近年来强化学习(RL)在算法交易领域受到了极大的关注。强化学习算法从经验中学习并基于奖励优化行动使其非常适合交易机器人。在这篇文章,我们将简单介绍如何使用Gym Anytrading环境和GME (GameStop Corp.)交易数据集构建一个基于强化学习的交易机器人。
强化学习是机器学习的一个子领域,涉及代理学习与环境交互以实现特定目标。代理在环境中采取行动,接收奖励形式的反馈,并学会随着时间的推移最大化累积奖励。代理的目标是发现一个将状态映射到行动的最优策略,从而导致最好的可能结果。
Gym Anytrading
Gym Anytrading是一个建立在OpenAI Gym之上的开源库,它提供了一系列金融交易环境。它允许我们模拟各种交易场景,并使用RL算法测试不同的交易策略。
安装依赖
将使用的主要库是TensorFlow, stable-baselines3和Gym Anytrading。运行以下代码来安装所需的依赖项:
!pip install tensorflow
!pip install stable_baselines3
!pip install gym
!pip install gym-anytrading
!pip install tensorflow-gpu
导入库
导入必要的库和设置环境开始:
# Gym stuff
import gym
import gym_anytrading
# Stable baselines - RL stuff
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3 import A2C
# Processing libraries
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
加载GME交易数据
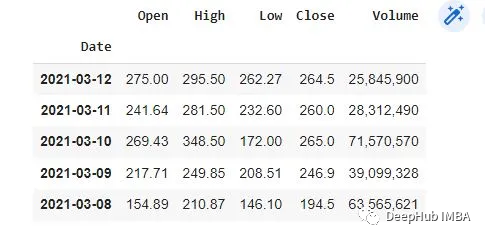
将使用GameStop Corp. (GME)的历史交易数据作为示例。我们假设您拥有CSV格式的GME交易数据,没有的话可以通过搜索引擎找到下载地址。
加载GME交易数据并为Gym Anytrading环境做准备:
# Load GME trading data
df = pd.read_csv('gmedata.csv')
# Convert data to datetime type
df['Date'] = pd.to_datetime(df['Date'])
df.dtypes
# Set Date as the index
df.set_index('Date', inplace=True)
df.head()
通过Gym创建交易环境
下一步就是使用Gym Anytrading创建交易环境。环境将代表GME交易数据,我们的代理将通过购买、出售和持有股票等行为与环境进行交互。
# Create the environment
env = gym.make('stocks-v0', df=df, frame_bound=(5, 100), window_size=5)
# View environment features
env.signal_features
# View environment prices
env.prices
探索环境
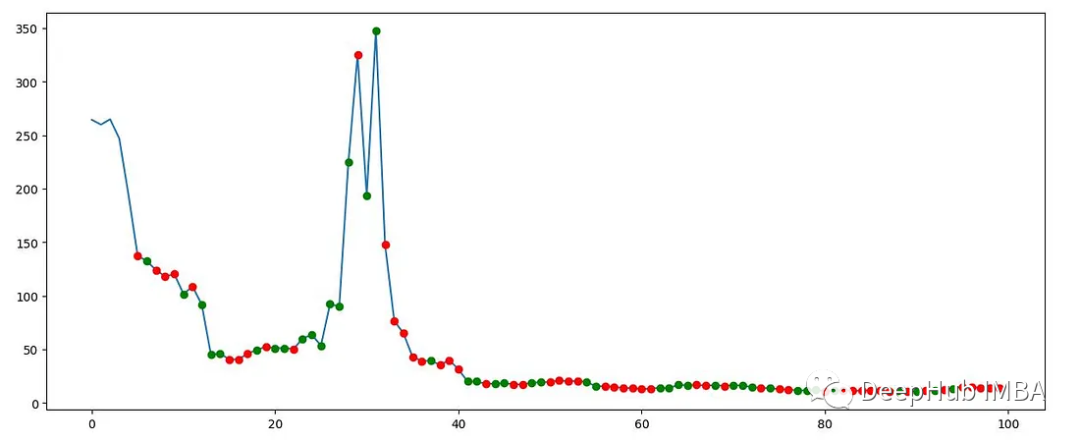
在继续构建RL模型之前,可以先对环境可视化了解其特征。
# Explore the environment
env.action_space
state = env.reset()
while True:
action = env.action_space.sample()
n_state, reward, done, info = env.step(action)
if done:
print("info", info)
break
plt.figure(figsize=(15, 6))
plt.cla()
env.render_all()
plt.show()
该图显示了GME交易数据的一部分,以及Gym Anytrading环境生成的买入和卖出信号。
构建强化学习模型
我们将使用stable-baselines3库构建RL模型。我们将使用A2C(Advantage Actor-Critic)算法
# Creating our dummy vectorizing environment
env_maker = lambda: gym.make('stocks-v0', df=df, frame_bound=(5, 100), window_size=5)
env = DummyVecEnv([env_maker])
# Initializing and training the A2C model
model = A2C('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=1000000)
评估模型
在训练模型之后,可以评估它在GME交易数据的不同部分上的表现。
# Create a new environment for evaluation
env = gym.make('stocks-v0', df=df, frame_bound=(90, 110), window_size=5)
obs = env.reset()
while True:
obs = obs[np.newaxis, ...]
action, _states = model.predict(obs)
obs, rewards, done, info = env.step(action)
if done:
print("info", info)
break
plt.figure(figsize=(15, 6))
plt.cla()
env.render_all()
plt.show()
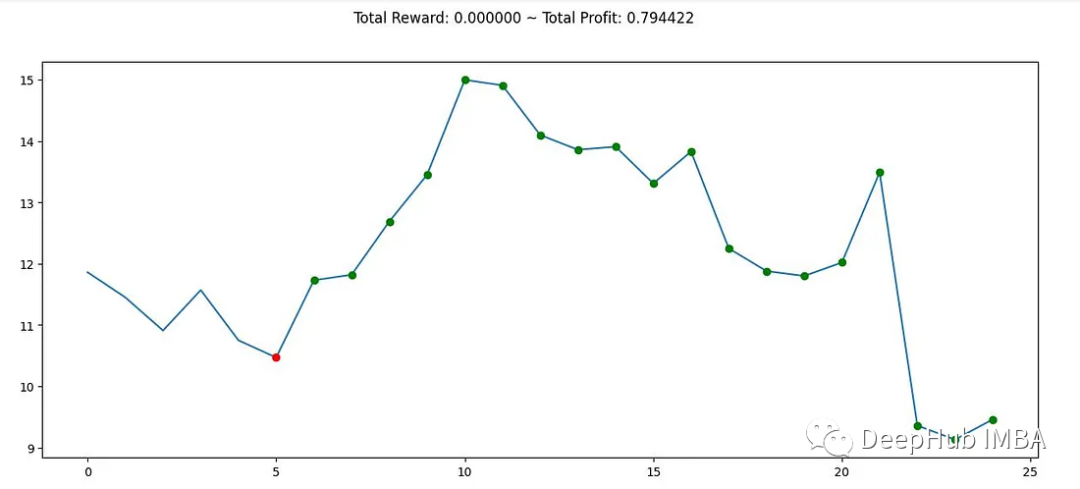
总结
在这篇文章中,我们介绍了如何使用Gym Anytrading环境和stable-baselines3库来构建一个基于强化学习的交易机器人。本文只是一个起点,构建一个成功的交易机器人需要仔细考虑各种因素并不断改进。
https://avoid.overfit.cn/post/77466ba1f1d34ccca01aa4096c0cf8d7
作者:Kabila MD Musa




![[JVM]String str1 = new String(“yhz“)和 String str2 = “yhz“ 的区别](https://img-blog.csdnimg.cn/18ba6ce386984c00ae4e8f5197e5c3e0.png)