摘要:
(1)首次在pFL(个性化联邦学习)中进行后门研究
在基准数据集 FEMNIST 和 CIFAR-10 上针对 6 种 pFL 方法测试了 4 种广泛使用的后门攻击,总共 600 次实验.
结果:具有部分模型共享的 pFL 方法可以显着提高针对后门攻击的鲁棒性。相比之下,具有完全模型共享的 pFL 方法没有表现出鲁棒性。
(2)分析鲁棒性不同的原因,对不同的pFL进行消融实验
提出轻量级防御方法:Simple-Tuning,它根据经验提高了针对后门攻击的防御性能
后门攻击:
后门攻击的目的只是误导后门模型,使其在具有后门触发器的样本上表现出异常行为。与中毒攻击类似,攻击者操纵一些训练样本,例如在样本中添加小补丁或添加额外的特定样本,以在模型中插入后门触发器。与旨在破坏 FL 模型预测性能或使 FL 训练发散的投毒攻击相比 [5,7,17,51],后门攻击只能由带有触发器的数据激活,因此更加隐蔽,更难以检测和防御。
目标是确定 pFL 方法是否也可以提供针对难度消除的后门攻击的鲁棒性
1、提出问题:
pFL 方法能否再次带来后门攻击的鲁棒性?
如果答案是肯定的,那么什么会带来鲁棒性,以及如何利用它?
通过一系列实验挖掘pFL方法鲁棒性的来源,我们发现个性化程度是鲁棒性效益的关键因素。我们观察到,具有完全模型共享的 pFL 方法并不能提高针对后门攻击的鲁棒性。相比之下,具有部分模型共享的 pFL 方法、FedBN [33] 和 FedRep [13] 显着提高了防御性能。这些观察结果表明,针对后门攻击的鲁棒性与 pFL 方法的较大个性化程度之间存在很强的正相关性。然后,为了进一步分析 pFL 方法鲁棒性不同的原因,我们对 pFL 方法进行了消融研究。对于完全模型共享方法,我们发现如果局部模型的训练更加依赖于全局模型,则它们更容易受到后门攻击。对于像 FedBN 或 FedRep 这样允许每个客户端拥有本地保存的 BN 层或线性分类器的部分模型共享方法,我们发现它们成功地阻止了个性化本地模型之间后门特征的传播。
提出了一种防御方法 Simple-Tuning,它允许训练 FL 模型,同时有效减少后门攻击的脆弱性。Simple-Tuning 首先重新初始化每个客户端训练模型的线性分类器,然后在本地训练数据集上对其进行训练。由于仅调整线性分类器,Simple-Tuning 更容易与现有的 FL 方法结合,并显着降低计算成本。我们测试了Simple-Tuning的防御性能,结果表明它显着提高了针对后门攻击的鲁棒性。
文章中的设置为:黑盒后门攻击
这些攻击不需要控制和了解模型架构、参数或训练方法等训练过程。它们也不需要任何计算资源,这使得它们在现实世界中成为重要的威胁。为了简单起见,我们考虑大多数后门攻击研究中使用的图像分类任务。
2、实验
2.1、整体稳健性评估
非独立同分布数据分布下pFL方法后门攻击的性能曲线:
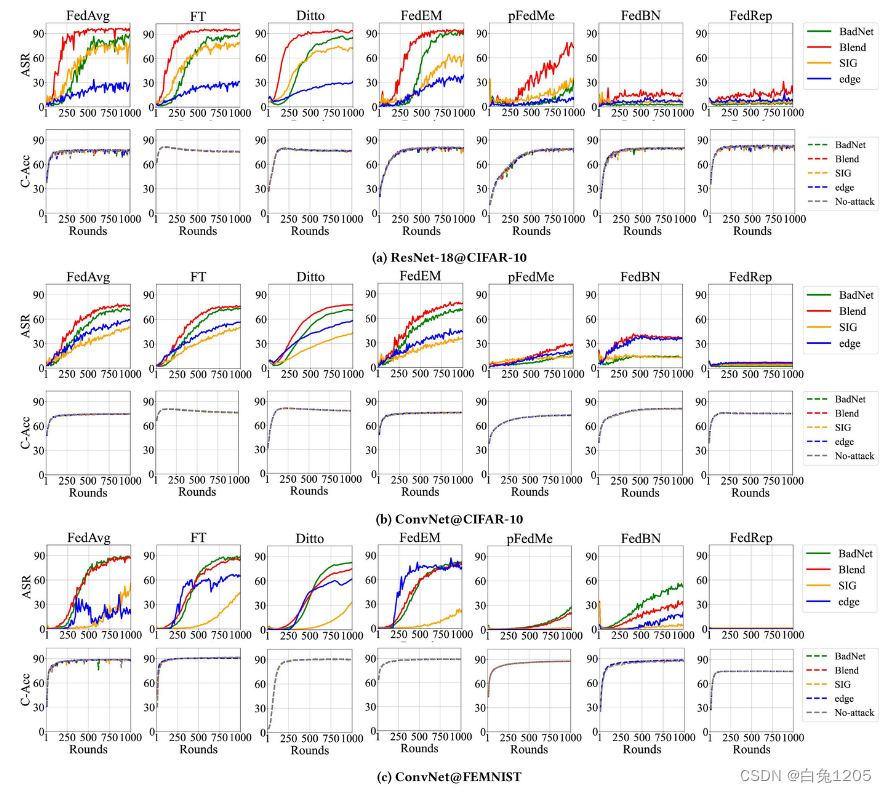
实验表现:
(1)即使不需要访问 FL 训练过程,简单的黑盒后门攻击,尤其是 BadNet 和 Blended 攻击也能获得出色的性能。这表明,实际的黑盒后门攻击是不可忽视的威胁。并且,对于所有 pFL 方法,后门攻击不会影响 C-Acc。
正如每个子图中所示,不同颜色的虚线几乎与灰色虚线重叠(干净的准确性,没有攻击)。它还反映了黑盒后门攻击的隐蔽性,这些攻击通常在没有触发器的情况下对样本进行攻击。然后,在这四种攻击方法中,混合攻击(红实线)在 CIFAR-10 数据集上实现了最佳攻击性能,在两个模型上的 ASR 超过 90%。在 FEMNIST 上,BadNet 攻击取得了最好的攻击性能,其次是 Blended 攻击。
(2)具有部分模型共享的 pFL 方法可以有效缓解后门攻击。可以清楚地观察到具有部分模型共享(最后两列)的 pFL 方法 FedRep 和 FedBN 对于后门攻击表现出出色的鲁棒性。FedRep对攻击表现出最佳的防御性能,可以将混合攻击和其他攻击的成功率限制在20%和10%以下。FedBN 在 CIFAR-10 数据集上实现了第二好的防御性能,并在较大的模型 ResNet-18 上将四种攻击的 ASR 降低到 20% 以下。这些积极的结果表明,除了提高预测精度之外,一些 pFL 方法(部分模型共享)还可以带来更好的针对后门攻击的鲁棒性。
(3)个性化程度是鲁棒性优势的关键因素。在各列中,我们观察到具有部分模型共享的 pFL 方法显着提高了防御性能,但除 pFedMe 方法外,所有具有完全模型共享的 pFL 方法(从第 2 列到第 5 列)都没有显示出针对后门攻击的鲁棒性的改进。这些观察结果表明,针对后门攻击的鲁棒性与 pFL 方法的较大个性化程度之间存在很强的正相关性。在第 5 节中,我们将深入研究为什么不同的模型共享程度会导致不同的防御效果,并表明 pfedMe 也像其他完整模型共享方法一样容易受到后门攻击。
2.2、基线防御方法的鲁棒性评估
我们采用四种防御方法:范数裁剪、添加噪声、Krum 和 Multi-Krum。

(1)简单范数裁剪(NC)方法的防御性能。[53]中使用的带有 c= 1 的 NC 无法针对混合攻击带来任何鲁棒性改进。我们进一步将 NC 对局部更新的范数约束降低到 0.5。在降低混合攻击ASR的同时,也导致C-Acc大幅下降。与规范削波一样,随着添加噪声 𝜎 强度的增加,AD 显着降低了混合攻击的 ASR。然而,这也会导致 C-Acc 显着下降。与边缘情况攻击的性能类似,Krum 还提高了针对混合攻击的鲁棒性。然而,由于每次聚合中只会选择一个模型,因此 C-Acc 也经历了显着下降。
1 的 NC 无法针对混合攻击带来任何鲁棒性改进。我们进一步将 NC 对局部更新的范数约束降低到 0.5。在降低混合攻击ASR的同时,也导致C-Acc大幅下降。与规范削波一样,随着添加噪声 𝜎 强度的增加,AD 显着降低了混合攻击的 ASR。然而,这也会导致 C-Acc 显着下降。与边缘情况攻击的性能类似,Krum 还提高了针对混合攻击的鲁棒性。然而,由于每次聚合中只会选择一个模型,因此 C-Acc 也经历了显着下降。
尽管Multi-Krum实现了更好的C-Acc,但它无法防御混合攻击。尽管 NC、AD 和 Krum 针对混合攻击表现出不同的鲁棒性改进,但它们都面临鲁棒性和干净准确性之间的严重权衡。
3、PFL针对后门攻击的鲁棒性分析
在FedBN中,由于每个客户端共享除本地BN层之外的所有参数,客户端之间的数据异构性导致本地BN层的参数存在差异。我们认为跨客户端的本地 BN 层的差异会阻碍本地模型中的后门特征传播。
在IID设置下,在没有数据异构性的情况下,客户端的本地BN层彼此变得更加一致,这应该会导致在此设置下更好的攻击结果。IID的ASR高于Non-IID。尤其是在ResNet-18上,FedBN并没有表现出防御效果,这与我们之前的分析是一致的。

为了进一步分析本地 BN 层的防御性能,我们对 BN 层的每个部分进行攻击评估,即运行统计数据 𝜇、𝜎 2 和可学习参数 𝛾 、𝛽。与 FedBN 不同,我们只是选择不共享运行统计数据或可学习参数。我们将它们表示为 Fed-sta 或 Fed-para。 Fed-sta、Fed-para 和原始 FedBN 在混合攻击和 CIFAR-10 数据集上的比较。
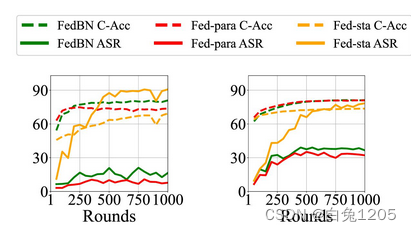
就 C-Acc 而言,Fed-sta 和 Fed-para 在 ResNet-18 上经历了下降,但后者下降较少。在ConvNet中,Fed-para保持与FedBN相同的C-Acc。令人惊讶的是,我们发现 Fed-para 的稳健性甚至比 FedBN 还要好。相比之下,Fed-sta 对 Blended 攻击的防御效果最差,ASR 在 ResNet-18 上甚至提高到 90%。这些结果表明,可学习参数的差异对于防止后门特征的传播可能比 BN 层运行统计数据的差异更重要。
随机选择 4 个良性客户端和对抗性客户端,并在 BadNet 和混合攻击的特征空间中可视化它们的训练样本。我们在 ResNet-18 和 CIFAR-10 上进行实验。结果如图6所示,其中黑点为后门样本。我们可以观察到大多数后门样本聚集在一个集群中,这表明全局特征提取器已经学习了后门特征。

4、防御方法
Simple-Tuning,它仅在训练过程后调整每个客户端的 FL 模型的线性分类器。具体来说,我们首先重新初始化线性分类器,并使用每个客户端的本地训练数据集重新训练它,同时冻结每个模型的剩余参数。与普通的Fine-tuning相比,Simple-Tuning(ST)做了两点改进:(1)与FT中调整整个模型相比,我们只在完成训练过程后调整线性分类器,这可以有效降低计算成本; (2)我们没有像FT那样继承原始模型的参数,而是选择在本地数据集上重新初始化和重新训练本地线性分类器。
在 FedAvg 和 Ditto 的训练模型上测试我们的方法,并展示针对 BadNet 和 Blended 攻击的防御性能。对于Simple-Tuning,我们采用默认的Kaiming Uniform归一化[22],并使用恒定学习率为0.005。我们只调整 10 个时期的线性分类器。包含ASR和C-Acc在ResNet-18和ConvNet模型上的结果如表1所示。我们将我们的方法的结果与原始 FedAvg 和 Ditto 模型以及仅微调局部线性分类器而不重新初始化的模型的结果进行比较。我们将后者表示为 FT 线性。如表 1 所示,我们的方法 Simple-Tuning 显着提高了针对后门攻击的鲁棒性。与原始模型相比,有效降低了两次后门攻击的ASR平均56.6%。它在较小的模型 ConvNet 上实现了更好的鲁棒性,将 ASR 降低到 20% 以下。令人惊讶的是,Simple-Tuning 甚至改进了除了 ConvNet 上的 Ditto 之外的 FL 方法的 C-Acc。这些结果证明了 Simple-Tuning 的巨大潜力。值得注意的是,FT-线性并不像普通 FT 那样表现出任何鲁棒性。它还验证了我们的方法中重新初始化对于后门鲁棒性的重要性。这表明直接微调 FL 后门模型可能无法有效消除后门触发器。它还与 [1] 的研究结果形成对比,[1] 利用 FT 方法来净化 DNN 模型中的水印、特定后门触发器。然而,他们证明了所有三种方法——普通 FT、FT 线性和带有随机线性分类器的 FT 线性——都可以有效地净化水印触发器。我们认为这主要是因为水印的触发器设置与一般后门触发器不同。在[1]中,作者将每个带水印样本的yt设置为随机选择的标签,而不是像后门攻击中那样设置固定目标标签。