文章目录
- 5. RocketMQ 消息中间件、RabbitMQ、ActiveMQ
- 【√】5.1 RocketMQ
- 6. Kafka 大数据量消息中间件、ElasticSearch、ZooKeeper
- 【√】6.1 Kafka
- 【√】6.2 ElasticSearch
- 7. 分布式、研发提效、高并发、线程安全
- 【√】7.1 分布式与集群
- 【√】7.2 高并发、线程安全
- 【×】7.3 研发提效
- 【√】7.4 设计模式
- 8. Linux 运维、Tomcat、Nginx、Docker、K8s、Kuboard
- 【×】8.1 Linux
- 【×】8.2 Docker 容器管理
- 【×】8.3 Kubernetes 容器编排工具
- 9. Maven 版本管理、Git、SVN
- 【×】9.1 项目版本管理 Git
- 10. 安全规约
以下目录参考上篇
- Java 基础
【√】1.1 数据结构:集合 Set Map List Array Tree
【√】1.2 基础算法:排序算法、二分算法、银行家算法、最短路径算法、最少使用算法、一致性哈希算法
【√】1.3 Thread
【×】1.4 代理、反射、流操作、Netty
【√】1.5 JVM 原理
【√】1.6 基础编程规约- MySQL 数据库、Oracle、Redis、NoSQL、ShardingSphere
【√】2.1 MySQL
【×】2.2 Oracle
【√】2.3 Redis
【√】2.4 ShardingSphere- Spring 框
【√】3.1 Spring
【√】3.2 SpringMVC
【√】3.3 SpringBoot
【√】3.4 SpringCloud
【√】3.4 Dubbo- Mybatis 持久层框架、JFinal、Heibernate
【√】4.1 MyBatis
【×】4.2 JFinal
【√】4.3 Heibernate
5. RocketMQ 消息中间件、RabbitMQ、ActiveMQ
MQ 优势:
错峰流控(业务削峰场景)、解耦、最终一致性、广播
1)数据缓冲:将上游数据接收到消息队列中,暂时存放,下游服务可以按照自己的节奏进行处理。上游数据一旦有大量的突发流量,保证了下游服务不会受到影响。
2)解耦以及扩展:将上游服务和下游服务通过消息队列进行通信。消息队列可以作为一个接口层,只要上游服务以及下游服务遵守接口的规范,便可以随意添加新的服务器。
3)冗余及健壮性:一个消息被保存为多个副本,多个下游服务可以消息同一个消息。比如消息队列 Kafka 支持副本
4)异步通信:数据暂时存放在消息队列中,下游服务可以在需要的时候再去处理它。
| RocketMQ | ActiveMQ | RabbitMQ | Kafka | |
|---|---|---|---|---|
| 基础 | 阿里基于电商业务参考Kafka设计 | 基于erlong开发 | 起源于日志系统 | |
| 吞吐量 | 十万 | 万 | 万 | 百万 |
| 时效性 | ms | ms | ||
| 高可用 | 分布式架构 | 主从架构高可用 | 分布式高可用 | |
| 消息可靠性 | 经过参数优化配置,消息可以做到0丢失 | 有较低的概率丢失数据 | 通过控制能够保证所有消息被消费且仅被消费一次 | |
| 优点 | MQ功能完善,支持10亿级别的消息堆积,超稳定,经历多次双十一验证 | MQ功能全面 | MQ功能完善,跨平台,支持多语言 | 吞吐量高;高可用;Pull方式获取消息消息有序且保证消费一次 |
| 缺点 | 不再维护 | 不利于二次开发,实现机制比较重决定了吞吐量低 | 功能支持简单的MQ功能,不支持失败重试,短轮询方式决定了实时性取决于轮询间隔时间 |
【√】5.1 RocketMQ

NameServer集群,Producer集群,Cosumer集群以及Broker集群
Producer负责生产消息
Cosumer负责消费消息,一般是后台系统负责异步消费
Broker消息中转角色,负责存储消息、转发消息
NameServer 担任路由消息的提供者
工作流程
1)首先启动NameServer。NameServer启动后监听端口,等待Broker、Producer以及Consumer连上来
2)启动Broker。启动之后,会跟所有的NameServer建立并保持一个长连接,定时发送心跳包。心跳包中包含当前Broker信息(ip、port等)、Topic信息以及Borker与Topic的映射
3)创建Topic。创建时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic
4)Producer发送消息。启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic所在的Broker;然后从队列列表中轮询选择一个队列,与队列所在的Broker建立长连接,进行消息的发送
5)Consumer消费消息。跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,进行消息的消费
优点
具有集群消费、⼴播消费、消息积压能⼒强、防⽌消息丢失、顺序消息、事务型消 息、保证⾼可⽤、⾼性能读写数据等优点的消息中间件
吞吐量高:单机吞吐量可达十万级
可用性高:分布式架构
消息可靠性高:经过参数优化配置,消息可以做到0丢失
功能支持完善:MQ功能较为完善,还是分布式的,扩展性好
支持10亿级别的消息堆积:不会因为堆积导致性能下降
源码是java:方便我们查看源码了解它的每个环节的实现逻辑,并针对不同的业务场景进行扩展
可靠性高:天生为金融互联网领域而生,对于要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况
稳定性高:RoketMQ在上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验
高性能的存储机制
RocketMq采用文件系统存储消息,和Kafka一样采用顺序写的方式写入消息,使用零拷贝发送消息,这三者的结合极大地保证了RocketMq的性能;
相对于ActiveMq采用关系型数据库进行存储的方式更高效。
顺序写:Kafka、RocketMQ 采用顺序写,直接追加数据到末尾,减少了操作系统到磁盘的寻址动作。
零拷贝:直接由内核缓冲区Read Buffer将数据复制到网卡;传统方式有四层复制,磁盘文件->读取到操作系统内核缓冲区Read Buffer;将内核缓冲区的数据->复制到应用程序缓冲区Application Buffer;将应用程序缓冲区Application Buffer中的数据->复制到socket网络发送缓冲区;将Socket buffer的数据->复制到网卡,由网卡进行网络传输
零拷贝技术采用了MappedByteBuffer内存映射技术,采用这种技术有一些限制,其中有一条就是传输的文件不能超过2G,这也就是为什么RocketMq的存储消息的文件CommitLog的大小规定为1G的原因
集群部署
集群部署思路
master节点的brokerId为0,slave节点的brokerId为1(大于0即可);
同一组broker的broker-Name相同,如master1和slave1都为broker-a;
每个broker节点配置相同的NameServer;
复制方式配置:master节点配置为ASYNC-MASTER,slave节点配置为SLAVE即可;
刷盘方式分为同步刷盘和异步刷盘,为了保证性能而不去考虑少量消息的丢失,因此同意配置为异步刷盘
1)单Master
单机模式, 即只有一个Broker, 如果Broker宕机了, 会导致RocketMQ服务不可用, 不推荐使用
2)多Master模式
组成一个集群, 集群每个节点都是Master节点, 配置简单, 性能也是最高, 某节点宕机重启不会影响RocketMQ服务
缺点:如果某个节点宕机了, 会导致该节点存在未被消费的消息在节点恢复之前不能被消费
3)【推荐】多Master多Slave模式,异步复制
每个Master配置一个Slave, 多对Master-Slave, Master与Slave消息采用异步复制方式, 主从消息一致只会有毫秒级的延迟
优点是弥补了多Master模式(无slave)下节点宕机后在恢复前不可订阅的问题。在Master宕机后, 消费者还可以从Slave节点进行消费。采用异步模式复制,提升了一定的吞吐量。总结一句就是,采用多Master多Slave模式,异步复制模式进行部署,系统将会有较低的延迟和较高的吞吐量
缺点就是如果Master宕机, 磁盘损坏的情况下, 如果没有及时将消息复制到Slave, 会导致有少量消息丢失
4)【推荐】多Master多Slave模式,同步双写
与多Master多Slave模式,异步复制方式基本一致,唯一不同的是消息复制采用同步方式,只有master和slave都写成功以后,才会向客户端返回成功
优点:数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
缺点就是会降低消息写入的效率,并影响系统的吞吐量
RocketMQ 高可用
集群部署NameServer
集群部署Broker,master挂掉,则会自动切换到其他的master
设置同步复制方式brokerRole:SYNC_MASTER;即使master节点挂了,slave上也有当前master的所有备份数据,保证消息完整性
异步复制,就是消息发送到master节点,只要master写成功,就直接向客户端返回成功,后续再异步写入slave节点
同步复制,就是等master和slave都成功写入内存之后,才会向客户端返回成功
负载均衡
1)producer发送消息的负载均衡:默认会轮询向Topic的所有queue发送消息,以达到消息平均落到不同的queue上;而由于queue可以落在不同的broker上,就可以发到不同broker上
2)consumer订阅消息的负载均衡:假设有5个队列,两个消费者,则第一个消费者消费3个队列,第二个则消费2个队列,以达到平均消费的效果。而需要注意的是,当consumer的数量大于队列的数量的话,根据rocketMq的机制,多出来的队列不会去消费数据,因此建议consumer的数量小于或者等于queue的数量,避免不必要的浪费
保证消息不丢失
Producer:同步发送+重试机制+多个master节点,尽可能减小消息丢失的可能性
同步发送模式,即消息发送到,消息发送 broker 后等待 broker 响应结果完成
producer 支持失败重试,默认3次;
多 master broker模式,即使某个主机宕机,仍可保证消息发送到其他 broker 节点
Consumer:ACK机制
Consumer先pull 消息到本地,消费完成后,才向服务器返回ack;即先消费,消费成功后再提交
保证消息不重复消费
rocketMq保证了同一个消费组只能消费一次,但会被不同的消费组重复消费,因此这种重复消费的情况不可避免;
业务处理一:业务逻辑保持幂等性,相同的消息多次执行,结果一致
业务处理二:消息主键作为表主键约束,消息先入库在消费,相同消息无法入库。
业务处理三:失败重试,消息处理失败支持重试三次
消息确认:ack机制
6. Kafka 大数据量消息中间件、ElasticSearch、ZooKeeper
TODO Kafka
ELK 日志系统
【√】6.1 Kafka
Kafka 是分布式、高吞吐、可扩展的消息队列服务。
消息队列Kafka版广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分。
Kafka Broker
一个单独的Kafka Server就是一个Broker。Broker的主要工作就是接收生产者发过来的消息,分配offset,之后保存到磁盘中。
同时,接收消费者、其他Broker的请求,根据请求类型进行相应处理并返回响应。在一般的生产环境中,一个Broker独占一台物理服务器。
队列消息 Kafka 版
Kafka 不支持失败重试
异步、批量、消息重试
Producer将消息经过KeySerializer、valueSerializer序列化后,经过Partition分区器处理,决定消息落到topic具体哪个分区中,最后将消息发送到客户端的消息缓冲池accumulator中,这个缓冲池的最大值默认为32M(buffer.memory)并交由一个Sender线程进行发送。消息在缓存池中会被分为一个个batch,每个batch默认大小为16KB(batch.size),消息一旦攒够该大小或超过最大空闲时间(linger.ms)将会被发送到broker。Producer通过参数(retries)控制消息发送的重试次数,由于网络抖动等原因,消息将会重新进行发送。
3.kafka中ack为0,1,-1代表啥
1)0代表生产者发送的消息一旦发送出去,不需要等待消息的确认,传输效率最高,但是可靠性无法保证
2)1代表生产者将消息发送出去,需要等待leader接收成功的消息确认,kafka默认为该值。
3)-1代表生产者将消息发送出去,需要等待ISR中所有的副本都接收成功。
4.kafka的unclean是啥
kafka中的一个配置unclean.leader.election.enable,新版本该值默认为false。一旦开启该配置,意味着在leader宕掉的情况下,非ISR中的follower也可以参与leader选举,这样就会造成数据的不一致情况的发生,消费者拿到的消息会重复。
5.kafka为什么不支持读写分离
kafka中消息的读写都会直接与leader进行交互,不会与follower进行交互,follower只是为了保证消息的可用性。kafka不支持读写分离主要因为:数据的延时问题以及因此导致的数据不一致性,follower在向leader进行数据拉取时,需要一定的时间,在这段时间内,follower内的数据与leader中的数据时不一致的。
6.kafka是否可以保证消息的顺序性
kafka不能保证整个topic中的消息是有序的,只能保证每个partition中的消息是有序的。
7.kafka中的consumer group是什么意思
consumer group是一个逻辑上的概念,多个消费者可以构成一个消费组,一个partition只能被消费组中的一个消费者所消费。但是多个消费组可以消费同一个partition。
8.什么情况下broker会从ISR中被踢出
leader负责维护ISR列表,每个Partition都会有一个ISR,如果其中一个follower超过10s(replica.lag.time.max.ms)没有向leader发起数据复制请求,则会被leader将其从ISR中移除。
9.如何避免消费端Rebalance
消费端的Rebalance就是让一个消费组内的所有消费者就如何消费topic的所有分区达成共识的过程,在Rebalance过程中,所有的Consumer实例都会停止消费,等待Rebalance的完成,严重影响消费端的TPS,所以应当尽量避免。
Rebalance发生的条件有三种:
1)消费组内的消费者成员数量发生变化
2)消费主题的数量发生变化
3)消费主题的分区数量发生变化
后面两种情况是不可避免的,所以我们能做的就是尽量避免第一种情况的发生
组内成员数量发生变化无非就两种情况,一种是为了提高消费速度增加了消费者组内的消费者数量,这种情况是正常的。另外一种情况是有消费者退出,这种情况需要避免。正常情况下,每个消费者都会定期向组协调器发送心跳,表明自己还存活,如果消费者不能及时的发送心跳,组协调器会被认为该消费者已经“死”了,就会导致消费者离组引发Rebalance问题。这里涉及到两个参数:session.timeout.ms和heartbeat.interval.ms分别为组协调器认为消费组存活的期限和消费者发送心跳的时间间隔。max.poll.interval.ms为consumer两次拉取数据的最大时间间隔,超过这个时间,也会导致消费者离组。另外,如果Consumer端频繁进行FullGC也会导致消费端长时间停顿,引发Rebalance。为了解决这个问题,主要从以下方面入手:
1)合理配置session.timeout.ms和heartbeat.interval.ms,避免因心跳发送超时导致的Rebalance。
2)调整max.poll.interval.ms的大小
3)监控消费这的GC情况
10.kafka是否有消息丢失以及消息重复的情况,如何解决
消息丢失:
1)request.required.acks属性设置为0,当网络异常,缓冲区满等情况,消息可能丢失
2)属性设置为1,leader确认接收,但是在副本进行同步之前挂掉了,数据可能丢失
解决方法:同步模式下,将属性设置为-1;异步模式下,不设置阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态
消息重复:主要针对的是消费者可能会重复读取相同消息的情况,消费者如果在处理了消息但是没有更新offset的情况下宕掉了,那么在它重启之后就会读取到之前已经处理过的数据。
解决方法:想要解决这种情况,就要保证消费端的幂等性,综合实际的情况来考虑。比如,将数据插入到数据库中可以先判断是否已经存在,如果存在,就不做插入处理等。
【√】6.2 ElasticSearch
Elasticsearch 是一个分布式、可扩展、近实时的搜索与数据分析引擎,是准实时刷新检索引擎;基于Lucene,Lucene是支持实时查询的, 原理是每次索引之后都做一次刷新。
Luence 是全文检索工具,包括信息检索、分词原理、词项、倒排索引、排序算法等内容
倒排索引是相对于正序索引来说的,根据文档查找词项是正排索引,按照词项查找文档是倒排索引。
词项是索引的最小单位;
数据存储格式为JSON
{
"name" : "Jay",
"desc" : "Is Jay",
"gender" : "male",
"birth" : "2000-10-10"
}
基础概念
1)Index 索引 索引是文档的集合;对应传统数据库中的数据库
2)Document 文档 文档是信息检索的对象;对应数据库中的行记录
3)Field 字段 字段对应数据库中的字段
5)Shards & Replicasedit 分片 简单理解为分表;分片的原理是在物理上拆分,不同的分片支持放在不同的服务器,解决单台服务器性能限制问题。副本,是对分片的备份,主分片损坏或异常丢失时,副本可以顶上来代替主分片,保证功能可用数据不丢失。
6) Template 模板设置 模板设置包括 settings 和 mappings,定义了索引的基本设置和 field 的映射关系,支持配置分词器等,多个索引可通过模板匹配的方式共用一个模板。
| ElasticSearch | 传统数据库 |
|---|---|
| Index 索引 | Database 数据库 |
| Type 类型 | Table 表 |
| Field 字段/域 | Column 列/字段 |
| Document 文档 | Row 行/记录 |
| Mappings 映射 | Schema 数据库对象集合 |
| Settings 设置 | |
| 一切皆索引 | 指定字段创建索引 |
| Query DSL | SQL 数据库语句 |
| GET http:// GET请求 | Select 查询 |
| POST http:// POST请求 | Add 新增 |
| PUT http:// PUT请求 | Update 更新 |
| DELETE http:// DELETE请求 | Delete 删除 |
环境配置 elasticsearch.yml
ES 启动时可能会出现bootstrap启动问题, 这个问题主要原因是服务器本身系统配置默认参数大小设置偏低, 适当调大即可; 百度一下修改指定系统文件即可.
编辑/安装路径/config/ jvm.options配置文件, 根据服务器本身配置去合理修改堆内存分配.默认分配-Xms4g, 服务器配置低的话, 就调小2或1; 配置高就适当调大多次测试ES的吞吐量找到最优配置参数.
# ---------------------------------- Cluster ----------------------------------#
# Use a descriptive name for your cluster:
# 集群名称自定义, 集群内多个节点的集群名称唯一
cluster.name: log_elk
# ------------------------------------ Node ---------------------------------#
# Use a descriptive name for the node:
# 节点名称自定义,集群内多个节点名称不重复
node.master: false
node.name: node-135
# ----------------------------------- Paths ----------------------------------
# Path to directory where to store the data (separate multiple locations by comma):
path.data: /opt/elkf/esData/data
path.logs: /opt/elkf/esData/logs
# ----------------------------------- Memory --------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# ---------------------------------- Network ---------------------------------
network.host: 192.168.15.135
http.port: 9200
# 配置集群自动发现节点
discovery.zen.ping.unicast.hosts:["192.168.15.135", "192.168.15.134"]
# 配置最大master节点数目
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
# 解决bootstrap启动问题
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
ES查询 term、terms、match、query、range、wildcard、fuzzy
term 查询某个字段包含某个关键词的文档
terms 查询某个字段里包含多个关键词的文档
term 不分词查询,意为包含,包含则返回结果;查询是在分词结果中匹配,大写要转换成小写,不推荐驼峰属性,推荐下划线属性。
match、query 分词查询,会对field进行分词操作,然后再查询
match_all 查询所有文档
multi_match 可以指定多个字段
match_phrase 短语匹配查询,ElasticSearch引擎首先分析(analyze)查询字符串,从分析后的文本中构建短语查询,这意味着必须匹配短语中的所有分词,并且保证各个分词的相对位置不变
GET lib3/user/_search
{
"query":{"match":{"age": 20}}
}
GET lib3/user/_search
{
"query":{
"match_all": {}
}
}
GET lib3/user/_search
{
"query":{
"multi_match": {
"query": "youyong",
"fields":["interests","name"]
}
}
}
范围查询 range
参数:from,to,include_lower,include_upper,boost
include_lower:是否包含范围的左边界,默认是true
include_upper:是否包含范围的右边界,默认是true
GET /lib3/user/_search
{
"query": {
"range": {
"birthday": {
"from": "1990-10-10",
"to": "2000-05-01",
"include_lower": true,
"include_upper": false
}
}
}
}
通配符查询 wildcard
GET /lib3/user/_search
{
"query": {
"wildcard": {
"name": "wang*"
}
}
}
GET /lib3/user/_search
{
"query": {
"wildcard": {
"name": "li?i"
}
}
}
模糊查询 fuzzy,fuzzy 查询是 term 查询的模糊等价
GET /lib3/user/_search
{
"query": {
"fuzzy": {
"interests": "chagge"
}
}
}
ES 数据保证不丢失
较多技术实现上保证数据不丢失方式,常见的有两种
- 异步刷新:比如 MySQL 主从复制,Redis 持久化方式、MQ的异步刷新、ES 的 index.translog.durability: “aync”
- 同步刷新:MySQL的binlog、Redis 的AOF 保证更新操作就纪录日志、MQ 轮询调度消费者阻塞得到响应才认为消费成功,ES 的 translog
ES 调优
参数调优
index.refreash_interval: 300s # 索引刷新时间
bootstrap.memory_lock: true # 锁定JVM内存,禁止swap磁盘和内存交换,保证ES性能
index.merge.scheduler.max_thread_count: 1 # 索引 merge 最大线程数
index.translog.durability: async # 异步写硬盘,提升效率
index.translog.sync_interval: 120s # 异步写硬盘间隔时间
indices.memory.index_buffer_size: 30 # 内存
discovery.zen.ping_timeout: 120s # 心跳超时时间
discovery.zen.fd.ping_interval: 120s # 心跳检测时间
discovery.zen.fd.ping_timeout: 120s # ping超时时间
discovery.zen.fd.ping_retries: 6 # 心跳重试次数
thread_pool.bulk.size:20 # 写入线程个数
thread_pool.bulk.queue_size:20 # 写入线程队列大小
配置合适的JVM内存和合适的分片副本大小;
bulk 批量写入提高吞吐量
多线程写入 ES 数据,最大化 ES 集群下 bulk 方式带来性能的提升
调整索引刷新时间,降低内存数据刷入到磁盘的频率来提高性能
锁定JVM内存,禁止swap内存和磁盘的交换来提高性能
合适的分片和副本大小:
对于数据量较小(100GB以下)的index,往往写入压力查询压力相对较低,一般设置35个shard,number_of_replicas设置为1即可(也就是一主一从,共两副本)。对于数据量较大(100GB以上)的index:一般把单个shard的数据量控制在(20GB50GB)让index压力分摊至多个节点:可通过index.routing.allocation.total_shards_per_node参数,强制限定一个节点上该index的shard数量,让shard尽量分配到不同节点上综合考虑整个index的shard数量,如果shard数量(不包括副本)超过50个,就很可能引发拒绝率上升的问题,此时可考虑把该index拆分为多个独立的index,分摊数据量,同时配合routing使用,降低每个查询需要访问的shard数量
ES 集群
# 开启集群,配置当前节点名称,在集群中是否作为主节点
cluster.name: niaonao_elk
node.master: false
node.name: node-1
network.host: 192.168.200.81
http.port: 9200
# 是否锁定内存
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 配置集群自动发现节点
discovery.zen.ping.unicast.hosts:["192.168.200.81", "192.168.200.83"]
# 配置最大master节点数目
discovery.zen.minimum_master_nodes: 1
# 解决bootstrap启动问题
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
7. 分布式、研发提效、高并发、线程安全
【√】7.1 分布式与集群
- 分布式缓存(Redis、MemCache)
- 分布式事务(Seata:AT、PCC、Sage、XA)
- 分布式数据库(数据分片、数据同步)
分布式与集群
分布式:把一个大业务拆分成多个子业务,每个子业务都是一套独立的系统,子业务之间相互协作最终完成整体的大业务。
集群:把处理同一个业务的系统部署多个节点 。
特性:
- 高可用
- 易扩展
分布式ID算法
| 算法 | 雪花算法 | UUID |
|---|---|---|
| 长度 | 64bit 的长整型数据 | 36bit字符型数据 |
| 原理 | 41bit时间戳+10bit机器ID+12bit序列号 | 基于MAC地址生成UUID的算法 |
| 优点 | 按时间趋势递增;高性能:内存生成;容量大,查询效率高 | 高性能:本地生成 |
| 缺点 | 依赖与系统时间的一致性,修改系统时间可能会出现重复值 | UUID太长不易存储:36长度的字符串;信息不安全:可能会造成MAC地址泄露; |
雪花算法原理:在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。 例如 MySQL 的 Innodb 存储引擎的主键
其他算法:美团(Leaf)、滴滴(Tinyid)、百度(uid-generator)
分布式缓存 Redis、MemCache
本地缓存不支持持久化、无法共享、无法扩展;
分布式缓存技术常用 Redis、MemCache、JBossCache
支持缓存共享(分布式缓存)、支持缓存扩展(集群主从复制)、支持持久化(Redis的rdb、aof)
数据一致性策略
1)分布式缓存数据一致性解决方案先操作数据库再删除key;数据强一致性要求的,可以加上队列,进行异步删除key
2)更新缓存加锁,应对并发场景数据安全
3)较短的过期时间
分布式事务 SEATA
SEATA Simple Extensible Autonomous Transaction Architecture 简单可扩展自治事务框架
事务,一批操作全部成功或全部失败,ACID 原子性、一致性、隔离性、持久性;分布式事务用于在分布式系统中保证不同节点之间的数据一致性。
数据一致性:强一致性、弱一致性、最终一致性
微服务系统,多个子系统在某个业务上的操作也要求具备事务性,不让会出现,上游操作成功,下游操作失败的情况,存在数据错乱。两边的数据要一致。
单机服务,通过单机事务就可控制数据的一致性,保证整个操作的成功或失败回滚。而微服务就需要引入分布式事务进行管理全局事务以保证数据的一致性。
分布式事务重要概念
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚
二阶段提交 (2PC two-phase commit protocol)
2pc是经典的强一致、中心化的原子提交协议。包含一个中心化协调者节点(coordinator)和N个参与者节点(partcipant)
协调者发送事务内容给所有参与者,参与者执行事务,不提交,返回执行成功或执行失败;
协调者收到了参与者的失败信息或超时信息,直接给所有参与者发送回滚(rollback)信息进行事务回滚,否则,发送提交(commit)信息
参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源
遗留问题:性能问题(执行过程需阻塞等待)、协调者单点故障问题、丢失消息导致的数据不一致问题
三阶段提交(3PC)
相交二阶段提交,引入了canCommit和参与者超时机制;
CanCommit-PreCommit-DoCommit
协调者先发送是否可以提交事务的请求到参与者,参与者给出响应;
都返回yes则发送事务内容给参与者,参与者执行事务内容,不提交,返回执行成功或失败;
协调者发送提交事务请求或回滚事务,参与者进行提交或回滚。
SEATA 支持四种模式AT、TCC、Sage、XA,常用模式AT
| 模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| AT | 无侵入的分布式事务解决方案 | 业务升级成本低,无侵入,对业务改造影响较小 | |
| TCC | 高性能 | 核心系统对性能要求很高的场景 | |
| Sage | 长事务解决方案 | 业务流较长且保证事务最终一致性的场景 | |
| XA | 强一致性 | 强一致性,性能低 | 不推荐使用 |
AT(Auto Transaction)模式原理
TM端使用@GolableTranscation进行全局事务开启、提交、回滚
TM开始RPC调用远程服务
RM端seata-client通过扩展DataSourceProxy,实现自动生成undo-log与TC上报
TM告知TC提交/回滚全局事务
TC通知RM各自执行commit/rollback操作,同时清除undo-log
一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
优点
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案
缺点
当操作的数据是共享型数据,会存在脏写的问题,所以如果是 用户独有数据可以使用AT模式。
分布式数据库
由多个不同站点的多个数据文件组成
允许多个用户访问和操作数据
某个站点故障,其他站点可顶上来,数据支持恢复
多个站点数据一致性
分布式锁

【√】7.2 高并发、线程安全
并发集合(JUC 包),线程池(ThreadPoolExecutor),阻塞队列(先进先出BlockingQueue,有界队列ArrayBlockingQueue,LinkedBlockingQueue ),CAS与原子操作(CAS、AQS、ABA),无锁并发框架Disruptor,锁状态(无锁-偏向锁-轻量级锁-重量级锁),锁优化(自旋、去除、粗化)
单例对象类的方法要保证方法的线程安全;
并发下,考虑锁优化与资源消耗,能用轻量级锁使用轻量级锁,能无锁就无锁;
并发下,考虑线程安全集合类、阻塞队列,JUC包Atomic实体,Condition、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentSkipListMap、CopyOnWriteArrayList、CountDownLatch、CyclicBarrier、Executors、ForkJoinTask、ForkJoinWorkerThread、FutureTask、LinkedBlockingQueue、ThreadPoolExecutor、Semaphore、ArrayBlockingQueue、CompletableFuture
ThreadLocal 变量及时回收,线程池场景下,线程会复用,不及时清理变量,存在OOM的风险
线程池推荐使用 ThreadPoolExecutor 去创建,避免显式创建线程,避免OOM
对多个资源,数据库,表,对象等加锁时要注意加锁顺序,避免出现锁问题
对于轻量级锁 ReentrantLock 注意加锁和释放锁中间不要抛异常,避免无法是否锁造成其他线程无法获取锁资源。
对于尝试机制获取锁资源的场景,需要先判断当前对象是否持有锁,lock.tryLock();避免 AQS 抛异常
对于并发访问下线程出现冲突的概率小于 20% 的情况推荐使用乐观锁,乐观锁重试次数不超出 3 次;
资金流水相关业务,推荐使用悲观锁策略
避免方法级别的同步,使用代码块同步代替,有助于业务扩展维护
ABA 问题,可以通过乐观锁、互斥锁进行控制;防止在 CAS 时出现 ABA 问题而继续完成操作的场景。
CAS 比对并替换 compareAndSwapInt、
AQS 同步队列 AbstractQueuedSynchronizer,维护了双向链表,节点操作时,通过自旋获取锁后再操作,通过 CAS 进行并发控制。
AQS 拥有状态量 volatile state; 先进先出队列 FIFO Queue; 锁获取锁释放 tryAcquire() tryRelease();
CountDownLatch 内部有一个类 Sync 内部实现就是操作 AQS 的状态量 state;
Condition 等待通知机制,包含一个等待队列,主要动作是等待和通知;Condition 的实现类是 AQS 的内部类 ConditionObject,Condition 是依赖 Lock 对象的,通过 await() signal() 方法等待、通知
public class CountDownLatch {
private class Sync extend AbstractQueuedSynchronizer{}
}
public class AbstractQueuedSynchronizer {
public class ConditionObject implements Condition{}
}
在获取同步状态时,AQS维护一个同步队列,获取同步状态失败的线程会加入到队列中进行自旋;移除队列(或停止自旋)的条件是前驱节点是头结点并且成功获得了同步状态。在释放同步状态时,同步器会调用unparkSuccessor()方法唤醒后继节点。
死锁
多个线程互相阻塞等待锁资源。就会死锁;
对多个数据库,表,对象操作时,注意加锁的顺序,避免出现死锁。
线程池
通过 ThreadPoolExecutor 创建线程池,避免资源浪费耗尽的风险;
corePoolSize:核心线程数
maximumPoolSize:最大线程数,线程池中允许的最大线程数
keepAliveTime:存活时间,当线程数大于核心时,这是空闲线程在终止前等待新任务的最长时间。
TimeUnit:存活时间单位
workQueue:阻塞队列类型
Executors.defaultThreadFactory():线程工厂方法,用于创建线程
defaultHandler:默认的拒绝策略
拒绝策略(当工作队列满且线程个数达到maximunPoolSize后所采取的策略)
- AbortPolicy 抛异常 throws a RejectedExecutionException.
- DiscardPolicy 丢弃新的任务 silently discards the rejected task.
- DiscardOldestPolicy 调用poll方法丢弃工作队列队头的任务 discards the oldest unhandled request and then retries execute, unless the executor is shut down, in which case the task is discarded.
- CallerRunsPolicy runs the rejected task directly in the calling thread of the execute method, unless the executor has been shut down, in which case the task is discarded.既不抛弃任务也不抛出异常,把队列中的任务放在调用者调用者线程中运行。
锁状态
锁只会升级不会降级,由偏向锁升级为轻量级锁,轻量级锁升为重量级锁。不会降级
当不存在资源竞争时,默认使用偏向锁;JVM 会使用 CAS 来保证线程安全,在对象头部 Mark Word 设置线程ID,标识偏向于该线程;当其他线程试图锁定某个已被偏向过的对象时,JVM 就会撤销偏向锁,升级为轻量级锁;轻量级锁依赖 CAS 操作 Mark Word 试图获取锁,获取得到就是轻量级锁,获取不到时升级为重量级锁 synchronized
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 无锁 | \ | \ | \ |
| 偏向锁 | 加锁释放锁不需要额外的消耗 | 线程间存在锁竞争 | 适用于只有一个线程访问同步块的场景 |
| 轻量级锁 | 竞争的线程不会阻塞 | 始终得不到锁竞争的线程,会自旋消耗资源 | 同步块执行速度快 |
| 重量级锁 | 线程竞争不使用自旋机制 | 线程会阻塞 | 同步块执行速度慢,追求并发量 |
锁优化机制
自旋锁在存在竞争的情况下,让当前线程自旋(忙循环)等待后,尝试获取对象的锁。
锁消除是对于不存在共享资源的代码块去除同步措施;
锁粗化是对于频繁加锁解锁操作适当扩大加锁范围;
轻量级锁在无竞争的情况下,使用 CAS 操作做同步;
偏向锁在无竞争的情况下,不再任何同步操作;
volatile、synchronized
volatile 具有可见性,适用于一写多读场景
synchronized 具有原子性、可见性、有序性,互斥同步锁;修饰实例方法,作用于实例对象;修饰静态方法,作用于类对象;修饰代码块;
原理:对象头里的标记字段 Mark Word,存储了对象的锁信息;一个对象获取锁资源后,会变更 Mark Word 中的锁标识;
一个对象拥有一个监控器 Monitor,MonitorEnter 和 MonitorExit 指令分别标识进去互斥同步操作。只有退出时,释放锁资源,其他阻塞对象才可尝试获取对象的锁。
阻塞队列
可以解决线程的安全问题。因为阻塞队列是线程安全的,所以生产者和消费者都可以是多线程的,不会发生线程安全问题;内部通过轻量级锁 ReentrantLock 和 Codition 实现;
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。创建 ArrayBlockingQueue 时,需要初始化队列的大小。不支持空元素。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。添加和删除方法都通过 Lock 做了并发处理,添加和删除不互斥,Condition 用来挂起和唤醒其他线程
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
【×】7.3 研发提效
研发架构
研发规范
研发效率
【√】7.4 设计模式
单例模式
单例模式+双锁检查+volatile
/**
* @author niaonao
* 线程安全的单例模式
* Double Check Locking 双锁机制,对单例进行两层加锁
* 使用使用了volatile关键字来保证其线程间的可见性
* 同步代码块中使用二次检查,以保证其不被重复实例化
*/
public class GFriendSingleMultithread {
volatile private static GFriendSingleMultithread grilfriend = null;
//默认的构造方法通过private 修饰为私有方法,该单例类就只允许通过getInstance() 获取创建实例。
private GFriendSingleMultithread(){}
public static GFriendSingleMultithread getInstance() {
if(null == grilfriend){ //第一层检查
//synchronized 修饰,同步代码块,处理多线程的关键字
synchronized (GFriendSingleMultithread.class) {
if(null == grilfriend){//第二层检查
grilfriend = new GFriendSingleMultithread();
}
}
}
return grilfriend;
}
}
工厂模式
Spring IOC就是通过工厂模式来实现的,将对象的创建和管理过程交由Spring去完成,主要通过beanFactory来实现,根据传入bean的名字来获取对象。BeanFactory
// Object 一个以所给名字注册的bean的实例
public static <T> T getBean(String name) throws BeansException {
return (T) beanFactory.getBean(name);
}
public static <T> T getBean(Class<T> clz) throws BeansException {
T result = (T) beanFactory.getBean(clz);
return result;
}
策略模式
策略模式针对不同的场景封装不同的算法,用于应对不同的业务场景。Spring中获取资源时会用到Resource接口,它用很多的实现类,像UrlResource访问网络资源,ClassPathResource方法类加载本地资源,InputStreamResource访问输入流中的资源等。有一个方法叫做DefaultResourceLoader,其中包含一个getResource方法,可以根据资源路径选取不同的Resource
@Override
public Resource getResource(String location) {
Assert.notNull(location, "Location must not be null");
for (ProtocolResolver protocolResolver : this.protocolResolvers) {
Resource resource = protocolResolver.resolve(location, this);
if (resource != null) {
return resource;
}
}
if (location.startsWith("/")) {
return getResourceByPath(location);
}
else if (location.startsWith(CLASSPATH_URL_PREFIX)) {
return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());
}
else {
try {
// Try to parse the location as a URL...
URL url = new URL(location);
return new UrlResource(url);
}
catch (MalformedURLException ex) {
// No URL -> resolve as resource path.
return getResourceByPath(location);
}
}
}
责任链模式
FilterChain 过滤器责任链
public interface FilterChain {
void doFilter(ServletRequest var1, ServletResponse var2) throws IOException, ServletException;
}
代理模式
AOP(面向切面编程)的底层就是使用代理模式实现的,将一些公共操作,如权限校验、日志打印、提交事务等操作封装成功公共模块,作为切面;将其放在切点前后,用于对切点做一系列的增强操作。
当类实现接口时,想要对其实现代理用的是JDK的方式,具体用Proxy类的new ProxyInstance方法获取代理对象,重写InvocationHandler接口的invoke方法实现具体的代理操作
当类没有实现接口时,利用CGLIB的方式完成代理,通过Enhancer创建代理对象,重写MethodInterceptor接口的intercept方法实现代理操作
可以看到其中很重要的一点就是获取代理对象,在Spring中AOP的核心类是AbstractAutoProxyCreator,它实现了InstantiationAwareBeanPostProcessor接口,重写postProcessBeforeInstantiation和getEarlyBeanReference、postProcessAfterInitialization方法来创建具体的代理对象
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) {
Object cacheKey = this.getCacheKey(beanClass, beanName);
if (!StringUtils.hasLength(beanName) || !this.targetSourcedBeans.contains(beanName)) {
if (this.advisedBeans.containsKey(cacheKey)) {
return null;
}
if (this.isInfrastructureClass(beanClass) || this.shouldSkip(beanClass, beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return null;
}
}
TargetSource targetSource = this.getCustomTargetSource(beanClass, beanName);
if (targetSource != null) {
if (StringUtils.hasLength(beanName)) {
this.targetSourcedBeans.add(beanName);
}
Object[] specificInterceptors = this.getAdvicesAndAdvisorsForBean(beanClass, beanName, targetSource);
Object proxy = this.createProxy(beanClass, beanName, specificInterceptors, targetSource);
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
} else {
return null;
}
}
观察者模式
观察者模式中包括三个部分 事件、事件源、监听器
ApplicationEvent 事件,通过继承该类,可以自定义自己的事件
ApplicationEventMulticaster,通过multicastEvent方法将事件广播给所有的事件监听器
ApplicationListener事件监听器,继承该类重写其中的onApplicationEvent方法(或者直接使用@EventListener注解),完成对监听事件的处理
适配器模式
实现方式:
SpringMVC中的适配器HandlerAdatper。
实现原理:
HandlerAdatper根据Handler规则执行不同的Handler。
实现过程:
DispatcherServlet根据HandlerMapping返回的handler,向HandlerAdatper发起请求,处理Handler。
HandlerAdapter根据规则找到对应的Handler并让其执行,执行完毕后Handler会向HandlerAdapter返回一个ModelAndView,最后由HandlerAdapter向DispatchServelet返回一个ModelAndView。
适配器模式可以通过新增一个适配器让两个原本不兼容的接口一起工作。比较常见的例如MethodBeforeAdviceInterceptor,它实现了MethodInterceptor接口,并且其中有一个MethodBeforeAdvice类型实例,
在inoke方法中调用advice的before方法,将这两个接口组合在一起工作,在方法执行之前完成一些操作,
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable {
@Override
public boolean supportsAdvice(Advice advice) {
return (advice instanceof MethodBeforeAdvice);
}
@Override
public MethodInterceptor getInterceptor(Advisor advisor) {
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
return new MethodBeforeAdviceInterceptor(advice);
}
}
public class MethodBeforeAdviceInterceptor implements MethodInterceptor, Serializable {
private MethodBeforeAdvice advice;
/**
* Create a new MethodBeforeAdviceInterceptor for the given advice.
* @param advice the MethodBeforeAdvice to wrap
*/
public MethodBeforeAdviceInterceptor(MethodBeforeAdvice advice) {
Assert.notNull(advice, "Advice must not be null");
this.advice = advice;
}
@Override
public Object invoke(MethodInvocation mi) throws Throwable {
this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis() );
return mi.proceed();
}
}
装饰者模式
实现方式:
Spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。
实质:
动态地给一个对象添加一些额外的职责。
就增加功能来说,Decorator模式相比生成子类更为灵活
8. Linux 运维、Tomcat、Nginx、Docker、K8s、Kuboard
【×】8.1 Linux

Linux 系统的核心是内核。内核控制着计算机系统上的所有硬件和软件,在必要时分配硬件,并根据需要执行软件。
包括用户空间和内核空间,用户空间(User Space)又包括用户的应用程序(User Applications)、C 库(C Library) ;内核空间(Kernel Space)包括系统调用接口(System Call Interface)、内核(Kernel)、平台架构相关的代码(Architecture-Dependent Kernel Code) 。
Linux 中一切皆文件,包含普通文件、目录文件、链接文件、设备文件、命名管道;
/bin:存放二进制可执行文件(ls,cat,mkdir 等),常用命令一般都在这里;
/etc:存放系统管理和配置文件;
/home:存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
/usr:用于存放系统应用程序/opt:额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
/proc:虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
/root:超级用户(系统管理员)的主目录(特权阶级 o);
/sbin: 存放二进制可执行文件,只有 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如 ifconfig 等;
/dev:用于存放设备文件
/mnt:系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
/boot:存放用于系统引导时使用的各种文件;
/lib :存放着和系统运行相关的库文件 ;
/tmp:用于存放各种临时文件,是公用的临时文件存储点;
/var:用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
/lost+found:这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
硬链接和软连接
命令
cat vi more less head echo 标准输出查看文件,向前向后查看文件,用于查看日志文件或配置文件
mkdir touch vi 创建文件
diff 比对文件不同
cp mv 复制源文件、移动源文件或目录
rm 删除
wc 统计文件字数行数等信息并打印
uniq 去重复行
grep 查找文件,支持正则表达式查询 ps -ef | grep nginx
find 查找文件 find / -name nginx
cd pwd ls ll 切换目录、遍历当前目录下文件
chmod chown 修改文件所属用户权限组 chmod 777 nginx.conf
ps kill 查看杀死进程
gzip unzip tar 解压缩命令
du -h [目录名]:查看指定文件夹下的所有文件大小
df -hl 查看磁盘空闲信息
uptime 查看服务器负载情况
job -l 查看后台任务
ifconfig 查看ip信息
netstat 测试网络是否连通
yum wget 下载资源
lrzsz 文件上传下载
sheel
BASH 是 Bourne Again SHell 的缩写。它由 Steve Bourne 编写,作为原始 Bourne Shell(由/ bin / sh 表示)的替代品。它结合了原始版本的 Bourne Shell 的所有功能,以及其他功能,使其更容易使用。从那以后,它已被改编为运行 Linux 的大多数系统的默认 shell。
【×】8.2 Docker 容器管理
部署方便、部署安全、隔离性好、扩展性好、快速回滚、成本低;
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动速度 | 秒级 | 分钟 |
| 性能 | 接近原生 | 弱 |
| 内存占用 | 很少 | 较多 |
| 硬盘占用 | MB | GB |
| 运行密度 | 单机运行上千个容器 | 单机运行几十个虚拟机 |
| 迁移性 | 优秀 | 一般 |

Docker Image 镜像
包含了一个基本操作系统环境,相当于一个 root 文件系统;
可以从仓库中拉取指定镜像;可以根据现有容器创建镜像;可以通过 DockerFile 构建镜像
Docker Container 容器
镜像运行后的实例就是容器;
容器包含运行、已暂停、重新启动、已退出状态
Docker Repository 仓库 Docker hub、阿里云镜像仓库
集中存放镜像的地方
命令
docker pull imagename # 拉取镜像
docker images # 遍历本地镜像
docker rmi imageid # 删除镜像
docker rmi image:tagname
docker tag imageid new-repo:tagname # 镜像tag变更
docker tag local-image:tagnam new-repo:tagname
docker push new-repo:tagname # 推送镜像到仓库
docker container ls # 遍历运行中的容器
docker container ps -all # 遍历已创建的容器
docker stop containerid # 停止运行中的容器
docker start containerid # 启动运行中的容器
docker rm containerid # 删除容器
docker run 运行镜像为容器,支持指定端口
docker exec 进入容器内部
docker inspect 查看镜像信息
Docker提供docker stats和docker事件等工具来监控生产中的Docker
镜像制作
通过已有容器创建
docker commit containerid
通过 Dockerfile 制作镜像
docker build
以 ActiveMQ 为例,创建一个 Dockerfile 文件,Dockerfile作为文件名称且无后缀名;
准备文件 jetty-realm.properties 变更管理账号。然后通过 Dockerfile 制作镜像,替换 ActiveMQ 配置文件,生成的镜像运行后,管理账号就是我们配置的新账号。
jetty-realm.properties
admin: niaonao, admin
user:user, user
Dockerfile
FROM webcenter/activemq:latest # 基于镜像制作新镜像
WORKDIR /opt/activemq/conf # 当前工作路径
ENV FILE_NAME jetty-realm.properties # 设置环境变量
RUN rm -rf $FILE_NAME # 存在文件则删除,添加准备好的文件到当前工作路径
COPY ./$FILE_NAME ./
RUN chmod 644 $FILE_NAME # 修改文件权限
RUN chown activemq.activemq -R $FILE_NAME
CMD ["sh", "-c", "/app/run.sh run"]
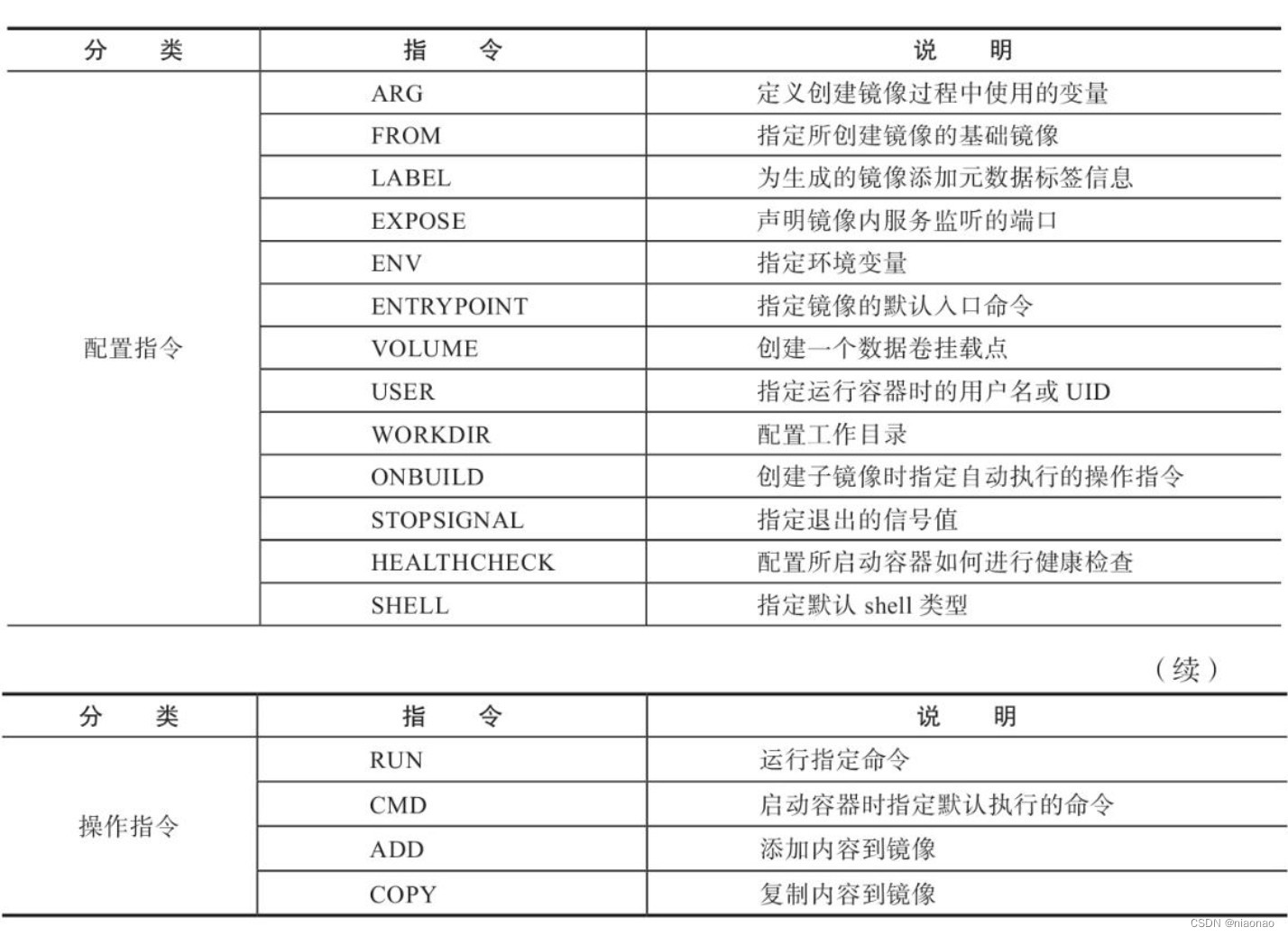
COPY 和 ADD 命令的区别
COPY 都有文件复制的功能,ADD会对压缩文件自动解压缩
【×】8.3 Kubernetes 容器编排工具
是⼀个开源容器管理⼯具,负责容器部署,容器扩缩容以及负载平衡。
K8s进行跨主机通信容器,Docker 构建运行容器,K8s编排管理容器。
容器编排是指,容器自动化部署、管理、扩容、联网;对多个容器进行编排化管理,按照编排组织部化部署应用。
9. Maven 版本管理、Git、SVN
服务监控 轮询、心跳
轮询:在轮询方式中,主机逐个查询的方式是主动向从机发送一条查询信息,等待从机应答,无应答则任务服务已挂或不存在
心跳:从机服务主动交互主机,更新在主机的心跳时间和信息。
【×】9.1 项目版本管理 Git
10. 安全规约
界面权限校验,不存在 token 返回公共请求登录页或欢迎页
防XSS攻击,表单安全校验
防SQL注入
接口访问白名单,接口授权访问
配置文件脱敏,用户数据脱敏
业务系统考虑风控,资损风控,违禁词风控等
MySQL 主从复制
分库分表
参考网上较多博客,感谢各大博主,不一一列举
ElasticSearch基本查询
ElasticSearch读写底层原理及性能调优
一致性Hash在负载均衡中的应用
seata四种模式对比
Power By niaonao, The End