设计性能认知
延时
| 操作名称 | 时间 |
|---|---|
| 1级缓存引用 | 0.5ns |
| 2级缓存引用 | 7ns |
| 互斥锁/解锁 | 100ns |
| 主存引用 | 100ns |
| 用zippy压缩1k字节 | 10,000ns=10μs |
| 通过1GB网络传输2KB字节 | 20,000ns = 20μs |
| 内存按照顺序读取1MB | 250,000ns=250μs |
| 同一个数据中心内的往返 | 500,000ns = 500μs |
| 磁盘寻找 | 10,000.000ns=10ms |
| 从网络中读取1MB | 10,000.000ns=10ms |
| 从硬盘中读取1MB | 30,000.000ns=30ms |
| 发送数据包CA(加利福尼亚)->荷兰->CA | 150,000.000ns=150ms |
可用性
| 可用性 | 每天停机时间 | 每年停机时间 |
|---|---|---|
| 99% | 14.40分钟 | 3.65日 |
| 99.9% | 1.44分钟 | 8.77小时 |
| 99.99% | 8.64秒 | 52.60分钟 |
| 99.999% | 864毫秒 | 5.62分钟 |
| 99.9999% | 86.4毫秒 | 31.56秒 |
系统设计步骤框架
步骤1 -理解问题并确定设计范围
步骤2 -提出高层次的设计并获得支持
步骤3 -重点难点的深度思考
步骤4 -价值和发展包装
常见设计场景
限速器设计
设计范围考虑
服务端or客户端
限速指标,ip?id?
系统规模
分布式or单机
高层次设计
位置
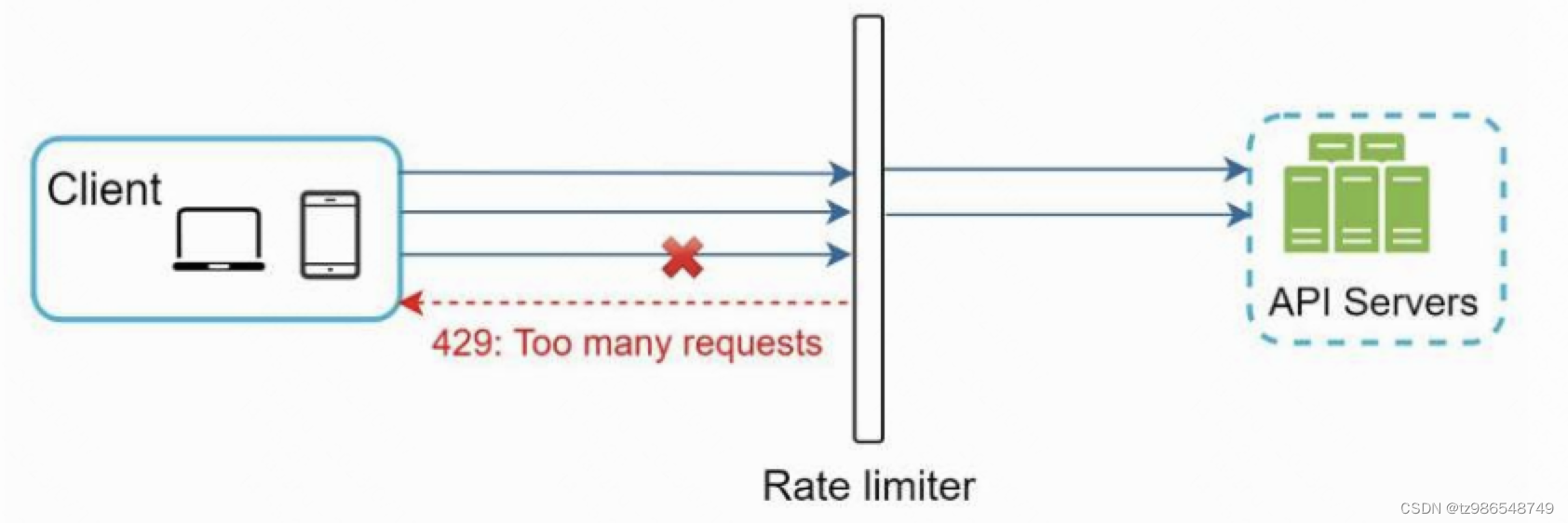
API网关是完全托管的支持速率限制、SSL终止、身份验证、IP白名单、服务的服务静态内容等。在API网关做统一的入口限速。服务之间的rpc,在rpc调用和接收层做控制。
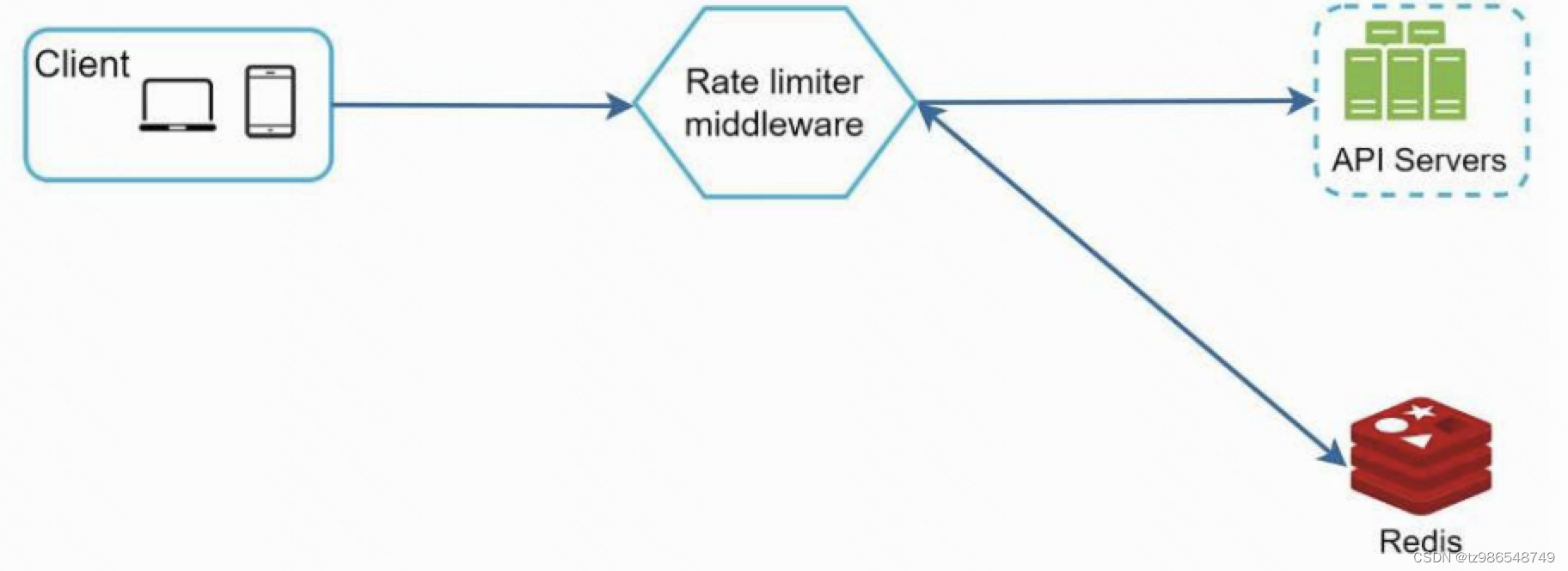
使用缓存支持分布式和高效读写,常用INCR和EXPIRE
算法
| 算法名称 | 算法原理 | 优点 | 缺点 |
|---|---|---|---|
| 令牌桶算法 | 令牌被放入桶中定期以预设的速率。一旦桶填满,就不会再添加令牌。请求拿到令牌才能经过,否则丢弃。核心参数桶大小、填充率,根据限流维度设计桶 | 易于实现,内存效率高 | 可能有爆发流量,调参难 |
| 漏桶算法 | 请求到达时,队列未满,则请求添加到队列中,否则丢弃,队列中请求定期取出处理。核心参数桶大小、流出率 | 稳定的用例流出率 | 调参难 |
| 滑动窗口计数算法 | 将一段时间分割成多个段来表示最近的请求分布,新的一毫秒可能淘汰最老的一毫秒桶 | 平滑了高峰流量,因为速率是基于平均速率以前的窗口。 | 时间存在误差,但是影响小 |
深度思考
规则如何制定
配置文件,文件可以通过从限流服务处拉取,方便配置
如何返回限流信息
http头中定义,如当前窗口剩余请求次数,预期什么时间可以重试等等
被限制的如何处理
丢弃规则,直接错误返回,排队,降级
分布式问题
多个限流服务器数据需要同步,所以使用同一redis
分布式竞争问题
redis Lua脚本
价值发展
除了http多协议支持
其他层面(ip层等)限速考虑
处理跟踪
分布式唯一id设计
设计范围
已知分布式,流量多大
高层次设计
- UUID
简单唯一速度快,但是写入索引效率降低,一般不采用 - 数据库自增id
会有高并发瓶颈 - 雪花算法
符号位+时间戳+机器id+序号
符号位为0,0表示正数,ID为正数,所以固定为0。
时间戳位不用多说,用来存放时间戳,单位是ms,时间戳部分占41bit,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始。
工作机器id位用来存放机器的id,通常分为5个区域位+5个服务器标识位。这里比较灵活,比如,可以使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点。
序号位是自增。
深度思考
数据库自增 id优化为双号段
单库生成自增 id,要是高并发的话,就会有瓶颈。专门开一个服务出来,这个服务每次就拿到当前 id 最大值,然后自己递增几个 id,一次性返回一批 id。然后服务端快使用一批时提前异步加载下一批。
雪花算法优化
机器id不便于维护改进
百度UidGenerator用在启动时会往数据库表(uid-generator需要新增一个WORKER_NODE表)中去插入一条数据,数据插入成功后返回的该数据对应的自增唯一id就是该机器的workId,而数据由host,port组成。
美团Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,在启动时都会都在Zookeeper中生成一个顺序Id
系统时间
时钟回拨问题
人为原因或者机器之间时间同步导致时钟往回,此时生成id会重复
短时间的重复可以稍微等待,或者加入拓展位,在回拨时加以区分
设计一个url伸缩器
设计范围
流量,缩短多少,缩短后的可用字符,能否删除或更新
高层次设计
基本用例:
URL缩短:给定一个长URL =>返回一个更短的URL
URL重定向:给定较短的URL =>重定向到原始URL
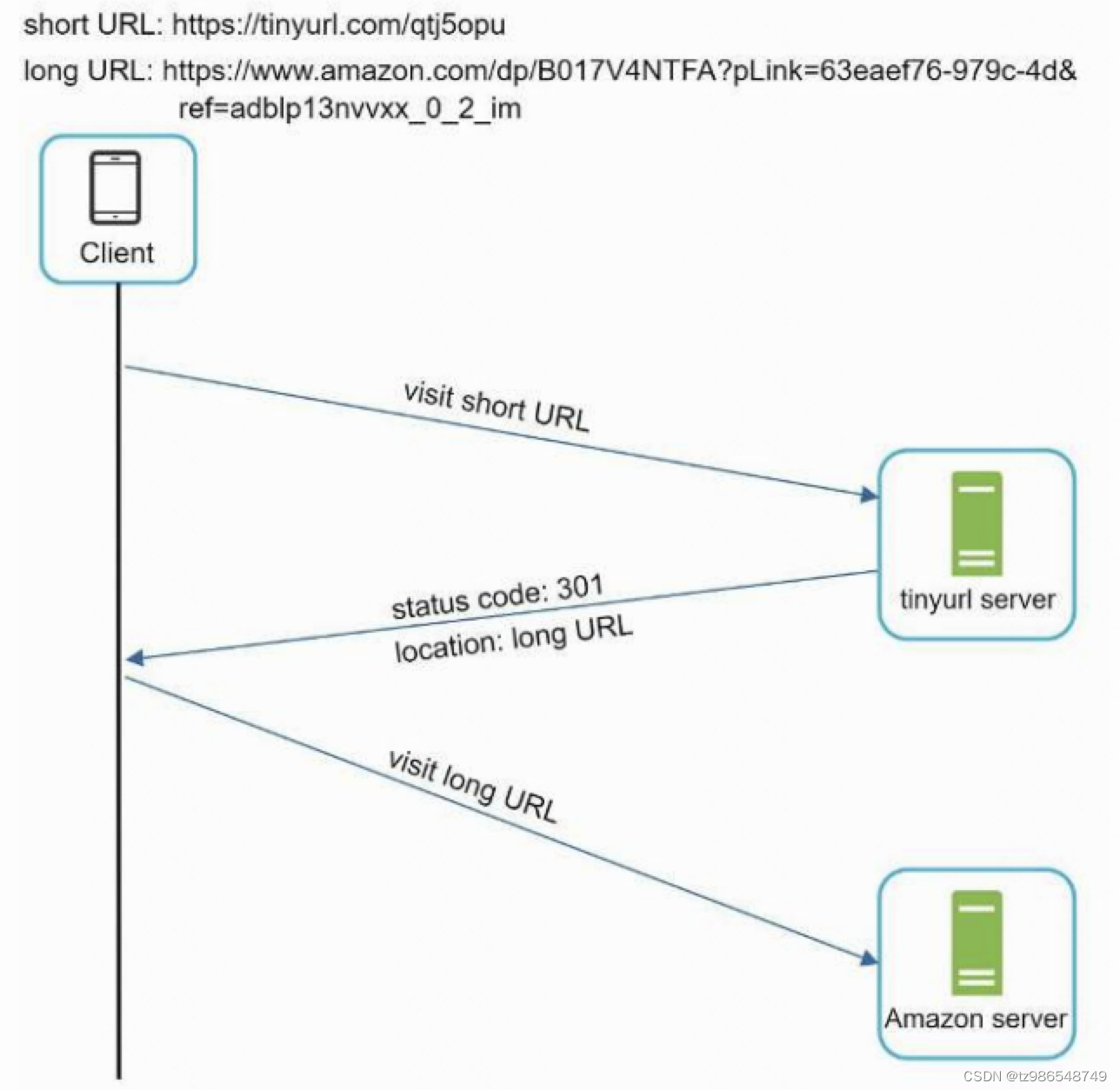
深度思考
缩短方案
如何缩短?使用hash
hash用多少位?用总数据量估计
碰撞了怎么办?在数据库检测碰撞后在原url加信息重新hash直到无碰撞
数据库检测查询成本高怎么办?缓存/布隆过滤器
使用进制转换
对于新的长链接生成一个全局唯一id,然后再进制转换
重定向
负载均衡+缓存+数据库
价值发展
速率限制防攻击
横向动态扩展web和数据库
设计一个网络爬虫
设计范围
设计目的:搜索引擎目录,数据挖掘
爬取数据类型
新增和变更是否需要考虑
是否需要存储
网站数量
预估流量和存储量
高层次设计
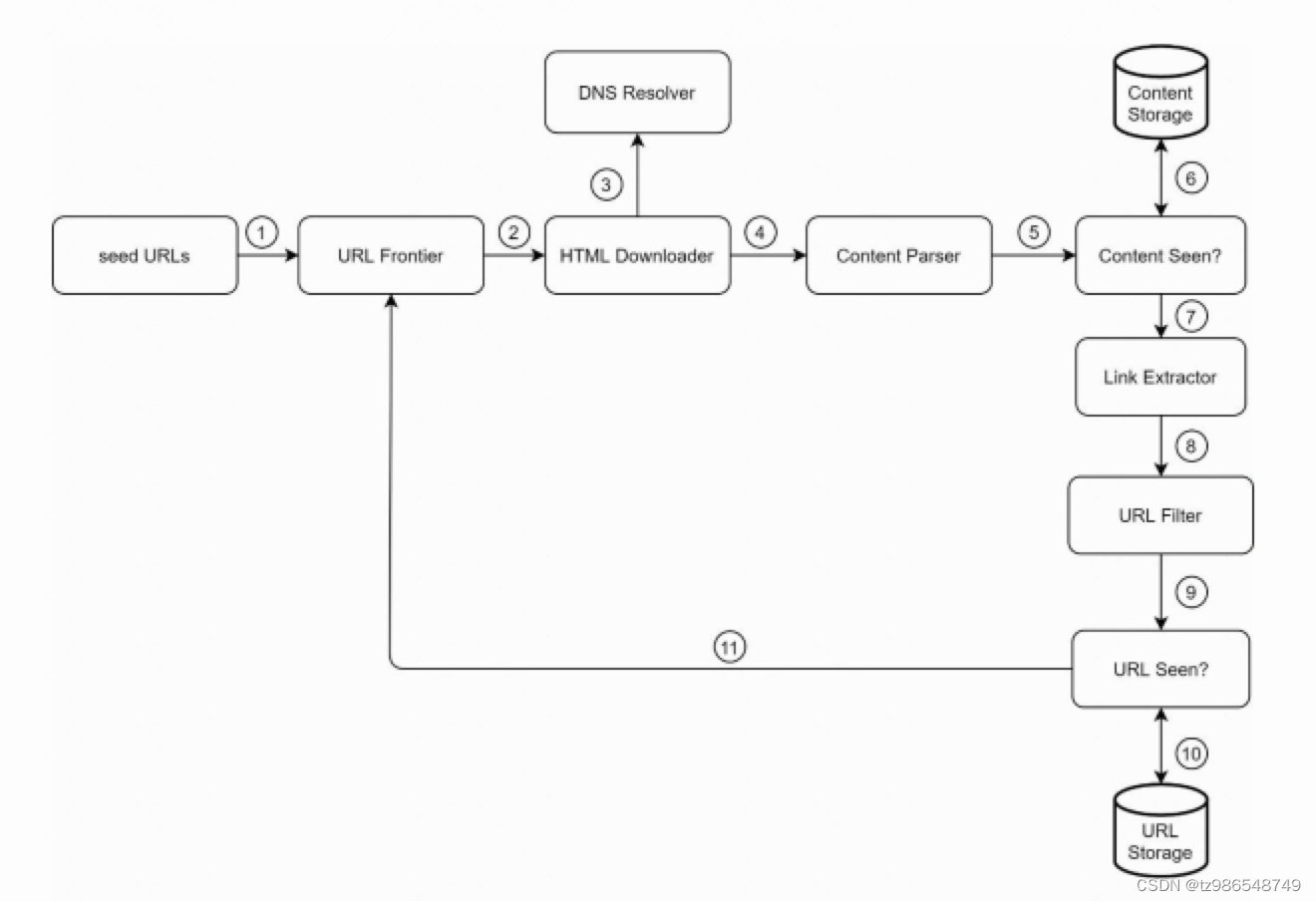
- 添加起始url
- 从待处理url中取一个url
- url找ip开始下载资源
- 解析资源
- 资源去重
- 存储
- 链接提取
- 链接过滤
- 链接去重
- 链接存储
- 递归
深度设计
递归算法
DFS可能过深,且内容相对不够全面,BFS会更好一些。
礼貌访问
关联的链接可能都来自同一个网站,进行爬取时对目标网站的访问可能过大,不太礼貌:对不同的域名用不同的队列存储

优先级
可能需要优先爬取一些关联的官网信息。
优先级队列,或者多个队列不同优先级,高优先级任务放高优先级队列,队列任务优先从高优先级队列取
保鲜
查看网页的更新记录
或者根据存储用hash判断
存储和判断
增加缓存读写
可扩展性
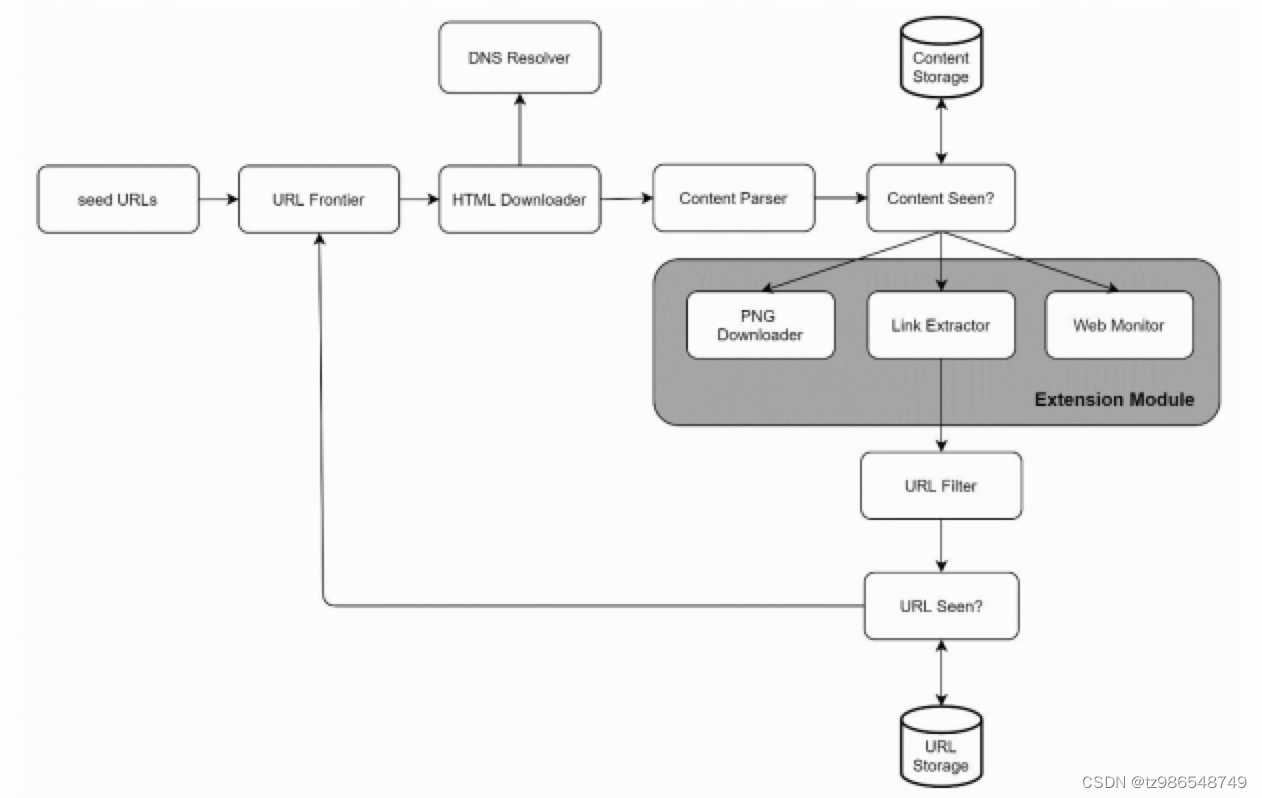
下载类型,过滤规则器(避免死循环,或者可能合规等问题)
价值发展
爬取后的数据如何方便分析和展示
设计一个通知系统
设计范围
类型:SMS、通知推送、邮件
实时性
硬件平台:IOS、android
如何触发:客户端、定时
订阅控制
消息发送量
高层次设计
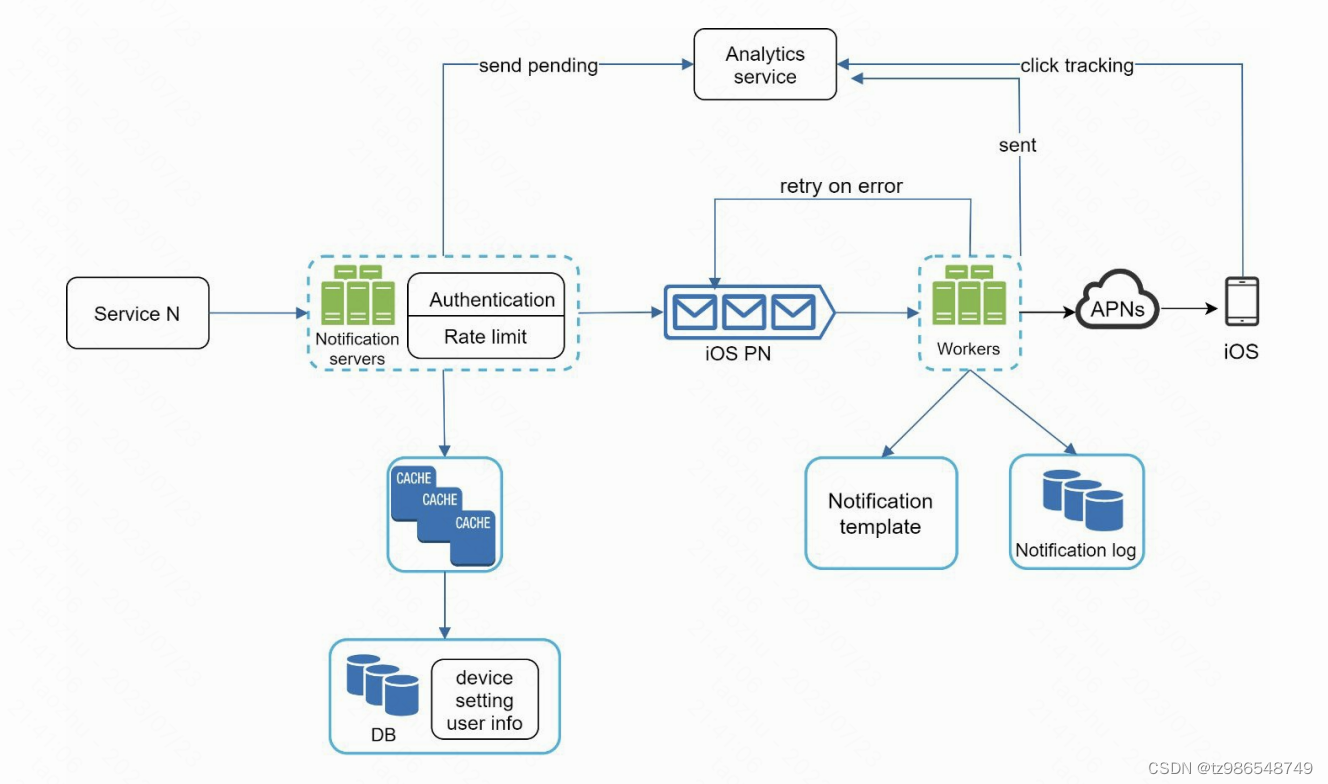
service:多个调用服务,定时任务、客户端
notification servers:提供通知发送api。通过缓存和db查询用户信息进行消息发送
msg queues:解耦,提高并发
workers:拉取事件发送消息
深度设计
消息防丢失、防重复消费、统一协议、监控
价值发展
限速、安全、用户设置
设计一个朋友圈系统
设计范围
使用端app/web/both
主要作用:用户可以发布内容并且可以查看好友发布内容
内容查看顺序:时间倒序
朋友数量
DAU
发送内容:图片/视频/文本
高层次设计
发布内容

Post service:持久化发布内容
Fanout service:朋友内容维护
Notification service:通知发布
读取内容

深度设计
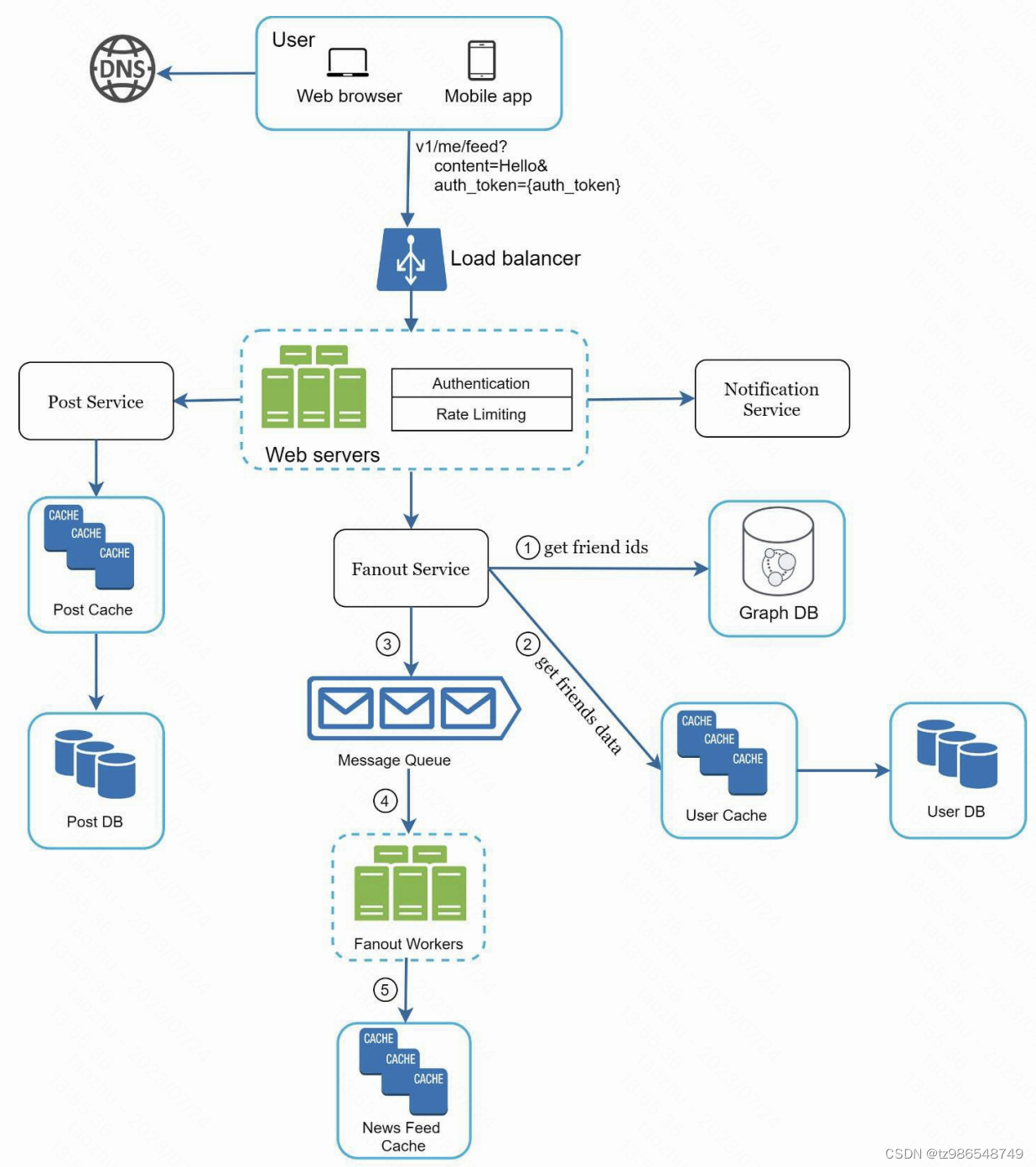
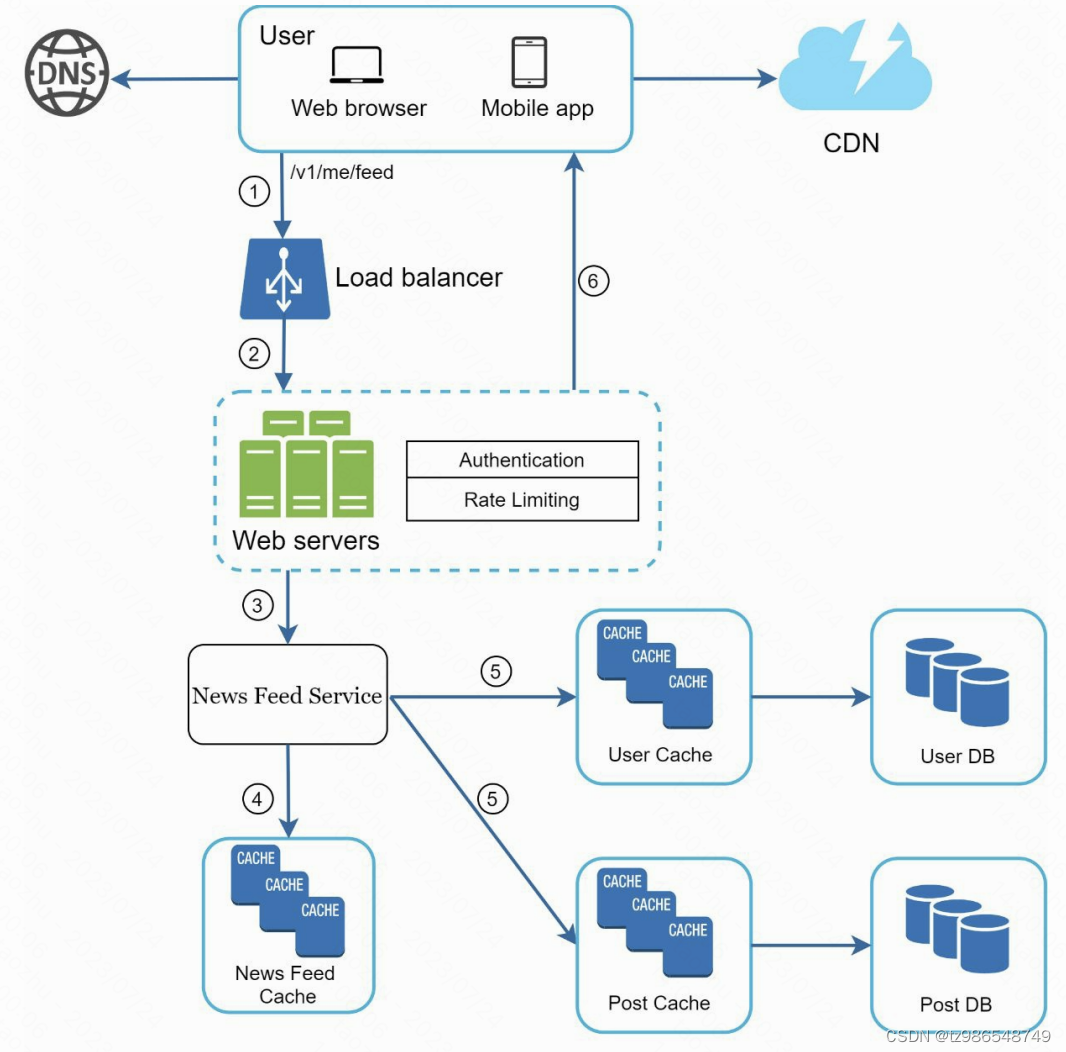
缓存设计
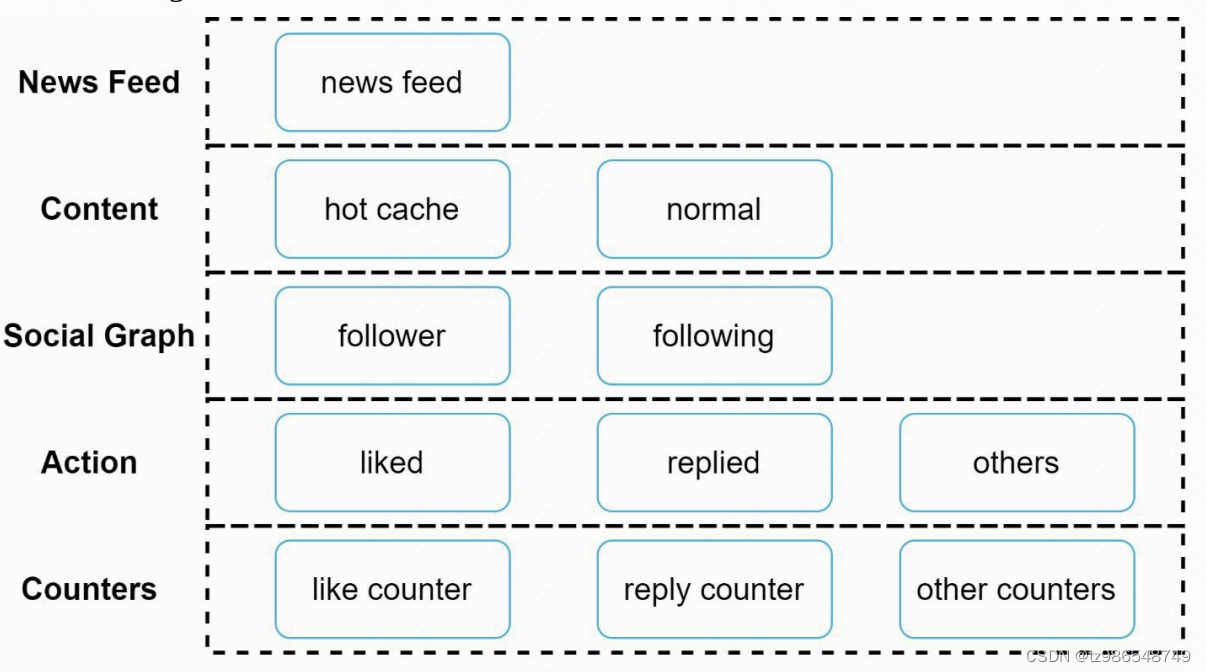
内容id
具体内容
关系图
行为
计数
价值发展
水平扩容
主备
数据分片
热点内容
监控
设计一个聊天系统
设计范围
1v1/group
移动端/web端/both
规模,多少DAU
群人数限制
核心功能:在线显示,支持文字即可
文字长度限制
聊天记录存储多久
高层次设计
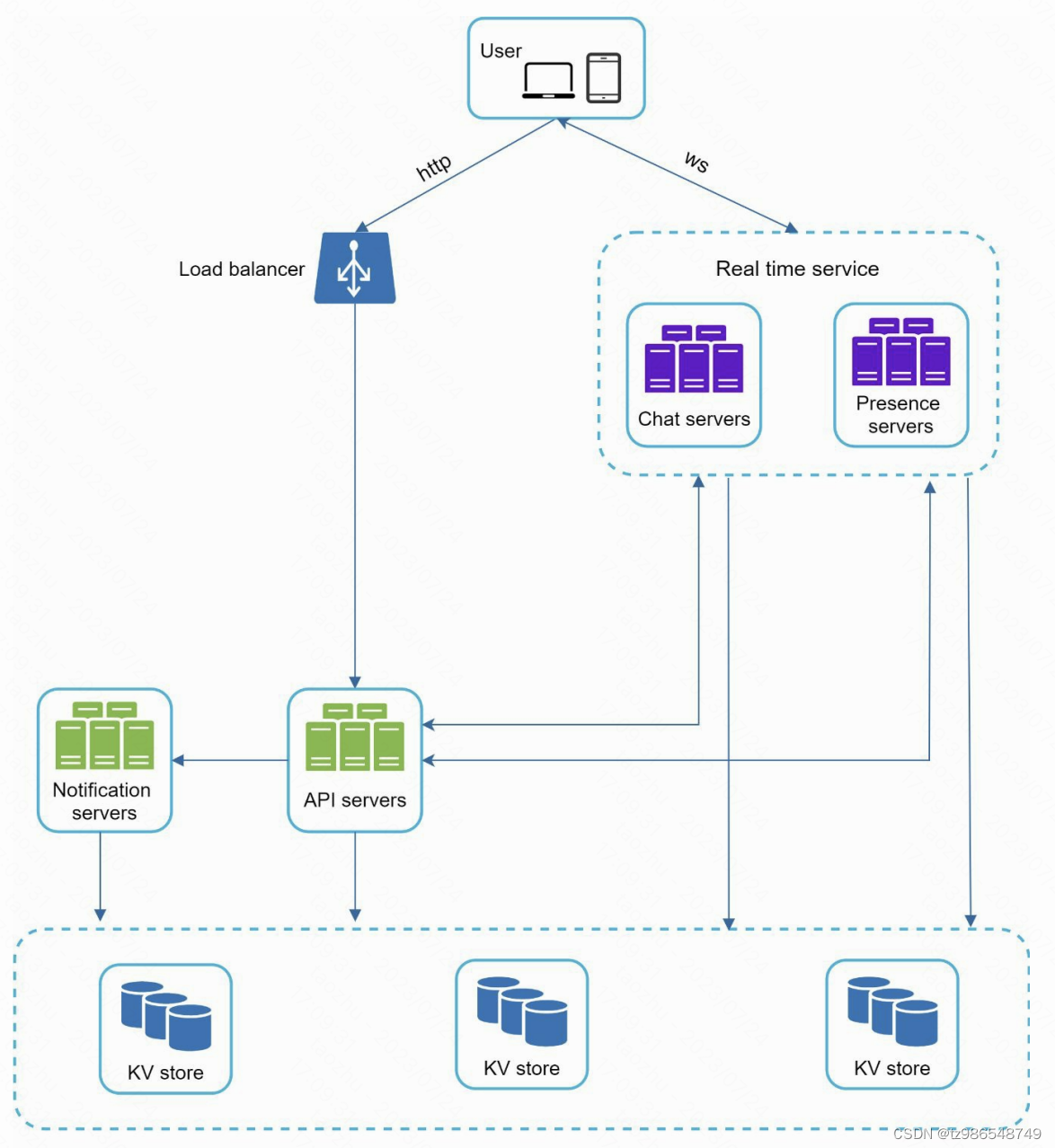
chat servers:提供消息发送和接收能力
Presence servers:管理在线离线状态
API servers:处理用户信息,登陆等
Notification servers:发送通知
kv store:存储历史聊天记录
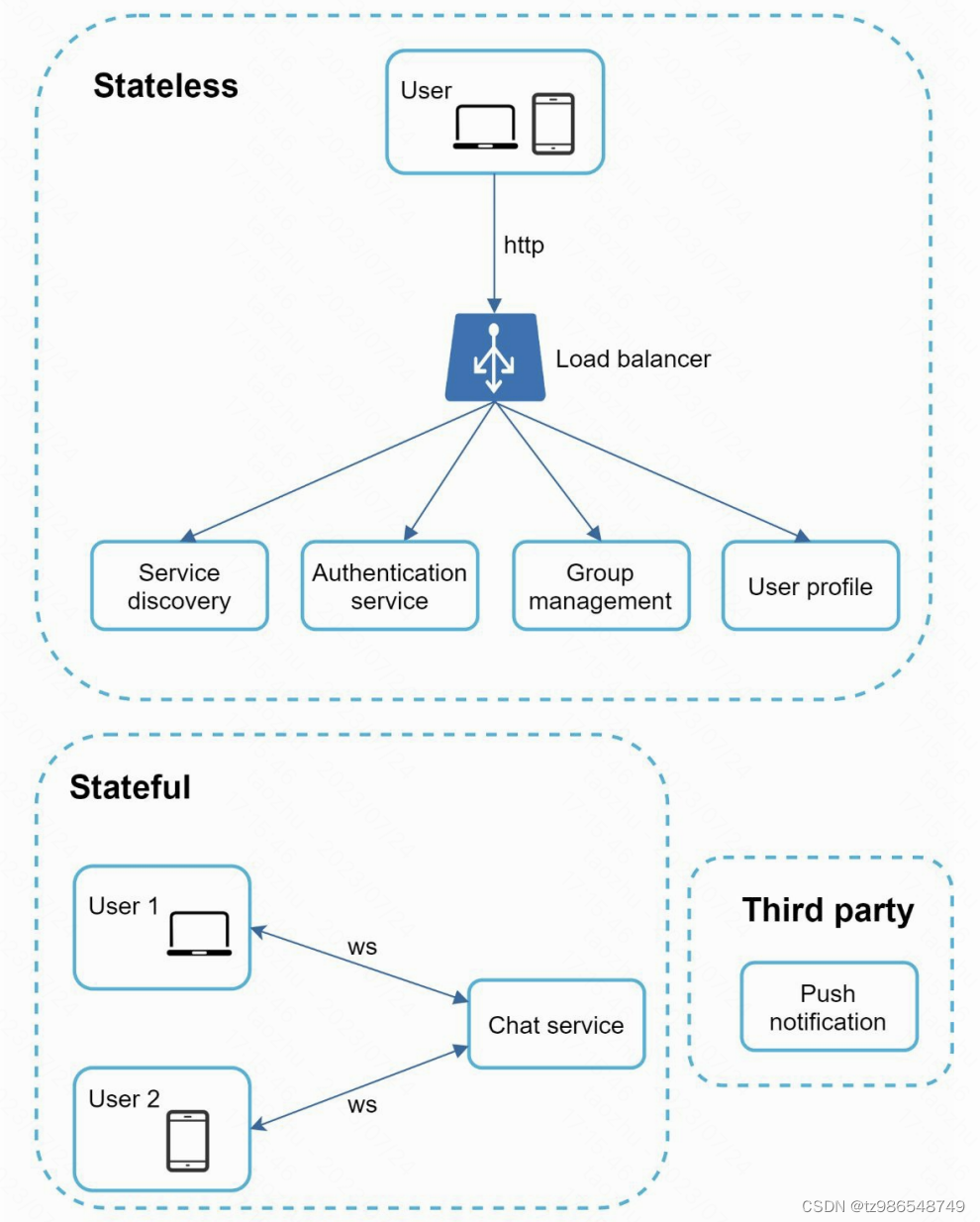
通过轮询或者websocket实现聊天
深度设计
1v1聊天
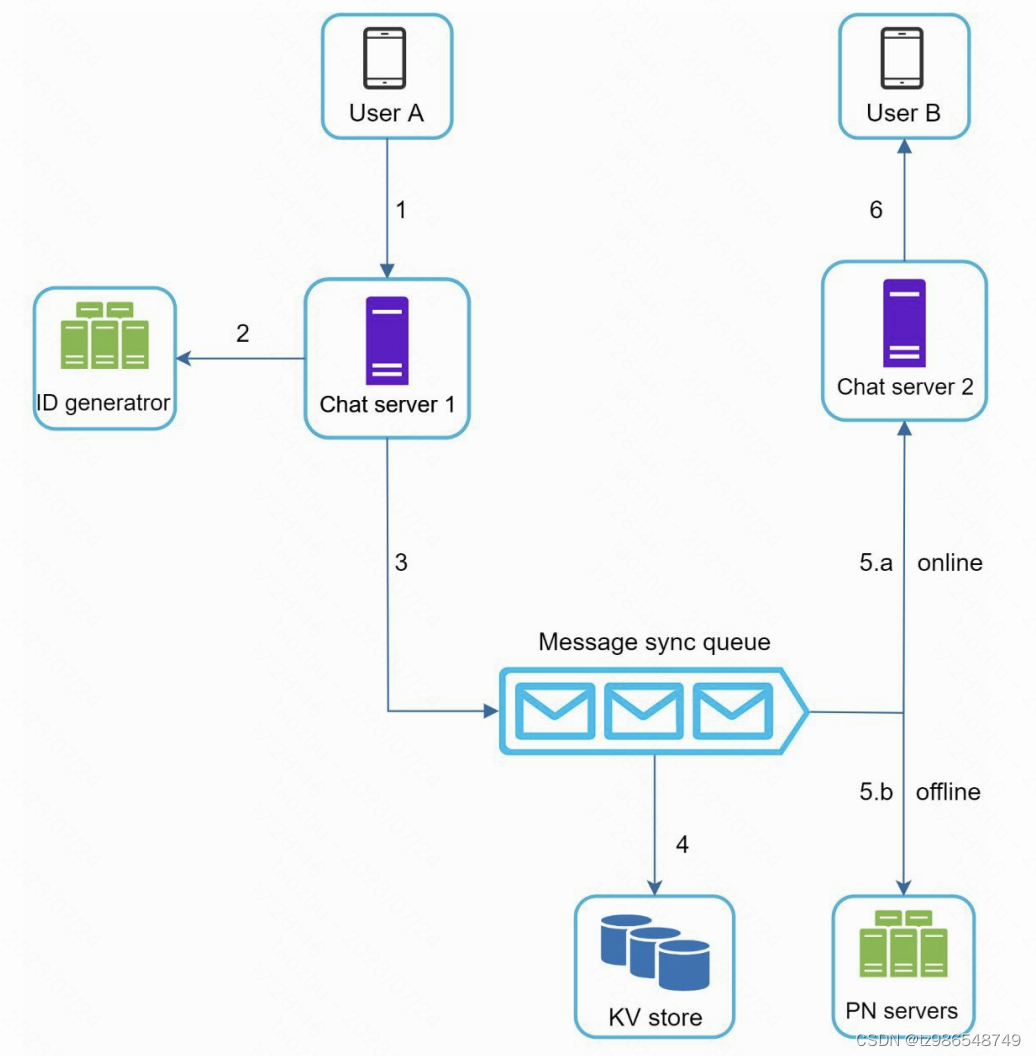
- 用户A发送聊天消息
- 聊天服务获取唯一id
- 发送到消息队列
- 存储消息
- 如果B在线则直接发送到B,否则存储到通知服务
群聊
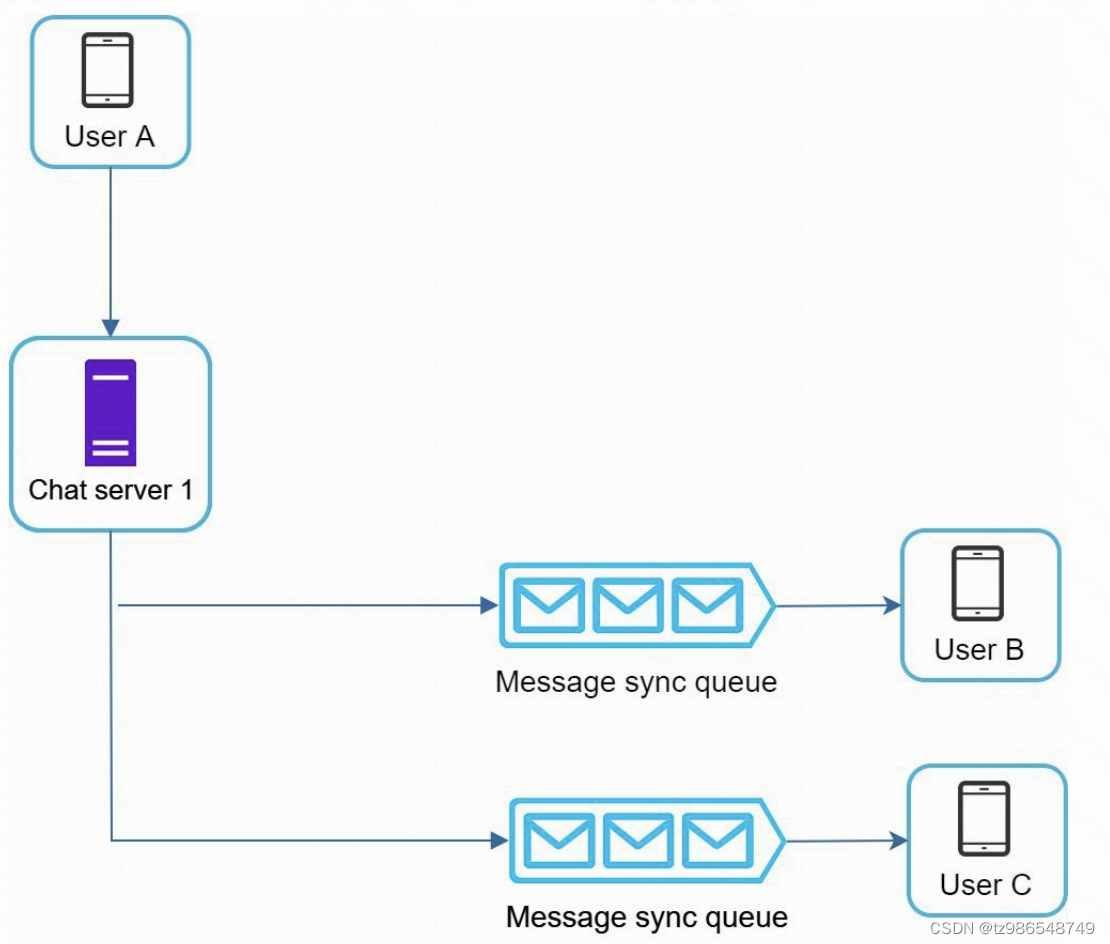
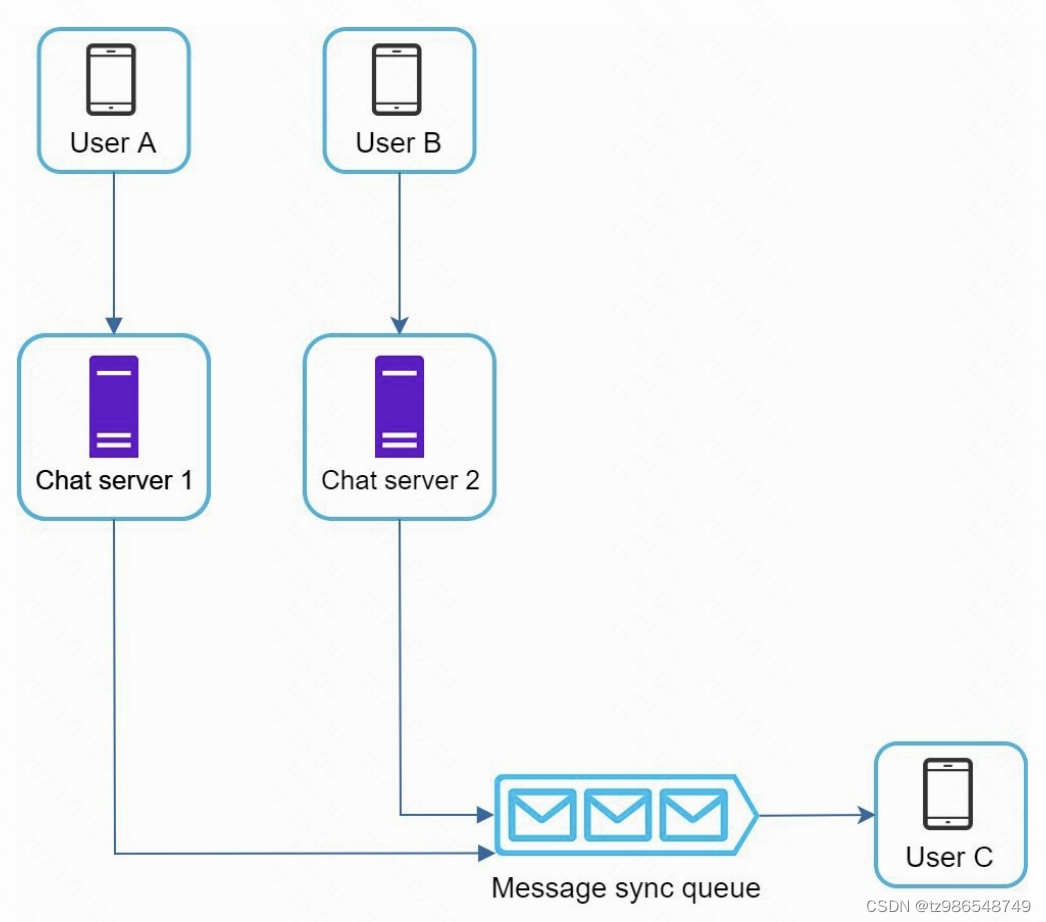
多终端问题

各自维护一个最大msgId,如果小于服务器的最大id则拉取数据
在线离线状态
心跳检测
websocket可直接维护状态

价值发展
多媒体支持
端到端加密
近期消息缓存
设计一个自动补全系统
设计范围
仅根据头补全
补全结果数量topk
补全优先级,历史频率
语言
用户量
高层次设计
数据收集服务
key为搜索单词,value为频率
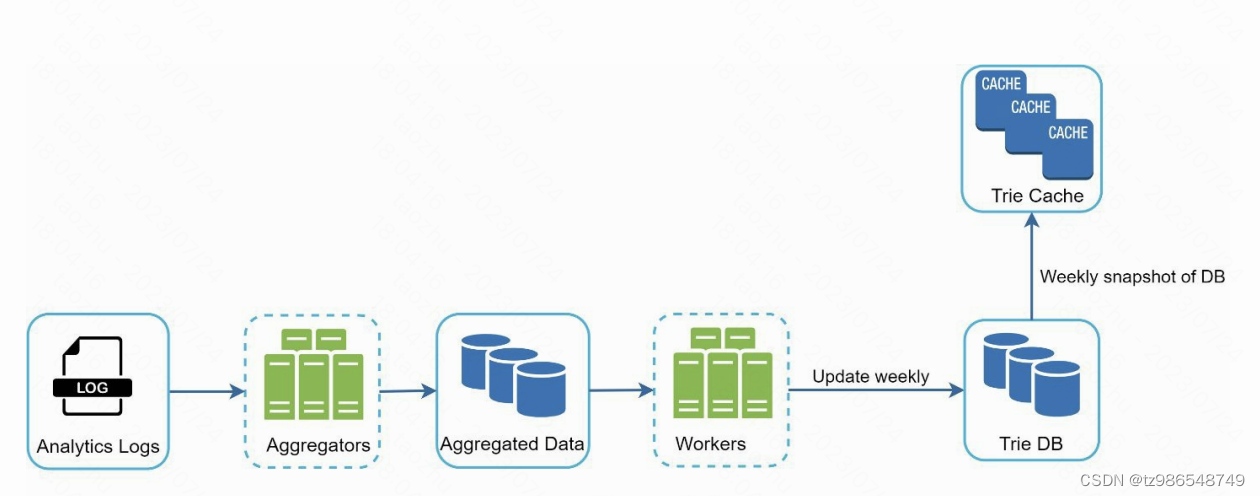
查询服务
select * from frequency_table where query like ‘prefix%’ order by frequency desc limit 5
深度设计
数据结构:前缀树+缓存
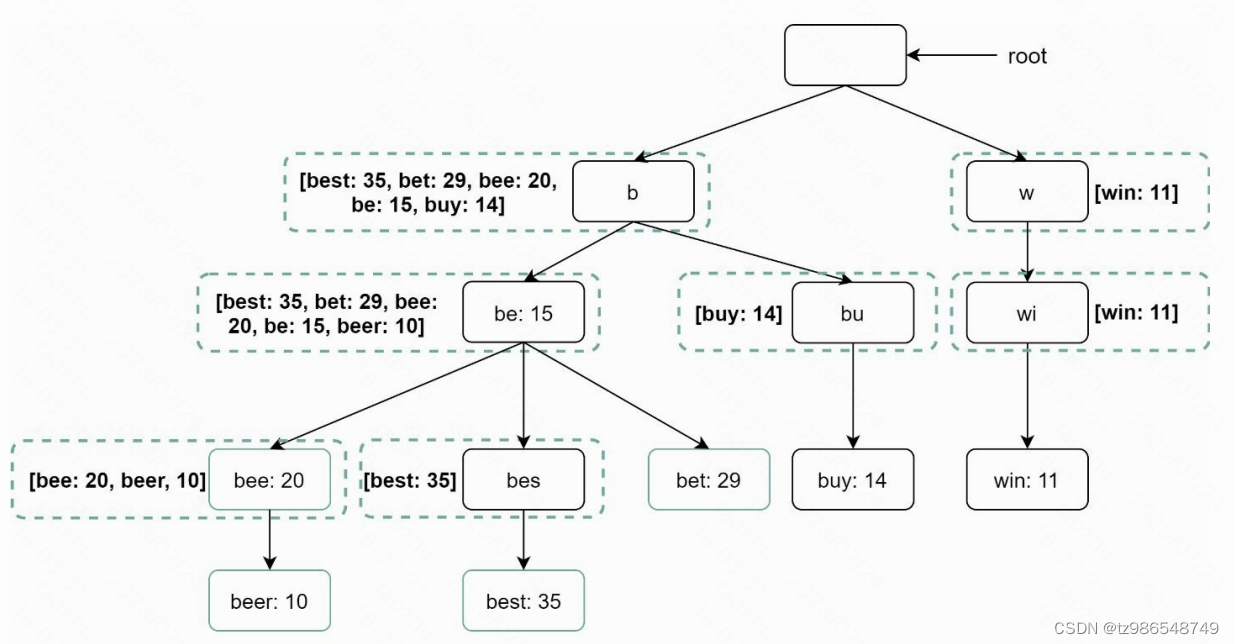
浏览器缓存,提升查询性能
价值发展
多语言:统一编码
实时性:历史和最近分权重、流处理
设计一个YOUTUBE
设计范围
核心功能:上传和查看视频
哪些客户端
日活
平均每人每天花费时间
视频格式
视频大小
存储大小、成本计算
高层次设计
上传
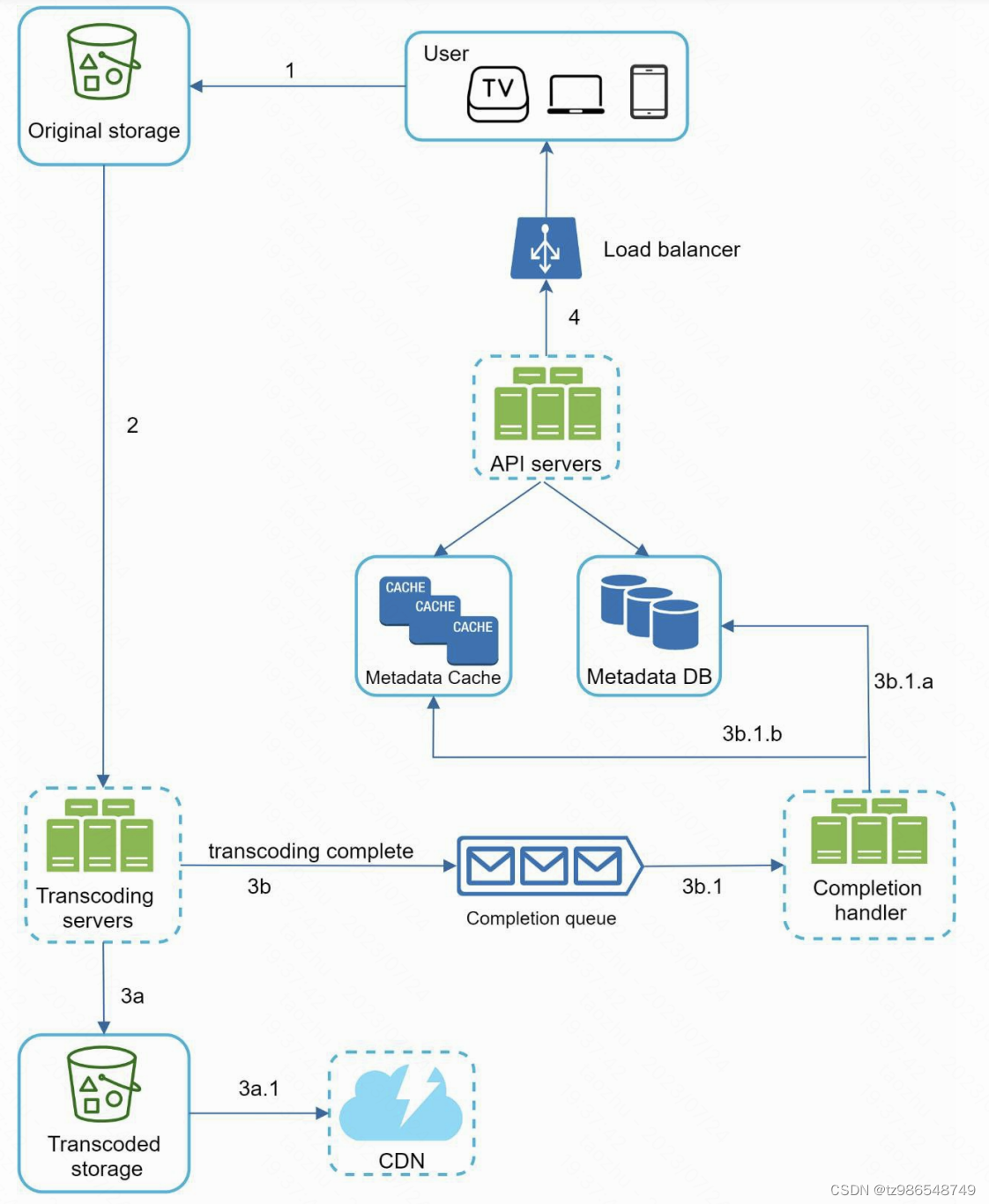
- 上传原始数据存储
- 读取数据并转码
- 转码完成后发送完成事件并存储转码结果分发到CDN,增加数据缓存
- 上传成功
转码的作用
- 压缩
- 多格式支持
- 多清晰度支持
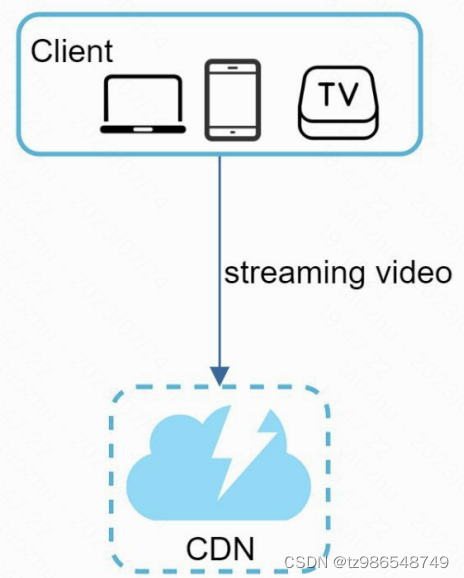
流式读取
深度设计
并行提速
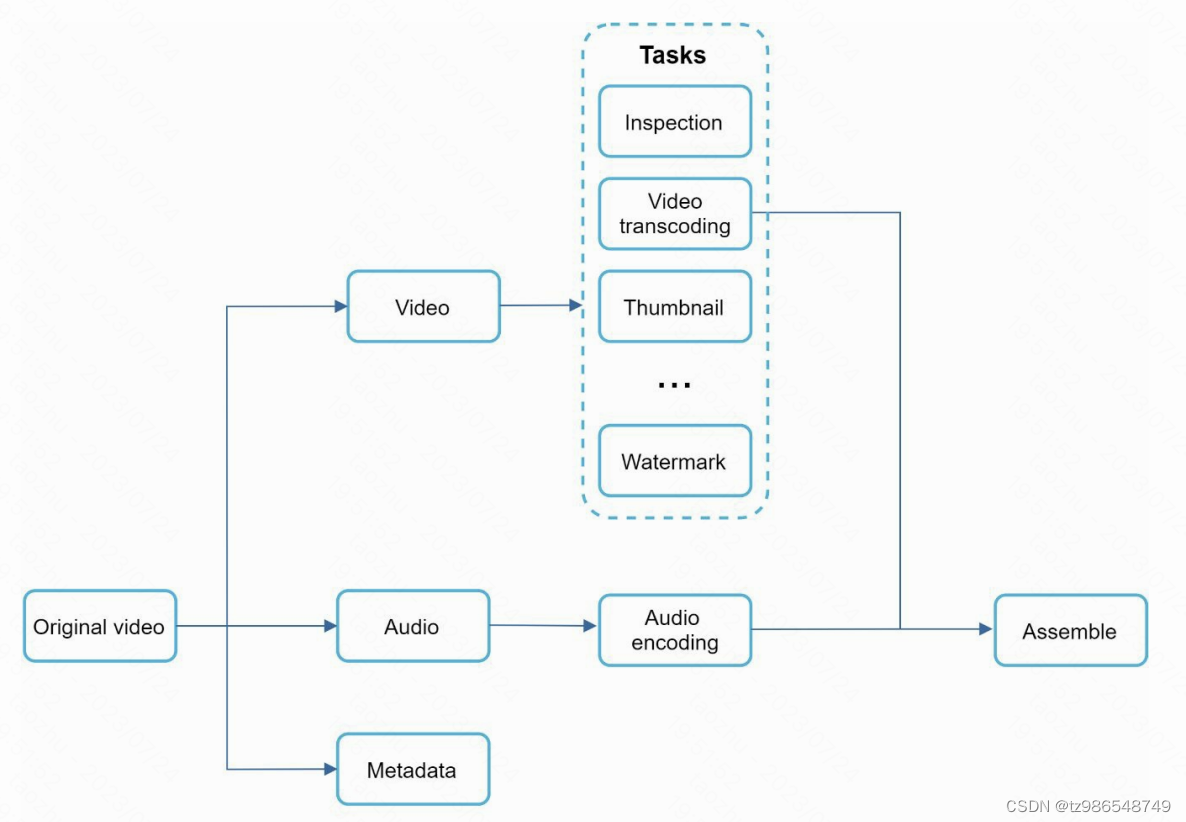
视频相关知识不足跳过这part。。。