基本概念
什么是过拟合?
过拟合(Overfitting)是机器学习和深度学习中常见的问题之一,它指的是模型在训练数据上表现得很好,但在未见过的新数据上表现较差的现象。
当一个模型过度地学习了训练数据的细节和噪声,而忽略了数据中的一般规律和模式时,就会发生过拟合。过拟合是由于模型过于复杂或者训练数据过少,导致模型记住了训练数据中的每个细节,从而无法泛化到新数据。
解决方法
1.增加训练数据量:通过增加更多的训练数据,使得模型能够更好地学习数据的一般规律,而不是过多地依赖于少量的数据样本。
2.简化模型:减少模型的复杂度,如减少网络的层数、减少节点数、减少参数量等,从而降低过拟合的风险。
3.使用正则化技术:如L1正则化、L2正则化等,通过在损失函数中添加正则化项,惩罚过大的权重,防止模型过度拟合训练数据。
4.使用Dropout:在训练过程中随机丢弃部分神经元,减少模型的复杂性,有助于防止过拟合。
5.交叉验证:使用交叉验证来评估模型的性能,通过不同子集的训练集和测试集来评估模型的泛化能力。
Dropout
Dropout是一种用于减少过拟合问题的正则化技术,常用于深度神经网络训练中。是一种随机丢弃(drop)神经元的方法。
在正常的神经网络中,每个神经元都会对输入进行权重计算和传递,这样每个神经元都可能贡献过多,导致网络过拟合训练数据。Dropout通过在训练过程中随机丢弃一部分神经元,即在前向传播过程中以一定的概率将某些神经元的输出置为0,这样可以强制神经网络学习到更加鲁棒的特征。
对比加Dropout层和不加Dropout层
import torch
import matplotlib.pyplot as plt
# 用于复现
# torch.manual_seed(1) # reproducible
# 20个数据点
N_SAMPLES = 20
# 隐藏层的个数为300
N_HIDDEN = 300
# training data
# 在-1到1之间等差取N_SAMPLES个点,然后再加维度,最终的数据变为N_SAMPLES行、1列的向量
x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
# 在均值为0、标准差为1的正态分布中采样N_SAMPLES个点的值,然后乘0.3,加上x,最后得到x对应的y值
y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# test data
test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# show data
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
# 快速搭建神经网络,不加dropout层
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
# 加了dropout层的
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5), # drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5), # drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
print(net_overfitting) # net architecture
print(net_dropped)
# 使用Adam优化神经网络的参数
optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
# 误差函数使用MSELoss
loss_func = torch.nn.MSELoss()
# 开启交互式绘图
plt.ion() # something about plotting
# 训练五百步
for t in range(500):
# 将x输入到不加dropout层的神经网络中,得预测值
pred_ofit = net_overfitting(x)
# 将x输入到加了dropout层的神经网络中,得预测值
pred_drop = net_dropped(x)
# 计算loss
loss_ofit = loss_func(pred_ofit, y)
# 计算loss
loss_drop = loss_func(pred_drop, y)
# 梯度清零
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
# 误差反向传播
loss_ofit.backward()
loss_drop.backward()
# 优化器逐步优化
optimizer_ofit.step()
optimizer_drop.step()
# 每10步进行更新
if t % 10 == 0:
"""
net_overfitting.eval()和net_dropped.eval()是将两个神经网络模型切换到评估模式,
用于在测试数据上进行稳定的前向传播,得到准确的预测结果。
"""
# change to eval mode in order to fix drop out effect
net_overfitting.eval()
net_dropped.eval() # parameters for dropout differ from train mode
# plotting
plt.cla()
test_pred_ofit = net_overfitting(test_x)
test_pred_drop = net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
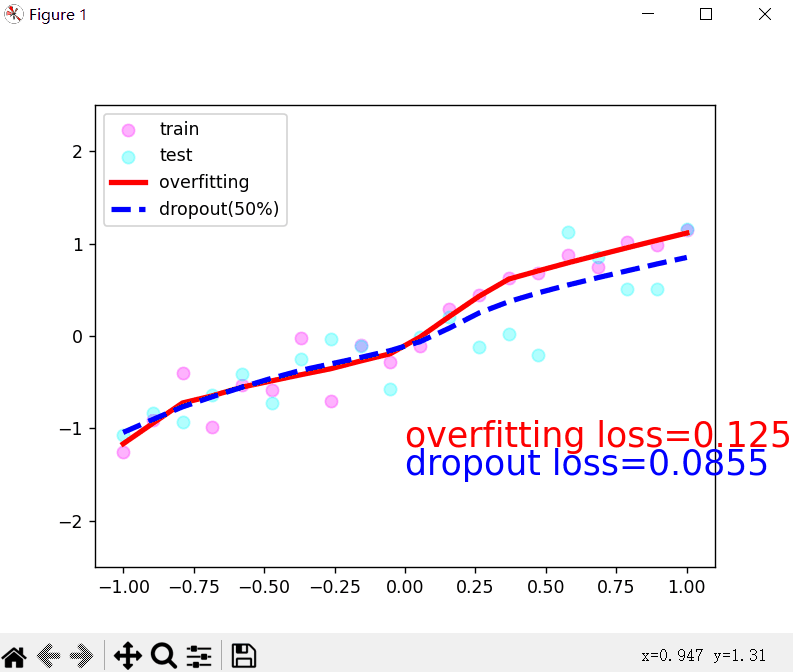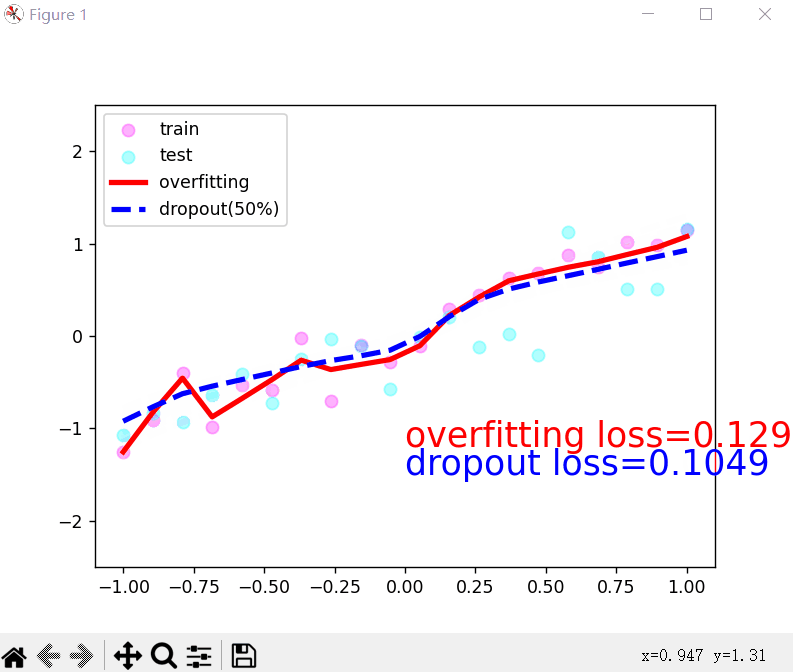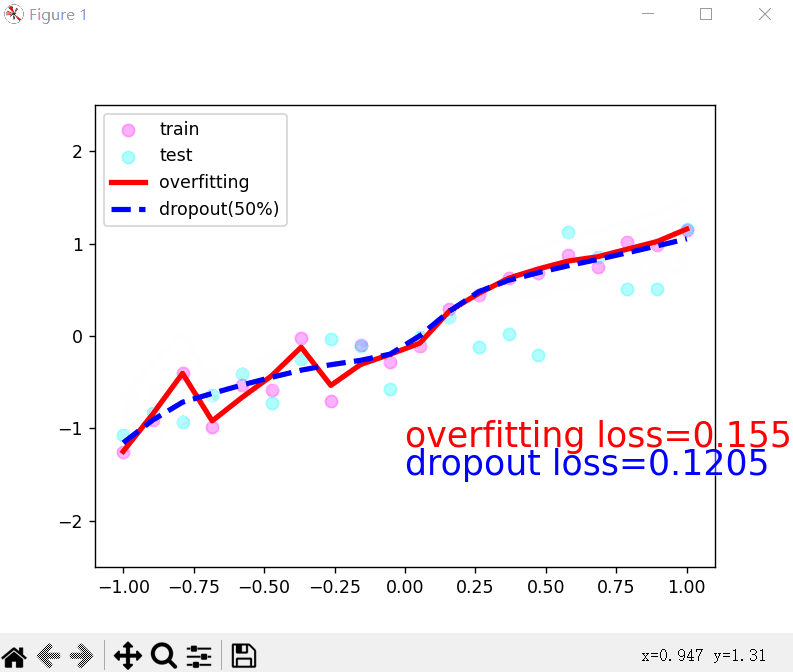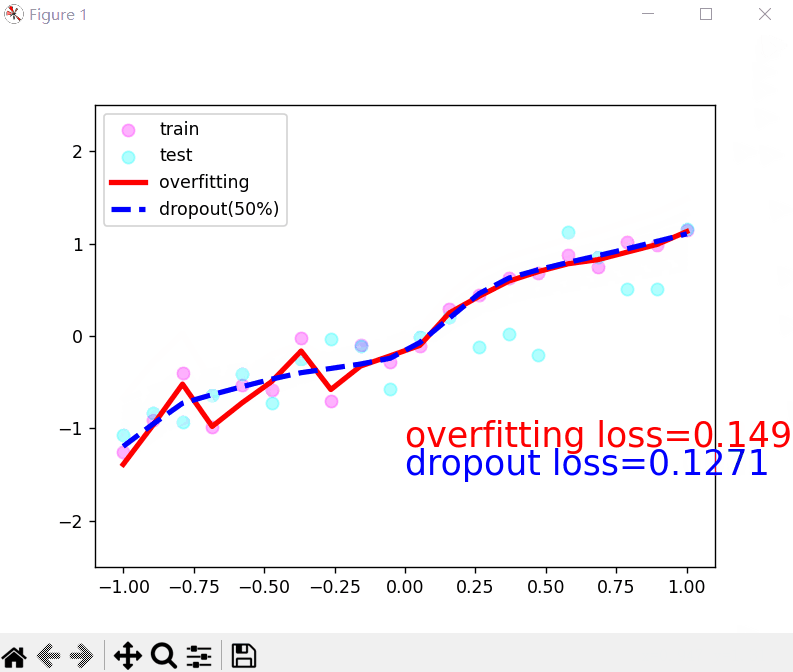
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data.numpy(), fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.pause(0.1)
# change back to train mode
"""
在训练模式下,神经网络中的Dropout层将会生效,即在前向传播过程中会随机丢弃一部分神经元。
这是为了在训练阶段增加模型的鲁棒性,避免过拟合。
"""
net_overfitting.train()
net_dropped.train()
# 关闭交互模式
plt.ioff()
plt.show()
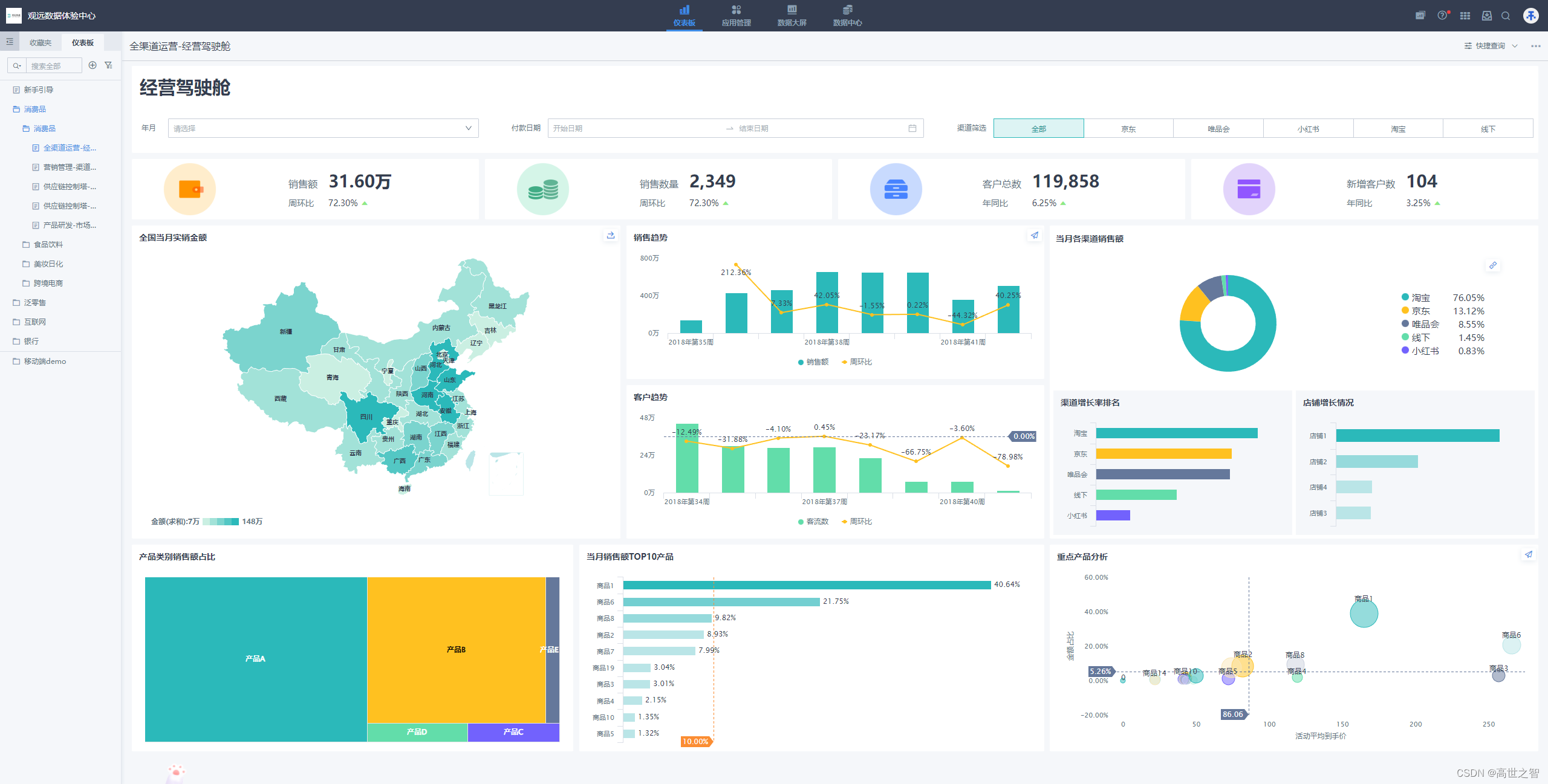
运行效果



![[JAVAee]volatile关键字](https://img-blog.csdnimg.cn/469a39b738a846bb8007c90500fd9689.png)