在上期内容,我们讲述了c++相比于C语言的更简易之处,本期就让我们继续学习相关的知识,了解c++宇宙
引用(起别名)
举个例子,诸葛亮,字孔明,号卧龙先生,你可以叫他诸葛亮,这是他的本名,也可以叫他卧龙先生,这是他的别名。
话不多说上代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a;//<====定义引用类型
cout << &b << endl;
cout << &a << endl;
return 0;
}看第七行和第八行,我们定义了一个变量a,像第八行那样的操作,就是给a起一个别名,b同a指向的是同一块地址,我们可以验证一下:
运行截图:
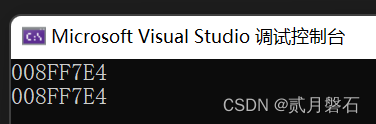
可以发现a和b的地址是一样的,也就可以得到一个结论,b值的改变,会导致a的变化
现在大家有一个疑问,这个起外号有啥用呢? 可以告诉大家,在普通场景下,引用操作毫无意义,但是在以下的场景下,作用巨大:
1.输出型参数
我们以前写一个交换函数,是不是得用指针,因为形参的改变不影响实参,C语言阶段不需要传地址才能实现,而现在我们只需要简单的引用:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
void swap(int& ra, int& rb)
{
int t = ra;
ra = rb;
rb = t;
cout << ra << rb << endl;
}
int main()
{
int a ,b;
cin >> a >> b ;
swap(a, b);
return 0;
}现在我们不需要复杂的指针引用,只需要把传进的参数换成别名,就可以直接对数值进行更改,因为别名和本身是指向同一个地址,二者相互影响。
引用特性
1. 引用在定义时必须初始化
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int a = 1;
int& b;//错误,要进行初始话
int& b = a;//正确,在定义的地方初始化
cout << b << endl;
return 0;
}2. 一个变量可以有多个引用
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a;//b是a的别名
int& c = b;//c是b的别名
//打印看看他们的地址是否相同:
cout << &a << &b << &c << endl;
return 0;
}仔细阅读代码会发现,我们定义了一个变量a,然后给a取了别名叫b,又给b取了个别名叫c,这样做是完全允许的。谁说人只能由=有一个外号?我不仅仅叫诸葛亮,也叫诸葛孔明,亦可以叫卧龙先生,这三者都是我。
那么改变c的数值会不会改变b呢,亦会不会改变c呢?让我们运行以下代码:
运行截图:
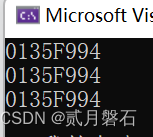
地址完全一样,这其中的意思相信大家都明白了,三者任意一个的改变,都会改变其他,就像是你问诸葛亮先生吃饭了吗?他回答吃了,那么孔明也吃了,卧龙先生也吃过了。哈哈哈哈是不是很形象。
3. 引用一旦引用一个实体,再不能引用其他实体
当一个变量名称为另一个变量的别名的时候,就不能在称为别的变量的别名:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a;//b是a的别名
int x = 1;
b = x;
cout << b << endl;
return 0;
}大家阅读这段代码,b是a的别名,思考一下b=x这句话,是给b赋x的值还是起别名
答案是赋值

这就是 “引用一旦引用一个实体,再不能引用其他实体”的含义。(只能和一个人结婚)
引用复杂的使用场景
1.引用做返回值
大家来看一段这样的代码:
//传值返回
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int count()
{
int n = 0;
n++;
return n;
}
int main()
{
int ret = count();
cout << ret << endl;
return 0;
}
大家思考一下,我们在调用函数之后,是不是把n返回到主函数之中
相信大家都知道肯定不是,因为这是传值返回,当函数调用结束后,n是不是就被销毁了,因为n是在函数中被定义的临时变量。
只要我们在这段代码稍加改动,就可以将其改成传引用返回
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int& count()
{
int n = 0;
n++;
return n;
}
int main()
{
int ret = count();
cout << ret << endl;
return 0;
}仔细区分这两段代码的区别,这段函数的返回值就是n的别名,也就是n的引用,大家想想,这个时候会发生什么事情,返回n的引用会引发什么问题?
前文我们提到,出了作用域,n就会被销毁,既然n已经销毁了,还要返回n的别名,是不是就成了类似于野指针的样子呀。
有些小伙伴会发出这样的疑问,空间都被销毁了,为了什么还能返回他的别名?
这是因为空间的销毁就像是退房一样,这个房间住着n这个人,现在这个房间n不用了,n退了这个房间,但是n还是存在的,而引用这个做法,就像是房间虽然退了,但是悄悄地把钥匙留下了。
这就造成了我们这段程序的结果不准确,有可能是1,也可能是随机值
只要我稍微一变招:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int& count()
{
int n = 0;
n++;
return n;
}
int main()
{
int& ret = count();
cout << ret << endl;
cout << ret << endl;
return 0;
}打印的值就会变成这样:

第一次打印ret还是1,第二次就变成了随机值
这涉及到以后要学习的知识,先给大家卖个关子哈哈哈哈,大家记住这个小tip
再来看这样一段代码:
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
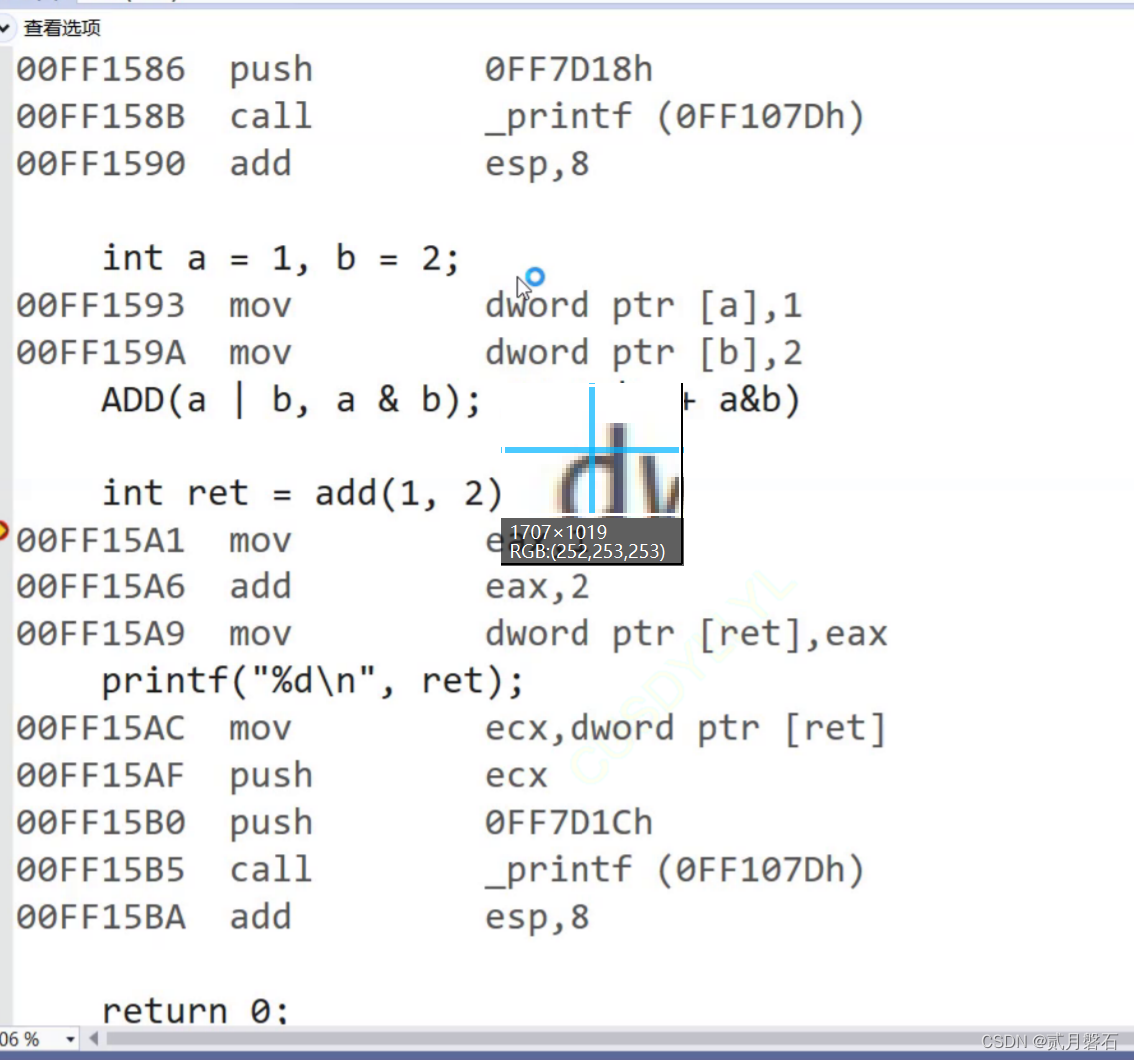
}大家觉得这段代码的返回值是3还是7,把自己的答案写在评论区
答案:

为什么会是7呢,这是栈帧有关的知识,给大家看一张图,C语言学的稳定的小伙伴应该是可以看得懂,当然C语言学的不好的同学可以看看博主曾经C语言的博客,希望能给大家带来帮助
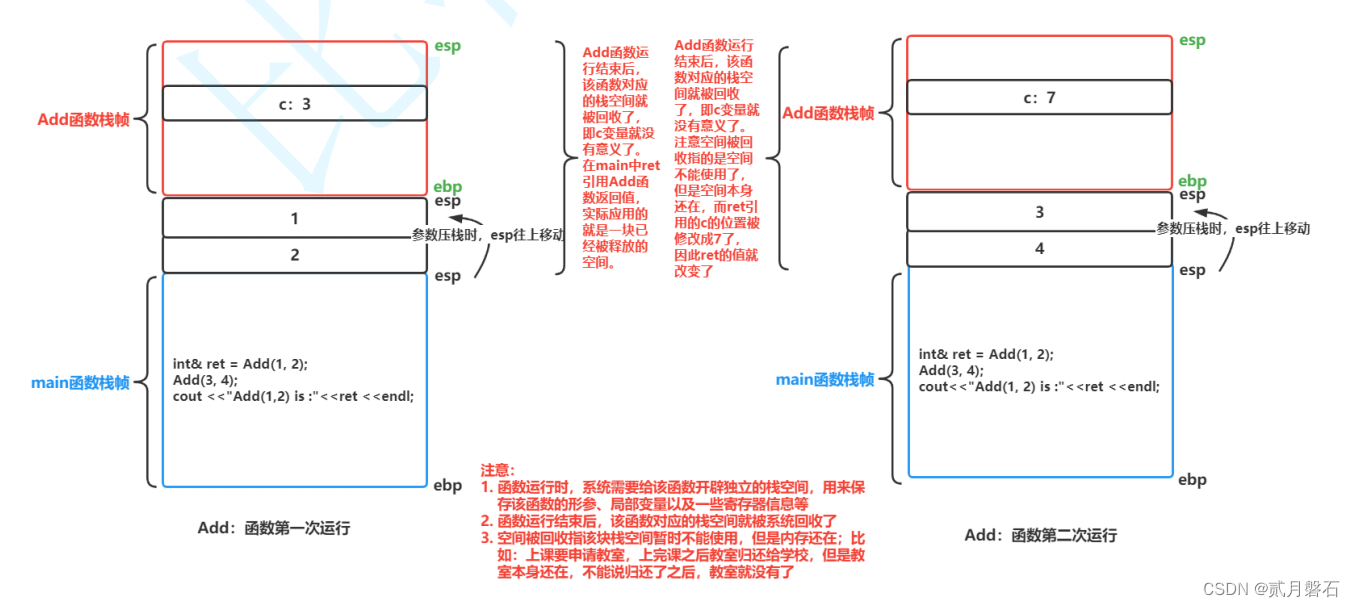
传值、传引用效率比较
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
#include <time.h>
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
}这段代码里我分别调用了传值返回和传引用返回,并且计算它们的运行时间供大家比较:
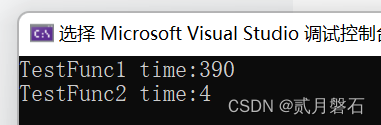
可以看出传值返回比传引用返回慢了很多很多,这仅仅只是传个参的小路就差了这么多!!!
所以衍生出一个问题:
什么时候该用传值返回,什么时候该用传引用返回?
1.返回的参数是一个全局变量或者静态对象,就不需要考虑生命周期的事,所以就用引用返回正正好好,提高很多的效率
2.在堆上动态申请的用引用返回,提高效率
引用和指针的区别
int main()
{
int a = 10;
int& ra = a;
cout<<"&a = "<<&a<<endl;
cout<<"&ra = "<<&ra<<endl;
return 0;
}int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}(仔细观察代码,自己运行一下)

内联函数
内联函数也是c++来补C语言的一个坑。
宏在C语言的使用相信大家都很熟悉了
宏的优点 :可以批量置换数值
宏最大的缺陷在于宏函数,现给大家看一段实现两数之和的宏函数
define add(x,x) ((x)+(y))#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
inline int Add(int x, int y)
{
return x + y;
}
int main()
{
Add(1, 2);
return 0;
}inline的作用就是和宏大差不差,但是没有宏的缺陷,宏函数没有调用的消耗,内联函数也没有,内联函数的特点是在release优化下把这个函数给展开,像编译器展开
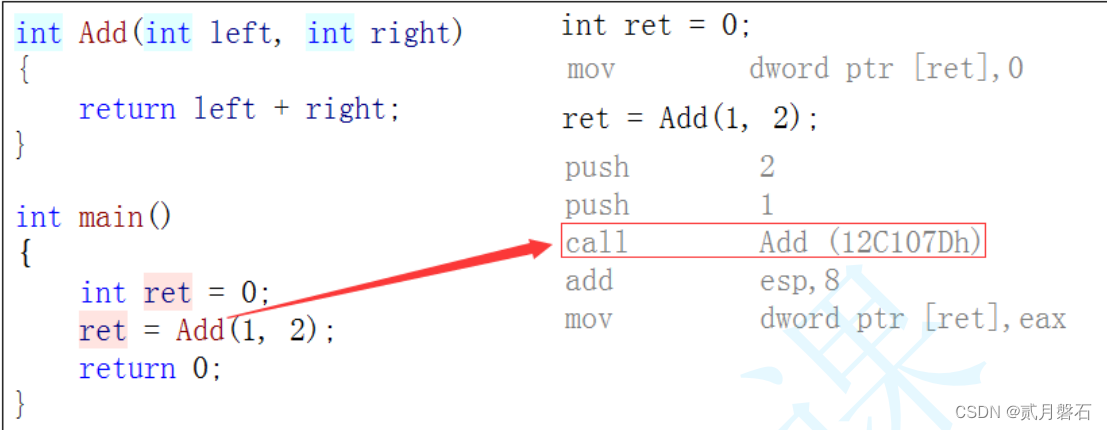
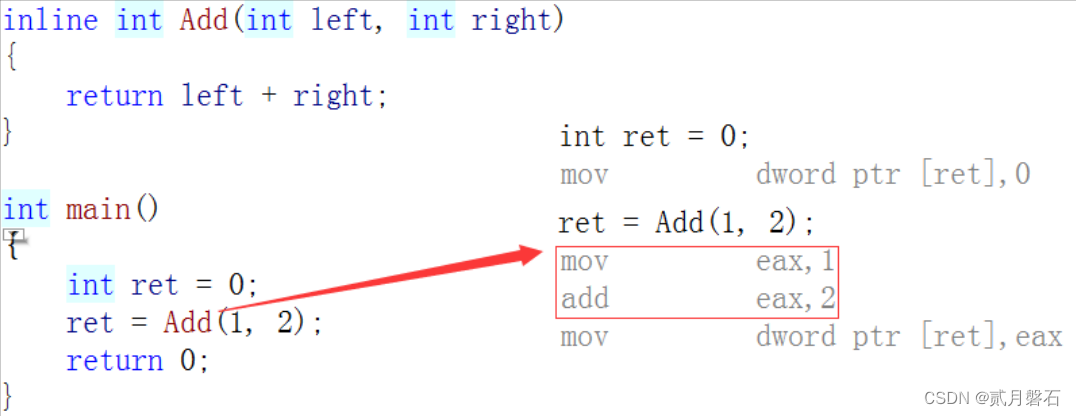
刚刚学到这块的时候,博主就在想,如果把所有的函数都搞成内联函数,那效率岂不是爽歪歪了 ,不知大家有没有这样的想法,哈哈哈哈这样的想法是很有想象力,现在博主也给大家解答一下这样是不可以的:
首先,我们是不可以把很大的函数建内联的,更不要说所有的函数,如果一个程序很长,变成内联会导致程序变大的,这叫做程序膨胀
内联的特性:
auto关键字(c++11)
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int a = 0;
int b = a;
return 0;
}我们先定义了一个a,一般我们要定义一个和a同类型的b的时候,是不是就要像代码那样操作,现在有了auto,我们完全可以换个方式:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int a = 0;
auto b = a;
return 0;
}把b的类型定义为auto,且让b=a,auto就会推到出a的类型,进而影响b,当然大家要分清,这里的a=b不是数值的等于,而是针对于类型。
这种方法走在常规场景下毫无价值,但是随着学习的深入,我们的代码会越来越多,auto的重大作中就显露出来了:
以后我们会学习一个新的类型:
std::vertor<std::string>::iterator
std::vertor<std::string>::iterator it = v.begin();
auto it = v.begin();
但是要【注意】:
auto不能推导的场景
// 此处代码编译失败, auto 不能作为形参类型,因为编译器无法对 a 的实际类型进行推导void TestAuto ( auto a ){}
void TestAuto (){int a [] = { 1 , 2 , 3 };auto b [] = { 4 , 5 , 6 };//错误}
基于范围的for循环(C++11)
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int arr[] = { 1,2,3,4,5 };
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
arr[i] *= 2;
}
return 0;
}以前我们对这个数组进行访问,要先求数组的大小,在进行for循环逐个遍历,现在我们来学用范围for访问数组
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int arr[] = { 1,2,3,4,5 };
for(auto e :arr)
{
cout << 2*e << " ";
}
return 0;
}现在我们来访问数组,就可以用这个范围for,这是一个固定的框架,大家把他记下来,就像当初学习for循环的时候那样,会用就行!
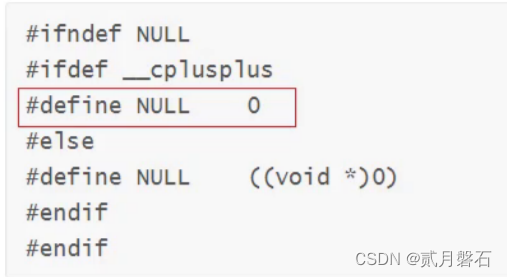
指针空值nullptr(C++11)
c++11补了一个c+98的大坑:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include <time.h>
using namespace std;
void f(int)
{
cout << " f(int)" << endl;
}
void f(int*)
{
cout << " f(int*)" << endl;
}
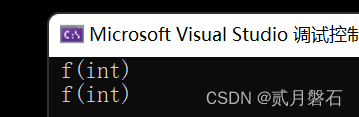
int main()
{
f(0);
f(NULL);
return 0;
}大家看这段代码,根据我们前边的学习,不难分辨这两个函数构成了函数重载,他们的类型不一样,按理说第一次传参传的是数字0,应该调用第一个函数,第二次传参应该调用第二个函数,因为传的是指针,但是实际却很坑: