文章目录
- 4. 多线程带来的的风险-线程安全 (重点)
- 4.1 观察线程不安全
- 4.2 线程安全的概念
- 4.3 线程不安全的原因
- 4.3.1原子性
- 4.3.2可见性
- 4.3.3代码顺序性
- 4.4 解决之前的线程不安全问题
- 5. synchronized[ˈsɪŋkrənaɪzd] 关键字-监视器锁monitor lock
- 5.1 synchronized 的特性
- 5.2 synchronized 使用示例
- 5.3 Java 标准库中的线程安全类
- 5.4死锁代码演示
- 5.5如何避免死锁?
- 6. volatile[ˈvɒlətaɪl] 关键字
大家好,我是晓星航。今天为大家带来的是 多线程-初阶(中) 相关的讲解!😀
4. 多线程带来的的风险-线程安全 (重点)
万恶之源,罪魁祸首,多线程抢占式执行,带来的随机性。
如果没有多线程,代码执行顺序就是固定的。(只有一条路)
如果有了多线程,此时抢占式执行下,代码执行的顺序,会出现更多的变数!!!代码执行顺序的可能性就从一种情况 变成了 无数种情况!!!所以就需要保证这无数种情线程调度顺序的前提下,代码的执行结果都是正确的。
只要有一种情况下,代码结果不正确,就都视为有 bug ,线程不安全
4.1 观察线程不安全
package thread;
class Counter {
public int count = 0;
public void add() {
count++;
}
}
public class ThreadDemo13 {
public static void main(String[] args) {
Counter counter = new Counter();
//搞两个线程,两个线程分别针对 counter 来 调用 5W 次的 add 方法。
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
//启动线程
t1.start();
t2.start();
//等待两个线程结束
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
//打印最终的 count 值
System.out.println("count = " + counter.count);
}
}
大家观察下是否适用多线程的现象是否一致?同时尝试思考下为什么会有这样的现象发生呢?


预期count结果是10_0000但是实际结果确实5~6w,为什么会出现这样的问题呢?
答:这里出现问题就是因为我们多线程调用count的时候是不确定的,导致线程不安全使得数据计算出错。
++操作本质上要分成三步:
1.先把内存中的值,读取到 CPU 的寄存器中。load
2.把 CPU 寄存器里的数值进行 +1 运行。 add
3.把得到的结果写道内存中。 save
这三个操作就是CPU上执行的三个指令。
如果是两个线程并发的执行 count++ ,此时就相当于两组 load add save 进行执行。此时不同的 线程调度顺序 就可能会产生一些结果上的差异。
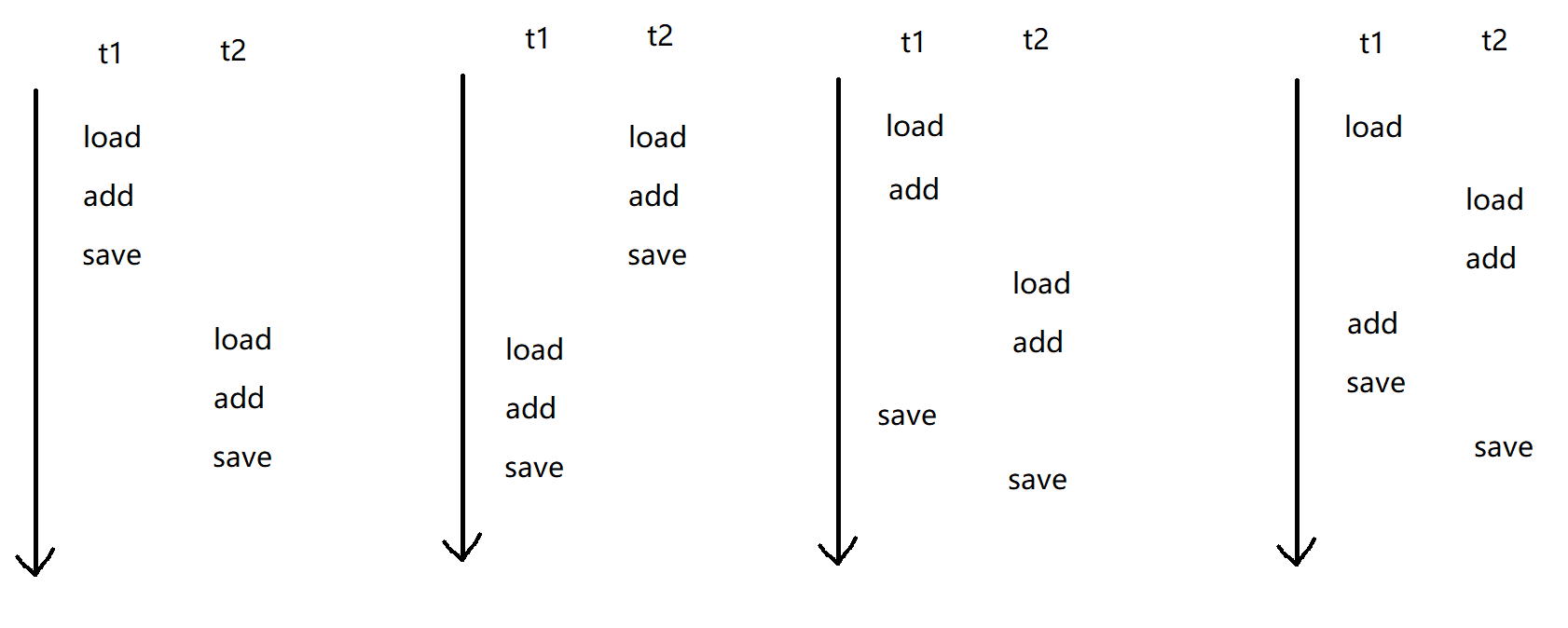
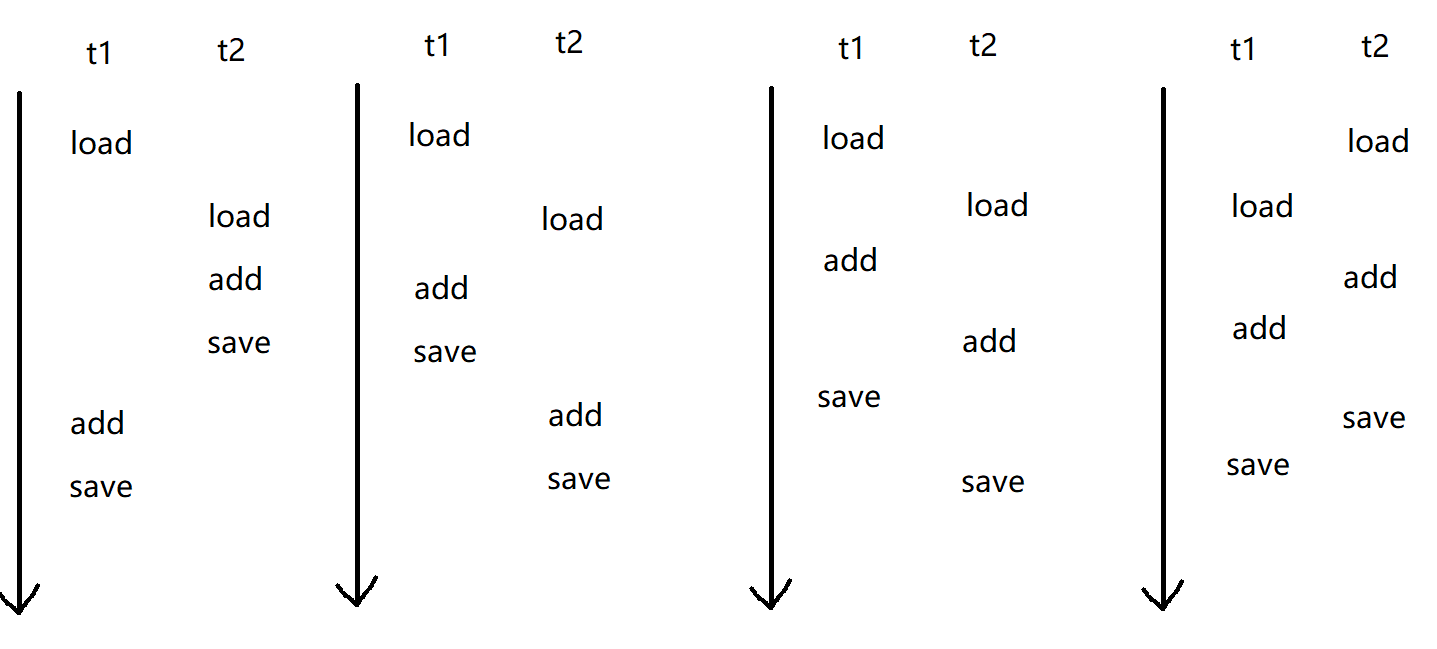
那么此时我们就会有各种各样的排列组合进来导致我们程序运行的随机性很大。进而导致我们运算时的结果就会出现差错。
这里我们t2读到了t1还没(提交)的数据,就类似于前面讲的"脏读"。因此会出现各种各样的错误。
解决方法:使用synchronized来对我们的add方法进行加锁,从而避免我们的代码出现脏读问题。
package thread;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 晓星航
* Date: 2023-07-14
* Time: 20:00
*/
class Counter {
public int count = 0;
synchronized public void add() {
count++;
}
}
public class ThreadDemo13 {
public static void main(String[] args) {
Counter counter = new Counter();
//搞两个线程,两个线程分别针对 counter 来 调用 5W 次的 add 方法。
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
//启动线程
t1.start();
t2.start();
//等待两个线程结束
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
//打印最终的 count 值
System.out.println("count = " + counter.count);
}
}

注:这里的第12行代码比之前的代码多了一个synchronized(加锁)

使用了加锁操作后,我们的运行结果就变为了预期值,即避免了脏读问题(t1修改还为提交数据,t2就已经读取完t1还为修改的数据了)。
加了synchronized之后,进入方法就会加锁,除了方法就会解锁,如果两个线程同时尝试加锁,此时一个能获取锁成功,另一个只能阻塞等待(BLOCKED),一直阻塞到刚才的线程释放锁(解锁),当前线程才能加锁成功!!!
加锁缺点:使代码执行速度大大降低。
4.2 线程安全的概念
想给出一个线程安全的确切定义是复杂的,但我们可以这样认为:
如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的。
4.3 线程不安全的原因
修改共享数据 (多个线程同时修改一个变量)
上面的线程不安全的代码中, 涉及到多个线程针对 counter.count 变量进行修改.
此时这个counter.count是一个多个线程都能访问到的 “共享数据”

counter.count这个变量就是在堆上. 因此可以被多个线程共享访问.
4.3.1原子性
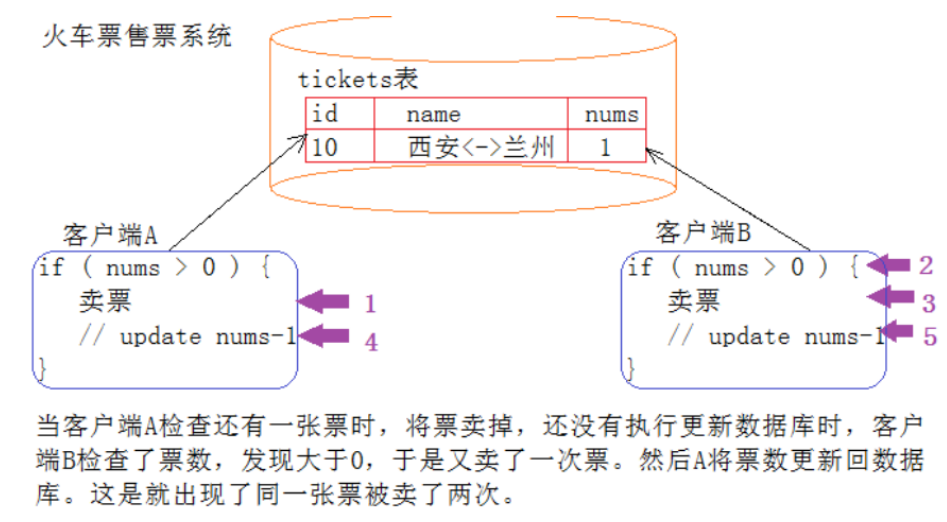
什么是原子性
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证,A进入 房间之后,还没有出来;B 是不是也可以进入房间,打断 A 在房间里的隐私。这个就是不具备原子性的。
那我们应该如何解决这个问题呢?是不是只要给房间加一把锁(synchronized),A 进去就把门锁上,其他人是不是就进不来了。这样就保证了这段代码的原子性了。
有时也把这个现象叫做同步互斥,表示操作是互相排斥的。
一条 java 语句不一定是原子的,也不一定只是一条指令
比如刚才我们看到的 n++,其实是由三步操作组成的:
- 从内存把数据读到 CPU load
- 进行数据更新 add
- 把数据写回到 CPU save
不保证原子性会给多线程带来什么问题
如果一个线程正在对一个变量操作,中途其他线程插入进来了,如果这个操作被打断了,结果就可能是 错误的。
这点也和线程的抢占式调度密切相关. 如果线程不是 “抢占” 的, 就算没有原子性, 也问题不大.
4.3.2可见性
可见性指, 一个线程对共享变量值的修改,能够及时地被其他线程看到.
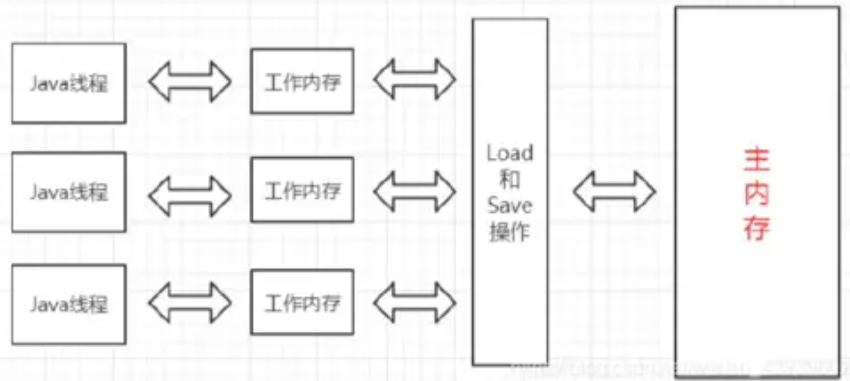
Java 内存模型 (JMM): Java虚拟机规范中定义了Java内存模型.
目的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并 发效果.
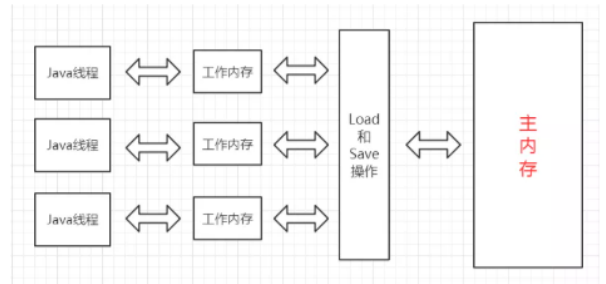
- 线程之间的共享变量存在 主内存 (Main Memory).
- 每一个线程都有自己的 “工作内存” (Working Memory) .
- 当线程要读取一个共享变量的时候, 会先把变量从主内存拷贝到工作内存, 再从工作内存读取数据.
- 当线程要修改一个共享变量的时候, 也会先修改工作内存中的副本, 再同步回主内存.
由于每个线程有自己的工作内存, 这些工作内存中的内容相当于同一个共享变量的 “副本”. 此时修改线程 1 的工作内存中的值, 线程2 的工作内存不一定会及时变化.
- 初始情况下, 两个线程的工作内存内容一致.

- 一旦线程1 修改了 a 的值, 此时主内存不一定能及时同步. 对应的线程2 的工作内存的 a 的值也不一定 能及时同步.
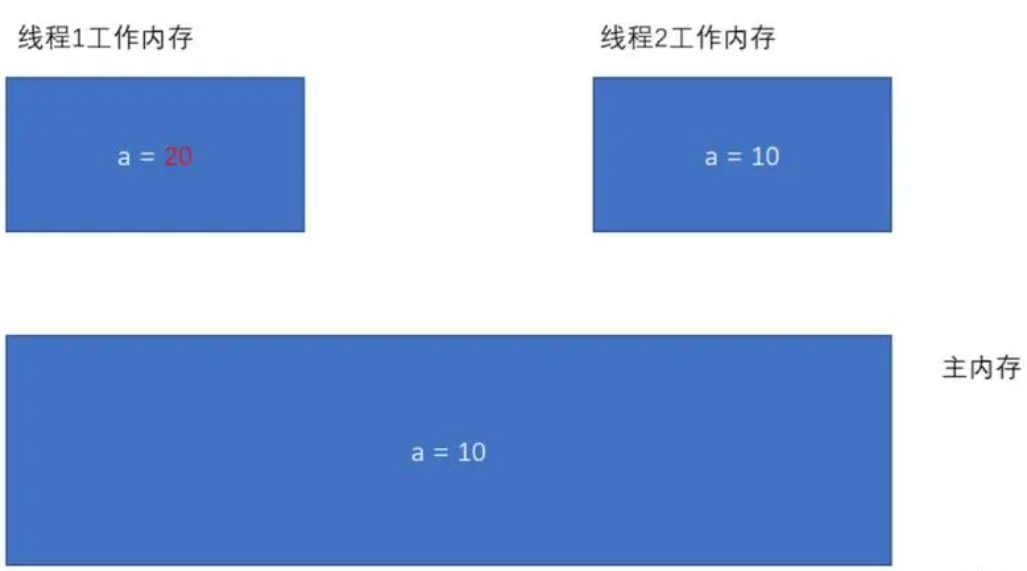
这个时候代码中就容易出现问题.
此时引入了两个问题:
- 为啥要整这么多内存?
- 为啥要这么麻烦的拷来拷去?
- 为啥整这么多内存?
实际并没有这么多 “内存”. 这只是 Java 规范中的一个术语, 是属于 “抽象” 的叫法. 所谓的 “主内存” 才是真正硬件角度的 “内存”.
而所谓的 “工作内存”, 则是指 CPU 的寄存器和高速缓存.
- 为啥要这么麻烦的拷来拷去?
因为 CPU 访问自身寄存器的速度以及高速缓存的速度, 远远超过访问内存的速度(快了 3 - 4 个数量级, 也 就是几千倍, 上万倍).
比如某个代码中要连续 10 次读取某个变量的值, 如果 10 次都从内存读, 速度是很慢的. 但是如果 只是第一次从内存读, 读到的结果缓存到 CPU 的某个寄存器中, 那么后 9 次读数据就不必直接访问 内存了. 效率就大大提高了.
那么接下来问题又来了, 既然访问寄存器速度这么快, 还要内存干啥??
答案就是一个字: 贵
值的一提的是, 快和慢都是相对的. CPU 访问寄存器速度远远快于内存, 但是内存的访问速度又远 远快于硬盘.
对应的, CPU 的价格最贵, 内存次之, 硬盘最便宜.
4.3.3代码顺序性
什么是代码重排序
一段代码是这样的:
- 去前台取下 U 盘
- 去教室写 10 分钟作业
- 去前台取下快递
如果是在单线程情况下,JVM、CPU指令集会对其进行优化,比如,按 1->3->2的方式执行,也是没问 题,可以少跑一次前台。这种叫做指令重排序
编译器对于指令重排序的前提是 “保持逻辑不发生变化”. 这一点在单线程环境下比较容易判断, 但 是在多线程环境下就没那么容易了, 多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代 码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价.
重排序是一个比较复杂的话题, 涉及到 CPU 以及编译器的一些底层工作原理, 此处不做过多讨论
4.4 解决之前的线程不安全问题
这里用到的机制,我们马上会给大家解释。
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
5. synchronized[ˈsɪŋkrənaɪzd] 关键字-监视器锁monitor lock
所以加锁,是要明确执行对哪个对象加锁的。
如果两个线程针对同一个对象加锁,会产生阻塞等待(锁竞争/锁冲突)
如果两个线程针对不同对象加锁,不会阻塞等待(不会锁竞争/锁冲突)
无论这个对象是个啥对象,原则就一条,锁对象相同,就会产生锁竞争(产生阻塞等待),锁对象不同就不会产生锁竞争(不会阻塞等待)
5.1 synchronized 的特性
1)互斥
synchronized 会起到互斥效果, 某个线程执行到某个对象的 synchronized 中时, 其他线程如果也执行到 同一个对象 synchronized 就会阻塞等待.
- 进入 synchronized 修饰的代码块, 相当于 加锁
- 退出 synchronized 修饰的代码块, 相当于 解锁

synchronized用的锁是存在Java对象头里的。

可以粗略理解成, 每个对象在内存中存储的时候, 都存有一块内存表示当前的 “锁定” 状态(类似于厕 所的 “有人/无人”).
如果当前是 “无人” 状态, 那么就可以使用, 使用时需要设为 “有人” 状态.
如果当前是 “有人” 状态, 那么其他人无法使用, 只能排队
一个线程先上了锁,其他线程只能等待这个线程释放。
理解 “阻塞等待”.
针对每一把锁, 操作系统内部都维护了一个等待队列. 当这个锁被某个线程占有的时候, 其他线程尝 试进行加锁, 就加不上了, 就会阻塞等待, 一直等到之前的线程解锁之后, 由操作系统唤醒一个新的 线程, 再来获取到这个锁.
注意:
- 上一个线程解锁之后, 下一个线程并不是立即就能获取到锁. 而是要靠操作系统来 “唤醒”. 这 也就是操作系统线程调度的一部分工作.
- 假设有 A B C 三个线程, 线程 A 先获取到锁, 然后 B 尝试获取锁, 然后 C 再尝试获取锁, 此时 B 和 C 都在阻塞队列中排队等待. 但是当 A 释放锁之后, 虽然 B 比 C 先来的, 但是 B 不一定就能 获取到锁, 而是和 C 重新竞争, 并不遵守先来后到的规则.
synchronized的底层是使用操作系统的mutex lock实现的.
2)刷新内存
synchronized 的工作过程:
- 获得互斥锁
- 从主内存拷贝变量的最新副本到工作的内存
- 执行代码
- 将更改后的共享变量的值刷新到主内存
- 释放互斥锁
所以 synchronized 也能保证内存可见性. 具体代码参见后面 volatile 部分.
3)可重入
synchronized 同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题;
理解 “把自己锁死”
一个线程没有释放锁, 然后又尝试再次加锁.
// 第一次加锁, 加锁成功 lock(); // 第二次加锁, 锁已经被占用, 阻塞等待. lock();按照之前对于锁的设定, 第二次加锁的时候, 就会阻塞等待. 直到第一次的锁被释放, 才能获取到第 二个锁. 但是释放第一个锁也是由该线程来完成, 结果这个线程已经躺平了, 啥都不想干了, 也就无 法进行解锁操作. 这时候就会 死锁.
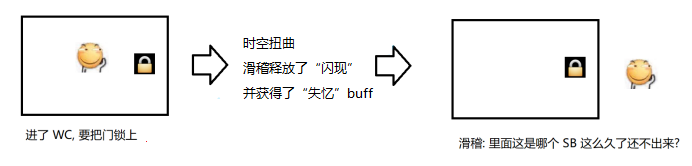
这样的锁称为 不可重入锁
Java 中的 synchronized 是 可重入锁, 因此没有上面的问题.
代码示例
在下面的代码中,
- increase 和 increase2 两个方法都加了 synchronized, 此处的 synchronized 都是针对 this 当前 对象加锁的.
- 在调用 increase2 的时候, 先加了一次锁, 执行到 increase 的时候, 又加了一次锁. (上个锁还没释 放, 相当于连续加两次锁)
这个代码是完全没问题的. 因为 synchronized 是可重入锁.
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
synchronized void increase2() {
increase();
}
}
在可重入锁的内部, 包含了 “线程持有者” 和 “计数器” 两个信息.
- 如果某个线程加锁的时候, 发现锁已经被人占用, 但是恰好占用的正是自己, 那么仍然可以继续获取 到锁, 并让计数器自增.
- 解锁的时候计数器递减为 0 的时候, 才真正释放锁. (才能被别的线程获取到)

如果允许二次加锁,这个锁就是可重入的。
如果不允许二次加锁,那么就会阻塞等待,就是不可重入的。这个情况会导致线程"僵住了",即死锁了。
因为在Java里面这种代码是很容易出现的。
为了避免不小心就死锁,Java就把synchronized设定成可重入的了。
但是c++,Python,操作系统原生的锁,都是不可重入的
5.2 synchronized 使用示例
synchronized 本质上要修改指定对象的 “对象头”. 从使用角度来看, synchronized 也势必要搭配一个具 体的对象来使用.
1)直接修饰普通方法: 锁的 SynchronizedDemo 对象
public class SynchronizedDemo {
public synchronized void methond() {
}
}
直接把synchronized修饰到方法上,此时相当于针对this加锁。

t1执行add,就加上锁了,针对count这个对象加上锁了。
t2执行add的时候,也尝试对count加锁,但是由于count已经被t1给占用了。因此这里的加锁操作就回阻塞。
2)修饰静态方法: 锁的 SynchronizedDemo 类的对象
public class SynchronizedDemo {
public synchronized static void method() {
}
}
3)修饰代码块: 手动指定锁哪个对象.
锁当前对象
public class SynchronizedDemo {
public void method() {
synchronized (this) {
}
}
}

锁内对象
public class SynchronizedDemo {
public void method() {
synchronized (SynchronizedDemo.class) {
}
}
}
我们重点要理解,synchronized 锁的是什么. 两个线程竞争同一把锁, 才会产生阻塞等待.
两个线程分别尝试获取两把不同的锁, 不会产生竞争.
5.3 Java 标准库中的线程安全类
Java 标准库中很多都是线程不安全的. 这些类可能会涉及到多线程修改共享数据, 又没有任何加锁措施.
- ArrayList
- LinkedList
- HashMap
- TreeMap
- HashSet
- TreeSet
- StringBuilder
但是还有一些是线程安全的. 使用了一些锁机制来控制.
- Vector (不推荐使用)
- HashTable (不推荐使用)
- ConcurrentHashMap
- StringBuffer
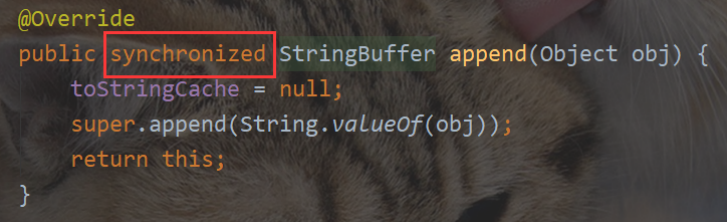
StringBuffer 的核心方法都带有
synchronized.
还有的虽然没有加锁, 但是不涉及 “修改”, 仍然是线程安全的
- String
那么强行加锁之后,线程就会变得安全,为什么不全部加锁呢?
答:因为加锁这个操作是有副作用的,有额外的时间开销,所以我们的API没有给所有的线程都强制加锁。
5.4死锁代码演示
死锁代码演示:
public class ThreadDemo15 {
public static void main(String[] args) {
Object locker1 = new Object();
Object locker2 = new Object();
Thread t1 = new Thread(()->{
synchronized (locker1) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2) {
System.out.println("t1 把 locker1 和 locker2 都拿到了");
}
}
});
Thread t2 = new Thread(()->{
synchronized (locker2) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker1) {
System.out.println("t2 把 locker1 和 locker2 都拿到了");
}
}
});
t1.start();
t2.start();
}
}

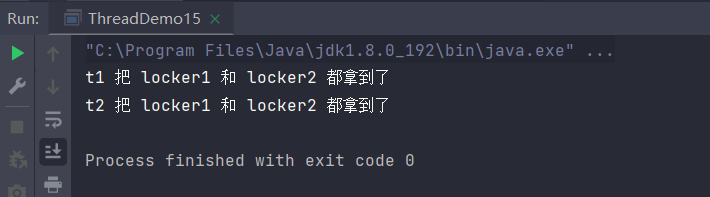
这里没有输出出结果就是因为死锁问题,t1和t2都获取不到所需的对象。(因为t1和t2所需要的对象都在对方手上,而他们需要获取到各自所需要的对象才会释放手上的,因为导致僵持住了)
小tips:shift + F6可以一键给所有变量改名。
5.5如何避免死锁?
死锁的四个必要条件:
1.互斥使用
线程1拿到了锁,线程2就得等着。(锁的基本特性)
2.不可抢占
线程1拿到锁之后,必须是线程1主动释放。不能是线程2把锁强行获取到。
3.请求与保持
线程1拿到锁A之后,再尝试获取锁B,A这把锁还是保持的。(不会因为获取锁B就把锁A释放了)
4.循环等待
线程1尝试获取锁A和锁B,线程2尝试获取锁B和锁A。
线程1在获取B的时候在等待线程2释放B;线程2在获取A的时候在等待线程1释放A。
这里四个条件,实际上就是一个条件,前面三个条件都是锁的基本特性,循环等待是这四个条件里唯一一个和代码结构相关的。也是咱们程序猿可以控制的。
那么我们如何避免死锁呢?
办法:给锁编号,然后指定一个固定的顺序(比如从小到大)来加锁。任意线程加多把锁的时候,都让线程遵守上述顺序,此时循环等待自然破除。



这里我们改了一下顺序把t2拿锁的顺序从先拿locker2再拿locker1,改为了和t1一样的顺序,即都是先拿小的,locker1,再拿locker2,就完美的解决了死锁问题。
改前代码运行结果:

改后代码运行结果:
6. volatile[ˈvɒlətaɪl] 关键字
用来解决一个读一个写可能造成的问题。
volatile 能保证内存可见性
volatile 修饰的变量, 能够保证 “内存可见性”.
代码在写入 volatile 修饰的变量的时候,
- 改变线程工作内存中volatile变量副本的值
- 将改变后的副本的值从工作内存刷新到主内存
代码在读取 volatile 修饰的变量的时候,
- 从主内存中读取volatile变量的最新值到线程的工作内存中
- 从工作内存中读取volatile变量的副本
前面我们讨论内存可见性时说了, 直接访问工作内存(实际是 CPU 的寄存器或者 CPU 的缓存), 速度 非常快, 但是可能出现数据不一致的情况.
加上 volatile , 强制读写内存. 速度是慢了, 但是数据变的更准确了.
代码示例
在这个代码中
- 创建两个线程 t1 和 t2
- t1 中包含一个循环, 这个循环以 flag == 0 为循环条件.
- t2 中从键盘读入一个整数, 并把这个整数赋值给 flag.
- 预期当用户输入非 0 的值的时候, t1 线程结束.
static class Counter {
public int flag = 0;
}
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
while (counter.flag == 0) {
// do nothing
}
System.out.println("循环结束!");
});
Thread t2 = new Thread(() -> {
Scanner scanner = new Scanner(System.in);
System.out.println("输入一个整数:");
counter.flag = scanner.nextInt();
});
t1.start();
t2.start();
}
// 执行效果
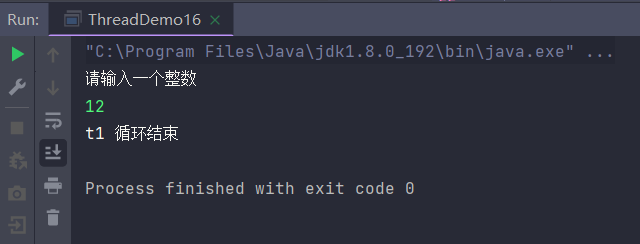
// 当用户输入非0值时, t1 线程循环不会结束. (这显然是一个 bug)
我们预期输入一个值,使得t2线程结束,而输入的值导致flag改变,进而使得t1里面的flag !=0结束循环,至此打印t1 循环结束,从而导致程序结束。
实际运行结果图:

那么为什么这里和我们预期结果不一样呢,t2输入值改变了flag使其不为0,但是线程t1仍然没有结束。
那么这个情况就叫做线程可见性问题。
下面就为大家讲解这个问题是如何出现的:
这里使用汇编来理解,大概就是两步操作:
1.load,把内存中的falg的值,读取到寄存器里。
2.cmp,把寄存器的值和0进行比较。根据比较结果,决定下一步往哪个方向执行(条件跳转指令)
上述是个循环,这个循环速度极快,一秒钟执行上百万次以上
循环这么多次,在t2真正修改之前,load得到的结果都是一样的。
另一方面,load操作和cmp操作相比,速度慢非常非常多。
由于load执行速度太慢(相比于cmp来说),在加上反复 load 得到的结果都一样,JVM就做出了一个非常大胆的决定~~~ 不再真正的重复load了,判定好像没人改flag值,那干脆就只读取一次就好了。(编译器优化的一种方式)
t1 读的是自己工作内存中的内容.
当 t2 对 flag 变量进行修改, 此时 t1 感知不到 flag 的变化.
如果给 flag 加上 volatile
static class Counter {
public volatile int flag = 0;
}
// 执行效果
// 当用户输入非0值时, t1 线程循环能够立即结束.

我们加上volatile
加上了volatile之后,我们编译器就知道了flag这个操作不能随便乱改,因此编译器再次运行的结果就是正确的。
我们从JMM的角度来重新描述内存可见性问题:
Java 程序里,主内存,每个线程都有自己的工作内存(t1 的 和 t2的 工作内存不是一个东西)
t1 线程进行读取的时候,知识读取了工作内存的值
t2 线程进行修改的时候,先修改的工作内存的值,然后再把工作内存的内容同步到主内存中。
但是由于编译器优化,导致 t1 没有重新的从主内存同步数据到工作内存,读取到的结果就是"修改之前"的结果。
主内存 --> 内存
工作内存 --> CPU寄存器
工作内存可能不只是 CPU寄存器 可能还有 CPU缓存(cache)
volatile 不保证原子性
volatile 和 synchronized 有着本质的区别. synchronized 能够保证原子性, volatile 保证的是内存可见性.
代码示例
这个是最初的演示线程安全的代码.
- 给 increase 方法去掉 synchronized
- 给 count 加上 volatile 关键字.
static class Counter {
volatile public int count = 0;
void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
此时可以看到, 最终 count 的值仍然无法保证是 100000.
synchronized 也能保证内存可见性 (存疑)
synchronized 既能保证原子性, 也能保证内存可见性. (要保存两个性质的话建议把synchronized 和 volatile 都用上)
对上面的代码进行调整:
- 去掉 flag 的 volatile
- 给 t1 的循环内部加上 synchronized, 并借助 counter 对象加锁.
static class Counter {
public int flag = 0;
}
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
while (true) {
synchronized (counter) {
if (counter.flag != 0) {
break;
}
}
// do nothing
}
System.out.println("循环结束!");
});
Thread t2 = new Thread(() -> {
Scanner scanner = new Scanner(System.in);
System.out.println("输入一个整数:");
counter.flag = scanner.nextInt();
});
t1.start();
t2.start();
}

感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘