深度学习(30)—— DeformableDETR(1)
原本想在一篇文章中就把理论和debug的过程都呈现,但是发现内容很多,所以就分开两篇,照常先记录理论学习过程,然后是实践过程。
注:大家一定不要看过理论就完事儿了,去扣代码,看人家怎么完成的?也学学大佬们的代码习惯,好吧。别把代码写得像屎一样。对自己对别人都好,尤其是那些变量名不要随便起,每一个咱都是有意义的,好吧!这一点基本咱还是养成吧!
文章目录
- 深度学习(30)—— DeformableDETR(1)
- 1. DETR的优缺点
- 1.1 优点
- 1.2 缺点
- 2. DeformableDETR拟解决问题
- 3. 核心block
- 3.1 Deformable attention module
- 3.2 Multi-scale Deformable Attention Module
- 3.3 Deformable Transformer Encoder
- 3.4 Deformable Transformer Decoder
- 4. 适用场景
【paper】点击自取
1. DETR的优缺点
1.1 优点
作为一种基于transformer的目标检测算法,DETR相比传统的基于区域的方法的优点是:
- 端到端的训练:DETR采用完全端到端的训练方式,不需要使用额外的候选框生成和选择算法,简化了目标检测流程并提高了效率。
- 不受先验知识限制:DETR不依赖于先验知识,如anchor或proposal,能够自动从数据中学习目标的位置和类别信息,更加灵活。
- 多任务学习:DETR可以同时进行物体检测和物体关联任务,通过在解码器中引入匹配损失函数,实现了全局感知和关联建模。
- 可解释性强:由于采用了Transformer的自注意力机制,DETR生成的目标位置是可解释的,每个位置处都对应一个类别和一个边界框。
1.2 缺点
- 训练时间较长:DETR的训练时间通常比传统的基于区域提议的方法要长,因为它需要更多的计算资源和更大规模的数据集来训练Transformer模型。
- 对小目标检测不够准确:DETR在处理小目标时容易出现检测不准确的问题,这可能是由于Transformer模型在处理小尺度信息时存在困难所导致的。
- 对密集目标的处理较差:DETR对于密集目标的检测效果相对较差,因为它没有显式地建模目标之间的重叠关系,而是通过注意力机制来实现目标关联。
2. DeformableDETR拟解决问题
为了解决DETR的KnowledgeGap,deformableDETR使用了以下方法:
- Deformable Attention Module:可变性注意力机制,不需要考虑全部的点,选择与其相关性强的点进行计算【reference point】,可以极大减少运算时间,提高模型效率。
- Multi-scale Deformable Attention Module:这个模块考虑多尺度特征图可以提高小目标检测的精度
3. 核心block
- transformer可以学习特征之间的关系,但是attention权重在开始的时候都是一个水平线上的,一起学习
- 可变性卷积可以有效的提取更鲜明特征,突出有特点的特征,但是他无法学习重要特征之间的关系
- 将可变性卷积和transformer结合【可变性注意力机制】发扬光大~
3.1 Deformable attention module
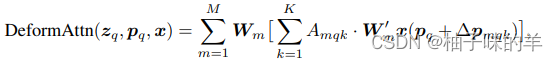
核心公式 其中m表示多头的head个数,k表示一个reference point采样的点,代码中设置为4,图中展示的是三个点。下面的举例我按照图解释,那么怎么做的呢?
- 首先对于reference point 【p】,先使用特征图x连接一个linear层得到与这个点相关性更强周围其他的三个点(k的个数)
- query这个特征连接linear得到reference point三个点的相对于其本身的3个key的偏移量(2维,x和y)
- query特征连接linear得到这三个点与reference point的重要程度(类似于attention权重)
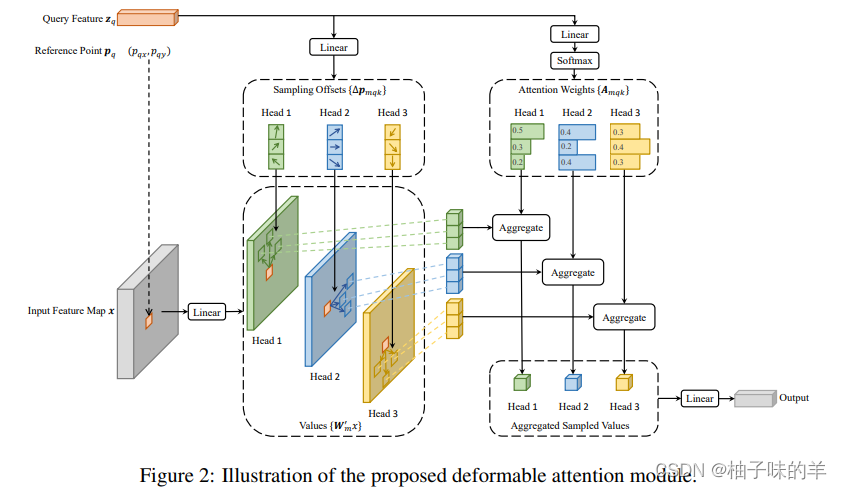
相较于以前:以前每个点都要与特征图上所有的点计算重要程度,得到相关性的权重。现在每个点只需要和与其相关的k(=3)个点计算
3.2 Multi-scale Deformable Attention Module
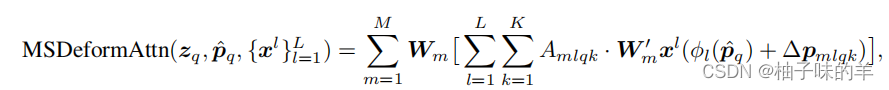
其实这里和前面的DeformableAttention Module类似,只是多了level的加成,既然要把不同level的特征做加和就难免需要考虑一个问题:如何将这些特征对齐?——只需要将reference point和他的key每个特征图上的位置做归一化,都在0-1的范围内,即可对齐。
3.3 Deformable Transformer Encoder
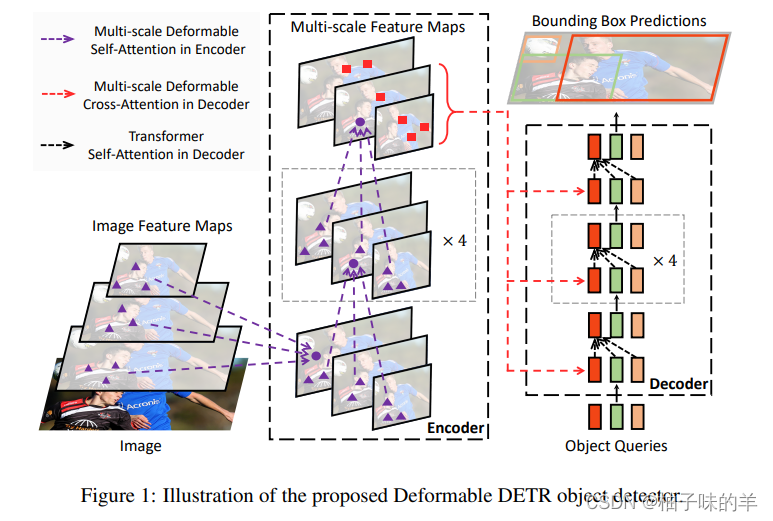
将DETR中的transformer attention机制全部替换成multi-scale deformable attention block。在encoder,分别从resnet的stage3-stage5学习到的特征,最小的特征图是stage5的一个卷积得到的。面对这种从上到下的结构没有使用FPN,使用multi-scale deformable attention block可以学习到不同分辨率特征的信息。在encoder的过程中这些特征要embedding,因为在不同的层级,所以作者不止使用position_embedding 而且增加了level_embedding。【level_embedding是可学习的!!!】
3.4 Deformable Transformer Decoder
在decoder中既有self-attention又有cross-attention。和DETR一样在这两个过程中都需要object query,与DETR不同,DETR初始化100个,Deformable DETR初始化300个。在cross-attention中,object query 用于提取学习从encoder学习的特征,即encoder学习的特征作为key。在self-attention中,就是object query自身进行
4. 适用场景
- 复杂场景下的目标检测:DeformableDETR能够处理不规则形状的目标,因此适用于复杂场景下的目标检测任务。
- 对细粒度特征要求较高的目标检测,DeformableDETR能够获得更准确和细节的特征表示,适用于对细粒度特征建模要求较高的目标检测任务。
886,我晚上梳理一下代码,明天出代码篇~