探究Redis服务启动的过程机制的技术原理和流程分析的指南
- Redis基本概念
- Redis特点说明
- Redis源码结构
- Redis功能架构
- Redis启动流程
- 初始化全局服务器配置
- 源码分析
- 分析说明
- initServerConfig方法
- 初始化的内容
- 保存机制的初始化策略
- 优化的初始化策略
- 指定配置文件
- 加载配置文件
- 默认的数据保存策略
- 每15分钟进行1次更新
- 每5分钟进行100次更新
- 每1分钟进行10000次更新
- 初始化服务器
- 加载数据库
- 读取文件的操作
- AOF文件加载
- loadAppendOnlyFile
- appendonly.aof
- 执行AOF命令
- RDB文件加载
- 从数据库文件中加载数据的基本步骤
- 网络监听
- Redis总结
Redis基本概念
Redis(REmote DIctionary Server)是由Salvatore Sanfilippo开发的高性能key-value存储系统,完全遵守BSD协议并且开源免费。
Redis特点说明
Redis具有以下几个特点,使其与其他key-value缓存产品(如memcache)相区别。
-
数据持久化: Redis支持将内存中的数据保存到磁盘中,以便在重新启动后再次加载使用。这使得Redis既能提供高速的读写性能,又能保证数据不会因为服务重启而丢失。
-
多样的数据结构: Redis不仅支持简单的key-value类型的数据,还提供了丰富的数据结构,包括list(列表)、set(集合)、zset(有序集合)和hash(哈希),扩展了Redis的应用场景。
-
数据备份: Redis支持主从模式的数据备份。在这种架构下,主节点负责写操作,而从节点负责数据的备份,确保数据的安全性和高可用性。
-
高性能: Redis以其出色的性能而闻名,能够处理高并发的读写请求。其内存存储和基于事件驱动的异步IO机制,使其能够在独立进程或线程中高效地执行操作,迅速响应请求。
-
原子性操作: Redis中的所有操作都是原子性的,保证了多个操作的执行不会被半途中断或干扰。此外,Redis还支持原子性地将一组操作合并为一个操作批量执行,提高了效率和性能。
-
丰富的扩展特性: Redis还提供了诸如发布/订阅、通知、键的过期等特性,使得Redis在构建实时应用、消息系统和计数器等场景中更加灵活和强大。
-
简洁的代码风格: Redis的代码风格极其精简,整个源码只有23000行,易于理解和阅读。这使得开发者可以通过阅读Redis源码来深入理解其实现原理,从而更好地使用和定制Redis。
Redis源码结构
Redis是一个开源的、高性能的键值存储系统。它的源代码目录结构如下:
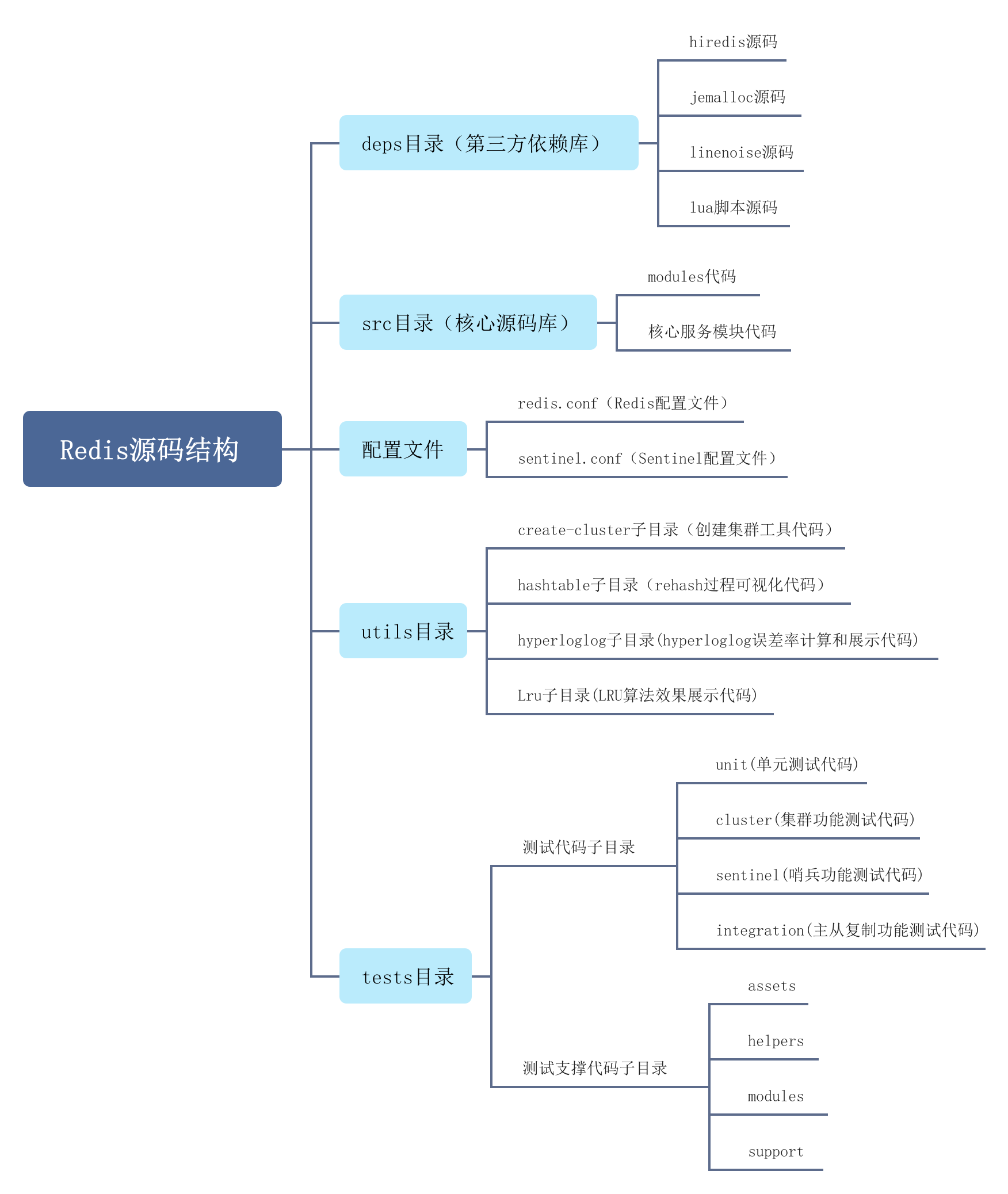
src:该目录包含了Redis的核心源代码。adlist.c、adlist.h:双向链表的实现。ae.c、ae.h:事件驱动库的实现,处理事件的多路复用。anet.c、anet.h:网络库的实现,封装了底层网络操作。config.h:配置文件,定义了Redis的各种编译选项和宏定义。crc16.c、crc64.c:CRC校验的实现。db.c、db.h:数据库的实现,包括键值对的存储和操作等。debug.c、debug.h:调试相关的实现。dict.c、dict.h:字典的实现,用于存储键值对。fmacros.h:一些常用的宏定义。help.h:帮助信息的定义。intset.c、intset.h:整数集合的实现。lzf_c.c、lzf_d.c:压缩算法LZF的实现。multi.c、multi.h:事务的实现。networking.c:网络模块的实现,包括请求的解析和响应的生成。object.c、object.h:对象的实现,包括字符串、列表、哈希等各种类型。pubsub.c、pubsub.h:发布订阅的实现。redis.c:Redis服务器的入口点,包含主循环和命令处理逻辑。redis-check-aof.c、redis-check-dump.c:用于检查和修复AOF日志和RDB文件的工具。redis-cli.c:Redis命令行客户端的实现。redis-benchmark.c:性能测试工具的实现。sha1.c、sha1.h:SHA1算法的实现。sds.c、sds.h:简单动态字符串的实现。server.c、server.h:服务器相关的实现,包括配置文件的解析、客户端的管理等。syncio.c、syncio.h:同步IO库的实现。t_hash.c、t_list.c、t_set.c、t_string.c、t_zset.c:各种数据类型的实现。util.c、util.h:工具函数的实现。
此外,还有一些其他的目录:
deps:该目录包含了Redis所依赖的第三方库,如Jemalloc、Lua等。tests:该目录包含了Redis的测试代码。utils:该目录包含了一些实用工具,如启动脚本、配置文件样例等。
以上是Redis源码的大致目录结构。不同版本的Redis可能会有一些差异,但总体结构类似。
Redis功能架构
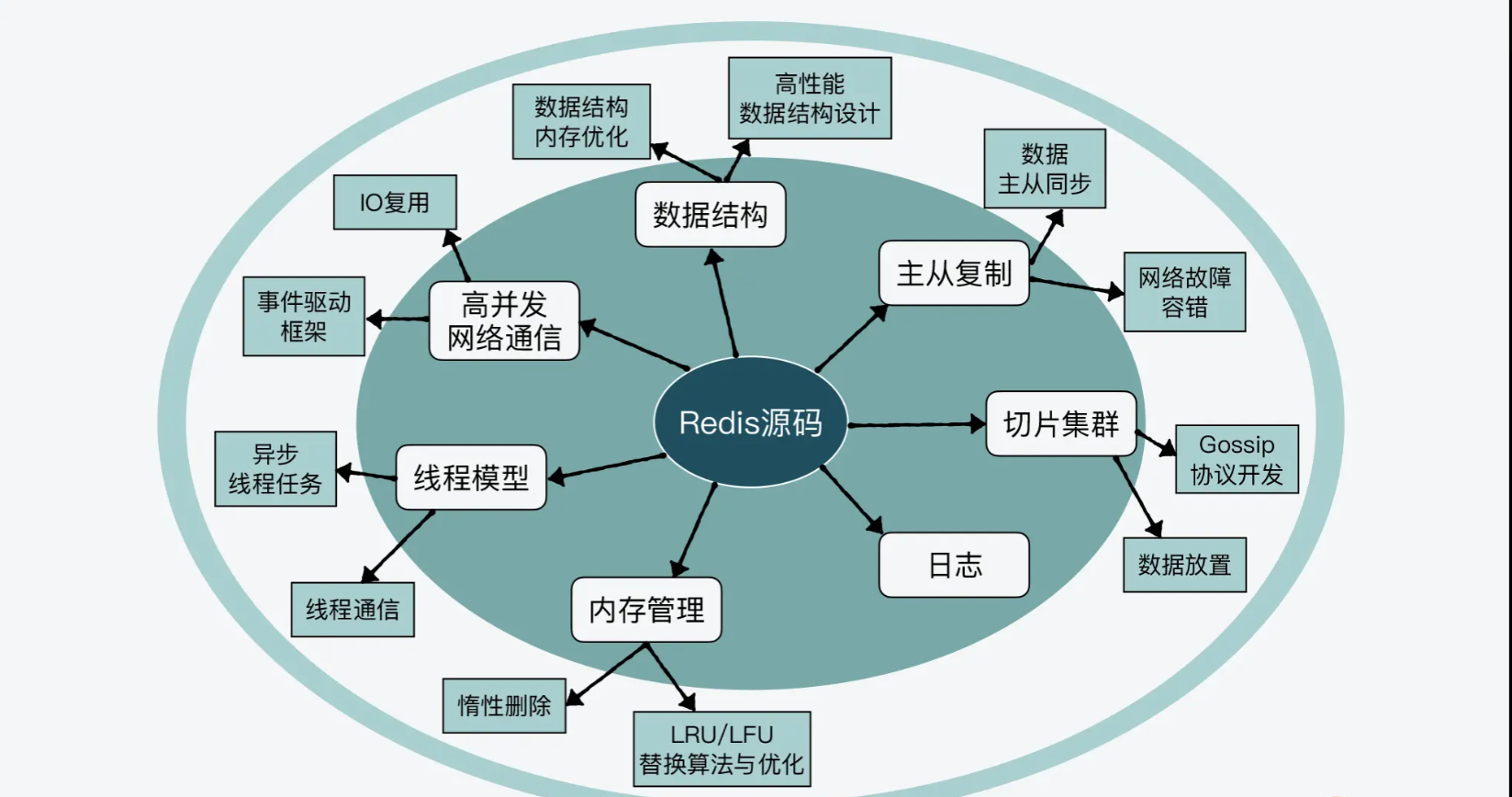
Redis启动流程
本文深入介绍了Redis的启动加载过程,可以总结为以下几个键步骤:

-
全局服务器配置的初始化
在服务器启动时,首先进行全局服务器配置的初始化。这包括初始化服务器的监听端口、最大连接数、日志级别等参数,以及其他与服务器运行相关的配置项。 -
配置文件的加载
接下来,系统会加载配置文件。如果用户指定了配置文件路径,则使用指定的配置文件进行加载;否则,系统将使用默认的配置文件。配置文件中包含了一些常用的配置项,如数据库地址、密码、缓存大小等。 -
服务器的初始化
服务器的初始化是指服务器程序的启动和必要的资源分配。在这一步中,服务器会创建并初始化网络监听器、数据库连接池、线程池等关键组件,为后续的业务逻辑提供支持。 -
数据库的加载
在服务器初始化完成后,会加载数据库配置和连接信息。服务器会连接到指定的数据库,对相关的数据表进行初始化,确保数据库的完整性和可用性。 -
网络监听
服务器会开启网络监听,开始接收来自客户端的请求。通过网络监听器,服务器可以接受和处理各种类型的请求,如查询、更新、删除等。同时,服务器会通过网络监听器将响应结果返回给客户端。
通过上述步骤,服务器完成了全局配置的初始化、配置文件的加载、服务器的初始化、数据库的加载和网络的监听。这些步骤确保了服务器能够正常运行,并能够接收和处理客户端的请求。
初始化全局服务器配置
源码分析
umask(server.umask = umask(0777));
uint8_t hashseed[16];
getRandomBytes(hashseed,sizeof(hashseed));
dictSetHashFunctionSeed(hashseed);
char *exec_name = strrchr(argv[0], '/');
if (exec_name == NULL) exec_name = argv[0];
server.sentinel_mode = checkForSentinelMode(argc,argv, exec_name);
initServerConfig();
ACLInit(); /* The ACL subsystem must be initialized ASAP because the
basic networking code and client creation depends on it. */
moduleInitModulesSystem();
connTypeInitialize();
/* Store the executable path and arguments in a safe place in order
* to be able to restart the server later. */
server.executable = getAbsolutePath(argv[0]);
server.exec_argv = zmalloc(sizeof(char*)*(argc+1));
server.exec_argv[argc] = NULL;
for (j = 0; j < argc; j++) server.exec_argv[j] = zstrdup(argv[j]);
/* We need to init sentinel right now as parsing the configuration file
* in sentinel mode will have the effect of populating the sentinel
* data structures with master nodes to monitor. */
if (server.sentinel_mode) {
initSentinelConfig();
initSentinel();
}
分析说明
通过将全局服务器配置的初始化过程封装到 initServerConfig() 函数中,可以提高代码的可维护性和可扩展性。在需要修改或扩展服务器配置时,只需要修改或扩展这个函数即可,而不需要修改其他相关的代码。
具体代码如下所示:
struct redisServer server;
initServerConfig(&server);
全局服务器配置通过 initServerConfig() 函数完成。这个函数的主要作用是对 server 变量进行初始化,server 是一个 redisServer 结构的变量。
initServerConfig方法
该函数的作用是确保服务器在启动时具有正确的初始配置,并为后续的加载和操作做准备。在 initServerConfig() 函数中,会对 server 变量的各个属性进行赋值。这些属性包括服务器的监听地址、监听端口、最大连接数、超时时间等。通过给这些属性赋予合适的初值,能够确保服务器在启动时具备正确的配置和参数设置。
void initServerConfig(void) {
int j;
char *default_bindaddr[CONFIG_DEFAULT_BINDADDR_COUNT] = CONFIG_DEFAULT_BINDADDR;
initConfigValues();
updateCachedTime(1);
server.cmd_time_snapshot = server.mstime;
getRandomHexChars(server.runid,CONFIG_RUN_ID_SIZE);
server.runid[CONFIG_RUN_ID_SIZE] = '\0';
changeReplicationId();
clearReplicationId2();
server.hz = CONFIG_DEFAULT_HZ; /* Initialize it ASAP, even if it may get
updated later after loading the config.
This value may be used before the server
is initialized. */
server.timezone = getTimeZone(); /* Initialized by tzset(). */
server.configfile = NULL;
server.executable = NULL;
server.arch_bits = (sizeof(long) == 8) ? 64 : 32;
server.bindaddr_count = CONFIG_DEFAULT_BINDADDR_COUNT;
for (j = 0; j < CONFIG_DEFAULT_BINDADDR_COUNT; j++)
server.bindaddr[j] = zstrdup(default_bindaddr[j]);
memset(server.listeners, 0x00, sizeof(server.listeners));
server.active_expire_enabled = 1;
server.lazy_expire_disabled = 0;
server.skip_checksum_validation = 0;
server.loading = 0;
server.async_loading = 0;
server.loading_rdb_used_mem = 0;
server.aof_state = AOF_OFF;
server.aof_rewrite_base_size = 0;
server.aof_rewrite_scheduled = 0;
server.aof_flush_sleep = 0;
server.aof_last_fsync = time(NULL);
server.aof_cur_timestamp = 0;
atomicSet(server.aof_bio_fsync_status,C_OK);
server.aof_rewrite_time_last = -1;
server.aof_rewrite_time_start = -1;
server.aof_lastbgrewrite_status = C_OK;
server.aof_delayed_fsync = 0;
server.aof_fd = -1;
server.aof_selected_db = -1; /* Make sure the first time will not match */
server.aof_flush_postponed_start = 0;
server.aof_last_incr_size = 0;
server.aof_last_incr_fsync_offset = 0;
server.active_defrag_running = 0;
server.notify_keyspace_events = 0;
server.blocked_clients = 0;
memset(server.blocked_clients_by_type,0,
sizeof(server.blocked_clients_by_type));
server.shutdown_asap = 0;
server.shutdown_flags = 0;
server.shutdown_mstime = 0;
server.cluster_module_flags = CLUSTER_MODULE_FLAG_NONE;
server.migrate_cached_sockets = dictCreate(&migrateCacheDictType);
server.next_client_id = 1; /* Client IDs, start from 1 .*/
server.page_size = sysconf(_SC_PAGESIZE);
server.pause_cron = 0;
server.latency_tracking_info_percentiles_len = 3;
server.latency_tracking_info_percentiles = zmalloc(sizeof(double)*(server.latency_tracking_info_percentiles_len));
server.latency_tracking_info_percentiles[0] = 50.0; /* p50 */
server.latency_tracking_info_percentiles[1] = 99.0; /* p99 */
server.latency_tracking_info_percentiles[2] = 99.9; /* p999 */
server.lruclock = getLRUClock();
resetServerSaveParams();
appendServerSaveParams(60*60,1); /* save after 1 hour and 1 change */
appendServerSaveParams(300,100); /* save after 5 minutes and 100 changes */
appendServerSaveParams(60,10000); /* save after 1 minute and 10000 changes */
/* Replication related */
server.masterhost = NULL;
server.masterport = 6379;
server.master = NULL;
server.cached_master = NULL;
server.master_initial_offset = -1;
server.repl_state = REPL_STATE_NONE;
server.repl_transfer_tmpfile = NULL;
server.repl_transfer_fd = -1;
server.repl_transfer_s = NULL;
server.repl_syncio_timeout = CONFIG_REPL_SYNCIO_TIMEOUT;
server.repl_down_since = 0; /* Never connected, repl is down since EVER. */
server.master_repl_offset = 0;
server.fsynced_reploff_pending = 0;
/* Replication partial resync backlog */
server.repl_backlog = NULL;
server.repl_no_slaves_since = time(NULL);
/* Failover related */
server.failover_end_time = 0;
server.force_failover = 0;
server.target_replica_host = NULL;
server.target_replica_port = 0;
server.failover_state = NO_FAILOVER;
/* Client output buffer limits */
for (j = 0; j < CLIENT_TYPE_OBUF_COUNT; j++)
server.client_obuf_limits[j] = clientBufferLimitsDefaults[j];
/* Linux OOM Score config */
for (j = 0; j < CONFIG_OOM_COUNT; j++)
server.oom_score_adj_values[j] = configOOMScoreAdjValuesDefaults[j];
/* Double constants initialization */
R_Zero = 0.0;
R_PosInf = 1.0/R_Zero;
R_NegInf = -1.0/R_Zero;
R_Nan = R_Zero/R_Zero;
/* Command table -- we initialize it here as it is part of the
* initial configuration, since command names may be changed via
* redis.conf using the rename-command directive. */
server.commands = dictCreate(&commandTableDictType);
server.orig_commands = dictCreate(&commandTableDictType);
populateCommandTable();
/* Debugging */
server.watchdog_period = 0;
}
initServerConfig() 函数还可能包括一些检查和验证步骤,以确保配置的正确性和合法性。例如,可以检查指定的监听端口是否已被占用,或者验证用户提供的参数是否符合要求。
初始化的内容
初始化的内容涵盖以下几个方面:
- 网络监听相关:配置绑定地址和TCP端口等网络监听参数。
- 虚拟内存相关:设置swap文件和page大小等虚拟内存参数。
- 保存机制:定义保存数据的策略,例如在多长时间内有多少次更新才进行保存。
- 复制相关:配置复制功能,包括是否作为slave、master的地址和端口等。
- Hash相关设置:对Hash结构相关的参数进行初始化。
- 初始化命令表:完成命令表的初始化,包括注册支持的命令、命令的参数和执行函数等。
通过对以上方面进行初始化,可以确保服务器在启动时具备合适的配置和参数设置。这样做有助于提高服务器的性能和稳定性,并且可以提供更好的用户体验。
为了进一步优化代码,建议将以上初始化的内容模块化,以提高代码的可读性和可维护性。可以将不同方面的初始化逻辑分别放到不同的函数中,然后在 initServerConfig() 函数中依次调用这些初始化函数,以实现整体的初始化过程。
总结而言,通过对不同方面的内容进行初始化,可以提高服务器性能和稳定性,同时对代码进行优化和模块化,有助于提高代码的可读性和可维护性。
保存机制的初始化策略
在服务器的保存机制中,需要确定初始化策略,即在多长时间内有多少次更新才进行保存。通过合理的设置保存策略,可以确保数据的稳定性和一致性,并在必要时提供数据的恢复和备份。
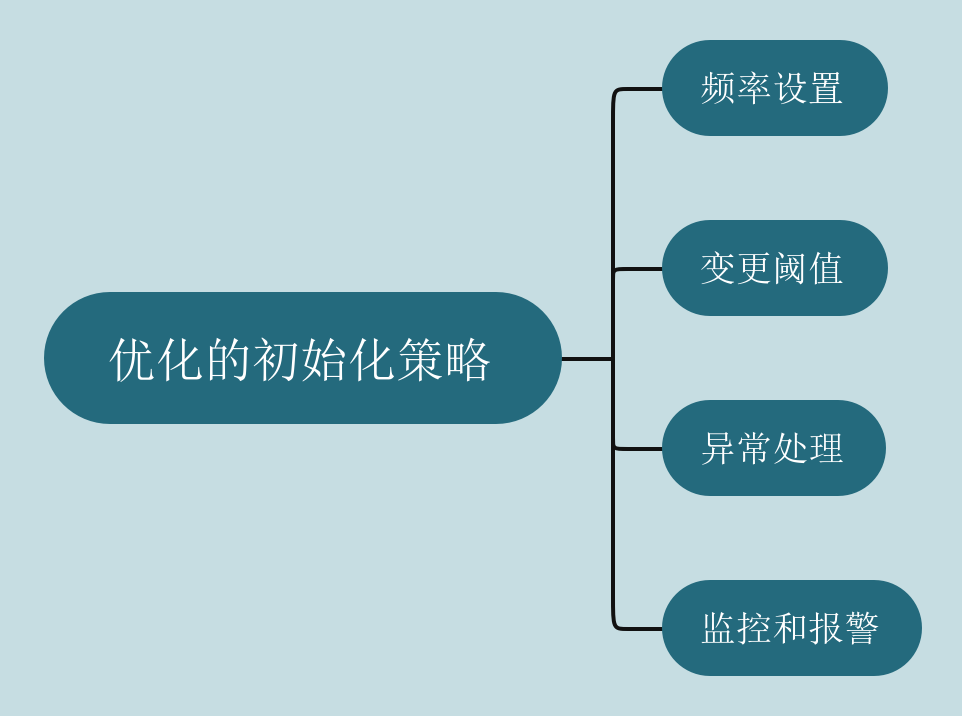
优化的初始化策略
-
频率设置:根据业务需求和数据敏感性,确定保存的频率。例如,可以将保存频率设置为每小时一次,或每天一次等。
-
变更阈值:定义在指定时间段内所发生的变更次数,超过该阈值才触发保存操作。这个阈值可以根据服务器的负载情况、数据更新频率和可接受的数据损失程度进行调整。例如,如果服务器的负载较高且数据更新频率较高,可以设置较小的阈值以保证数据的实时性。
-
异常处理:考虑到突发情况和异常场景,建议在策略中加入异常处理机制。例如,可以设置一个最大保存间隔时间,即使在达到变更阈值之前,如果超过该时间没有进行保存,也会触发保存操作,以避免数据丢失。
-
监控和报警:实现监控和报警系统,用于监控保存操作是否成功,并及时发送警报通知相关人员,以便及时采取措施解决潜在的问题。
// 1小时内1次更新
appendServerSaveParams(60*60,1);
// 5分钟内100次更新
appendServerSaveParams(300,100);
// 1分钟内10000次更新
appendServerSaveParams(60,10000);
指定配置文件
如果在启动服务器时指定了配置文件,那么在下面的“加载配置文件”步骤中,将根据配置文件的内容来更改服务器的某些配置。
这个步骤的目的是为了实现根据用户指定的配置文件来自定义服务器的设置。通过加载配置文件,可以轻松地更改服务器的各种参数和选项,以适应不同的需求和环境。系统会读取配置文件的内容,并解析其中的特定参数。然后,根据这些参数的值,进行相应的配置更改,例如修改服务器的端口号、调整缓存大小、设定权限等。
这种动态加载配置文件的方式可以提供更大的灵活性和可配置性。用户可以根据自己的需求,通过修改配置文件来定制服务器的行为,而无需修改源代码或重新编译。
使用配置文件还可以方便地管理和维护服务器配置。通过将配置项集中存储在配置文件中,可以更加清晰地查看和修改服务器的设置,而不需要深入代码中查找。
加载配置文件
当指定了配置文件之后,Redis会使用loadServerConfig()函数来加载配置文件。这个过程非常简单,主要是通过标准I/O库打开配置文件,然后逐行读取并覆盖之前设置的默认配置。
配置文件的使用可以让用户根据自己的需求来自定义Redis的设置。通过编辑配置文件,可以轻松地更改Redis的各种参数和选项,以适应不同的使用场景和需求。
注意,在Redis的代码包中,有一个默认配置文件。如果在启动Redis服务器时没有指定配置文件,那么Redis不会使用这个默认文件中的配置,而是会使用之前步骤中的默认初始化配置。
默认配置文件中的配置项与之前步骤中默认初始化的配置项可能会有所不同。因此,如果没有指定配置文件,不能认为Redis的行为会按照默认配置文件进行。
默认的数据保存策略
在默认配置文件中,这些配置项定义了Redis在何时将数据写入磁盘进行持久化。每个配置项都由两个参数组成:时间间隔和更新次数。有一个典型的数据保存策略示例
每15分钟进行1次更新
save 900 1
每5分钟进行100次更新
save 300 10
每1分钟进行10000次更新
save 60 10000
在上述示例中,第一个配置项表示每隔15分钟,Redis会对数据进行一次更新并写入磁盘。第二个配置项表示每隔5分钟,Redis会对数据进行100次更新后才写入磁盘。第三个配置项表示每隔1分钟,Redis会对数据进行10000次更新后才写入磁盘。
这些配置可以根据具体的需求进行调整。通过修改时间间隔和更新次数,可以根据数据更新频率和持久化要求来优化数据保存策略。
初始化服务器
初始化服务器的工作主要在initServer()函数中完成。该函数负责完成之前未完成的工作,并对server变量进行初始化。具体的工作包括设置信号处理、创建clients和slaves列表、创建Pub/Sub通道列表,同时还会创建共享对象。
下面是一些示例的共享对象的创建:
shared.crlf = createObject(REDIS_STRING, sdsnew("\r\n"));
shared.ok = createObject(REDIS_STRING, sdsnew("+OK\r\n"));
shared.err = createObject(REDIS_STRING, sdsnew("-ERR\r\n"));
shared.emptybulk = createObject(REDIS_STRING, sdsnew("$0\r\n\r\n"));
最后,如果启用了虚拟内存机制,还需要初始化虚拟内存相关的内容,例如,Thread I/O等。通过initServer()函数的执行,服务器的各个组件和变量将得到正确的初始化,为后续的操作和功能提供了基础。
注意,在实际应用中,根据具体需求可以对initServer()函数的实现进行进一步优化和扩展,以满足不同的业务需求和性能要求。
加载数据库
在完成了上面的所有的初始化工作之后,Redis开始加载数据到内存中,如果启用了appendonly了,则Redis从appendfile加载数据,否则就从dbfile加载数据。
完成了上述所有的初始化工作后,Redis会开始将数据加载到内存中。根据配置的不同,Redis会从不同的地方加载数据。
读取文件的操作
如果启用了持久化机制中的appendonly选项,Redis会从appendonly文件中加载数据;否则,Redis会从数据库文件(dbfile)中加载数据。
这一步是将持久化的数据重新加载到内存中,以便在服务器重启后恢复数据的一部分。这样,用户可以继续使用之前存储的数据,而无需重新生成或重新存储数据。
注意,加载数据的过程可能会花费一些时间,具体的加载速度取决于数据量的大小和硬件性能等因素。在加载数据的过程中,Redis会将数据逐步地加载到内存中,并进行相应的索引和数据结构的构建,以便提供快速和高效的数据访问。
AOF文件加载
loadAppendOnlyFile
了解一下从appendfile中加载数据的过程。在执行loadAppendOnlyFile()函数之前,我们首先需要了解appendfile保存了哪些信息。为此,让我们假设我们执行了以下两条命令,并在配置文件中开启了appendonly选项。
例子:
SET key1 value1
SET key2 value2
在Redis的appendfile中,我们将找到以下数据:
*3\r\n$3\r\nSET\r\n$4\r\nkey1\r\n$6\r\nvalue1\r\n
*3\r\n$3\r\nSET\r\n$4\r\nkey2\r\n$6\r\nvalue2\r\n
上述数据是通过RESP(Redis Serialization Protocol)格式来保存的。RESP是一种简单且高效的序列化协议,用于在Redis中编码和解码数据。
在执行loadAppendOnlyFile()函数时,Redis会读取并解析appendfile的内容,将其中的数据加载到内存中供后续使用。通过存储和加载appendfile中的数据,Redis可以实现持久化机制,并确保在服务器重启后能够恢复之前的数据状态。
注意,使用appendfile来保存数据会增加磁盘空间的占用,因此应根据实际需求和硬件资源来选择是否开启该选项。此外,为了保证数据的一致性和可靠性,建议定期对appendfile进行备份和监测。
appendonly.aof
在redis的appendonly.aof文件中,保存的是来自客户端的请求命令。您可能会注意到,在这些保存的命令中,并没有包含GET命令。这是因为在appendonly.aof文件中,只保存了写入数据的请求命令,而不保存读取数据的命令。
在加载数据时,Redis会按照保存的请求命令的顺序重新执行这些命令,以还原先前存储的数据状态。
server.appendonly = 0;
fakeClient = createFakeClient();
startLoading(fp);
-
Redis在开始加载数据之前会暂时关闭appendonly选项。然后,Redis会创建一个假的Redis客户端,并将server.appendonly设置为0以表示关闭appendonly选项。
-
Redis会使用这个假的客户端来执行startLoading(fp)函数,其中fp是指向appendonly.aof文件的指针。通过这个过程,Redis会逐行读取appendonly.aof文件中的命令,并按顺序执行它们,从而加载数据到内存中。
注意,关闭appendonly选项是为了避免加载数据时出现冲突或错误。加载完数据后,可以再次打开appendonly选项,确保之后的请求命令能够被正确地保存。
执行AOF命令
读取appendonly.aof文件中的命令,并在假的Redis客户端上下文中执行这些命令。在执行命令的过程中,服务器不会对该客户端做任何应答。
fakeClient->argc = argc;
fakeClient->argv = argv;
cmd->proc(fakeClient);
/* 假的客户端不应该有回复 */
redisAssert(fakeClient->bufpos == 0 && listLength(fakeClient->reply) == 0);
这段代码会将加载过程中的命令参数(argc)和命令参数值(argv)分配给假的客户端(fakeClient),然后通过cmd->proc(fakeClient)来执行这些命令。
如果在加载过程中,发现物理内存不足且Redis开启了VM(虚拟内存)功能,那么还需要处理swap操作以释放一些内存空间给加载的数据使用。一旦加载完成,将重新设置appendonly标志,以确保之后的请求命令能够正确保存到appendonly.aof文件中。
RDB文件加载
接下来我们将讨论从数据库文件中加载数据(rdbLoad()函数)的步骤。当Redis没有开启appendonly时,我们需要将数据加载到内存中,主要步骤如下:
从数据库文件中加载数据的基本步骤
- 处理SELECT命令,即选择数据库。
- 读取key。
- 读取value。
- 检测key是否已过期。
- 将新的对象添加到哈希表中。
- 如果需要,设置过期时间。
- 如果开启了VM,执行swap操作。
通过以上步骤,我们可以将数据库文件中的数据有效地加载到内存中,以供Redis后续使用。这些步骤确保了数据的正确性和有效性,并在需要的情况下进行过期检查和swap操作,以便更好地管理内存空间。
网络监听
在完成初始化配置和数据加载后,Redis会启动监听服务。值得一提的是,Redis的网络库并不使用libevent或libev等库。
在启动监听服务之后,Redis会开始监听指定的端口,等待来自客户端的连接请求。一旦有客户端请求连接,Redis就会按照定义的协议进行通信,并执行相应的命令或操作。
尽管Redis没有使用libevent或libev这样的外部库来实现网络功能,但它依然能够高效地处理并发连接请求和网络通信。Redis使用了自己的网络库,这样可以更好地控制和优化网络通信的细节,提高效率和可靠性。
通过以上优化,Redis能够在初始化配置和数据加载完成后快速启动监听服务,并通过自身的网络库实现高效的并发网络通信。
Redis总结
Redis是一个开源、高性能的key-value存储系统。它支持数据持久化、多样的数据结构、数据备份以及拥有高性能和原子性操作等特点。此外,Redis提供了丰富的扩展特性,包括发布/订阅、通知和键的过期等,适用于各种实时应用和消息系统。Redis的代码风格简洁,源码可读性强,进一步促进了开发者对Redis的理解和使用。
相信看了本篇内容,你应该对Redis的启动逻辑有了一定的认识,后面会针对于源码进行深入分析,敬请期待!