快速排序,简称快排。其实看快速排序的名字就知道它肯定是一个很牛的排序,C语言中的qsort和C++中的sort底层都是快排。
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
目录
快排的单趟排序
1. hoare版本
2. 挖坑法
3. 前后指针版本
快排的递归实现
快排的非递归实现
快排的优化
1.随机选数
2.三数取中
3.小区间优化
4.三路并排
快排基本思想:
- 1.先从数列中取出一个数作为基准数。
- 2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 3.再对左右区间重复第二步,直到各区间只有一个数或者这个区间不存在。
动图演示:

将区间按照基准值划分为左右两半部分的常见方式有:
1. hoare版本
2. 挖坑法
3. 前后指针版本
单趟排序后的目标:左边的值比key要小,右边的值比key要大。
快排的单趟排序
1. hoare版本

hoare版本时,如果我们选择最左边的值做key,一定要让右边的指针先走,如果我们选择最右边的值做key,一定要让左边的指针先走,这是为了保证左右指针相遇时指向的值比key小,最后把相遇的值和key值交换,达到单趟排序的目的。
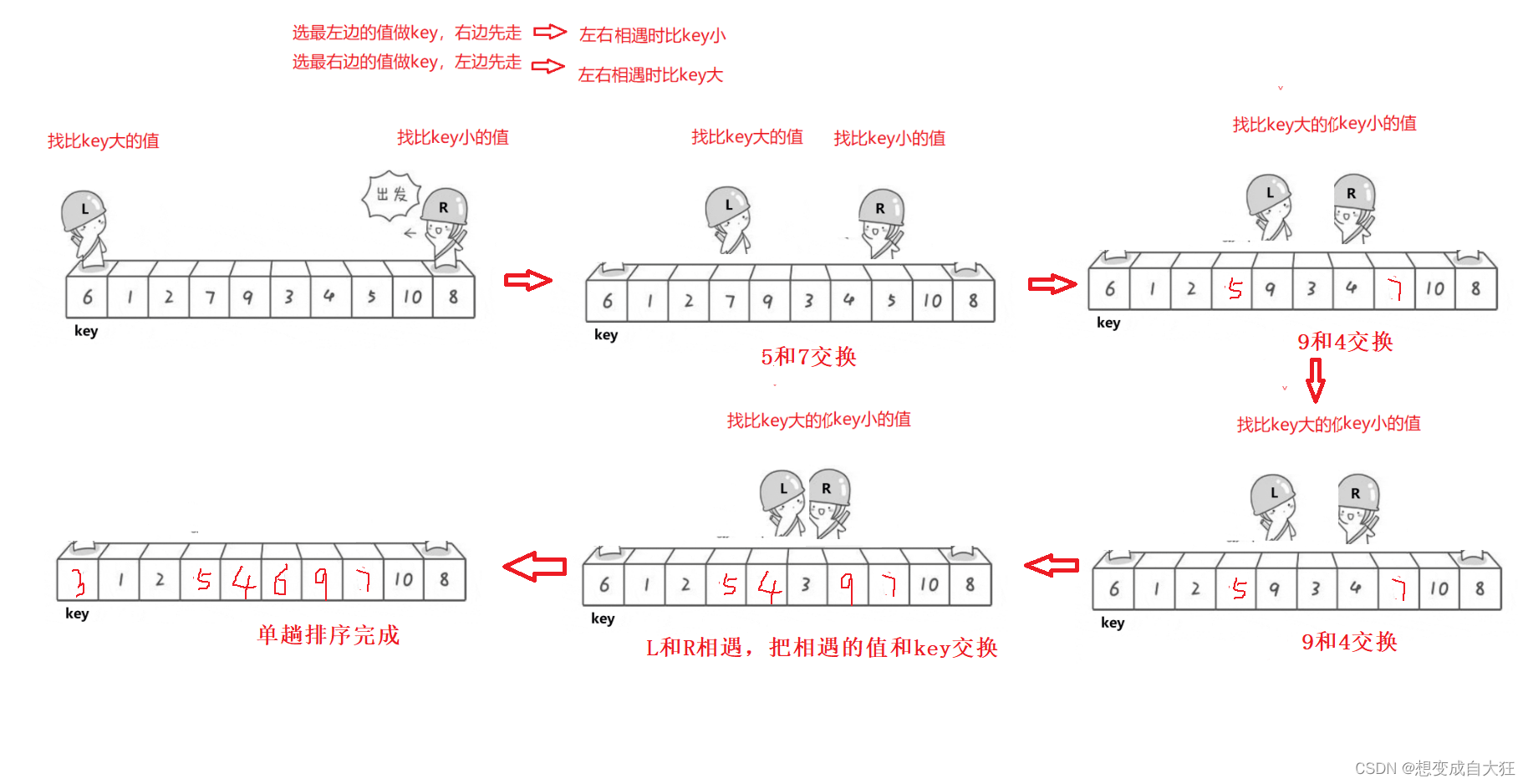
左右指针指向的值和key做比较时要加上等于,如果不加等于,当数组里都是同一个数时,会陷入死循环。
代码:
int Partion(int* a,int left,int right)
{
int keyi = left;
while (left < right)
{
//右边先走,找小
//防止特殊情况,保证left<right,防止越界
while (left < right && a[right] >= a[keyi])
right--;
//左边再走,找大
while (left < right && a[left] <= a[keyi])
left++;
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
keyi = left;
return keyi;
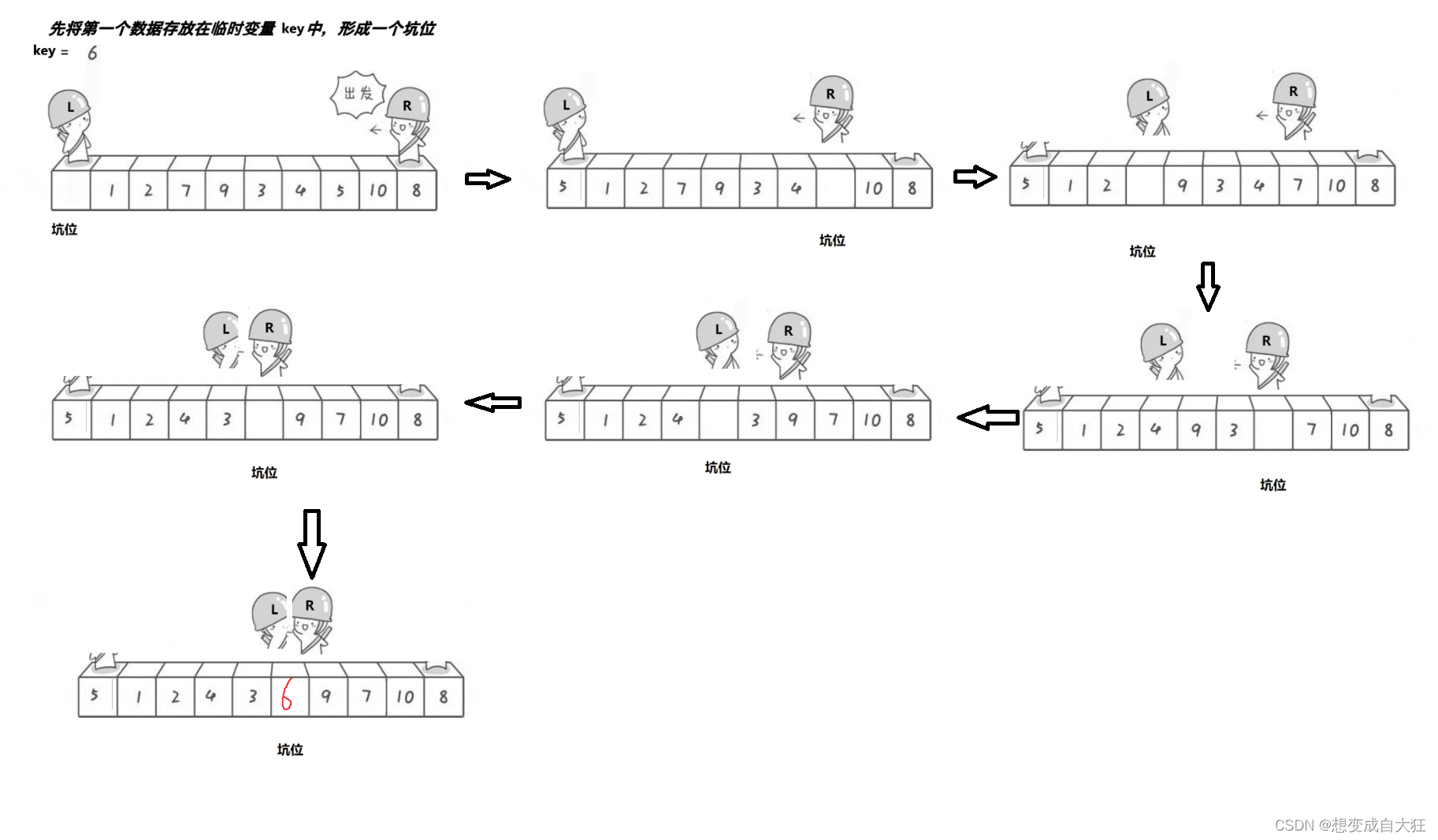
}2. 挖坑法

1.begin =L; end = R; 将key挖出形成第一个坑a[begin]。
2.end--由后向前找比key小的数,找到后挖出此数填前一个坑a[begin]中,此数的位置变成新的坑位。
3.begin++由前向后找比key大的数,找到后也挖出此数填到前一个坑a[end]中,此数的位置变成新的坑位。
4.再重复执行2,3二步,直到begin ==end ,将基准数填入a[begin]中。
代码:
// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{
int keyi = a[left];
int hole = left;
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end && a[end] >= a[keyi])
end--;
a[hole] = a[end];
hole = end;
while (begin < end && a[begin] <= keyi)
begin++;
a[hole] = a[begin];
hole = begin;
}
a[hole] = keyi;
return hole;
}3. 前后指针版本

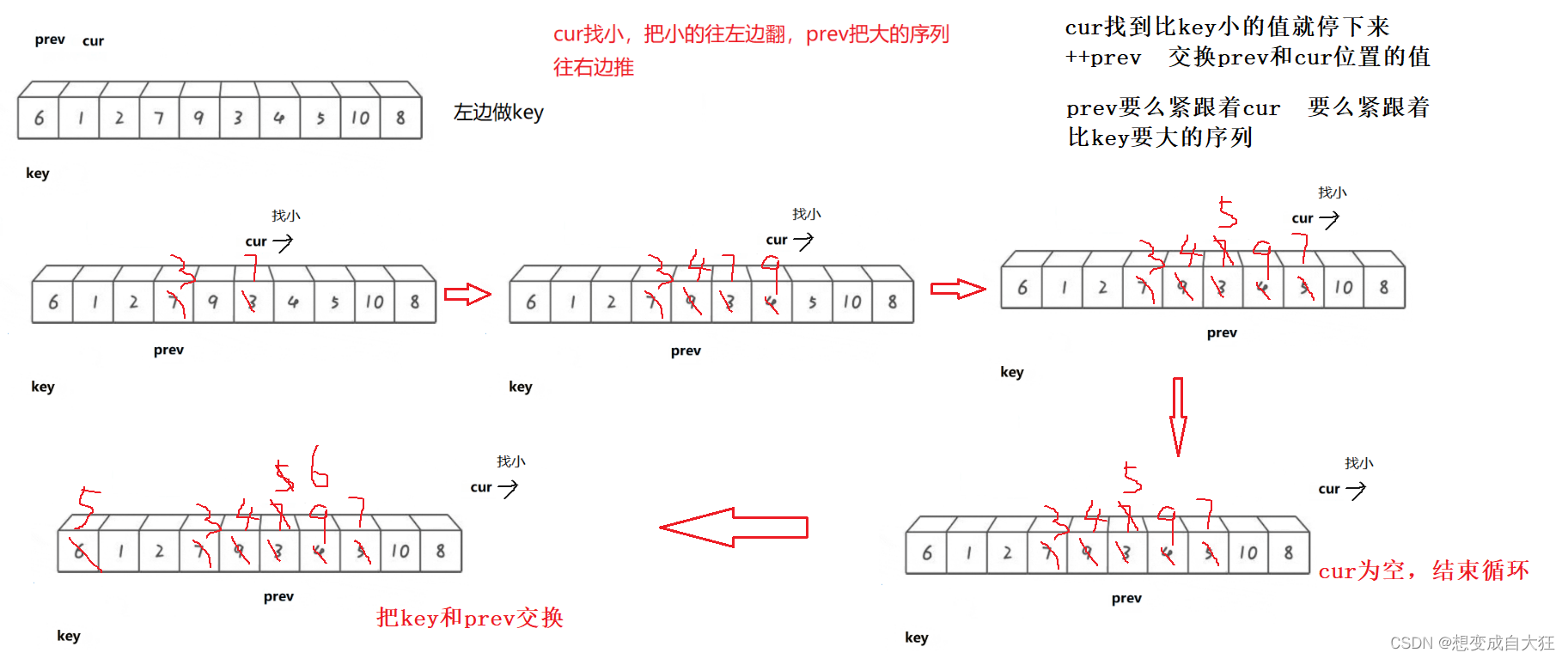
快速排序的前后指针法相比于Hoare版和挖坑版在思路上有点不同,前后指针版的思路是引入两个指针cur和prev(待排序数的下标),在开始的时候先规定一个基准值key(一般为最右边或者最左边的那个数据),然后让两个指针指向key的下一个数(也可以prev指向),开始下面循环: 若cur指向的内容小于key,则prev先向后移动一位,然后交换prev和cur指向的数,然后cur++;如果cur指向的内容大于key,则cur++。
可以选取最左边的值或者最右边的值做key,但是要注意一些细节性的问题,最左边做key,结束的时候直接将key和prev的值交换,最右边做key,结束的时候需要把prev++,再将key和prev的值交换。
最左边的值做key示意图:
代码:
// 快速排序前后指针法
int PartSort3(int* a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && a[++prev] != a[cur])
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}快排的递归实现
快排的递归思想类似于二叉树的前序遍历。
代码:
void QuickSort(int* a, int left, int right)
{
//结束条件:当区间只有一个数或者区间不存在
if (left >= right)
return;
int keyi = PartSort1(a, left, right);
//int keyi = PartSort2(a, left, right);
//int keyi = PartSort3(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}快排的非递归实现
计算机在实现递归时会调用系统的堆栈,这很消耗计算机内存资源,所以采用非递归算法的本质就是手动模拟系统的堆栈调用来降低computer资源的消耗。
基本思路:
1.对原数组进行一次划分,分别将最左边的元素下标和最右边的元素下标入栈 stack。
2.判断 stack 是否为空,若是,直接结束;若不是,将栈顶元素下标取出,进行一次划分。
3.判断左边的元素长度(这里指 right - left + 1)大于 1,将左边的元素下标入栈;同理,右边的元素下标。
4.循环步骤 2、3。
用C语言实现非递归的快排需要自己实现栈,用C++可以直接使用自带的栈。
C语言代码(栈需要自己实现):
void QuickSortRon(int* a, int left, int right)
{
ST st;
StackInit(&st);
StackPush(&st,left);
StackPush(&st, right);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
int keyi = Partion1(a, begin, end);
//int keyi = Partion2(a, begin, end);
//int keyi = Partion3(a, begin, end);
//[left, keyi - 1] keyi [keyi + 1, right]
if (keyi + 1 < end)
{
StackPush(&st, keyi + 1);
StackPush(&st, end);
}
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
}
StackDestroy(&st);
}C++代码:
#include <iostream>
#include <stack>
using namespace std;
void QuickSortRon(int* a, int left, int right)
{
//手动利用栈来存储每次分块快排的起始点
//栈非空时循环获取中轴入栈
stack<int> s;
if (left < right)
{
int keyi = PartSort1(a, left, right);
if (keyi - 1 > left) //确保左分区存在
{
//将左分区端点入栈
s.push(left);
s.push(keyi - 1);
}
if (keyi + 1 < right) //确保右分区存在
{
s.push(keyi + 1);
s.push(right);
}
while (!s.empty())
{
//得到某分区的左右边界
int end = s.top();
s.pop();
int begin = s.top();
s.pop();
keyi = PartSort1(a, begin, end);
if (keyi - 1 > begin) //确保左分区存在
{
//将左分区端点入栈
s.push(begin);
s.push(keyi - 1);
}
if (keyi + 1 < end) //确保右分区存在
{
s.push(keyi + 1);
s.push(end);
}
}
}
}快排的优化
上述选key值的方法都存在一定的缺陷:
当选到的key值都是中位数,快排效率最好,类似于二分。当选到的key值都是最大或最小值,快排效率会很慢。快排的递归调用会创建函数栈帧,递归层数太多,可能会栈溢出。
1.随机选数
int key = left + rand() % (left + right);2.三数取中
选取左边,中间,右边,既不是最大,也不是最小的那个数做key。(面对最坏的情况,选中位数做key,变成最好的情况)
int GetMidIndex(int* a, int left, int right)
{
//int mid = (left + right) / 2;
int mid = left + ((right - left) >> 1);
if (a[left] > a[mid])
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
else//arr[left] < arr[mid]
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
}3.小区间优化
对于递归的快排小区间优化,当分割到小区间时,不再用递归分割的思路给这段子区间排序,直接使用插入排序,减少递归次数,因为最后几层的递归几乎占了递归的绝大部分。
//递归实现快速排序O(N*logN)
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
return;
//小区间优化,当分割到小区间时,不再用递归分割的思路让这段子区间有序
//对于递归快排,减少递归次数
if (right - left + 1 < 10)//区间可以不确定,保证是比较小的区间就可以了
{
InsertSort(arr + left, right - left + 1);
}
else
{
int keyi = Partion3(arr, left, right);
//[left,keyi] keyi [keyi+1,right]
QuickSort(arr, left, keyi - 1);
QuickSort(arr, keyi + 1, right);
}
}4.三路并排
快排有一个缺陷:当需要排序的数全部相同时,或者大量数据相同时,性能会下降,快排会非常慢,我们可以采用一些方法优化。
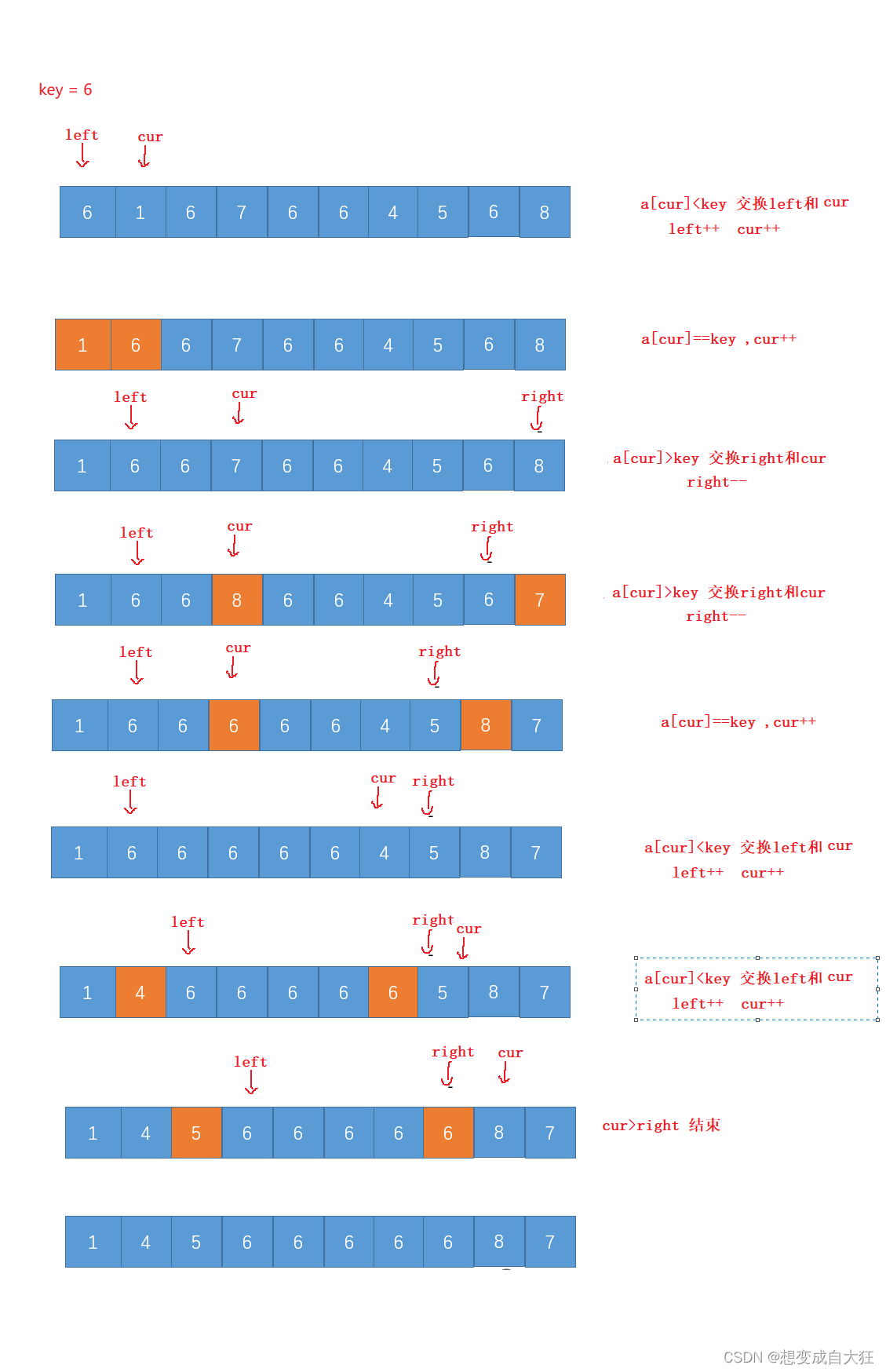
在上述的快排中,我们采用的都是两路并排的方法,即选一个key值,把比key小的值甩到一边,比key大的值甩到一边。为了优化排序的数全部相同或者大部分相同这些情况,我们采用三路并排,即将比key小的值甩到左边,比key大的值甩到右边,和key相等的值放到中间。

1.a[cur]<key 交换left和cur
2.a[cur]==key ,cur++ ,保证等于key的值在中间
3.a[cur]>key 交换right和cur
 代码:
代码:
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
if ((right - left + 1) < 15)
{
//小区间使用直接插入,减少递归次数
InsertSort(a + left, right - left + 1);
}
else
{
//三数取中
int mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[mid]);
int begin = left, end = right;
int key = a[begin];
int cur = begin + 1;
while (cur <= end)
{
if (a[cur] < key)
{
Swap(&a[begin], &a[cur]);
cur++;
begin++;
}
else if (a[cur] > key)
{
Swap(&a[end], &a[cur]);
end--;
}
else //a[cur]==key
{
cur++;
}
}
QuickSort(a, left, end - 1);
QuickSort(a, end + 1, right);
}
}