全文共8000余字,预计阅读时间约18~28分钟 | 满满干货(附代码案例),建议收藏!
本文目标:详解Chat Completion Models的参数及应用实例,并基于该API实现一个本地知识库的多轮对话智能助理
代码&文件下载点这里
一、介绍
在OpenAI大模型生态中的文本模型包括了Completion模型和Chat模型,之前的文章已经详细介绍了OpenAI的完整大模型生态和Completion模型,如还不了解的可以看这两篇文章:
大模型实战(三):OpenAI大模型生态
大模型开发(六):OpenAI Completions模型详解并实现多轮对话机器人
本文介绍Chat类模型及其API使用方法,在OpenAI官网中可以看到模型列表如下:
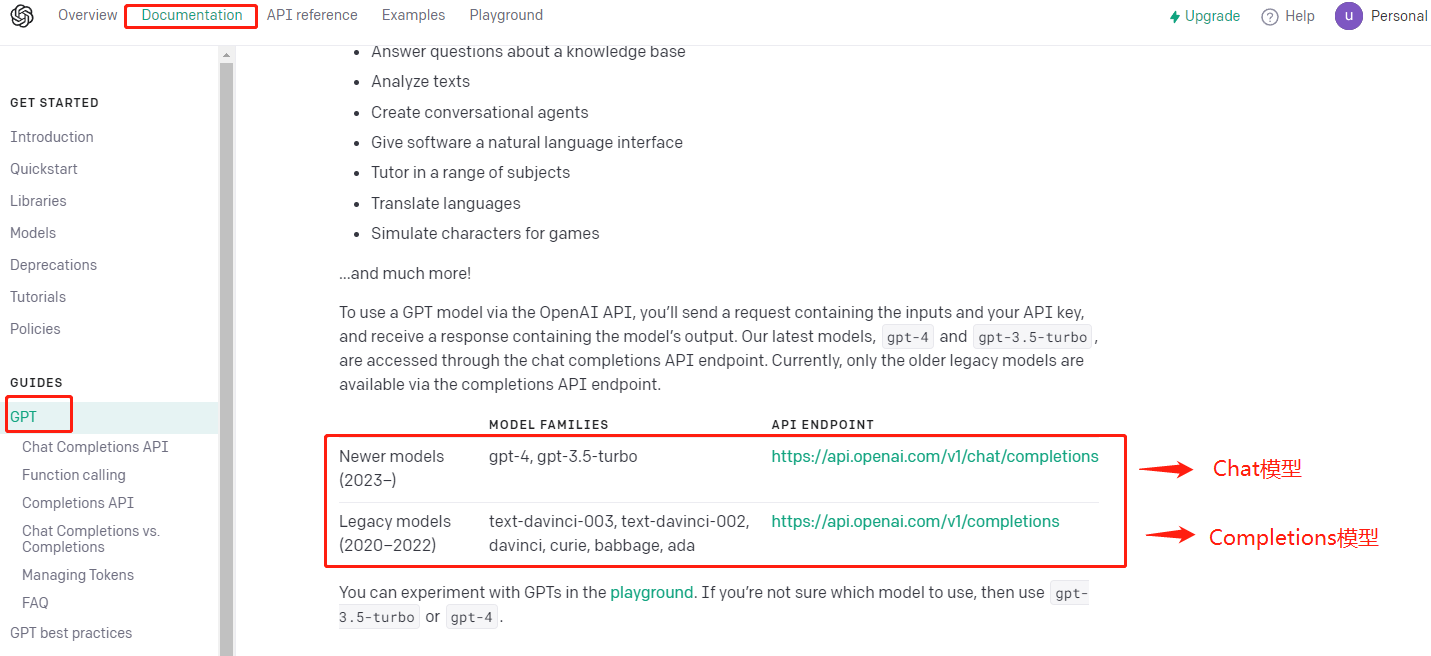
从模型的发展顺序上来看,Chat模型是Completion模型的升级版。

二、Chat Completion Models与Completions Models的关系
Completion模型核心功能是根据提示(prompt)进⾏提示语句的补全(即继续进行后续⽂本创作),它本质上是文本补全模型。
而Chat模型升级的核心功能是对话能力, 它基于大量高质量对话文本进行微调,能够更好的理解用户对话意图,所以它能更顺利的完成与用户的对话。
大语言模型本质上都是概率模型,根据前文提示进⾏补全是⼤语⾔模型的原始功能,而对话类的功能则是加⼊额外数据集之后训练的结果
当Completions Models和Chat Completions 接收不完整信息时,推理差异也是比较明显的,运行如下代码:
chat_completions_res = openai.ChatCompletion.create(
model = "gpt-3.5-turbo-16k-0613",
messages = [
{"role": "user", "content":"你好呀,请问我"}
]
)
chat_completions_res.choices[0].message["content"]
completions_res = openai.Completion.create(
model = "text-davinci-003",
prompt = "你好呀,请问我",
max_tokens = 1000
)
completions_res["choices"][0]["text"].strip()
看下推理结果:
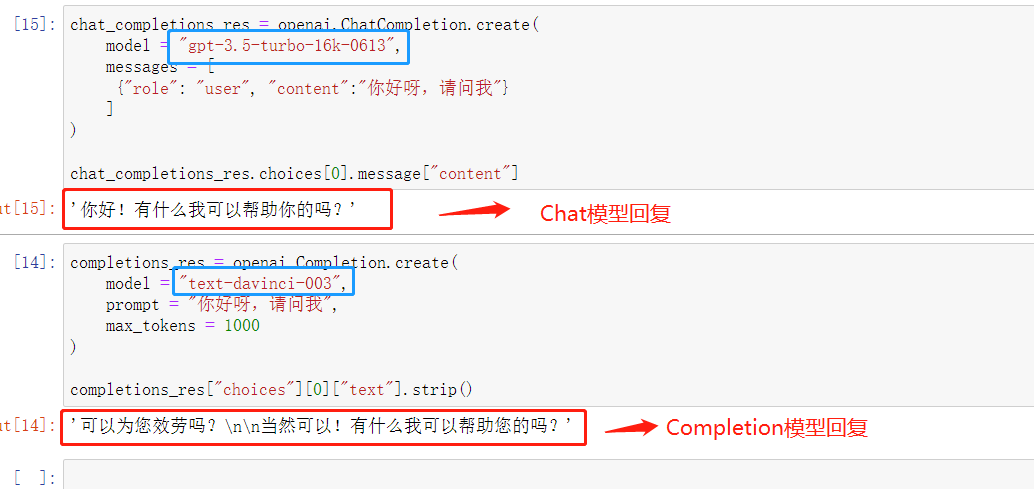
其实可以能看出来,Chat模型能够比较好的理解对话意图,而Completions模型则是根据概率进行对话补全。
Chat模型的核心优势也就体现出来了: 理解⼈类意图的能力,与大语⾔模型(LLMs)交互最低⻔槛的形式就是对话,如果模型能够非常好的理解人类对话意图,才会更有利于模型的发展和社会价值的认同,这就是为什么gpt-3.5和davinci模型同属于⼀代模型,但基于gpt-3.5的 ChatGPT⼀炮而红,而早两年推出的davinci模型却远不及gpt-3.5影响力大。
据OpenAI官网数据,自gpt-3.5 API发布以来,约97%的开发者更偏向于使用Chat模型API进行开发
三、Chat Completion Models发展历程
Chat Completion Models 发展是非常迅速的,截止到目前2023年7月22日,OpenAI的官方数据如下:
- 2023年3月1日,gpt-3.5-turbo API正式发布
- 2023年3月14日,gpt-4 API正式发布,但是需要申请使用
在这两个里程碑后,也在不断的更新迭代,可用性不断的提升,经费也在不断的下降,如下图:

- 2023年6月13日:OpenAI宣布在Chat Completion模型中加入函数调用(Function calling)功能,全面开放16K对话长度的模型、降低模型调用资费等
这代表着Chat模型不再需要借助LangChain框架就可以直接在模型内部调用外部工具API,可以更加便捷的构建以LLM为核心的AI应用程序。
- 2023年7月6日:真正的王炸更新,申明将全面开放gpt-4 API,同时重点强调了原先的编程模型(code)模型的功能将合并入chat模型,同时,未来将更新Chat模型的fine - tunes API。
四、 Chat Completions Model API基本情况
截至目前,OpenAI发布的Chat Completions模型主要包括gpt-3.5和gpt-4两类模型,这两个模型也是目前ChatGPT应用程序背后的对话大模型。
根据官网给出的说明,gpt-3.5模型是基于text-davinci-003微调的模型,由code-davinci-002这一基座模型经过几轮微调后训练得到,对应的模型微调关系如下所示:

gpt-4则是完全重新训练的最新一代的对话类大模型,在诸多国内外大模型评测榜单上,gpt-4也是目前(多语种)对话效果最好的一类对话类大模型。
OpenAI发布的Chat Completions模型如下:

但目前为止,Chat Completions模型并未开放全部的API,大多数模型的长文本对话模型(即标注为32k的模型),也需要填写申请方可使用,填写地址:申请地址 。
4.1 调用示例
与调用Completion模型需要使用Completion.create函数类似,若要调用Chat类大模型,则需要使用ChatCompletion.create函数。调用代码如下:
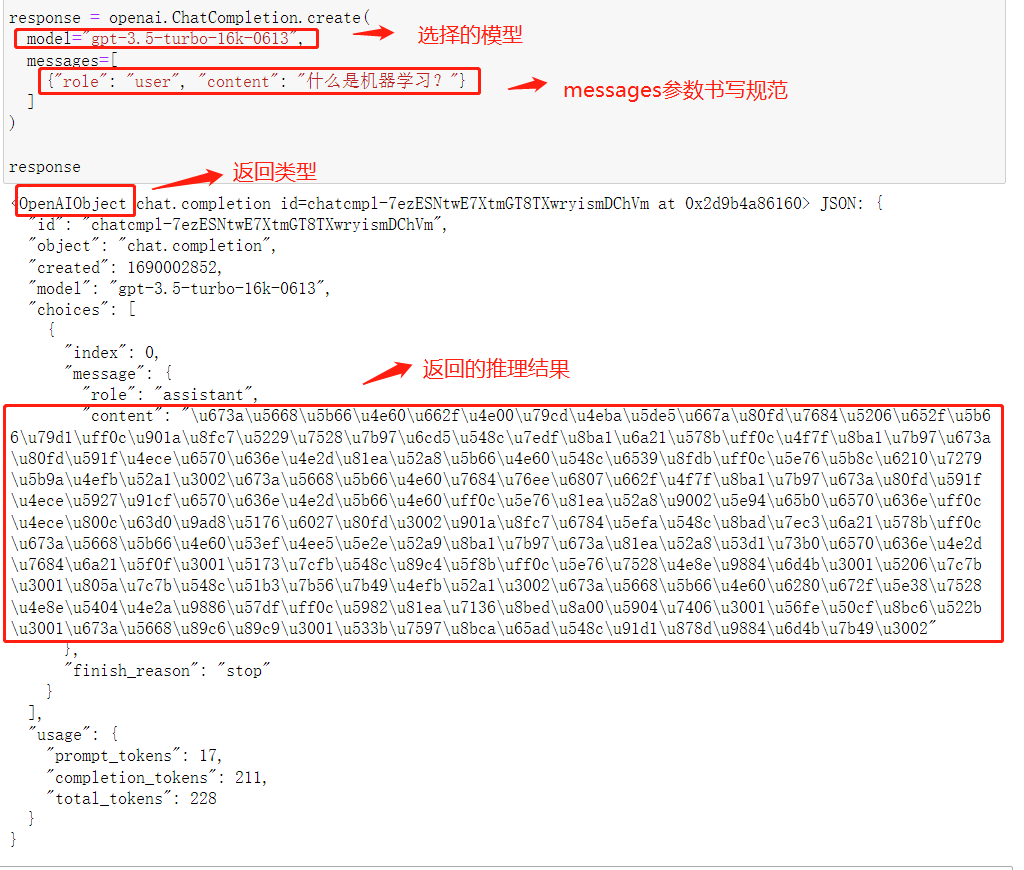
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "什么是机器学习?"}
]
)
reponse
和Completion.create非常明显的一个区别在于,ChatCompletion.create函数的调用不再需要prompt参数,而是换成了messages参数,并且,不同于prompt参数对象是以简单的字符串形式呈现,messages参数则是一个基本构成元素为字典的列表,其内每个字典都代表一条独立的消息,每个字典都包含两个键值(Key-value)对,其中第一个Key都是字符串role(角色)表示某条消息的作者,第二个key为content(内容)表示消息具体内容。
看下推理结果:
messages参数是ChatCompletion.create函数最重要的参数之一,它可以简单理解为输入给模型的信息,模型接收到message之后也会输出对应的回答信息,代码如下:
# 查看第一个返回结果的message
response.choices[0].message['content']
看下推理结果:

对话模型需要输入“message”,返回也是“message”,可以说这种文本交互形式确实非常符合人类在进行聊天时的问答习惯。
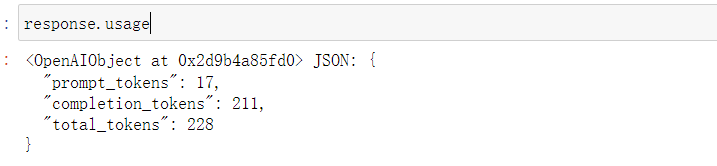
和Completion模型一样,Chat模型同样也可以在返回结果的usage中查看本次对话所占用的token数量,其中"prompt_tokens"表示提示词占用token数量,"completion_tokens"则表示返回结果所占用token数量,而"total_tokens"则是二者相加,代表本次对话总共占用token数量。
4.2 参数详解
ChatCompletion.create函数的详细参数解释,官网介绍 。和Completion.create函数相比,ChatCompletion.create函数的参数结构发生了以下变化:
- 用messages参数代替了prompt参数,使之更适合能够执行对话类任务
- 新增functions和function_call参数,使之能够在函数内部调用其他工具的API
- 其他核心参数完全一致,例如temperature、top_p、max_tokens、n、presence_penalty等参数的解释和使用方法都完全一致,且这些参数具体的调整策略也完全一致.
- 剔除了best_of参数,即Chat模型不再支持从多个答案中选择一个最好的答案这一功能
各参数具体情况如下图:

五、messages参数详解
5.1 参数结构
messages是一种用于描述ChatCompletion模型和用户之间通信信息的高级抽象,从表示形式上来说,一个messages是一个列表,包含多个字典,每个字典都是一条消息,其中,一条消息由包含两个键值对(即每个字典都包含两个键值对),第一个键值对用于表示消息发送者,其中第一个Key为字符串’role’,Value为参与对话的角色名称,或者可以理解为本条消息的作者或消息发送人名称,第二个键值对表示具体消息内容,Key为字符串’content’,Value为具体的消息内容,用字符串表示。
例如下面的代码指代:messages包含一条信息,一个名为user的角色发送了一条名为’请问什么是机器学习?'的消息:
返回的message结果也是一个“字典”,也包含了信息的发送方和具体信息内容
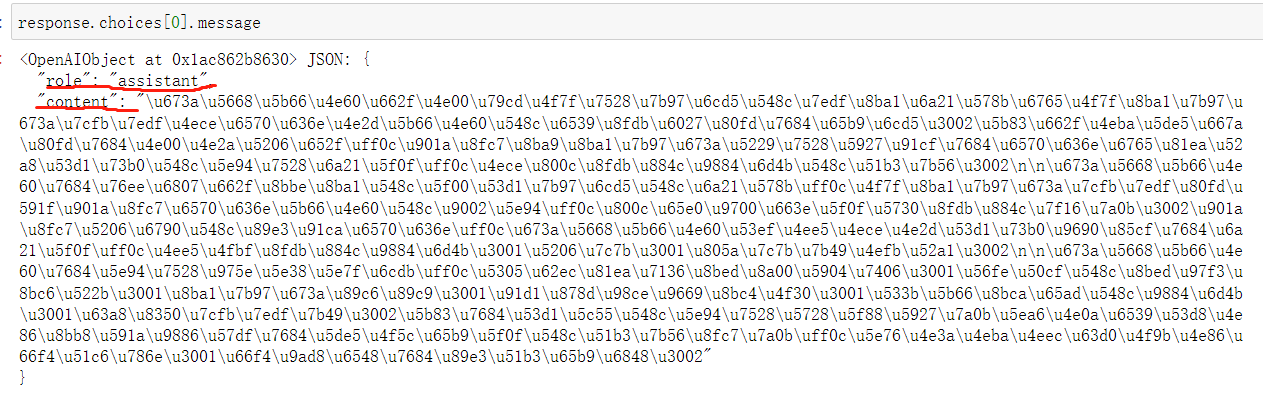
即发送方是一个名为’assistant’的角色,具体内容则是一段关于什么是机器学习的描述。
 Chat模型的每个对话任务都是通过输入和输出message来完成的。
Chat模型的每个对话任务都是通过输入和输出message来完成的。
5.2 message中的角色划分
5.2.1 user role和assistant role
一个最简单的对话就是扮演user(用户)这个角色(‘role’:‘user’),然后在content中输入问题并等待模型回答。而模型在实际回答过程中,会扮演一个名为assistant(助手)这个角色(‘role’:‘assistant’)进行回答,这里的user和assistant是具有明确含义的字符串,即如果一条信息的role是user,则表明这是用户向模型发送的聊天信息,相当于是Completion模型中的prompt,而如果一条信息的role是assistant,则表示这是当前模型围绕某条用户信息做出的回应,相当于是相当于是Completion模型中的text。
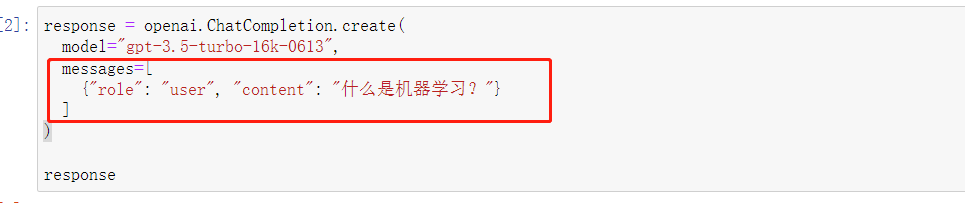
基于这样的一个定义的规则,最简单的Chat模型的调用方法就是在messages参数中设置一条role为user的参数,在content中输入聊天的内容,而模型则会根据这条用户输入给模型的消息进行回答,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "什么是机器学习?"}
]

同时,Messages可以包含多条信息,但模型只会对于最后一条用户信息进行回答,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "什么是机器学习?"},
{"role": "user", "content": "什么是深度学习?"}
]
)

assistant消息和role消息是一一对应的,在一般情况下,assistant消息只会围绕messages参数中的最后一个role信息进行回答。
5.2.2 system role
user和assistant的这种提问方式尽管足够清晰,但往往形式上不够丰富,在实践中人们发现,给聊天机器人进行一个身份设置,是非常有效的引导模型创作出想要的结果的方法,例如如果希望获得一个关于“什么是机器学习?”更加严谨且丰富的答案,可以以“假设你是一名机器学习领域的资深专家,具备20年以上的研究经历”为模型进行身份设置,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "假设你是一名机器学习领域的资深专家,具备20年以上的研究经历,请帮我回答,什么是机器学习?"}
]
)
response.choices[0].message['content']
看下模型给出的推理:

如果使用system role 身份设定,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "你是一名机器学习领域的资深专家,具备20年以上的研究经历"},
{"role": "user", "content": "请问什么是机器学习?"}
]
)
response.choices[0].message['content']
看下推理结果:

在原有消息之前,新增一条消息{“role”: “system”, “content”: “你是一名机器学习领域的资深专家,具备20年以上的研究经历”},能起到设定模型身份的作用。所以这条消息的实际含义是,以system的身份发送一条消息,消息内容为“你是一名机器学习领域的资深专家,具备20年以上的研究经历”。system就是messages参数的role可以选取的第三个字符串,意为该消息为一条系统消息。
相比用户消息,系统消息有以下几点需要注意,其一是系统消息的实际作用是给整个对话系统进行背景设置,不同的背景设置会极大程度影响后续对话过程中模型的输出结果,例如如果系统设置为“你是一位资深医学专家”,那么接下来系统在进行回答医学领域相关问题时则会引用大量医学术语,而如果系统设置为“你是一位资深喜剧演员”,那么接下来系统进行的回答则会更加风趣幽默:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "你是一名资深的喜剧演员"},
{"role": "user", "content": "请问什么是机器学习?"}
]
)
response.choices[0].message['content']
看下推理结果:

很明显能看出来风格的转变是非常大的。
另外,当messages中只包含一条system消息时,系统会围绕system进行回答,此时系统的assistant的应答消息则更像是一个completion的过程,即围绕system的prompt进行进一步的文本补全:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "你是一名机器学习领域的资深专家,具备20年以上的研究经历"},
]
)
看下推理结果:

需要根据system系统信息对系统进行设置,然后再提问,那么先system消息再user消息的顺序是非常重要的,例如还是上面的例子,还是希望以喜剧演员的身份介绍机器学习,但如果调换了system消息和user消息的顺序,system消息的作用就会失效,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "请问什么是机器学习?"},
{"role": "system", "content": "你是一名资深的喜剧演员"}
]
)
看下推理结果:

模型能解答“请问什么是机器学习?”这个问题,但却没有正确接受“你是一名资深喜剧演员”这个设定。
根据OpenAI官网说明,截至目前,gpt-3.5系列模型仍然无法对system提供的系统消息保持长期关注,即在多轮对话中,模型极有可能逐渐忘记自己的身份设定。根据长期使用情况来看,gpt-4模型对system设置的长期关注要好于gpt-3.5系列模型。
对于messages中可选的role来说,除了ueser、assistant、system之外,还有一个function role,用于表示某条消息为某函数的调用指令,function role是OpenAI 0613更新中提供的新的role选项,用于Chat模型调用外部定义函数或者工具API时使用。
六、message参数应用实例
对ChatCompletion.create函数来说,通过灵活的messages参数,能够非常便捷高效的实现诸多类型的对话需求,例如基于提示词模板的提问、Few-shot提问、基于某背景知识的提问等。
在大模型开发(八):基于思维链(CoT)的进阶提示工程文章中提出了四个经典的推理题,本文就以这四个问题作为示例,看一下如何用用在Chat模型下如何进行推理。
先提前定义好四组问题的问题和答案:
Q1 = '罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?'
A1 = '现在罗杰总共有11个网球。'
Q2 = '食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?'
A2 = '现在食堂总共有9个苹果。'
Q3 = '杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?'
A3 = '现在总共有4个蓝色高尔夫球。'
Q4 = '艾米需要4分钟才能爬到滑梯顶部,她花了1分钟才滑下来,水滑梯将在15分钟后关闭,请问在关闭之前她能滑多少次?'
A4 = '关闭之前艾米能滑3次。'
gpt-3.5是基于对话语料进行的微调,它具有比text-davinci-003更强大的推理能力,四个推理问题对于gpt-3.5来说,除了最后一个问题不一定能得出正确答案外,其他问题均能在不进行额外提示的情况下进行很好的回答。
经过测试,gpt-4模型能够非常好的回答第四个推理问题。但这并不代表此前的CoT和LtM技术就不再重要,面对超出模型原生能力的更加复杂的推理问题(如SCAN数据集的命令解释问题),仍然还是需要使用这些提示工程技术。
6.1 借助多轮user-assistant消息进行few-shot
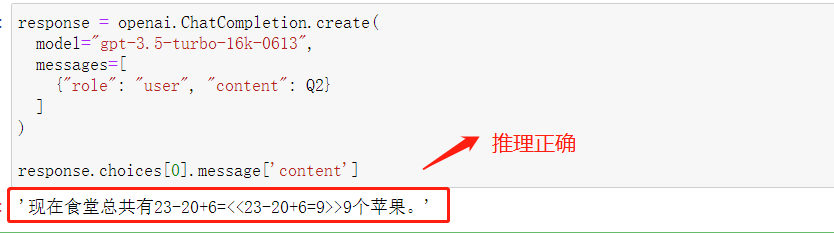
先看下使用Zero-shot提示对第二个推理题Q2 进行提问,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": Q2}
]
)
response.choices[0].message['content']
看下推理结果:
如果想在Chat模型中进行Few-shot,最好的办法就是在messages中设置多轮user-assistant消息,所以做法就是:尝试以第一个问题的问题和答案作为提示示例,引导模型解答第二个问题,则可以按照如下方式设置messages,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": Q1},
{"role": "assistant", "content": A1},
{"role": "user", "content": Q2}
]
)
response.choices[0].message['content']
看下推理结果:
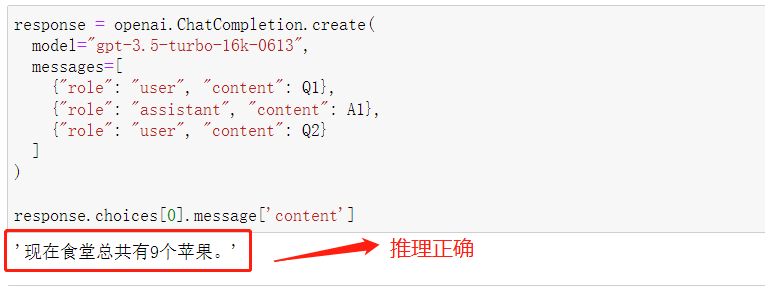
相比单独进行Q2的提问,经过Few-shot的提示回答的结果,会更加接近A1结果(‘现在罗杰总共有11个网球。’)的表示格式。
assistant消息是可以自定义的,用于给模型提供回答的范本,不仅可以按照system-user的形式规定回答风格,而且还可以按照user-assistant-user-assistant…形式来进行Few-shot。
6.2 借助system role进行Few-shot
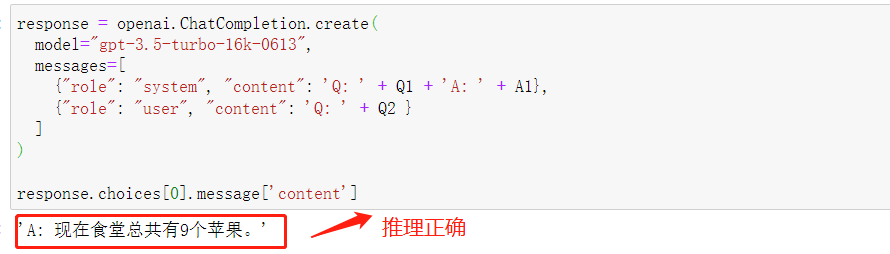
可以把提示示例写进一条system信息中,作为当前问答的背景信息,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": 'Q: ' + Q1 + 'A: ' + A1},
{"role": "user", "content": 'Q: ' + Q2 }
]
)
response.choices[0].message['content']
看下推理结果:
6.3 借助system role输入提示模板
即然system消息能够作为背景设定的基本消息并对后续的问答消息造成影响,那么很容易想到的system消息的一个应用场景就是借助system role输入提示模板,例如在Completions模型中为了更好的提高模型推理能力,可以在每个prompt中加入一句“请一步步推理并得出结论”进而实现Zero-shot-CoT。而在Chat模型中,这种prompt模板信息是非常适合通过system role进行输入的,例如围绕第四个推理问题,可以通过输入一条内容为“请一步步推理并得出结论”的系统信息,来引导模型完成Zero-shot-CoT,代码如下:
prompt_temp_cot = '请一步步思考并解决问题'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": prompt_temp_cot},
{"role": "user", "content": Q1}
]
)
response.choices[0].message['content']
看下推理结果:

再测试一下LtM提示法,代码如下:
prompt_temp_ltm = '为了解决当前这个问题,请列举我们先要解决的问题,并逐步解决原问题。'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": prompt_temp_ltm},
{"role": "user", "content": Q1}
]
)
response.choices[0].message['content']
看下推理结果:
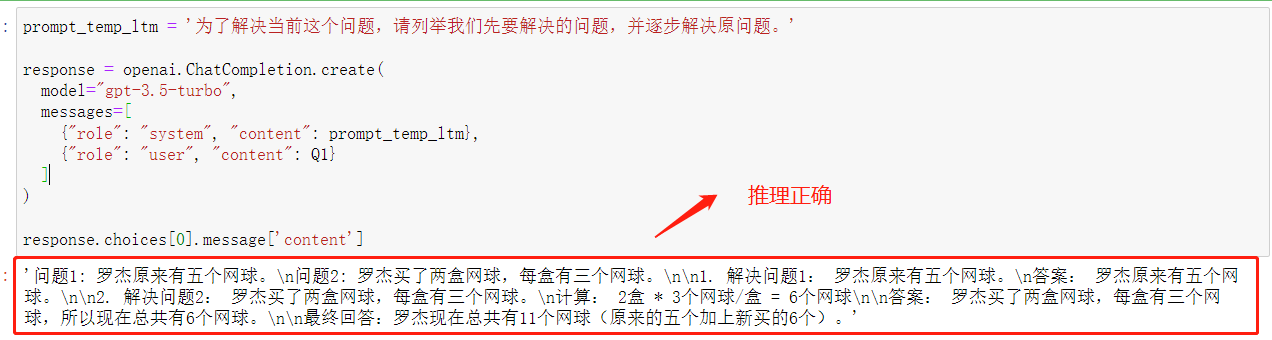
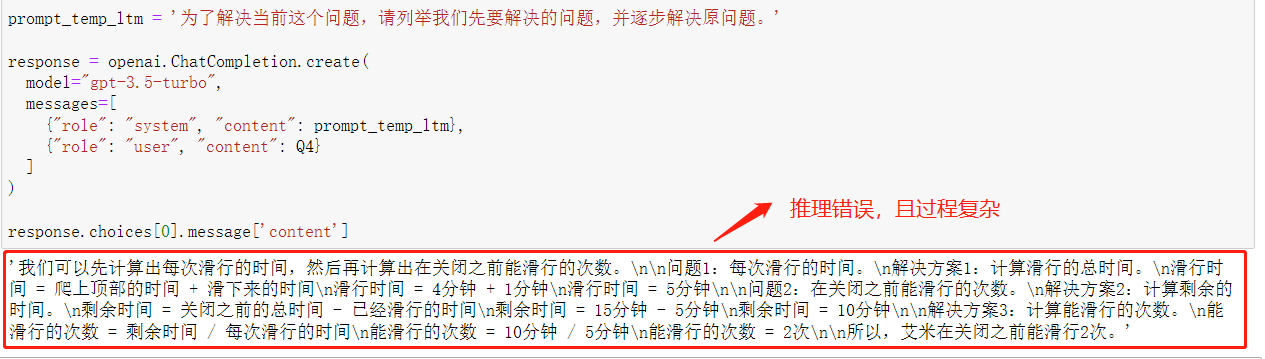
其实在多次尝试中也发现了,gpt-3.5的推导过程复杂且不稳定,使用LtM提示法回答Q4这个最难的推理题时,10次能回答正确3次,直接提问更是一次都回答不对,
prompt_temp_ltm = '为了解决当前这个问题,请列举我们先要解决的问题,并逐步解决原问题。'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": prompt_temp_ltm},
{"role": "user", "content": Q4}
]
)
response.choices[0].message['content']
推理结果如下:
**gpt-4模型在相同提示策略下,会表现出更强大的推理性能。**同样是围绕第四个问题,对gpt-4模型进行CoT和LtM提示结果如下:
response = openai.ChatCompletion.create(
model="gpt-4-0613",
messages=[
{"role": "system", "content": prompt_temp_cot},
{"role": "user", "content": Q4}
]
)
response.choices[0].message['content']
第一次推理结果:

第二次推理结果:
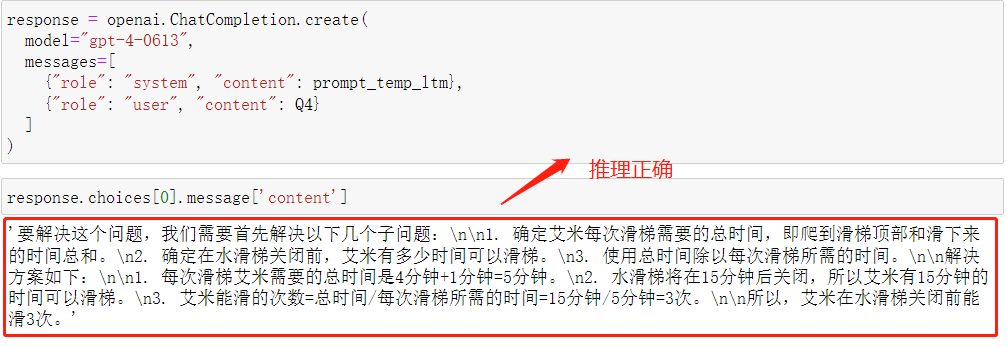
除了推理能力外,gpt-4各方面性能都属于目前大模型领域的顶流。
6.4 借助system role设置聊天背景信息
一个非常常见的system role的使用方法,就是借助system消息进行聊天背景信息的设定,很多时候可以在system消息中输入一段长文本,这段长文本将在聊天开始之前输入到系统中,而在之后的聊天中,即可让assistant围绕这个长文本进行回答,这是一种最简单的实现大语言模型围绕本地知识库进行问答的方法。
在system消息中输入一段关于虚拟人物“算法小陈”的个人简介,而在之后的提问中,user和assistant将可以自由的围绕这段输入的背景信息进行问答:
text = '陈某,男,1995年1月23日出生于内蒙古赤峰市。\
2017年毕业于北京某大学计算机系,同时获得计算机博士学位。\
毕业后在硅谷的一家著名科技公司工作了五年,专注于人工智能和机器学习的研发。'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": text},
{"role": "user", "content": '请问陈某是哪一年出生的?'}
]
)
response.choices[0].message['content']
看下回答结果:
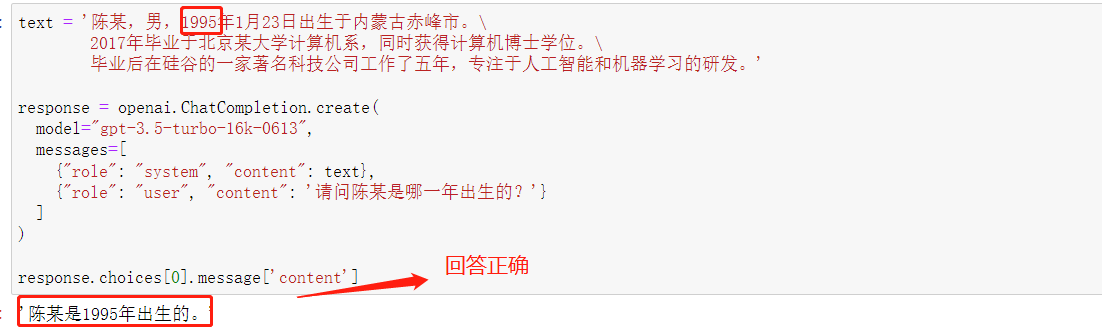
背景背景信息能够被模型学习并以此进行特定问题的回答。这就是一种非常简单的围绕本地知识进行问答的实现形式。
不过需要注意的是,system role输入的信息也算是输入给模型的信息,因此受限于大语言模型的最大输入信息长度,单独借助system role在ChatCompletion.create函数中输入背景信息并不能真正意义上实现高度定制化、超大规模文本的本地知识库问答。但是,如果围绕着超大规模本地文本知识库先进行基于滑动窗口的文本切分,以确保切分后的小文本段落满足Max tokens要求,并且配合Embedding过程进行user问题和短文本的实时匹配,再把每个user问题匹配的关联度最高的文本以system消息的形式输入到模型中,再进行回答,则可以非常高效并且准确的实现本地知识库问答。而在这个过程中,借助system role进行背景文字的输入就非常基本的技术手段。
6.5 借助.append方法进行多轮对话
除了通过内部参数修改来实现不同功能外,messages参数的另一个重要应用是借助append方法来高效实现多轮对话。
不同于Completion模型需要将历史问答都拼接为一个字符串并输入到新的prompt中来实现历史消息的输入,对于Chat模型来说,只需要将模型返回的message消息+用户新的提问message拼接到模型的messages参数中,并再次向模型进行提问,即可非常便捷的实现多轮对话。
单独设置messages参数,并将此前的问题+答案进行拼接,代码如下:
text = '陈某,男,1995年1月23日出生于内蒙古赤峰市。\
2017年毕业于北京某大学计算机系,同时获得计算机博士学位。\
毕业后在硅谷的一家著名科技公司工作了五年,专注于人工智能和机器学习的研发。'
messages=[
{"role": "system", "content": text},
{"role": "user", "content": '请问陈某是哪一年出生?'}
]
messages.append(response.choices[0].message.to_dict())
messages
此时的messages是这样的:

此时messages参数包含了最开始的问题+问题答案。接下来在messages消息中添加下一个问题:
messages.append({'role': 'user', 'content': '请问我刚才的问题是?'})
messages
此时的messages是这样的:

接下来再次调用模型,并输入messages作为参数,此时模型将同时结合此前的所有消息,并围绕最后一个user信息进行回答:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=messages
)
response.choices[0].message['content']
此时推理结果:
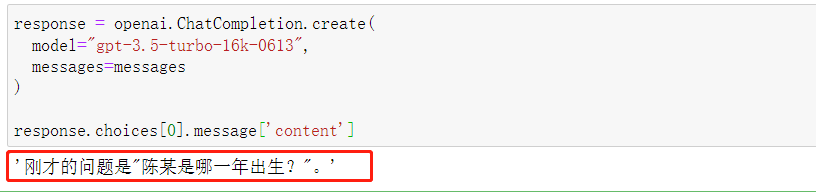
能够发现,相比Completions模型,Chat类模型能够更加便捷的实现多轮对话。
七、实操:训练一个本地知识库的智能助理
最后,尝试实现一个手动实操项目,即训练一个简易的大模型开发内容智能助理,要求让这个智能助理能够理解Chat Completions模型的相关内容,同时也能够围绕该问题进行多轮对话,以辅助进行学习。
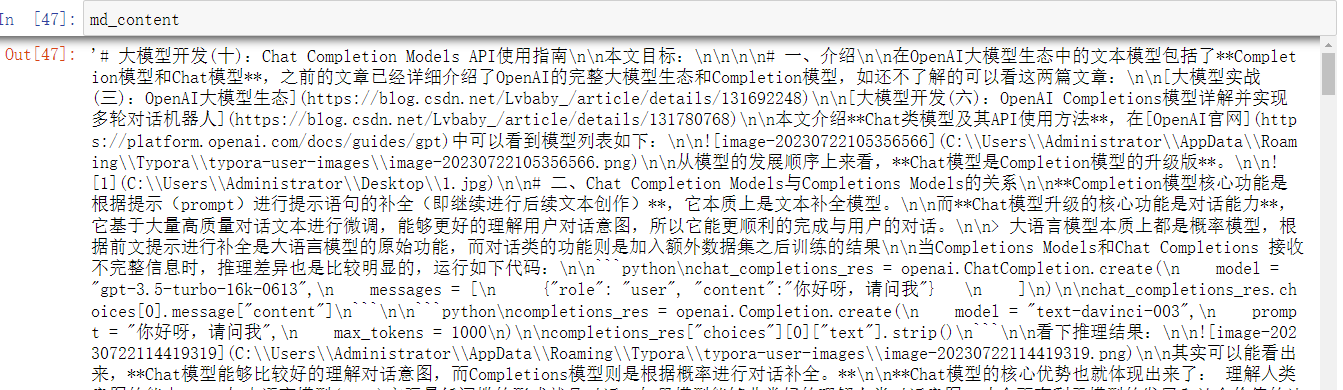
gpt系列模型的知识库截止于2021年9月,因此模型本身是不知道ChatCompletion.create函数的,因此只通过模型原始的知识库是无法完成多轮对话函数编写的,因此需要先把Chat Completions模型的相关内容输入给模型,然后再引导模型完成多轮对话。
Step 1:打开并读取Markdown文件
# 打开并读取Markdown文件
with open('大模型开发(十):Chat Completion Models API使用指南.md', 'r', encoding='utf-8') as f:
md_content = f.read()
Step 2:作为system message输入给模型
读取之后尝试将其作为system message输入给模型,然后要求模型根据本节内容编写一个能够实现多轮对话的函数,可以先通过如下message测试模型是否已经学习到ChatCompletion.create相关信息:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": md_content},
{"role": "user", "content": '请帮我介绍下openai.ChatCompletion.create这个函数'}
]
)
response.choices[0].message['content']
看下推理结果:

此时模型已经能够了解openai.ChatCompletion.create函数使用方法与基本规则。
Step 3:创建多轮对话函数
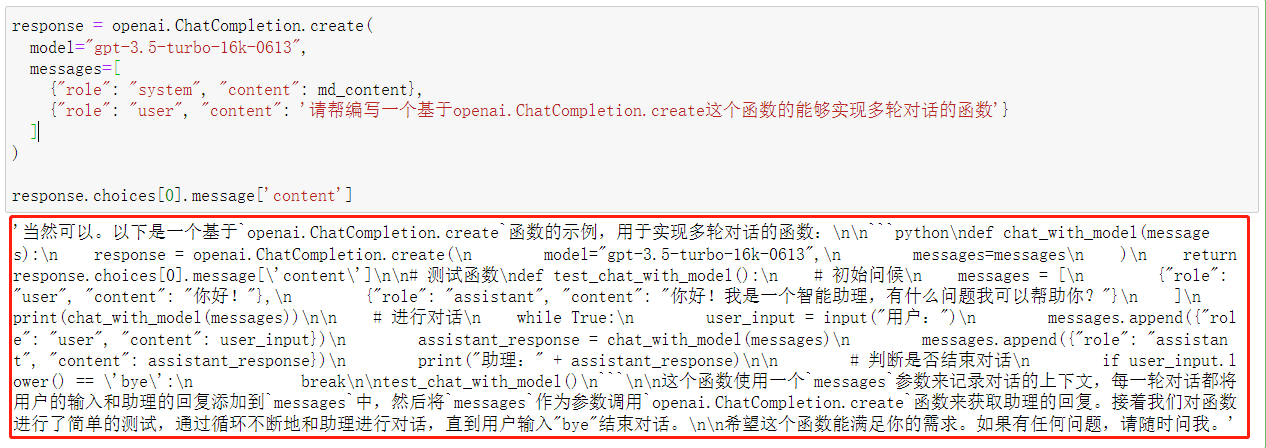
接下来尝试令其编写一个多轮对话函数,代码如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": md_content},
{"role": "user", "content": '请帮编写一个基于openai.ChatCompletion.create这个函数的能够实现多轮对话的函数'}
]
)
response.choices[0].message['content']
看下推理结果:
Step 4:将编写结果转化为markdown格式,并写入本地
with open('chatCompletionsModelTest.md', 'a', encoding='utf-8') as f:
f.write(response.choices[0].message['content'])
保存后打开看一下:
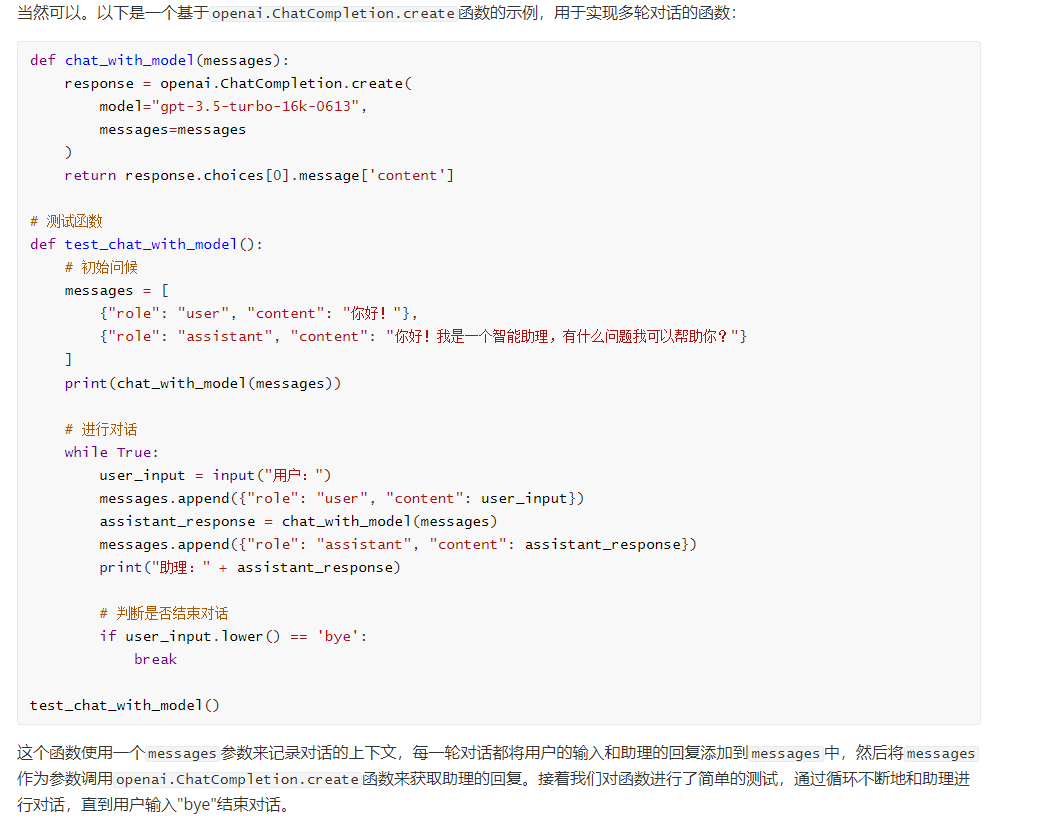
Step 5:运行函数
def chat_with_model(messages):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=messages
)
return response.choices[0].message['content']
# 测试函数
def test_chat_with_model():
# 初始问候
messages = [
{"role": "user", "content": "你好!"},
{"role": "assistant", "content": "你好!我是一个智能助理,有什么问题我可以帮助你?"}
]
print(chat_with_model(messages))
# 进行对话
while True:
user_input = input("用户:")
messages.append({"role": "user", "content": user_input})
assistant_response = chat_with_model(messages)
messages.append({"role": "assistant", "content": assistant_response})
print("助理:" + assistant_response)
# 判断是否结束对话
if user_input.lower() == 'bye':
break
test_chat_with_model()
看下运行情况:

至此,就成功完成了将本地的Chat Completions Models的相关知识输入到模型中,然后借助模型完成Chat模型多轮对话的编写需求。
Step 6:优化
以更进一步将Chat Completions Models的相关知识作为system message进行输入,即可完成围绕课程问题的问答机器人,优化代码如下:
def chat_with_model(prompt, model="gpt-3.5-turbo-16k-0613"):
messages = [
{"role": "system", "content": md_content},
{"role": "user", "content": prompt}
]
while True:
response = openai.ChatCompletion.create(
model=model,
messages=messages
)
# 获取模型回答
answer = response.choices[0].message['content']
print(f"模型回答: {answer}")
# 询问用户是否还有其他问题
user_input = input("您还有其他问题吗?(输入退出以结束对话): ")
if user_input == "退出":
break
# 记录用户回答
messages.append({"role": "user", "content": user_input})
运行一下:

可以看出来,回答的问题都是本文上述说到内容和知识,其实这样就可以认为是它完成了本地知识库的问题。
八、总结
文章从介绍Chat Completion Models开始,阐述了其与Completions Models的关系及其发展历程。深入解读了Chat Completions Model API,包括调用示例及参数详解。在此基础上,专门对messages参数进行了详解,包括参数结构,以及message中的角色划分。并且,提供了丰富的message参数应用实例,如借助多轮user-assistant消息进行few-shot,使用system role进行Few-shot,输入提示模板,设置聊天背景信息,以及使用.append方法进行多轮对话。文章的最后部分提供了实际操作示例,训练一个本地知识库的智能助理,为实际应用Chat Completion Models提供了参考。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!



![[JAVAee]volatile关键字](https://img-blog.csdnimg.cn/469a39b738a846bb8007c90500fd9689.png)