漏斗分析是一套流程式的数据分析方法,能够科学地反映各阶段用户转化情况。漏斗分析模型已经广泛应用于用户行为分析类产品,且功能十分强大:它可以评估总体或各个环节的转化情况、促销活动效果;也可以与其他数据分析模型结合进行深度用户行为分析,从而找到用户流失的原因,以提升用户量、活跃度、留存率。
漏斗分析最常用的两个互补型指标是转化率和流失率。例如如有100人访问某电商网站,有27人支付成功。这个过程共有5步,第一步到第二步的转化率为88%,流失率为12%,第二步到第三步转化率为32%,流失率68%……以此类推。整个过程的转化率为27%,流失率为73%。该模型就是经典的漏斗分析模型。每一层漏斗,就是一个漏斗事件。其中,最核心的指标就是转化率。
漏斗的三个要素:
时间:特指漏斗的转化周期,即为完成每一层漏斗所需时间的集合。
节点:每一层漏斗,就是一个节点。
流量:就是人群(人数)。
对于时间来说:通常来讲,一个漏斗的转化周期越短越好。
对于节点来说:最核心的指标就是转化率,计算公式为:转化率 = 本层事件转化人数/上层事件转化人数
对于流量来说:不同特定人群在同一个漏斗下的表现情况一定是不一样的,例如同一类的高端电子产品漏斗里,年轻人和老人的转化率肯定不一样的。
AARRR模型是漏斗分析的其中一种,可以指导我们主要检测和分析哪些指标,是生命周期中的 5 个重要环节的缩写,包括:用户获取(Acquisition)、用户激活(Activation)、用户留存(Retention)、收入(Revenue)、自传播(Refer)

以在线电子书为例,新用户从打开 APP 到购买,总共会经过这样一条包括以下四个主要环节的路径:
1.打开 APP 进入首页
2.进入书籍页面
3.开始试读
4.购书
每一个环节都只会有部分用户会走到下一个环节,走到的我们称为转化,没有走到的我们称为流失,这一系列环节就像一层层漏斗一样。对应的,我们将一层一层分析转化的方法称为漏斗(Funnel)分析法。通过漏斗分析法,我们就可以发现究竟在哪几层转化特别低值得优先改善。
从电子书平台后台抽取了用户数据,把数据存放在对应的变量名之中,具体如下:
首先把前10个最活跃用户ID找出来:
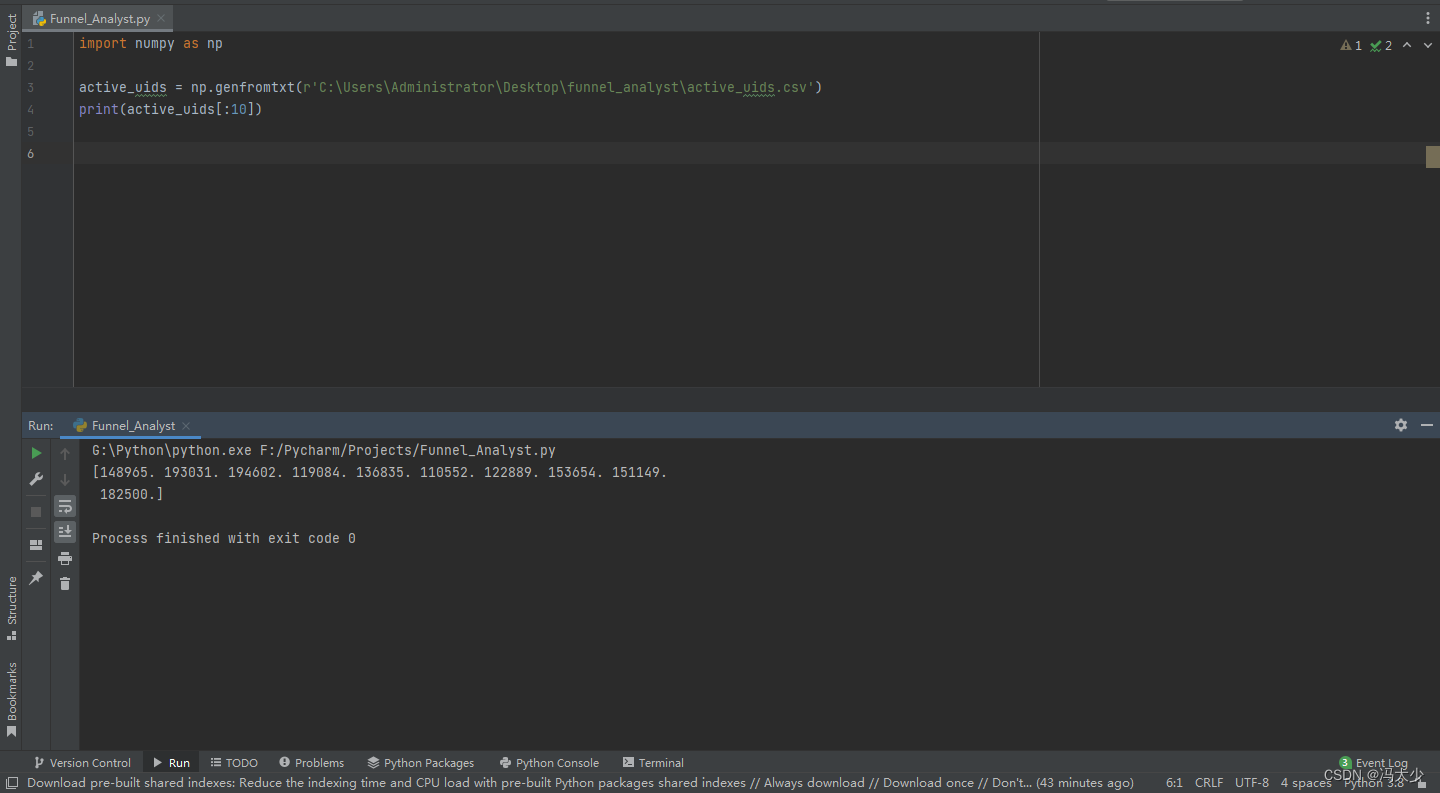
import numpy as np
active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
print(active_uids[:10])
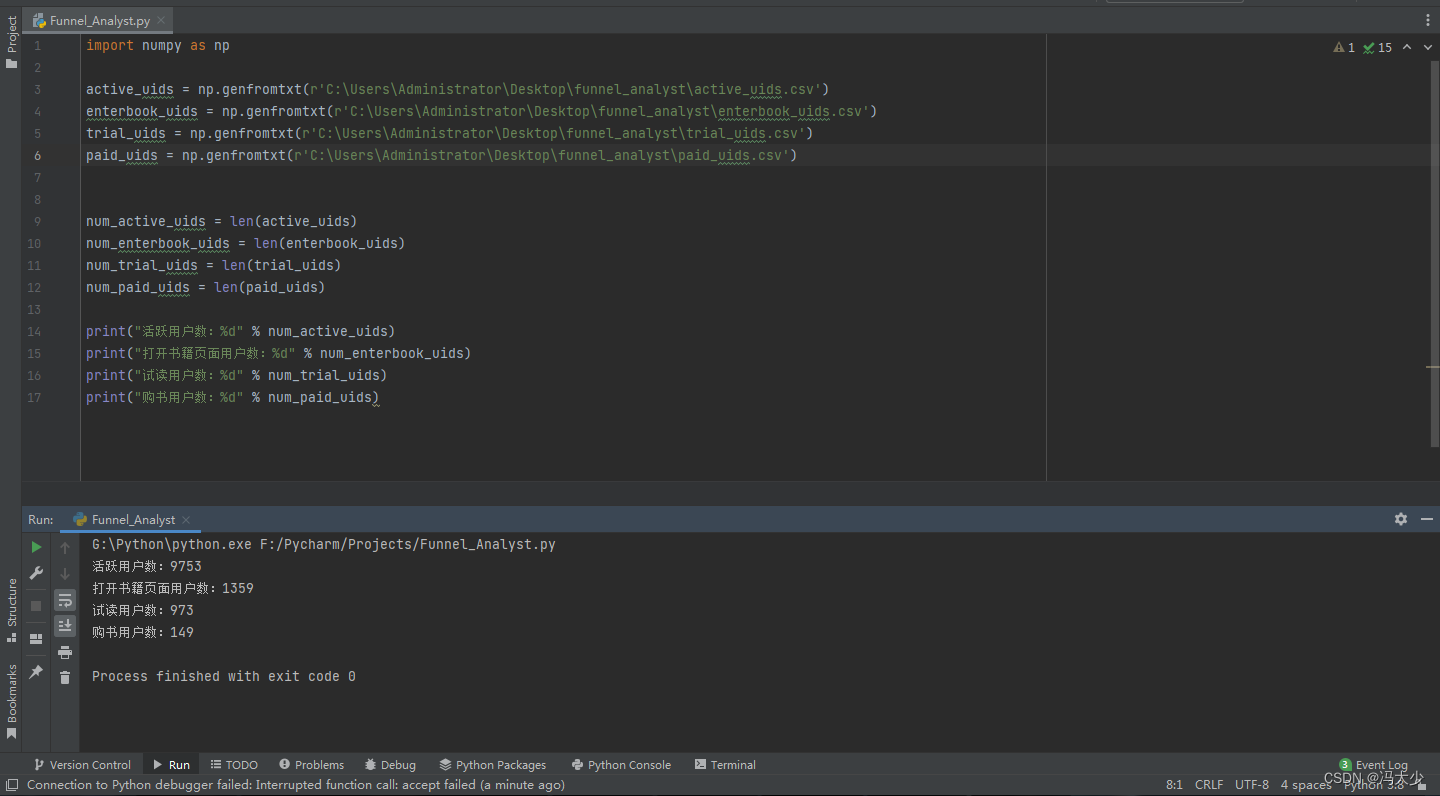
获取4种 ID 类型的数量:
import numpy as np
active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
num_active_uids = len(active_uids)
num_enterbook_uids = len(enterbook_uids)
num_trial_uids = len(trial_uids)
num_paid_uids = len(paid_uids)
print("活跃用户数:%d" % num_active_uids)
print("打开书籍页面用户数:%d" % num_enterbook_uids)
print("试读用户数:%d" % num_trial_uids)
print("购书用户数:%d" % num_paid_uids)
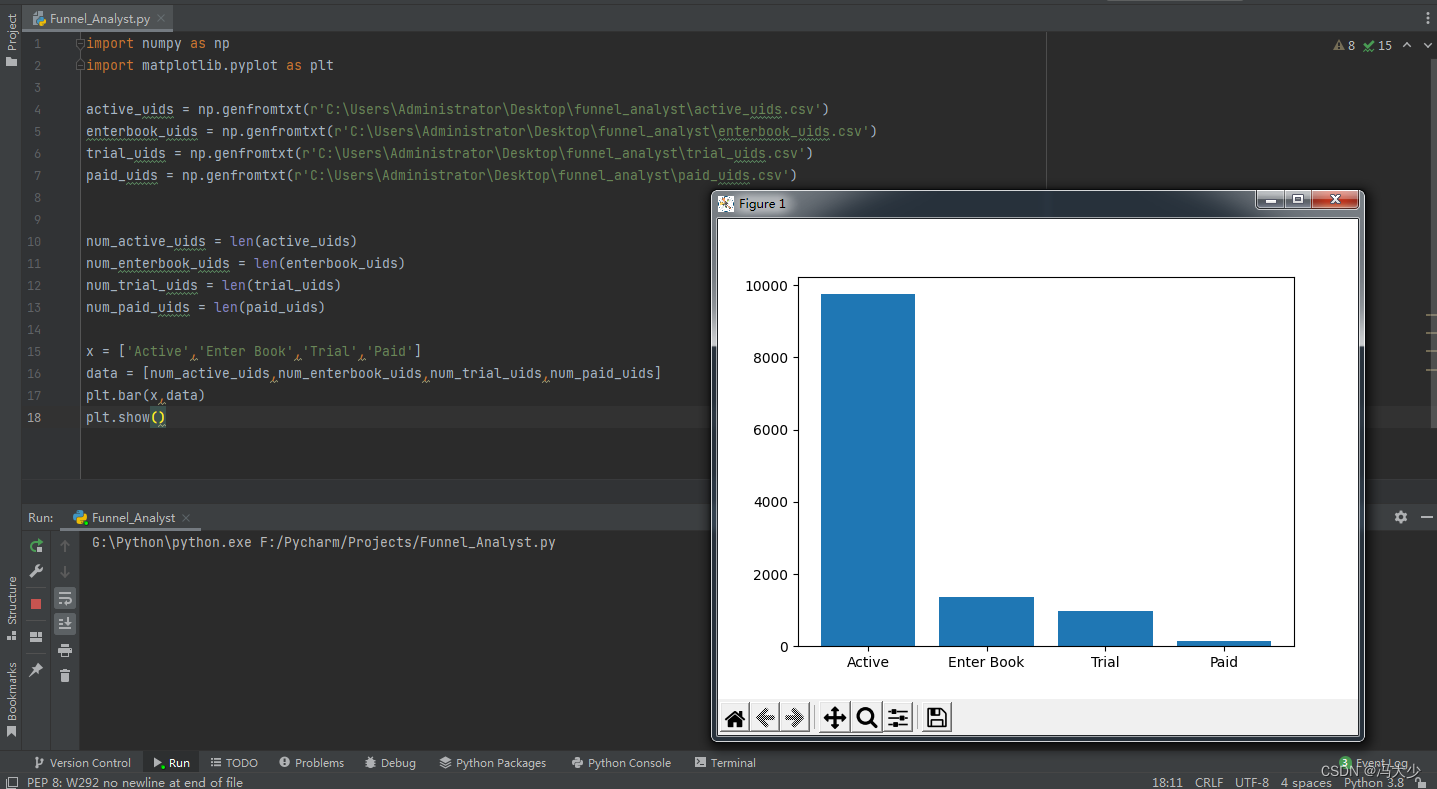
根据获取的 ID数,可以绘制一个直观的柱形图:
import numpy as np
import matplotlib.pyplot as plt
active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
num_active_uids = len(active_uids)
num_enterbook_uids = len(enterbook_uids)
num_trial_uids = len(trial_uids)
num_paid_uids = len(paid_uids)
x = ['Active','Enter Book','Trial','Paid']
data = [num_active_uids,num_enterbook_uids,num_trial_uids,num_paid_uids]
plt.bar(x,data)
plt.show()
在图中可以明显看到,从试读到购买的转化率不高。其实存在两条不同的购买转化路径,我们需要分别分析。
首先,我们分析那些进入书籍页,没有试读而直接购买的用户。这时候我们不能简单的看数字,而是要根据原始的用户 ID 来进行操作。经过试读再购买的用户 ID,一定同时属于试读用户的 ID,也属于购买用户的 ID,也就是 trial_uids 和 paid_uids 这两个列表间重合的部分 ID,就是经过试读再购买的用户 ID 了。
如何可以快速找到两个列表重合的部分呢? Python 有一个集合的方法可以快速去重。可以使用 intersection() 方法,执行 s.intersection(t) 。因为 s 和 t 的交集与 t 和 s 的交集是完全一致的,顺序并不重要。因此 t.intersection(s) 的效果也一样。最简单的写法是 s & t 或 t & s。
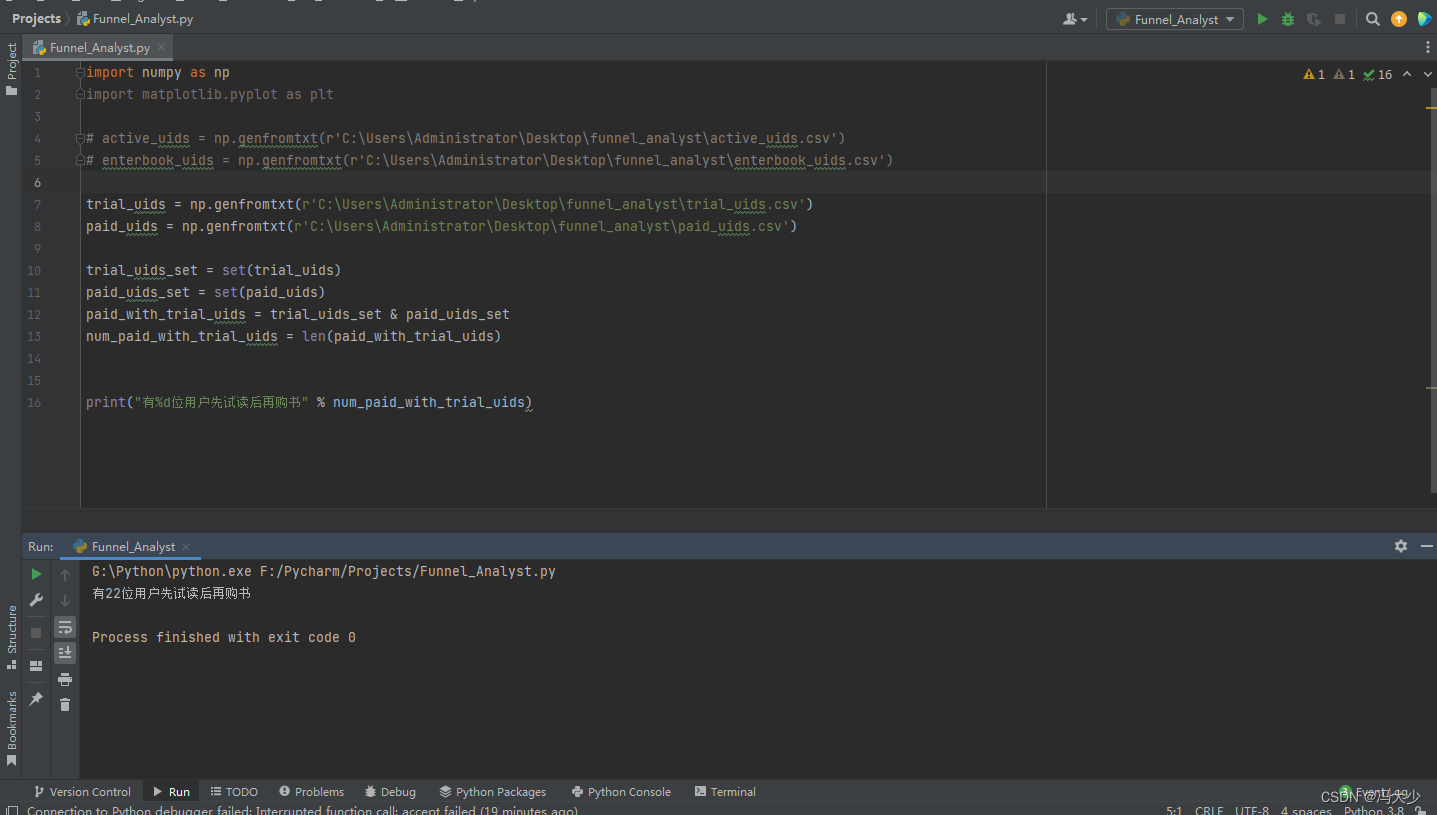
import numpy as np
# import matplotlib.pyplot as plt
# active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
# enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
trial_uids_set = set(trial_uids)
paid_uids_set = set(paid_uids)
paid_with_trial_uids = trial_uids_set & paid_uids_set
num_paid_with_trial_uids = len(paid_with_trial_uids)
print("有%d位用户先试读后再购书" % num_paid_with_trial_uids)
通过输出结果,得知有22位用户先试读后再购书。而没有试读就直接购买的用户 ID,一定存在于 paid_uids 中,且一定不存在于 trial_uids。只要对集合求差集,就可以得出结果。
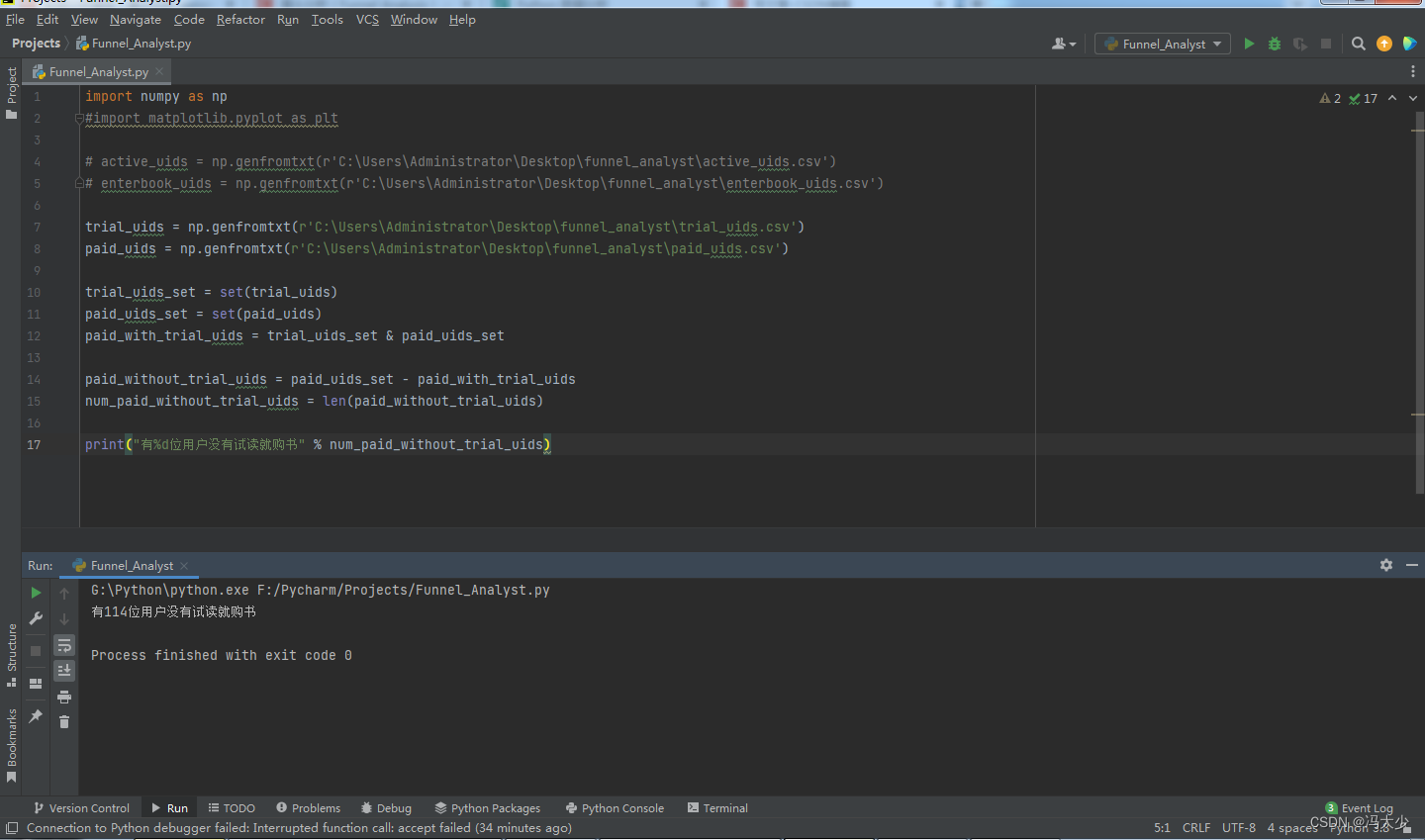
import numpy as np
#import matplotlib.pyplot as plt
# active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
# enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
trial_uids_set = set(trial_uids)
paid_uids_set = set(paid_uids)
paid_with_trial_uids = trial_uids_set & paid_uids_set
paid_without_trial_uids = paid_uids_set - paid_with_trial_uids
num_paid_without_trial_uids = len(paid_without_trial_uids)
print("有%d位用户没有试读就购书" % num_paid_without_trial_uids)
通过输出结果,得知有114位用户没有试读就购书。
我们就按照两个不同的路径,分别绘出两个漏斗,因为我们主要注意力放在用户进入书籍页后,所以可以暂时不管活跃用户那一层。
漏斗一:用户经过 进入书籍页面-试读书籍-试读后购买 三步。
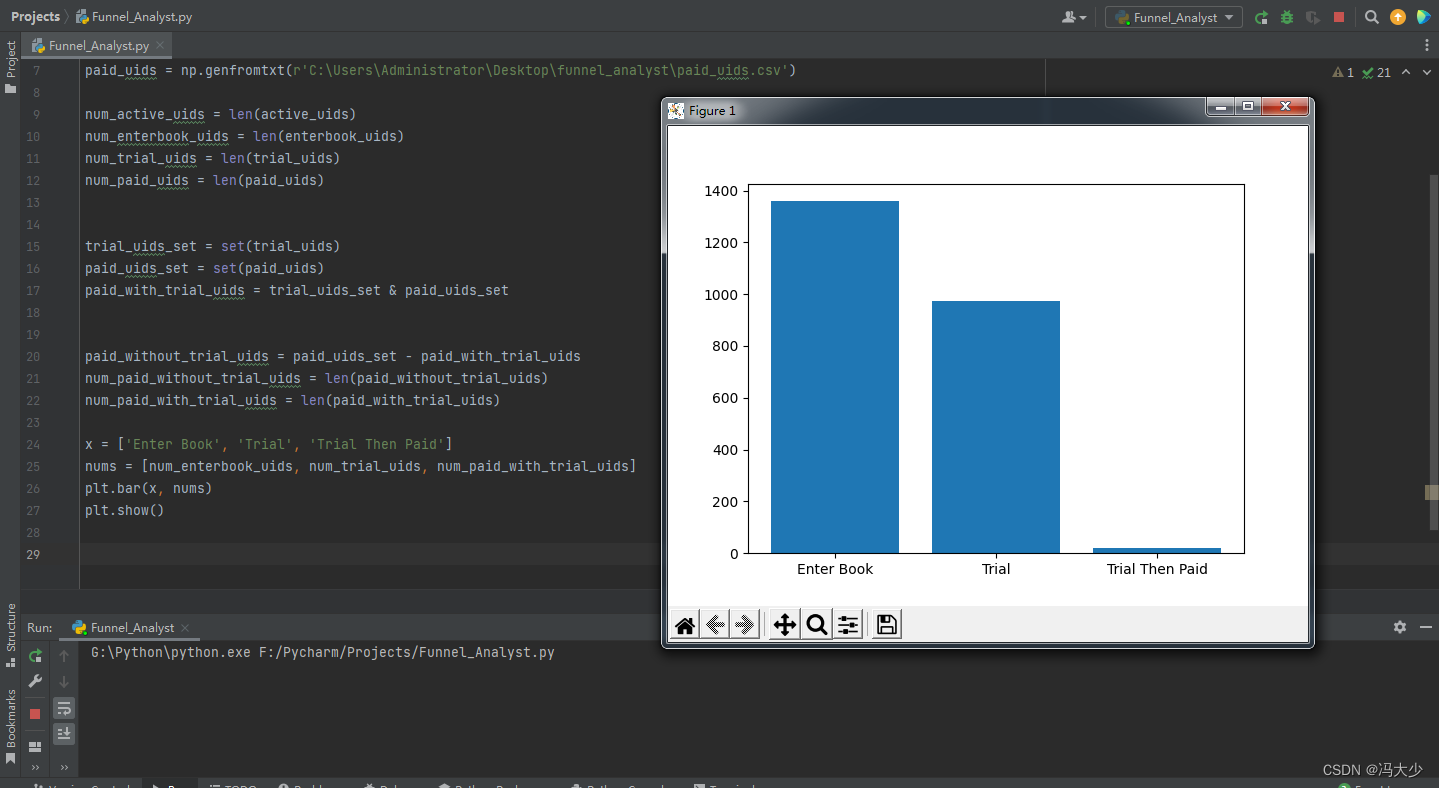
import numpy as np
import matplotlib.pyplot as plt
active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
num_active_uids = len(active_uids)
num_enterbook_uids = len(enterbook_uids)
num_trial_uids = len(trial_uids)
num_paid_uids = len(paid_uids)
trial_uids_set = set(trial_uids)
paid_uids_set = set(paid_uids)
paid_with_trial_uids = trial_uids_set & paid_uids_set
paid_without_trial_uids = paid_uids_set - paid_with_trial_uids
num_paid_without_trial_uids = len(paid_without_trial_uids)
num_paid_with_trial_uids = len(paid_with_trial_uids)
x = ['Enter Book', 'Trial', 'Trial Then Paid']
nums = [num_enterbook_uids, num_trial_uids, num_paid_with_trial_uids]
plt.bar(x, nums)
plt.show()
漏斗二:用户经过 进入书籍页面-直接购买 两步。
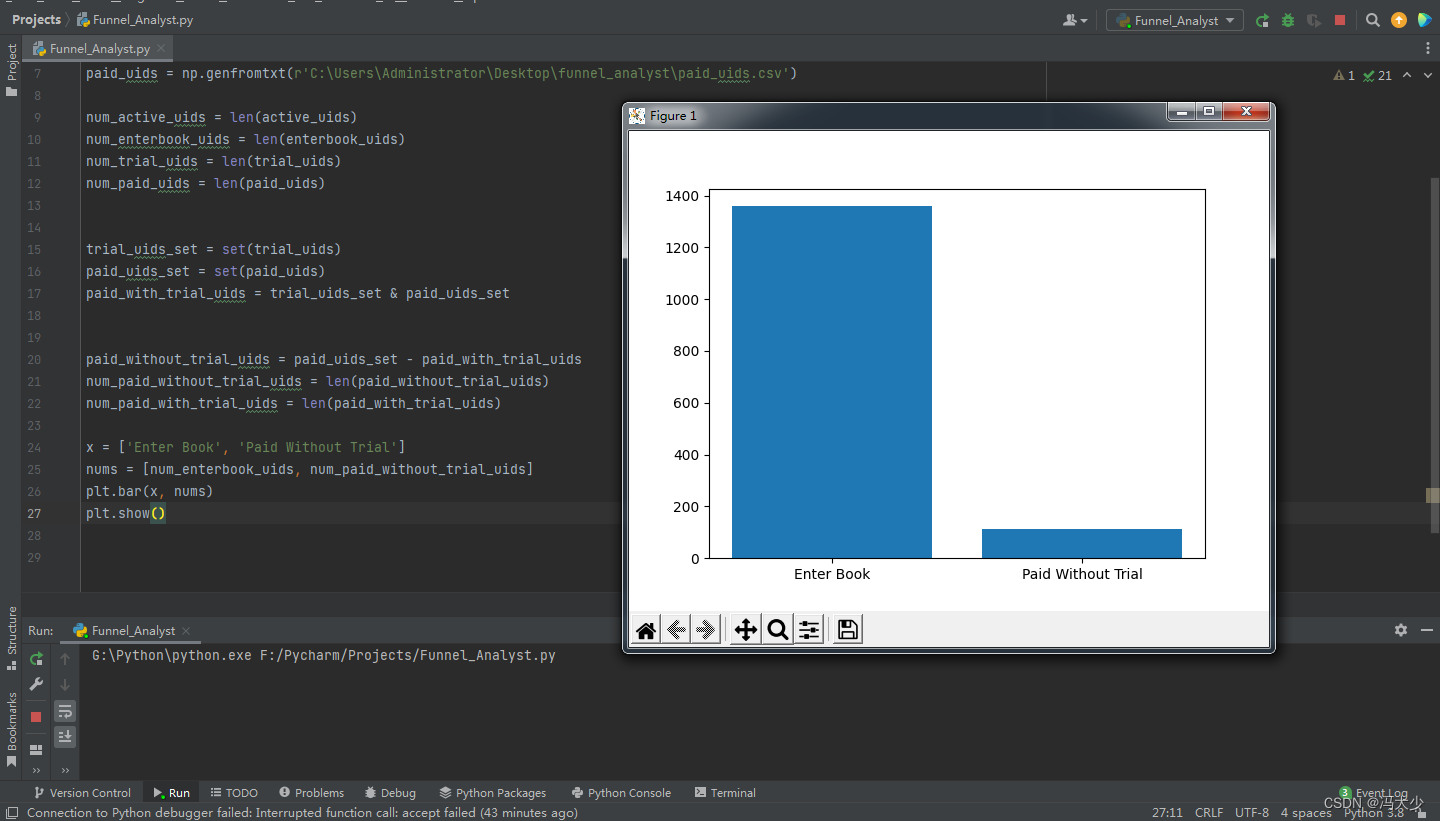
import numpy as np
import matplotlib.pyplot as plt
active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
num_active_uids = len(active_uids)
num_enterbook_uids = len(enterbook_uids)
num_trial_uids = len(trial_uids)
num_paid_uids = len(paid_uids)
trial_uids_set = set(trial_uids)
paid_uids_set = set(paid_uids)
paid_with_trial_uids = trial_uids_set & paid_uids_set
paid_without_trial_uids = paid_uids_set - paid_with_trial_uids
num_paid_without_trial_uids = len(paid_without_trial_uids)
num_paid_with_trial_uids = len(paid_with_trial_uids)
x = ['Enter Book', 'Paid Without Trial']
nums = [num_enterbook_uids, num_paid_without_trial_uids]
plt.bar(x, nums)
plt.show()
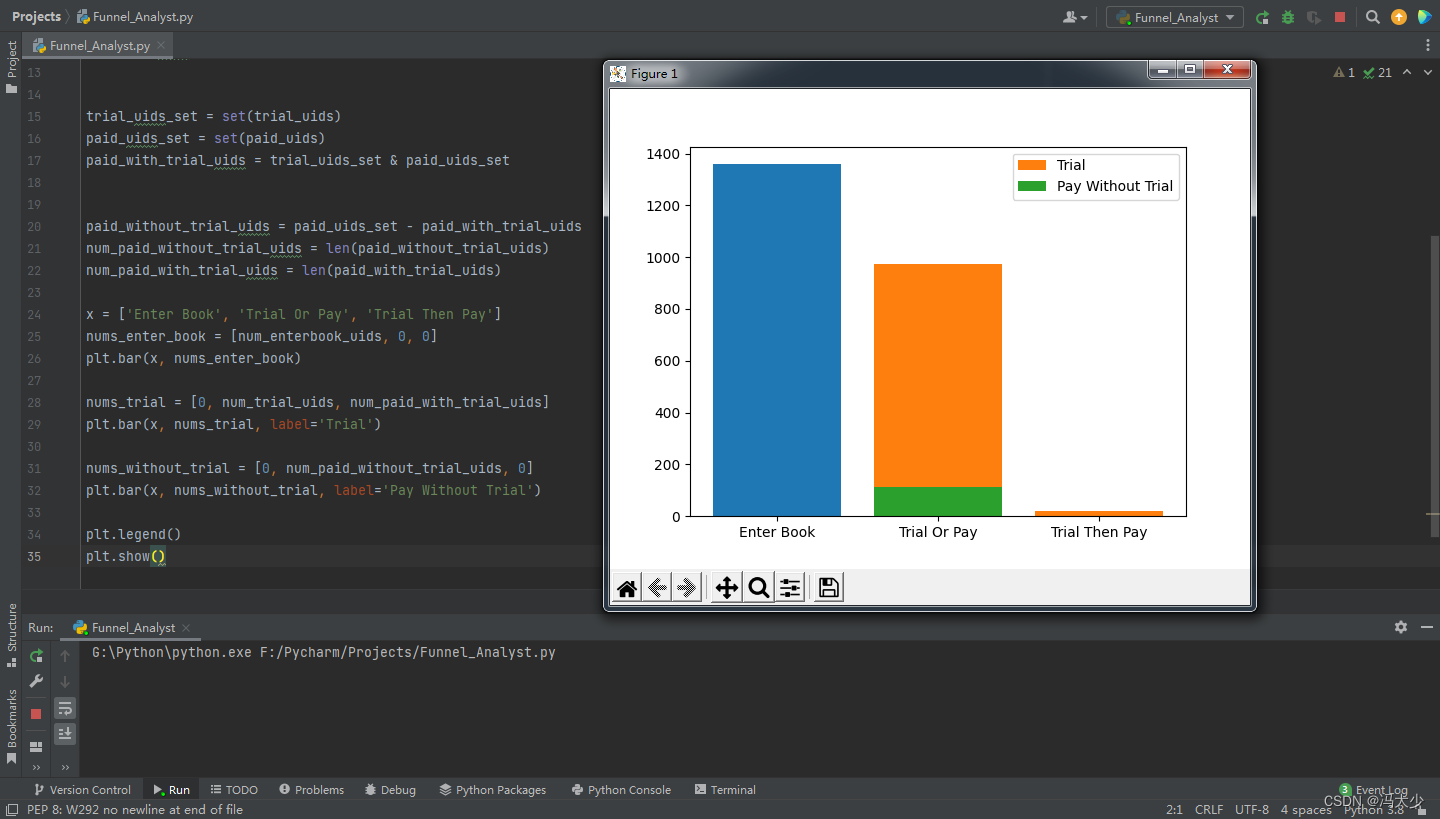
直接把这两个漏斗图画在一起 :
import numpy as np
import matplotlib.pyplot as plt
active_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\active_uids.csv')
enterbook_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\enterbook_uids.csv')
trial_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\trial_uids.csv')
paid_uids = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\paid_uids.csv')
num_active_uids = len(active_uids)
num_enterbook_uids = len(enterbook_uids)
num_trial_uids = len(trial_uids)
num_paid_uids = len(paid_uids)
trial_uids_set = set(trial_uids)
paid_uids_set = set(paid_uids)
paid_with_trial_uids = trial_uids_set & paid_uids_set
paid_without_trial_uids = paid_uids_set - paid_with_trial_uids
num_paid_without_trial_uids = len(paid_without_trial_uids)
num_paid_with_trial_uids = len(paid_with_trial_uids)
x = ['Enter Book', 'Trial Or Pay', 'Trial Then Pay']
nums_enter_book = [num_enterbook_uids, 0, 0]
plt.bar(x, nums_enter_book)
nums_trial = [0, num_trial_uids, num_paid_with_trial_uids]
plt.bar(x, nums_trial, label='Trial')
nums_without_trial = [0, num_paid_without_trial_uids, 0]
plt.bar(x, nums_without_trial, label='Pay Without Trial')
plt.legend()
plt.show()
从图可见,在漏斗的第二层,也就是对应用户进入书籍页的第二步,绝大部分(973)用户选择了试读,少部分(114)用户选择了直接购买;但是试读用户后续只有 22 位购书,也就是说,经过试读的用户再购书的数量和转换,远远小于那些一进书籍页直接买书的用户。于是,我们就产生一个大胆的想法——试读究竟有没有用?如果取消会怎样,是否会增加?如果我们决定先取消试读功能,然后观察和比较购买转化率,这个结果很可能不客观。因为外部环境是随时间不断发生变化的,如果在不同的日期做实验,即便结果上有差别,那么我们很难解释这个差别是因为我们在 APP 上的更改导致,还是因为日期本身导致,因为不同的日期(例如周末、节假日、双十一)对用户消费行为是会产生影响的。
我们可以引入A/B 测试,就是如果一个产品有多个版本想要进行比较和取舍,就在同一段时间内,将目标人群随机的分成相等数量的多组,每组使用不同版本的产品,然后比较结果。

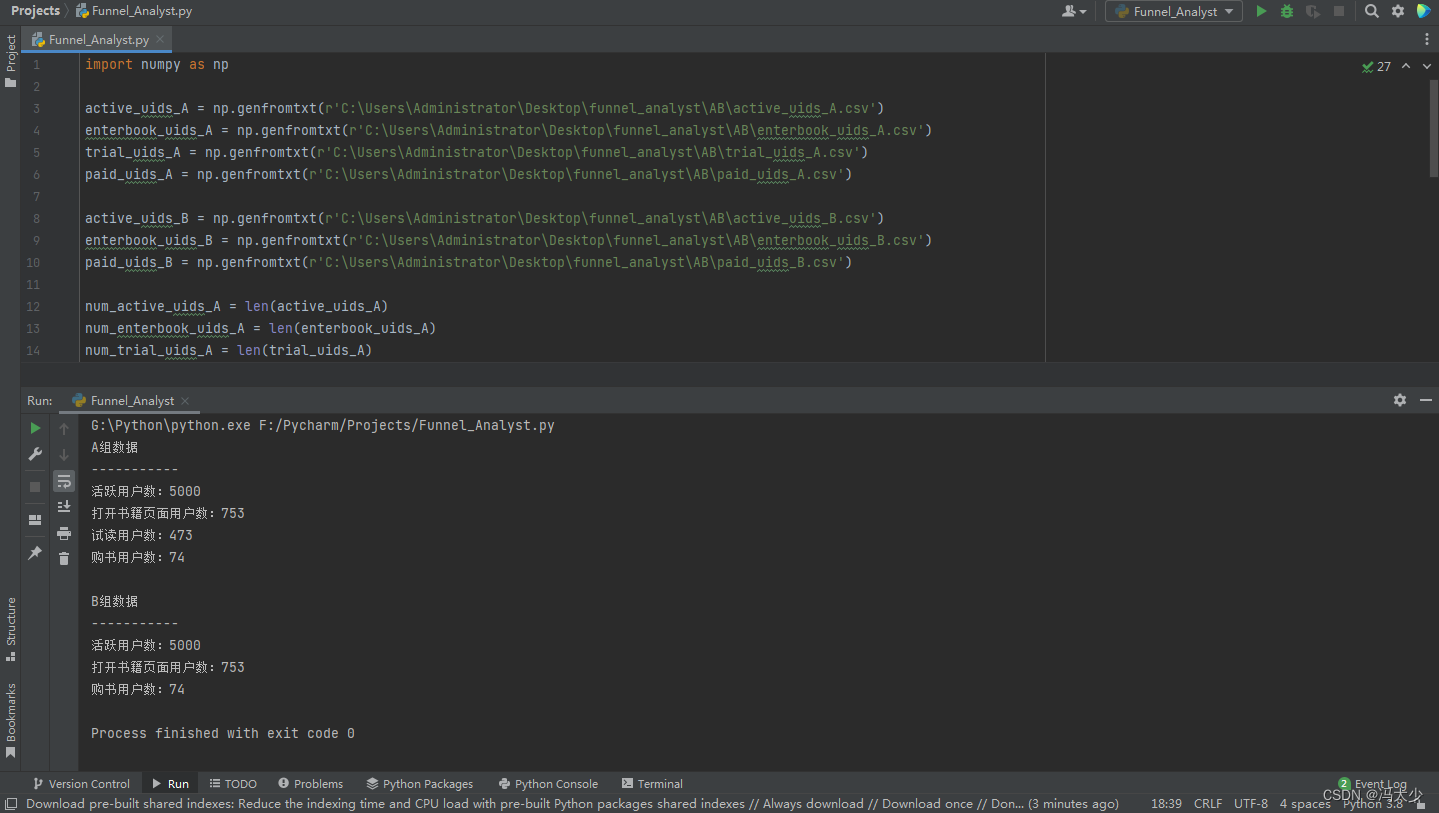
经过 AB测试后, 从电子书后台获取 A、B 两组的实验数据,并定义2组 的变量名。
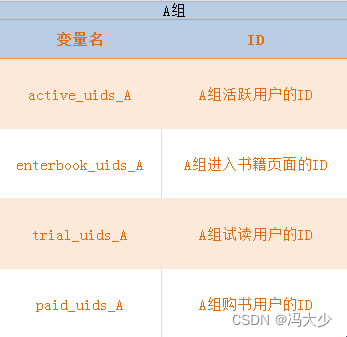
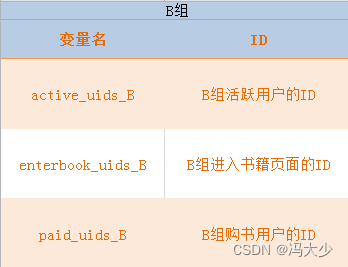
import numpy as np
active_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\active_uids_A.csv')
enterbook_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\enterbook_uids_A.csv')
trial_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\trial_uids_A.csv')
paid_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\paid_uids_A.csv')
active_uids_B = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\active_uids_B.csv')
enterbook_uids_B = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\enterbook_uids_B.csv')
paid_uids_B = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\paid_uids_B.csv')
num_active_uids_A = len(active_uids_A)
num_enterbook_uids_A = len(enterbook_uids_A)
num_trial_uids_A = len(trial_uids_A)
num_paid_uids_A = len(paid_uids_A)
num_active_uids_B = len(active_uids_A)
num_enterbook_uids_B = len(enterbook_uids_A)
num_paid_uids_B = len(paid_uids_A)
print("A组数据")
print("-----------")
print("活跃用户数:%d" % num_active_uids_A)
print("打开书籍页面用户数:%d" % num_enterbook_uids_A)
print("试读用户数:%d" % num_trial_uids_A)
print("购书用户数:%d" % num_paid_uids_A)
print(" ")
print("B组数据")
print("-----------")
print("活跃用户数:%d" % num_active_uids_B)
print("打开书籍页面用户数:%d" % num_enterbook_uids_B)
print("购书用户数:%d" % num_paid_uids_B)
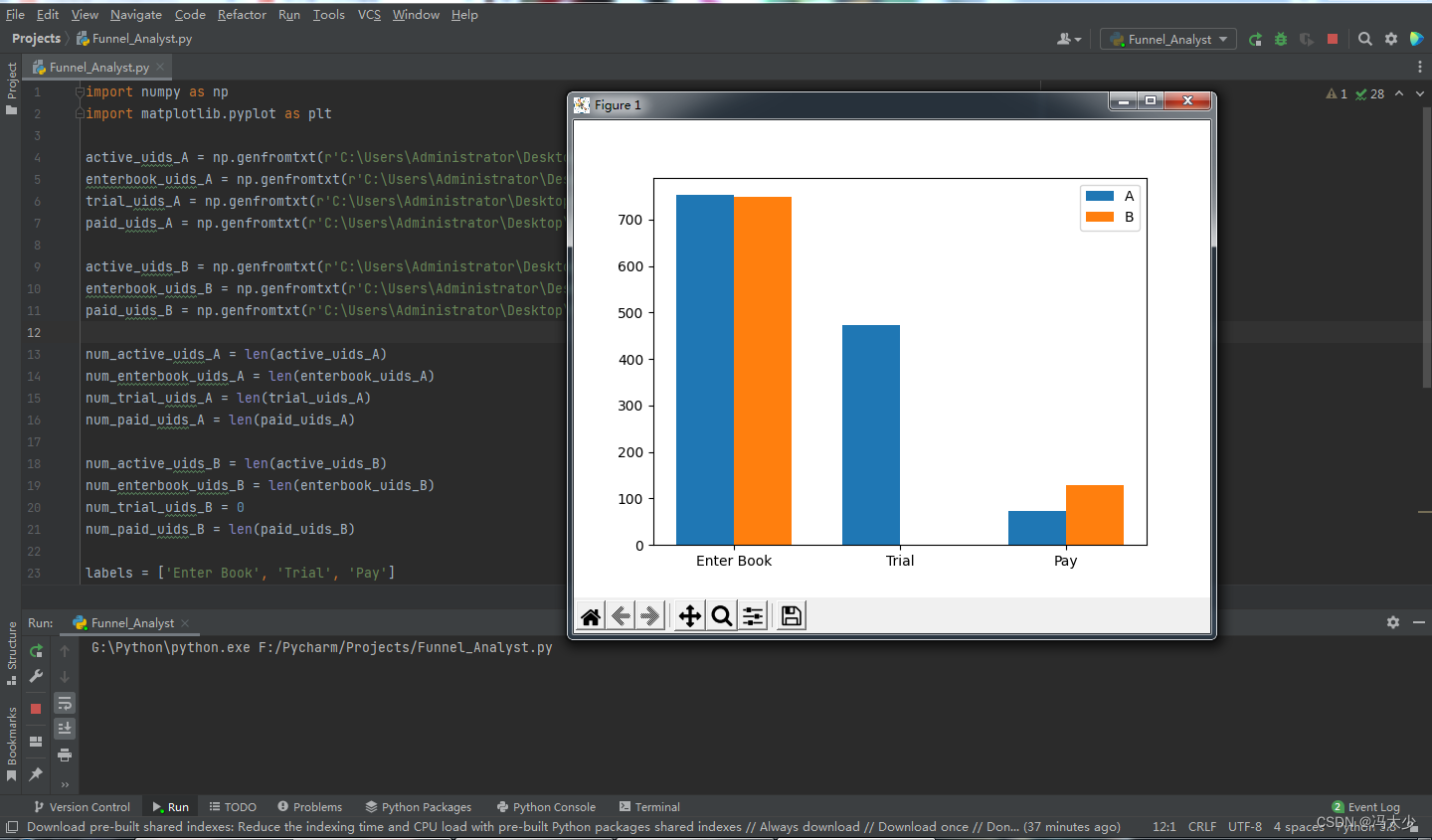
得出以上A、B 两组关键数据后, 再次用柱状图来比较两组的购买转换漏斗:
import numpy as np
import matplotlib.pyplot as plt
active_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\active_uids_A.csv')
enterbook_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\enterbook_uids_A.csv')
trial_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\trial_uids_A.csv')
paid_uids_A = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\paid_uids_A.csv')
active_uids_B = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\active_uids_B.csv')
enterbook_uids_B = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\enterbook_uids_B.csv')
paid_uids_B = np.genfromtxt(r'C:\Users\Administrator\Desktop\funnel_analyst\AB\paid_uids_B.csv')
num_active_uids_A = len(active_uids_A)
num_enterbook_uids_A = len(enterbook_uids_A)
num_trial_uids_A = len(trial_uids_A)
num_paid_uids_A = len(paid_uids_A)
num_active_uids_B = len(active_uids_B)
num_enterbook_uids_B = len(enterbook_uids_B)
num_trial_uids_B = 0
num_paid_uids_B = len(paid_uids_B)
labels = ['Enter Book', 'Trial', 'Pay']
data_A = [num_enterbook_uids_A, num_trial_uids_A, num_paid_uids_A]
data_B = [num_enterbook_uids_B, num_trial_uids_B, num_paid_uids_B]
x = np.arange(len(labels))
width = 0.35
plt.bar(x - width/2, data_A, width, label='A')
plt.bar(x + width/2, data_B, width, label='B')
plt.xticks(x, labels)
plt.legend()
plt.show()
我们可以发现在进入书籍页这一层,A、B 两组的数据是差不多的,因为我们的测试是针对书籍页面内部的试读按钮,并不会影响用户从书籍首页进入书籍页的判断,因为此时他们就看不到书籍页面长什么样。同时也可以看到 B 组支付的数据是明显高于 A 组的。我们是不是可以下结论,取消了试读后,销量会更好呢?经过把这个 AB 测试持续了一周,发现每天的结果都和第一天一样,也证明这测试的有效性。
虽然数据验证了取消试读后用户反而更愿意购买,但是这背后的原因是什么呢?明明其它在线阅读软件、平台都有试读功能,难道他们都错了吗?因此要更深入了解原因,就必须分析试读的这部分用户的行为和数据。
用户开始试读后,第一次进入书籍阅读页面后,有以下三种可能的行为:
读书
下一页
退出阅读
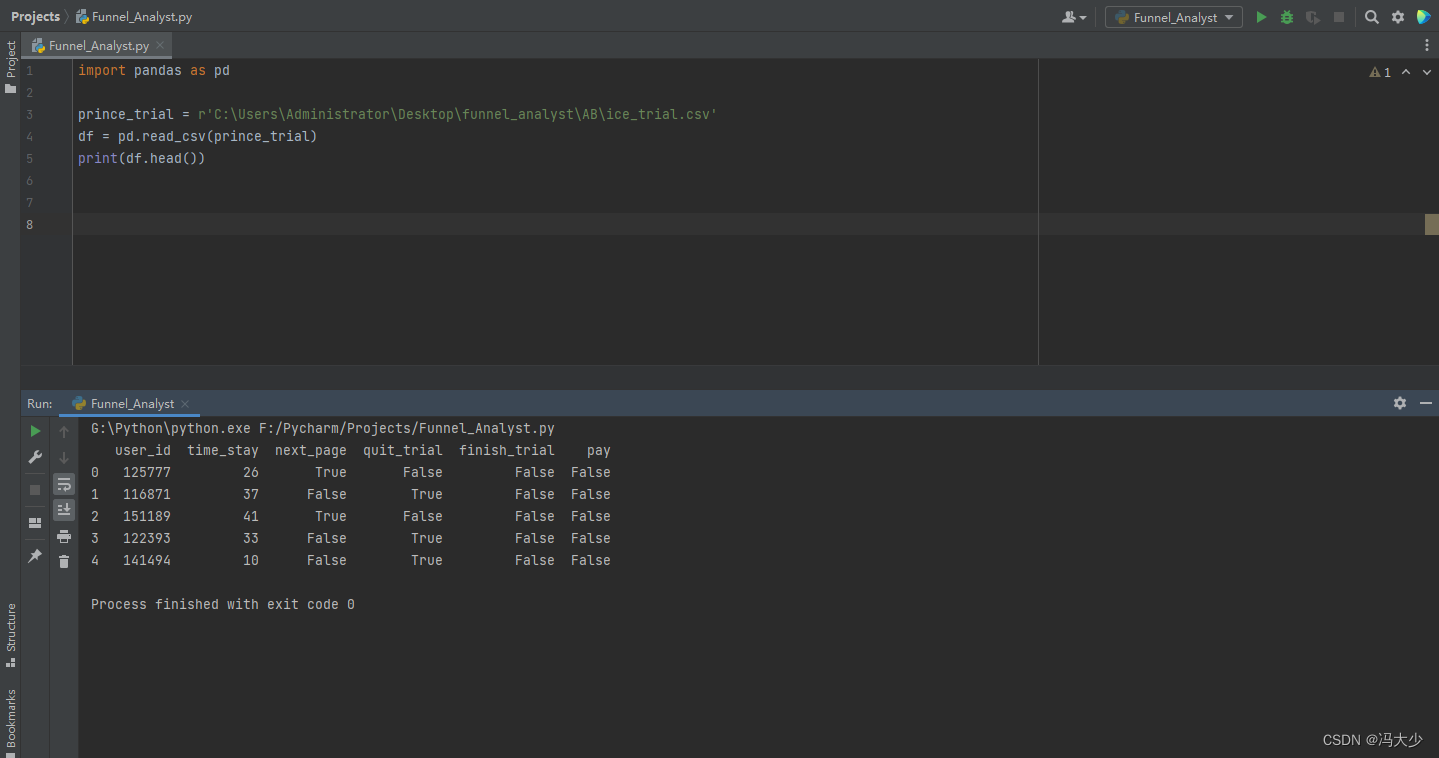
那我们就研究一下用户是怎样进行行为选择的。下一页、退出阅读都是对应具体的按钮,程序可以检测用户有没有点击这两个按钮,但是用户有没有读书,我们怎么知道呢?虽然我们不能直接知道用户有没有在读书,但是可以知道用户花了多少时间停留在这个阅读界面上啊,除去极少数例外,用户停留的时间越长,越有可能在读书。 于是,我们通过调用过去一周 这电子书的试读数据去深入分析:
import pandas as pd
prince_trial = r'C:\Users\Administrator\Desktop\funnel_analyst\AB\ice_trial.csv'
df = pd.read_csv(prince_trial)
print(df.head())
我们得到以上前5的数据,各自
user_id:用户 ID
time_stary: 停留时间(s)
next_page:是否点击下一页
quit_trial:退出阅读
finish_trial:完成试读
pay:购买
以第一行为例,表示 ID 为 125777 的用户试读了,在第一页停留了 26 秒,点击了下一页,没有选择退出阅读,没有完成试读,最终没有购买。
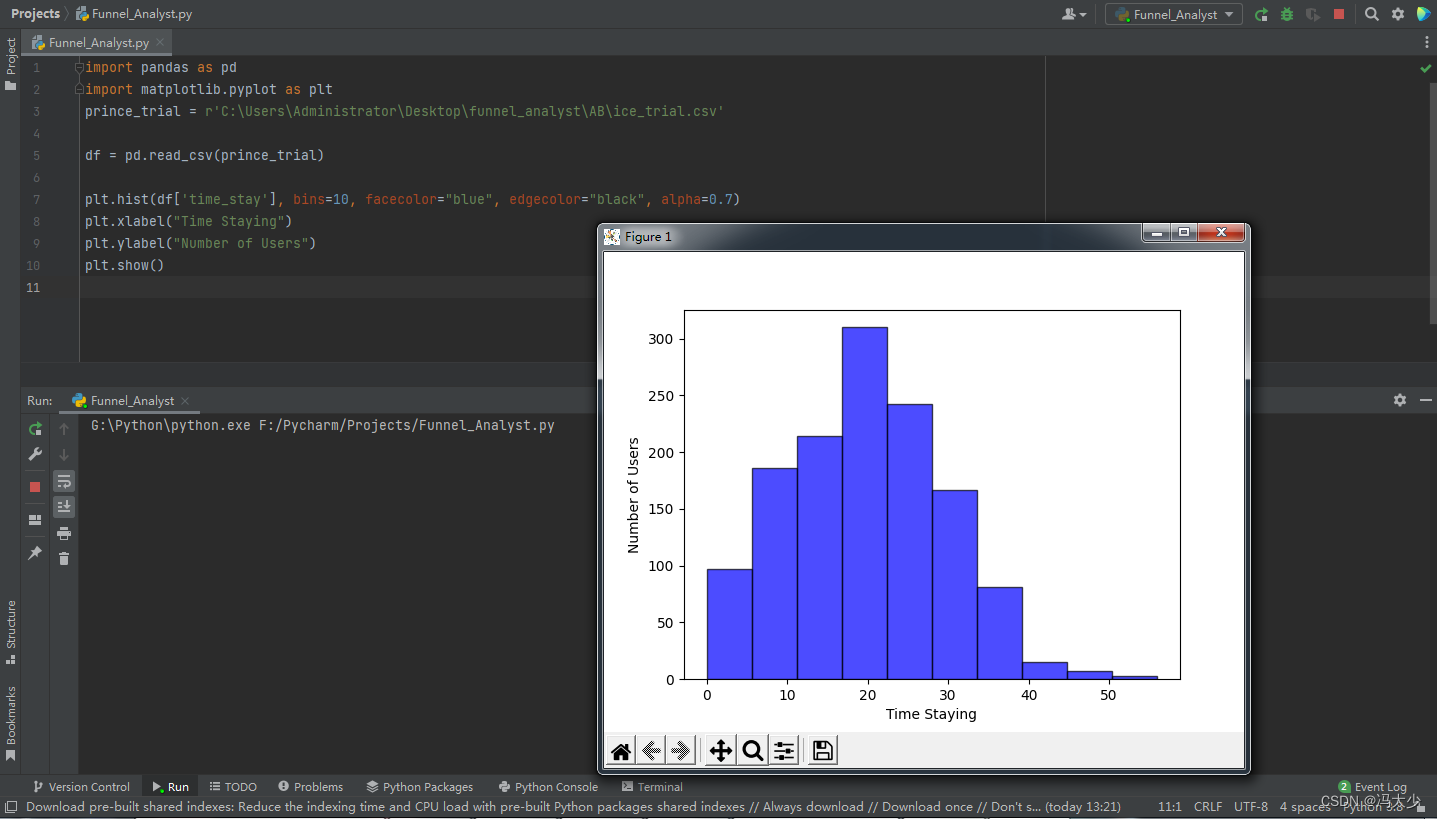
分析用户的停留时间分布:
import pandas as pd
import matplotlib.pyplot as plt
prince_trial = r'C:\Users\Administrator\Desktop\funnel_analyst\AB\ice_trial.csv'
df = pd.read_csv(prince_trial)
plt.hist(df['time_stay'], bins=10, facecolor="blue", edgecolor="black", alpha=0.7)
plt.xlabel("Time Staying")
plt.ylabel("Number of Users")
plt.show()
可以发现,绝大部分试读用户在第一页的停留时间,不超过 30 秒,如果不超过 30 秒,很显然是读不完一页内容的,他们点击下一页的可能性应该也不大。为了验证这个猜想,我们将用户分成两组,一组阅读时间在 30 秒及以下,另一组在 30 秒以上,分别观察点击下一页的比例是多少?
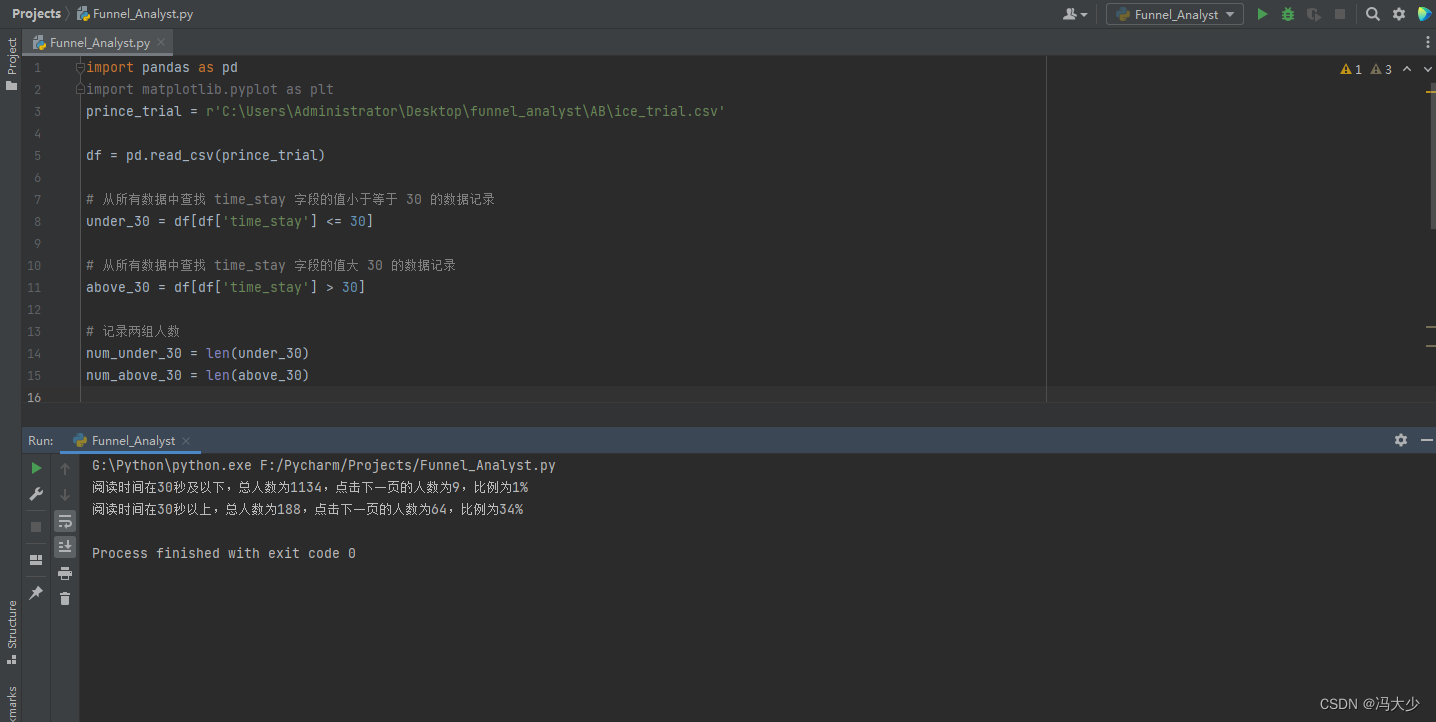
import pandas as pd
import matplotlib.pyplot as plt
prince_trial = r'C:\Users\Administrator\Desktop\funnel_analyst\AB\ice_trial.csv'
df = pd.read_csv(prince_trial)
# 从所有数据中查找 time_stay 字段的值小于等于 30 的数据记录
under_30 = df[df['time_stay'] <= 30]
# 从所有数据中查找 time_stay 字段的值大 30 的数据记录
above_30 = df[df['time_stay'] > 30]
# 记录两组人数
num_under_30 = len(under_30)
num_above_30 = len(above_30)
under_30_and_next_page = under_30[under_30['next_page']]
above_30_and_next_page = above_30[above_30['next_page']]
num_under_30_and_next_page = len(under_30_and_next_page)
num_above_30_and_next_page = len(above_30_and_next_page)
ratio_under_30_and_next_page = num_under_30_and_next_page / num_under_30
ratio_above_30_and_next_page = num_above_30_and_next_page / num_above_30
print("阅读时间在30秒及以下,总人数为%d,点击下一页的人数为%d,比例为%.0f%%" %
(num_under_30, num_under_30_and_next_page, 100 * ratio_under_30_and_next_page))
print("阅读时间在30秒以上,总人数为%d,点击下一页的人数为%d,比例为%.0f%%" %
(num_above_30, num_above_30_and_next_page, 100 * ratio_above_30_and_next_page))
这样我们就可以得出以下的比例结果:
阅读时间在30秒及以下,总人数为1134,点击下一页的人数为9,比例为1%
阅读时间在30秒以上,总人数为188,点击下一页的人数为64,比例为34%
我们已经发现了阅读时间和用户是否点下一页,甚至和购买之间的相关关系,那么,我们是不是可以说,只要想办法让用户阅读时间变长,就能最终增加购买呢?相关性不代表因果性。例如,一家超市发现雪糕和空调的销售量之间存在相关关系,并不代表超市想办法增加雪糕的销量,就能相应增加空调销量。因为夏天到了天气炎热才是这两者销量同时上升的原因。
在产品里,很可能有一个因素,会同时导致用户阅读时间短,以及不愿意购买,是什么因素呢?这时候,我们又想到,用户看不懂一本中文书的主要原因是因为内容太复杂,而看不懂英文书则很可能是因为英语能力不够。所以说,那么多放弃的用户,是不是因为虽然想读英文版的,但是真的去读了,发现自己的英语能力不够所以直接放弃了呢?要验证这点,我们要么能够找到足够多的用户去做问卷调查和访谈,要么也可以在产品里直接询问用户。于是我们在用户点返回的环节上,做了一个弹窗,询问用户为什么放弃,是对内容本身不感兴趣,还是觉得太难,还是两者都有,或者都不是。
通过搜集几天的数据,得到如下反馈数据:
不感兴趣 : 152
看不懂英文 : 888
两者都是 : 122
其他原因: 130
通过绘制一个饼图来直观的显示反馈数据:
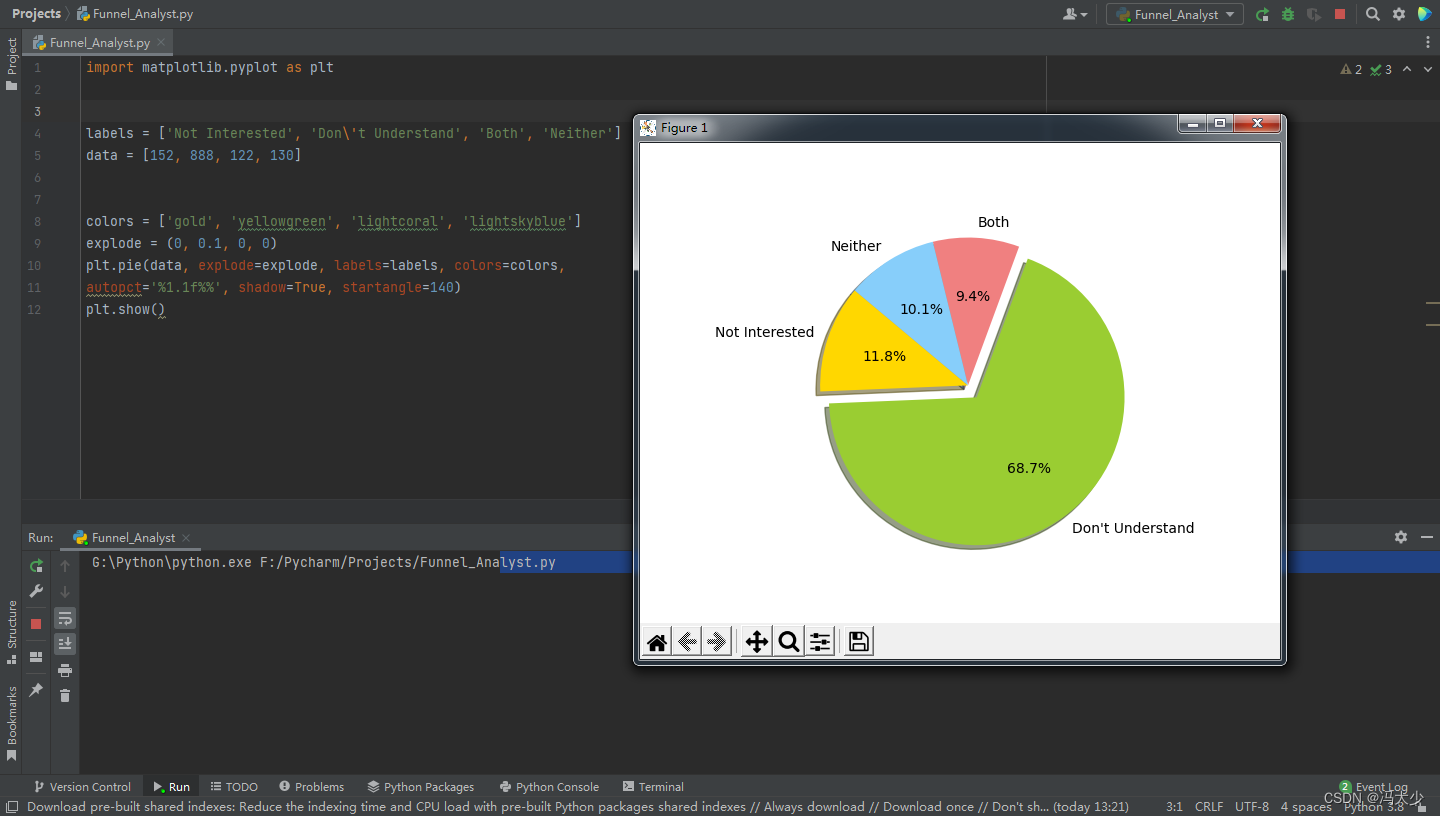
import matplotlib.pyplot as plt
labels = ['Not Interested', 'Don\'t Understand', 'Both', 'Neither']
data = [152, 888, 122, 130]
colors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue']
explode = (0, 0.1, 0, 0)
plt.pie(data, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=140)
plt.show()
现在我们可以确认了,之前 AB 测试中,A 组中选择了试读的大部分用户,的确是因为在试读阶段发现看不懂就草草放弃了;而 B 组的用户因为没有试读机会,很多本来看不懂的用户并不知道自己看不懂,于是先买了再说。而中文书阅读 APP 为什么可以大大方方的提供试读功能,是因为试读后因为看不懂就放弃购买的可能性不大。所以,我们完整的经历了一个发现问题、提出假设、试验分析、提出方案的过程。在这个过程中,数据分析发挥了不可或缺但是并非唯一的作用,因为发现问题和提出假设需要洞察力,提出方案需要创造力,这些能力并非仅仅看数字就能获得。因此,数据分析只是帮助我们发现问题的手段,我们可以将数据作为分析的起点,但是切勿作为分析的终点,一定要深入了解用户,在原理上弄明白他们的使用场景和遇到的困境,才能够持续迭代产品,也让自己不停地进步。

![[附源码]计算机毕业设计基于Vue的社区拼购商城Springboot程序](https://img-blog.csdnimg.cn/005011ba90164b02a28520def08818da.png)





![[论文分享] DnD: A Cross-Architecture Deep Neural Network Decompiler](https://img-blog.csdnimg.cn/7cd353a008d6430db17b0449437dd7ea.png)
