CMU 15-445 -- Join Algorithms - 11
- 引言
- Parallel & Distributed
- Inter-query vs. Intra-query Parallelism
- Process Model
- Approach #1: Process per DBMS Worker
- Approach #2: Process Pool
- Approach #3: Thread per DBMS Worker
- Execution Parallelism
- Inter-query Parallelism
- Intra-query Parallelism
- Intra-operator Parallelism (Horizontal)
- Inter-operator Parallelism (Vertical)
- 观察
- I/O Parallelism
- Multi-disk Parallelism
- Partitioning
- Vertical Partitioning
- Horizontal Partitioning
- 小结
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录,附加个人拙见,同样借助CMU 15-445课程内容来完成MIT 6.830 lab内容。
Parallel & Distributed
随着摩尔定律逐渐失效,处理器走向多核,系统可以通过并行执行增加吞吐量,减少延迟,使得系统响应更快。
Parallel:如运行在多核 CPU 上
- 每个 DB 节点物理上非常接近,通过高速 LAN 相连接
- 通信成本极小
Distributed:如分布式数据库
- 节点之间距离可能很远,通过公网相连接
- 通信成本和通信可能出现的问题不可忽略
Inter-query vs. Intra-query Parallelism
- Inter-Query:不同的查询并行执行
- 增加吞吐量,减少延迟
- Intra-Query:同样的查询的不同 operators 并行执行
- 减少长时查询的延迟,主要用于 Streaming
Process Model
DBMS 的 process model 定义了多用户数据库系统处理并发请求的架构。在下文中,用 worker 指代执行查询任务的单位,它可能是 Process(es),也可能是 Thread(s)。
Approach #1: Process per DBMS Worker
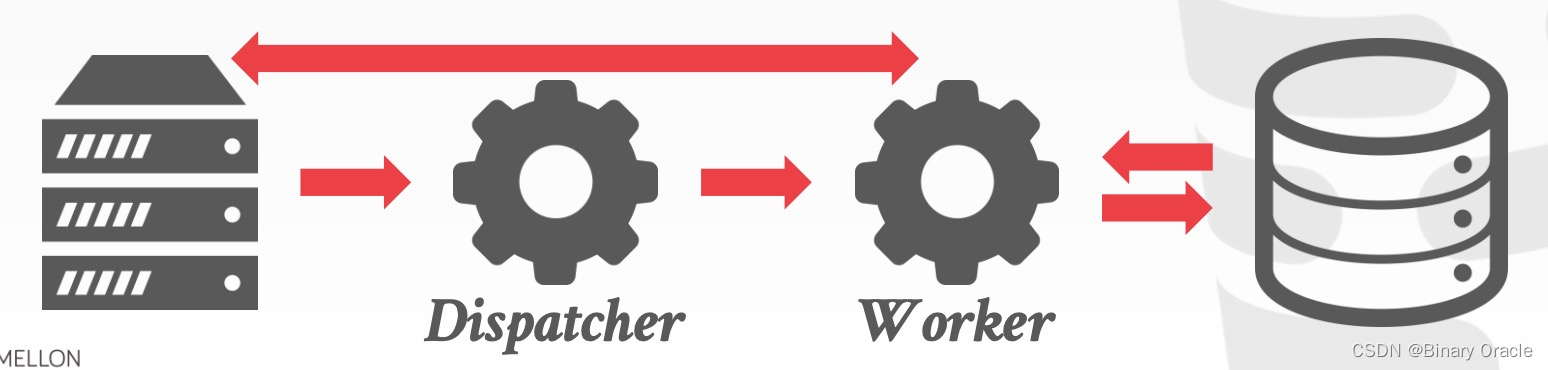
用户请求经过 Dispatcher 后,由 Dispatcher 分配相应的 Worker 完成查询并返回结果,每个 worker 都是单独的 OS Process
- 依赖 OS scheduler 来调度
- 使用 shared-memory 来存储全局数据结构
- 单个 worker 崩溃不会引起整个系统崩溃
这种 Process Model 出现在 threads 跨平台支持很不稳定的时代,主要是为了解决系统的可移植性问题。使用这种 Process Model 的数据库有历史版本的 DB2、ORACLE 和 PostgreSQL 等。
Approach #2: Process Pool
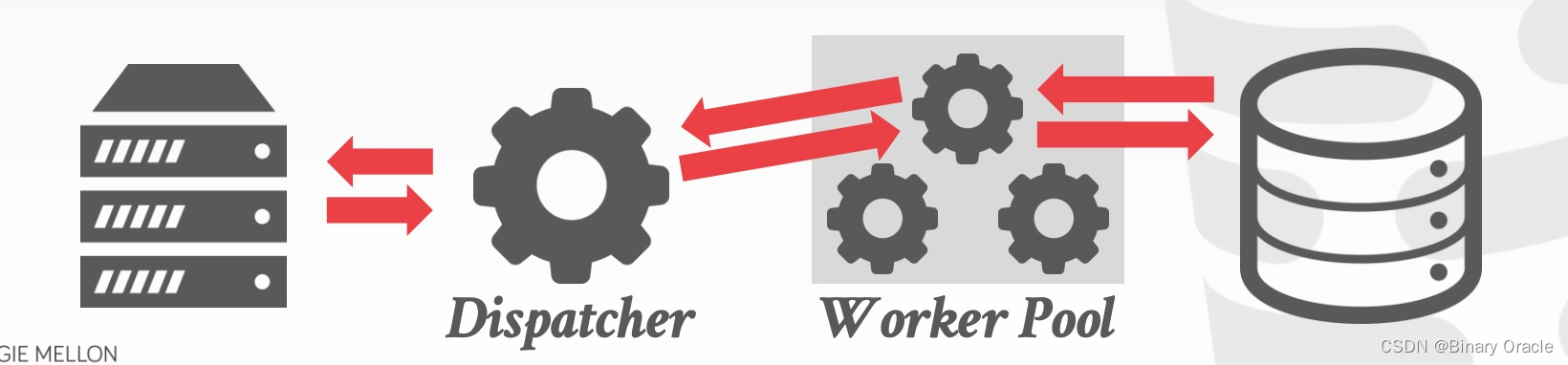
用户请求经过 Dispatcher 后,由 Dispatcher 分配相应的 Worker 完成查询,将结果返回 Dispatcher,后者再返回给用户。每个 Worker 可以使用 Worker Pool 中任意空闲的 Process(es):
- 依赖 OS scheduler 来调度
- 使用 shared-memory 来存储全局数据结构
- 不利于 CPU cache
使用这种 Process Model 的数据库有 DB2、PostgreSQL(2015)。
Approach #3: Thread per DBMS Worker

整个 DBMS 由一个 Process 和多个 Worker Threads 构成:
- DBMS 自己控制调度策略:每个查询拆成多少个任务、使用多少个 CPU cores、将任务分配到哪个 core 上,每个 task 的输出存储在哪里。自己控制调度策略的理由与自己构建 Buffer Pools 的理由是一样的:DBMS 比 OS 有更多的领域知识。
- dispatcher 不一定存在
- thread 崩溃可能导致整个系统崩溃
- 使用多线程架构的优势
- context switch 成本更低
- 天然地可以在 threads 之间共享全局信息,无需使用 shared memory
使用这种 Process Model 的数据库有 DB2、MSSQL、MySQL、Oracle (2014) 及其它近 10 年出现的 DBMS 等。
Execution Parallelism
Inter-query Parallelism
通过并行执行多个查询来提高 DBMS 性能。如果这些查询都是只读查询,那么处理不同查询之间的关系无需额外的工作;如果查询存在更新操作,那么处理好不同之间查询的关系将变得很难。相关内容将在后续章节中介绍。
Intra-query Parallelism
通过并行执行单个查询的单个或多个 operators 来提高 DBMS 性能:
- Approach #1:Intra-Operator
- Approach #2:Inter-Operator
这两个方法可以被同时使用,每个 relational operator 都有并行的算法实现。
Intra-operator Parallelism (Horizontal)
将 data 拆解成多个子集,然后对这些子集并行地执行相应的 operator,DBMS 通过将 exchange operator 引入查询计划,来合并子集处理的结果,过程类似 MapReduce,举例如下图所示:
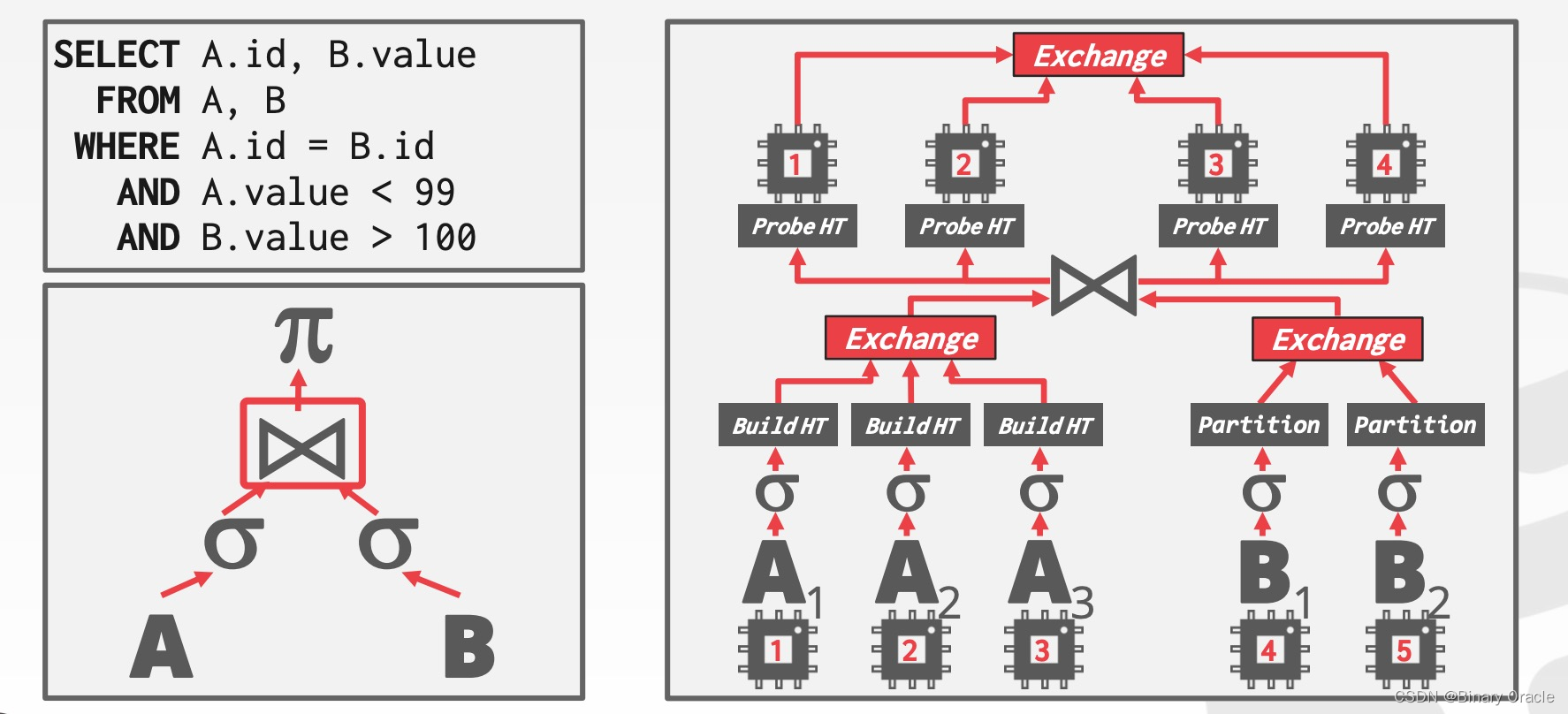
Inter-operator Parallelism (Vertical)
将 operators 串成 pipeline,数据从上游流向下游,一般无需等待前一步操作执行完毕,也称为 pipelined parallelism,举例如下:
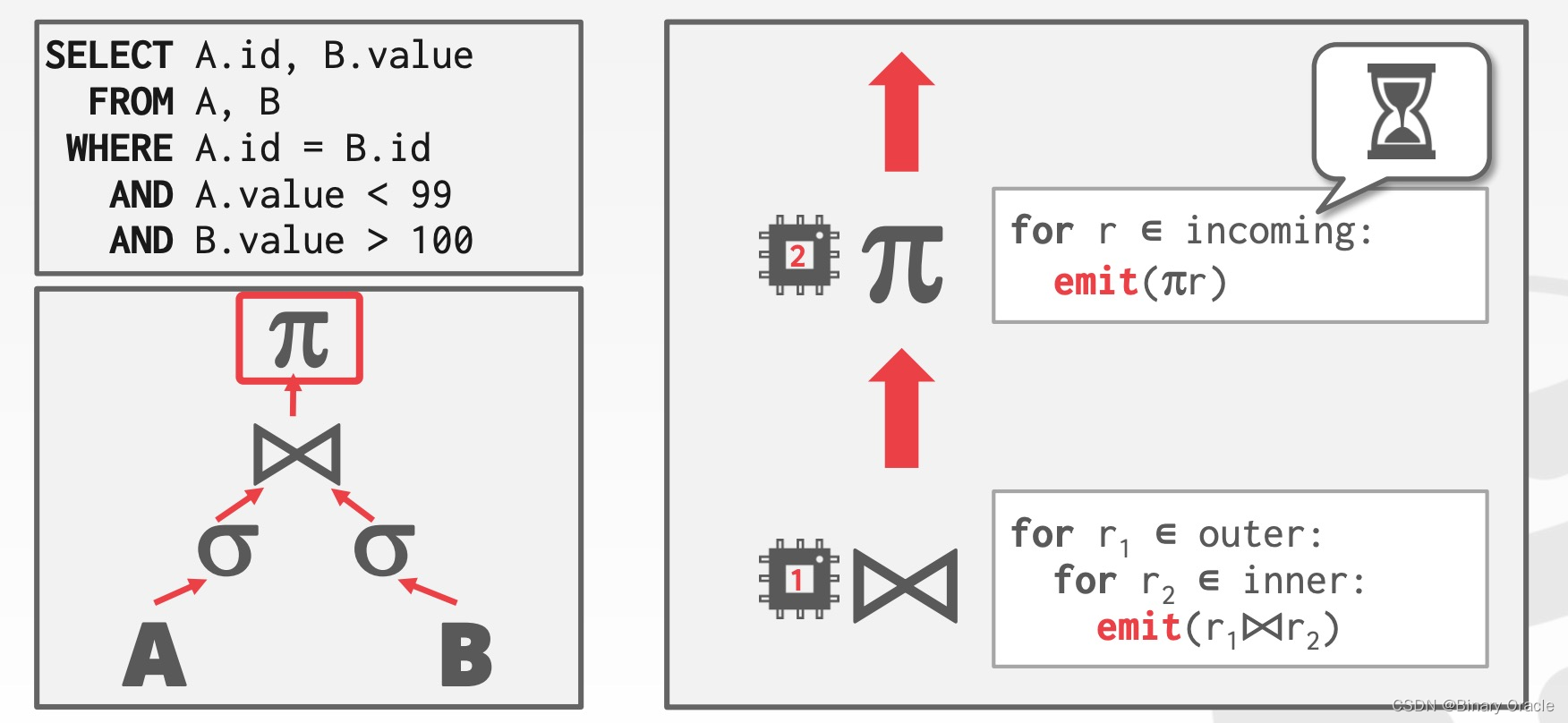
这种方式在传统 DBMSs 中并不常用,因为许多 operators,如 join, 必须扫描所有 tuples 之后才能得到结果。它更多地被用在流处理系统,如 Spark、Nifi、Kafka,、Storm、Flink、Heron。
观察
值得注意的是,使用额外的 processes/threads 来并行地执行查询可以通过提高 CPU 利用率来提高 DBMS 效率;但如果 DBMS 效率瓶颈出现在 disk 数据存取上,这种优化带来的效果就非常有限,甚至有可能因为 disk I/O 的提高导致整体性能下降,如 cache miss rate 提高等等。
I/O Parallelism
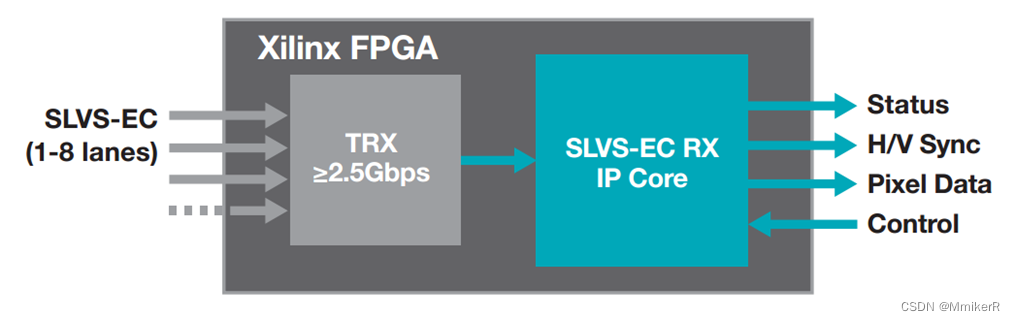
I/O Parallelism 通过将 DBMS 安装在多个存储设备上来实现:
- Multiple Disks per Database
- One Database per Disk
- One Relation per Disk
- Split Relation across Multiple Disks
Multi-disk Parallelism
通过 OS 或硬件配置将 DBMS 的数据文件存储到多个存储设备上,整个过程对 DBMS 透明,如使用 RAID:
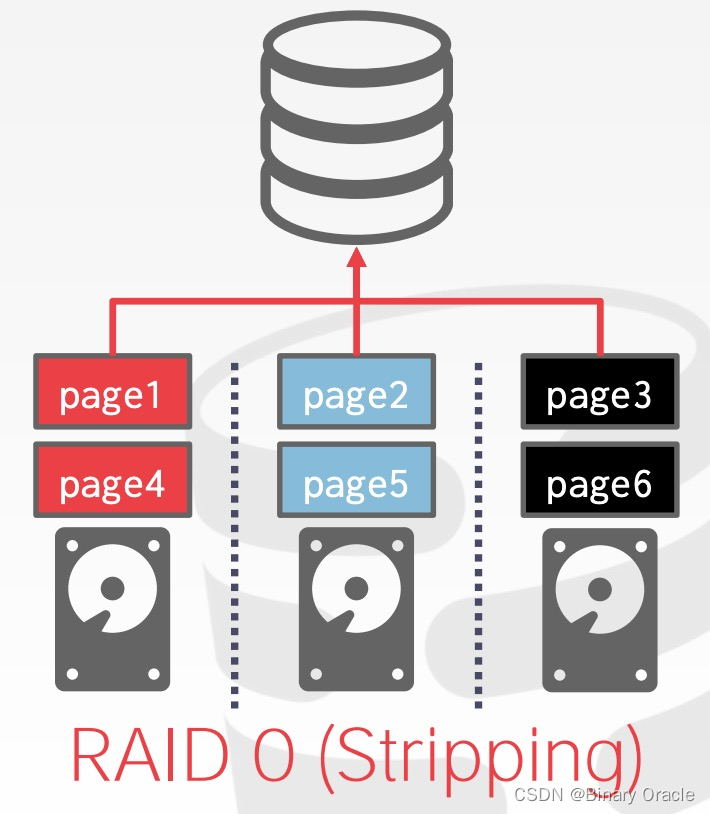
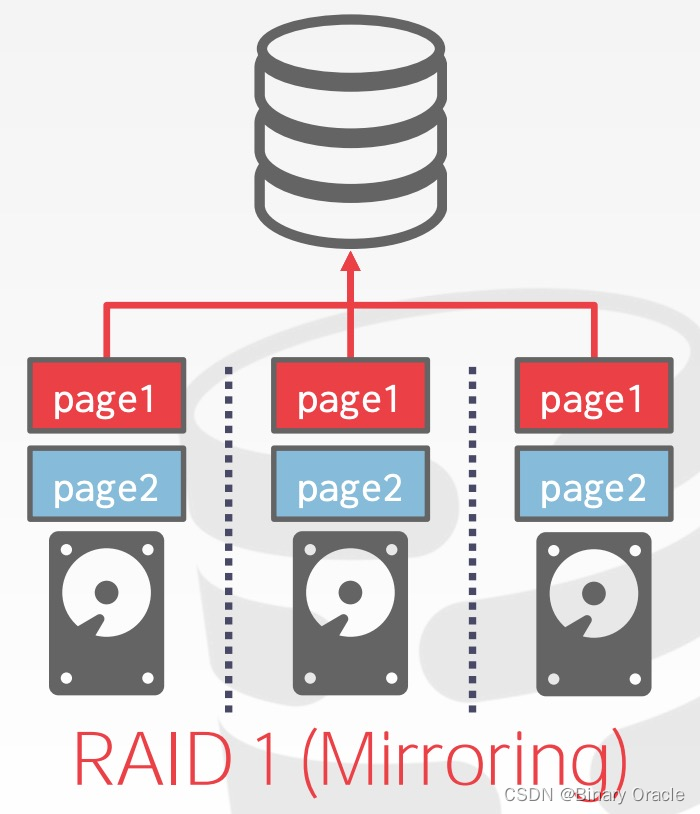
一些 DBMS 甚至允许用户为单个 database 指定 disk location。
Partitioning
将一个 logical table 拆分成多个 physical segments 分开存储。理想情况下,partitioning 应该对应用透明,但这并不一定能实现。
Vertical Partitioning
原理上类似列存储数据库,将 table 中的部分 attributes 存储到不同的地方,如:
CREATE TABLE foo (
attr1 INT,
attr2 INT,
attr3 INT,
attr4 TEXT
);

Horizontal Partitioning
基于某个可定制的 partitioning key 将 table 的不同 segments 分开存储,包括:
- Hash Partitioning
- Range Partitioning
- Predicate Partitioning

小结
并发执行很重要,几乎所有 DBMS 都需要它,但要将这件事做对很难,体现在
- Coordination Overhead
- Scheduling
- Concurrency Issues
- Resource Contention
本节对应教材PDF