目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- Tensorflow 环境
- PyCharm环境
- 模块实现
- 古诗生成
- 1. 数据预处理
- 2. 模型构建
- 3. 模型训练及保存
- 4. 使用模型生成古诗
- 5. 产生藏头诗
- 6. 用词云展示生成的古诗
- 歌词生成
- 1. 数据预处理
- 2. 模型构建
- 3. 模型训练并保存
- 4. 生成歌词
- 系统测试
- 1. 生成古诗和藏头诗
- 2. 生成歌词
- 工程源代码下载
- 其它资料下载

前言
本项目以循环神经网络为基础,构建了多层RNN模型。通过对数据集进行训练,并对模型和数据集进行调整,实现了生成藏头诗与歌词的功能。
在这个项目中,我们使用了循环神经网络(RNN)作为模型的基础。RNN是一种能够处理序列数据的神经网络,它在处理文本和语音等序列数据方面表现出色。
我们构建了多层RNN模型,这意味着我们堆叠了多个RNN层以增强模型的表达能力。多层RNN模型可以更好地捕捉数据中的复杂关系和上下文信息。
通过对数据集进行训练,我们让模型学习到了不同类型的藏头诗和歌词。经过调整模型和数据集,我们进一步提高了生成的藏头诗和歌词的质量和多样性。
最终,我们的模型可以接受用户输入的藏头信息,并生成具有相应的藏头诗,或者根据用户提供的歌词开头生成完整的歌词。通过这个项目,我们可以创造出富有创意和感情的文本作品,为用户带来更多的艺术体验和乐趣。
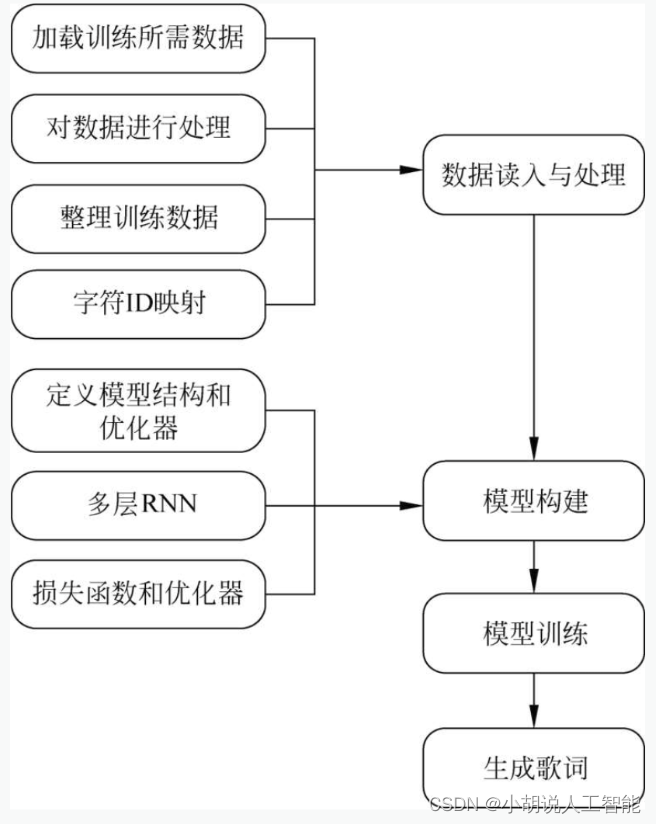
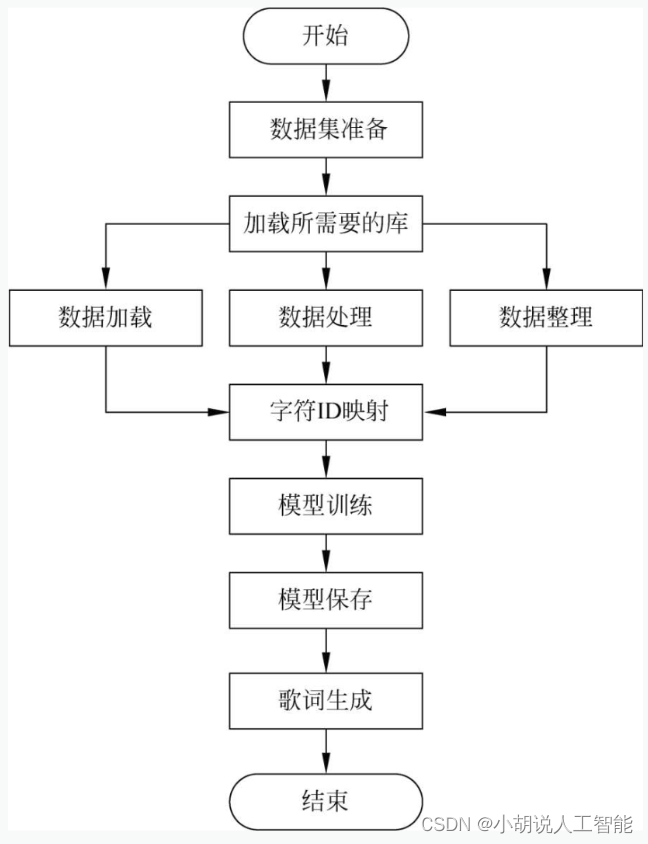
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如下两图所示。
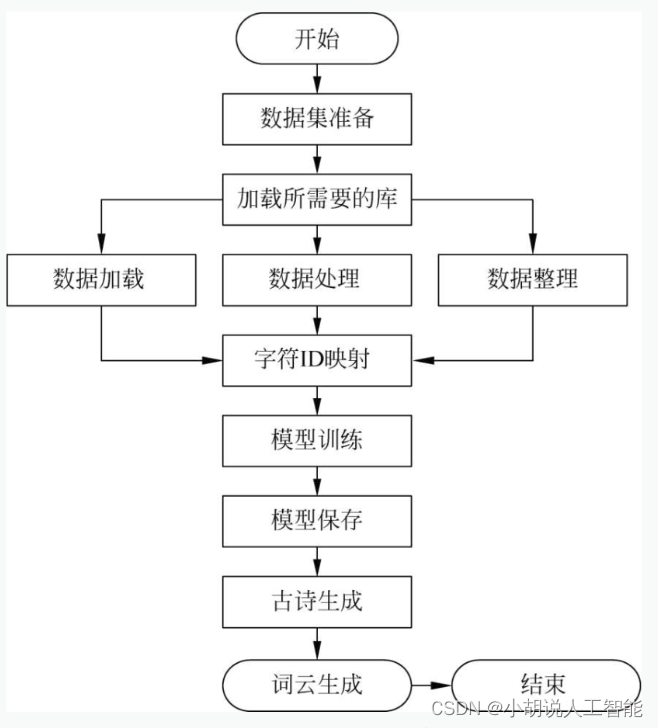
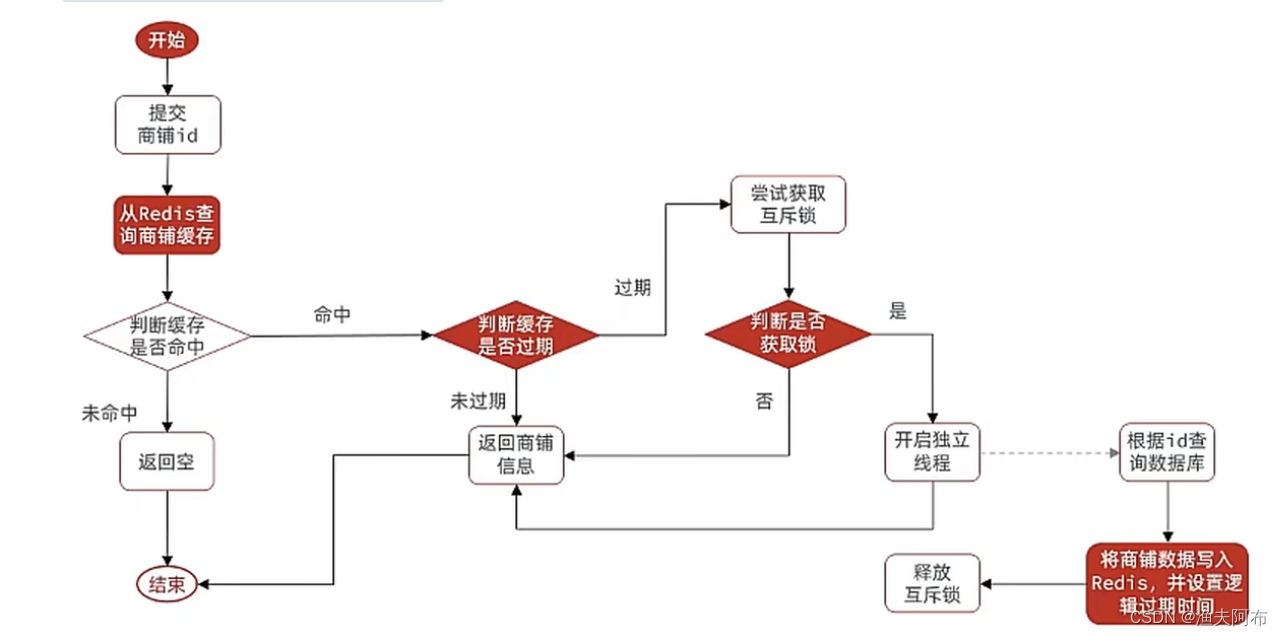
系统流程图
系统流程如下两图所示。
运行环境
本部分包括 Python 环境、Tensorflow环境和Pycharm 环境。
Python 环境
基于Python 3.7.3,在PyCharm环境下进行开发。
Tensorflow 环境
打开Anaconda Prompt,输入清华仓库镜像:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
创建Python 3.7环境,名称为TensorFlow。此时Python版本和后面TensorFlow的版本存在匹配问题,此步选择Python3.x。
conda create -n tensorflow python==3.7
有需要确认的地方,都按Y键。
在Anaconda Prompt中激活TensorFlow环境:
conda activate tensorflow
安装CPU版本的TensorFlow:
pip install -upgrade --ignore -installed tensorflow
安装完毕。
PyCharm环境
IDE为PyCharm,任何版本均可。
模块实现
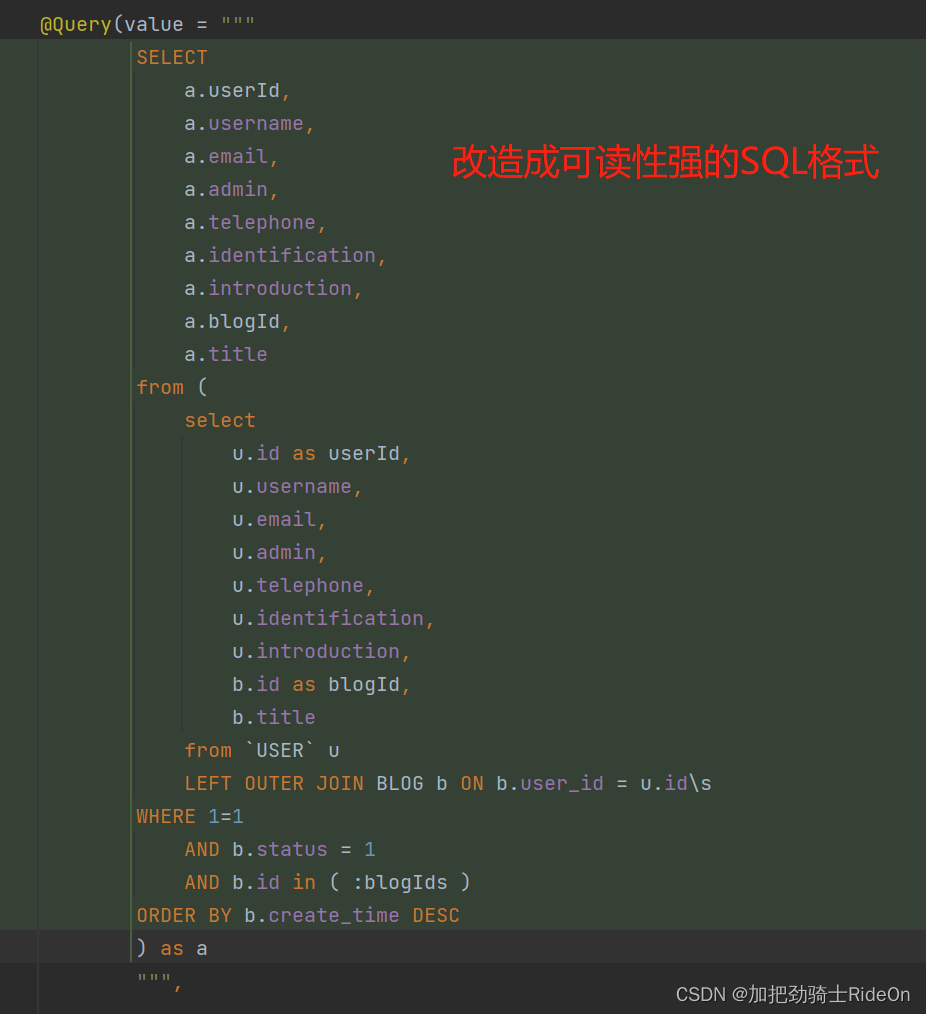
本项目由古诗生成和歌词生成两部分组成。古诗生成由数据预处理、模型构建、模型训练及保存、使用模型生成古诗、产生藏头诗和用词云展示模块组成,下面分别介绍各模块的功能及相关代码。
古诗生成
1. 数据预处理
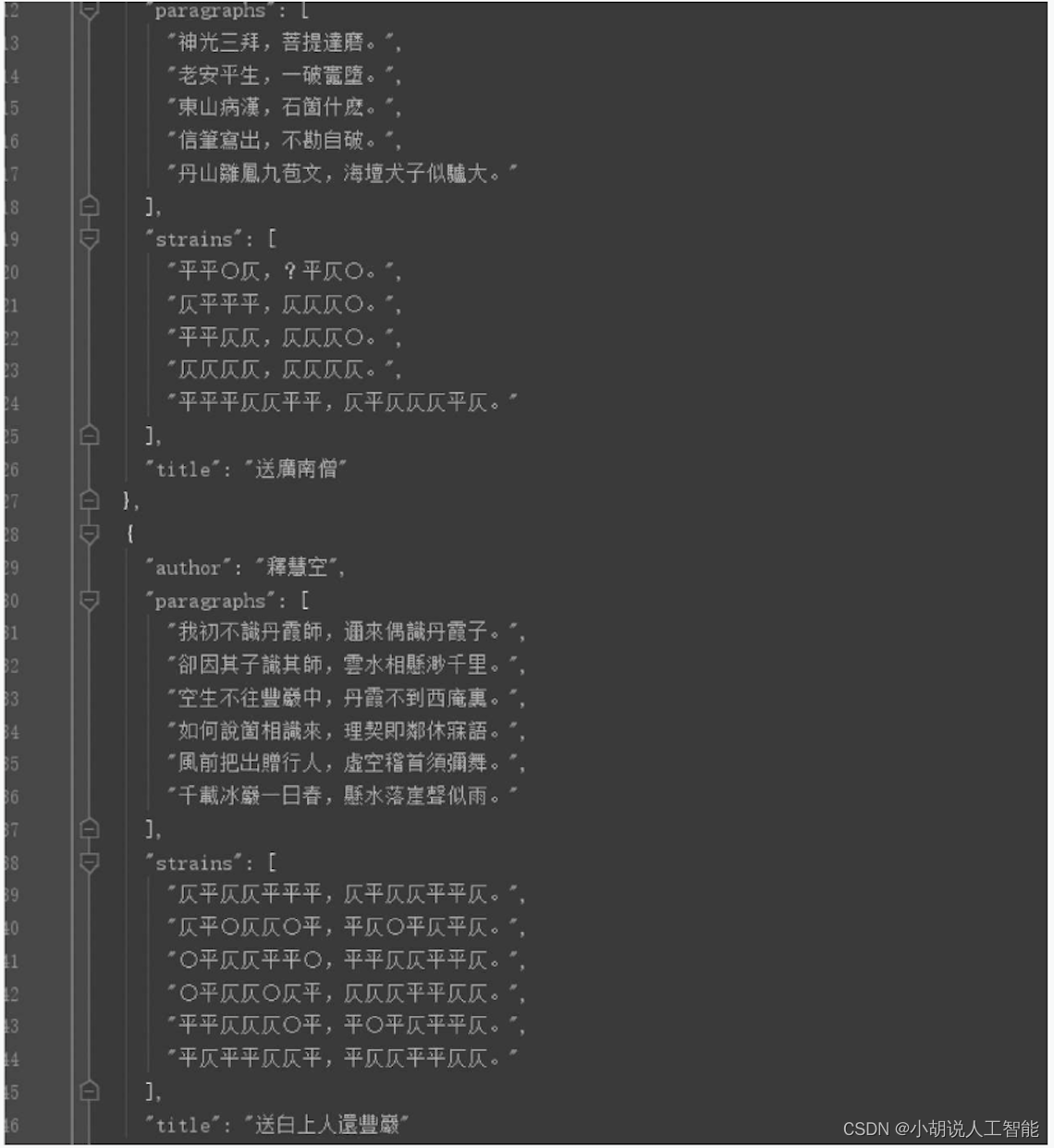
本部分包括加载所需要的库与数据、数据处理和整理训练数据。下载地址为https://github.com/chinese-poetry/chinese-poetry。
1)加载库与数据
相关代码如下:
import tensorflow as tf
import numpy as np
import glob
import json
from collections import Counter
from tqdm import tqdm
from snownlp import SnowNLP #主要做繁体字转简体字
poets = []
paths = glob.glob('chinese-poetry/json/poet.*.json') #加载数据
训练古诗数据的具体样式,如下图所示。
2)数据处理
相关代码如下:
for path in paths: #对每一个json文件
data = open(path, 'r').read() #将它读取
data = json.loads(data) #将字符串加载成字典
for item in data: #对每一项
content = ''.join(item['paragraphs']) #将正文取出拼接到一起
if len(content) >= 24 and len(content) <= 32: #取长度合适的诗
content = SnowNLP(content)
poets.append('[' + content.han + ']') #如果是繁体转为简体
poets.sort(key=lambda x: len(x)) #按照诗的长度排序
3)整理数据
相关代码如下:
batch_size = 64
X_data = []
Y_data = []
for b in range(len(poets) // batch_size): #分批次
start = b * batch_size #开始位置
end = b * batch_size + batch_size #结束位置
batch = [[char2id[c] for c in poets[i]] for i in range(start, end)]
#两层循环每首诗的每个字转换成序列再迭代
maxlen = max(map(len, batch))#当前最长的诗为多少字
X_batch = np.full((batch_size, maxlen - 1), 0, np.int32) #用零进行填充
Y_batch = np.full((batch_size, maxlen - 1), 0, np.int32) #用零进行填充
for i in range(batch_size):
X_batch[i, :len(batch[i]) - 1] = batch[i][:-1] #每首诗最后一个字不要
Y_batch[i, :len(batch[i]) - 1] = batch[i][1:] #每首诗第一个字不要
X_data.append(X_batch)
Y_data.append(Y_batch)
#整理字符与ID之间的映射
chars = []
for item in poets:
chars += [c for c in item]
chars = sorted(Counter(chars).items(), key=lambda x:x[1], reverse=True)
print('共%d个不同的字' % len(chars))
print(chars[:10])
#空位为了特殊字符
chars = [c[0] for c in chars]#对于每一个字
char2id = {c: i + 1 for i, c in enumerate(chars)} #构造字符与ID的映射
id2char = {i + 1: c for i, c in enumerate(chars)} #构造ID与字符的映射
2. 模型构建
数据加载进模型之后,需要定义模型结构、使用多层RNN、定义损失函数和优化器。
1)定义模型结构和优化器
相关代码如下:
hidden_size = 256 #隐藏层大小
num_layer = 2
embedding_size = 256
#进行占位
X = tf.placeholder(tf.int32, [batch_size, None])
Y = tf.placeholder(tf.int32, [batch_size, None])
learning_rate = tf.Variable(0.0, trainable=False) #定义学习率,不可训练
2)使用多层RNN
相关代码如下:
cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(hidden_size, state_is_tuple=True) for i in range(num_layer)],
state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32) #全零初始状态
embeddings = tf.Variable(tf.random_uniform([len(char2id) + 1, embedding_size], -1.0, 1.0))
embedded = tf.nn.embedding_lookup(embeddings, X) #得到嵌入后的结果
outputs, last_states = tf.nn.dynamic_rnn(cell, embedded, initial_state=initial_state)
outputs = tf.reshape(outputs, [-1, hidden_size]) #改变形状
logits = tf.layers.dense(outputs, units=len(char2id) + 1)
logits = tf.reshape(logits, [batch_size, -1, len(char2id) + 1])
probs = tf.nn.softmax(logits) #得到概率
3)定义损失函数和优化器
相关代码如下:
loss = tf.reduce_mean(tf.contrib.seq2seq.sequence_loss(logits, Y, tf.ones_like(Y, dtype=tf.float32))) #求出损失
params = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, params), 5)
#进行梯度截断操作
optimizer = tf.train.AdamOptimizer(learning_rate).apply_gradients(zip(grads, params))
#得到优化器
3. 模型训练及保存
在定义模型架构和编译后,通过训练集训练模型,使模型生成古诗。这里使用训练集和测试集拟合并保存模型。
1)模型训练
相关代码如下:
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(50):
sess.run(tf.assign(learning_rate, 0.002 * (0.97 ** epoch))) #指数衰减
data_index = np.arange(len(X_data))
np.random.shuffle(data_index) #每一轮迭代数据打乱
X_data = [X_data[i] for i in data_index]
Y_data = [Y_data[i] for i in data_index]
losses = []
for i in tqdm(range(len(X_data))):
ls_, _ = sess.run([loss, optimizer],feed_dict={X: X_data[i],Y: Y_data[i]})
losses.append(ls_)
2)模型保存
相关代码如下:
saver = tf.train.Saver()
saver.save(sess, './poet_generation_tensorflow')
import pickle
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char], fw) #保存成一个pickle文件
模型被保存后,可以被重用,也可以移植到其他环境中使用。
4. 使用模型生成古诗
本部分包括加载资源、重新定义网络、使用多层RNN、定义损失函数和优化器、生成古诗。
1)加载资源
相关代码如下:
import tensorflow as tf
import numpy as np
import pickle
#加载模型
with open('dictionary.pkl', 'rb') as fr:
[char2id, id2char] = pickle.load(fr)
2)重新定义网络
相关代码如下:
batch_size = 1
hidden_size = 256 #隐藏层大小
num_layer = 2
embedding_size = 256
#占位操作
X = tf.placeholder(tf.int32, [batch_size, None])
Y = tf.placeholder(tf.int32, [batch_size, None])
learning_rate = tf.Variable(0.0, trainable=False)
3)使用多层RNN
相关代码如下:
cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(hidden_size, state_is_tuple=True) for i in range(num_layer)],
state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32) #初始化
embeddings = tf.Variable(tf.random_uniform([len(char2id) + 1, embedding_size], -1.0, 1.0))
embedded = tf.nn.embedding_lookup(embeddings, X)
outputs, last_states = tf.nn.dynamic_rnn(cell, embedded, initial_state=initial_state)
outputs = tf.reshape(outputs, [-1, hidden_size])
logits = tf.layers.dense(outputs, units=len(char2id) + 1)
probs = tf.nn.softmax(logits) #得到概率
targets = tf.reshape(Y, [-1])
4)定义损失函数和优化器
相关代码如下:
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=targets))
params = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, params), 5)
optimizer = tf.train.AdamOptimizer(learning_rate).apply_gradients(zip(grads, params))
sess = tf.Session()
sess.run(tf.global_variables_initializer())#得到初始状态
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('./'))
5)生成古诗
相关代码如下:
def generate():
states_ = sess.run(initial_state)
gen = ''
c = '['
while c != ']'
gen += c
x = np.zeros((batch_size, 1))
x[:, 0] = char2id[c]
probs_, states_ = sess.run([probs, last_states], feed_dict={X: x, initial_state: states_}) #得到状态与概率
probs_ = np.squeeze(probs_) #去掉维度
pos = int(np.searchsorted(np.cumsum(probs_), np.random.rand() * np.sum(probs_))) #根据概率分布产生一个整数
c = id2char[pos]
return gen[1:]
5. 产生藏头诗
相关代码如下:
def generate_with_head(head):
states_ = sess.run(initial_state)
gen = ''
c = '['
i = 0
while c != ']':
gen += c
x = np.zeros((batch_size, 1))
x[:, 0] = char2id[c]
probs_, states_ = sess.run([probs, last_states], feed_dict={X: x, initial_state: states_})
probs_ = np.squeeze(probs_)
pos = int(np.searchsorted(np.cumsum(probs_), np.random.rand() * np.sum(probs_)))
if (c=='[' or c == '。' or c == ',') and i<len(head):
#判断为第一个字的条件
c = head[i]
i += 1
else:
c = id2char[pos]
return gen[1:]
#将结果写入文件中
f=open('guhshiwordcloud.txt','w',encoding='utf-8')
f.write(generate())
f.write(generate_with_head('天地玄黄'))
f.write(generate_with_head('宇宙洪荒'))
f.write(generate_with_head('寒来暑往'))
f.close()
6. 用词云展示生成的古诗
本部分包括加载所需要的库、打开生成的古诗文件、提取关键词和权重、生成对象、从图片中生成需要的颜色、显示词云和保存图片。
1)加载所需要的库
相关操作如下:
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba.analyse
2)打开生成的古诗文件
相关操作如下:
text = open('guhshiwordcloud.txt','r', encoding='UTF-8').read()
3)提取关键词和权重
相关操作如下:
freq = jieba.analyse.extract_tags(text, topK=200, withWeight=True)
#权重控制关键词在词云里面的大小
print(freq[:20])#打印前20个
freq = {i[0]: i[1] for i in freq} #转成字典
4)生成对象
相关操作如下:
mask = np.array(Image.open("color_mask.png")) #以图片为参考
wc = WordCloud(mask=mask, font_path='Hiragino.ttf', mode='RGBA', background_color=None).generate_from_frequencies(freq)
5)从图片中生成需要的颜色
相关操作如下:
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors)
6)显示词云
相关操作如下:
plt.imshow(wc, interpolation='bilinear') #设定插值形式
plt.axis("off") #无坐标轴
plt.show()
7)保存图片
相关操作如下:
wc.to_file('gushiwordcloud.png')
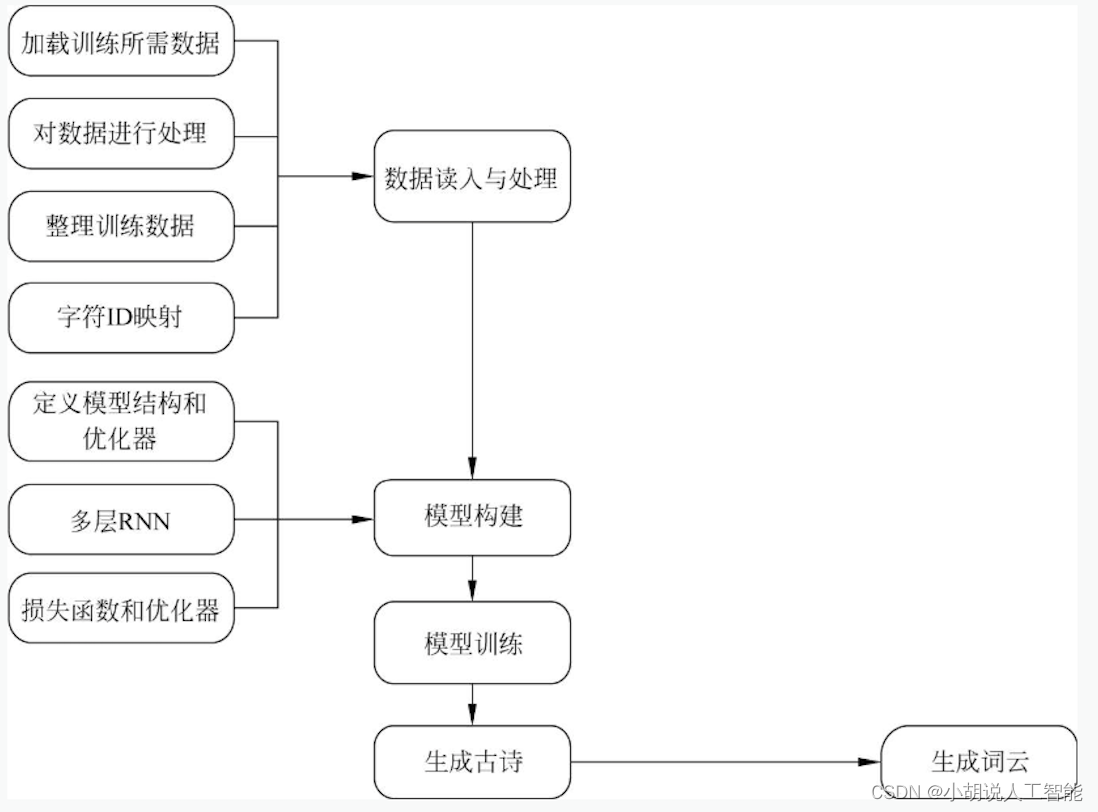
歌词生成
本部分包括数据预处理、模型构建、模型训练并保存、生产歌词,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
相关操作如下:
#首先加载相应的库
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.callbacks import LambdaCallback
import numpy as np
import random
import sys
import pickle
sentences = []
#读取训练所需数据并进行预处理
with open('../lyrics.txt', 'r', encoding='utf8') as fr: #读取歌词文件
lines = fr.readlines() #一行一行读取
for line in lines:
line = line.strip() #去掉空格字符
count = 0
for c in line:
if (c >= 'a' and c <= 'z') or (c >= 'A' and c <= 'Z'):
count += 1 #统计英文字符个数
if count / len(line) < 0.1: #进行筛选
sentences.append(line)
#整理字符和ID之间的映射
chars = {}
for sentence in sentences:
for c in sentence:
chars[c] = chars.get(c, 0) + 1
chars = sorted(chars.items(), key=lambda x:x[1], reverse=True)
chars = [char[0] for char in chars]
vocab_size = len(chars)
char2id = {c: i for i, c in enumerate(chars)}
id2char = {i: c for i, c in enumerate(chars)}
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char], fw)
2. 模型构建
相关操作如下:
maxlen = 10
step = 3
embed_size = 128
hidden_size = 128
vocab_size = len(chars)
batch_size = 64
epochs = 20
X_data = []
Y_data = []
for sentence in sentences:
for i in range(0, len(sentence) - maxlen, step): #每次平移3
#根据前面的字来预测后面一个字
X_data.append([char2id[c] for c in sentence[i: i + maxlen]])
y = np.zeros(vocab_size, dtype=np.bool)
y[char2id[sentence[i + maxlen]]] = 1
Y_data.append(y)
X_data = np.array(X_data)
Y_data = np.array(Y_data)
print(X_data.shape, Y_data.shape)
#定义序列模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_size, input_length=maxlen))
model.add(LSTM(hidden_size, input_shape=(maxlen, embed_size)))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
#定义序列样本生成函数
def sample(preds, diversity=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds + 1e-10) / diversity #取对数
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas) #取最大的值拿到生成的字
#定义每轮训练后的回调函数
def on_epoch_end(epoch, logs):
print('-' * 30)
print('Epoch', epoch)
index = random.randint(0, len(sentences)) #随机选取一句
for diversity in [0.2, 0.5, 1.0]:
print('----- diversity:', diversity)
sentence = sentences[index][:maxlen] #随机选一首歌把前十个字取出
print('----- Generating with seed: ' + sentence)
sys.stdout.write(sentence)
for i in range(400):
x_pred = np.zeros((1, maxlen))
for t, char in enumerate(sentence):
x_pred[0, t] = char2id[char] #把x相应位置的值改为ID
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = id2char[next_index] #把下一个字拿出来
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
3. 模型训练并保存
相关操作如下:
model.fit(X_data, Y_data, batch_size=batch_size, epochs=epochs, callbacks=[LambdaCallback(on_epoch_end=on_epoch_end)])
model.save('song.h5')
4. 生成歌词
下面的代码使用之前生成的模型生成歌词,需要提供一句起始歌词:
#导入所需要的库
from keras.models import load_model
import numpy as np
import pickle
import sys
maxlen = 10
model = load_model('song.h5') #加载使用上一段代码生成的模型
with open('dictionary.pkl', 'rb') as fr: #打开.pkl文件
[char2id, id2char] = pickle.load(fr)
#定义序列样本生成函数
def sample(preds, diversity=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds + 1e-10) / diversity #使用对数
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas) #最大的概率
#提供一句起始歌词
sentence = '天地玄黄宇宙洪荒'
sentence = sentence[:maxlen] #不能超过最大长度
diversity = 1.0
print('----- Generating with seed: ' + sentence)
print('----- diversity:', diversity)
sys.stdout.write(sentence)
for i in range(400): #迭代400次
x_pred = np.zeros((1, maxlen)) #初始化为0
for t, char in enumerate(sentence):
x_pred[0, t] = char2id[char]
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = id2char[next_index] #把下一个字拿出来
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
系统测试
本部分包括生成古诗和藏头诗、生成歌词两部分。
1. 生成古诗和藏头诗
本部分包括训练古诗生成的模型、古诗、藏头诗和词云。
1)训练古诗生成的模型
模型保存在相应文件中,供后续代码使用生成古诗与藏头诗,如图所示。
2)生成古诗
使用前面代码训练保存的模型生成四句七言律诗,如图所示。

3)生成藏头诗
使用前面代码训练保存的模型生成藏头诗,输入“天地玄黄”,结果如图所示。

输入“宇宙洪荒”,结果如图所示。

输入“寒来暑往”,结果如图所示。

4)生成词云
生成一首普通古诗和三首藏头诗并保存在文件中,用来生成词云,如图1-4所示。




2. 生成歌词
模型保存在相应文件中供后续使用。训练生成模型如图5所示,生成歌词结果如图6所示。


工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。









![[MySQL]MySQL用户管理](https://img-blog.csdnimg.cn/img_convert/bc2ec15e195617e2974468e0afd19359.png)