文本根据词典进行纠错
输入一段可能带有错误信息的文字, 通过词典来检测其中可能错误的词。
例如:有句子如下:中央人民政府驻澳门特别行政区联络办公室1日在机关大楼设灵堂
有词典如下:中国人民,中央人民,澳门,西门
检测时,根据词典可以得出句子中的中央人民可能为中国人民,澳门可能为西门,并返回结果
处理逻辑如下:
- 首先对词典进行逐字打码,例如中国人民处理成:*国人民,中*人民,中国*民,中国人*,并返回一个index_list记录对应的位置和打码的位置(后面才可以根据这个index_list找到候选词)。
- 接着对句子进行N-gram,比如检测第二个字央时,设置n为4(一般都处理为4),处理成:中央,中央人,中央人民,央人,央人民,央人民政,并对央打码,处理成:中*,中*人,中*人民,*人,*人民,*人民政
- 最后与上述处理完的词典进行对比,如果找到相同的比如:词典里面的 中*人民 与 检测央时返回的N-gram里面的 中*人民相同,便根据index_list找到词典中的中国人民,由此可得,央字的候选词为国。如下:{‘correction’: ‘国’, ‘index’: 1, ‘candidate’: [‘中国人民’], ‘original’: ‘央’}
实现代码如下:
- 对词典进行处理:
def get_new_dict(dict):
'''
将词典逐字打码
:param dict:
:return: 新词典以及对应的index
'''
new_dict = []
index_list = []
for j in range(len(dict)):
for i in range(len(dict[j])):
if i < len(dict[j]):
new_dic = dict[j][:i] + '*' + dict[j][i+1:]
else:
new_dic = dict[j][:i] + '*'
new_dict.append(new_dic)
index_list.append((j,i))
return new_dict,index_list
#测试:
dicts = ['中国人民','中央人民','澳门','西门']
new_dict,index_list = get_new_dict(dicts)
print(new_dict)
print("**********************")
print(index_list)
输出:
index_list的元组第一个值表示词典的索引位置,第二个值表示对应这个词打码位置的索引

- 对句子进行N-gram
def get_ngram(content,loc,n):
'''
切分Ngram.函数为根据索引位置切分,如果想切分整个content,只需要加一个循环使loc从0到len(conten)-1
:param content: 原文
:param loc: 想要检测的字的索引位置
:param n: 切分长度
:return: ngram
'''
i_min = loc-n+1 if loc-n+1 >= 0 else 0
i_max = loc+1
j_min = loc+1
j_max = loc+1+n if loc+1+n < len(content) else loc+1+1
ngram_list = []
for i in range(i_min,i_max):
for j in range(j_min,j_max):
if j-i > 4 or j - i < 2:
continue
ngram_list.append(content[i:j].replace(content[loc],'*'))
return ngram_list
#测试
content = '中央人民政府驻澳门特别行政区联络办公室1日在机关大楼设灵堂'
loc = 1
ngram_list = get_ngram(content,loc,n=4)
print(ngram_list)
输出:

- 最后进行词典与N-gram的比对并返回相应结果:
def get_result(ngram_list,new_dict,index_list,loc,original,dicts):
'''
获取结果
:param ngram_list: 原文分割后的Ngram
:param new_dict: 打码处理后的字典
:param index_list: 处理后的字典对应的索引位置
:param loc: 检测字的索引位置
:param original: 检测的字
:param dicts: 原始词典
:return:
'''
candidate = []
error_dic = {}
for word in ngram_list:
if word in new_dict:
indexs = [i for (i, v) in enumerate(new_dict) if v == word]
for index in indexs:
index = index_list[index]
correction = dicts[index[0]][index[1]]
if original == correction:
continue
candidate.append(dicts[index[0]])
error_dic['correction'] = correction
error_dic['index'] = loc
error_dic['candidate'] = candidate
error_dic['original'] = original
return error_dic
#测试
original = content[loc]
error_dic = get_result(ngram_list,new_dict,index_list,loc,original,dicts)
print(error_dic)
输出:
{‘correction’: ‘国’, ‘index’: 1, ‘candidate’: [‘中国人民’], ‘original’: ‘央’}
完整代码如下:
def get_ngram(content,loc,n):
'''
切分Ngram.函数为根据索引位置切分,如果想切分整个content,只需要加一个循环使loc从0到len(conten)-1
:param content: 原文
:param loc: 想要检测的字的索引位置
:param n: 切分长度
:return: ngram
'''
i_min = loc-n+1 if loc-n+1 >= 0 else 0
i_max = loc+1
j_min = loc+1
j_max = loc+1+n if loc+1+n < len(content) else loc+1+1
ngram_list = []
for i in range(i_min,i_max):
for j in range(j_min,j_max):
if j-i > 4 or j - i < 2:
continue
ngram_list.append(content[i:j].replace(content[loc],'*'))
return ngram_list
def get_new_dict(dict):
'''
将词典逐字打码
:param dict:
:return: 新词典以及对应的index
'''
new_dict = []
index_list = []
for j in range(len(dict)):
for i in range(len(dict[j])):
if i < len(dict[j]):
new_dic = dict[j][:i] + '*' + dict[j][i+1:]
else:
new_dic = dict[j][:i] + '*'
new_dict.append(new_dic)
index_list.append((j,i))
return new_dict,index_list
def get_result(ngram_list,new_dict,index_list,loc,original,dicts):
'''
获取结果
:param ngram_list: 原文分割后的Ngram
:param new_dict: 打码处理后的字典
:param index_list: 处理后的字典对应的索引位置
:param loc: 检测字的索引位置
:param original: 检测的字
:param dicts: 原始词典
:return:
'''
candidate = []
error_dic = {}
for word in ngram_list:
if word in new_dict:
indexs = [i for (i, v) in enumerate(new_dict) if v == word]
for index in indexs:
index = index_list[index]
correction = dicts[index[0]][index[1]]
if original == correction:
continue
candidate.append(dicts[index[0]])
error_dic['correction'] = correction
error_dic['index'] = loc
error_dic['candidate'] = candidate
error_dic['original'] = original
return error_dic
#测试
#测试
dicts = ['中国人民','中央人民','澳门','西门']
content = '中央人民政府驻澳门特别行政区联络办公室1日在机关大楼设灵堂'
loc = 7
original = content[loc]
ngram_list = get_ngram(content,loc,n=4)
new_dict,index_list = get_new_dict(dicts)
error_dic = get_result(ngram_list,new_dict,index_list,loc,original,dicts)
print(error_dic)
'''
输出:
{'correction': '西', 'index': 7, 'candidate': ['西门'], 'original': '澳'}
'''
Macbert是什么?
原始 BERT 模型的缺点之一是预训练和微调阶段任务不一致,pretrain 有 [mask] 字符,而 finetune 没有。
MacBERT 用目标单词的相似单词,替代被 mask 的字符,减轻了预训练和微调阶段之间的差距。
输入一句话,给其中的字打上“mask”标记,来预测“mask”标记的地方原本是哪个字。
input: 欲把西[mask]比西子,淡[mask]浓抹总相宜
output: 欲把西[湖]比西子,淡[妆]浓抹总相宜
通过transformers使用macbert:
https://huggingface.co/hfl/chinese-macbert-base/tree/main
这是macbert的模型地址,包括词典,配置等等
通过pipeline调用语言模型:
pipeline有以下几种task:
task (
str):
The task defining which pipeline will be returned. Currently accepted tasks are:
- `"audio-classification"`: will return a [`AudioClassificationPipeline`].
- `"automatic-speech-recognition"`: will return a [`AutomaticSpeechRecognitionPipeline`].
- `"conversational"`: will return a [`ConversationalPipeline`].
- `"feature-extraction"`: will return a [`FeatureExtractionPipeline`].
- `"fill-mask"`: will return a [`FillMaskPipeline`]:.
- `"image-classification"`: will return a [`ImageClassificationPipeline`].
- `"question-answering"`: will return a [`QuestionAnsweringPipeline`].
- `"table-question-answering"`: will return a [`TableQuestionAnsweringPipeline`].
- `"text2text-generation"`: will return a [`Text2TextGenerationPipeline`].
- `"text-classification"` (alias `"sentiment-analysis"` available): will return a
[`TextClassificationPipeline`].
- `"text-generation"`: will return a [`TextGenerationPipeline`]:.
- `"token-classification"` (alias `"ner"` available): will return a [`TokenClassificationPipeline`].
- `"translation"`: will return a [`TranslationPipeline`].
- `"translation_xx_to_yy"`: will return a [`TranslationPipeline`].
- `"summarization"`: will return a [`SummarizationPipeline`].
- `"zero-shot-classification"`: will return a [`ZeroShotClassificationPipeline`].
#text-classification :文本分类
from transformers import pipeline
pipe = pipeline("text-classification",model='hfl/chinese-macbert-base')#模型地址
response = pipe("This restaurant is awesome")
print(response)
'''
[{'label': 'LABEL_0', 'score': 0.6576499342918396}]
'''
#fill-mask 文本填充
from transformers import pipeline
pipe = pipeline("fill-mask",model='hfl/chinese-macbert-base')
response = pipe("我爱吃[MASK]")
print(response)
'''
会输出前五个觉得可能的词替代mask的位置
[{'score': 0.31384092569351196, 'token': 511, 'token_str': '。', 'sequence': '我 爱 吃 。'},
{'score': 0.2933292090892792, 'token': 8013, 'token_str': '!', 'sequence': '我 爱 吃 !'},
{'score': 0.045837629586458206, 'token': 4638, 'token_str': '的', 'sequence': '我 爱 吃 的'},
{'score': 0.02681967243552208, 'token': 2124, 'token_str': '它', 'sequence': '我 爱 吃 它'},
{'score': 0.025146018713712692, 'token': 1557, 'token_str': '啊', 'sequence': '我 爱 吃 啊'}]
'''
直接调用模型得到结果,首先要知道传入macbert的数据应该有三个,分别是经过token emb 分词,segment emb 分句子,position emb 分句子中的位置,可以利用AutoTokenizer得到
from transformers import AutoTokenizer,TFAutoModelForMaskedLM
def get_token(filename='hfl/chinese-macbert-base'):
'''
创建分词器
:param finlename:
:return: tokenizers
'''
tokenizers = AutoTokenizer.from_pretrained(filename)
return tokenizers
def get_model(filename='hfl/chinese-macbert-base'):
'''
构建模型
:param filename: 模型所在位置
:return: model
'''
model = TFAutoModelForMaskedLM.from_pretrained(filename)
return model
tokenizers = get_token()
model = get_model()
content = '我爱吃饭'
token = tokenizers(content,return_tensors='tf')#设置返回格式,好传入model
output = model(token)
print(output)
- 首先先查看一下token的数据:
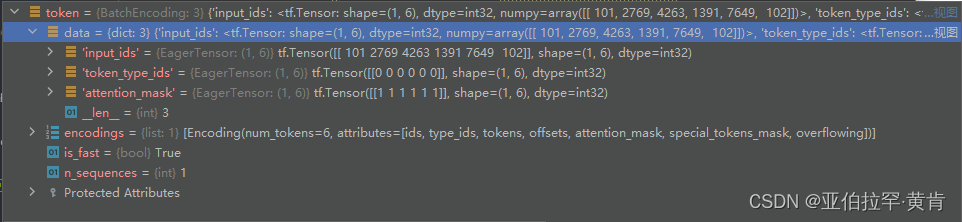
可以看到传入的参数有三个,这里我们这需要第一个input_ids(会分出[CLS],[SEP],代表句子开头和结尾,并不是我们需要的数据,在后面的处理中需要过滤掉),这个input_ids是输入的content被分词后每个词对应在词典vocab.txt里面的位置(vocav.txt在模型所在的网址处,最下面一个就是),得到input_ids去词典里面找就可以得到content被分词后的情况。 - 查看output
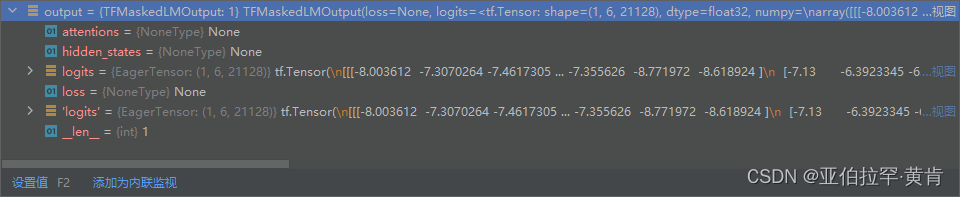
其中的logits的shape为(1, 6, 21128)对应的就是第一个句子,六个分词,21128个词,三维表示的意思就是这个分词在词典中对应的概率。我们可以通过上述得到的input_ids和logits对应的三维概率,根据词典来得到这个分词的替换词。 - 完整代码如下:记得去网址下载词典并放在相应位置
from transformers import AutoTokenizer,TFAutoModelForMaskedLM
import tensorflow as tf
def get_vocab(filename='vocab.txt'):
'''
:param filename: 文件名称
:return: vocab_list
'''
vocab_list = []
with open(filename,'r',encoding='utf8') as fp:
for line in fp:
vocab_list.append(line)
return vocab_list
def get_token(filename='hfl/chinese-macbert-base'):
'''
创建分词器
:param finlename:
:return: tokenizers
'''
tokenizers = AutoTokenizer.from_pretrained(filename)
return tokenizers
def get_model(filename='hfl/chinese-macbert-base'):
'''
构建模型
:param filename: 模型所在位置
:return: model
'''
model = TFAutoModelForMaskedLM.from_pretrained(filename)
return model
def get_new_word(input_ids,logits,vocab_list,top_k):
'''
:param input_ids: 分词后的结果
:param logits: model返回的数据
:param vocab_list: 词典
:return: 存放原来词和五个替换词的字典
'''
result= []
input_ids_index = 0
for sentence in logits:
for predict in sentence:
new_word = []
token = input_ids[0][input_ids_index]
token = vocab_list[token].replace('\n', '')
if token in ['[CLS]','[SEP]']:#分词会分出 '[CLS]','[SEP]',并不是需要的数据故不管
input_ids_index += 1
continue
index_max = tf.argsort(-predict).numpy().tolist()[:top_k]
for index in index_max:
dic = {}
str = vocab_list[index].replace('\n','')
dic['correction'] = str
dic['index'] = input_ids_index
dic['prob'] = predict.numpy().tolist()[index]
dic['original'] = token
new_word.append(dic)
result.append(new_word)
input_ids_index += 1
return result
if __name__ == '__main__':
vocab_list = get_vocab()
tokenizers = get_token()
model = get_model()
content = '我爱吃饭'
token = tokenizers(content,return_tensors='tf')#设置返回格式,好传入model
input_ids = token['input_ids'].numpy().tolist()#转成列表
output = model(token)
logits = tf.nn.softmax(output.logits)
result = get_new_word(input_ids, logits, vocab_list,top_k=5)#top_k是获取前五个概率值最大的替换词
print(result)
'''
[
[{'correction': '我', 'index': 1, 'prob': 0.49622663855552673, 'original': '我'},
{'correction': '也', 'index': 1, 'prob': 0.02421947941184044, 'original': '我'},
{'correction': '不', 'index': 1, 'prob': 0.021840188652276993, 'original': '我'},
{'correction': '爱', 'index': 1, 'prob': 0.01763201504945755, 'original': '我'},
{'correction': '你', 'index': 1, 'prob': 0.013141845352947712, 'original': '我'}],
[{'correction': '爱', 'index': 2, 'prob': 0.7990172505378723, 'original': '爱'},
{'correction': '不', 'index': 2, 'prob': 0.008415293879806995, 'original': '爱'},
{'correction': '要', 'index': 2, 'prob': 0.007923864759504795, 'original': '爱'},
{'correction': '是', 'index': 2, 'prob': 0.0068937744945287704, 'original': '爱'},
{'correction': '想', 'index': 2, 'prob': 0.0060282074846327305, 'original': '爱'}],
[{'correction': '吃', 'index': 3, 'prob': 0.4919191598892212, 'original': '吃'},
{'correction': '的', 'index': 3, 'prob': 0.03245647996664047, 'original': '吃'},
{'correction': '你', 'index': 3, 'prob': 0.0290437750518322, 'original': '吃'},
{'correction': '有', 'index': 3, 'prob': 0.021838273853063583, 'original': '吃'},
{'correction': '我', 'index': 3, 'prob': 0.017963092774152756, 'original': '吃'}],
[{'correction': '!', 'index': 4, 'prob': 0.10435411334037781, 'original': '饭'},
{'correction': '。', 'index': 4, 'prob': 0.07520557194948196, 'original': '饭'},
{'correction': '啊', 'index': 4, 'prob': 0.06121807172894478, 'original': '饭'},
{'correction': '?', 'index': 4, 'prob': 0.04430496692657471, 'original': '饭'},
{'correction': '吗', 'index': 4, 'prob': 0.029895102605223656, 'original': '饭'}]
]
'''

![[附源码]计算机毕业设计基于Vue的社区拼购商城Springboot程序](https://img-blog.csdnimg.cn/005011ba90164b02a28520def08818da.png)





![[论文分享] DnD: A Cross-Architecture Deep Neural Network Decompiler](https://img-blog.csdnimg.cn/7cd353a008d6430db17b0449437dd7ea.png)