Abstract&Introduction&Related Work
-
研究任务
对大模型进行部分微调 -
已有方法和相关工作
现有技术通常通过扩展模型深度引入推理延迟(Houlsby 等人,2019;Rebuffi 等人,2017),或通过减少模型可用序列长度(Li 和 Liang,2021;Lester 等人,2021;Ham-bardzumyan 等人,2020;Liu 等人,2021) -
面临挑战
这些方法通常无法达到微调基线,提出了效率与模型质量之间的权衡。 -
创新思路
学习过度参数化的模型实际上位于低内在维度上。我们假设模型适应期间权重变化也具有低“内在秩”,从而提出了我们提出的低秩适应
(LoRA)方法。
-
实验结论
- 预训练模型可以共享并用于为不同任务构建许多小型 LoRA 模块。我们可以冻结共享模型并通过替换图 1 中的矩阵 A 和 B 来有效地切换任务,显著减少存储需求和任务切换开销
- LoRA 使训练更高效,并在使用自适应优化器时将硬件入门门槛降低了多达 3 倍,因为我们不需要计算大多数参数的梯度或保持优化器状态。相反,我们只优化注入的、更小的低秩矩阵
- 我们简单的线性设计允许我们在部署时将可训练矩阵与冻结权重合并,在构造上不引入与完全微调模型相比的推理延迟
- LoRA 正交于许多先前方法,并且可以与其中许多方法结合使用, 例如前缀调整
常规的完全微调的公式: max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) \max_\Phi\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log\left(P_\Phi(y_t|x,y_{<t})\right) maxΦ∑(x,y)∈Z∑t=1∣y∣log(PΦ(yt∣x,y<t))
完全微调的主要缺点之一是对于每个下游任务,我们学习一组不同的参数∆Φ,其维数|∆Φ|等于|Φ0|。因此,如果预训练模型很大(如GPT-3,其中|Φ0| ≈ 1750亿),存储和部署许多独立实例的微调模型可能具有挑战性
在本文中采用了一种更具参数效率的方法,其中任务特定参数增量 ∆ Φ = ∆ Φ ( Θ ) ∆Φ = ∆Φ(Θ) ∆Φ=∆Φ(Θ)进一步由尺寸更小的一组参数 Θ Θ Θ编码,其中 ∣ Θ ∣ |Θ| ∣Θ∣ 远小于 ∣ Φ 0 ∣ |Φ_0| ∣Φ0∣
公式更改为: max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) \max_\Theta\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log\left(p_{\Phi_0+\Delta\Phi(\Theta)}(y_t|x,y_{<t})\right) maxΘ∑(x,y)∈Z∑t=1∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))
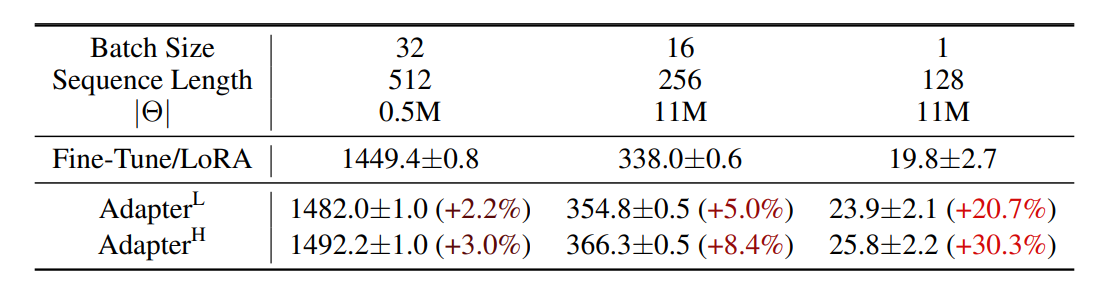
GPT-2中型单次前向传递的推理延迟,以毫秒为单位,平均100次试验。我们使用NVIDIA Quadro RTX8000。“|Θ|”表示适配器层中可训练参数的数量。AdapterL和AdapterH是两种adapter微调的变体,在在线、短序列长度场景中,适配器层引入的推理延迟可能很大。
当我们需要像 Shoeybi 等人(2020);Lepikhin 等人(2020)那样分片模型时,这个问题会变得更糟,因为额外的深度需要更多的同步 GPU 操作,如 AllReduce 和 Broadcast,除非我们多次冗余地存储适配器参数。
直接优化很难,另一个方向,如前缀调整(Li 和 Liang,2021)所示,面临着不同的挑战。我们观察到前缀调整难以优化,并且其性能在可训练参数中非单调变化,证实了原始论文中类似的观察。更根本地说,为适应保留序列长度的一部分必然会减少处理下游任务的可用序列长度,我们怀疑这使得在提示下调整表现不及其他方法。我们将对任务性能的研究推迟到第 5 节。
LoRA
低秩参数化更新矩阵
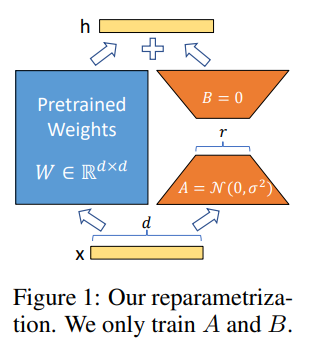
神经网络包含许多密集层执行矩阵乘法。这些层中的权重矩阵通常具有完整的秩。当适应特定任务时,Aghajanyan等人(2020)表明,预训练语言模型具有低“内在维度”,并且尽管随机投影到较小子空间,仍然可以有效地学习。受此启发,我们假设在适应过程中权重的更新也具有低“内在秩”。对于预训练的权重矩阵 W 0 ∈ R d × k ˉ \begin{aligned}W_0\in\mathbb{R}^{d\times\bar{k}}\end{aligned} W0∈Rd×kˉ,我们通过用低秩分解表示后者来约束其更新 W 0 + Δ W = W 0 + B A W_{0}+\Delta W=W_{0}+BA W0+ΔW=W0+BA,其中 B ˉ ∈ R d × r , A ∈ R r × k \bar{B}\in\mathbb{R}^{d\times r},A\in\mathbb{R}^{r\times k} Bˉ∈Rd×r,A∈Rr×k,并且秩 r ≪ min ( d , k ) r\ll\min(d,k) r≪min(d,k)
在训练期间, W 0 W_0 W0 被冻结并且不接收梯度更新,而A和B包含可训练参数。 W 0 W_0 W0和 ∆ W = B A ∆W = BA ∆W=BA 都与相同的输入相乘,并且它们各自的输出向量按坐标相加。对于 h = W 0 x h = W_0x h=W0x,我们修改后的前向传递产生: h = W 0 x + Δ W x = W 0 x + B A x h=W_0x+\Delta Wx=W_0x+BAx h=W0x+ΔWx=W0x+BAx 我们在图1中说明了我们的重新参数化。我们对A使用随机高斯初始化,并对B使用零,因此 ∆ W = B A ∆W = BA ∆W=BA 在训练开始时为零。然后将 ∆ W x ∆Wx ∆Wx 按 α / r α/r α/r 缩放,其中 α α α 是 r r r 中的常数。当使用Adam进行优化时,调整 α α α 大致相当于调整学习率(如果我们适当地缩放初始化)。因此,我们简单地将 α α α 设置为第一个尝试的r并且不调整它。这种缩放有助于减少在改变 r r r 时重新调整超参数的需要(Yang&Hu,2021)
全精调的一般化
更一般形式的精调允许训练预训练参数的子集。LoRA更进一步,并且不要求在适应过程中累积梯度更新到权重矩阵具有完整秩。这意味着当将LoRA应用于所有权重矩阵并训练所有偏差时,我们通过将LoRA秩r设置为预训练权重矩阵的秩来大致恢复全精调的表现力。换句话说,随着我们增加可训练参数的数量,训练LoRA大致收敛于训练原始模型,而基于适配器的方法收敛于MLP,基于前缀的方法收敛于无法接受长输入序列的模型。
没有额外推理延迟
部署到生产环境时,我们可以显式计算并存储
W
=
W
0
+
B
A
W = W_0 + BA
W=W0+BA并像往常一样进行推理。注意
W
0
W_0
W0 和
B
A
BA
BA 都在
R
d
×
k
R_d×k
Rd×k 中。 当我们需要切换到另一个下游任务时,我们可以通过减去
B
A
BA
BA 然后添加不同的
B
0
A
0
B_0A_0
B0A0来恢复
W
0
W_0
W0,这是一个快速操作,并且内存开销很小。关键是这保证了与精调模型相比,在推理过程中不会引入任何额外的延迟
应用到 TRANSFORMER
原则上,我们可以将LoRA应用于神经网络中任何子集的权重矩阵,以减少可训练参数的数量。在Transformer架构中,自注意模块中有四个权重矩阵 ( W q , W k , W v , W o ) (W_q,W_k,W_v,W_o) (Wq,Wk,Wv,Wo)和MLP模块中的两个。我们将 W q (或 W k , W v ) W_q(或W_k,W_v) Wq(或Wk,Wv)视为 d m o d e l × d m o d e l d_{model}×d_{model} dmodel×dmodel维度的单个矩阵,尽管输出维度通常被切成注意力头。我们仅限于将注意力权重适应下游任务,并冻结MLP模块(因此它们不会在下游任务中训练),既为了简单又为了参数效率。我们进一步研究了在TRANSFORMER中适应不同类型的注意力权重矩阵的影响
实际好处和局限性
最显著的好处来自减少内存和存储使用量。对于使用Adam训练的大型变压器,如果
r
≤
d
m
o
d
e
l
r≤d_{model}
r≤dmodel,则我们最多可以将
V
R
A
M
VRAM
VRAM 使用量减少2/3,因为我们不需要为冻结参数存储优化器状态。在GPT-3 175B上,我们将训练期间的VRAM消耗从1.2TB减少到350GB。当r = 4且仅查询和值投影矩阵被调整时,checkpoint大小大约减少了10,000倍(从350GB减少到35MB)这使我们能够使用更少的GPU进行训练并避免I/O瓶颈。另一个好处是我们可以通过仅交换LoRA权重而不是所有参数来更低成本地在部署时切换任务。这允许创建许多定制模型,可以在存储预训练权重的VRAM上的机器上即时切换
与全精调相比,在GPT-3 175B上训练速度提高了25%,因为我们不需要计算大多数参数的梯度
LoRA也有其局限性。例如,在单次前向传递中批量输入具有不同A和B的不同任务并不简单,如果选择将A和B吸收到W中以消除额外推理延迟。尽管可以不合并权重并动态选择要用于批处理中样本的LoRA模块,用于延迟不关键的场景
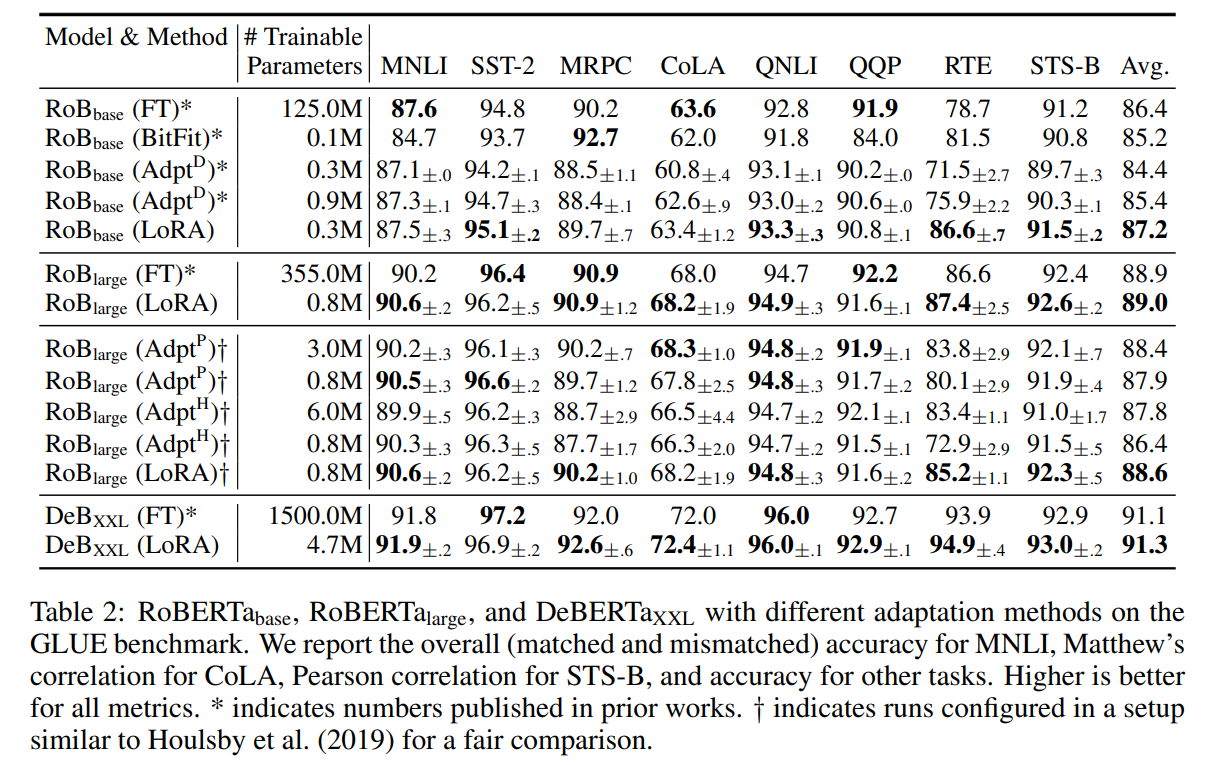
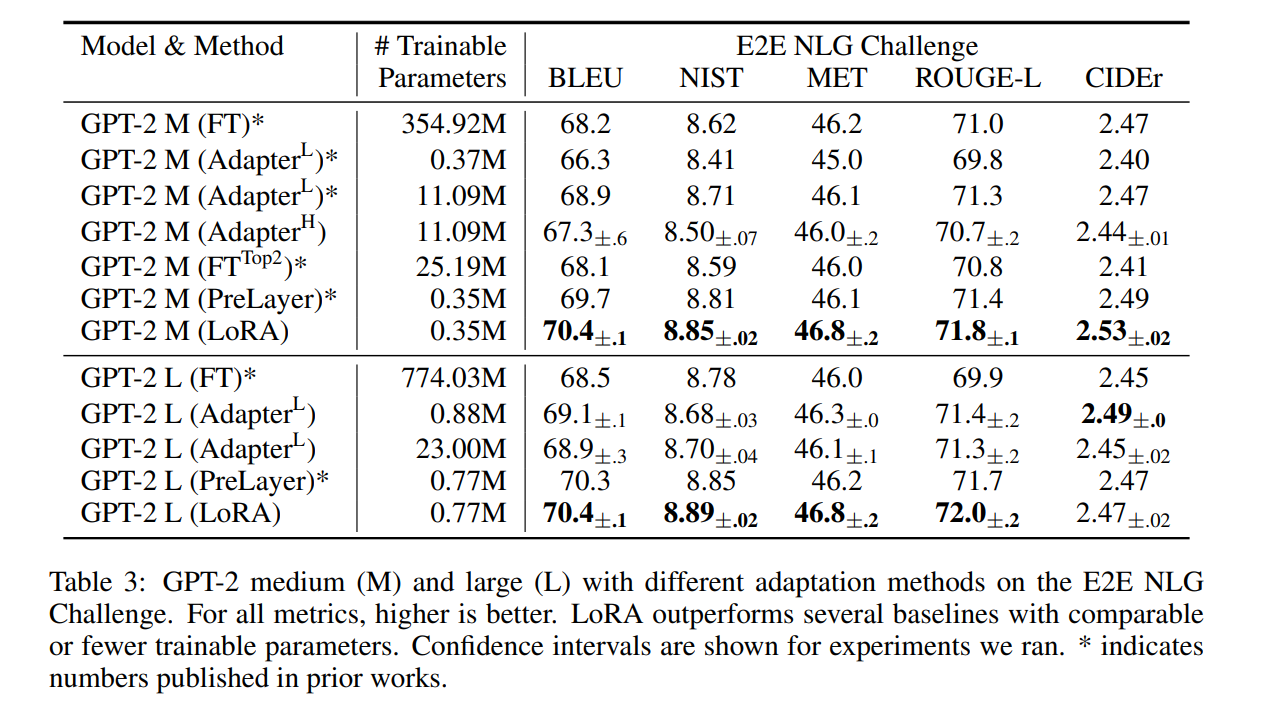
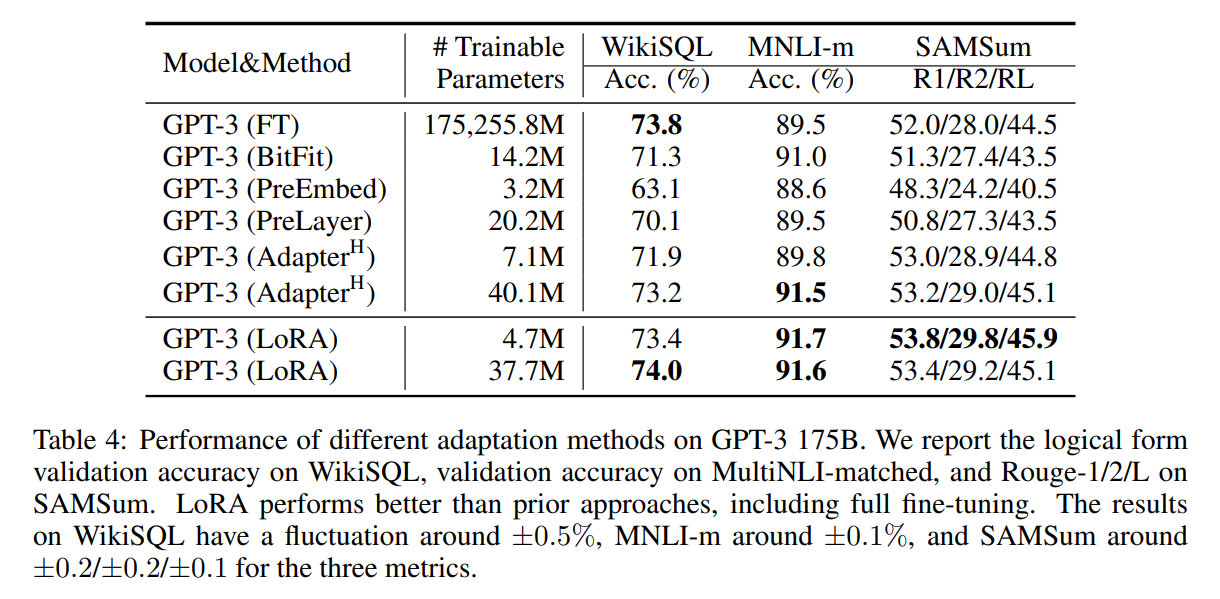
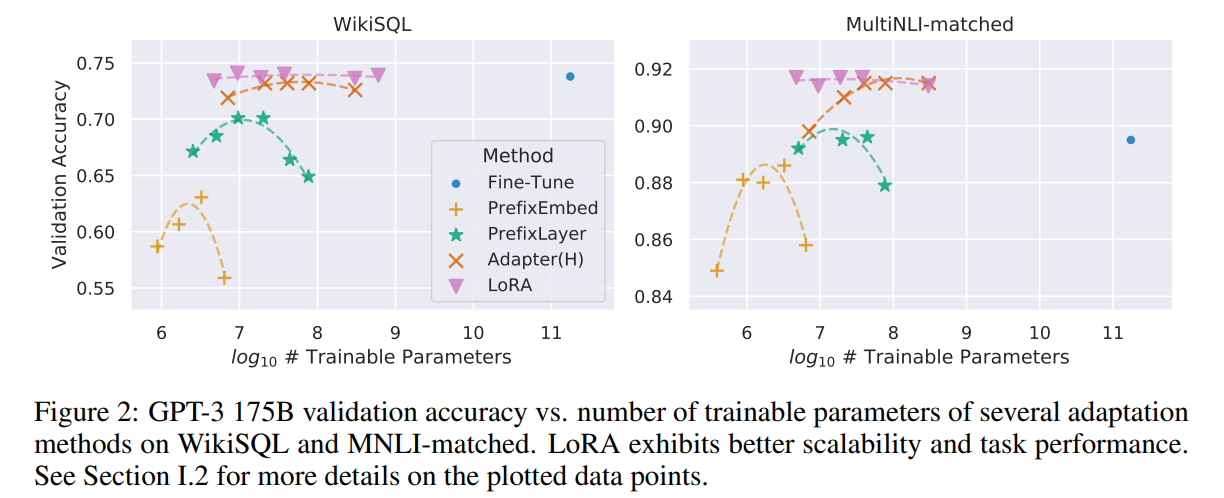
Experiments
翻译: 我们在RoBERTa(Liu等人,2019),DeBERTa(He等人,2021)和GPT-2(Radford等人,b)上评估LoRA的下游任务性能,然后扩展到GPT-3 175B(Brown et al.,2020)。我们的实验涵盖了从自然语言理解(NLU)到生成(NLG)的广泛任务范围。具体而言,我们对RoBERTa和DeBERTa进行GLUE(Wang等人,2019)基准测试。我们遵循Li&Liang(2021)在GPT-2上的设置进行直接比较,并添加WikiSQL(Zhong等人,2017)(NL到SQL查询)和SAMSum(Gliwa等人,2019)(会话摘要)用于GPT-3的大规模实验
Conclusions
在硬件要求和为不同任务托管独立实例的存储/切换成本方面,对巨大语言模型进行微调是极其昂贵的。我们提出了一种高效的适应策略LoRA,既不引入推理延迟,也不减少输入序列长度,同时保持高模型质量。重要的是,LoRA通过共享绝大部分模型参数,允许快速进行任务切换,从而可以作为服务部署。虽然我们的重点是Transformer语言模型,但所提出的原则通常适用于任何具有密集层的神经网络
未来的工作方向有很多:
- LoRA可以与其他高效适应方法结合,可能提供正交改进
- 微调或LoRA背后的机制尚不清楚 - 在预训练期间学习的特征如何转化为在下游任务中表现良好?我们认为相比于完全微调,LoRA使得回答这个问题更加可行
- 我们主要依赖启发式方法来选择应用LoRA的权重矩阵。是否有更加原则性的方法来做这件事?
- ΔW的秩缺失表明W可能也是秩缺失的,这可能会激发未来的研究工作
Remark
使用低秩分解,并且冻住大头而只训练部分参数获得了非常高效的方法,LoRA已经成为现在垂直领域微调唯一选择(全量fine-tune需要太多资源,包括GPU和数据),大道至简,dope!





![[JAVAee]volatile关键字](https://img-blog.csdnimg.cn/469a39b738a846bb8007c90500fd9689.png)