1 mnist数据集
下载数据集:
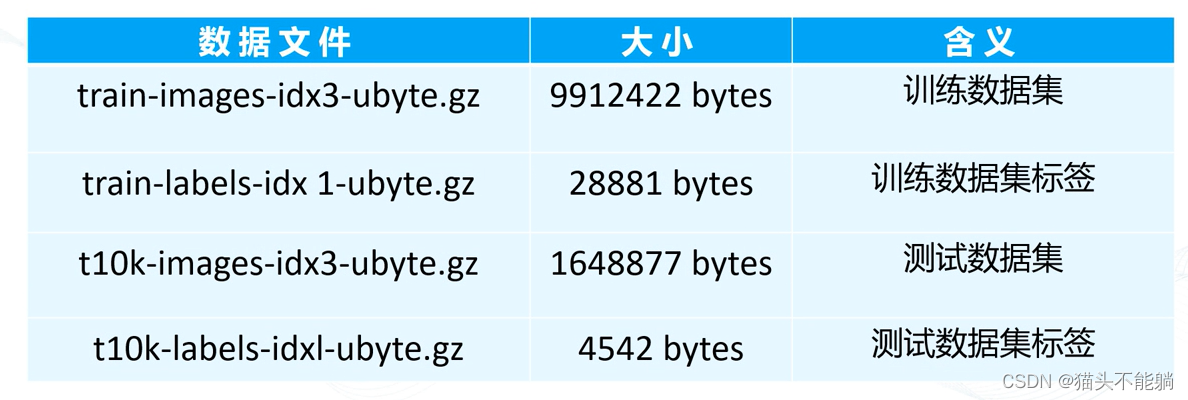
手动下载:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
tf程序下载:
tensorflow2.x将数据集集成在Keras中。tensorflow2.0,更新删除了input_data的函数。
import tensorflow as tf
# tf.__version__
mint=tf.keras.datasets.mnist
(x_,y_),(x_1,y_1)=mint.load_data()
import matplotlib.pyplot as plt
plt.imshow(x_[0], cmap="binary")
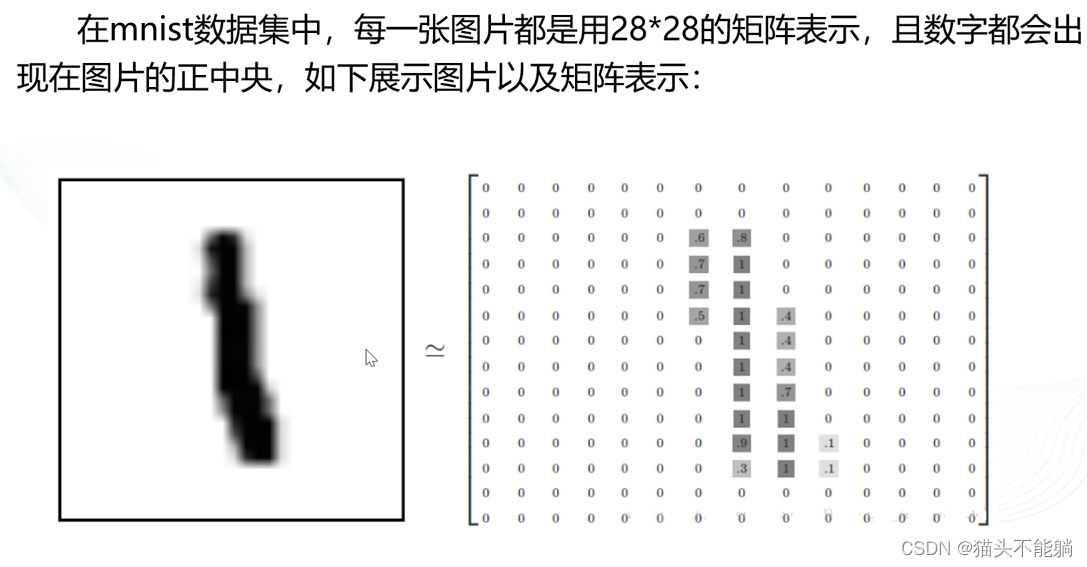
plt.show()在mnist数据集中,属性mnist.train.images 是训练样本,其形状为(55000,784),其中55000是图像的个数,784实际 上是单个样本,即每张图片都是由一个784维的向量表示(28*28) 。下面演示读取第一张图片:
import tensorflow as tf
import numpy as np
import cv2
# 加载 MNIST 数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 访问第一张图像
image = train_images[0]
array=np.reshape(image,[28,28,1])
cv2.imshow("image",array)
cv2.waitKey(0)
cv2.destroyAllWindows()mnist中的mnist.train.labels属性表示训练图像的标签,形状是(55000,10) ,每一个标签用独热表示,即one-hot编码。所谓独热表示,就是用一维N个向量来表示N个类别,每个类别占据独立的
一位,任何时候独热表示中只有一位是1,其他各位都为0。
import tensorflow as tf
# 加载 MNIST 数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 转换标签为 one-hot 编码
num_classes = 10
train_labels = tf.one_hot(train_labels, num_classes)
print(train_labels[0])
2 构建Mnist识别模型
2.1 模型简介与前向传输
MNIST手写字识别模型是一个三层的神经网络模型,有输入层、隐藏层以及输出层和一个softmax函数组成,每-层的特性如下:

mnist模型前向传输

import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import regularizers
# 输入层为28*28的像素
INPUT_NODE = 784
# 输出层0~9有10类
OUTPUT_NODE = 10
# 隐藏层节点数
LAYER1_NODE = 500
# 正则化项的系数
REGULARIZATION_RATE = 0.0001
# 为模型添加正则化
def get_regularizer_variable(weights, regularizer):
if regularizer is not None:
tf.add_to_collection("losses", regularizer(weights))
# 定义前向传输过程
def forward(input_tensor, regularizer):
# 第一层神经网络权重
weights1 = tf.Variable(tf.random.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
# 第一层神经网络偏置项
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第一层神经网络输出
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 第二层网络权重
weights2 = tf.Variable(tf.random.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
# 第二层神经网络偏置项
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
get_regularizer_variable(weights2, regularizer)
# 第二层神经网络输出
layer2 = tf.matmul(layer1, weights2) + biases2
return layer2
if __name__ == "__main__":
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((-1, 28 * 28)).astype('float32') / 255.0
test_images = test_images.reshape((-1, 28 * 28)).astype('float32') / 255.0
train_labels = tf.keras.utils.to_categorical(train_labels, num_classes=OUTPUT_NODE)
test_labels = tf.keras.utils.to_categorical(test_labels, num_classes=OUTPUT_NODE)
model = tf.keras.Sequential([
layers.Dense(LAYER1_NODE, activation='relu', input_shape=(INPUT_NODE,),
kernel_regularizer=regularizers.l2(REGULARIZATION_RATE)),
layers.Dense(OUTPUT_NODE)
])
logits = model(train_images)
print(logits)2.2优化、保存及验证模型
2.2.1 优化和保存模型

import tensorflow.compat.v1 as tf
from tf_slim import l2_regularizer
tf.disable_eager_execution()
# 输入层为28*28的像素
INPUT_NODE = 784
# 输出层0~9有10类
OUTPUT_NODE = 10
# 隐藏层节点数
LAYER1_NODE = 500
# batch的大小
BATCH_SIZE = 128
# 训练轮
TRAINING_STEPS = 30000
# 基础的学习率
LEARNING_RATE_BASE = 0.01
# 学习率的衰减率
LEARNING_RATE_DECAY = 0.99
# 正则化项的系数
REGULARIZATION_RATE = 0.0001
# 为模型添加正则化
def get_regularizer_variable(weights, regularizer):
if regularizer is not None:
tf.add_to_collection("losses", regularizer(weights))
# 定义前向传输过程
def forward(input_tensor, regularizer):
# 第一层神经网络权重
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
# 第一层神经网络偏置项
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第一层神经网络输出
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)# 第二层网络权重
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
# 第二层神经网络偏置项
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第二层神经网络输出
layer2 = tf.matmul(layer1, weights2) + biases2
return layer2
# 程序运行起点
if __name__ == "__main__":
# 读取数据集并转化为one-hot
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, INPUT_NODE).astype('float32')
num_samples = x_train.shape[0]
y_train = tf.keras.utils.to_categorical(y_train).astype('float32')
y_test = tf.keras.utils.to_categorical(y_test)
# 声明占位符
x_placeholder = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_placeholder = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
regularizer = l2_regularizer(REGULARIZATION_RATE)
# 调用前向传输
y = forward(x_placeholder, regularizer)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_placeholder, 1))
# 计算batch所有交叉熵的均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection("losses"))
global_step = tf.Variable(0, trainable=False)
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
dataset = dataset.batch(BATCH_SIZE).repeat()
iterator = dataset.make_initializable_iterator()
learing_rate = tf.train.exponential_decay(learning_rate=LEARNING_RATE_BASE, global_step=global_step,
decay_steps=num_samples / BATCH_SIZE,
decay_rate=LEARNING_RATE_DECAY)
train_step = tf.train.GradientDescentOptimizer(learing_rate).minimize(loss)
with tf.Session() as sess:
sess.run(iterator.initializer)
init_op = tf.global_variables_initializer()
sess.run(init_op)
xs, ys = iterator.get_next()
for i in range(TRAINING_STEPS):
xn, yn = sess.run([xs, ys])
_, _, _ = sess.run([train_step, loss, global_step], feed_dict={x_placeholder: xn, y_placeholder: yn})
if i % 1000 == 0:
print("loss:", sess.run(loss, feed_dict={x_placeholder: xn, y_placeholder: yn}))
saver = tf.train.Saver()
saver.save(sess, "mnist_model/mnistModel.ckpt")2.2.2 验证模型
训练模型的主要目的是对未知的数据进行预测,因此验证模型是检验模型健壮性的主要依据。mnist手写字模型的验证主要有两种方式:
(1) 使用验证集进行验证;
(2)自制图片进行验证。
(1) 使用验证集进行验证
import tensorflow.compat.v1 as tf
tf.disable_eager_execution()
# 输入层为28*28的像素
INPUT_NODE = 784
# 输出层0~9有10类
OUTPUT_NODE = 10
# 隐藏层节点数
LAYER1_NODE = 500
# 为模型添加正则化
def get_regularizer_variable(weights, regularizer):
if regularizer is not None:
tf.add_to_collection("losses", regularizer(weights))
# 定义前向传输过程
def forward(input_tensor, regularizer):
# 第一层神经网络权重
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
# 第一层神经网络偏置项
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第一层神经网络输出
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 第二层网络权重
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
# 第二层神经网络偏置项
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第二层神经网络输出
layer2 = tf.matmul(layer1, weights2) + biases2
return layer2
def evaluate(x_test, y_test):
# 获取默认计算图
with tf.Graph().as_default() as g:
# 分别声明x与y_的占位符
x_placeholder = tf.placeholder(tf.float32, [None, INPUT_NODE], name="x-input")
y_placeholder = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name="y-input")
# 获取验证集的数据
validate_feed = {x_placeholder: x_test, y_placeholder: y_test}
# 调用前向传输过程
y = forward(x_placeholder, None)
# 评估验证的正确性
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_placeholder, 1))
# 打印准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
# 读取训练好的模型
ckpt = tf.train.get_checkpoint_state("model/")
if ckpt and ckpt.model_checkpoint_path:
# 恢复模型
saver.restore(sess, ckpt.model_checkpoint_path)
# 向模型喂入数据上
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print(" validation accuracy =", accuracy_score)
else:
print("No checkpoint file found")
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_test = x_test.reshape(-1, INPUT_NODE).astype('float32')
y_test = tf.keras.utils.to_categorical(y_test).astype('float32')
evaluate(x_test, y_test)(2)自制图片进行验证
import cv2
import tensorflow.compat.v1 as tf
tf.disable_eager_execution()
# 输入层为28*28的像素
INPUT_NODE = 784
# 输出层0~9有10类
OUTPUT_NODE = 10
# 隐藏层节点数
LAYER1_NODE = 500
# 为模型添加正则化
def get_regularizer_variable(weights, regularizer):
if regularizer is not None:
tf.add_to_collection("losses", regularizer(weights))
# 定义前向传输过程
def forward(input_tensor, regularizer):
# 第一层神经网络权重
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
# 第一层神经网络偏置项
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第一层神经网络输出
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 第二层网络权重
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
# 第二层神经网络偏置项
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
get_regularizer_variable(weights1, regularizer)
# 第二层神经网络输出
layer2 = tf.matmul(layer1, weights2) + biases2
return layer2# 对图像数据进行预处理
def preHandle():
# 读取图像数据
img = cv2.imread("two.png")
if img is not None:
print('读取成功!')
else:
print('读取失败!')
print(cv2.__version__)
# 将图像数据转化为灰度图像
gray_image = cv2.cvtColor(img, cv2.COLOR_BGRA2GRAY)
# 将图像数据转化为28*28矩阵
img = cv2.resize(gray_image, (28, 28))
pixels = []
h, w = img.shape
# 将图像数据归一化
for i in range(h):
for j in range(w):
pixels.append((255 - img[i, j]) * 1.0 / 255.0)
print(img.shape)
return pixels
def recognize():
# 获取默认计算图
with tf.Graph().as_default() as g:
# 声明占位符
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name="x-input")
y = forward(x, None)
# 声明saver对象
saver = tf.train.Saver()
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
result = preHandle()
# checkpoint函数会自动找到最新模型的文件名
ckpt = tf.train.get_checkpoint_state("model/")
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
prediction = tf.argmax(y, 1)
# 喂入神经网络数据
predint = prediction.eval(feed_dict={x: [result]}, session=sess)
print("result :", predint[0])
return predint[0]
else:
print("no model found")
return
if __name__ == '__main__':
recognize()读取成功!
4.1.2
(28, 28)
result : 23 TensorBoard可视化
3.1 tensorboard简介及配置
为了更方便TensorFlow程序的理解、调试与优化, Google发布了-套叫做TensorBoard的可视化工具,能在模型训练过程中将各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。主要可以可视化以下数据:
(1)标量数据(scalar) :用于记录和展示训练过程中的指标趋势,如准确率或者训练损失,以便观察损失是否正常收敛

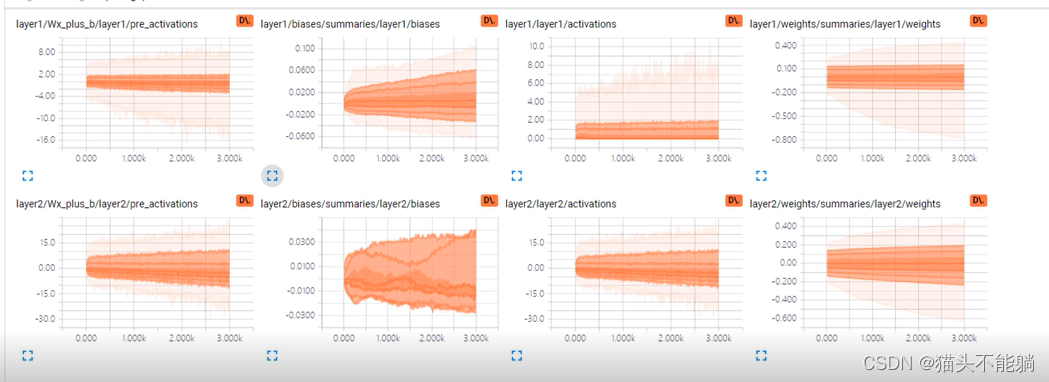
(2)直方图(histogram) :用于可视化任何tensor中数值的变化趋势,例如,可以用于记录参数在训练过程中的分布变化趋势,分析参数是否正常训练,有无异常值,分布是否符合预期等。
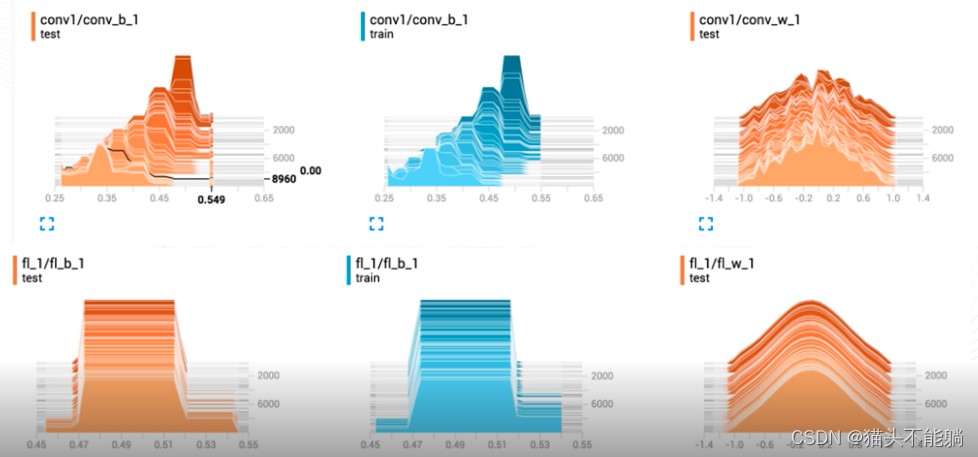
(3)图片(images) :可用于查看输入或生成的图片样本,辅助开发者定位问题,可用于卷积层或者其他参数的图形化展示。
(4)计算图(graph)显示代码中定义的计算图,也可以显示包括每个节点的计算时间、内存使用等情况。
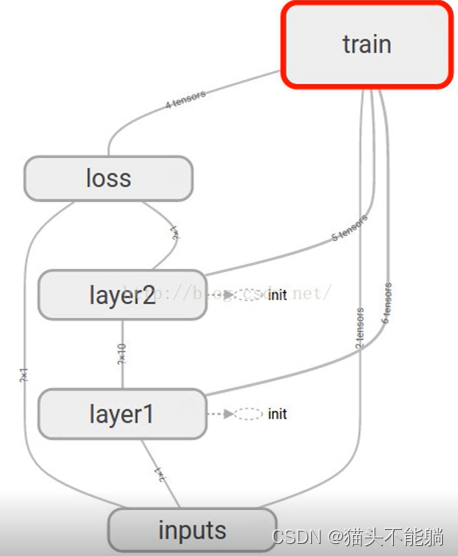
(5)数据分布(distribution) :显示模型参数随迭代次数的变化情况。