BinaryTree要实现的方法
总结
-
remove不在BinNode里,而是BinTree里
-
递归的两种写法
从上往下:同一对象的递归(参数多一个,判空用一句话),子对象的递归(参数void,判空用两句话)(因为分叉,所以递归是真递归)
从下往上:不分叉,为了效率,可以用循环
// 我的最初写法(递归更新一条路径上的全部节点high值)
template <typename T>
void BinNode<T>::updateHigh(void)
{
int oldHigh = high;
high = std::max(getHigh(left), getHigh(right)) + 1;
if (parent != NULL && oldHigh != high) parent->updateHigh();
}
// 调用
rt->updateHigh();
// 改良版(循环更新一条路径上的全部节点high值)
template <typename T>
void BinTree<T>::updateHighAbove(BinNode<T> * rt)
{
while (rt)
{
if (!rt->updateHigh()) break; //这是书里说的优化,但书中并未实现
rt = rt->parent;
}
}
template <typename T>
bool BinNode<T>::updateHigh(void) //返回是否更新了树高
{
int oldHigh = high;
high = std::max(getHigh(left), getHigh(right)) + 1;
return oldHigh != high;
}
// 调用
updateHighAbove(rt);
-
整棵树与根节点的区别:整棵树的类型是BinTree 而根节点的类型是BinNode。二者都有成员变量high和size改了根节点的size,没改整棵树的size
-
发现high也有上一条的问题。书上BinTree没有设置high,BinNode没有size,那就删掉,省的单独更新
-
为什么remove写两个,因为
切断来自parent的指针和更新高度不用层层进行,还是为了提高效率。remove_core负责递归,remove在最外层负责切断来自parent的指针和更新高度 -
remove如果rt是根节点那么不进行
切断来自parent的指针和更新高度,析构函数要用 -
静态成员函数可以不依附于具体对象来调用。为了调用时简洁。静态成员函数就很像是面向过程了
code BinNode
# pragma once
# include <algorithm>
# define getHigh(x) x ? x->high : -1
// 仿函数:打印功能
template <typename T>
struct print {
void operator ()(T data)
{
std::cout << data << std::endl;
}
};
template <typename T>
struct BinNode {
int high;
T data;
BinNode<T> * left;
BinNode<T> * right;
BinNode<T> * parent;
int Size(BinNode<T> * x)
{
if (x)
{
return 1 + Size(x->left) + Size(x->right);
}
return 0;
}
BinNode(T const & d, BinNode<T> * p) : data(d), parent(p), left(NULL), right(NULL), size(1), high(0) {}
BinNode<T> * insertAsLeft(T const & val)
{
left = new BinNode<T>(val, this);
return left;
}
BinNode<T> * insertAsRight(T const & val)
{
right = new BinNode<T>(val, this);
return right;
}
bool updateHigh(void)
{
int oldHigh = high;
high = std::max(getHigh(left), getHigh(right)) + 1;
return oldHigh != high;
}
template <typename T2>
void travPre(T2 visit)
{
visit(data);
if (left) left->travPre(visit);
if (right) right->travPre(visit);
}
template <typename T2>
void travIn(T2 visit)
{
if (left) left->travIn(visit);
visit(data);
if (right) right->travIn(visit);
}
template <typename T2>
void travPost(T2 visit)
{
if (left) left->travPost(visit);
if (right) right->travPost(visit);
visit(data);
}
};
code BinTree
# pragma once
# include "BinNode.h"
template <typename T>
class BinTree
{
protected:
public:
int size;
BinNode<T> * root;
public:
BinTree():size(0), root(NULL){}
~BinTree() { if (root) remove(root); }
//***********************************************************只读*********************************************************
int Size(void) const { return size; }
bool empty(void) const { return size == 0; }
BinNode<T> * Root(void) const { return root; }
//***********************************************************可写*********************************************************
// 节点插入
BinNode<T> * insertAsRoot(T const & e)
{
size = 1;
root = new BinNode<T>(e, NULL);
return root;
}
BinNode<T> * insertAsLeft(T const & e, BinNode<T> * rt)
{
++size;
rt->insertAsLeft(e);
updateHighAbove(rt);
return rt->left;
}
BinNode<T> * insertAsRight(T const & e, BinNode<T> * rt)
{
++size;
rt->insertAsRight(e);
updateHighAbove(rt);
return rt->right;
}
// 子树接入,返回接入位置rt
BinNode<T> * attachAsLeft(BinTree<T> * newSubtree, BinNode<T> * rt)
{
size += newSubtree->size;
rt->left = newSubtree->root;
updateHighAbove(rt);
// 清空newSubtree原来的东西
newSubtree->size = 0;
newSubtree->root = NULL;
return rt;
}
BinNode<T> * attachAsRight(BinNode<T> * newSubtree, BinNode<T> * rt)
{
size += newSubtree->size;
rt->right = newSubtree->root;
updateHighAbove(rt);
// 清空newSubtree原来的东西
newSubtree->size = 0;
newSubtree->root = NULL;
return rt;
}
int remove(BinNode<T> * rt)
{
// 切断来自parent的指针
fromParentTo(rt) = NULL;
// 更新高度
updateHighAbove(rt->parent);
int ans = remove_core(BinNode<T> * rt);
size -= ans
return ans;
}
int remove_core(BinNode<T> * rt)
{
if (!rt) return 0; // 递归出口
int ans = remove(rt->left) + remove(rt->right) + 1;
delete rt;
return ans;
}
BinTree<T> * secede(BinNode<T> * rt) // 先不考虑 如果rt是树根
{
// 切断来自parent的指针
fromParentTo(rt) = NULL;
size -= BinNode<T>::Size(rt);
BinTree<T> * newTree = new BinTree<T>();
newTree->root = rt;
rt->parent = NULL;
updateHighAbove(rt->parent);
return newTree;
}
void updateHighAbove(BinNode<T> * rt)
{
while (rt)
{
if (!rt->updateHigh()) break;
rt = rt->parent;
}
}
//***********************************************************遍历*********************************************************
template <typename T2>
void travPre(T2 visit)
{
if (root) root->travPre(visit);
}
template <typename T2>
void travIn(T2 visit)
{
if (root) root->travIn(visit);
}
template <typename T2>
void travPost(T2 visit)
{
if (root) root->travPost(visit);
}
private:
BinNode<T> * & fromParentTo(BinNode<T> * x)
{
if (x == x->parent->left) return x->parent->left;
else return x->parent->right;
}
};
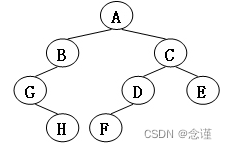
测试程序(树的结构如图)
# include <iostream>
# include "BinTree.h"
int main(void)
{
BinTree<char> T1;
BinNode<char> * pA = T1.insertAsRoot('A');
BinNode<char> * pB = T1.insertAsLeft('B', pA);
BinNode<char> * pG = T1.insertAsLeft('G', pB);
BinNode<char> * pC = T1.insertAsRight('C', pA);
BinNode<char> * pE = T1.insertAsRight('E', pC);
BinNode<char> * pH = T1.insertAsRight('H', pG);
BinNode<char> * pD = T1.insertAsLeft('D', pC);
BinNode<char> * pF = T1.insertAsLeft('F', pD);
print<int> p;
std::cout << T1.Size() << '\n';
// 高度测试
std::cout << "根高度:"; std::cout << T1.Root()->high; std::cout << "\n";
std::cout << "C高度:"; std::cout << pC->high; std::cout << "\n";
// 遍历测试
std::cout << "后序遍历:"; T1.travPost(p); std::cout << "\n";
std::cout << "中序遍历:"; T1.travIn(p); std::cout << "\n";
// 移除测试
std::cout << "删掉:" << T1.remove(pD) << "个节点" << '\n';
std::cout << "C高度:"; std::cout << pC->high; std::cout << "\n";
std::cout << "中序遍历:"; T1.travIn(p); std::cout << "\n";
std::cout << T1.Size() << '\n';
// 切断测试
BinTree<char> * pT2 = T1.secede(pC);
std::cout << "中序遍历T1:"; T1.travIn(p); std::cout << "\n";
std::cout << "中序遍历T2:"; pT2->travIn(p); std::cout << "\n";
std::cout << T1.Size() << '\n';
std::cout << pT2->Size() << '\n';
return 0;
}
输出
8
根高度:3
C高度:2
后序遍历:H G B F D E C A
中序遍历:G H B A F D C E
删掉:2个节点
C高度:1
中序遍历:G H B A C E
6
中序遍历T1:G H B A
中序遍历T2:C E
4
2
迭代遍历
上面的代码是递归的遍历。现在再写迭代的前序、中序、后序遍历。
尾递归
前序遍历的递归代码,左右子树都属于尾递归。中序遍历的递归代码,右子树属于尾递归。而后序遍历完全不属于尾递归。所以后序遍历比前、中序遍历复杂得多。要理解这句话,还要先了解尾递归转成迭代的方法,而这也是编译器在编译之前常做的优化手段。
以汉诺塔为例,理解递归转迭代
BinTree 的三个遍历接口不变,只需修改BinNode 的遍历函数。
travPre迭代1:直接转化(但不可推广到中、后序)
仅说思路:根节点进栈。当栈非空:出栈访问,然后右子树入栈,左子树入栈。
这个完全模拟了尾递归时编译器的操作。至于为什么先右后左,因为这样出栈时才能先左后右。
(汉诺塔那篇文章如果你把结果打印出来,发现迭代的结果跟递归结果是反过来的,如果将入栈的两句话交换位置,那么输出结果一模一样)
travPre迭代2:新思路(可推广)
我们通过仔细观察travPre,得到前序遍历的迭代算法。
template <typename T2>
void travPre(T2 visit)
{
// 出栈,访问
visit(data);
// 左侧链一路访问到底
if (left) left->travPre(visit);
// 每访问一个左孩子,将对应右孩子进栈备用
if (right) right->travPre(visit);
}
迭代2的算法
template <typename T2>
void travPre2(T2 visit)
{
// 出栈顶。右孩子进栈,访问左孩子。转到左孩子,重复上一步。直到没有左孩子,出栈顶。
BinNode<T> * current;
Stack<BinNode<T>*> s;
s.push(this);
while (!s.empty())
{
current = s.pop();
while (current)
{
visit(current->data);
if (current->right) s.push(current->right);
current = current->left;
}
}
}
travIn迭代
按图索骥,继续先观察递归算法
void travIn(T2 visit)
{
// 沿左侧链一路向左进栈
if (left) left->travIn(visit);
// 没有左子树时,出栈访问
visit(data);
// 访问完马上转到右儿子,进一个栈
if (right) right->travIn(visit);
}
travIn迭代算法
template <typename T2>
void travIn2(T2 visit)
{
// 左孩子进栈,没有左孩子时,出栈顶访问,一个右孩子进栈,右孩子的左孩子到底进栈
BinNode<T> * current = this;
Stack<BinNode<T>*> s;
while (current)
{
s.push(current);
current = current->left;
}
while (!s.empty())
{
current = s.pop();
visit(current->data);
current = current->right;
while (current)
{
s.push(current);
current = current->left;
}
}
}
travPost迭代
比较复杂。邓老师将其描述为,藤绕树。先找藤的头。
善后工作
为了调用更加友好,BinTree 的三个遍历接口加一个tag参数,缺省为0,宏定义ITER(意为迭代)为1
template <typename T2>
void travPre(T2 visit, int tag = 0)
{
if (root)
{
if (tag & ITER) root->travPre2(visit);
else root->travPre(visit);
}
}
template <typename T2>
void travIn(T2 visit, int tag = 0)
{
if (root)
{
if (tag & ITER) root->travIn2(visit);
else root->travIn(visit);
}
}
template <typename T2>
void travPost(T2 visit, int tag = 0)
{
if (root)
{
if (tag & ITER) root->travPost2(visit);
else root->travPost(visit);
}
}