromFile方法解析onnx文件
bool parsed = parser->parseFromFile(onnx_file, static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
std::cerr << "Failed to parse onnx file!!" << std::endl;
return -1;
}
// 配置网络参数
// 我们需要告诉tensorrt我们最终运行时,输入图像的范围,batch size的范围。这样tensorrt才能对应为我们进行模型构建与优化。
nvinfer1::ITensor* input = network->getInput(0); // 获取了网络的第一个输入节点。
nvinfer1::IOptimizationProfile* profile = builder->createOptimizationProfile(); // 创建了一个优化配置文件。
// 网络的输入节点就是模型的输入层,它接收模型的输入数据。
// 在 TensorRT 中,优化配置文件(Optimization Profile)用于描述模型的输入尺寸和动态尺寸范围。
// 通过优化配置文件,可以告诉 TensorRT 输入数据的可能尺寸范围,使其可以创建一个适应各种输入尺寸的优化后的模型。
// 设置最小尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4(1, 3, 640, 640));
// 设置最优尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4(1, 3, 640, 640));
// 设置最大尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4(1, 3, 640, 640));
// ========== 3. 创建config配置:builder--->config ==========
// 配置解析器
std::unique_ptr<nvinfer1::IBuilderConfig> config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
// 添加之前创建的优化配置文件(profile)到配置对象(config)中
// 优化配置文件(profile)包含了输入节点尺寸的设置,这些设置会在模型优化时被使用。
config->addOptimizationProfile(profile);
// 设置精度
if (!builder->platformHasFastInt8())
{
sample::gLogInfo << "设备不支持int8,本次将默认使用int16" << std::endl;
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
else {
sample::gLogInfo << "设备支持int8,本次将使用int8量化" << std::endl;
auto calibrator = new CalibrationDataReader(calib_dir, calib_list_file);
config->setFlag(nvinfer1::BuilderFlag::kINT8);
config->setInt8Calibrator(calibrator);
}
// config->setFlag(nvinfer1::BuilderFlag::kFP16);
builder->setMaxBatchSize(1);
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 创建流,用于设置profile
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream)
{
std::cerr << "Failed to create CUDA profileStream File" << std::endl;
return -1;
}
config->setProfileStream(*profileStream);
// ========== 5. 序列化保存engine ==========
// 使用之前创建并配置的 builder、network 和 config 对象来构建并序列化一个优化过的模型。
std::unique_ptr<nvinfer1::IHostMemory> plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
std::ofstream engine_file("./weights/best.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
// ========== 6. 释放资源 ==========
std::cout << "Engine build success!" << std::endl;
return 0;
}
CUDA-GPU并行计算:从理论到图像处理实践
CUDA-GPU开发简介
CUDA是一种并行计算平台和编程模型,由NVIDIA推出,它可以利用GPU(图形处理器)进行高效的并行计算。使用CUDA编程可以提高计算密集型应用程序的性能,例如图像处理、科学计算、机器学习、深度学习等。相比于使用CPU进行串行计算,使用GPU并行计算可以大大提高计算速度和效率。在图像处理或深度学习中,我们通常会对图像进行预处理,如调整图像大小、归一化、通道交换等。这些操作需要对图像的每一个像素进行处理,所以如果使用CPU进行串行处理的话,会消耗很大的计算资源和时间。因此,我们通常会使用CUDA进行并行处理,以提高处理速度和效率。
CUDA编程步骤概述
CUDA编程的基本步骤可以概括为以下几个部分:
- 定义kernel核函数:kernel函数是在GPU上运行的并行代码,它们被定义为
__global__函数。这些函数通常处理输入数组的单个元素。一个简单的kernel函数可能会执行一个像素的颜色变换等简单操作。例如,一个简单的向量加法kernel函数可能如下所示:
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
在这个例子中,blockIdx.x和threadIdx.x是CUDA提供的内置变量,它们分别表示当前的块索引和线程索引。
- 分配内存并初始化数据:CUDA提供了API函数,如
cudaMalloc()和cudaMemcpy(),分别用于在GPU上分配内存并将数据从CPU(也称为主机)复制到GPU(也称为设备)。例如:
int numElements = 50000;
size_t size = numElements * sizeof(float);
float *d_A = nullptr;
cudaMalloc((void **)&d_A, size);
在这个例子中,我们首先计算需要分配的内存大小,然后使用cudaMalloc()函数在GPU上分配内存。d_A是一个设备指针,指向GPU内存。
- 启动kernel函数:启动kernel函数使用
<<<...>>>语法。语法中的参数指定了启动kernel的并行线程格的大小。例如:
int threadsPerBlock = 256;
int blocksPerGrid =(numElements + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
在这个例子中,我们根据要处理的元素数量来确定线程格的大小。
- 将结果从GPU上复制回主机端:完成计算后,可以使用
cudaMemcpy()函数将结果从GPU内存复制回CPU内存。例如:
float *h_C = (float *)malloc(size);
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
在这个例子中,我们首先在CPU上为结果数组分配内存,然后使用cudaMemcpy()函数将结果从GPU复制回CPU。
- 释放内存:最后,我们使用
cudaFree()函数释放GPU内存,并使用标准的C或C++函数释放CPU内存。例如:
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
在这个例子中,我们释放了在GPU和CPU上分配的所有内存。
CUDA执行单元——线程块
在CUDA编程模型中,代码是以并行的形式编写的,且是在线程的层面上进行的。在CUDA编程中,一个CUDA Kernel 是由众多的线程(threads)组成的,这些线程可以被组织成一个或多个block(块),而这些block又可以被组织成一个或多个grid(网格)。如下图:
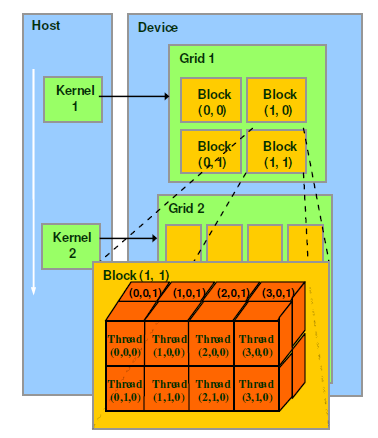
- Thread:线程是CUDA中最基本的执行单元,每个线程都执行相同的操作,但操作的数据不同。
- BLock:线程块是线程的集合,所有线程共享同一线程块的共享内存,并且可以通过线程块内同步方式进行通信。
- Grid:网格是线程块的集合,网格中的所有线程块可以同时执行,每个线程块的线程都相互独立,块之间不能直接通信。
一个grid可以包含多个block,block可以是一维、二维或三维的,block中的thread也可以是一维、二维或三维的。每个线程都有一个唯一的线程ID,可以用来访问不同的数据和内存位置。在同一个线程块中,线程ID是从0开始连续编号的,可以通过内置变量 threadIdx 来获取:
// 获取本线程的索引,blockIdx 指的是线程块的索引,blockDim 指的是线程块的大小,threadIdx 指的是本线程块中的线程索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
在CUDA编程中,block和thread的数量和大小通常需要根据计算任务的特点进行调整,以最大化利用GPU的计算能力。例如,对于大规模的并行计算任务,可以使用更多的线程和线程块来充分利用GPU的并行处理能力。而对于计算量较小的任务,使用更少的线程和线程块可能会更高效。
// 计算需要的线程总量(高度 x 宽度):640*640=409600
int jobs = dst_height * dst_width;
// 一个线程块包含256个线程
int threads = 256;
// 计算线程块的数量
int blocks = ceil(jobs / (float)threads);
// 调用kernel函数
preprocess_kernel<<<blocks, threads>>>(img_buffer_device, dst, dst_width, dst_height, jobs); // 函数的参数
CUDA内核Kernel核函数
在CUDA编程中,一个核心概念是kernel函数,这是在GPU上执行的并行计算的实体。这些函数通过特殊的调用语法,启动了在GPU中并行运行的线程。当一个kernel函数启动时,每个线程都将执行同样的代码,允许大规模并行处理。
标记为kernel函数的方式是使用__global__关键字,这告诉编译器这个函数是在GPU上执行的,而不是在CPU上。除此之外,一个kernel函数与常规函数相似,可以有输入和输出参数,可以有控制流程和局部变量,甚至可以调用其他函数。
在kernel函数内部,CUDA提供了一些内置的变量,如threadIdx,blockIdx,和blockDim,这些可以帮助我们理解每个线程的具体位置和上下文。利用这些变量,可以有效地控制并行任务的执行路径。
要启动一个kernel函数,需要使用特殊的语法<<<...>>>。在这个语法中,第一个参数是指定线程块(block)的数量,第二个参数是指定每个线程块中线程的数量。这些参数可以是一个整数或一个dim3类型,后者允许在x、y、z三个方向上指定线程的数量。如果仅提供了一个整数,它将被解释为x方向的线程数量,而y和z方向的线程数量默认为1。
以下是一个简单的示例,这是一个简单的向量加法的kernel函数:
// 向量加法
__global__ void add(int *a, int *b, int *c, int N)
{
// 获取本线程块的索引,blockIdx 指的是线程块的索引,blockDim 指的是线程块的大小,threadIdx 指的是线程的索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N)
c[tid] = a[tid] + b[tid];
}
此处的add函数被标记为__global__,表示它是一个kernel函数。在该函数内部,我们使用blockIdx.x, blockDim.x, 和 threadIdx.x 来计算一个唯一的线程ID,这样每个线程可以独立地处理一个元素。
然后我们可以如下调用这个kernel函数:
// 调用kernel函数
add<<<n_blocks, n_threads>>>(dev_a, dev_b, dev_c, N);
其中,n_blocks和n_threads分别是线程块的数量和每个线程块中的线程数量,而dev_a, dev_b, dev_c 和 N 是传递给kernel函数的参数。
CUDA内核函数示例代码
这段CUDA代码主要演示了如何使用CUDA进行简单的并行计算,并对比了在CPU和GPU上进行同样计算的时间差异。主要执行以下操作:
- 定义一个GPU并行函数(kernel函数)
add:这个函数的目的是对两个整数数组进行逐元素相加。函数接受两个输入数组a和b以及一个输出数组c,所有这些数组都存储在GPU上。同时,函数还接受一个参数N,表示数组的大小。函数中,每个线程的索引tid由当前线程所在的线程块索引blockIdx.x、线程块的大小blockDim.x以及线程在其所在的线程块中的索引threadIdx.x共同决定。如果tid小于N,则线程会将a和b中的对应元素相加并存储到c中。 - 在
main函数中执行一系列操作:- 检查命令行参数:如果命令行参数的数量不为2,程序会打印错误消息并退出。
- 初始化数据:首先在CPU内存中初始化两个数组
a和b,其中每个元素的值等于其索引。然后,使用cudaMalloc函数在GPU内存中为数组a、b和c分配空间。 - 在CPU上进行数组相加:程序首先在CPU上将数组
a和b逐元素相加,并将结果存储到数组c中。同时,使用CUDA事件来测量这个过程的运行时间。 - 在GPU上进行数组相加:程序将数组
a和b的内容从CPU内存复制到GPU内存,然后调用GPU并行函数add来将a和b逐元素相加并将结果存储到c中。函数add使用一个配置为n_blocks个线程块,每个线程块包含n_threads个线程的GPU并行配置。同时,程序使用CUDA事件来测量这个过程的运行时间。 - 检查CPU和GPU运算结果是否一致:程序将GPU上的运算结果复制回CPU内存,并检查它是否与CPU上的运算结果一致。
- 释放GPU内存:最后,程序使用
cudaFree函数释放在GPU上为a、b和c分配的内存。
#include <stdio.h>
__global__ void add(int *a, int *b, int *c, int N)
{
// 获取本线程的索引,blockIdx 指的是线程块的索引,blockDim 指的是线程块的大小,threadIdx 指的是本线程块中的线程索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// printf("tid: %d blockIdx.x: %d blockDim.x: %d threadIdx.x: %d \n", tid, blockIdx.x, blockDim.x, threadIdx.x);
if (tid < N)
c[tid] = a[tid] + b[tid];
}
int main(int argc, char **argv)
{
// 检查命令行参数
if (argc != 2)
{
fprintf(stderr, "Usage: ./test <N>");
}
int N = std::atoi(argv[1]);
int a[N], b[N], c[N], c_from_gpu[N];
int *dev_a, *dev_b, *dev_c;
// 在设备端分配内存
cudaMalloc((void **)&dev_a, N * sizeof(int));
cudaMalloc((void **)&dev_b, N * sizeof(int));
cudaMalloc((void **)&dev_c, N * sizeof(int));
// 初始化数组
for (int i = 0; i < N; i++)
{
a[i] = i;
b[i] = i;
}
// 统计CPU上运行时间
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
for (int i = 0; i < N; i++)
{
c[i] = a[i] + b[i];
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float time;
cudaEventElapsedTime(&time, start, stop);
printf("Time spent on CPU: %f ms\n", time);
// 将数据从主机端复制到设备端
cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
// 调用kernel函数,在GPU上运行并发计算
// 一个线程块包含256个线程
int n_threads = 256;
// 计算线程块的数量
int n_blocks = std::ceil(N * 1.0f / n_threads);
// 统计时间
cudaEventRecord(start, 0);
// 调用kernel函数,传递线程块数量和大小
add<<<n_blocks, n_threads>>>(dev_a, dev_b, dev_c, N);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time, start, stop);
printf("Time spent on GPU: %f ms\n", time);
// 将数据从设备端复制到主机端
cudaMemcpy(c_from_gpu, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost);
// 检查结果是否一致
for (int i = 0; i < N; i++)
{
if (c[i] != c_from_gpu[i])
{
printf("Error: inconsistent results!\n");
}
}
// 释放设备端内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
# ./build/test 500000
Time spent on CPU: 2.163136 ms
Time spent on GPU: 0.029248 ms
总结
如果你喜欢我们的文章或者需要源代码全文,可以关注VX公纵号:01编程小屋,发送tensorrt获取源代码全文。