本篇文章来详细介绍一下数据结构中的链表。
目录
1.链表的概念及结构
2.链表的分类
3.单链表的实现
4.链表的面试题
5.双向链表的实现
6.顺序表和链表的区别
1.链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。

注意:
- 从上图可看出,链式结构在逻辑上是连续的,但是在物理上不一定连续
- 现实中的结点一般都是从堆上申请出来的
- 从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续
2.链表的分类
实际中链表的结构非常多样,以下3种情况组合起来就有8种链表结构,2^3 = 8:
1.单项或者双向
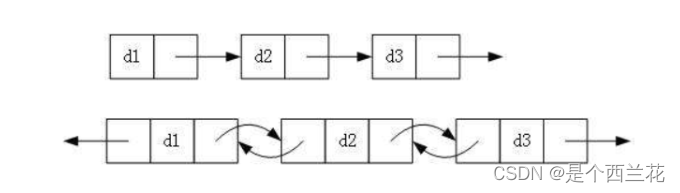
2.带头或者不带头
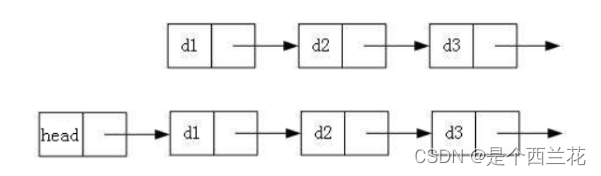
3.循环或者非循环

虽然有这么多的链表的结构,但是我们实际中最常用的还是两种结构
1.无头单向非循环链表

2.带头双向循环链表

1.无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2.带头双向循环链表∶结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
3.单链表的实现
//无头+单行+非循环链表的增删改查实现
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SListNode;
// 动态申请一个节点
SListNode* BuySListNode(SLTDataType x);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDataType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDataType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDataType x);
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?因为单链表只能向后访问
void SlistInsertAfter(SListNode* pos, SLTDataType x);
// 单链表删除pos位置之后的值
// 分析思考为什么不删除pos位置?因为单链表只能向后访问
void SlistEraseAfter(SListNode* pos);
// 单链表的销毁
void SListDestroy(SListNode** pphead);
//在pos之前插入
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x);
//删除pos位置的值
void SListErase(SListNode** pphead, SListNode* pos);接口实现:
// 动态申请一个节点
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
//申请成功
newnode->data = x;
newnode->next = NULL;
return newnode;
}
// 单链表打印
void SListPrint(SListNode* plist)
{
SListNode* cur = plist;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDataType x)
{
assert(pplist);//链表为空,pphead也不为空,因为它是头指针plist的地址
SListNode* newnode = BuySListNode(x);
//空链表
if (*pplist == NULL)
{
*pplist = newnode;
}
else
{
SListNode* tail = *pplist;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDataType x)
{
assert(pplist);//链表为空,pphead也不为空,因为它是头指针plist的地址
SListNode* newnode = BuySListNode(x);
newnode->next = *pplist;
*pplist = newnode;
}
// 单链表的尾删
void SListPopBack(SListNode** pplist)
{
assert(pplist);//链表为空,pphead也不为空,因为它是头指针plist的地址
assert(*pplist);//空链表不能尾删
if ((*pplist)->next == NULL)
{
free(*pplist);
*pplist = NULL;
}
else
{
//方法一:
SListNode* tail = *pplist;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
//方法二
/*SListNode* tail = *pplist;
SListNode* prev = *pplist;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;*/
}
}
// 单链表头删
void SListPopFront(SListNode** pplist)
{
assert(pplist);//链表为空,pphead也不为空,因为它是头指针plist的地址
assert(*pplist);//空链表不能头删
SListNode* del = *pplist;
*pplist = (*pplist)->next;
free(del);
del = NULL;
}
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDataType x)
{
SListNode* cul = plist;
while (cul)
{
if (cul->data == x)
return cul;
cul = cul->next;
}
return NULL;
}
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?没有地址,找不到,单链表只能找后面的
void SlistInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
// 单链表删除pos位置之后的值
// 分析思考为什么不删除pos位置?没有地址,找不到
void SlistEraseAfter(SListNode* pos)
{
assert(pos);
assert(pos->next);
SListNode* del = pos->next;
pos->next = pos->next->next;
free(del);
del = NULL;
}
// 单链表的销毁
void SListDestroy(SListNode** pphead)
{
SListNode* del = *pphead;
while (*pphead)
{
del = *pphead;
*pphead = (*pphead)->next;
free(del);
}
}
//在pos之前插入
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
if (pos == *pphead)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
SListNode* cur = *pphead;
while (cur)
{
if (cur->next == pos)
{
newnode->next = pos;
cur->next = newnode;
return;
}
cur = cur->next;
}
}
}
//删除pos位置的值
void SListErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
if (pos == *pphead)
{
*pphead = (*pphead)->next;
free(pos);
}
else
{
SListNode* cur = *pphead;
while (cur)
{
if (cur->next == pos)
{
cur->next = pos->next;
free(pos);
return;
}
cur = cur->next;
}
}
}4.链表的面试题
1.删除链表中等于给定值val的所有结点。OJ链接
2.反转一个单链表。OJ链接
3.给定一个带有头结点head的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。ОJ链接
4.输入一个链表,输出该链表中倒数第k个结点。OJ链接
5.将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有结点组成的。OJ链接
6.编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前。OJ链接
7.链表的回文结构。OJ链接
8.输入两个链表,找出它们的第一个公共结点。OJ链接
9.给定一个链表,判断链表中是否有环。OJ链接
【思路】
快慢指针,即慢指针一次走一步,快指针一次走两步,两个指针从链表起始位置开始运行,如果链表带环则一定会在环中相遇,否则快指针率先走到链表的末尾。
【扩展问题】
1.为什么快指针每次走两步,慢指针走一步可以?
假设链表带环,两个指针最后都会进入环,快指针先进环,慢指针后进环。当慢指针刚进环时,可能就和快指针相遇了,最差情况下两个指针之间的距离刚好就是环的长度。此时,两个指针每移动一次,之间的距离就缩小一步,不会出现每次刚好是套圈的情况,因此:在慢指针走到一圈之前,快指针肯定是可以追上慢指针的,即相遇。
2.快指针一次走3步,走4步,...n步行吗?
假设:快指针每次走3步,满指针每次走一步,此时快指针肯定先进环,慢指针后来才进
环。假设慢指针进环时候,快指针的位置如图所示:
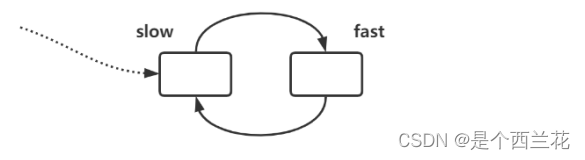
此时按照上述方法来绕环移动,每次快指针走3步,慢指针走1步,是永远不会相遇的,快指针刚好将慢指针套圈了,因此不行。
只有快指针走2步,慢指针走一步才可以,因为换的最小长度是1,即使套圈了两个也在相同的位置。
10.给定一个链表,返回链表开始入环的第一个结点。如果链表无环,则返回NULL。OJ链接
结论:
双指针:先让一个指针走一步,一个指针走两步,最终两个指针会在环内相遇。再让一个指针从链表起始位置开始遍历链表,同时让一个指针从判环时相遇点的位置开始绕环运行,两个指针都是每次均走一步,最终肯定会在入口点的位置相遇。
证明:
说明:
phead为链表的起始点,E为环入口点,M与判断是否是环的时候相遇点(快慢指针第9题)
设:
环的长度为R,H到E的距离为LE到M的距离为X则:M到E的距离为R-x
在判环时,快慢指针相遇时所走的路径长度:
- fast: L +X + nR
- slow: L+ x
注意:
1.当慢指针进入环时,快指针可能已经在环中绕了n圈了,n至少为1因为:快指针先进环走到M的位置,最后又在M的位置与慢指针相遇
2.慢指针进环之后,快指针肯定会在慢指针走一圈之内追上慢指针
因为:慢指针进环后,快慢指针之间的距离最多就是环的长度,而两个指针在移动时,每次它们至今的距离都缩减一步(速度差是1),因此在慢指针移动一圈之前快指针肯定是可以追上慢指针的
而快指针速度是满指针的两倍,因此有如下关系是:2*(L+ X)= L+ X + nR
L+ x = nR
L= nR- x(n为1,2,3,4.......n的大小取决于环的大小,环越小n越大)
极端情况下,假设n = 1,此时:L =R- x
即:一个指针从链表起始位置运行,一个指针从相遇点位置绕环,每次都走一步,两个指针最终会在入口点的位置相遇
11.给定一个链表,每个结点包含一个额外增加的随机指针,该指针可以指向链表中的任何结点
或空结点。
要求返回这个链表的深度拷贝。OJ链接
5.双向链表的实现
// 带头+双向+循环链表增删查改实现
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int LTDataType;
typedef struct ListNode
{
struct ListNode* prev;
LTDataType data;
struct ListNode* next;
}LTNode;
//初始化
//void InitListNode(LTNode** phead)//使用二级指针
LTNode* InitListNode();//使用返回值
//打印
void LTPrint(LTNode* phead);
//尾插
void LTPushBack(LTNode* phead, LTDataType x);
//头插
void LTPushFront(LTNode* phead, LTDataType x);
//判空
bool LTEmpty(LTNode* phead);
//尾删
void LTPopBack(LTNode* phead);
//头删
void LTPopFront(LTNode* phead);
//查找
LTNode* LTFind(LTNode* phead, LTDataType x);
//pos之前插入(与顺序表一致)
void LTInsert(LTNode* pos, LTDataType x);
//删除pos位置的值
void LTErase(LTNode* pos);
//释放链表
void LTDestroy(LTNode* phead);接口实现:
LTNode* BuyaNewNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
newnode->prev = NULL;
newnode->next = NULL;
newnode->data = x;
return newnode;
}
//初始化
LTNode* InitListNode()
{
LTNode* phead = BuyaNewNode(0);
phead->next = phead;
phead->prev = phead;
return phead;
}
//打印
void LTPrint(LTNode* phead)
{
assert(phead);
printf("gurad<==>");
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d<==>", cur->data);
cur = cur->next;
}
printf("gurad\n");
}
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{
//LTInsert(phead, x);
assert(phead);
LTNode* newnode = BuyaNewNode(x);
LTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{
//LTInsert(phead->next, x);
assert(phead);
LTNode* newnode = BuyaNewNode(x);
newnode->next = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next->prev = newnode;
}
bool LTEmpty(LTNode* phead)
{
if (phead->next == phead)
{
return true;
}
else
{
return false;
}
}
//尾删
void LTPopBack(LTNode* phead)
{
assert(phead);
assert(!LTEmpty(phead));//空链表
//LTErase(phead->prev);
LTNode* tail = phead->prev;
LTNode* tailprev = tail->prev;
free(tail);
phead->prev = tailprev;
tailprev->next = phead;
}
//头删
void LTPopFront(LTNode* phead)
{
assert(phead);
assert(!LTEmpty(phead));//空链表
//LTErase(phead->next);
LTNode* frist = phead->next;
LTNode* second = frist->next;
free(frist);
phead->next = second;
second->prev = phead;
}
//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//pos之前插入(与顺序表一致)
void LTInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = BuyaNewNode(x);
LTNode* prev = pos->prev;
newnode->prev = prev;
newnode->next = pos;
prev->next = newnode;
pos->prev = newnode;
}
//删除pos位置的值
void LTErase(LTNode* pos)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
}
//释放链表
void LTDestroy(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
}6.顺序表和链表的区别
链表(双向循环带头链表):
优点:
- 任意位置插入删除O(1)
- 按需申请释放空间
缺点:
- 不支持下标随机访问
- CPU高速缓存命中率会更低
顺序表:
缺点:
- 前面部分插入删除数据,效率是O(N),需要挪动数据。
- 空间不够,需要扩容。a、扩容是需要付出代价的 b、一般还会伴随空间浪费。
优点:
- 尾插尾删效率不错。
- 下标的随机访问。
- CPU高速缓存命中率会更高
| 不同点 | 顺序表 | 链表 |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持,为O(N) |
| 任意位置插入或者删除元素 | 可能需要搬移元素,效率低O(N) | 只需要修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入或删除频繁 |
| 缓存利用率 | 高 | 低 |
备注:缓存利用率参考存储体系结构 以及 程序的局部性原理。
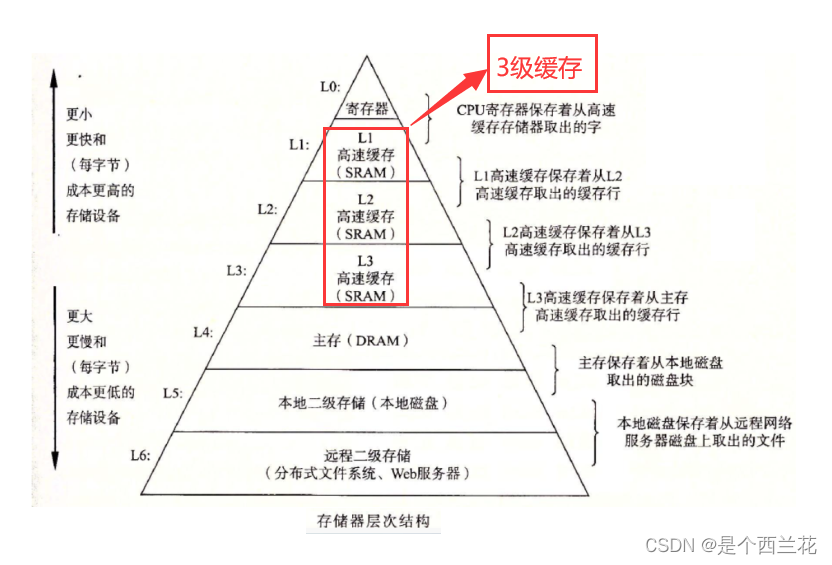
数据结构是为了帮助我们跟好的管理内存。内存需要电,关机后就会消失,磁盘存储的数据在关机后也不会消失。
在CPU与内存之间存在寄存器和三级缓存。内存小使用寄存器(一般几个字节),大的使用三级缓存。
CPU读取数据时
- 先去看数据是否在缓存,在就叫缓存命中,则直接访问
- 不在就不命中,先加载数据到缓存,再访问
因为缓存一次会加载需要的数据以及这个数据旁边的数据,数组是连续存放的,所以缓存利用率高。
可以参考:与程序员相关的CPU缓存知识
本篇结束。