目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- Tensorflow 环境
- 模块实现
- 1. 方言分类
- 数据下载及预处理
- 模型构建
- 模型训练及保存
- 2. 语音识别
- 数据预处理
- 模型构建
- 模型训练及保存
- 3. 模型测试
- 功能选择界面
- 语言识别功能实现界面
- 方言分类功能实现界面
- 系统测试
- 1. 训练准确率
- 2. 测试效果
- 3. 模型应用
- 工程源代码下载
- 其它资料下载

前言
本项目利用语音文件和方言标注文件,提取语音的梅尔倒谱系数特征,并对这些特征进行归一化处理。在基于标注文件的指导下,构建了一个字典来管理数据。接着,我们选择WaveNet机器学习模型进行训练,并对模型的输出进行softmax处理。最终,经过训练后的模型将被保存以备后续使用。
在项目中,我们首先获取语音文件和标注文件,并使用相应的技术来提取梅尔倒谱系数特征。这些特征可以捕捉语音信号的频谱信息,并为后续的模型训练提供输入。
为了准确地将语音文件与标注对应起来,我们根据标注文件建立了一个字典,使得每个语音文件能够与其对应的标注信息关联。
为了训练有效的语音识别模型,我们选择了WaveNet机器学习模型。WaveNet是一种基于深度学习的模型,被广泛用于音频生成和识别任务。我们使用训练数据来训练WaveNet模型,以便它能够学习语音文件与对应标注之间的关联。
最后,在训练完成后,我们将模型的输出通过softmax处理,以得到最终的预测结果。这样的处理可以将输出转换为概率分布,使得模型更容易对语音进行正确的识别。
经过这一系列的步骤,我们的项目能够实现对语音文件的识别,并根据标注信息对方言进行分类。训练好的模型将被保存,以备后续在实际应用中使用。这个项目为语音识别领域的进一步研究和应用提供了可靠的基础。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。

系统流程图
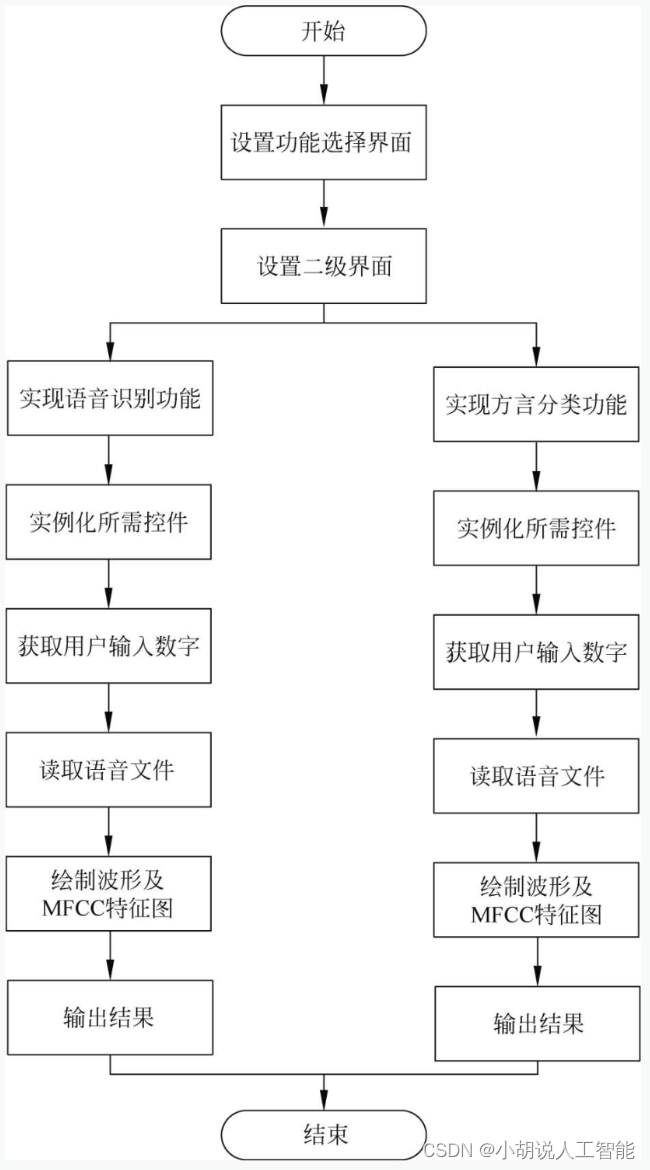
语音识别及方言分类流程如图1所示,页面设计流程如图2所示。

运行环境
本部分包括 Python 环境和Tensorflow 环境。
Python 环境
需要Python 3.6及以上配置,在Windows环境 下推荐下载Anaconda完成Python所需的配置,下载地址为https://www.anaconda.com/。也可以下载虚拟机在Linux环境下运行代码。
Tensorflow 环境
打开Anaconda Prompt,输入清华仓库镜像:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
创建Python 3.6.5环境,名称为TensorFlow。此时Python版本和后面TensorFlow的版本存在匹配问题,此步选择Python3.x。
conda create -n tensorflow python==3.6.5
有需要确认的地方,都按Y键。
在Anaconda Prompt中激活TensorFlow环境:
conda activate tensorflow
安装与python3.6.5匹配的CPU版本的TensorFlow:
pip install tensorflow==1.9
安装Python和TensorFlow匹配的Keras版本,此处为Keras2.2.0:
pip install Keras==2.2.0
三者版本若不匹配,导入Keras时Kernel将会出现问题。
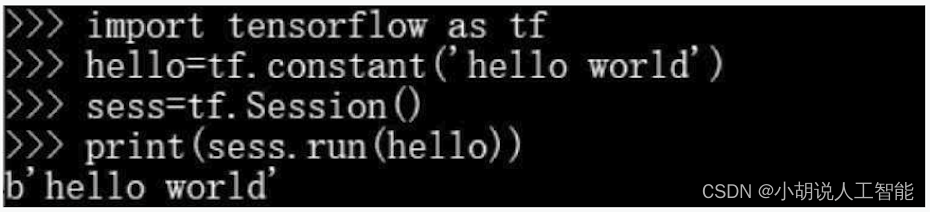
安装完毕,进行检验,在cmd中输入Python后, 按图所示输入,若成功输出则安装成功。
模块实现
本项目包括3个模块:方言分类、语音识别和模型测试,下面分别给出各模块的功能介绍及相关代码。
1. 方言分类
本部分包含数据下载及预处理、模型构建、模型训练及保存。
数据下载及预处理
数据集由科大讯飞提供,内有长沙话、上海 话和南昌话3种方言,包含50~300KB的语音数据集19489条,其中17989条训练数据,1500条验证数据,下载地址为http://challenge.xfyun.cn/2019/。下载数据集并导入,训练集、验证集的数据分别命名为train_fles和dev_fles。通过使用glob ()函数实现,导入数据代码如下:
#加载pcm文件,其中17989条训练数据,1500条验证数据
#定义训练集
train_files = glob.glob(r'D:\homework\dialect\data\*\train\*\*.pcm')
#定义验证集
dev_files = glob.glob(r'D:\homework\dialect\data\*\dev\*\*\*.pcm')
print(len(train_files), len(dev_files),train_files[0])
#打印语音数据集的数量与训练集第一条数据
对下载的语音数据集进行整理分类,为训练集和验证集中的每一条数据打标签。相关代码如下:
labels = {'train': [], 'dev': []}
#对于train_files中的每一条数据
for i in tqdm(range(len(train_files))):
path = train_files[i] #取出路径
label = path.split('\\')[1] #以'\\'划分路径,取出其中对应地区分类的标签
labels['train'].append(label)#以字典进行存储
#对于dev_files中的每一条数据进行如上操作
for i in tqdm(range(len(dev_files))):
path = dev_files[i]
label = path.split('\\')[1]
labels['dev'].append(label)
print(len(labels['train']), len(labels['dev']))
#整理每条语音数据对应的分类标签图
数据集下载后进行预处理。定义处理语音数据、pcm格式转wav格式、可视化语音数据集的3个函数。由于语音片段长短不一,去除少于1s的短片段,并将长片段切分为不超过3s的片段。
a. 处理语音数据
相关代码如下:
def load_and_trim(path, sr=16000):
audio = np.memmap(path, dtype='h', mode='r') #对大文件分段读取
audio = audio[2000:-2000]
audio = audio.astype(np.float32)
energy = librosa.feature.rms(audio) #计算能量
frames = np.nonzero(energy >= np.max(energy) / 5) #最大能量的1/5视为静音
indices = librosa.core.frames_to_samples(frames)[1]#去除静音
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
slices = []#存储划分为小于3s大于1s的切片
for i in range(0, audio.shape[0], slice_length):
s = audio[i: i + slice_length]#切分为3s片段
if s.shape[0] >= min_length:
slices.append(s) #去除小于1s的片段
return audio, slices
b. pcm转wav函数
相关代码代码如下:
def pcm2wav(pcm_path, wav_path, channels=1, bits=16, sample_rate=sr):
data = open(pcm_path, 'rb').read() #读取文件
fw = wave.open(wav_path, 'wb') #存储wav路径
fw.setnchannels(channels) #设置通道数:单声道
fw.setsampwidth(bits // 8) #将样本宽度设置为bits/8个字节
fw.setframerate(sample_rate) #设置采样率
fw.writeframes(data) #写入data个长度的音频
fw.close()
c. 可视化语音数据集函数
相关代码如下:
def visualize(index, source='train'):
if source == 'train':
path = train_files[index] #训练集路径
else:
path = dev_files[index] #验证集路径
print(path)
audio, slices = load_and_trim(path) #去除两端静音,并切分为片段
print('Duration: %.2f s' % (audio.shape[0] / sr)) #打印处理后的长度
plt.figure(figsize=(12, 3)) #图像大小
plt.plot(np.arange(len(audio)), audio) #绘制波形
plt.title('Raw Audio Signal') #设置标题
plt.xlabel('Time') #设置横坐标
plt.ylabel('Audio Amplitude') #设置纵坐标
plt.show() #绘图展示
feature = mfcc(audio, sr, numcep=mfcc_dim) #提取mfcc特征
print('Shape of MFCC:', feature.shape) #打印mfcc特征
fig = plt.figure(figsize=(12, 5)) #图像大小
ax = fig.add_subplot(111)
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto') #绘制mfcc
plt.title('Normalized MFCC') #图像标题
plt.ylabel('Time') #设置纵坐标
plt.xlabel('MFCC Coefficient') #设置横坐标
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False); #设置横坐标间隔
plt.show() #绘图展示
wav_path = r'D:/homework/dialect/example.wav'#wav文件存储路径
pcm2wav(path, wav_path) #pcm文件转化为wav文件
return wav_path
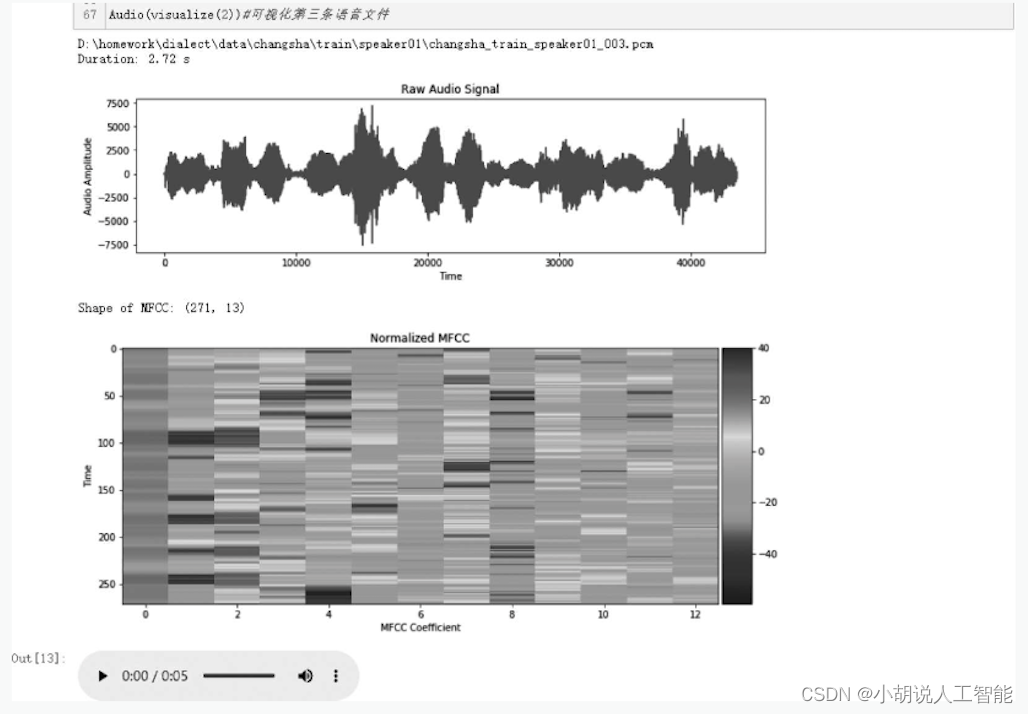
以可视化第3条语音数据为例,结果如图3所示。分别将训练集和验证集的MFCC特征进行归一化处理,相关代码如下:
#对训练集MFCC特征归一化
X_train = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_train]
#对验证集MFCC特征归一化
X_dev = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_dev]
使用LabelEncoder()将标签处理为整数,并通过to_categorical()函数将训练集和验证集分别转化为向量,再定义迭代器函数,相关代码如下:
le = LabelEncoder()
Y_train = le.fit_transform(Y_train) #处理训练集标签
Y_dev = le.transform(Y_dev) #处理验证集标签
num_class = len(le.classes_) #3个类别
Y_train = to_categorical(Y_train, num_class) #将训练集转化为向量
Y_dev = to_categorical(Y_dev, num_class) #将验证集转化为向量
模型构建
数据加载进模型之后,需要定义模型结构,并优化损失函数。
(1) 定义模型结构
模型使用多层因果空洞卷积(Causal Dilated Convolution)处理数据。首先,构建并使用一维卷积层;其次,引入BN (BatchNormalization) 算法、定义batchnorm ()函数进行正则化,用以消除模型的过拟合问题;再次,定义activation ()函数,用于激活神经网络训练;最后,定义res_block () 函数,基础块常用Conv+BN+Relu+Conv+BN侧边分支的模式,达到修复目的。通过GlobalMaxPooling1D ()对整个序列输出进行降维,定义softmax逻辑回归模型。最后一层卷积的特征图个数和字典大小相同,经过softmax函数处理之后,对每一个小片段对应的MFCC都能得到在整个字典上的概率分布。相关代码如下:
#定义多层因果空洞卷积MFCC一维,使用conv1d
def conv1d(inputs, filters, kernel_size, dilation_rate):
return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
#加速神经网络训练BN算法
def batchnorm(inputs):
return BatchNormalization()(inputs)
#定义神经网络激活函数
def activation(inputs, activation):
return Activation(activation)(inputs)
def res_block(inputs, filters, kernel_size, dilation_rate):
hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')
hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')
h0 = Multiply()([hf, hg])
#tanh激活函数
ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
return Add()([ha, inputs]), hs
#tanh激活函数
h0 = activation(batchnorm(conv1d(X, filters, 1, 1)), 'tanh')
shortcut = []
for i in range(num_blocks):
for r in [1, 2, 4, 8, 16]:
h0, s = res_block(h0, filters, 7, r)
shortcut.append(s)
#Relu激活函数
h1 = activation(Add()(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
h1 = batchnorm(conv1d(h1, num_class, 1, 1))
h1 = GlobalMaxPooling1D()(h1) #通过GlobalMaxPooling1D对整个序列输出进行降维
Y = activation(h1, 'softmax') #softmax逻辑回归模型
(2) 优化损失函数
确定模型架构,进行编译。这是多类别的分类问题,故使用CTC(Connectionist temporalclassification) 算法计算损失函数。由于所有标签都带有相似的权重,故使用精确度作为性能指标。相关代码如下:
#Adam优化算法
optimizer = Adam(lr=0.01, clipnorm=5)
#模型输入/输出
model = Model(inputs=X, outputs=Y)
#模型损失和准确率
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
#模型保存路径
checkpointer = ModelCheckpoint(filepath='D:/homework/dialect/fangyan.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
模型训练及保存
在定义模型架构和编译之后,通过训练集训练模型,使模型进行方言分类。这里将使用训练集和验证集拟合并保存模型。
(1) 模型训练
相关代码如下:
#分批读取数据
history = model.fit_generator(
#训练集批处理器
generator=batch_generator(X_train, Y_train),
#每轮训练的数据量
steps_per_epoch=len(X_train),
epochs=epochs,
#测试集批处理器
validation_data=batch_generator(X_dev, Y_dev),
validation_steps=len(X_dev)
callbacks=[checkpointer, lr_decay])
其中,一批(batch)就是在一次前向/后向传播过程用到的训练样例数量,即一次用1180条语音数据进行训练,共训练11800条语音数据,如图所示。

通过观察训练集和测试集的损失函数、准确率的大小评估模型训练程度,制定模型训练的进一步决策。训练集和测试集的损失函数(或准确率)不变且基本相等为模型训练的最佳状态。训练过程中保存的准确率和损失函数以图片的形式显示,方便观察。
train_loss = history.history['loss']#训练集损失函数
valid_loss = history.history['val_loss']#验证集损失函数
#画图
plt.plot(train_loss, label='训练')
plt.plot(valid_loss, label='验证')
plt.legend(loc='upper right')
plt.xlabel('训练次数')
plt.ylabel('损失')
plt.show()
train_acc = history.history['acc']#训练集精确度
valid_acc = history.history['val_acc']#验证集精确度
#画图
mpl.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(train_acc, label='训练')
plt.plot(valid_acc, label='验证')
plt.legend(loc='upper right')
plt.xlabel('训练次数')
plt.ylabel('精确度')
plt.legend()
plt.show()
(2) 模型保存
相关代码如下:
#保存模型
model.save('fangyan.h5') #HDF5文件
模型被保存后,可以被重用,也可以移植到其他环境中使用。为类别预测,将字典保存为.pkl文件,相关代码如下:
#保存字典
with open('resources.pkl', 'wb') as fw:
pickle.dump([class2id, id2class, mfcc_mean, mfcc_std], fw)
2. 语音识别
本部分包含数据预处理、模型构建、模型训练及模型保存。
数据预处理
数据集来源地址为www.openslr.org/18/,包含100~400KB的语音数据集13388条。下载数据集并导入,通过使用glob ()函数来实现。相关代码如下:
#加载trn,读取语音对应的文本文件
text_paths = glob.glob(r'D:/homework/language/language/data/*.trn')
#导入数据集
total = len(text_paths) #统计文本个数
print(total) #打印数据集总数
with open(text_paths[0], 'r', encoding='utf8') as fr:
lines = fr.readlines()
print(lines) #打印第一条数据中内容
语音识别数据集中有表示语音的.wav文件,也有表示标音的.trn文件。打印第一条数据, 输出如图所示。

对下载的语音数据集进行整理,将文本中的中文保存到texts的列表中、每个音频的路径保存到paths列表中,相关代码如下:
#提取文本内容和语音文件路径,去掉空白格
texts = [] #放置文本
paths = [] #防止每个语音文件的路径
for path in text_paths:
with open(path, 'r', encoding='utf8') as fr:
lines = fr.readlines()
line = lines[0].strip('\n').replace(' ', '')
#用逗号替换空白格,去掉拼音
texts.append(line) #更新文本,添加整理好的内容
paths.append(path.rstrip('.trn'))#除去.trn的文件就是.wav音频文件
print(paths[0], texts[0])#打印语音文件所在路径以及对应的文本内容
下载语音数据集并进行预处理。定义处理语音数据和可视化语音数据集的两个函数。在处理语音数据的函数中,去除语音文件两端的静音部分。处理语音数据部分函数代码如下:
def load_and_trim(path):
audio, sr = librosa.load(path) #读取音频
energy = librosa.feature.rms(audio) #计算能量
frames = np.nonzero(energy >= np.max(energy) / 5) #最大能量的1/5视为静音
indices = librosa.core.frames_to_samples(frames)[1] #去除静音
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
return audio, sr
#可视化语音数据集部分函数代码
def visualize(index):
path = paths[index] #获取某个音频
text = texts[index] #获取音频对应的文本
print('Audio Text:', text)
audio, sr = load_and_trim(path) #调用函数去除两端静音
plt.figure(figsize=(12, 3))
plt.plot(np.arange(len(audio)), audio)
plt.title('Raw Audio Signal')
plt.xlabel('Time')#x轴为时间
plt.ylabel('Audio Amplitude') #y轴为音频高度
plt.show()
feature = mfcc(audio, sr, numcep=mfcc_dim, nfft=551) #计算MFCC特征
print('Shape of MFCC:', feature.shape)
fig = plt.figure(figsize=(12, 5))
ax = fig.add_subplot(111)
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto')
plt.title('Normalized MFCC')
plt.ylabel('Time')
plt.xlabel('MFCC Coefficient')
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False);
plt.show()
return path
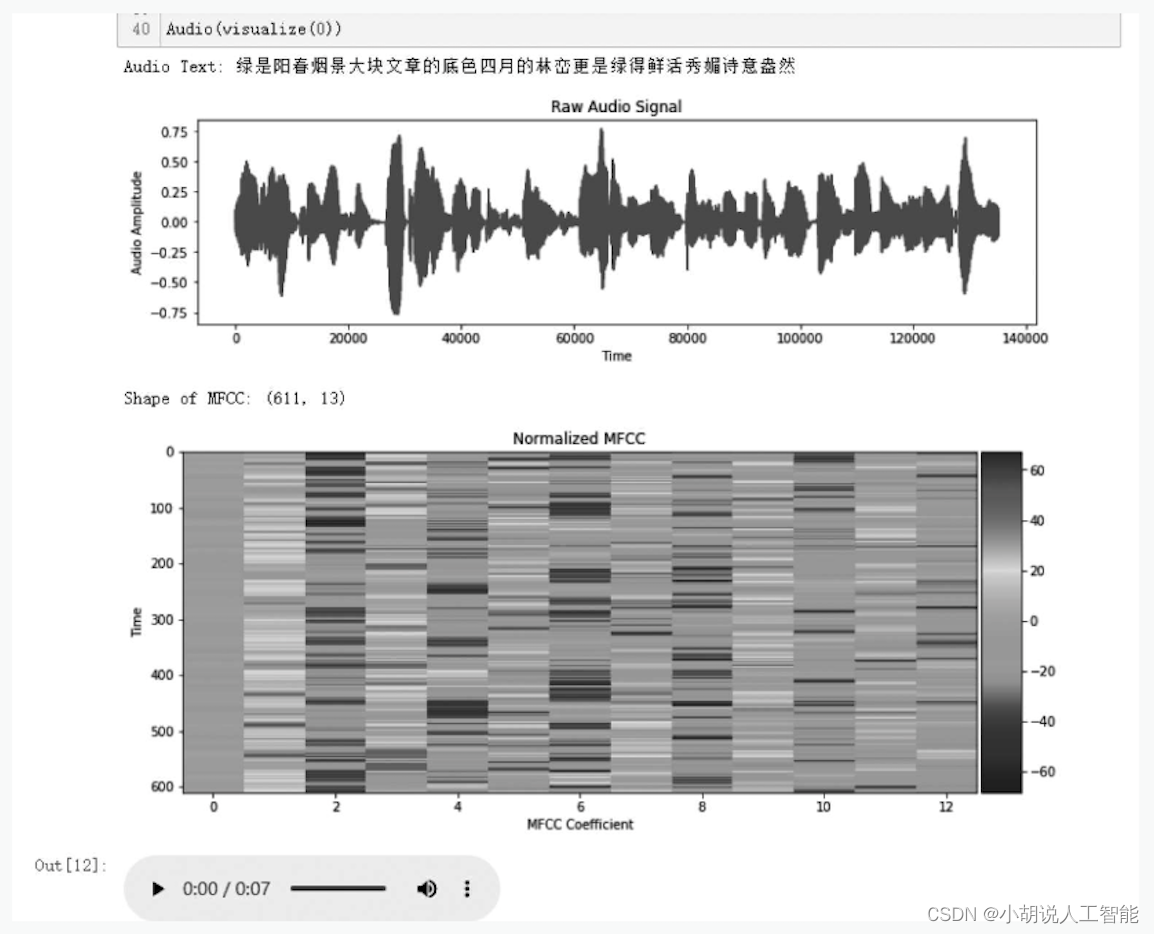
以可视化第一条语音数据为例,结果如图所示。
将音频文件的MFCC特征进行归一化处理并建立字典,相关代码如下:
features=[(feature-mfcc_mean)/(mfcc_std + 1e-14) for feature in features]
#建立字典
chars = {}
for text in texts:
for c in text:
chars[c] = chars.get(c, 0) + 1
chars = sorted(chars.items(), key=lambda x: x[1], reverse=True)
chars = [char[0] for char in chars]
print(len(chars), chars[:100]) #打印随机100段音频中汉字数量
char2id = {c: i for i, c in enumerate(chars)}
id2char = {i: c for i, c in enumerate(chars)}
对数据进行划分,将数据总数的90%作为训练集。定义产生批数据的函数batch_generator()。相关代码如下:
data_index = np.arange(total)
np.random.shuffle(data_index) #将索引打乱
train_size = int(0.9 * total) #训练数据占90%
test_size = total - train_size
train_index = data_index[:train_size] #切分出来训练数据的索引
test_index = data_index[train_size:] #切分出来测试数据的索引
X_train = [features[i] for i in train_index] #取出训练音频的MFCC特征
Y_train = [texts[i] for i in train_index] #取出训练的标签
X_test = [features[i] for i in test_index] #取出测试音频的MFCC特征
Y_test = [texts[i] for i in test_index] #取出测试的标签
模型构建
数据加载进模型后,需要定义模型结构,并优化损失函数。
(1) 定义模型结构
定义WaveNet网络。使用多层因果空洞卷积处理数据,模型结构使用方法和方言分类部分大致相同。
(2) 损失函数及模型优化
确定模型架构后进行编译。这是多类别的分类问题,故使用CTC ( Connectionist temporalclassification) 算法计算损失函数。相关代码如下:
def calc_ctc_loss(args): #CTC损失函数
y, yp, ypl, yl = args
return K.ctc_batch_cost(y, yp, ypl, yl)
ctc_loss = Lambda(calc_ctc_loss, output_shape=(1,), name='ctc')([Y, Y_pred, X_length, Y_length]) #调用函数
model = Model(inputs=[X, Y, X_length, Y_length], outputs=ctc_loss)
optimizer = SGD(lr=0.02, momentum=0.9, nesterov=True, clipnorm=5)
model.compile(loss={'ctc': lambda ctc_true, ctc_pred: ctc_pred}, optimizer=optimizer) #定义模型
checkpointer = ModelCheckpoint(filepath='asr.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
模型训练及保存
在定义模型架构和编译之后,通过训练集训练模型,使模型识别语音。这里,将使用训练集和验证集来拟合并保存模型。
1) 模型训练
相关代码如下:
#分批读取数据
history = model.fit_generator(
#训练集批处理器
generator=batch_generator(X_train, Y_train),
#每轮训练的数据量
steps_per_epoch=len(X_train),
epochs=epochs,
#测试集批处理器
validation_data=batch_generator(X_dev, Y_dev),
validation_steps=len(X_dev)
callbacks=[checkpointer, lr_decay])
一批(batch) 数据不超过753条,如图所示。

相关代码如下:
#训练集损失
train_loss = history.history['loss']
#验证集损失
valid_loss = history.history['val_loss']
#绘制损失函数图像
mpl.rcParams['font.sans-serif'] = ['SimHei'] #默认字体黑体
plt.plot(np.linspace(1, epochs, epochs), train_loss, label='训练')
plt.plot(np.linspace(1, epochs, epochs), valid_loss, label='验证')
plt.legend(loc='upper right')
plt.xlabel('训练次数')
plt.ylabel('损失')
plt.legend()
plt.show()
2) 模型保存
为后续图形用户界面设计导入,将模型保存为.h5格式的文件。
相关代码如下:
#模型保存
sub_model.save('asr.h5')
将字典保存为pkl格式文件,相关代码如下:
#字典保存
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char], fw)
模型及字典被保存后,可以被重用,也可以移植到其他环境中使用。
3. 模型测试
在设计好的图形用户界面中导入模型,选取语音文件,展示原始波形及MFCC特征图。可选择实现语音识别和方言分类两个功能。图形用户主要包括3个界面:功能选择界面、语言识别功能实现界面和方言识别功能实现界面。
功能选择界面
相关操作如下
(1)设置功能选择界面为根窗体。初始化功能选择界面的各个属性,相关操作如下:
#设置功能选择界面的大小及标题
root = Tk()
root.geometry('300x450')
root.title('语音识别及方言分类')
#界面展示
mainloop()
根窗体是图像化应用程序的根控制器,是Tkinter底层控件的实例。导入Tkinter模块后,调用Tk()函数初始化根窗体实例,用title()函数设置标题文字,用geometry()函数设置窗体大小(以像素为单位)。将根窗体置于主循环中,除非用户关闭,否则程序始终处于运行状态。主循环的根窗体中,可持续呈现其他可视化控件实例,监测事件的发生并执行相应的处理程序。
(2)设置界面需展示的控件及其相应属性和布局,相关操作如下:
#设置文本标签,提示用户欢迎信息
lb = Label(root, text='欢迎使用!',font=('华文新魏',22))
lb.pack()
#设置文本标签位置
lb.place(relx=0.15, rely=0.2, relwidth=0.75, relheight=0.3)
#设置两个提示按钮及文本字体大小
btn = Button(root, text='语音识别',font=('华文新魏',12),command=asr)
btn.pack()
#设置第一个按钮位置
btn.place(relx=0.3, rely=0.5, relwidth=0.4, relheight=0.1)
btn_btn = Button(root, text='方言分类',font=('华文新魏',12),command = dialect)
btn_btn.pack()
#设置第二个按钮位置
btn_btn.place(relx=0.3, rely=0.65, relwidth=0.4, relheight=0.1)
标签实例lb,按钮实例btn和btn_ btn在父容器root中实例化,设置text (文本)、font (字体)和命令属性;在实例化控件时,实例的属性以“属性=属性值”的形式枚举列出,不区分先后次序。属性值通常用文本形式表示。
按钮主要是为响应鼠标单击事件触发运行程序所设的,除控件共有属性外,命令(command) 是最重要的属性。通常将要触发执行的程序以函数形式预先定义,直接调用函数,参数表达式为“command=函数名”,函数名后面不加括号,不传递参数。故设置命令属性以触发与按钮文本相对应的功能实现界面。
使用place () 方法配合relx、rely和relheight, relwidth参数所得到的界面可自适应根窗体尺寸的大小。
语言识别功能实现界面
相关操作如下:
(1)调用Toplevel () 函数,设置二级界面,用于语音识别功能的实现。
(2)实例化所需文本标签、图像标签、文本及按钮控件。
(3)定义函数用于获取用户输入数字,选取后续进行识别语音文件。
(4) 定义函数读取语音文件,进行一系列处理后,绘制原始波形及MFCC特征两个图像,并保存到本地。
#语音文件初始处理,去除两端静音
audio, sr = librosa.load(wavs[int(x)]) #读取语音文件
energy = librosa.feature.rms(audio) #计算语音文件能量
#判定能量小于最大能量1/5为静音
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0] #去除两端静音
plt.figure(figsize=(12, 3)) #图像大小
plt.plot(np.arange(len(audio)), audio) #绘制原始波形
plt.title('Raw Audio Signal') #图像标题
plt.xlabel('Time') #图像横坐标
plt.ylabel('Audio Amplitude') #图像纵坐标
#保存原始波形图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/语音识别/原始波形.png')
#feature.shape二维数组(切片数量,维度)
#指定音频文件、采样率、mfcc维度,获取MFCC特征
feature = mfcc(audio, sr, numcep=mfcc_dim, nfft=551)
#绘制MFCC特征图
fig = plt.figure(figsize=(12, 5))#图像大小
ax = fig.add_subplot(111) #分块绘图
#绘制mfcc特征
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto')
plt.title('Normalized MFCC') #图像标题
plt.ylabel('Time') #图像纵坐标
plt.xlabel('MFCC Coefficient') #图像横坐标
#右侧colorbar绘制
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False); #图像横坐标值设置
#保存MFCC特征图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/语音识别/mfcc.png')
(5) 定义两个函数,分别用于在界面中展示MFCC特征图和原始波形图。
(6)定义函数,取出语音文件标注的文本,并在界面中展示。
(7)定义函数,加载训练好的模型进行语音识别,将识别结果进行输出展示。
audio, sr = librosa.load(wavs[int(x)]) #读取语音文件
energy = librosa.feature.rms(audio) #计算语音文件能量
#判定能量小于最大能量1/5为静音
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0] #去除两端静音
X_data = mfcc(audio, sr, numcep=mfcc_dim, nfft=551) #获取mfcc特征
X_data = (X_data - mfcc_mean) / (mfcc_std + 1e-14) #mfcc归一化处理
#加载模型进行语音识别
pred = model.predict(np.expand_dims(X_data, axis=0))
#加载预测结果
pred_ids = K.eval(K.ctc_decode(pred, [X_data.shape[0]], greedy=False,beam_width=10, top_paths=1)[0][0])
pred_ids = pred_ids.flatten().tolist()
#实例化lb标签,在界面中展示识别文本结果
lb3 = Label(top, text='识别结果:'+''.join([id2char[i] for i in pred_ids]))
lb3.place(relx=0.1, rely=0.96, relwidth=0.75, relheight=0.03)
(8)设置按钮控件的command属性,与上述定义好的函数相联系,确保正确触发与按钮相对应的可实现功能。
方言分类功能实现界面
相关操作如下:
(1) 调用Toplevel () 函数,设置二级界面,用于方言分类功能的实现。
(2) 实例化所需文本标签、图像标签、文本及按钮控件。
(3) 定义函数,随机选取后续进行方言分类的语音文件。
(4) 定义函数,读取语音文件,进行一系列处理后,绘制原始波形及MFCC特征两个图像,并保存到本地。
#定义函数,加载语音文件,去除两端静音,对长语音进行片段切片
def load_and_trim(path, sr=16000):
audio = np.memmap(path, dtype='h', mode='r') #对大文件分段读取
audio = audio[2000:-2000]
audio = audio.astype(np.float32)
energy = librosa.feature.rms(audio) #计算能量
#最大能量的1/5视为静音
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1] #去除静音
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0] #去除静音后的语音文件
slices = [] #存储划分为小于3s大于1s的切片
for i in range(0, audio.shape[0], slice_length):
s = audio[i: i + slice_length] #切分为3s片段
if s.shape[0] >= min_length:
slices.append(s) #去除小于1s的片段
return audio, slices
#定义函数以读取语音文件,绘制原始波形及MFCC特征两个图像,并保存到本地
def run2():
#从文本框中提取随机选取的语音文件路径
path = txt1.get("0.0","end")
path = path.strip("\n").split(" ")[0]
audio, slices = load_and_trim(path) #去除两端静音,并切分为片段
#绘制原始波形图像
plt.figure(figsize=(12, 3))#图像大小
plt.plot(np.arange(len(audio)), audio) #绘制波形
plt.title('Raw Audio Signal')#设置标题
plt.xlabel('Time') #设置横坐标
plt.ylabel('Audio Amplitude')#设置纵坐标
#保存原始波形图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/原始波形.png')
#绘制MFCC特征图像
feature = mfcc(audio, sr, numcep=mfcc_dim) #提取MFCC特征
fig = plt.figure(figsize=(12, 5))#图像大小
ax = fig.add_subplot(111)
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto') #绘制MFCC
plt.title('Normalized MFCC')#图像标题
plt.ylabel('Time')#设置纵坐标
plt.xlabel('MFCC Coefficient')#设置横坐标
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False);#设置横坐标间隔
#保存mfcc特征图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/mfcc.png')
(5) 定义两个函数,分别用于在界面中展示MFCC特征图和原始波形图。
(6) 定义函数,取出语音文件所属类别并在界面中展示。
(7) 定义函数,加载训练好的模型进行方言分类,将识别结果进行输出展示。
path = txt1.get("0.0","end")
path = path.strip("\n").split(" ")[0]
#去除两端静音,并切分为片段
audio, slices = load_and_trim(path)
#获取mfcc特征
X_data = [mfcc(s, sr, numcep=mfcc_dim) for s in slices]
#MFCC归一化处理
X_data = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_data]
maxlen = np.max([x.shape[0] for x in X_data])
X_data = pad_sequences(X_data, maxlen, 'float32', padding='post', value=0.0)
#加载模型进行方言分类
prob = model.predict(X_data)
prob = np.mean(prob, axis=0)
pred = np.argmax(prob)
prob = prob[pred]
pred = id2class[pred]
#实例化lb标签,在界面中展示识别预测类别
lb3 = Label(top1, text='预测类别:'+ pred + ' Confidence:'+ str(prob))
lb3.place(relx=0.1, rely=0.96, relwidth=0.75, relheight=0.03)
(8) 设置按钮控件的command属性,与上述定义好的函数相联系,确保正确触发与按钮相对应的可实现功能。
系统测试
本部分包括训练准确率、测试效果及模型应用。
1. 训练准确率
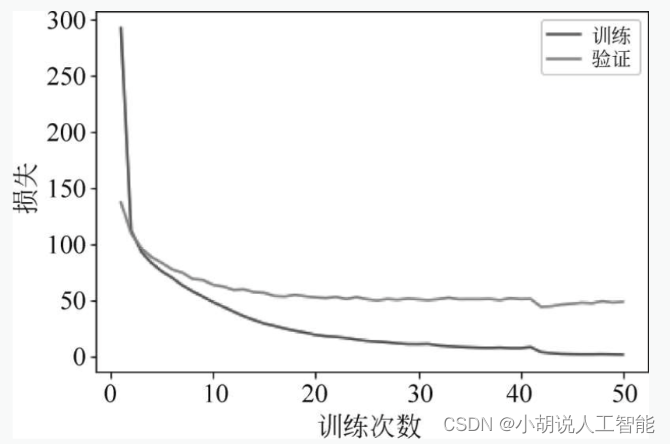
语音识别任务,预测模型训练比较成功。随着训练次数的增多,模型在训练数据、测试数据上的损失逐渐收敛,最终趋于稳定,如图所示。
方言分类中,在训练集上测试准确率超过了98%,意味着这个预测模型训练比较成功。随着训练次数的增多,模型在训练数据上的损失和准确率逐渐收敛,最终趋于稳定;但在测试数据上的损失和准确率不够稳定,有一定波动,如图4和图5所示。
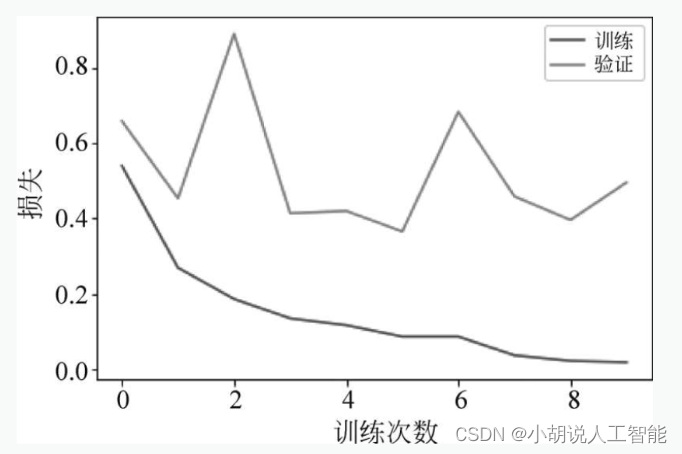
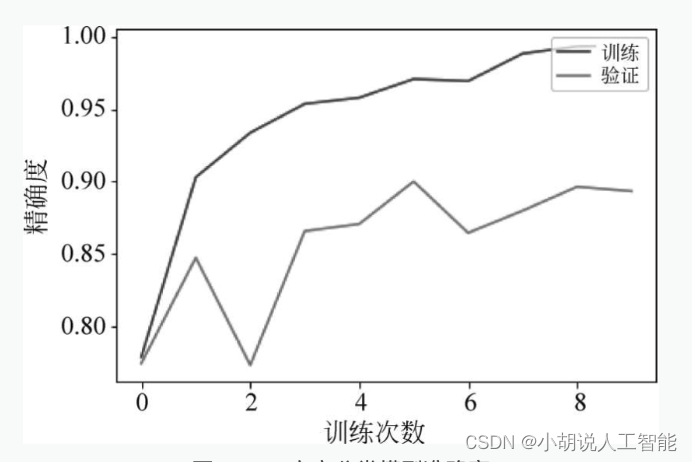
2. 测试效果
对测试集进行测试,识别的文本、分类标签与原始数据进行显示和对比,如下图所示。

由结果可以看出,模型可以实现语音识别及方言分类。
3. 模型应用
本部分包括图形用户界面使用说明和测试效果。
1. 图形用户界面使用说明
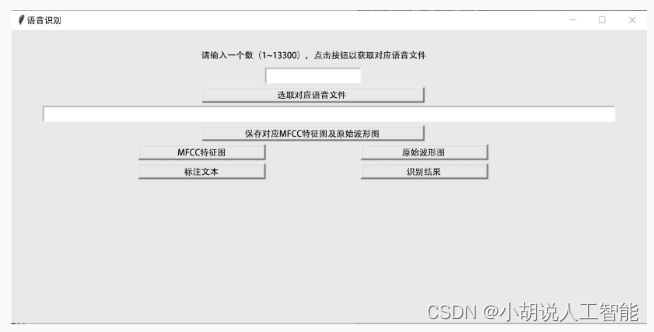
编译及运行.py文件后,初始界面如图所示。

界面从上至下分别是文本提示语和两个按钮。单击[语音识别]按钮,可以弹出二级界面——语音识别功能实现界面,如图6所示;单击[方言分类]按钮,可以弹出二级界面——方言分类功能实现界面,如图7所示。
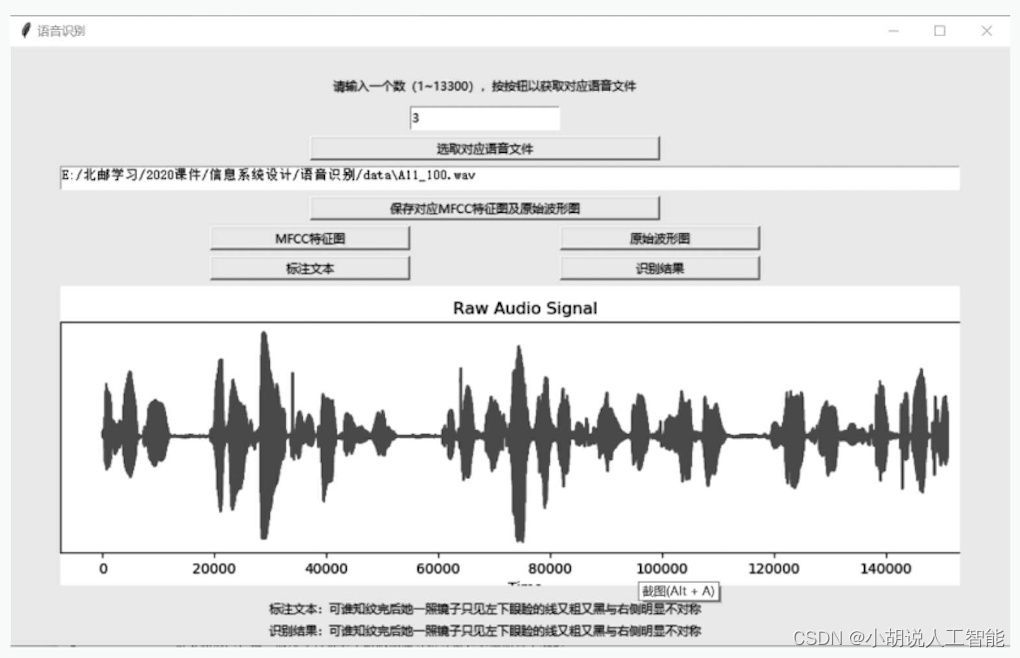
界面从上至下分别是文本提示语、输入框、按钮和文本框。在输入框中输入数字,单击[选取对应语音文件]按钮,选择本次进行语音识别的文件,文本框中输出该文件路径;单击[保存对应MFCC特征图及原始波形图]按钮,保存对应图像到本地;单击[MFCC特征图]按钮和[原始波形图]按钮以显示保存到本地的图像;单击[标注文本]按钮,显示对应标注文件的文本;单击[识别结果]按钮,进行预测,显示预测的文本结果。
界面从上至下分别是文本提示语、按钮和文本框。根据文本提示,单击[选取语音文件]按钮,随机选择本次进行语音识别的文件,文本框中输出该文件路径;单击[保存对应MFCC特征图及原始波形图]按钮,保存对应图像到本地后;单击| [MFCC特征图]和[原始波形图]按钮以显示保存到本地的图像;单击[标注类别]按钮,显示文件对应的所属类别;单击[识别类别]按钮,进行预测,显示预测的类别结果。

2.测试效果
图形用户界面的语音识别测试结果如图所示。
图形用户界面的方言分类测试结果如图所示。

工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。