目录
1、确认应答机制
2、超时重传机制
3、滑动窗口
4、流量控制
5、拥塞控制
6、延迟应答
(各位好,博主新建了个公众号《自学编程村》,拉到底部即可看到,有情趣可以关注看看哈哈,关注后还可以加博主wx呦~~~,拉到底部就可以看到啦)
TCP中采用了许许多多的机制,来保证网络传输过程当中数据的可靠性的问题。这里的可靠可以广义一点来理解。它几乎涉及到了方方面面。我们现在就挑选一些最最重要的机制来进行讲解。
1、确认应答机制
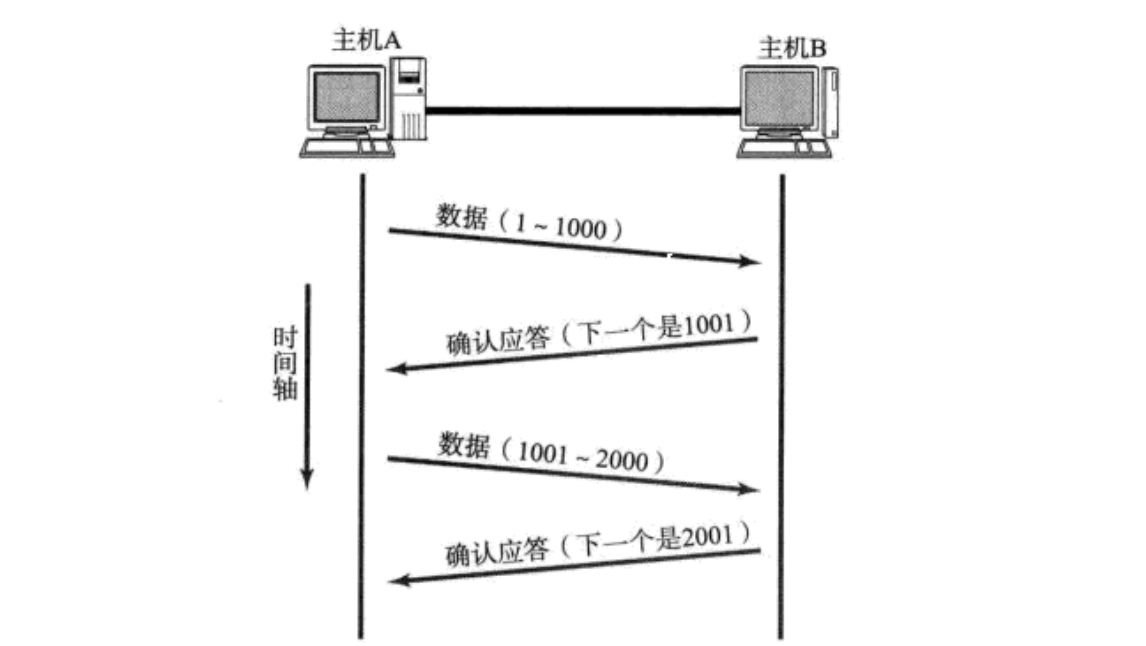
如图,我们在之前的TCP协议的特性中实际上也详细地说到过。
对于某一个报文,其发送出去之后,返回的报文需要携带一个ACK的应答标志。这里就点出其有这样一个性质,不再做过多赘述。
2、超时重传机制
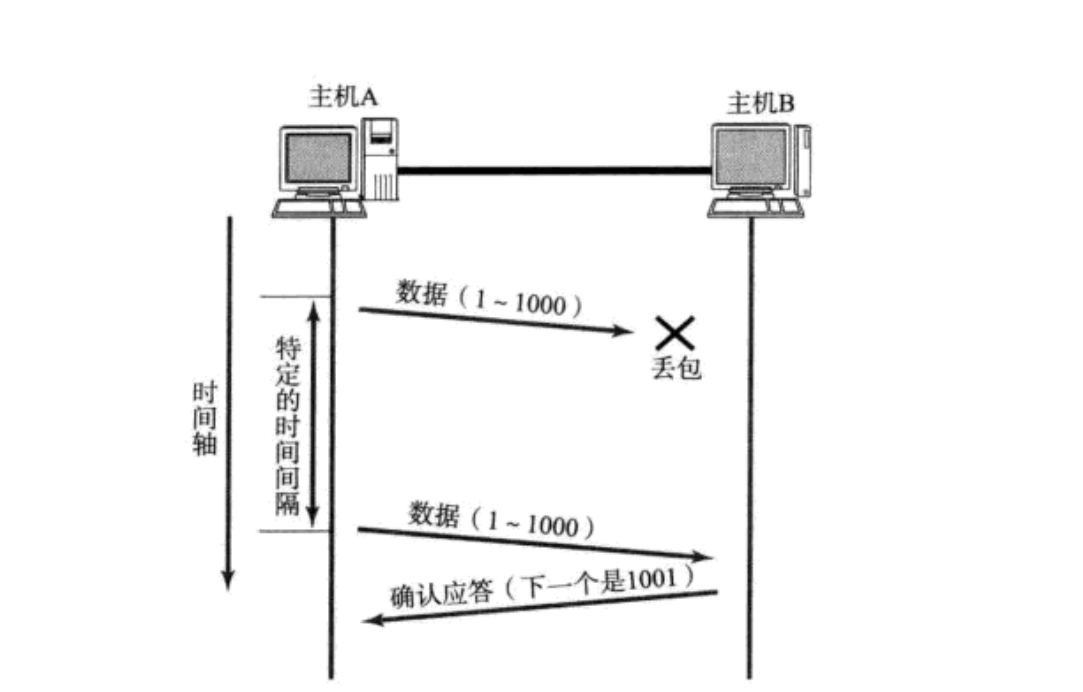
主机A发送数据给B之后, 可能因为网络拥堵等原因, 数据无法到达主机B;
如果主机A在一个特定时间间隔内没有收到B发来的确认应答, 就会进行重发。
但是, 主机A未收到B发来的确认应答, 也可能是因为ACK丢失了
因此主机B会收到很多重复数据. 那么TCP协议需要能够识别出那些包是重复的包, 并且把重复的丢弃掉.
这时候我们可以利用前面提到的序列号, 就可以很容易做到去重的效果(这是序号的第二个作用,也是可靠性的体现)
【超时的时间间隔】
最理想的情况下, 找到一个最小的时间, 保证 "确认应答一定能在这个时间内返回".
但是这个时间的长短, 随着网络环境的不同, 是有差异的.
如果超时时间设的太长, 会影响整体的重传效率;
如果超时时间设的太短, 有可能会频繁发送重复的包;
需要指出的是,应用层不需要关心通信细节。
比如,你在应用层上想要发送一个信息,但是我在底层可能是通过发送多次、甚至有触发了超时重传等等。而站在用户的角度呢,你不用去管它,我传输层不管怎么发,反正最终把你的数据发出去就可以了。也就是说,应用层的传输和底层传输层的并不是一对一、一一对应的关系。
就是说,我们这里所说的关系,都是在传输层上的,都是操作系统、网络等帮助我们做好的。
快重传
对于超时重传机制,我们可以再细分两种情况来进行讨论一下:
情况一:
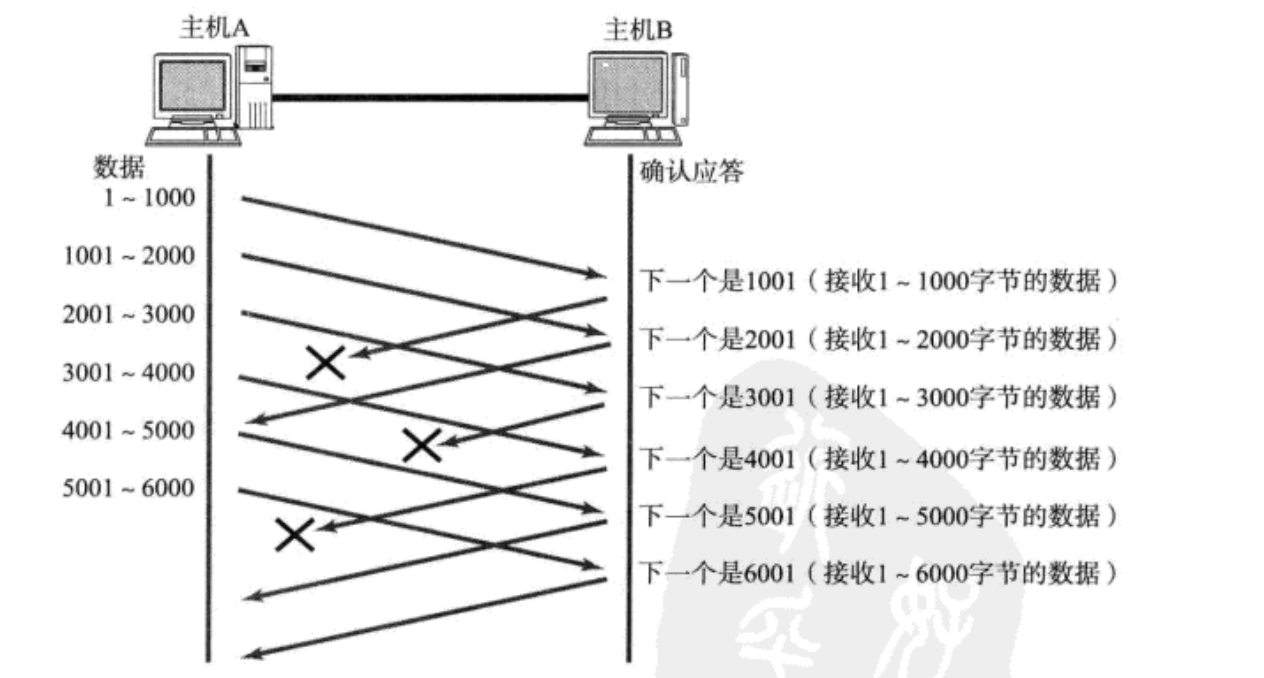
数据包已经抵达, ACK被丢了。这种情况下, 部分ACK丢了并不要紧, 因为可以通过后续的ACK进行确认。
这种情况没有什么好说的。
情况二:
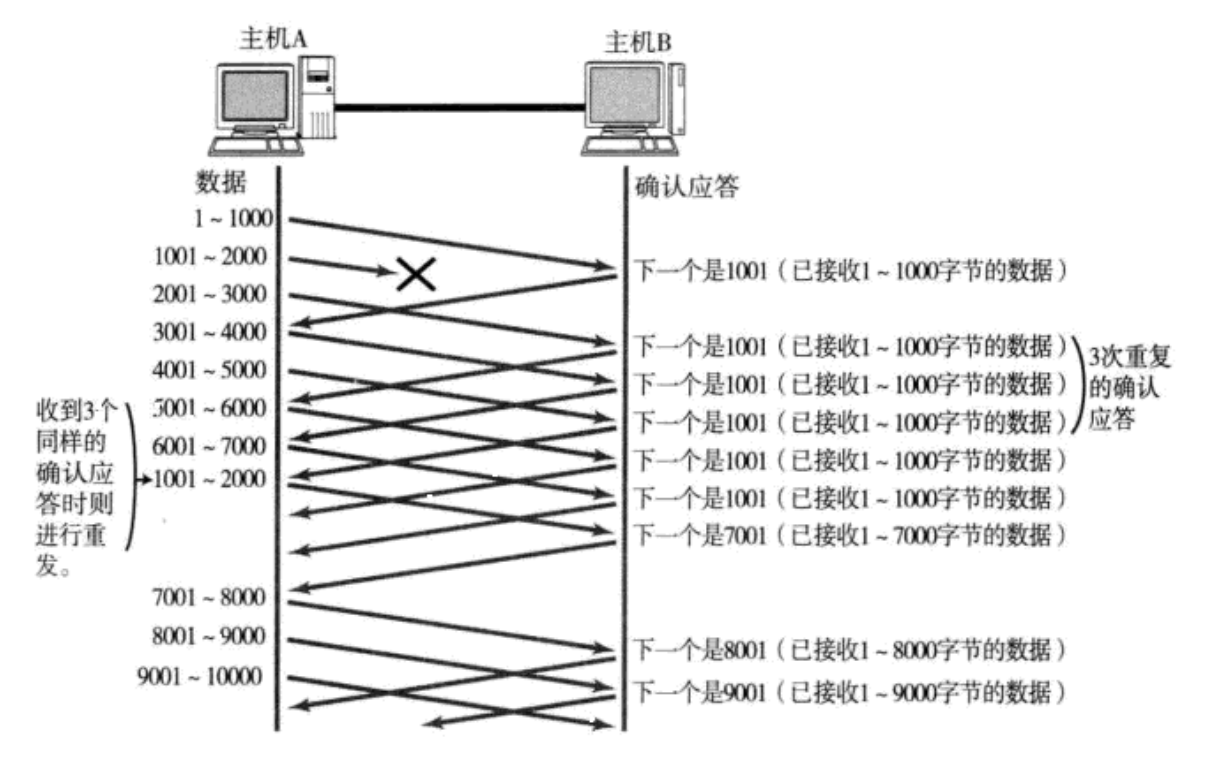
如上图,比如数据包就直接丢了。
当某一段报文段丢失之后, 发送端会一直收到 1001 这样的ACK, 就像是在提醒发送端 "我想要的是 1001"一样;
如果发送端主机连续三次收到了同样一个 "1001" 这样的应答, 就会将对应的数据 1001 - 2000 重新发送;
这个时候接收端收到了 1001 之后, 再次返回的ACK就是7001了
(因为2001 - 7000)接收端其实之前就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中
这种机制被称为 "高速重发控制"(也叫 "快重传")
(注意,在一般情况下,其实没有这种机制,我们也会重传,但其为超时重传)
一般情况下,超时重传用来兜底(比如我的窗口大小只有1个报文)
3、滑动窗口
刚才我们讨论了确认应答策略, 对每一个发送的数据段, 都要给一个ACK确认应答. 收到ACK后再发送下一个数据段。这种方式叫做串性发送消息。
这样做有一个比较大的缺点, 就是性能较差. 尤其是数据往返的时间较长的时候
既然这样一发一收的方式性能较低, 那么我们一次发送多条数据, 就可以大大的提高性能(其实是将多个段的等待时间重叠在一起了).如下图

这样做的好处,不仅仅是提高了效率,而且能容忍部分ACK的丢失
那为啥我们不一下子把数据全部发过去呢?
原因很简单,我们发送的数据的多少,同时还要受到对方接受能力的影响。(这个指双方的窗口(接受缓冲区)大小,并且在三次握手时就已经协商完毕)
窗口大小指的是暂时无需等待确认应答而可以继续发送数据的最大值. 上图的窗口大小就是4000个字节(四个段)
那滑动窗口是什么捏?
对于一个发送缓冲区,我们将其分成三个部分:
滑动窗口之前、滑动窗口里、滑动窗口之后
滑动窗口之前的数据是属于已经发送并且已经收到ACK的数据。(收到之后就删掉了)
滑动窗口之后的数据是属于尚未发送的数据。
滑动窗口里的:可以(已经)发送或者未收到ACK的数据。
滑动窗口的巧妙之处就在于,其一旦收到某一个数据的ACK,其前面的数据就表示都受到了,即滑动窗口可以的尾部可以直接滑动到该数据之处。(即我收到谁,我就可以认为之前的都收到了)
滑动窗口是属于发送缓冲区的一部分! 有多大呢? <=对方的接收缓冲区的大小。
如何理解滑动窗口?
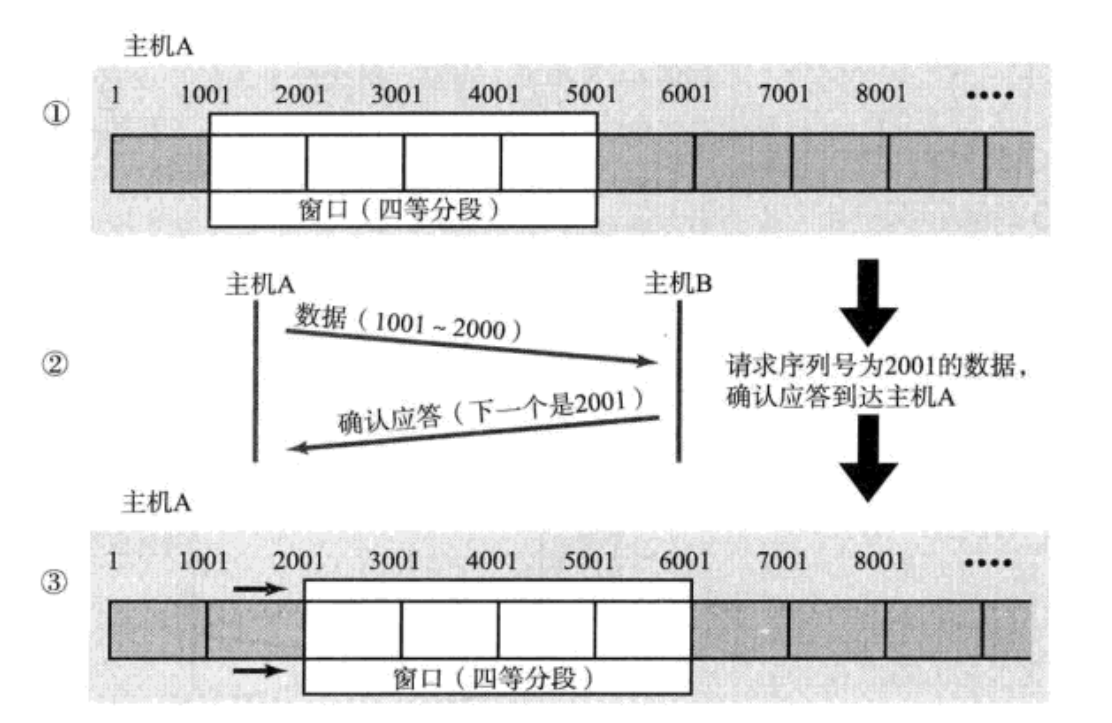
定义两个指针,一个left,一个right。就不断让left和right加数值就可以实现滑动窗口的移动了。
为了避免其过大超出缓冲区的范围,我们就将其设计为环形的,即可以模上一个数值。
我们之前在上层的接口Send()实际上就是在往缓冲区里写。(往滑动窗口后面写)
(在后面的OJ题中,我们也将会用到滑动窗口呦)
如果缓冲区满了,在上层的体现就是send()阻塞。
本质上,发送缓冲区也就是一种生产者消费者模型。
窗口越大, 则网络的吞吐率就越高;即滑动窗口的大小是可变的(可变大、变小)
4、流量控制
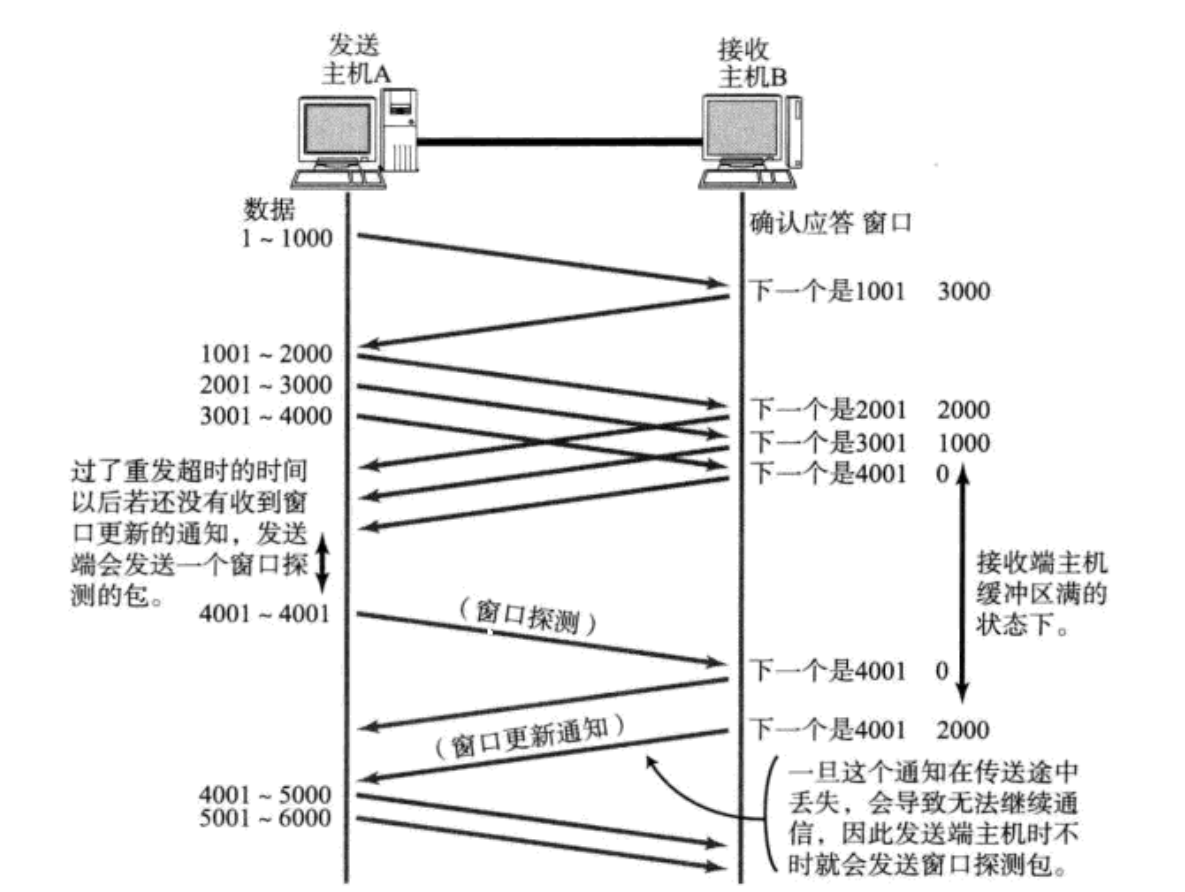
接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 "窗口大小" 字段, 通过ACK端通知发送端;
窗口大小字段越大, 说明网络的吞吐量越高;
接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
发送端接受到这个窗口之后, 就会减慢自己的发送速度;
如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数
据段(可能会携带PSH标志位), 使接收端把窗口大小告诉发送端。与此同时,接收方在有空间之后也需要给发送方发送窗口更新通知。
如果就是不取,那是应用层的BUG了,这个锅就是不OS传输层的了。
所以,调用recv本质上就是将数据从接收缓冲区中读走。
5、拥塞控制
那有没有要考虑是网络的问题呢?
少量的丢包, 我们仅仅是触发超时重传; 大量的丢包, 我们就认为网络拥塞;
当TCP通信开始后, 网络吞吐量会逐渐上升; 随着网络发生拥堵, 吞吐量会立刻下降;
拥塞控制, 归根结底是TCP协议想尽可能快的把数据传输给对方, 但是又要避免给网络造成太大压力的折中方案.
此处引入一个概念程为拥塞窗口
它的作用是:你的数据发送的速率不能超过我拥塞窗口的大小,不然就可能会造成拥塞。
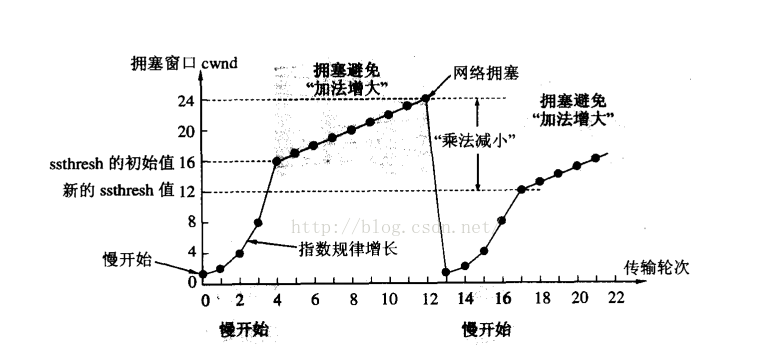
发送开始的时候, 定义拥塞窗口大小为1;
每次收到一个ACK应答, 拥塞窗口加1;
每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口大小做比较, 取较小的值作为实际发送的窗口;
像上面这样的拥塞窗口增长速度, 是指数级别的. "慢启动" 只是指初使时慢, 但是增长速度非常快.
为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍.
此处引入一个叫做慢启动的阈值,当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长(通常是拥塞窗口的1/2)
(1)当TCP开始启动的时候, 慢启动阈值等于窗口最大值;
(2)tcp认为,当它重传了一个报文段即触发了超时重传机制后,其就会认为网络拥塞,这个时候,其会将慢启动阈值记为cwnd的一半,cwnd置为1。
(3)而当其触发的是快速重传机制的时候(即收到了三个或者以上相同的ACK),其会将慢启动阈值设置为cwmd的一般,然后将cwnd设置为慢启动阈值的值(或者加三,加三的原因表明是 有三个老的数据报离开了网络)然后重传丢失的报文段,这个时候,如果收到的是该报文段的ACK,那么拥塞窗口+1;如果收到的是新的报文段的ACK,那么证明网络已经回复,进入拥塞避免的线性增长阶段。
TCP拥塞控制这样的过程, 就好像 热恋的感觉
6、延迟应答
如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小.
假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
就是说,先等一会,等用户从我的缓冲区中取走一点,然后我给你返回的接受缓冲区就会更大。
一定要记得, 窗口越大, 网络吞吐量就越大, 传输效率就越高. 我们的目标是在保证网络不拥塞的情况下尽量提高传输
效率;
那么所有的包都可以延迟应答么? 肯定也不是;
数量限制: 每隔N个包就应答一次;
时间限制: 超过最大延迟时间就应答一次;
具体的数量和超时时间, 依操作系统不同也有差异; 一般N取2, 超时时间取200ms
原创不易,如果觉得写的不错,就点个赞呗~~~笔芯~~~~
下面是笔者的微信公众号,也欢迎来关注呀~~~




![[附源码]计算机毕业设计基于Vue的社区拼购商城Springboot程序](https://img-blog.csdnimg.cn/005011ba90164b02a28520def08818da.png)