导包准备
from pyspark import SparkConf, SparkContext
import os
import json
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
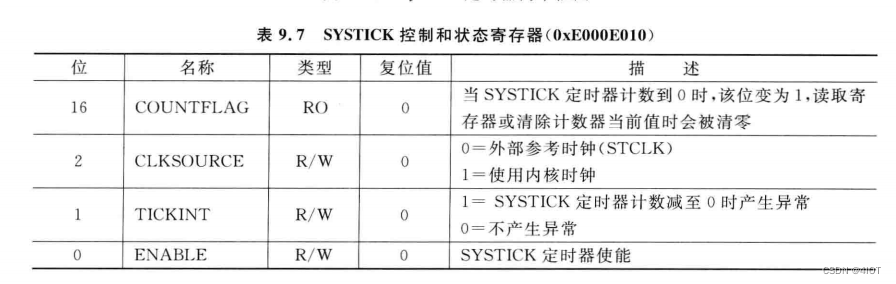
TODO 城市销售额排名
读文件textFile()
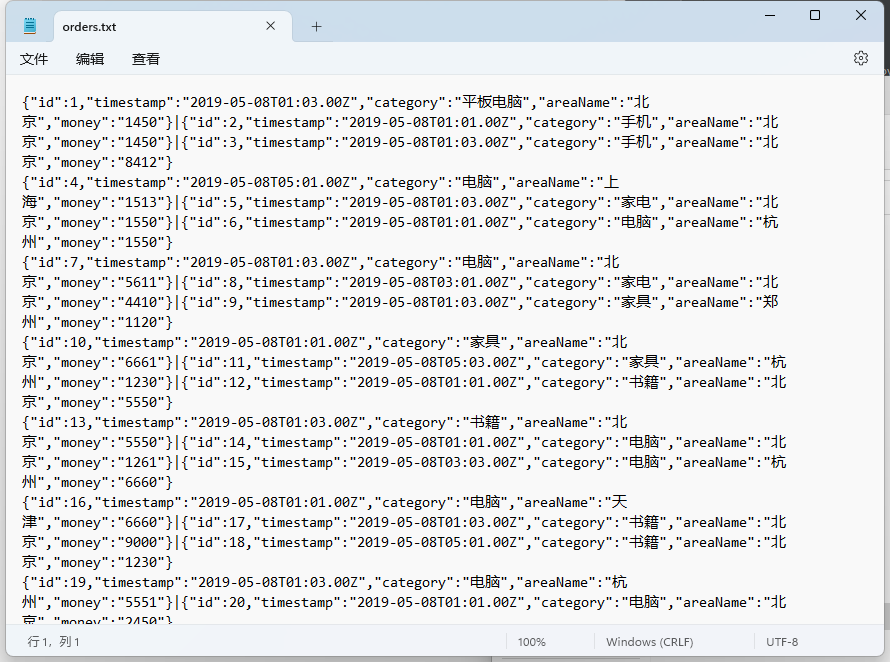
file_rdd = sc.textFile("D:/orders.txt")
print(file_rdd.collect())

去 | ,取出JSON字符串, flatMap()
json_rdd = file_rdd.flatMap(lambda x: x.split("|")) # 取出JSON字符串
print(json_rdd.collect())

json转为字典 map()
dict_rdd = json_rdd.map(lambda x: json.loads(x)) # json转为字典
print(dict_rdd.collect())

取出城市与销售额(str->int)存入元组 map()
city_rdd = dict_rdd.map(lambda x: (x['areaName'], int(x['money']))) # 取出城市与销售额(str->int)存入元组
print(city_rdd.collect())
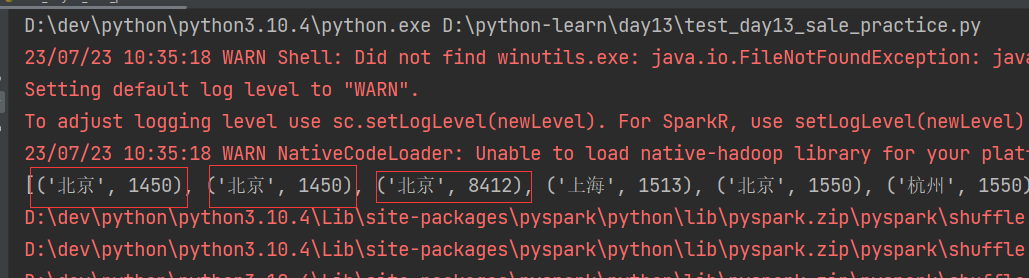
聚合每个城市销售额总量 reduceByKey()
rdd_sale = city_rdd.reduceByKey(lambda a, b: a + b) # 聚合每个城市销售额总量
print(rdd_sale.collect())

排序 sortBy()
rdd_sort = rdd_sale.sortBy(lambda x: x[1], ascending=False, numPartitions=1) # 排序
print(rdd_sort.collect())

TODO 全部城市有哪些商品品类在销售、
从字典中取出销售类别,再去重 distinct()
category_rdd = dict_rdd.map(lambda x: x['category']).distinct()
print(category_rdd.collect())

TODO 查看北京市有哪些类别在售卖
过滤其他城市 filter()
Peking_rdd = dict_rdd.filter(lambda x: x["areaName"] == "北京")
Peking_category_rdd = Peking_rdd.map(lambda x: x['category']).distinct()
print(Peking_category_rdd.collect())
关闭
sc.stop()