Pytorch 数据处理
要点总结
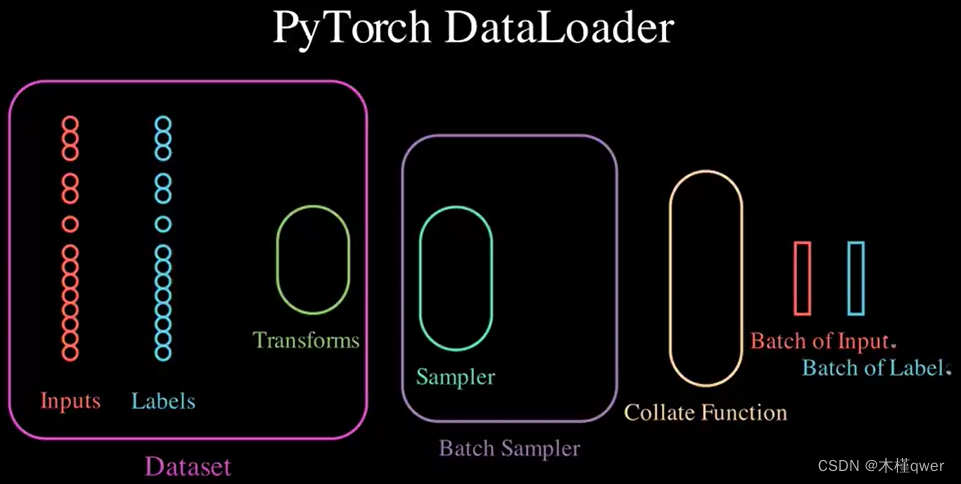
1、功能
Dataset:准备数据集,一般会针对自己的数据集格式重写Dataset,定义数据输入输出格式
Dataloader:用于加载数据,通常不用改这部分内容2、看代码时请关注
Dataloader中collate_fn 传入的参数,这个参数是 数据以 batch 堆叠的列表
Dataset中getitem对原始数据的处理方式
这份笔记不完善,还需要学习加深(TBD)
举例
train_dataset = CenternetDataset(train_lines, input_shape, num_classes, train = True)
gen = DataLoader(train_dataset, shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,drop_last=True, collate_fn=centernet_dataset_collate, sampler=train_sampler)
1、DataLoader
1.1 collate-fn的功能
pytorch中collate_fn函数的使用&如何向collate_fn函数传参 ⭐⭐(这篇博文总结到位!)
dataloader取数据的index,进入dataset的getitem确定读取数据具体内容,然后回到dataloader进行数据堆叠生成batch。(个人理解,不一定准确)

collate_fn用法
collate_fn的用处:
自定义数据堆叠过程
自定义batch数据的输出形式
collate_fn的使用
定义一个以data为输入的函数
输入输出分别与getitem函数和loader调用时对应
——理解不通透,不过没关系,现在至少加深理解多一分了!!!

1.2 可视化加深理解
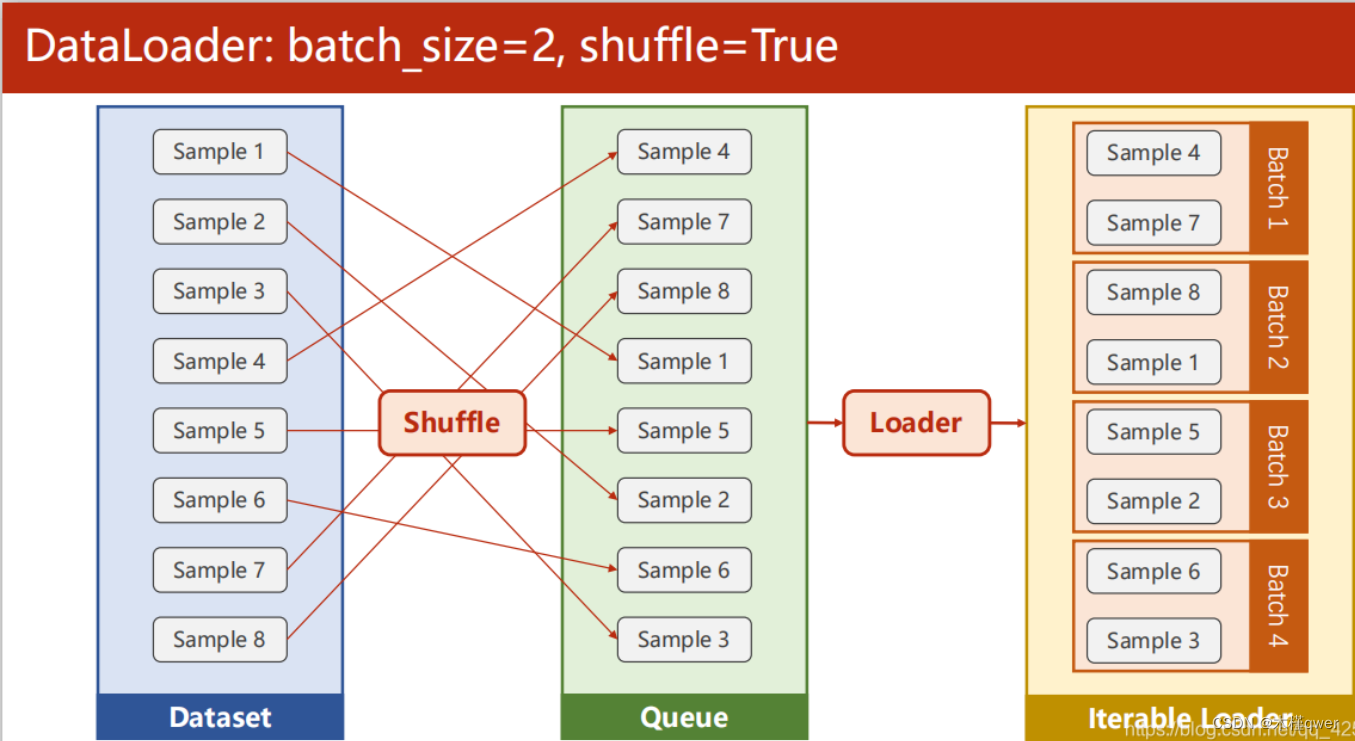
PyTorch DataLoader工作原理可视化 ⭐
数据加载的形象过程
如何 shuffle 和 loader
以下内容不然懂
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
Dataset中使用transforms
import torchvision.transforms as transforms
self.to_tensor = transforms.ToTensor() # ?









![[论文解析] Denoising Diffusion Probabilistic Models](https://img-blog.csdnimg.cn/dd53db2dd7de4af4bec697fc5b23e36f.png)