目录
- 1 构建模型多样性
- 1.1 特征多样性
- 1.2 样本多样性
- 1.3 模型多样性
- 2. 训练过程融合
- 2.1 Bagging
- 2.2 Boosting
- 3. 训练结果融合
- 3.1 加权法
- 3.2 Stacking 融合
- 3.3 Blending 融合
- 4. 实战案例
本章主要分为构建多样性、训练过程融合和训练结果融合三部分。模型融合常常是竞赛取得胜利的关键,相比之下具有差异性的模型融合往往能给结果带来很大提升
1 构建模型多样性
本节将介绍三种模型融合中构建多样性的方式,分别是特征多样性、样本多样性和模型多样性。其中多样性是指子模型之间存在着差异,可以通过降低子模型融合的同质性来构建多样性,好的多样性有助于模型融合效果的提升。
1.1 特征多样性
构建多个有差异的特征集并分别建立模型,可使特征存在于不同的超空间(hyperspace),从而建立的多个模型有不同的泛化误差,最终模型融合时可以起到互补的效果。
在竞赛中,队友之间的特征集往往是不一样的,在分数差异不大的情况下,直接进行模型融合基本会获得不错的收益。另外,像随机森林中的 max_features、XGBoost 中的 colsample_bytree 和 LightGBM 中的 feature_fraction 都是用来对训练集中的特征进行采样的,其实本质上就是构建特征的多样性。
1.2 样本多样性
样本多样性也是竞赛中常见的一种模型融合方式,这里的多样性主要来自不同的样本集。具体做法是将数据集切分成多份,然后分别建立模型。我们知道很多树模型在训练的时候会进行采样 (sampling),主要目的是防止过拟合,从而提升预测的准确性。
有时候将数据集切分成多份并不是随机进行的,而是根据具体的赛题数据进行切分,需要考虑如何切分可以构建最大限度的数据差异性,并用切分后的数据分别训练模型。
例如,在天池 “全球城巿计算AI挑战赛” 中,竞赛训练集包含从2019年1月1日到1月25日共25天的地铁刷卡数据记录,要求预测1月26日每个地铁站点每十分钟的平均出入客流量(2019年1月26日是周六)。显然,工作日和周末的客流量分布具有很大差异,这时会面临一个问题,若只保留周末的数据进行训练,则会浪费掉很多数据;若一周的数
据全部保留,则会对工作日的数据产生一定影响。这时候就可以云试构建两组有差异性的样本分别训练模型,即整体数据保留为一组,周末数据为一组。当然,模型融合后的分数会有很大提升。
1.3 模型多样性
不同模型对数据的表达能力是不同的,比如 FM 能够学习到特征之间的交叉信息,并且记忆性较强;树模型可以很好地处理连续特征和离散特征(如LightGBM和CatBoost),并且对异常值也具有很好的健壮性。把这两类在数据假设、表征能力方面有差异的模型融合起来肯定会达到一定的效果。
对于竞赛而言,传统的树模型(XGBoost、LightGBM、CatBoost)和神经网络都需要尝试一遍,然后将尝试过的模型作为具有差异性的模型融合在一起。
除了上面所讲,还有很多其他构建多样性的方法,比如训练目标多样性、参数多样性和损失函数选择的多样性等,这些都能产生非常好的效果。
2. 训练过程融合
模型融合的方式有两种,第一种是训练过程融合,比如我们了解到的随机森林和 XGBoost,基于这两种模型在训练中构造多个决策树进行融合,这里的多个决策树可以看作多个弱学习器。其中随机森林通过 Bagging 的方式进行融合,XGBoost 通过 Boosting 的方式进行融合。
2.1 Bagging
Bagging 的思想很简单,即从训练集中有放回地取出数据(Bootstrapping),这些数据构成样本集,这也保证了训练集的规模不变,然后用样本集训练弱分类器。重复上述过程多次,取平均值或者采用投票机制得到模型融合的最终结果。上述流程的示意图如下图所示。
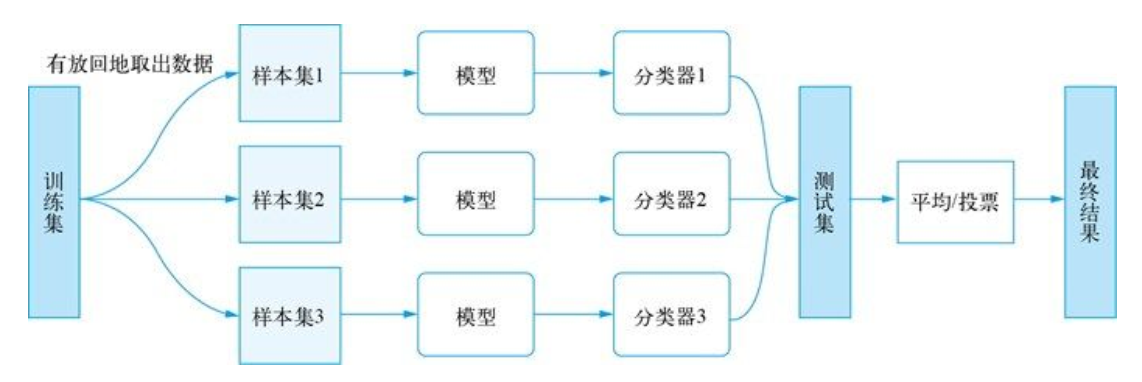
当我们在不同的样本集上训练模型时,Bagging 通过减小误差之间的差来减少分类器的方差。换言之,Bagging 可以降低过拟合的风险。
Bagging 算法的效率来自于训练数据的不同,各模型之间存在着很大的差异,并且在加权融合的过程中可使训练数据的错误相互抵消。当然,这里可以选择相同的分类器进行训练,也可以选择不同的分类器。另外,基于 Bagging 的算法有 Bagging meta-estimator 和随机森林。
2.2 Boosting
毫不夸张地讲,Boosting 的思想其实并不难理解,首先训练一个弱分类器,并把这个弱分类器分错类的样本记录下来,同时给予这个弱分类器一定的权重;然后建立一个新的弱分类器,新的弱分类器基于前面记录的错误样本进行训练,同样,我们也给予这个分类器一个权重。重复上面的过程,直到弱分类器的性能达到某一指标,例如当再建立的新弱分类器并不会使准确率显著提升时,就停止迭代。最后,把这些弱分类器各自乘上相应的权重并全部加起来,就得到了最后的强分类器。其实,基于 Boosting 的算法是比较多的,有 Adaboost、LightGBMXGBoost 和 CatBoost 等。
3. 训练结果融合
模型融合的第二种方式是训练结果融合,主要分为加权法、Stacking 和 Blending,这些方法都可以有效地提高模型的整体预测能力,在竞赛中也是参赛者必须要掌握的方法。
3.1 加权法
加权法对于一系列任务(比如分类和回归)和评价指标(如 AUC、MSE 或 Logloss)都是很有效的,比如我们有 10 个算法模型并都预测到了结果,直接对这 10 个结果取平均值或者给予每个算法不同的权重,即得到了融合结果。加权法通常还能减少过拟合,因为每个模型的结果可能存在一定的噪声,加权法能够平滑噪声,提高模型的泛化性。
-
分类问题
对于分类问题,需要注意不同分类器的输出结果范围一致,因为输出的预测结果可以是 0/1 值,也可以是介于 0 和 1 之间的概率。另外,投票法(Voting)也是一种特殊的加权法,假设三个模型分别输出三组结果∶ 1010110011 1110110011 1110110011 \begin{aligned} 1010110011 \\ 1110110011 \\ 1110110011 \end{aligned} 101011001111101100111110110011只要保证这三个结果的权重一致,不论是投票法(少数服从多数),还是加权法(固定0.5为阈值),最终得到的融合结果均为 1110110011。 -
回归问题
对于回归问题,如果使用加权法,则会非常简单。这里主要介绍算法平均和几何平均,那么为什么有两种选择呢,主要还是因为评价指标。在2019腾讯广告算法大赛中,选择几何平均的效果远远好于选择算术平均,这是由于评分规则是平均绝对百分比误差(SMAPE)。此时如果选择算术平均则会使模型融合的结果偏大,这不符合平均绝对百分比误差的直觉,越小的值对评分影响越大,算术平均会导致出现更大的误差,所以选择几何平均,能够使结果偏向小值。SMAPE 的公式如下:
SMAPE = 1 n ∑ t = 1 n ∣ F t − A t ∣ ( F t + A t ) / 2 \text{SMAPE} = \frac{1}{n} \sum_{t=1}^n \frac{|F_t - A_t|}{(F_t + A_t) / 2} SMAPE=n1t=1∑n(Ft+At)/2∣Ft−At∣- 算术平均
基于算术平均数的集成方法在算法中是用得最多的,因为它不仅简单,而且基本每次使用该算法都有较大概率能获得很好的效果。其公式如式:
p r e d = p r e d 1 + p r e d 2 + ⋯ + p r e d n n pred = \frac{pred_1 + pred_2 + \cdots + pred_n}{n} pred=npred1+pred2+⋯+predn - 几何平均
几何平均。根据很多参赛选手的分享,基于几何平均数的加权法在算法中使用得还不是很多,但在实际情况中,有时候基于几何平均数的模型融合效果要稍好于基于算术平均数的效果。其公式如下:
p r e d = ( p r e d 1 + p r e d 2 + ⋯ + p r e d n ) n pred = \sqrt[n]{(pred_1 + pred_2 + \cdots + pred_n)} pred=n(pred1+pred2+⋯+predn)
- 算术平均
-
排序问题
一般推荐问题中的主要任务是对推荐结果进行排序,常见的评价指标有 mAP(mean Average Precision)、NDCG(NormalizedDiscounted Cumulative Gain)、MRR(Mean ReciprocalRank)和 AUC,这里主要介绍MRR 和 AUC。-
MRR
给定推荐结果 q q q,如果 q q q 在推荐序列中的位置是 r r r,那么 M R R ( q ) MRR(q) MRR(q) 就是 1 / r 1/r 1/r。可以看出,如果向用户推荐的产品在推荐序列中命中,那么命中的位置越靠前,得分也就越高。显然,排序结果在前在后的重要性是不一样的,因此我们不仅要进行加权融合,还需要让结果偏向小值。这时候就要对结果进行转换,然后再用加权法进行融合,一般而言使用的转换方式是 log 变换。其基本思路如下:首先,输入三个预测结果文件,每个预测结果文件都包含 M M M 条记录,每条记录对应 N N N 个预测结果,最终输出三个预测结果文件的整合结果。内部的具体细节可以分为以下两步。
第一步:统计三个预测结果文件中记录的所有推荐商品(共 N N N 个商品)出现的位置,例如商品 A,在第一份文件中的推荐位置是 1,在第二个文件的推荐位置是 3,在第三个文件中未出现,此时我们计商品 A 的得分为 l o g 1 + l o g 3 + l o g ( N + 1 ) log1 + log3 + log(N+1) log1+log3+log(N+1),此处我们使用 N + 1 N+1 N+1 来表示未出现,即 N N N 个推荐商品中是找不到商品 A 的,所以只能是 N + 1 N+1 N+1。
第二步:对每条记录中的商品按计算得分由小到大排序,取前 N N N 个作为这条记录的最终推荐结果。
-
AUC
AUC 作为排序指标,一般使用排序均值的融合思路,使用相对顺序来代替原先的概率值。很多以 AUC 为指标的比赛均取得了非常不错的成绩,如下两步为一种使用过程:第一步∶对每个分类器中分类的概率进行排序,然后用每个样本排序之后得到的排名值(rank)作为新的结果。
第二步:对每个分类器的排名值求算术平均值作为最终结果。
-
3.2 Stacking 融合
使用加权法进行融合虽然简单,但需要人工来确定权重,因此可以考虑更加智能的方式,通过新的模型来学习每个分类器的权重。这里我们假设有两层分类器,如果在第一层中某个特定的基分类器错误地学习了特征空间的某个区域,则这种错误的学习行为可能会被第二层分类器检测到,这与其他分类器的学习行为一样,可以纠正不恰当的训练。上述过程便是Stacking融合的基本思想。
这里需要注意两点:第一,构建的新模型一般是简单模型,比如逻辑回归这样的线性模型;第二,使用多个模型进行 Stacking 融合会有比较好的结果。
Stacking 融合使用基模型的预测结果作为第二层模型的输入。然而,我们不能简单地使用完整的训练集数据来训练基模型,这会产生基分类器在预测时就已经 “看到” 测试集的风险,因此在提供预测结果时出现过度拟合问题。所以我们应该使用 Out-of-Fold 的方式进行预测,也就是通过 K 折交叉验证的方式来预测结果。这里我们将Stacking 融合分为训练阶段和测试阶段两部分,将并以流程图的形式展示每部分的具体操作。如下图所示为训练阶段。
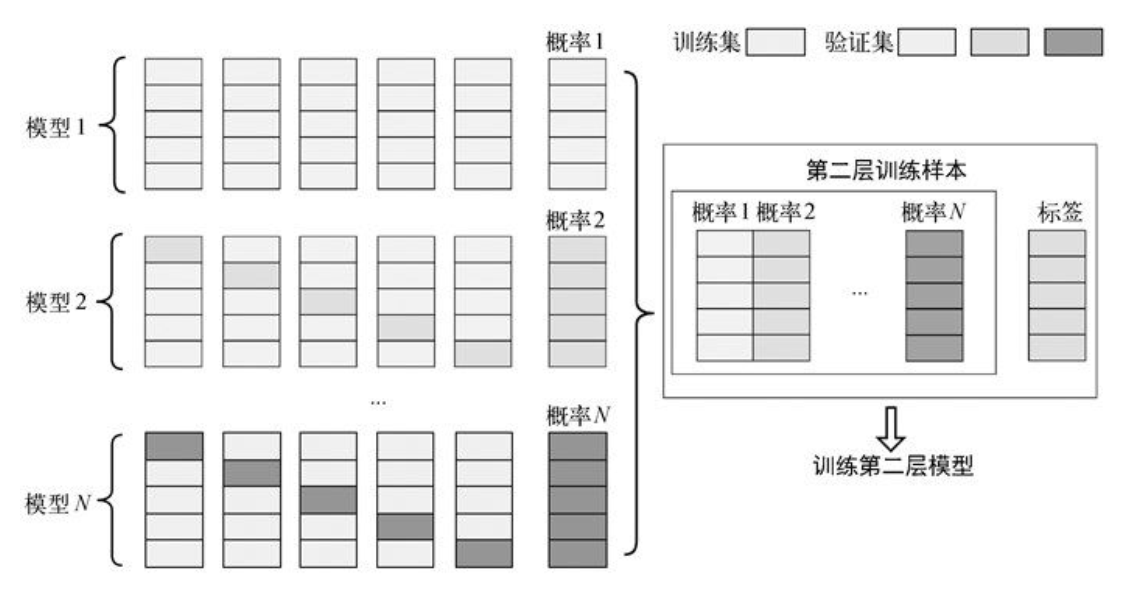
在上图中,我们对每个模型都使用五折交叉验证的方式,然后可以获取完整验证集的预测概率结果,最终将得到的 N 列概率结果和训练集标签拼接成第二层的训练样本,这样就可以训练第二层的模型。之后,我们将五折交叉验证时训练的模型(如模型1,可以训练得到 5 个不一样的模型 1)用作测试集的训练。
如下图所示,测试阶段将使用训练阶段训练好的模型,首先使用模型 1 得到的 5 个模型分别对测试集进行预测,然后将 5 个概率结果通过加权平均得到一个概率结果概率 1。然后对模型 ⒉到模型 N N N 也依次进行以上操作,最后得到 N N N个概率结果。将这 N N N 个结果作为第二层的测试样本,然后使用第二层训练得到的模型对第二层测试样本预测得到最终结果。

请思考特征加权的线性堆叠,可参考相应论文 “Feature-WeightedLinear Stacking two layer stacking”,其实就是对传统的 Stacking 融合方法在深度上进行扩展。通过传统的 Stacking 融合方法得到概率值,再将此值与基础特征集进行拼接,重新组成新的特征集,进行新一轮训练。
3.3 Blending 融合
不同于 Stacking 融合使用 K 折交叉验证方式得到预测结果,Blending 融合是建立一个Holdout 集,将不相交的数据集用于不同层的训练,这样可以在很大程度上降低过拟合的风险。假设我们构造两层 Blending,将训练集按 5:5 的比例分为两部分(train_one和train_two),测试集为 test。
第一层用 train_one 训练多个模型,将此模型对 train_two 和 test 的预测结果合并到原始特征集中,作为第二层的特征集。第二层用 train_two 的特征集和标签训练新的模型,然后对 test 预测得到最终的融合结果。
4. 实战案例
参考代码仓库,有很多可复用的代码,建立多理解。