CMU 15-445 -- Embedded Database Logic - 12
- 引言
- User-Defined Functions (UDF)
- SQL Functions
- External Programming Language
- Stored Procedures
- Stored Procedures 与 UDF 的区别
- Database Triggers
- Change Notifications
- User-Defined Types (UDT)
- Views
- views vs select...into
- views update
- Materialized Views
- Conclusion
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录,附加个人拙见,同样借助CMU 15-445课程内容来完成MIT 6.830 lab内容。
到目前为止,我们都假设所有的业务逻辑都位于应用本身,应用通过与 DBMS 通过多次通信,来达到最终业务目的,如下图所示:
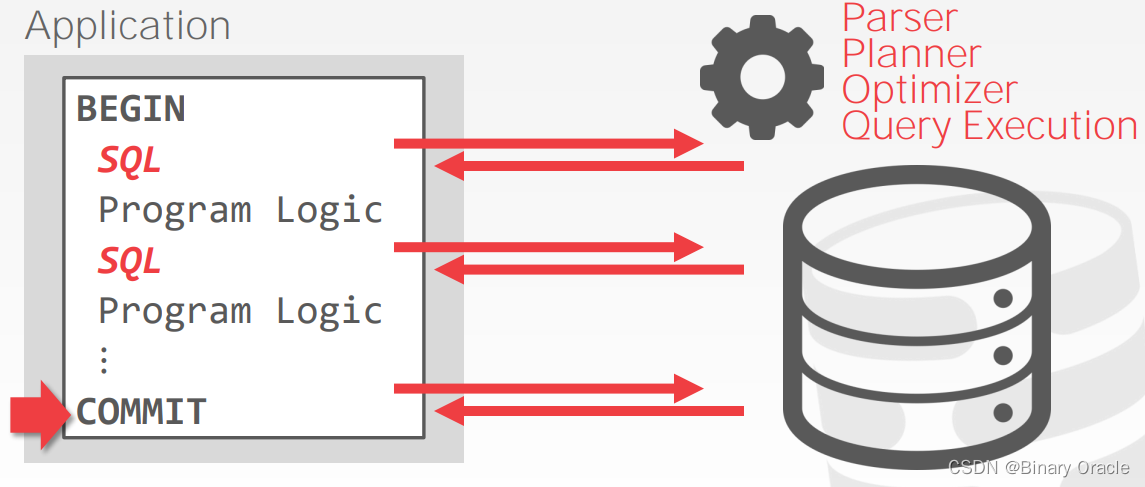
这种做法有两个坏处:
- 多个 RTT,更多延迟
- 不同的应用无法复用查询逻辑
如果能将部分业务逻辑转移到 DBMS 中,就能够在以上两个方面得到优化。本节将介绍将业务逻辑转移到 DBMS 中的几种方法:
- User-defined Functions
- Stored Procedures
- Triggers
- Change Notifications
- User-defined Types
- Views
注意:将业务逻辑嵌入 DBMS 中也有坏处,比如不同版本的应用依赖于不同版本的 Stored Procedures 等,后期将增加 DBMS 的运维成本,因此这种做法也有其劣势,要具体问题具体分析。
User-Defined Functions (UDF)
UDF 允许应用开发者在 DB 自定义函数,根据返回值类型可以分为:
- Scalar Functions:返回单个数值
- Table Functions:返回一张数据表
UDF 函数计算的定义可以通过两种方式:
- SQL Functions
- External Programming Languages
SQL Functions
SQL Functions 包含一列 SQL 语句,DBMS 按顺序执行这些语句,以最后一条语句的返回值作为整个 Function 的返回值:
CREATE FUNCTION get_foo(int) RETURNS foo AS $$
SELECT * FROM foo WHERE foo.id = $1;
$$ LANGUAGE SQL;
External Programming Language
一些 DBMSs 支持使用非 SQL 定义 UDF:
- SQL Standard:SQL/PSM
- Oracle/DBS:PL/SQL
- Postgres:PL/pgSQL
- MySQL/Sybase:Transact-SQL
以下是 PL/pgSQL 的例子:
CREATE OR REPLACE FUNCTION sum_foo(i int) RETURN int AS $$
DECLARE foo_rec RECORD;
DECLARE out INT;
BEGIN
out := 0
FOR foo_rec IN SELECT id FROM foo
WHERE id > i LOOP
out := out + foo_rec.id;
END LOOP;
RETURN out;
END;
$$ LANGUAGE plpgsql;
Stored Procedures
Stored Procedure 同样允许应用开发者自定义复杂逻辑,它的主要特点是:
- 可以有多个输入和输出值
- 可以修改数据表及数据结构
- 通常不在 SQL 查询中调用
通常应用程序会直接调用 Stored Procedures,如下图所示:
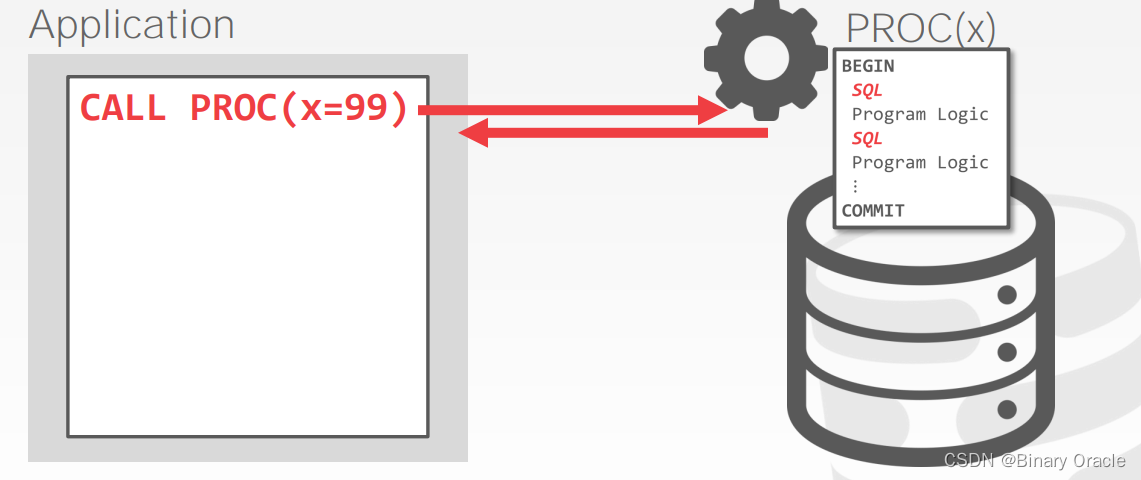
Stored Procedures 与 UDF 的区别
抛开具体特征,从语义出发:
- UDF: perform a subset of a read-only computation within a query
- Stored Procedure: perform a complete computation that is independent of a query
Database Triggers
Trigger 通常被用来连接事件与 UDF:当某个 DB 事情发生时,监听相关事件的 trigger 负责调用对应的 UDF。
通常开发者需要定义:
-
触发的事件类型: INSERT, UPDATE, DELETE, TRUNCATE, CREATE, ALTER, DROP
-
事件的定义域: TABLE, DATABASE, VIEW, SYSTEM
-
触发的时机:
- before the statement executes
- after the statement executes
- before each row that the statement affects
- instead of the statement
举例如下:
CREATE TABLE foo (
id INT PRIMARY KEY,
val VARCHAR(16)
);
CREATE TABLE foo_audit (
id SERIAL PRIMARY KEY,
foo_id INT REFERENCES foo (id),
orig_val VARCHAR,
cdate TIMESTAMP
);
CREATE OR REPLACE FUNCTION log_foo_updates() RETURNS trigger AS $$
BEGIN
IF NEW.val <> OLD.val THEN
INSERT INTO foo_audit (foo_id, orig_val, cdate)
VALUES(OLD.id, OLD.val, NOW());
END IF
RETURN NEW
END
$$ LANGUAGE plpgsql;
CREATE TRIGGER foo_updates BEFORE UPDATE ON foo FOR EACH ROW
EXECUTE PROCEDURE log_foo_updates();
Change Notifications
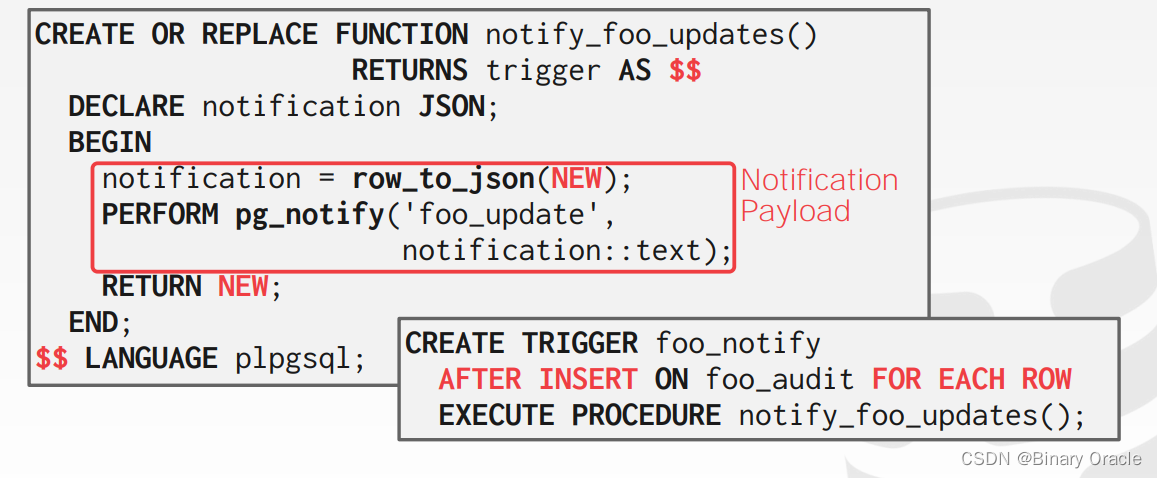
在数据库中,“change notification”(变更通知)类似于触发器(trigger),但是它是指DBMS向外部实体发送消息,告知数据库中发生了一些值得注意的事件。
可以将其类比为"pub/sub"(发布/订阅)系统,其中数据库作为发布者发布通知,而外部实体作为订阅者接收通知。
"change notification"通常可以与触发器(trigger)链接在一起,以便在发生变更时传递通知。
在SQL标准中,这种机制通常被称为"LISTEN + NOTIFY"。
User-Defined Types (UDT)
尽管 DBMSs 支持所有基本的原始数据类型,但如果我们想存储组合数据类型,如 struct,该如何做?就已有的知识,我们能想到两种方法:
- Attribute Splitting:即将组合数据类型单独作为一张表 (pros&cons)
- Application Serialization:即将组合数据序列化 (pros&cons)
除此之外,DBMS 通常还提供额外的 API,方便用户自定义数据,即 UDT:
- Oracle supports PL/SQL
- DB2 supports creating types based on build-in types
- MySQL/Postgres only support type definition using external languages

Views
可以将 View 理解成一张虚拟表,这张表是一个只读查询的结果集,可以被其它查询引用。通常 View 的用途包括:
- 简化查询语句
- 对某些用户选择性隐藏数据
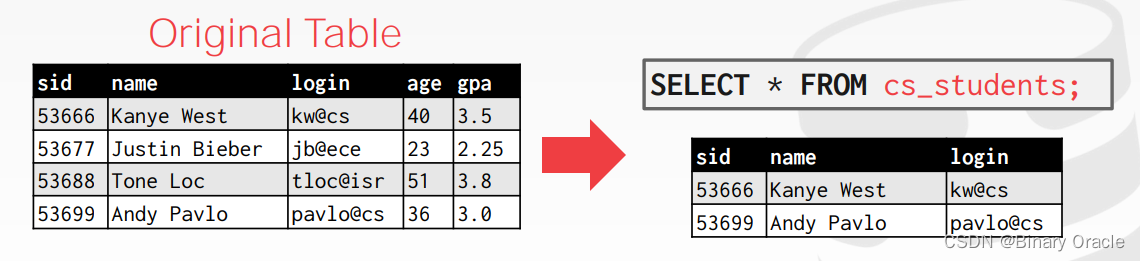
以下面这张 student 表为例:
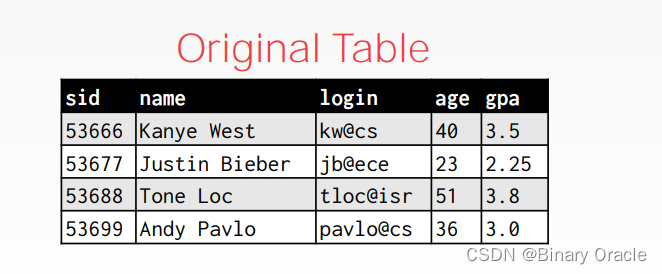
创建 cs_students View:
CREATE VIEW cs_students AS
SELECT sid, name, login
FROM student
WHERE login LIKE '%@cs';
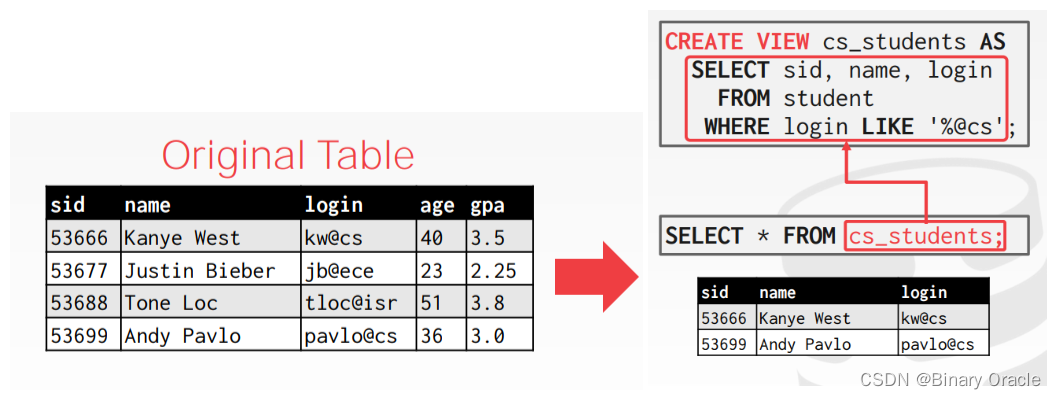
创建 cs_gpa View:
CREATE VIEW cs_gpa AS
SELECT AVG(gpa) AS avg_gpa
FROM student
WHERE login LIKE '%@cs';
views vs select…into
VIEW:
- 视图(VIEW)是一种虚拟表,它仅在需要时动态地生成结果。它不包含实际数据,而是根据与视图相关联的查询来生成结果。每当查询引用该视图时,视图将立即执行,并返回查询结果。
SELECT…INTO:
- SELECT…INTO语句用于从一个表中选择数据,并将其复制到新的静态表中。新表的结构将根据SELECT语句的结果自动创建,并且不会随原始表的更新而更新。这意味着一旦数据被选择并复制到新表中,新表的内容将保持不变,即使原始表的数据发生更改也不会影响新表的内容。
在总结上述两个概念:
- 视图是动态的,每次引用视图时都会生成最新的结果。
- SELECT…INTO创建一个静态表,一旦数据复制到新表中,该表的内容不会随原始表的更改而更新。
views update
根据SQL-92标准规定,如果一个视图具备以下特性,应用程序可以对其进行修改:
-
仅包含一个基本表:该视图应该基于单个底层表。它不能是多个表的组合,也不能包含子查询。
-
不包含分组、去重、联合或聚合:该视图不能涉及GROUP BY、HAVING、UNION或聚合函数(例如SUM、COUNT、AVG等)等操作。它应该是对单个基本表的简单、直接的数据表示。
如果一个视图满足以上两个条件,就被认为是可更新的。这意味着应用程序可以对该视图执行修改(插入、更新、删除)操作,并且这些更改将应用到底层的基本表中。然而,如果一个视图是基于多个表或包含复杂的操作(如分组或聚合),那么数据库管理系统将更难确定如何应用更改,此时该视图可能不具备可更新性。
Materialized Views
View 对应的查询在 View 每次被使用时都会被执行一次,如果我们希望 View 实体化,提高查询效率,可以使用 Materialized Views,后者的数据会随着底层数据改变而被自动更新,举例如下:
CREATE MATERIALIZED VIEW cs_gpa AS
SELECT AVG(gpa) AS avg_gpa
FROM student
WHERE login LIKE '%@cs';
“Materialized views” (物化视图)是数据库中的特殊类型视图。与普通视图不同,物化视图实际上存储了视图的结果集,而不是每次查询时动态生成。这使得物化视图能够在查询时更快地返回结果,因为它们避免了每次查询都执行复杂的计算。
物化视图的特点如下:
-
存储实际数据:物化视图将视图的结果集存储在磁盘上,以表的形式存在。因此,当查询物化视图时,它会直接从磁盘中获取数据,而不是每次执行查询时都重新计算结果。
-
自动更新:虽然物化视图存储了结果数据,但底层的基本表在更新时可能导致物化视图的数据变得过时。因此,可以配置物化视图定期自动更新,以确保其数据与基本表保持同步。
-
提高查询性能:由于物化视图存储了结果数据,所以当查询物化视图时,它可以直接从存储中获取结果,而不需要再次执行复杂的查询计算,从而显著提高了查询性能。
尽管物化视图提供了查询性能的提升,但也需要权衡存储空间和数据更新的成本。因此,在选择使用物化视图时,需要考虑数据更新的频率和数据的变化程度,以及对查询性能的要求。物化视图通常在数据仓库和大型数据集的环境中使用,以加速复杂查询的执行。
Conclusion
将应用逻辑放入 DBMS 中的各有利弊:
- Pros
- 减少 RTT,提高效率
- 不同应用之间实现逻辑重用
- Cons
- 迁移性差
- 运维成本高
本节对应教材PDF





![[JVM]String str1 = new String(“yhz“)和 String str2 = “yhz“ 的区别](https://img-blog.csdnimg.cn/18ba6ce386984c00ae4e8f5197e5c3e0.png)