作者前言
个人主页::小小页面
gitee页面:秦大大
一个爱分享的小博主 欢迎小可爱们前来借鉴
______________________________________________________
目录
SQL提高
日期函数
length
round
reverse
substring
ifnull
case when
cast
grouping sets
排序函数
开窗函数
____________________________________________________________________
内置函数
日期函数
now()
select now();
获取当前时间(获取到秒)
year()
select year(now());
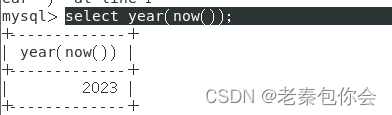
获取当前的年,注意一下year()里的()要填now()
month()
select month(now());

获取当前月份
day()
select day(now());

获取当前的日期
length
select first_name, length(first_name) from new_employees limit 0,10;
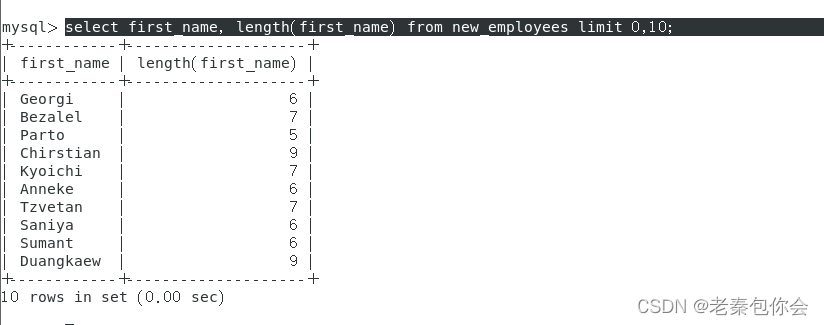
查看字符长度
round
select round(1.22, 3)
注意一下,这里的保留小数不会自动补全,会四舍五入
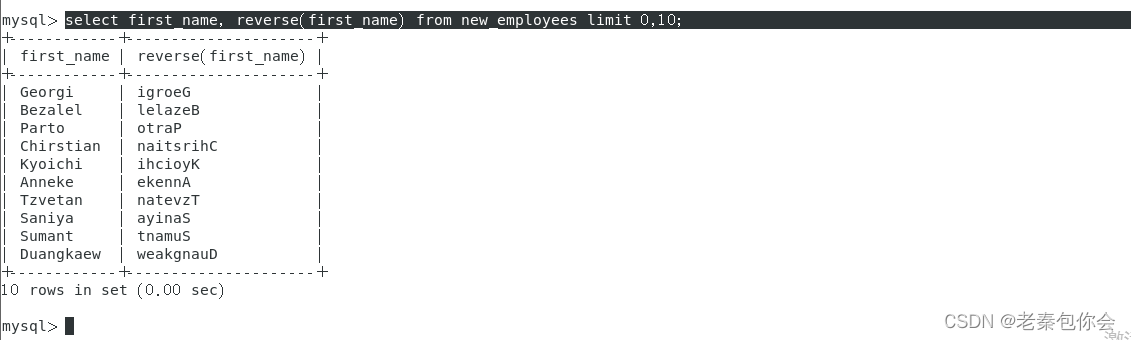
reverse()
字符串翻转
select first_name, reverse(first_name) from new_employees limit 0,10;
substring()
截取字符串
-- 截取字符串
-- start开始的位置,如果没有则默认从第一位开始,length截取的长度
SUBSTRING(column, start, length)column:字段
start:从哪一位开始
length:截取的长度
select first_name, substring(first_name,1,5) from new_employees limit 0,10;

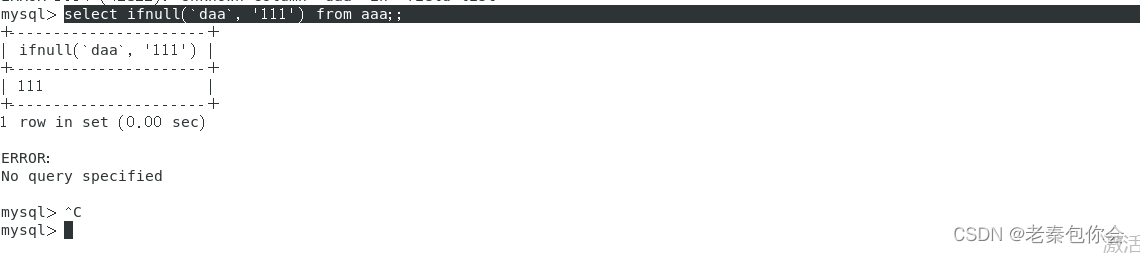
ifnull()
判空
会把null(空)变成别名
select ifnull(`daa`, '111') from aaa;;
isnull
nvl
coalesce
这三个都是一样的效果
case when(当...)
这个函数一点特别,就拿python的if ...elif....else(或者C语言的if.....else if.....else)来说,我们只需写好条件和代码块就行了,但是这个函数的写法是这样的
select
case when 条件
then '运行内容1'
when 条件
then '运行内容2'
else "运行内容"
end as 别名其实sql语句没有格式,这样写是为了让大家好看,when 相当于else if()
cast
以前的数据库的不同类型的数据不能相加和相减的,而现在的数据库有些可以,mysql就是之一

现在已经不支持了,这里演示不了
-- cast(column as data_type)
-- 更改字段类型
select cast(column as int(10)) from table
select cast(column as char(10)) from tablegrouping sets
前面我们学过一个分组,group by,这个方法把所有的符合条件的分成一组,只显示出集体,不显示出个人,简单理解为分组加聚合
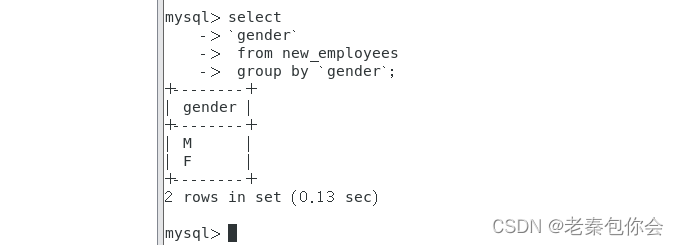
如图,而grouping sets
这个在mysql中也无法使用,但是我们可以做出这样的效果
select
depart
,gender
,count(id) cnt
from table
grouping sets(
(depart) -- 部门维度
,(gender) -- 性别维度
,(depart, gender) -- 部门及性别的维度
,() -- 不分组,全部人数
)但是我们可以分析一下 利用这个方法相对于进行了三次分组然后再利用union distinct连接起来
第一次是分组depart
第二次是分组gender
第三次分组depart, gender
代码:
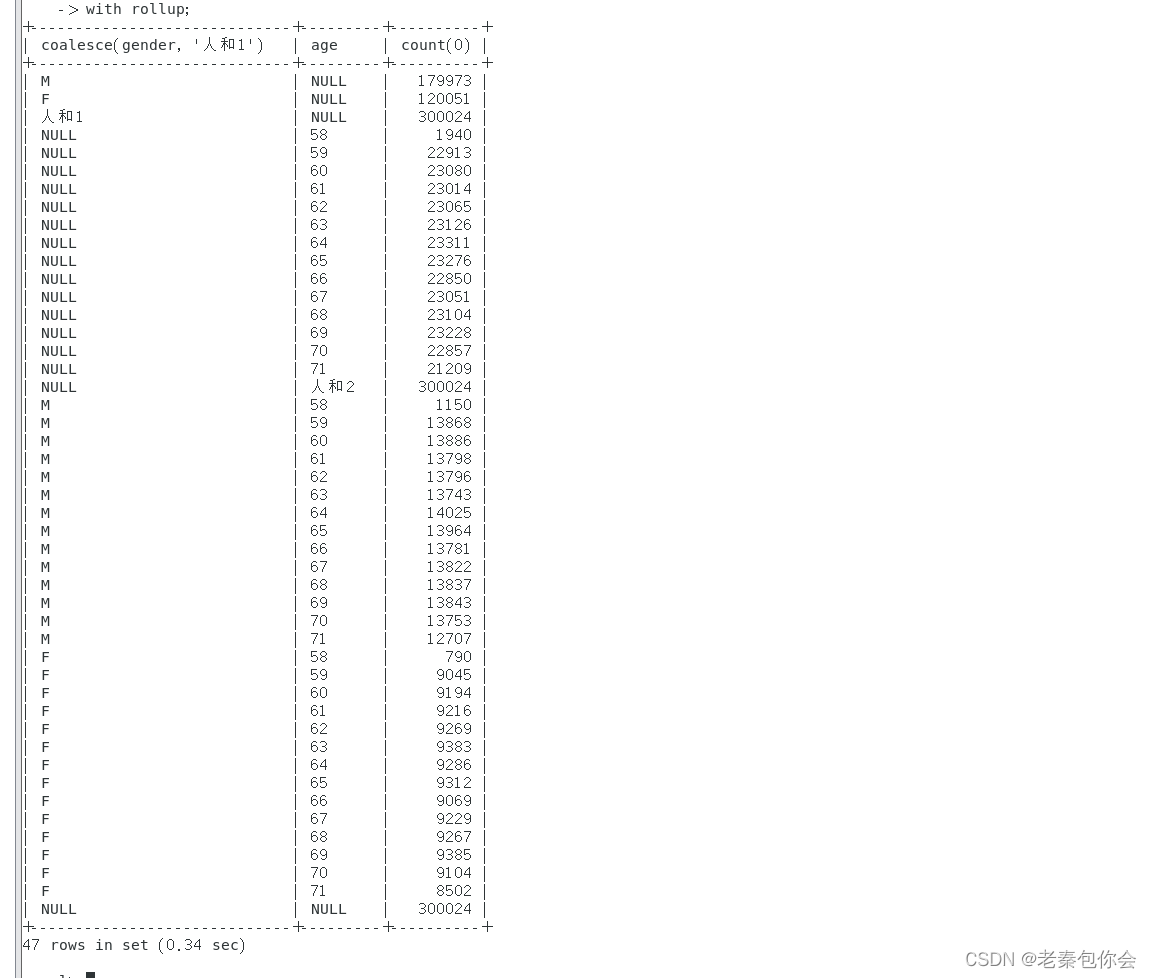
select
coalesce(gender, '人和1')
, null `age`
, count(0)
from new_employees
group by `gender`
with rollup
union distinct
select
null `gender`
, coalesce(age, '人和2')
, count(0)
from new_employees
group by `age`
with rollup
union distinct
select
`gender`
, `age`
, count(0)
from new_employees
group by`gender`, `age`
with rollup;结果:
排序函数
在前面中我们学过一个order by
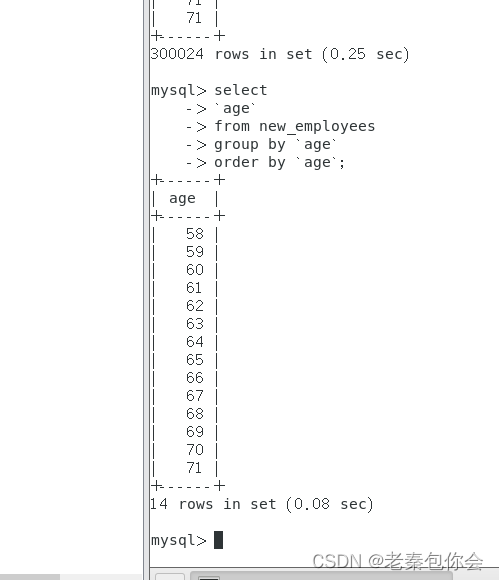
而这个排序函数起到的就是给个编号这样可以方便我们查找
分三类
row_number() over() as 别名 ====》从小到大,依次往下
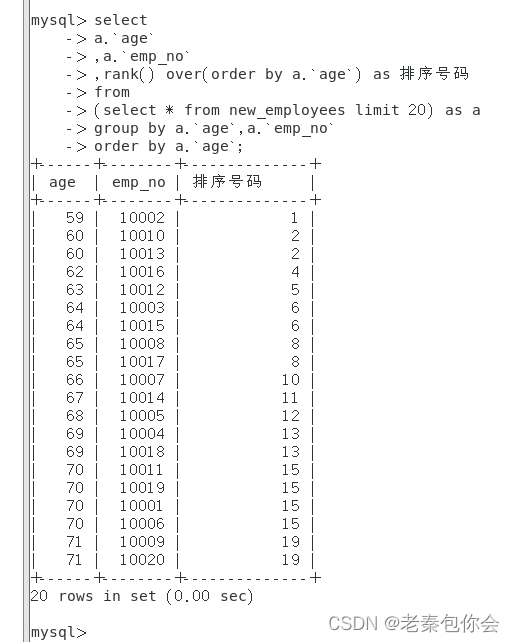
rank() over() as 别名 ======》从小到大 相同数据位居一样,但是不同数据名次依旧
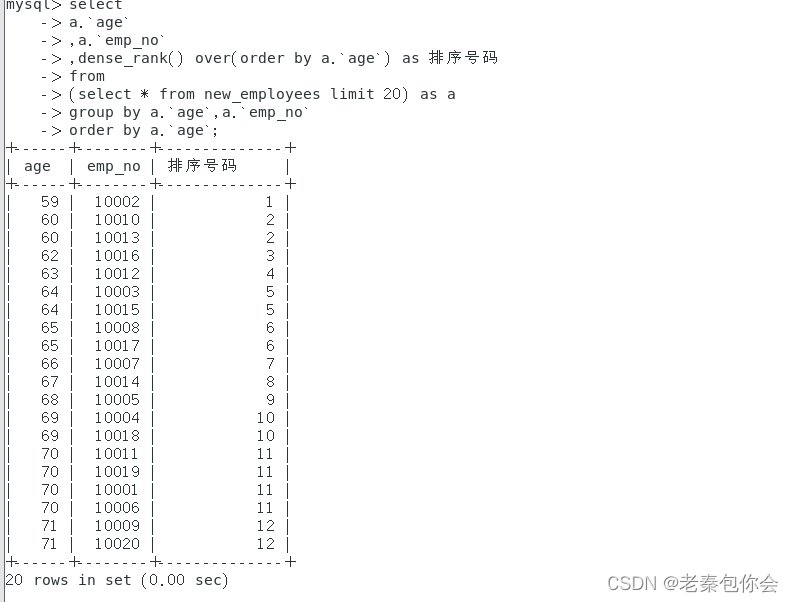
dense_rank() over() as 别名 =====》从小到大,相同数据位居一样 名次从1开始无断层
-- row_number() 根据选择字段排序,若存在相同数据,则随机排顺序
-- 根据年龄从大到小排序
select
row_number() over(order by age desc) rk
from table
-- rank() 根据选择字段排序,若存在相同数据,则并列名次,但是名次个数任然占用
-- 根据年龄从小到大排序
select
rank() over(order by age) rk
from table
-- dense_rank() 根据选择字段排序,若存在相同数据,则并列名次,但是名次个数不占用
-- 根据年龄从小到大排序
select
dense_rank() over(order by age) rk
from table
开窗函数
-- function([column]) OVER(partition by column [order by column])
-- function通常为聚合函数,也可以是排序的函数
-- 根据性别和年龄分组,对身高进行排序
select
row_number() over(partition by gender, age order by high) rk
from table
-- 根据性别和年龄分组,求出人数
select
count(id) over(partition by gender, age) cnt
from table
where id is not null记住一定要有函数function,可以是avg() sum()等
partition by 是我们可以理解为是group by 的前半身,只分组不聚合,因为group by有有聚合的效果,而开窗函数缺少聚合效果,简单的说分组男女性别,就是会显示出哪个人是男性及相关信息
row_number() over () as 别名
select
emp_no
,age
,dept_no
,gender
,row_number() over(partition by dept_no,gender order by age desc) as kkk
from (
select
a.emp_no
,a.age
,a.gender
,b.dept_no
from new_employees as a join dept_emp as b on a.emp_no =b.emp_no
) as c
limit 30;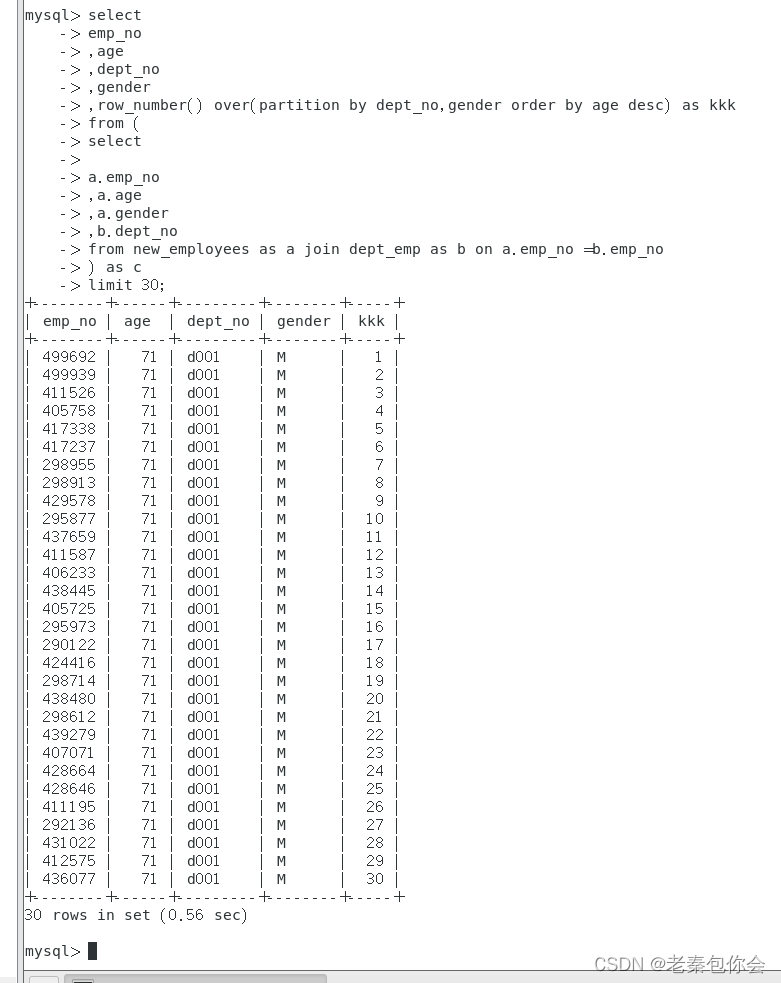
count(0)over()as 别名
select
emp_no
,age
,dept_no
,gender
,count(1) over(partition by dept_no,gender) as kkk
from (
select
a.emp_no
,a.age
,a.gender
,b.dept_no
from new_employees as a join dept_emp as b on a.emp_no =b.emp_no limit 30
) as c;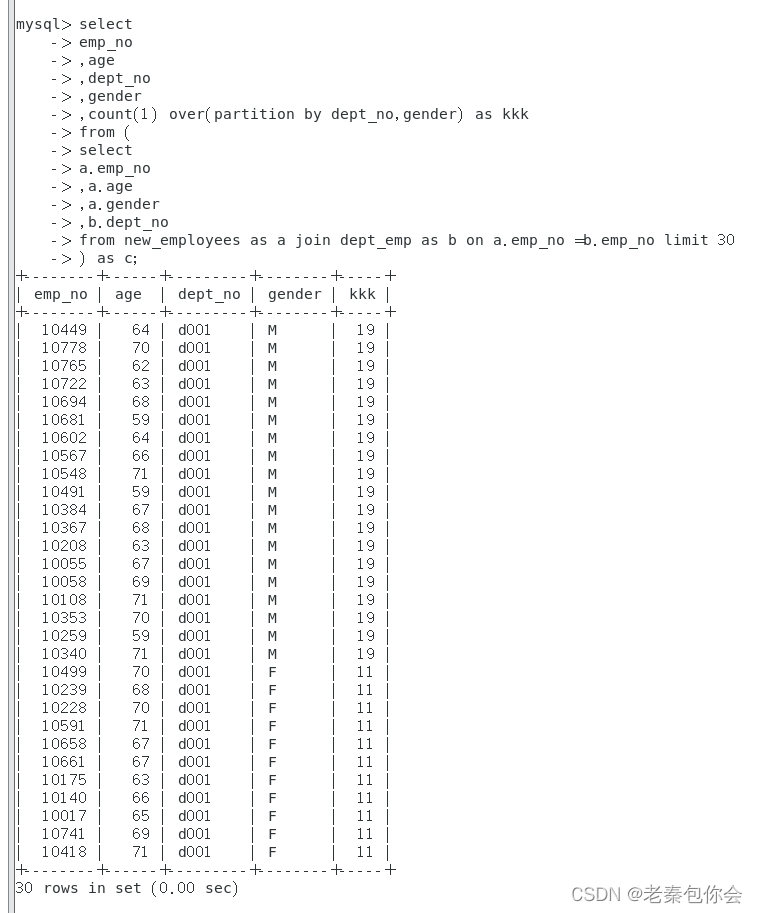
可以看出kkk有重复的数据,就拿第一条数据说 这条数据属于这19个数据,如果把count函数替换成avg(age)就可以明确哪个人超出平均值,哪些人没有超出
总结:
关于sql语句先介绍到这里,有不懂的小可爱可以私聊