一、时间长河谁能解
在人类生存的地球上,存在着一种很神秘的东西:时间,它看不见摸不着,但速度恒定,单调递增且永无止境的往前推进,人类的历史被淹没在茫茫的时间长河中。
同时在地球附近,一个星球叫做:Flink 星球。
如同太阳需要氢原子作为燃料,Flink 星球的燃料就是地球提供的数据,它的使命就是勤勤恳恳的为地球计算数据,为了满足地球人蛮荒发展催生的海量数据和复杂业务,Flink 星球也在不断迭代不断发展。
Flink 星球最神秘的地方在于,它可以自由调整时间的流动方式,既可以把时间更改为和地球一样的处理时间(ProcessingTime),也可以把它的时间更改为事件时间(EventTime),给多少数据,就流动多少时间。
随着 Flink 星球不断的进化,从 1.15 版本开始,为了更好的符合这个星球的计算使命,把事件时间作为默认时间。也就是在默认情况下,提供多少数据,就流动多少时间。
但是凡事都要遵守原则,Flink 星球时间的原则就是:可以停滞,也可以速度不恒定,但一定是单调递增,誓不回退。
Flink 星球吸收了地球的很多重要理念,其中一条就是:分工合作,不同的事情交给不同的团队完成。
由于地球的业务太多,有太多工厂在生产数据,比如文件系统、 Socket,Kafka,JDBC,于是 Flink 星球成立了专业的团队:连接器,这个团队只做一件事,收数据。
另外内部还成立了算子团队来和连接器对接,比如:
- 业务专一的 Source 算子,也就是连接器;
- 老实忠厚的 Map 算子,进来一条数据处理一条数据输出一条数据;
- 高标准强要求的 Filter 算子,对于不符合条件的数据,一律拦截;
- 能力强业务精的 Process 算子,可以对任意数据做任意计算。
另外,由于地球的某些工厂严重腐化,爱睡懒觉,磨洋工,运送数据的飞船经常未按约定时间到达 Flink 星球,这让 Flink 某些团队特别头疼。
比如如下工作场景该如何解决:
场景一 如上图,有四条数据(3、6、9、7),当3、6、9 分别来了之后,Flink 的时间跟随数据一直递增到 9 。
如上图,有四条数据(3、6、9、7),当3、6、9 分别来了之后,Flink 的时间跟随数据一直递增到 9 。
如果这时候来了一条数据为7,此时 Flink 中的时间会推进到多少?
场景二
算子1 有两个实例在处理数据,某一个时刻,下游算子2同时接收到了这两个实例发送过来的数据 3 和数据 5 ,此刻算子 2 中的时间是多少?
二、水印机制解难题
在没有发明水印之前,Flink 星球的工人使用了一种比较极端的数据处理方式:延迟的数据直接丢掉。这直接导致了计算结果异常,外交事件频出,疲于奔命。
之后一段时间,在不断的和地球的交涉中,Flink 星球交付了一种水印机制,暂时平息了风波。
(1)水印的产生
水印(Watermark)也是一种数据,不同于地球人给过来的数据,水印是算子团队内部产生的一种特殊的数据,只附带了时间属性。
水印可以由任意算子产生,一般由 Source 算子产生的。算子中有一个定时器,每隔 200ms 产生一个水印数据。
如下图就是 Source 算子的内部结构,里面维护了一个最大时间戳,每来一条数据,如果数据的时间比这个最大时间戳大,就更新这个时间戳。
另外还有一个定时器,默认情况下,每隔 200 ms 工作一次,每次工作,都会使用这个最大的时间戳的时间值,封装成一条水印数据,发送到数据的流水线上,和数据一同流向下一个算子。
如下图,是一个流水线上,Source 算子和 Map 算子努力工作的场景,传送带上有一些数据在流动。蓝色的是地球人发过来的要处理的数据,橙色的是 Source 算子自己产生的数据。
Source 算子产生水印的策略是,数据的时间是多少,水印的时间就是多少。
当数据 15 经过 Source 算子时,会把数据中的时间拿出来和 Source 算子内部的最大时间戳比对,如果比这个时间戳大,则把 内部的 maxTimestamp 赋值为 15。
定时器每隔 200ms 触发一次,每次到点了,就会用这个最大时间戳生成一个 watermark,发送到数据流中。
(2)水印的第一个作用:触发计算
交待了水印的背景以及初步的产生方式后,还需要介绍一下水印到底是如何在地球人延迟交付数据后,还能相对准确的算准数据的。
在 Flink 世界中,水印的作用只有两大场景:窗口计算和定时器,这里使用一个窗口计算的例子来说明。
首先为何要有窗口计算,因为数据是源源不断产生,没有一个终点,计算永远也不会停止,所以在无限的数据集上永远也无法得到最终结果。
如果把这无限的数据,切分成一段一段的有限数据集合,就可以做计算了,如下图:
Source 算子读取数据,发送数据到 Map 算子,Map算子在转换之后,根据数据的事件时间不同,把数据划分到三个窗口中,Process 算子来计算每个窗口中的数据总和。
那么问题来了,Process 算子在什么时候触发每个窗口的计算呢?
流水线上有数据5,水印5,数据8,数据10,水印10,依次经过 process 算子
当 数据5和水印5 经过 process 算子后的情况是:
数据5 被放到窗口1中,水印5 经过 Process 算子后,会判断水印值是否大于等于窗口结束时间 10,发现没有,则不触发计算。
等到了数据10和水印10过来之后:
数据8 被放到第一个窗口中。由于窗口是左闭右开,数据10被放到了第二个窗口中。
同时水印10由于等于第一个窗口的结束时间,第一个窗口被触发了计算。如果计算逻辑是求和,则第一个窗口的结果是 13.
(3)水印的第二个作用:处理延时数据
上面的例子展示了,如果水印时间和数据时间相等的情况。如果需要考虑数据延迟,那么需要调整水印生成策略,让水印的生成落后于数据的产生,
比如:水印时间 = 数据时间 - 3
比如有如下初始数据,假设 Process 算子后面有这些数据待处理。
每个数据时间后,紧跟着水印时间,水印时间为数据时间 - 3.
如下图,数据5、数据10、数据13是正常数据,但是数据6是迟到数据:
如下图,数据 8 被放到第一个窗口中,然后 process 算子收到水印5,比较是否到了窗口的结束时间,还未达到。继续处理下面的数据。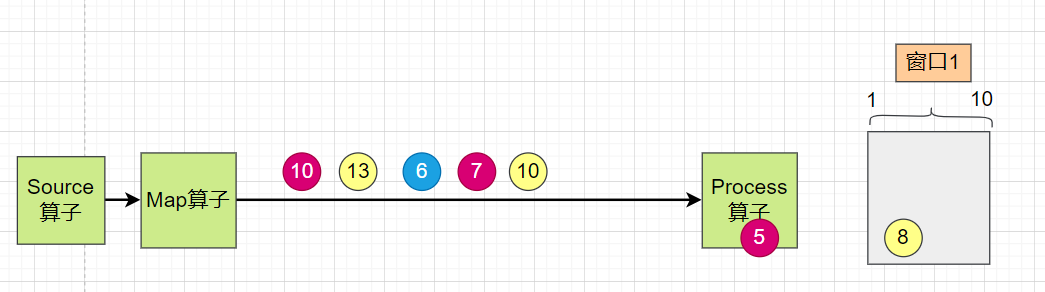
如下图,当数据 10 到达 process 算子时,被放到第二个窗口。此时虽然数据已经等于窗口结束时间了,但是此时水印才为7,仍然未达到窗口触发时间。
如下图,这条延时的数据6 还是被放到了第一个窗口,并没有被丢弃。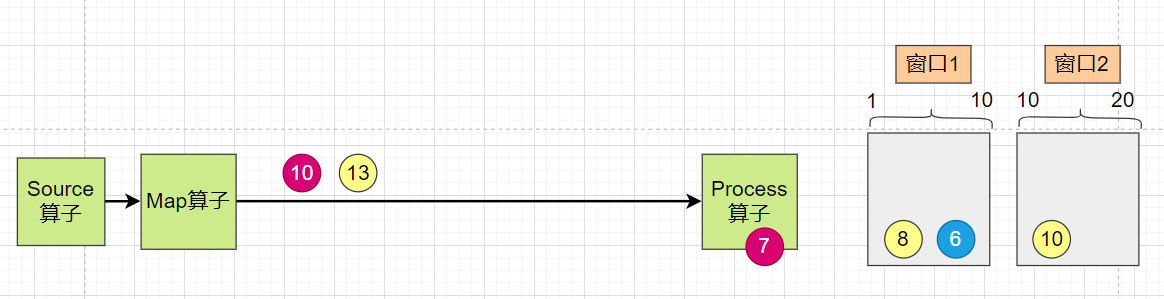
如下图, 13 这条数据被放到了 窗口2,此时水印10到达了 process 算子,就会触发窗口1 的计算,得到一个统计结果。
这样就很好的处理了延时数据。
三、Api里面见玄机
具体如何在代码中实现,下面展示了一段代码:
在代码中,source 算子从 一个 Socket 中读取数据,交由 map 算子处理
map 算子把字符串切割成字段,封装成对象返回
然后定义了水印的生成方式:
Configuration config = new Configuration();
config.setInteger("rest.port", 8081);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(config);
DataStreamSource<String> source = env.socketTextStream("192.168.10.100", 9999);
SingleOutputStreamOperator<EventBean2> beanStream = source.map(s -> {
String[] split = s.split(",");
return new EventBean2(Long.parseLong(split[0]),Long.parseLong(split[1]) ,Integer.parseInt(split[2]));
}).returns(EventBean2.class);
SingleOutputStreamOperator<EventBean2> watermarkedStream = beanStream.assignTimestampsAndWatermarks(
WatermarkStrategy.<EventBean2>forBoundedOutOfOrderness(Duration.ofMillis(0))
.withTimestampAssigner(new SerializableTimestampAssigner<EventBean2>() {
@Override
public long extractTimestamp(EventBean2 eventBean, long l) {
return eventBean.getTimestamp();
}
})
);
这个 WatermarkStrategy 中有两种生成方式:
- forMonotonousTimestamps
- forBoundedOutOfOrderness
第一种就是乱序时间为0的情况,也就是紧跟着数据的时间。第二种可以设置一个延迟的时间,比如上面的案例中,可以延迟3s
另外既然水印的时间从数据中来,就需要告诉 Flink,如何从数据中抽取时间出来
于是还需要指定 withTimestampAssigner。
当前指定水印可以从任意算子开始。
四、源码里面找真理
Flink 源码是相当庞大的,一层层的往下点,很容易会迷路失去方向,那么为了了解核心源码,可以采用 debug 的方式,先在业务代码上打断点,等到了断点处,会显示调用栈,然后阅读调用栈上的核心代码就可以。
(1)当数据到达算子的时候,如何处理的
我们在业务代码抽取时间戳的地方打一个断点,然后在 Idea 中看调用栈:
跑起来,在 Socket 中输入一行数据后,就可以在 Idea 中就可以看到长长的调用栈:
点到第三个调用栈,可以看到到了这个类中:TimestampsAndWatermarksOperator
这也是一个单独的算子,它的职责就是从事件中提取时间,并生成水印

最后一行:watermarkGenerator.onEvent(event, newTimestamp, wmOutput); 点进去的逻辑是:
maxTimestamp = Math.max(maxTimestamp, eventTimestamp);
也就是用事件时间和当前的算子的记录时间比较,如果事件时间比当前时间大,则更新当前的时间。
(2)定时器如何周期性发射水印
从业务代码中往里面点几步
可以看到这个类,集成了 WatermarkGenerator 接口
定义了两个方法,事件到来的触发和周期性发射方法
我们可以在这个地方打一个断点,看是如何周期性发射水印的
重新启动,这时候还没有数据,已经到断点处来
可以点到第二个调用栈,看看
来到 onProcessingTime
第一行的逻辑就是:
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
使用最大的时间戳减去定义的延时时间减去1,构造一个水印发送出去。
第二行得到当前的系统时间,注册了一个定时器,定时器的触发时间是,当前时间+水印发射的间隔时间(200ms)
也就是当前时间过了 200ms,又会触发这个 onProcessingTime,又会重复当前的逻辑。
不是我们想象中的使用一个 while 循环。
五、到了再见时间
本次,我们在 Flink 星球上,鉴赏了 Flink 星球为了处理延时数据而做出的努力,创造了水印这样的一个神奇的机制,来处理流式计算业务的延时问题。
相信下一次碰到类似问题,会有所启发。



![[附源码]计算机毕业设计基于Vue的社区拼购商城Springboot程序](https://img-blog.csdnimg.cn/005011ba90164b02a28520def08818da.png)