文章目录
- 1各类数据库基本概念
- 1.1关系型数据库(SQL)
- 1.2非关系型数据库(NoSQL)
- 1.3图数据库
- 1.3.1图数据库特点
- 1.3.2图数据库应用场景
- 2图数据库基本概念
- 2.1用户访问菜单
- 2.2节点(用户、角色、菜单)
- 2.3关系(拥有角色、可以访问)
- 2.4属性(节点/关系的属性)
- 2.5呈现效果(用户-角色-菜单)
- 3Neo4j开发工具
- 4Neo4J下载安装
- 4.1安装JDK8/11
- 4.1Neo4j Browser(浏览版)
1各类数据库基本概念
1.1关系型数据库(SQL)
关系型数据库是一种基于关系模型的数据库,它使用表格来存储和管理数据。每个表格都是由一组列和行组成,列表示数据的属性,行表示数据的实例。关系型数据库通常使用 SQL(Structured Query Language)来查询和管理数据。简单一点就是,你能把数据整理成表格的形式,这样的表格形式的数据,就可以称之为关系型数据。最常见的就是我们excel里面的表格,或者word里面的表格
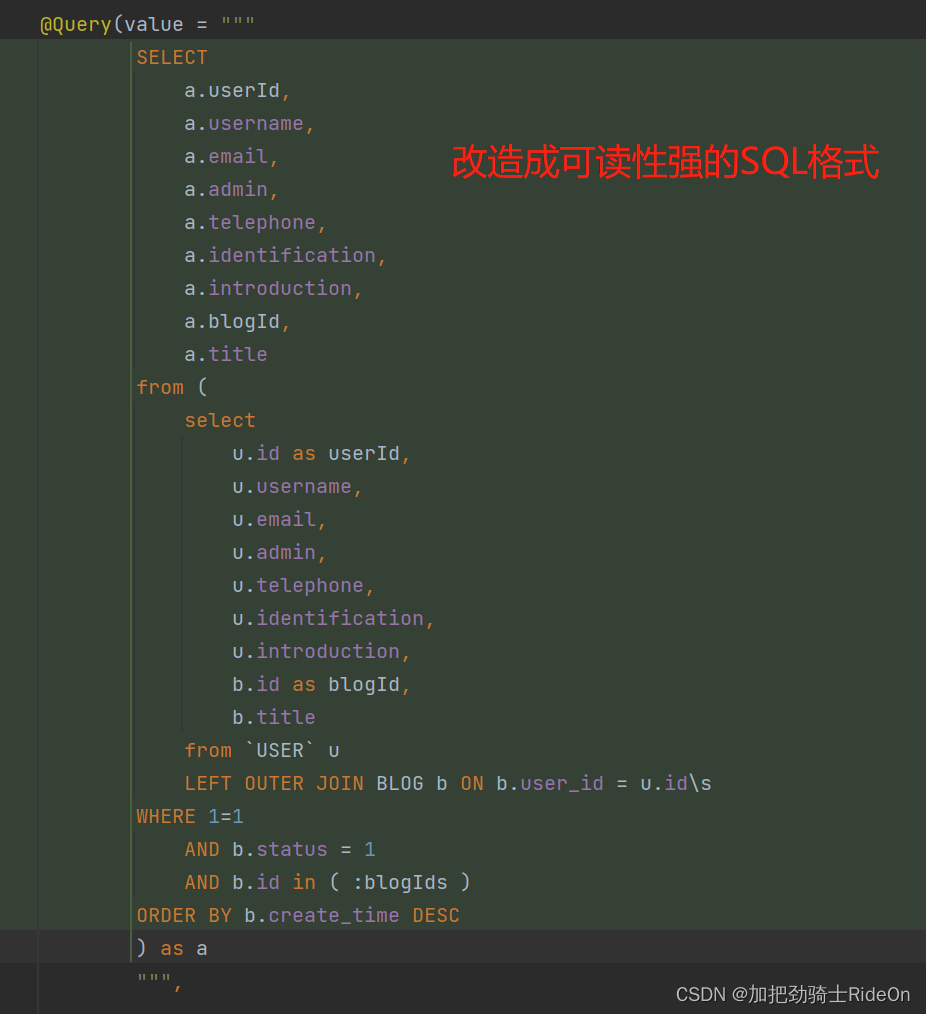
此类数据库都是使用SQL语句来进行管理,例如
select * from userinfo where name = '张三'
常见的关系型数据库有:
@Getter
@AllArgsConstructor
public enum DbType {
MYSQL("mysql", "MySql数据库"),
MARIADB("mariadb", "MariaDB数据库"),
ORACLE("oracle", "Oracle11g及以下数据库(高版本推荐使用ORACLE_NEW)"),
ORACLE_12C("oracle12c", "Oracle12c+数据库"),
DB2("db2", "DB2数据库"),
H2("h2", "H2数据库"),
HSQL("hsql", "HSQL数据库"),
SQLITE("sqlite", "SQLite数据库"),
POSTGRE_SQL("postgresql", "Postgre数据库"),
SQL_SERVER2005("sqlserver2005", "SQLServer2005数据库"),
SQL_SERVER("sqlserver", "SQLServer数据库"),
DM("dm", "达梦数据库"),
XU_GU("xugu", "虚谷数据库"),
KINGBASE_ES("kingbasees", "人大金仓数据库"),
PHOENIX("phoenix", "Phoenix HBase数据库"),
GAUSS("zenith", "Gauss 数据库"),
CLICK_HOUSE("clickhouse", "clickhouse 数据库"),
GBASE("gbase", "南大通用(华库)数据库"),
GBASEDBT("gbasedbt", "南大通用数据库"),
OSCAR("oscar", "神通数据库"),
SYBASE("sybase", "Sybase ASE 数据库"),
OCEAN_BASE("oceanbase", "OceanBase 数据库"),
FIREBIRD("Firebird", "Firebird 数据库"),
HIGH_GO("highgo", "瀚高数据库"),
CUBRID("cubrid", "CUBRID数据库"),
GOLDILOCKS("goldilocks", "GOLDILOCKS数据库"),
CSIIDB("csiidb", "CSIIDB数据库"),
SAP_HANA("hana", "SAP_HANA数据库"),
IMPALA("impala", "impala数据库"),
OTHER("other", "其他数据库");
}
尽管关系型数据库具有很多优点,例如数据结构清晰、数据一致性高、支持 SQL 等,但是也存在一些缺陷,以下是一些常见的缺陷:
- 不适合大数据处理:关系型数据库在处理大规模数据时效率较低,因为它们需要进行多次 JOIN 操作来查询数据,这会导致查询速度变慢。此外,关系型数据库的存储结构也不适合存储非结构化数据,例如图像、视频等。
- 难以扩展:由于关系型数据库的设计初衷是为了处理小规模数据,因此它们的扩展性较差。当需要处理更大规模的数据时,需要使用分布式数据库或者 NoSQL 数据库来解决扩展性问题。
- 繁琐的数据模型设计:关系型数据库需要进行严格的数据模型设计,包括表结构、列定义、键定义等,这需要一定的专业知识和经验。如果设计不当,可能会导致数据冗余、数据不一致等问题。
- 高并发性能问题:在高并发的情况下,关系型数据库的性能可能会受到影响。由于关系型数据库使用锁机制来保证数据的一致性,因此在并发访问量较大的情况下,可能会出现死锁、阻塞等问题。
随着大数据、云计算、物联网等新兴技术的发展,NoSQL 数据库和分布式数据库等新型数据库也逐渐崭露头角,成为了关系型数据库的有力补充。
1.2非关系型数据库(NoSQL)
非关系型数据库(NoSQL)相对于传统的关系型数据库(SQL)具有以下优点,有助于解决关系型数据库的一些短板:
- 可扩展性:NoSQL 数据库可以通过分布式部署来实现水平扩展,可以轻松地处理大规模数据和高并发请求。
- 高性能:由于 NoSQL 数据库采用了不同的数据结构和查询方式,因此在某些场景下具有更高的查询速度和吞吐量,例如在处理大量非结构化数据时。
- 弱一致性:NoSQL 数据库通常采用弱一致性模型,即在不同节点之间可能存在数据不一致的情况,但是可以通过数据复制和容错机制来保证数据的可靠性和可用性。
- 支持多种数据类型:NoSQL 数据库不仅可以存储结构化数据,还可以存储半结构化或非结构化数据,例如文档、键值对、图形数据等。
灵活的数据模型设计:NoSQL 数据库不需要遵循严格的表结构和键值关系,可以根据具体应用场景进行灵活的数据模型设计和调整,更加符合实际的业务需求。
常见的 NoSQL 数据库包括以下几种:
- 文档型数据库:文档型数据库存储的数据是类似于 JSON 格式的半结构化数据,每个文档可以有不同的结构和字段,更加灵活。常用的文档型数据库包括 MongoDB、Couchbase 等。适用于存储半结构化数据,例如日志、用户资料、文本等。
- 键值型数据库:键值型数据库存储的数据是以键值对的形式进行存储和访问的,可以快速地进行读写操作。常用的键值型数据库包括 Redis、Amazon DynamoDB、Riak 等。适用于存储缓存、会话、排行榜、计数器等数据。
- 列族型数据库:列族型数据库采用列族的方式来存储数据,每个列族包含多个列,可以支持动态地添加和删除列,适用于存储大规模的结构化数据。常用的列族型数据库包括 HBase、Cassandra 等。
- 图形数据库:图形数据库以图形结构的方式存储数据,可以快速地进行复杂的图形遍历和查询操作,适用于存储社交网络、推荐系统、知识图谱等数据。常用的图形数据库包括 Neo4j、OrientDB 等。
在选择 NoSQL 数据库时,需要根据具体业务需求和数据特点来进行选择。例如,如果需要存储半结构化的数据,可以选择文档型数据库;如果需要快速地读写键值对,可以选择键值型数据库;如果需要存储大规模的结构化数据,可以选择列族型数据库;如果需要存储复杂的图形数据,可以选择图形数据库。
1.3图数据库
1.3.1图数据库特点
图数据库是一种专门用于存储图形数据的 NoSQL 数据库。与传统的关系型数据库和其他 NoSQL 数据库不同,图数据库利用图形数据模型来存储和管理数据。图形数据模型由节点和边组成,节点代表实体,边代表实体之间的关系。例如,在社交网络中,用户可以表示为节点,朋友关系可以表示为边。
图数据库具有以下特点:
- 灵活的数据模型:图数据库采用图形数据模型,可以灵活地存储和表示各种类型的数据,例如社交网络、地图、知识图谱等。
- 快速的图形遍历:图数据库可以快速地遍历图形数据,通过节点和边之间的关系来发现数据之间的联系和模式,可以用于实现推荐系统、路径分析等功能。
- 高性能的查询和事务处理:图数据库支持高效的查询和事务处理,可以处理大规模的图形数据和高并发请求,具有较高的性能和可扩展性。
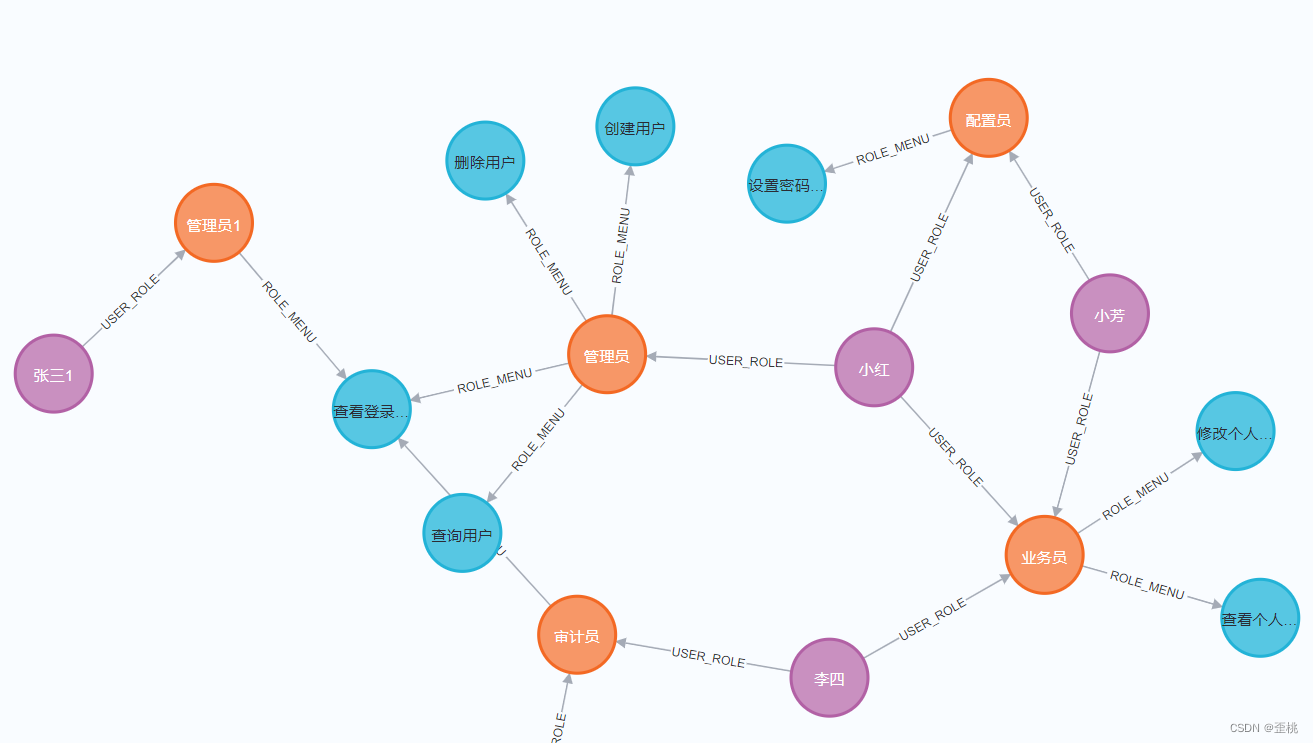
- 可视化和交互性:图数据库可以通过图形界面来可视化和交互数据,使用户可以更加直观地理解和操作数据。例如如下图所示。
1.3.2图数据库应用场景
图数据库在以下领域有广泛的应用场景:
- 社交网络:图数据库可以用于存储和分析社交网络数据,例如用户、好友、关注、分享等,可以用于实现社交网络分析、推荐系统和个性化推荐等功能。
- 推荐系统:图数据库可以用于存储和分析用户行为数据,例如浏览记录、购买记录、评分等,可以用于实现个性化推荐、商品推荐和广告定向投放等功能。
- 知识图谱:图数据库可以用于存储和管理知识图谱数据,例如实体、属性、关系等,可以用于实现智能问答、语义搜索和自然语言处理等功能。
- 网络安全:图数据库可以用于存储和分析网络安全数据,例如攻击者、受害者、攻击路径等,可以用于实现威胁情报分析、安全事件管理和风险评估等功能。
- 生物信息学:图数据库可以用于存储和分析生物信息学数据,例如基因、蛋白质、代谢物等,可以用于实现基因组学、药物研发和生物信息学研究等功能。
2图数据库基本概念
2.1用户访问菜单
用户访问菜单是我们目前所有的软件中最常见的一个功能了,本文将基于用户访问菜单来介绍这个图数据库的概念。
在用户访问菜单中,我们的信息主体有如下三个
- 用户
- 角色
- 菜单
信息关联有如下两个
- 用户-角色
- 角色-菜单
张三这个用户登录系统以后,能访问那些菜单?
- 张三(用户)根据关联关系《用户-角色》找到张三所拥有的《角色》(审计员)
- 实体审计员(角色)根据关联关系《角色-菜单》找到审计员所拥有的菜单访问权限(查看操作记录)
本文将使用neo4j来开始介绍图数据库。
图数据库的数据模型中,我们将信息分为三类,分别为节点、关系、属性
本文为了简单介绍,使用一个用户访问菜单的功能来进行介绍。
2.2节点(用户、角色、菜单)
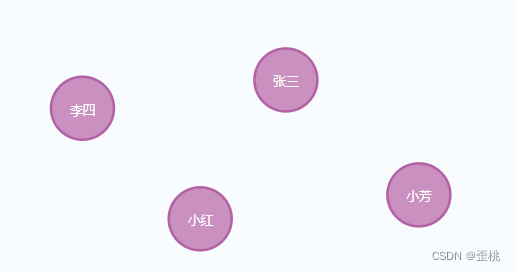
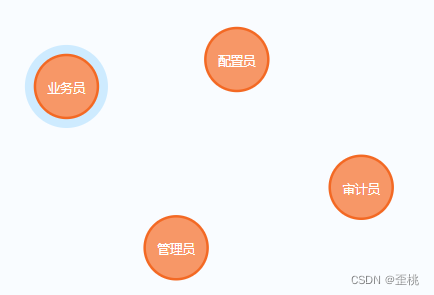
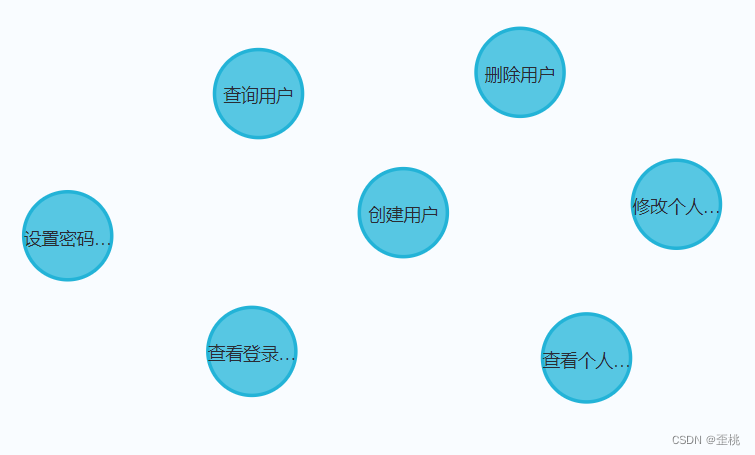
将诸如人物、电影、书籍或其他具体事物称之为节点,那么在我们上面的案例中
那么用户、角色、菜单,都是节点。
用户节点
角色节点
菜单节点
节点是图中的实体。
- 节点可以用labels标记,代表它们在您的域中的不同角色(例如,Person)。
- 节点可以包含任意数量的键值对或属性(例如,name)。
- 节点标签还可以将元数据(例如索引或约束信息)附加到某些节点
2.3关系(拥有角色、可以访问)
关系就是连接节点的概念、事件或事物。在关系数据库中,这些关系通常存储在具有链接字段的数据库行中。简单一点说就是,一条线把两个节点连起来,这条线就是关系。
如下所示,例如小芳和配置员、业务员中间被一根有向箭头连起来了,这个有向箭头就是关系,这个关系叫做拥有角色。
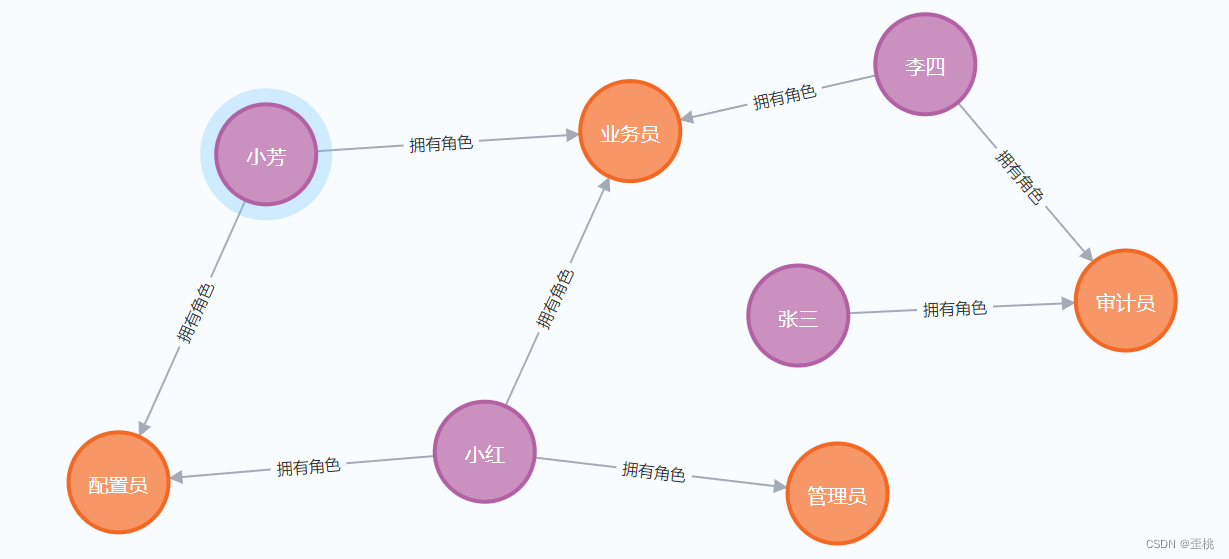
同理角色和菜单,角色可以看到访问那些菜单的这个箭头《可以访问》,就是关系

关系在两个节点实体(用户——拥有角色——> 角色)之间提供定向的命名连接。
- 关系总是有方向、类型、开始节点和结束节点,并且它们可以像节点一样有属性。
- 在不牺牲性能的情况下,节点可以具有任意数量或类型的关系。
- 尽管关系总是定向的,但它们可以在任何方向上有效地导航。
2.4属性(节点/关系的属性)
节点和边都可以拥有可搜索的属性。例如,如果你的节点代表人,他们可能拥有名字、性别、出生日期、身高等属性。而边的属性可能描述了两个人之间的关系何时建立,见面的情况或关系的性质。
例如我们在Neo4J中,查看《审计员》这个节点,我们发现它有三个属性,有id,roleName、roleDes。
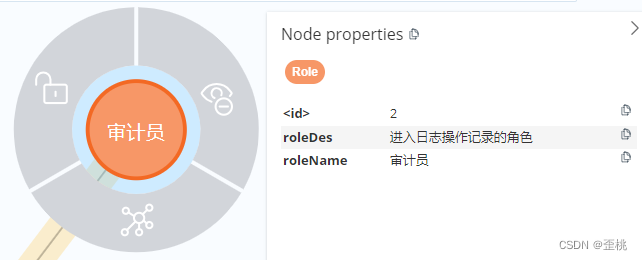
同理,当我们查看《可以访问》这个关系时,我们也能发现它有两个属性,分别是id和name。

2.5呈现效果(用户-角色-菜单)
这是我们用neo4j构建的一个图谱关系,我们可以非常清晰的看到每个用户所拥有的角色,以及每个角色所能访问的菜单。

对于关系型数据库有专门的SQL语言来帮我对数据进行操作,同样的图数据库也会有专门的语言来帮我们对数据库进行操作。
如下的语言是cypher编写,用来帮助我们对数据进行操作,例如我们现在想查询小红这个用户可以访问那些菜单,那就是小红->角色->菜单的逻辑
MATCH (u:User{userName: '小红'})-[:USER_ROLE]->(r:Role)-[:ROLE_MENU]->(m:Menu)
RETURN u,r,m

3Neo4j开发工具
使用Neo4j进行开发,下面是一些我们常用的工具。本文中,我使用的就是Neo4j Browser和Cypher。
• Neo4j Desktop — 用于使用 Neo4j 的本地开发环境,无论是使用本地数据库实例还是位于远程服务器上的数据库。免费下载包括 Neo4j 企业版许可证。
• Neo4j Browser — 在线浏览器界面,用于查询和查看数据库中的数据。使用 Cypher 查询语言的基本可视化功能。
• Neo4j Operations Manager (NOM) — 一种基于 UI 的工具,使数据库管理员能够监视、管理和操作企业版中的所有 Neo4j 数据库管理系统。
视频系列:NOM Bytes介绍了该产品并提供了一些实用技巧。有关详细信息,
请参阅Neo4j Ops Manager文档。
• Data Impourer — 一种无代码工具,允许您从平面文件 (.csv和.tsv) 加载数据,定义图形模型,将数据映射到它,并将其导入 Neo4j 数据库。
• Neo4j Bloom — 面向业务用户的可视化工具,无需任何代码或编程技能即可查看和分析数据。有关详细信息,请参阅文档。
• Cypher是一种开放数据查询语言,基于openCypher 计划。它是用于属性图的最成熟和直观的查询语言
• Neo4j 驱动程序 ——官方支持的驱动程序和社区驱动程序。
• Neo4j 连接器 — 一组连接器,用于将您的常规工作环境与 Neo4j 集成。
• GraphQL Library是一个灵活的、低代码的开源 JavaScript 库,通过利用连接数据的力量,可以为跨平台和移动应用程序快速开发 API。
• OGM — Neo4j 的对象图映射库。
4Neo4J下载安装
4.1安装JDK8/11
你需要安装JDK环境,4.0版本及以上需要JDK11。
4.1Neo4j Browser(浏览版)
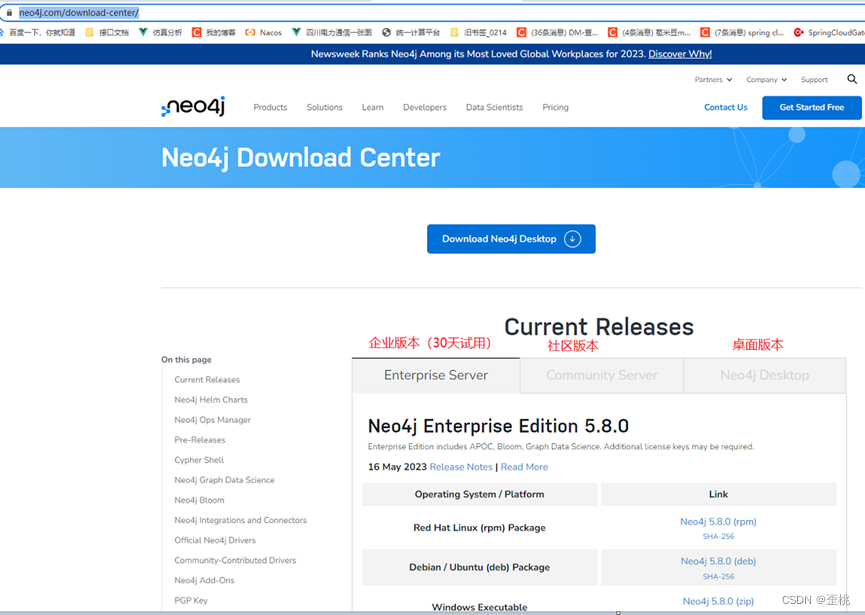
本文中,选择windows社区版本的4.4.21。
下载地址:https://neo4j.com/download-center/
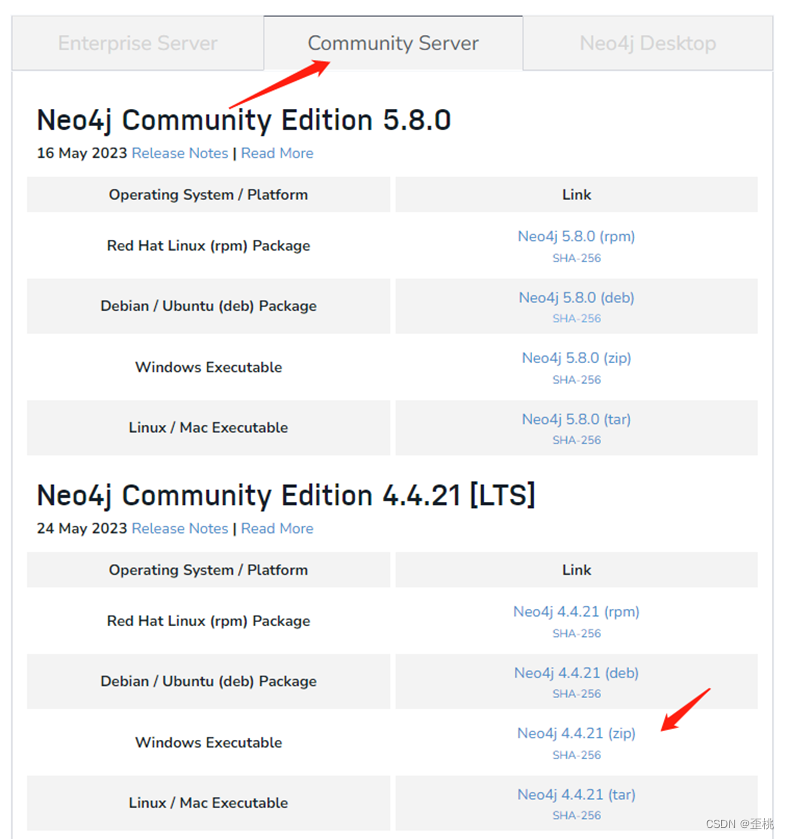
将下载的压缩包解压即可
cmd中,在bin目录下输入neo4j console即可启动neo4j。(快捷方式:电脑进入bin目录,在地址栏输入cmd)即可在该目录下打开cmd。
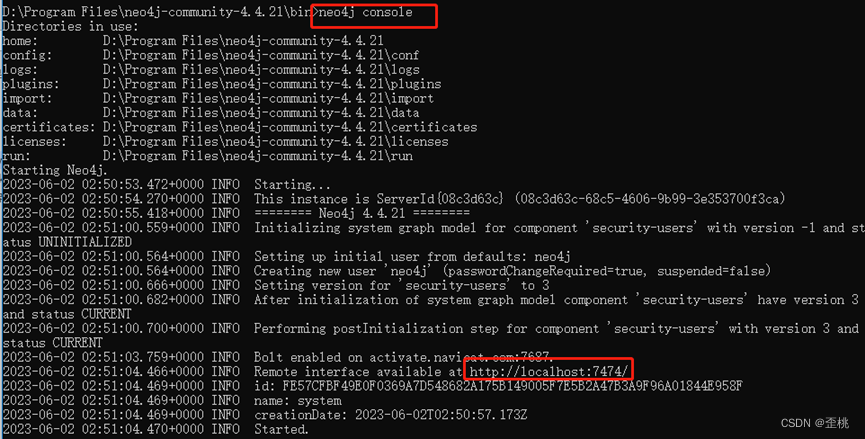
浏览器访问上述地址,http://localhost:7474/
默认用户名neo4j,密码neo4j

至此完毕!


![[MySQL]MySQL用户管理](https://img-blog.csdnimg.cn/img_convert/bc2ec15e195617e2974468e0afd19359.png)