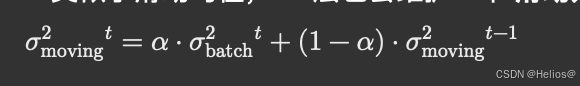在上一篇文章《推荐系统(二十一):基于MaskNet的商品推荐CTR模型实现》中,笔者基于 MaskNet 构建了一个简单的模型。笔者所经历的工业级实践证明,将 MaskNet 和 Wide&Deep 结合应用,可以取得不错的效果,本文将基于MaskNet 和 Wide&Deep 实现一个商品推荐 CTR 模型。
1.MaskNet 与 Wide&Deep 结合的推荐系统优势
MaskNet 与 Wide&Deep 结合,本质上是通过 “显式记忆+隐式泛化+动态聚焦” 三重机制,实现从数据到场景的全链路优化。适用于电商、内容平台等需平衡长期偏好与实时反馈、处理高稀疏特征的复杂推荐系统。关于两者结合的优势,可以从如下五个方面来看:
(1)结构互补,能力增强
- Wide 部分:通过线性模型(如逻辑回归)捕捉显式特征交互(如用户历史点击与商品的共现),擅长“记忆”(Memorization),解决高频、确定性特征组合的推荐问题。
- Deep 部分:通过多层神经网络学习隐式特征交互,实现“泛化”(Generalization),挖掘长尾、稀疏特征之间的潜在关联。
- MaskNet:通过自注意力(Self-Attention)或门控机制动态调整特征权重,过滤噪声并突出关键特征交互。显式建模高阶特征交互,减少人工特征工程依赖。动态特征权重调整提升模型对用户实时兴趣的捕捉能力。在实践中,可将 MaskNet 作为 Deep 网络的子模块(如替换全连接层),通过自注意力机制增强隐式特征交互的建模能力。
(2)动态与静态兴趣融合
在用户行为序列中,MaskNet 可动态放大近期点击商品的影响力(如用户临时兴趣),而 Wide 部分维持长期偏好(如用户性别、年龄相关特征)。技术实现:通过门控机制(如 Sigmoid)生成特征掩码,抑制噪声特征(如偶然点击),增强关键信号。
(3)稀疏数据与冷启动优化
Wide 侧人工交叉特征直接建模关键稀疏信号(如冷门品类偏好),MaskNet 利用注意力挖掘潜在关联(如长尾商品相似性),缓解数据稀疏性,加速冷启动收敛。
(4)高效工业落地
Wide 部分轻量级计算保障实时性,MaskNet 通过并行化设计(如 Multi-Head Attention)平衡效果与效率,适配高并发场景,支持多模态扩展(文本/图像融合)。
(5)多目标协同优化
结合 Wide&Deep 的多任务学习能力(如 CTR 与 CVR 联合预估)与 MaskNet 的灵活结构,联合建模点击率(CTR)、转化率(CVR)等任务,兼顾推荐准确性、多样性及业务指标(如 GMV),满足复杂业务需求。
2. 模型架构
如下图所示,在 Deep 部分增加了一个 MaskBlock,采用 Serial 模式。
- Deep Feature:Deep Feature 包括用户特征和商品特征,经过 Embedding Layer 并连接后维数(dimension)为 26。
- Mask Block:包含两个全连接层,输出层(V_mask)维数必须为 26,从而与 Deep Feature 的 Embedding 结果 V_emb 的维数相同,如此才能进行点积计算。
- MLP:V_mask 与 V_emb 进行点积计算后得到一个相等维数(dim=26)的加权向量 V_maskEMB。V_maskEMB 输入 MLP(输出层维数 32),输出一个32维的 Deep Vector。
- Wide Feature:Wide Feature 包括用户和商品的多个交叉特征,如 user_id_x_item_id、user_gender_x_item_category,经过 Embedding Layer 并连接后维数(dimension)为 12000,正如其名,很“Wide”。
- Linear Layer:Wide 部分的核心作用是捕捉简单的线性关系(如交叉特征、记忆效应),其输出应为一个标量值(即1维)。该标量会与 Deep 部分的输出拼接,最终通过 Sigmoid 函数生成预测概率。在提出 Wide & Deep 模型的原始论文中,Wide 部分直接使用逻辑回归,相当于Dense(1),本文的结构完全遵循了这一范式。
- Deep 部分和 Wide 部分拼接:Deep Vector(dim=32),Wide Vector(dim=1),拼接后得到一个 32+1 =33 维的向量。
- 预测输出:输出层只有一个神经元,33 维的向量加权求和得到一个 logits,经过 Sigmolid 函数得到 0~1的数值,这个数值即为 CTR Prediction。
- 损失计算:CTR Prediction 与 Label 计算交叉墒损失。

3. 模型实现
3.1 模拟数据生成
# ====================
# 1. 模拟数据生成
# ====================
def generate_mock_data(num_users=100, num_items=200, num_interactions=1000):
"""生成模拟用户、商品及交互数据"""
# 设置随机种子保证可复现性
np.random.seed(42)
tf.random.set_seed(42)
# 用户特征
user_data = {
'user_id': np.arange(1, num_users + 1),
'user_age': np.random.randint(18, 65, size=num_users),
'user_gender': np.random.choice(['male', 'female'], size=num_users),
'user_occupation': np.random.choice(['student', 'worker', 'teacher'], size=num_users),
'city_code': np.random.randint(1, 2856, size=num_users),
'device_type': np.random.randint(0, 5, size=num_users)
}
# 商品特征
item_data = {
'item_id': np.arange(1, num_items + 1),
'item_category': np.random.choice(['electronics', 'books', 'clothing'], size=num_items),
'item_brand': np.random.choice(['brandA', 'brandB', 'brandC'], size=num_items),
'item_price': np.random.randint(1, 199, size=num_items)
}
# 交互数据
interactions = []
for _ in range(num_interactions):
user_id = np.random.randint(1, num_users + 1)
item_id = np.random.randint(1, num_items + 1)
# 点击标签。0: 未点击, 1: 点击。在真实场景中可通过客户端埋点上报获得用户的点击行为数据
click_label = np.random.randint(0, 2)
interactions.append([user_id, item_id, click_label])
return user_data, item_data, interactions
# 生成数据
num_users = 100
num_items = 200
user_data, item_data, interactions = generate_mock_data(num_users, num_items, 10000)
3.2 合并、划分数据集
# ====================
# 2. 合并、划分数据集
# ====================
# 合并用户特征、商品特征和交互数据
interaction_df = pd.DataFrame(interactions, columns=['user_id', 'item_id', 'click_label'])
user_df = pd.DataFrame(user_data)
item_df = pd.DataFrame(item_data)
df = interaction_df.merge(user_df, on='user_id').merge(item_df, on='item_id')
# 划分数据集:训练集、测试集
labels = df[['click_label']]
features = df.drop(['click_label'], axis=1)
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2,
random_state=42)
3.3 特征工程
# ====================
# 3. 特征工程
#
# 本部分对原始用户数据、商品数据、用户-商品交互数据进行分类处理,加工为模型训练需要的特征
# 1.数值型特征:如用户年龄、价格,少数场景下可直接使用,但最好进行标准化,从而消除量纲差异
# 2.类别型特征:需要进行 Embedding 处理
# 3.交叉特征:由于维度高,需要哈希技巧处理高维组合特征
# ====================
"""
用户特征处理
"""
user_id = feature_column.categorical_column_with_identity('user_id', num_buckets=num_users + 1)
user_id_emb = feature_column.embedding_column(user_id, dimension=8)
scaler_age = StandardScaler()
df['user_age'] = scaler_age.fit_transform(df[['user_age']])
user_age = feature_column.numeric_column('user_age')
user_gender = feature_column.categorical_column_with_vocabulary_list('user_gender', ['male', 'female'])
user_gender_emb = feature_column.embedding_column(user_gender, dimension=2)
user_occupation = feature_column.categorical_column_with_vocabulary_list('user_occupation',
['student', 'worker', 'teacher'])
user_occupation_emb = feature_column.embedding_column(user_occupation, dimension=2)
city_code_column = feature_column.categorical_column_with_identity(key='city_code', num_buckets=2856)
city_code_emb = feature_column.embedding_column(city_code_column, dimension=8)
device_types_column = feature_column.categorical_column_with_identity(key='device_type', num_buckets=5)
device_types_emb = feature_column.embedding_column(device_types_column, dimension=8)
"""
商品特征处理
"""
item_id = feature_column.categorical_column_with_identity('item_id', num_buckets=num_items + 1)
item_id_emb = feature_column.embedding_column(item_id, dimension=8)
scaler_price = StandardScaler()
df['item_price'] = scaler_price.fit_transform(df[['item_price']])
item_price = feature_column.numeric_column('item_price')
item_category = feature_column.categorical_column_with_vocabulary_list('item_category',
['electronics', 'books', 'clothing'])
item_category_emb = feature_column.embedding_column(item_category, dimension=2)
item_brand = feature_column.categorical_column_with_vocabulary_list('item_brand', ['brandA', 'brandB', 'brandC'])
item_brand_emb = feature_column.embedding_column(item_brand, dimension=2)
"""
交叉特征预处理
"""
# 使用TensorFlow的交叉特征(crossed_column)定义了Wide部分的特征列,主要用于捕捉用户与商品特征之间的组合效应
# 将用户ID(user_id)和商品ID(item_id)组合成一个新特征,捕捉**“特定用户对特定商品的偏好”**
# 用户ID和商品ID的组合往往非常大(num_users * num_items),直接编码会导致维度爆炸,使用哈希函数将组合映射
# 到固定数量的桶(如hash_bucket_size=10,000个),可控制内存和计算开销,适用于稀疏高维特征(如用户-商品对)
# crossed_column:生成交叉特征,以 user_id 和 item_id 为例,通过哈希函数将任意组合映射到固定范围 [0, hash_bucket_size-1]
# 交叉过程:将 user_id 和 item_id 拼接为字符串,如"123_456",再计算哈希值 hash("123_456") % 10000 → 42,
# indicator_column:将哈希值转换为稀疏One-Hot向量,维度为 hash_bucket_size。比如哈希值 42 将生成一个10000维向量,第42位为1,其余为0
user_id_x_item_id = feature_column.crossed_column(
[user_id, item_id], hash_bucket_size=10000)
user_id_x_item_id = feature_column.indicator_column(user_id_x_item_id)
user_gender_x_item_category = feature_column.crossed_column(
[user_gender, item_category], hash_bucket_size=1000)
user_gender_x_item_category = feature_column.indicator_column(user_gender_x_item_category)
user_occupation_x_item_brand = feature_column.crossed_column(
[user_occupation, item_brand], hash_bucket_size=1000)
user_occupation_x_item_brand = feature_column.indicator_column(user_occupation_x_item_brand)
"""
特征列定义
"""
deep_feature_columns = [
user_id_emb,
user_age,
user_gender_emb,
user_occupation_emb,
item_id_emb,
item_category_emb,
item_brand_emb,
item_price
]
wide_feature_columns = [
user_id_x_item_id,
user_gender_x_item_category,
user_occupation_x_item_brand
]
3.4 构建 MaskWideDeep 模型
# ====================
# 4. 构建MaskWideDeep模型
# MaskNet 是一个结合动态特征加权的深度模型,适用于结构化数据的二分类任务。
# 其核心创新点是通过子网络生成样本级别的特征权重,增强了模型的特征选择能力,结构简单但有效
# ====================
class MaskWideDeep(tf.keras.Model):
"""
初始化函数中进行特征列分离:即通过deep_feature_columns和wide_feature_columns明确定义了
哪些特征属于Deep部分(嵌入特征、数值特征),哪些属于Wide部分(交叉特征)
"""
def __init__(self, deep_feature, wide_feature, hidden_units=[64, 32]):
super().__init__()
# 定义DenseFeatures层,处理特征列
# 作用:所有类型的特征列(包括数值列、分桶列、嵌入列等)必须通过DenseFeatures转换为密集张量(Dense Tensor),才能作为神经网络的输入
# 原因:
# 1-feature_column 只是定义了特征的处理逻辑(如分桶、哈希、嵌入等),并不实际执行数据转换,因此 deep_feature 和 wide_feature 并不是张量。
# 换言之,特征列(如 numeric_column, embedding_column)仅定义了如何从输入数据中提取特征,但未执行实际转换,例如 numeric_column 定义了数值特征的标准化逻辑
# 2-DenseFeatures 层的作用是将原始输入数据(字典形式)根据特征列的定义,转换为模型可用的多维密集张量
self.deep_dense_features = tf.keras.layers.DenseFeatures(deep_feature)
self.wide_dense_features = tf.keras.layers.DenseFeatures(wide_feature)
# Wide部分(线性模型)
self.linear = tf.keras.layers.Dense(1, activation=None)
# Deep部分
# MaskBlock组件
# mask_block 的输出维度需严格匹配特征列处理后的维度(如 26),否则矩阵相乘会失败
self.mask_block = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
# 这一层的输出维数必须与 deep_feature 的维数相同,否则动态加权计算时(mask*feature_emb)会报错
# Sigmoid 激活确保权重在[0, 1] 之间,实现特征重要性软选择。类似注意力机制,抑制不重要特征,增强关键特征
tf.keras.layers.Dense(26, activation='sigmoid') # 生成动态权重
])
# 深度网络:由多个全连接层组成,默认结构为 [64, 32],激活函数为 ReLU
# 作用:对加权后的特征进行高阶非线性组合学习
self.dnn = tf.keras.Sequential([
tf.keras.layers.Dense(unit, activation='relu')
for unit in hidden_units
])
# 输出层:单个神经元,Sigmoid 激活,适用于二分类任务,输出概率值
self.output_layer = tf.keras.layers.Dense(1, activation='sigmoid')
# 单一输入参数:inputs 参数是一个字典,包含所有原始特征(如user_id、user_age等)。
# 特征自动筛选:每个 DenseFeatures 层会根据绑定的特征列定义,从inputs中提取对应的特征并处理
# 例如,wide_dense_features 会提取 user_id_x_item_id 等交叉特征,而忽略其他特征
def call(self, inputs):
# wide 部分,与普通Wide&Deep模型相同
wide_in = self.wide_dense_features(inputs)
wide_out = self.linear(wide_in)
# 特征嵌入:输入数据转换为密集张量 x
# 输入层:使用 DenseFeatures 处理结构化数据的特征列(feature_columns),将原始特征(如数值型、分类型)转换为密集张量
deep_in = self.deep_dense_features(inputs)
# 动态加权:mask_block 生成掩码 mask,与 deep_in 逐元素相乘(deep_in * mask),实现特征动态选择
mask = self.mask_block(deep_in)
deep_in = tf.keras.layers.multiply([deep_in, mask]) # 特征动态加权
# 特征学习:加权后的特征输入 dnn 进行深度特征提取
deep_out = self.dnn(deep_in)
# Wide部分的线性层和Deep部分的DNN层独立训练,通过concatenate([wide_out, deep_out])实现联合预测
# 预测输出:最终通过 Sigmoid 输出概率
combined = tf.keras.layers.concatenate([wide_out, deep_out])
return self.output_layer(combined)
3.5 模型训练、评估、保存
# ====================
# 5. 模型训练、评估、保存
# ====================
# 创建输入函数
def df_to_dataset(features, labels, shuffle=True, batch_size=32):
ds = tf.data.Dataset.from_tensor_slices((
dict(features),
{
'output_1': labels['click_label']}
))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size)
return ds
# 转换数据集
train_ds = df_to_dataset(train_features, train_labels)
test_ds = df_to_dataset(test_features, test_labels, shuffle=False)
# 初始化模型
model = MaskWideDeep(deep_feature_columns, wide_feature_columns)
# 编译
# loss='binary_crossentropy':使用二元交叉熵损失函数,因为 CTR 预估这是一个二分类问题
# metrics=['AUC', 'accuracy']:在训练和评估时跟踪两个指标
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC', 'accuracy'])
# 训练
history = model.fit(train_ds,
validation_data=test_ds,
epochs=10,
verbose=1)
# 评估
test_loss, test_auc, test_acc = model.evaluate(test_ds)
print(f"\n测试集评估结果:AUC={test_auc:.3f}, 准确率={test_acc:.3f}")
# 示例:绘制训练曲线
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.plot(history.history['loss'], label='Loss')
plt.legend()
plt.show()
# ====================
# 6. 模型保存
# ====================
model.save('masknet_recommender')
print("模型已保存到 masknet_recommender 目录")
3.6 完整代码
import tensorflow as tf
# MAC M1 芯片不支持部分命令,因此禁用GPU设备
tf.config.set_visible_devices([], 'GPU') # 禁用GPU设备
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow import feature_column
# ====================
# 1. 模拟数据生成
# ====================
def generate_mock_data(num_users=100, num_items=200, num_interactions=1000):
"""生成模拟用户、商品及交互数据"""
# 设置随机种子保证可复现性
np.random.seed(42)
tf.random.set_seed(42)
# 用户特征
user_data = {
'user_id': np.arange(1, num_users + 1),
'user_age': np.random.randint(18, 65, size=num_users),
'user_gender': np.random.choice(['male', 'female'], size=num_users),
'user_occupation': np.random.choice(['student', 'worker', 'teacher'], size=num_users),
'city_code': np.random.randint(1, 2856, size=num_users),
'device_type': np.random.randint(0, 5, size=num_users)
}
# 商品特征
item_data = {
'item_id': np.arange(1, num_items + 1),
'item_category': np.random.choice(['electronics', 'books', 'clothing'], size=num_items),
'item_brand': np.random.choice(['brandA', 'brandB', 'brandC'], size=num_items),
'item_price': np.random.randint(1, 199, size=num_items)
}
# 交互数据
interactions = []
for _ in range(num_interactions):
user_id = np.random.randint(1, num_users + 1)
item_id = np.random.randint(1, num_items + 1)
# 点击标签。0: 未点击, 1: 点击。在真实场景中可通过客户端埋点上报获得用户的点击行为数据
click_label = np.random.randint(0, 2)
interactions.append([user_id, item_id, click_label])
return user_data, item_data, interactions
# 生成数据
num_users = 100
num_items = 200
user_data, item_data, interactions = generate_mock_data(num_users, num_items, 10000)
# ====================
# 2. 合并、划分数据集
# ====================
# 合并用户特征、商品特征和交互数据
interaction_df = pd.DataFrame(interactions, columns=['user_id', 'item_id', 'click_label'])
user_df = pd.DataFrame(user_data)
item_df = pd.DataFrame(item_data)
df = interaction_df.merge(user_df, on='user_id').merge(item_df, on='item_id')
# 划分数据集:训练集、测试集
labels = df[['click_label']]
features = df.drop(['click_label'], axis=1)
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2,
random_state=42)
# ====================
# 3. 特征工程
#
# 本部分对原始用户数据、商品数据、用户-商品交互数据进行分类处理,加工为模型训练需要的特征
# 1.数值型特征:如用户年龄、价格,少数场景下可直接使用,但最好进行标准化,从而消除量纲差异
# 2.类别型特征:需要进行 Embedding 处理
# 3.交叉特征:由于维度高,需要哈希技巧处理高维组合特征
# ====================
"""
用户特征处理
"""
user_id = feature_column.categorical_column_with_identity('user_id', num_buckets=num_users + 1)
user_id_emb = feature_column.embedding_column(user_id, dimension=8)
scaler_age = StandardScaler()
df['user_age'] = scaler_age.fit_transform(df[['user_age']])
user_age = feature_column.numeric_column('user_age')
user_gender = feature_column.categorical_column_with_vocabulary_list('user_gender', ['male', 'female'])
user_gender_emb = feature_column.embedding_column(user_gender, dimension=2)
user_occupation = feature_column.categorical_column_with_vocabulary_list('user_occupation',
['student', 'worker', 'teacher'])
user_occupation_emb = feature_column.embedding_column(user_occupation, dimension=2)
city_code_column = feature_column.categorical_column_with_identity(key='city_code', num_buckets=2856)
city_code_emb = feature_column.embedding_column(city_code_column, dimension=8)
device_types_column = feature_column.categorical_column_with_identity(key='device_type', num_buckets=5)
device_types_emb = feature_column.embedding_column(device_types_column, dimension=8)
"""
商品特征处理
"""
item_id = feature_column.categorical_column_with_identity('item_id', num_buckets=num_items + 1)
item_id_emb = feature_column.embedding_column(item_id, dimension=8)
scaler_price = StandardScaler()
df['item_price'] = scaler_price.fit_transform(df[['item_price']])
item_price = feature_column.numeric_column('item_price')
item_category = feature_column.categorical_column_with_vocabulary_list('item_category',
['electronics', 'books', 'clothing'])
item_category_emb = feature_column.embedding_column(item_category, dimension=2)
item_brand = feature_column.categorical_column_with_vocabulary_list('item_brand', ['brandA', 'brandB', 'brandC'])
item_brand_emb = feature_column.embedding_column(item_brand, dimension=2)
"""
交叉特征预处理
"""
# 使用TensorFlow的交叉特征(crossed_column)定义了Wide部分的特征列,主要用于捕捉用户与商品特征之间的组合效应
# 将用户ID(user_id)和商品ID(item_id)组合成一个新特征,捕捉**“特定用户对特定商品的偏好”**
# 用户ID和商品ID的组合往往非常大(num_users * num_items),直接编码会导致维度爆炸,使用哈希函数将组合映射
# 到固定数量的桶(如hash_bucket_size=10,000个),可控制内存和计算开销,适用于稀疏高维特征(如用户-商品对)
# crossed_column:生成交叉特征,以 user_id 和 item_id 为例,通过哈希函数将任意组合映射到固定范围 [0, hash_bucket_size-1]
# 交叉过程:将 user_id 和 item_id 拼接为字符串,如"123_456",再计算哈希值 hash("123_456") % 10000 → 42,
# indicator_column:将哈希值转换为稀疏One-Hot向量,维度为 hash_bucket_size。比如哈希值 42 将生成一个10000维向量,第42位为1,其余为0
user_id_x_item_id = feature_column.crossed_column(
[user_id, item_id], hash_bucket_size=10000)
user_id_x_item_id = feature_column.indicator_column(user_id_x_item_id)
user_gender_x_item_category = feature_column.crossed_column(
[user_gender, item_category], hash_bucket_size=1000)
user_gender_x_item_category = feature_column.indicator_column(user_gender_x_item_category)
user_occupation_x_item_brand = feature_column.crossed_column(
[user_occupation, item_brand], hash_bucket_size=1000)
user_occupation_x_item_brand = feature_column.indicator_column(user_occupation_x_item_brand)
"""
特征列定义
"""
deep_feature_columns = [
user_id_emb,
user_age,
user_gender_emb,
user_occupation_emb,
item_id_emb,
item_category_emb,
item_brand_emb,
item_price
]
wide_feature_columns = [
user_id_x_item_id,
user_gender_x_item_category,
user_occupation_x_item_brand
]
# ====================
# 4. 构建MaskWideDeep模型
# MaskNet 是一个结合动态特征加权的深度模型,适用于结构化数据的二分类任务。
# 其核心创新点是通过子网络生成样本级别的特征权重,增强了模型的特征选择能力,结构简单但有效
# ====================
class MaskWideDeep(tf.keras.Model):
"""
初始化函数中进行特征列分离:即通过deep_feature_columns和wide_feature_columns明确定义了
哪些特征属于Deep部分(嵌入特征、数值特征),哪些属于Wide部分(交叉特征)
"""
def __init__(self, deep_feature, wide_feature, hidden_units=[64, 32]):
super().__init__()
# 定义DenseFeatures层,处理特征列
# 作用:所有类型的特征列(包括数值列、分桶列、嵌入列等)必须通过DenseFeatures转换为密集张量(Dense Tensor),才能作为神经网络的输入
# 原因:
# 1-feature_column 只是定义了特征的处理逻辑(如分桶、哈希、嵌入等),并不实际执行数据转换,因此 deep_feature 和 wide_feature 并不是张量。
# 换言之,特征列(如 numeric_column, embedding_column)仅定义了如何从输入数据中提取特征,但未执行实际转换,例如 numeric_column 定义了数值特征的标准化逻辑
# 2-DenseFeatures 层的作用是将原始输入数据(字典形式)根据特征列的定义,转换为模型可用的多维密集张量
self.deep_dense_features = tf.keras.layers.DenseFeatures(deep_feature)
self.wide_dense_features = tf.keras.layers.DenseFeatures(wide_feature)
# Wide部分(线性模型)
self.linear = tf.keras.layers.Dense(1, activation=None)
# Deep部分
# MaskBlock组件
# mask_block 的输出维度需严格匹配特征列处理后的维度(如 26),否则矩阵相乘会失败
self.mask_block = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
# 这一层的输出维数必须与 deep_feature 的维数相同,否则动态加权计算时(mask*feature_emb)会报错
# Sigmoid 激活确保权重在[0, 1] 之间,实现特征重要性软选择。类似注意力机制,抑制不重要特征,增强关键特征
tf.keras.layers.Dense(26, activation='sigmoid') # 生成动态权重
])
# 深度网络:由多个全连接层组成,默认结构为 [64, 32],激活函数为 ReLU
# 作用:对加权后的特征进行高阶非线性组合学习
self.dnn = tf.keras.Sequential([
tf.keras.layers.Dense(unit, activation='relu')
for unit in hidden_units
])
# 输出层:单个神经元,Sigmoid 激活,适用于二分类任务,输出概率值
self.output_layer = tf.keras.layers.Dense(1, activation='sigmoid')
# 单一输入参数:inputs 参数是一个字典,包含所有原始特征(如user_id、user_age等)。
# 特征自动筛选:每个 DenseFeatures 层会根据绑定的特征列定义,从inputs中提取对应的特征并处理
# 例如,wide_dense_features 会提取 user_id_x_item_id 等交叉特征,而忽略其他特征
def call(self, inputs):
# wide 部分,与普通Wide&Deep模型相同
wide_in = self.wide_dense_features(inputs)
wide_out = self.linear(wide_in)
# 特征嵌入:输入数据转换为密集张量 x
# 输入层:使用 DenseFeatures 处理结构化数据的特征列(feature_columns),将原始特征(如数值型、分类型)转换为密集张量
deep_in = self.deep_dense_features(inputs)
# 动态加权:mask_block 生成掩码 mask,与 deep_in 逐元素相乘(deep_in * mask),实现特征动态选择
mask = self.mask_block(deep_in)
deep_in = tf.keras.layers.multiply([deep_in, mask]) # 特征动态加权
# 特征学习:加权后的特征输入 dnn 进行深度特征提取
deep_out = self.dnn(deep_in)
# Wide部分的线性层和Deep部分的DNN层独立训练,通过concatenate([wide_out, deep_out])实现联合预测
# 预测输出:最终通过 Sigmoid 输出概率
combined = tf.keras.layers.concatenate([wide_out, deep_out])
return self.output_layer(combined)
# ====================
# 5. 模型训练与评估
# ====================
# 创建输入函数
def df_to_dataset(features, labels, shuffle=True, batch_size=32):
ds = tf.data.Dataset.from_tensor_slices((
dict(features),
{
'output_1': labels['click_label']}
))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size)
return ds
# 转换数据集
train_ds = df_to_dataset(train_features, train_labels)
test_ds = df_to_dataset(test_features, test_labels, shuffle=False)
# 初始化模型
model = MaskWideDeep(deep_feature_columns, wide_feature_columns)
# 编译
# loss='binary_crossentropy':使用二元交叉熵损失函数,因为 CTR 预估这是一个二分类问题
# metrics=['AUC', 'accuracy']:在训练和评估时跟踪两个指标
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC', 'accuracy'])
# 训练
history = model.fit(train_ds,
validation_data=test_ds,
epochs=10,
verbose=1)
# 评估
test_loss, test_auc, test_acc = model.evaluate(test_ds)
print(f"\n测试集评估结果:AUC={test_auc:.3f}, 准确率={test_acc:.3f}")
# 示例:绘制训练曲线
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.plot(history.history['loss'], label='Loss')
plt.legend()
plt.show()
# ====================
# 5. 模型保存
# ====================
model.save('masknet_recommender')
print("模型已保存到 masknet_recommender 目录")
4.运行结果示例
Epoch 1/10
2025-04-05 21:36:42.640541: W tensorflow/tsl/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
250/250 [==============================] - 2s 3ms/step - loss: 0.7177 - auc: 0.4979 - accuracy: 0.4983 - val_loss: 0.6931 - val_auc: 0.5112 - val_accuracy: 0.5035
Epoch 2/10
250/250 [==============================] - 0s 2ms/step - loss: 0.6905 - auc: 0.5549 - accuracy: 0.5414 - val_loss: 0.6929 - val_auc: 0.5099 - val_accuracy: 0.5100
Epoch 3/10
250/250 [==============================] - 0s 2ms/step - loss: 0.6825 - auc: 0.6307 - accuracy: 0.5932 - val_loss: 0.6937 - val_auc: 0.5159 - val_accuracy: 0.5115
Epoch 4/10
250/250 [==============================] - 0s 2ms/step - loss: 0.6683 - auc: 0.7068 - accuracy: 0.6495 - val_loss: 0.6948 - val_auc: 0.5138 - val_accuracy: 0.5005
Epoch 5/10
250/250 [==============================] - 0s 2ms/step - loss: 0.6474 - auc: 0.7747 - accuracy: 0.7067 - val_loss: 0.6967 - val_auc: 0.5169 - val_accuracy: 0.5105
Epoch 6/10
250/250 [==============================] - 0s 2ms/step - loss: 0.6224 - auc: 0.8206 - accuracy: 0.7418 - val_loss: 0.7007 - val_auc: 0.5154 - val_accuracy: 0.5075
Epoch 7/10
250/250 [==============================] - 0s 2ms/step - loss: 0.5953 - auc: 0.8496 - accuracy: 0.7726 - val_loss: 0.7066 - val_auc: 0.5169 - val_accuracy: 0.5075
Epoch 8/10
250/250 [==============================] - 0s 2ms/step - loss: 0.5666 - auc: 0.8707 - accuracy: 0.7901 - val_loss: 0.7144 - val_auc: 0.5151 - val_accuracy: 0.5090
Epoch 9/10
250/250 [==============================] - 0s 2ms/step - loss: 0.5376 - auc: 0.8891 - accuracy: 0.8030 - val_loss: 0.7247 - val_auc: 0.5164 - val_accuracy: 0.5085
Epoch 10/10
250/250 [==============================] - 0s 2ms/step - loss: 0.5103 - auc: 0.9007 - accuracy: 0.8167 - val_loss: 0.7351 - val_auc: 0.5189 - val_accuracy: 0.5205
63/63 [==============================] - 0s 972us/step - loss: 0.7351 - auc: 0.5189 - accuracy: 0.5205
测试集评估结果:AUC=0.519, 准确率=0.521
模型已保存到 masknet_recommender 目录
4.1 训练过程可视化
由于是随机生成的数据,训练 Accuracy 虽然随着训练的进行提高,但是验证 Accuracy 却未明显升高。

4.2 在其他工程调用模型
# 导入必要的库
import tensorflow as tf
import pandas as pd
import numpy as np
# 人工构造数据
num_users = 100
num_items = 200
# 重新生成新的样本,模拟真实数据进行预测
def generate_new_samples(num_samples=5):
new_samples = []
for _ in range(num_samples):
user_id = np.random.randint(1, num_users + 1)
item_id = np.random.randint(1, num_items + 1)
user_age = np.random.randint(18, 65)
user_gender = np.random.choice(['male', 'female'])
user_occupation = np.random.choice(['student', 'worker', 'teacher'])
city_code = np.random.randint(1, 2856)
device_type = np.random.randint(0, 5)
item_category = np.random.choice(['electronics', 'books', 'clothing'])
item_brand = np.random.choice(['brandA', 'brandB', 'brandC'])
item_price = np.random.randint(1, 199)
new_samples.append({
'user_id': user_id,
'user_age': user_age,
'user_gender': user_gender,
'user_occupation': user_occupation,
'city_code': city_code,
'device_type': device_type,
'item_id': item_id,
'item_category': item_category,
'item_brand': item_brand,
'item_price': item_price
})
return pd.DataFrame(new_samples)
# 生成新的样本数据并预览
new_samples = generate_new_samples(num_samples=5)
# 设置display.max_columns为None,强制显示全部列:
pd.set_option('display.max_columns', None)
print("\nGenerated New Samples:\n", new_samples)
test_sample = {
'user_id': tf.convert_to_tensor(new_samples['user_id'].values, dtype=tf.int64),
'user_age': tf.convert_to_tensor(new_samples['user_age'].values, dtype=tf.int64),
'user_gender': tf.convert_to_tensor(new_samples['user_gender'].values, dtype=tf.string),
'user_occupation': tf.convert_to_tensor(new_samples['user_occupation'].values, dtype=tf.string),
'city_code': tf.convert_to_tensor(new_samples['city_code'].values, dtype=tf.int64),
'device_type': tf.convert_to_tensor(new_samples['device_type'].values, dtype=tf.int64),
'item_id': tf.convert_to_tensor(new_samples['item_id'].values, dtype=tf.int64),
'item_category': tf.convert_to_tensor(new_samples['item_category'].values, dtype=tf.string),
'item_brand': tf.convert_to_tensor(new_samples['item_brand'].values, dtype=tf.string),
'item_price': tf.convert_to_tensor(new_samples['item_price'].values, dtype=tf.int64)
}
# 从目录加载模型
best_model = tf.keras.models.load_model('masknet_recommender')
# 明确使用默认签名
predict_fn = best_model.signatures['serving_default']
# 进行预测
prediction = predict_fn(**test_sample)
# 提取并打印预测结果
predicted_ctr = prediction['output_1'].numpy().flatten()
new_samples['ctr_prob'] = predicted_ctr
print("\nPrediction Results:")
for idx, row in new_samples.iterrows():
print(f"Item ID: {row['item_id']} | CTR Score: {row['ctr_prob']:.4f}")
运行结果示例:
Generated New Samples:
user_id user_age user_gender user_occupation city_code device_type \
0 91 49 female student 2223 4
1 61 38 female worker 103 3
2 93 52 female worker 921 0
3 31 47 male teacher 1482 3
4 47 32 female student 1582 1
item_id item_category item_brand item_price
0 151 clothing brandA 189
1 14 electronics brandB 8
2 107 clothing brandB 81
3 12 books brandC 164
4 69 electronics brandC 39
Metal device set to: Apple M1 Pro
systemMemory: 16.00 GB
maxCacheSize: 5.33 GB
2025-04-05 21:42:49.803612: W tensorflow/tsl/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
Prediction Results:
Item ID: 151 | CTR Score: 0.5109
Item ID: 14 | CTR Score: 0.5160
Item ID: 107 | CTR Score: 0.5195
Item ID: 12 | CTR Score: 0.4289
Item ID: 69 | CTR Score: 0.5206