简介
通过Python内置csv模块,可以读取和写入CSV(逗号分隔值)文件。
CSV是一种常见的文件格式,通常用于存储表格数据,每行数据由逗号分隔,每个字段可以用引号括起来。
测试文件内容如下
列号,年龄,姓名,性别,爱好
1,23,关羽,男,骑车
2,45,李四,男,打篮球
3,25,王美丽,女,织毛衣
4,76,关大头,男,抠脚
5,28,淑女,女,旅游
目录
1. 读取 csv 文件
1.1. 读取全部内容
1.2. 固定读取第n行
1.3. 范围读取第n-m行
1.4. 读取最后一行
1.5. 跳过第n-m行
1.6. 固定读取第n列
1.7. 范围读取第n-m列
1.8. 跳过第n-m列
2. 写入 csv 文件
2.1. 追加内容但最后
2.2. 指定第n行写入内容
2.3. 指定n行m列追加内容
2.4. 修改第n行m列内容
2.5. 修改符合要求的值
3. 字典式读取和写入
1. 读取 csv 文件
1.1. 读取全部内容
创建一个读取的对象,遍历所有行
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历所有行
for row in reader:
print(row)
1.2. 固定读取第n行
由于 csv 模块不能直接指定第n行,可以通过跳过的方式读取
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 循环文件前2行
for _ in range(2):
next(reader) # 跳过前2行
# 读取下一行,也就是第3行
row_3 = next(reader)
print(row_3)
可以通过内置方法 readlines 读取指定行
with open(r'E:\test.csv', 'r', encoding='utf-8') as f:
# 通过索引读取第3行
lines = f.readlines()[2]
print(lines )
1.3. 范围读取第n-m行
csv 模块不能直接指定第n行,同样通过跳过的方式读取
读取第 3 - 5 行
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 循环文件前2行
for _ in range(2):
next(reader) # 跳过前2行
# 循环读取下n行
for _ in range(3): #遍历3次
row = next(reader)
print(row)
直接使用内置方法 readlines 读取 3-5 行
with open(r'E:\test.csv', 'r', encoding='utf-8') as f:
# 使用索引读取第3-5行
lines = f.readlines()[2:5]
# 直接打印3-5行
print(lines)
# 删除换行符,遍历读取
for line in lines:
cleaned_line = line.strip() # 去除行尾换行符
print(cleaned_line)
1.4. 读取最后一行
csv 模块中没有直接读取最后一行的方法,通过循环读取全部内容,持续更新赋值给变量,那么最后变量得到的结果就是最后一行
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 循环赋值
for row in reader:
last_row = row
# 赋值的最后一行就是最终内容
print(last_row)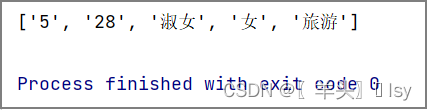
直接通过内置函数 readlines 读取最后一行
with open(r'E:\test.csv', 'r', encoding='utf-8') as f:
# 读取最后一行
lines = f.readlines()[-1]
print(lines)
1.5. 跳过第n-m行
通过内置函数 enumerate 输出的序号来判断跳过第 2-3 行
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 指定迭代序号,序号从1开始
for num,row in enumerate(reader, 1):
# 如果序号为2-3,那么跳出当前循环
if 2 <= num <= 3:
continue
# 打印序号和值
print(num,row)
跳过最后一行(将csv阅读对象转换为列表)
- 如果CSV文件非常大,将其读取到内存中作为列表可能会导致内存占用过高,尤其是在处理大型CSV文件时,可能会影响程序的性能并导致内存不足错误。
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 将csv对象转换为列表
row_list = list(reader)
# 遍历这个列表和行号
for num,row in enumerate(row_list, 1):
# 如果行号=总行数,跳出循环
if num == len(row_list):
break
# 输出每行内容
print(row)
1.6. 固定读取第n列
通过索引读取第 3 列
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历读取所有行
for row in reader:
# 判断长度大于3
if len(row) >= 3:
# 如果长度大于3,则通过索引读取第3列
print(row[2])
else:
print('null')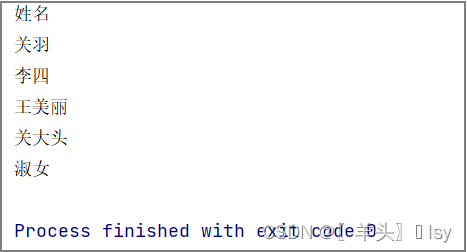
读取第1、2、4列
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历读取所有行
for row in reader:
# 指定第1、2、4列
print(row[0], row[1], row[3])
读取最后 1 列
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历读取所有行
for row in reader:
# 通过索引读取最后1列
print(row[-1])
1.7. 范围读取第n-m列
通过索引读取第 2-4 列
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历读取所有行
for row in reader:
# 通过索引读取第 2-4 列
print(row[1:4])
1.8. 跳过第n-m列
跳过第 2-3 列
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历读取所有行
for row in reader:
# 跳过2-3列(读取1列和3列后面全部)
print(row[0], *row[3:]) # *表示解包
跳过最后一列
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as f:
# 创建csv阅读器对象
reader = csv.reader(f)
# 遍历读取所有行
for row in reader:
# 输出最后一列前面的所有列
print(row[:-1])
2. 写入 csv 文件
2.1. 追加内容但最后
打开文件时,a表示追加,w表示覆盖
import csv
# w表示覆盖,a表示追加
with open(r'E:\test.csv', 'a', newline='', encoding='utf-8-sig') as f:
# 创建csv写入器对象
writer = csv.writer(f)
'''写入单行'''
writer.writerow([]) # 如果前面有内容,先写入 一个空行
writer.writerow([6, 13, '妲己', '女', '约会'])
'''写入多行,关键字后面加s'''
data = [
[7, 49, '孙悟空', '男', '打架'],
[8, 14, '猪八戒', '男', '吃饭'],
[9, 20, '沙悟净', '男', '干活']
]
writer.writerows(data)
2.2. 指定第n行写入内容
方法:读取原内容 → 追加新内容 → 覆盖原内容
import csv
# 读取文件内容,转换为列表
with open(r'E:\test.csv', 'r', newline='', encoding='utf-8-sig') as f:
original_data = list(csv.reader(f))
# 指定在第2行插入内容
original_data.insert(1, [6, 13, '妲己', '女', '约会'])
# 将新内容直接覆盖到原文件
with open(r'E:\test.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerows(original_data)
2.3. 指定n行m列追加内容
方法:读取原内容 → 追加新内容 → 覆盖原内容
import csv
# 读取文件内容,转换为列表
with open(r'E:\test.csv', 'r', newline='', encoding='utf-8-sig') as f:
original_data = list(csv.reader(f))
# 指定在第2行、第3列后面追加内容
original_data[1].insert(3, '临时1,临时2')
# 将新内容直接覆盖到原文件
with open(r'E:\test.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerows(original_data)
2.4. 修改第n行m列内容
方法:读取原内容 → 修改内容 → 覆盖原内容
import csv
# 读取文件内容,转换为列表
with open(r'E:\test.csv', 'r', newline='', encoding='utf-8-sig') as f:
original_data = list(csv.reader(f))
# 指定更新第2行3列的内容
original_data[1][2] = '临时1'
# 将新内容直接覆盖到原文件
with open(r'E:\test.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f, quoting=csv.QUOTE_NONE, quotechar='', escapechar='\\')
writer.writerows(original_data)
2.5. 修改符合要求的值
方法:读取原内容 → 遍历每行 → 遍历行的每列 → 条件判断 → 修改内容 → 覆盖原内容
import csv
# 读取文件内容,转换为列表
with open(r'E:\test.csv', 'r', newline='', encoding='utf-8-sig') as f:
rows = list(csv.reader(f))
# 遍历所有行
for row in rows:
# 遍历所有列索引和列的值
for idx, col in enumerate(row):
# 判断以 '李' 开头的字符
if col.startswith("李"):
row[idx] = "李**" # 修改内容
# 将新内容直接覆盖到原文件
with open(r'E:\test.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f, quoting=csv.QUOTE_NONE, quotechar='', escapechar='\\')
writer.writerows(rows)
3. 字典式读取和写入
- 通过键值对方式读取和写入内容。在csv文件中的键值对并不是以 key:value 的形式表现,而 key 表示标题(第1行),value 表示内容(第1行下面对应的内容)
通过键访问值
import csv
# 指定字符集为 utf-8-sig 是为了自动处理BOM字符,并消除\ufeff的出现
with open(r'E:\test.csv', 'r', encoding='utf-8-sig') as csvfile:
# 创建csv阅读器对象
reader = csv.DictReader(csvfile)
# 遍历所有行
for row in reader:
# 可以通过键来访问每一列的内容
print(row['姓名'], row['年龄'], row['性别'])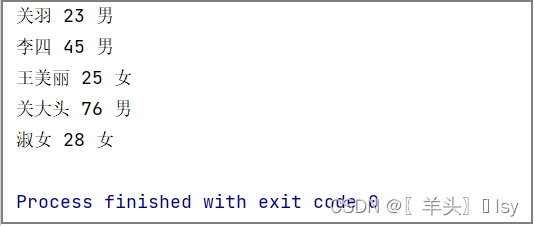
写入数据
import csv
# 要写入CSV文件的键值对数据
data = [
{'姓名': 'new_姓名1', '年龄': 'new_年龄1', '性别': 'new_性别1'},
{'姓名': 'new_姓名2', '年龄': 'new_年龄2', '性别': 'new_性别2'},
{'姓名': 'new_姓名3', '年龄': 'new_年龄3', '性别': 'new_性别3'}
]
# 打开CSV文件追加内容
with open(r'E:\test.csv', 'a', newline='') as csvfile:
# 创建csv写入器对象
writer = csv.writer(csvfile)
# 写入空行
writer.writerow([])
# 写入键值对数据
fieldnames = data[0].keys() # 确定列标题(即键)
writer.writerow(fieldnames) # 写入列标题
for row in data:
writer.writerow(row.values()) # 写入数据行