查询规划
- 查询规划
- 总体处理流程
- pg_plan_queries函数
- standard_planner函数
- subquery_planner函数
- inheritance_planner函数
- grouping_planner函数
- 总结
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书
查询规划
在先前,我们分别学习了查询分析和查询重写,接下来我们将学习查询规划。查询规划、查询分析和查询重写是数据库系统中处理查询语句的三个关键阶段,它们之间存在紧密的关系:
查询规划是数据库管理系统中的关键步骤之一,它涉及将用户提交的查询语句转换为可执行的执行计划。查询规划的目标是找到最优的执行计划,以在数据库中高效地执行查询操作。该过程包括查询优化、索引选择、连接顺序、访问方法等决策,以及生成最终的查询执行计划,以便在数据库系统中执行查询并返回结果。
查询规划、查询分析和查询重写是数据库系统中处理查询语句的三个关键阶段,它们之间存在紧密的关系:
- 查询分析:在查询分析阶段,数据库系统将接收到的原始查询语句进行解析和语法分析,生成对应的抽象语法树或查询树。这个过程包括语法验证、语义验证、语句解析等,以确保查询语句的合法性和正确性。
- 查询重写:在查询重写阶段,数据库系统根据查询规则(如视图、规则、触发器等)对查询树进行重写和转换,以便将用户提交的查询转换为等价但更高效的查询形式。这个过程可能会应用优化规则、替换视图、应用规则和触发器等。
- 查询规划:在查询规划阶段,数据库系统根据重写后的查询树和数据库的统计信息,通过选择合适的访问路径、连接顺序、索引使用等策略,生成最终的查询执行计划。查询规划的目标是找到最优的执行计划,以在数据库中高效地执行查询操作。
总结一下:查询分析阶段负责将原始查询转换为查询树,查询重写阶段负责将查询树进行转换和优化,而查询规划阶段负责在优化后的查询树基础上生成最终的查询执行计划。这三个阶段相互配合,共同完成数据库查询的处理过程。
总体处理流程
查询规划的最终目的是得到可被执行器执行的最优计划,整个过程可分为预处理、生成路径和生成计划三个阶段,具体如下:
- 预处理阶段:
- 语义分析:在预处理阶段,数据库系统会对查询进行语义分析,检查查询是否符合语义规范,并确保查询中的表、列名等对象都是有效的和存在的。
- 查询重写:数据库系统可能会在预处理阶段应用一些查询重写规则,例如视图展开、规则应用等,将用户提交的查询转换为等价的查询形式,以便更好地进行优化。
- 生成路径阶段:
- 选择访问路径:数据库系统根据查询涉及的表、索引和统计信息,选择合适的访问路径,如全表扫描、索引扫描、索引范围扫描等,以尽可能减少数据的访问量。
- 连接顺序:如果查询涉及多个表的连接操作,数据库系统需要决定这些表之间的连接顺序,以便在连接操作中尽早过滤不必要的数据。
- 排序和聚合:如果查询需要排序或聚合操作,数据库系统会决定如何执行这些操作,选择合适的算法和排序策略。
- 生成计划阶段:
- 物理运算:在这个阶段,数据库系统会将逻辑查询计划转换为物理查询计划,选择实际的执行算法和数据访问方法,包括选择具体的操作算子,如Join、Sort、Aggregate等。
- 执行计划评估:数据库系统会对生成的物理查询计划进行成本估算,评估每个操作的执行成本,包括访问数据的成本、排序成本、聚合成本等,以及各种操作的代价。
- 选择最优计划:根据成本估算,数据库系统会选择最优的物理查询计划作为最终的执行计划,并将该计划传递给执行器执行。
整个查询规划过程涉及对查询的结构进行转换、优化和评估,以找到最佳的执行计划,从而在数据库系统中高效地执行查询操作。通过预处理、生成路径和生成计划三个阶段的组合,数据库系统能够充分利用查询的结构信息和统计信息,实现查询的优化和高效执行。
来看看书上是怎么说的吧

查询分析工作完成之后,其最终产物—查询树链表将被移交给查询规划模块,该模块的入口函数是pg _plan_queries,它负责将查询树链表变成执行计划链表。pg_plan_queries 只会处理非Utility命令,它调用pg_plan_query对每一个查询树进行处理,并将生成的 PlannedStmt结构体(数据结构5.12)构成一个链表(执行计划链表)返回。pg_plan_query中负责实际计划生成的是planner函数,我们通常认为从planner函数开始就进入了执行计划的生成阶段。
pg_plan_queries函数
pg_plan_queries函数源码如下:(路径:src/backend/tcop/postgres.c)
/*
* Generate plans for a list of already-rewritten queries.
*
* For normal optimizable statements, invoke the planner. For utility
* statements, just make a wrapper PlannedStmt node.
*
* The result is a list of PlannedStmt nodes.
*/
List *
pg_plan_queries(List *querytrees, int cursorOptions, ParamListInfo boundParams)
{
List *stmt_list = NIL;
ListCell *query_list;
// 对于每个已经重写的查询树进行查询规划
foreach(query_list, querytrees)
{
Query *query = lfirst_node(Query, query_list);
PlannedStmt *stmt;
// 如果是UTILITY命令,无需进行规划,直接创建一个PlannedStmt节点包装它
if (query->commandType == CMD_UTILITY)
{
stmt = makeNode(PlannedStmt);
stmt->commandType = CMD_UTILITY;
stmt->canSetTag = query->canSetTag;
stmt->utilityStmt = query->utilityStmt;
stmt->stmt_location = query->stmt_location;
stmt->stmt_len = query->stmt_len;
}
else
{
// 对于普通查询,调用pg_plan_query函数执行查询规划
stmt = pg_plan_query(query, cursorOptions, boundParams);
}
// 将生成的PlannedStmt节点添加到结果列表中
stmt_list = lappend(stmt_list, stmt);
}
// 返回已规划的查询计划列表
return stmt_list;
}
pg_plan_query函数的源码如下(路径:src/backend/tcop/postgres.c)
/*
* Generate a plan for a single already-rewritten query.
* This is a thin wrapper around planner() and takes the same parameters.
*/
PlannedStmt *
pg_plan_query(Query *querytree, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt *plan;
/* Utility commands have no plans. */
if (querytree->commandType == CMD_UTILITY)
return NULL;
/* Planner must have a snapshot in case it calls user-defined functions. */
Assert(ActiveSnapshotSet());
TRACE_POSTGRESQL_QUERY_PLAN_START();
if (log_planner_stats)
ResetUsage();
/* call the optimizer */
plan = planner(querytree, cursorOptions, boundParams);
if (log_planner_stats)
ShowUsage("PLANNER STATISTICS");
#ifdef COPY_PARSE_PLAN_TREES
/* Optional debugging check: pass plan output through copyObject() */
{
PlannedStmt *new_plan = copyObject(plan);
/*
* equal() currently does not have routines to compare Plan nodes, so
* don't try to test equality here. Perhaps fix someday?
*/
#ifdef NOT_USED
/* This checks both copyObject() and the equal() routines... */
if (!equal(new_plan, plan))
elog(WARNING, "copyObject() failed to produce an equal plan tree");
else
#endif
plan = new_plan;
}
#endif
/*
* Print plan if debugging.
*/
if (Debug_print_plan)
elog_node_display(LOG, "plan", plan, Debug_pretty_print);
TRACE_POSTGRESQL_QUERY_PLAN_DONE();
return plan;
}
planner 函数的源码如下:(路径:src/backend/optimizer/plan/planner.c)
/*
* planner - 生成查询的执行计划
*
* 参数:
* parse:经过解析和重写后的查询树。
* cursorOptions:游标选项。
* boundParams:参数列表信息。
*
* 返回值:
* 返回生成的执行计划 PlannedStmt。
*/
PlannedStmt *
planner(Query *parse, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt *result;
// 检查是否设置了planner_hook,如果设置了,则调用该钩子函数
if (planner_hook)
result = (*planner_hook)(parse, cursorOptions, boundParams);
else
// 如果没有设置planner_hook,则调用标准的规划器函数standard_planner
result = standard_planner(parse, cursorOptions, boundParams);
return result;
}
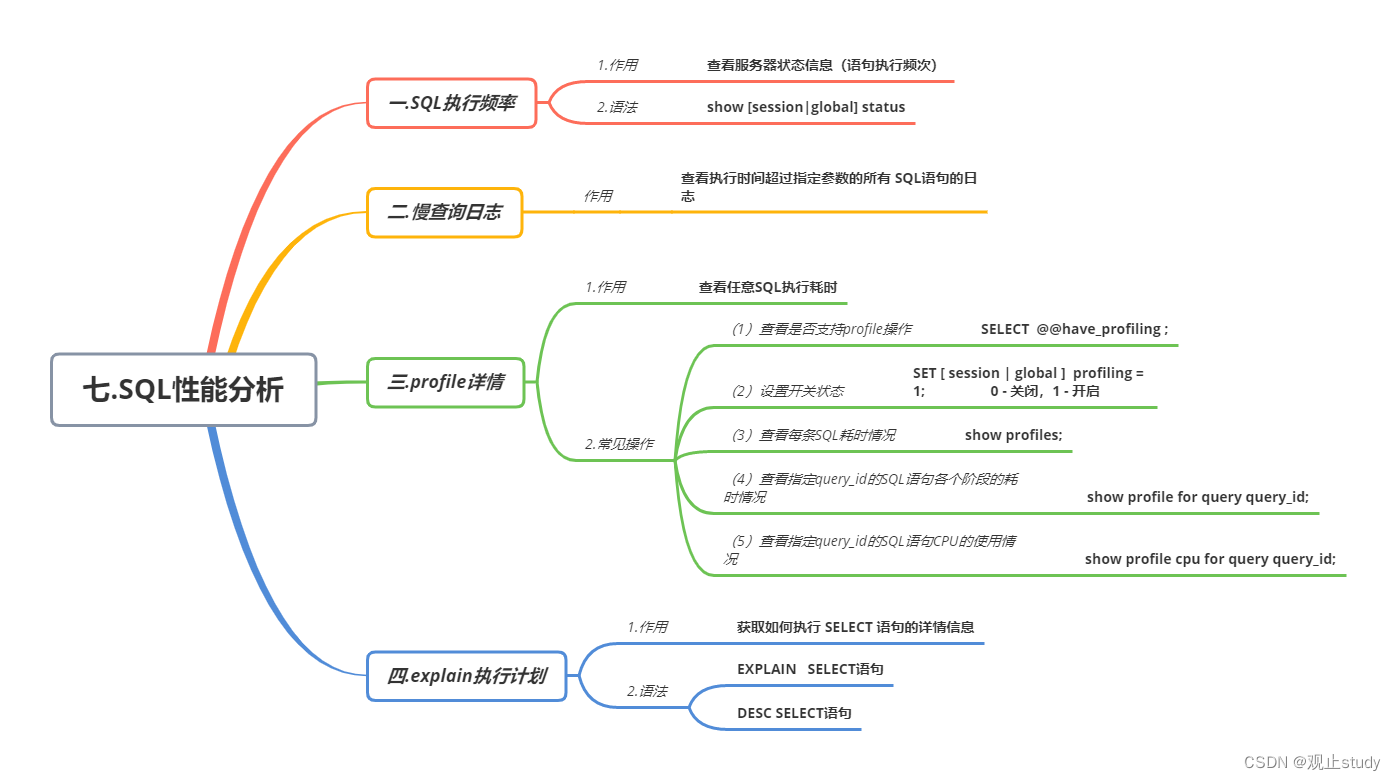
planner函数的处理流程和函数调用关系如图5-22所示。
planner函数会调用函数standard_planner 进入标准的查询规划处理。函数standard_planner接收Query查询树及外部传递的参数信息,返回PlannedStmt结构体,该结构体包含执行器执行该查询所需要的全部信息,包括计划树Plan、子计划树SubPlan 和执行所需的参数信息。standard_planner通过调用函数subquery_planner和 set_plan_references分别完成计划树的生成、优化与清理工作。
PlannedStmt结构体如下所示:
typedef struct PlannedStmt
{
NodeTag type;
CmdType commandType; /* select|insert|update|delete|utility */
uint32 queryId; /* query identifier (copied from Query) */
bool hasReturning; /* is it insert|update|delete RETURNING? */
bool hasModifyingCTE; /* has insert|update|delete in WITH? */
bool canSetTag; /* do I set the command result tag? */
bool transientPlan; /* redo plan when TransactionXmin changes? */
bool dependsOnRole; /* is plan specific to current role? */
bool parallelModeNeeded; /* parallel mode required to execute? */
struct Plan *planTree; /* tree of Plan nodes */
List *rtable; /* list of RangeTblEntry nodes */
/* rtable indexes of target relations for INSERT/UPDATE/DELETE */
List *resultRelations; /* integer list of RT indexes, or NIL */
/*
* rtable indexes of non-leaf target relations for UPDATE/DELETE on all
* the partitioned tables mentioned in the query.
*/
List *nonleafResultRelations;
/*
* rtable indexes of root target relations for UPDATE/DELETE; this list
* maintains a subset of the RT indexes in nonleafResultRelations,
* indicating the roots of the respective partition hierarchies.
*/
List *rootResultRelations;
List *subplans; /* Plan trees for SubPlan expressions; note
* that some could be NULL */
Bitmapset *rewindPlanIDs; /* indices of subplans that require REWIND */
List *rowMarks; /* a list of PlanRowMark's */
List *relationOids; /* OIDs of relations the plan depends on */
List *invalItems; /* other dependencies, as PlanInvalItems */
int nParamExec; /* number of PARAM_EXEC Params used */
Node *utilityStmt; /* non-null if this is utility stmt */
/* statement location in source string (copied from Query) */
int stmt_location; /* start location, or -1 if unknown */
int stmt_len; /* length in bytes; 0 means "rest of string" */
} PlannedStmt;

下面对查询规划处理总体控制的几个函数进行介绍。
standard_planner函数
函数subquery_planner接收Query查询树,返回Plan (计划树),该计划树被包装在PlannedStmt中。对含有子查询的情况,可通过递归调用为子查询生成相应的子计划并链接到上层计划。该函数主要调用相关预处理函数,依据消除冗余条件、减少递归层数、简化路径生成等原则对Query查询树进行预处理。

standard_planner的返回值是一个PlannerStmt结构,其中包含执行器执行计划时的全部信息,含了计划树(Plan)、子计划树和相关参数信息。该函数有三个参数:
- parse:一个Query结构,表示需要处理的查询树。
- cursorOption:整型,表示游标选项,在处理与游标操作时用到。
- ParamListInfo 结构,记录了所用到的参数信息。
subquery_planner函数的处理流程如下所示:
- 创建子查询的PlannerInfo结构体
首先,subquery_planner 函数会为子查询创建一个独立的 PlannerInfo 结构体,用于存储子查询的上下文信息。然后,将子查询的解析树、全局规划器状态和其他相关参数设置到新创建的 PlannerInfo 结构体中。
- 预处理子查询
在这一步中,会进行一些预处理工作,包括处理子查询的 WITH 子句(如果有)、解析子查询的 HAVING 子句、设置查询的目标列表和 HAVING 子句中的聚合表达式。- 初始查询优化
接下来,会调用 query_planner 函数对子查询进行初步的查询优化,生成子查询的初始查询计划。这一步骤主要是生成子查询的初始关系路径,并计算子查询中各个表达式的初始运行成本。- 处理子查询的 FROM 子句
在这一步中,会调用 query_planner 函数对子查询的 FROM 子句进行处理,包括展开子查询中的 LATERAL 关键字,生成子查询的初始关系路径,并计算子查询中各个表达式的初始运行成本。- 处理子查询的 WHERE 子句
这一步是处理子查询的 WHERE 子句,包括对子查询中的 JOIN 条件和其他过滤条件进行处理,生成子查询的初始关系路径,并计算子查询中各个表达式的初始运行成本。- 处理子查询的 GROUP BY 子句和 HAVING 子句
在这一步中,会处理子查询中的 GROUP BY 子句和 HAVING 子句,生成子查询的初始关系路径,并计算子查询中各个表达式的初始运行成本。- 处理子查询的投影列表
接下来,会处理子查询的投影列表,包括对子查询中的 SELECT 子句进行处理,生成子查询的初始关系路径,并计算子查询中各个表达式的初始运行成本。- 生成子查询的最终查询计划
在完成所有子查询的预处理和优化后,会调用 create_plan 函数为子查询生成最终的查询计划。该函数会根据子查询的关系路径、投影列表和其他操作符,生成一个最终的 Plan 结构体表示子查询的执行计划。- 添加子查询到父查询
最后,将子查询的执行计划添加到父查询的 PlannerInfo 结构体中,并返回。

standard_planner函数源码如下:(路径:src/backend/optimizer/plan/planner.c)
PlannedStmt *
standard_planner(Query *parse, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt *result;
PlannerGlobal *glob;
double tuple_fraction;
PlannerInfo *root;
RelOptInfo *final_rel;
Path *best_path;
Plan *top_plan;
ListCell *lp,
*lr;
/*
* Set up global state for this planner invocation. This data is needed
* across all levels of sub-Query that might exist in the given command,
* so we keep it in a separate struct that's linked to by each per-Query
* PlannerInfo.
*/
glob = makeNode(PlannerGlobal);
glob->boundParams = boundParams;
glob->subplans = NIL;
glob->subroots = NIL;
glob->rewindPlanIDs = NULL;
glob->finalrtable = NIL;
glob->finalrowmarks = NIL;
glob->resultRelations = NIL;
glob->nonleafResultRelations = NIL;
glob->rootResultRelations = NIL;
glob->relationOids = NIL;
glob->invalItems = NIL;
glob->nParamExec = 0;
glob->lastPHId = 0;
glob->lastRowMarkId = 0;
glob->lastPlanNodeId = 0;
glob->transientPlan = false;
glob->dependsOnRole = false;
/*
* Assess whether it's feasible to use parallel mode for this query. We
* can't do this in a standalone backend, or if the command will try to
* modify any data, or if this is a cursor operation, or if GUCs are set
* to values that don't permit parallelism, or if parallel-unsafe
* functions are present in the query tree.
*
* For now, we don't try to use parallel mode if we're running inside a
* parallel worker. We might eventually be able to relax this
* restriction, but for now it seems best not to have parallel workers
* trying to create their own parallel workers.
*
* We can't use parallelism in serializable mode because the predicate
* locking code is not parallel-aware. It's not catastrophic if someone
* tries to run a parallel plan in serializable mode; it just won't get
* any workers and will run serially. But it seems like a good heuristic
* to assume that the same serialization level will be in effect at plan
* time and execution time, so don't generate a parallel plan if we're in
* serializable mode.
*/
if ((cursorOptions & CURSOR_OPT_PARALLEL_OK) != 0 &&
IsUnderPostmaster &&
dynamic_shared_memory_type != DSM_IMPL_NONE &&
parse->commandType == CMD_SELECT &&
!parse->hasModifyingCTE &&
max_parallel_workers_per_gather > 0 &&
!IsParallelWorker() &&
!IsolationIsSerializable())
{
/* all the cheap tests pass, so scan the query tree */
glob->maxParallelHazard = max_parallel_hazard(parse);
glob->parallelModeOK = (glob->maxParallelHazard != PROPARALLEL_UNSAFE);
}
else
{
/* skip the query tree scan, just assume it's unsafe */
glob->maxParallelHazard = PROPARALLEL_UNSAFE;
glob->parallelModeOK = false;
}
/*
* glob->parallelModeNeeded should tell us whether it's necessary to
* impose the parallel mode restrictions, but we don't actually want to
* impose them unless we choose a parallel plan, so it is normally set
* only if a parallel plan is chosen (see create_gather_plan). That way,
* people who mislabel their functions but don't use parallelism anyway
* aren't harmed. But when force_parallel_mode is set, we enable the
* restrictions whenever possible for testing purposes.
*/
glob->parallelModeNeeded = glob->parallelModeOK &&
(force_parallel_mode != FORCE_PARALLEL_OFF);
/* Determine what fraction of the plan is likely to be scanned */
if (cursorOptions & CURSOR_OPT_FAST_PLAN)
{
/*
* We have no real idea how many tuples the user will ultimately FETCH
* from a cursor, but it is often the case that he doesn't want 'em
* all, or would prefer a fast-start plan anyway so that he can
* process some of the tuples sooner. Use a GUC parameter to decide
* what fraction to optimize for.
*/
tuple_fraction = cursor_tuple_fraction;
/*
* We document cursor_tuple_fraction as simply being a fraction, which
* means the edge cases 0 and 1 have to be treated specially here. We
* convert 1 to 0 ("all the tuples") and 0 to a very small fraction.
*/
if (tuple_fraction >= 1.0)
tuple_fraction = 0.0;
else if (tuple_fraction <= 0.0)
tuple_fraction = 1e-10;
}
else
{
/* Default assumption is we need all the tuples */
tuple_fraction = 0.0;
}
/* primary planning entry point (may recurse for subqueries) */
root = subquery_planner(glob, parse, NULL,
false, tuple_fraction);
/* Select best Path and turn it into a Plan */
final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
best_path = get_cheapest_fractional_path(final_rel, tuple_fraction);
top_plan = create_plan(root, best_path);
/*
* If creating a plan for a scrollable cursor, make sure it can run
* backwards on demand. Add a Material node at the top at need.
*/
if (cursorOptions & CURSOR_OPT_SCROLL)
{
if (!ExecSupportsBackwardScan(top_plan))
top_plan = materialize_finished_plan(top_plan);
}
/*
* Optionally add a Gather node for testing purposes, provided this is
* actually a safe thing to do.
*/
if (force_parallel_mode != FORCE_PARALLEL_OFF && top_plan->parallel_safe)
{
Gather *gather = makeNode(Gather);
gather->plan.targetlist = top_plan->targetlist;
gather->plan.qual = NIL;
gather->plan.lefttree = top_plan;
gather->plan.righttree = NULL;
gather->num_workers = 1;
gather->single_copy = true;
gather->invisible = (force_parallel_mode == FORCE_PARALLEL_REGRESS);
/*
* Since this Gather has no parallel-aware descendants to signal to,
* we don't need a rescan Param.
*/
gather->rescan_param = -1;
/*
* Ideally we'd use cost_gather here, but setting up dummy path data
* to satisfy it doesn't seem much cleaner than knowing what it does.
*/
gather->plan.startup_cost = top_plan->startup_cost +
parallel_setup_cost;
gather->plan.total_cost = top_plan->total_cost +
parallel_setup_cost + parallel_tuple_cost * top_plan->plan_rows;
gather->plan.plan_rows = top_plan->plan_rows;
gather->plan.plan_width = top_plan->plan_width;
gather->plan.parallel_aware = false;
gather->plan.parallel_safe = false;
/* use parallel mode for parallel plans. */
root->glob->parallelModeNeeded = true;
top_plan = &gather->plan;
}
/*
* If any Params were generated, run through the plan tree and compute
* each plan node's extParam/allParam sets. Ideally we'd merge this into
* set_plan_references' tree traversal, but for now it has to be separate
* because we need to visit subplans before not after main plan.
*/
if (glob->nParamExec > 0)
{
Assert(list_length(glob->subplans) == list_length(glob->subroots));
forboth(lp, glob->subplans, lr, glob->subroots)
{
Plan *subplan = (Plan *) lfirst(lp);
PlannerInfo *subroot = (PlannerInfo *) lfirst(lr);
SS_finalize_plan(subroot, subplan);
}
SS_finalize_plan(root, top_plan);
}
/* final cleanup of the plan */
Assert(glob->finalrtable == NIL);
Assert(glob->finalrowmarks == NIL);
Assert(glob->resultRelations == NIL);
Assert(glob->nonleafResultRelations == NIL);
Assert(glob->rootResultRelations == NIL);
top_plan = set_plan_references(root, top_plan);
/* ... and the subplans (both regular subplans and initplans) */
Assert(list_length(glob->subplans) == list_length(glob->subroots));
forboth(lp, glob->subplans, lr, glob->subroots)
{
Plan *subplan = (Plan *) lfirst(lp);
PlannerInfo *subroot = (PlannerInfo *) lfirst(lr);
lfirst(lp) = set_plan_references(subroot, subplan);
}
/* build the PlannedStmt result */
result = makeNode(PlannedStmt);
result->commandType = parse->commandType;
result->queryId = parse->queryId;
result->hasReturning = (parse->returningList != NIL);
result->hasModifyingCTE = parse->hasModifyingCTE;
result->canSetTag = parse->canSetTag;
result->transientPlan = glob->transientPlan;
result->dependsOnRole = glob->dependsOnRole;
result->parallelModeNeeded = glob->parallelModeNeeded;
result->planTree = top_plan;
result->rtable = glob->finalrtable;
result->resultRelations = glob->resultRelations;
result->nonleafResultRelations = glob->nonleafResultRelations;
result->rootResultRelations = glob->rootResultRelations;
result->subplans = glob->subplans;
result->rewindPlanIDs = glob->rewindPlanIDs;
result->rowMarks = glob->finalrowmarks;
result->relationOids = glob->relationOids;
result->invalItems = glob->invalItems;
result->nParamExec = glob->nParamExec;
/* utilityStmt should be null, but we might as well copy it */
result->utilityStmt = parse->utilityStmt;
result->stmt_location = parse->stmt_location;
result->stmt_len = parse->stmt_len;
return result;
}
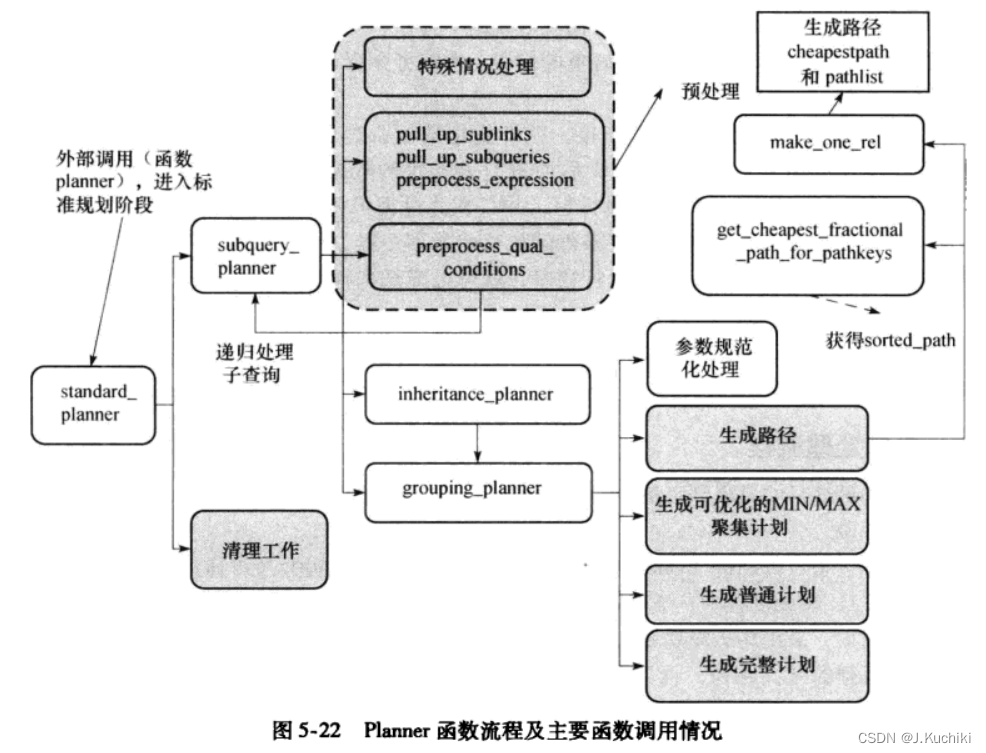
standard_planner的主要流程如下所示:
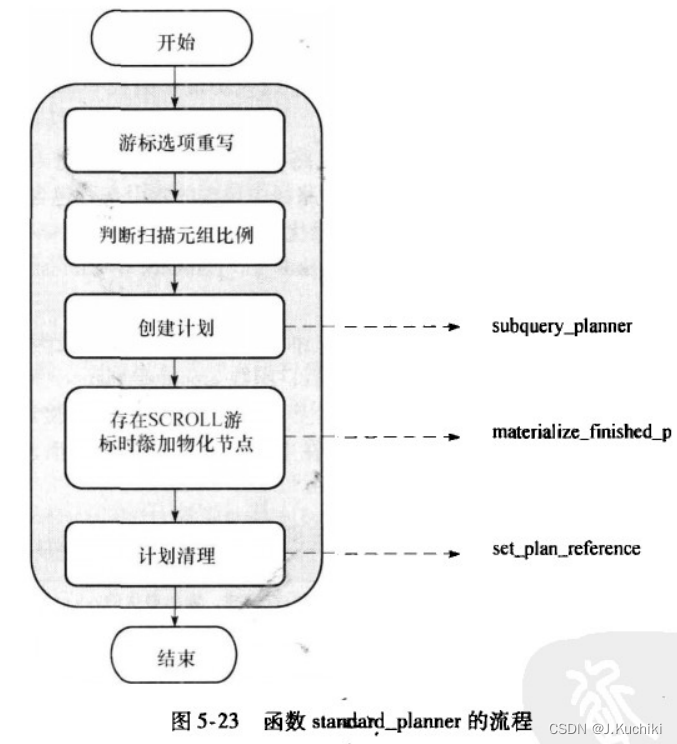
subquery_planner函数
subquery_planner负责创建计划,可递归处理子查询。函数路径(src/backend/optimizer/plan/planner.c)
subquery_planner的工作分为两部分:
- 依据消除冗余条件、减少查询层次、简化路径生成的基本思想,调用预处理函数对查询树进行预处理。
- 调用inheritance_planner或grouping_planner进入生成计划流程,该过程不对查询树做出实质性的改变。
subquery_planner函数源码如下:
/*--------------------
* subquery_planner
* Invokes the planner on a subquery. We recurse to here for each
* sub-SELECT found in the query tree.
*
* glob is the global state for the current planner run.
* parse is the querytree produced by the parser & rewriter.
* parent_root is the immediate parent Query's info (NULL at the top level).
* hasRecursion is true if this is a recursive WITH query.
* tuple_fraction is the fraction of tuples we expect will be retrieved.
* tuple_fraction is interpreted as explained for grouping_planner, below.
*
* Basically, this routine does the stuff that should only be done once
* per Query object. It then calls grouping_planner. At one time,
* grouping_planner could be invoked recursively on the same Query object;
* that's not currently true, but we keep the separation between the two
* routines anyway, in case we need it again someday.
*
* subquery_planner will be called recursively to handle sub-Query nodes
* found within the query's expressions and rangetable.
*
* Returns the PlannerInfo struct ("root") that contains all data generated
* while planning the subquery. In particular, the Path(s) attached to
* the (UPPERREL_FINAL, NULL) upperrel represent our conclusions about the
* cheapest way(s) to implement the query. The top level will select the
* best Path and pass it through createplan.c to produce a finished Plan.
*--------------------
*/
PlannerInfo *
subquery_planner(PlannerGlobal *glob, Query *parse,
PlannerInfo *parent_root,
bool hasRecursion, double tuple_fraction)
{
PlannerInfo *root;
List *newWithCheckOptions;
List *newHaving;
bool hasOuterJoins;
RelOptInfo *final_rel;
ListCell *l;
/* Create a PlannerInfo data structure for this subquery */
root = makeNode(PlannerInfo);
root->parse = parse;
root->glob = glob;
root->query_level = parent_root ? parent_root->query_level + 1 : 1;
root->parent_root = parent_root;
root->plan_params = NIL;
root->outer_params = NULL;
root->planner_cxt = CurrentMemoryContext;
root->init_plans = NIL;
root->cte_plan_ids = NIL;
root->multiexpr_params = NIL;
root->eq_classes = NIL;
root->append_rel_list = NIL;
root->pcinfo_list = NIL;
root->rowMarks = NIL;
memset(root->upper_rels, 0, sizeof(root->upper_rels));
memset(root->upper_targets, 0, sizeof(root->upper_targets));
root->processed_tlist = NIL;
root->grouping_map = NULL;
root->minmax_aggs = NIL;
root->qual_security_level = 0;
root->hasInheritedTarget = false;
root->hasRecursion = hasRecursion;
if (hasRecursion)
root->wt_param_id = SS_assign_special_param(root);
else
root->wt_param_id = -1;
root->non_recursive_path = NULL;
/*
* If there is a WITH list, process each WITH query and build an initplan
* SubPlan structure for it.
*/
if (parse->cteList)
SS_process_ctes(root);
/*
* Look for ANY and EXISTS SubLinks in WHERE and JOIN/ON clauses, and try
* to transform them into joins. Note that this step does not descend
* into subqueries; if we pull up any subqueries below, their SubLinks are
* processed just before pulling them up.
*/
if (parse->hasSubLinks)
pull_up_sublinks(root);
/*
* Scan the rangetable for set-returning functions, and inline them if
* possible (producing subqueries that might get pulled up next).
* Recursion issues here are handled in the same way as for SubLinks.
*/
inline_set_returning_functions(root);
/*
* Check to see if any subqueries in the jointree can be merged into this
* query.
*/
pull_up_subqueries(root);
/*
* If this is a simple UNION ALL query, flatten it into an appendrel. We
* do this now because it requires applying pull_up_subqueries to the leaf
* queries of the UNION ALL, which weren't touched above because they
* weren't referenced by the jointree (they will be after we do this).
*/
if (parse->setOperations)
flatten_simple_union_all(root);
/*
* Detect whether any rangetable entries are RTE_JOIN kind; if not, we can
* avoid the expense of doing flatten_join_alias_vars(). Also check for
* outer joins --- if none, we can skip reduce_outer_joins(). And check
* for LATERAL RTEs, too. This must be done after we have done
* pull_up_subqueries(), of course.
*/
root->hasJoinRTEs = false;
root->hasLateralRTEs = false;
hasOuterJoins = false;
foreach(l, parse->rtable)
{
RangeTblEntry *rte = (RangeTblEntry *) lfirst(l);
if (rte->rtekind == RTE_JOIN)
{
root->hasJoinRTEs = true;
if (IS_OUTER_JOIN(rte->jointype))
hasOuterJoins = true;
}
if (rte->lateral)
root->hasLateralRTEs = true;
}
/*
* Preprocess RowMark information. We need to do this after subquery
* pullup (so that all non-inherited RTEs are present) and before
* inheritance expansion (so that the info is available for
* expand_inherited_tables to examine and modify).
*/
preprocess_rowmarks(root);
/*
* Expand any rangetable entries that are inheritance sets into "append
* relations". This can add entries to the rangetable, but they must be
* plain base relations not joins, so it's OK (and marginally more
* efficient) to do it after checking for join RTEs. We must do it after
* pulling up subqueries, else we'd fail to handle inherited tables in
* subqueries.
*/
expand_inherited_tables(root);
/*
* Set hasHavingQual to remember if HAVING clause is present. Needed
* because preprocess_expression will reduce a constant-true condition to
* an empty qual list ... but "HAVING TRUE" is not a semantic no-op.
*/
root->hasHavingQual = (parse->havingQual != NULL);
/* Clear this flag; might get set in distribute_qual_to_rels */
root->hasPseudoConstantQuals = false;
/*
* Do expression preprocessing on targetlist and quals, as well as other
* random expressions in the querytree. Note that we do not need to
* handle sort/group expressions explicitly, because they are actually
* part of the targetlist.
*/
parse->targetList = (List *)
preprocess_expression(root, (Node *) parse->targetList,
EXPRKIND_TARGET);
/* Constant-folding might have removed all set-returning functions */
if (parse->hasTargetSRFs)
parse->hasTargetSRFs = expression_returns_set((Node *) parse->targetList);
newWithCheckOptions = NIL;
foreach(l, parse->withCheckOptions)
{
WithCheckOption *wco = (WithCheckOption *) lfirst(l);
wco->qual = preprocess_expression(root, wco->qual,
EXPRKIND_QUAL);
if (wco->qual != NULL)
newWithCheckOptions = lappend(newWithCheckOptions, wco);
}
parse->withCheckOptions = newWithCheckOptions;
parse->returningList = (List *)
preprocess_expression(root, (Node *) parse->returningList,
EXPRKIND_TARGET);
preprocess_qual_conditions(root, (Node *) parse->jointree);
parse->havingQual = preprocess_expression(root, parse->havingQual,
EXPRKIND_QUAL);
foreach(l, parse->windowClause)
{
WindowClause *wc = (WindowClause *) lfirst(l);
/* partitionClause/orderClause are sort/group expressions */
wc->startOffset = preprocess_expression(root, wc->startOffset,
EXPRKIND_LIMIT);
wc->endOffset = preprocess_expression(root, wc->endOffset,
EXPRKIND_LIMIT);
}
parse->limitOffset = preprocess_expression(root, parse->limitOffset,
EXPRKIND_LIMIT);
parse->limitCount = preprocess_expression(root, parse->limitCount,
EXPRKIND_LIMIT);
if (parse->onConflict)
{
parse->onConflict->arbiterElems = (List *)
preprocess_expression(root,
(Node *) parse->onConflict->arbiterElems,
EXPRKIND_ARBITER_ELEM);
parse->onConflict->arbiterWhere =
preprocess_expression(root,
parse->onConflict->arbiterWhere,
EXPRKIND_QUAL);
parse->onConflict->onConflictSet = (List *)
preprocess_expression(root,
(Node *) parse->onConflict->onConflictSet,
EXPRKIND_TARGET);
parse->onConflict->onConflictWhere =
preprocess_expression(root,
parse->onConflict->onConflictWhere,
EXPRKIND_QUAL);
/* exclRelTlist contains only Vars, so no preprocessing needed */
}
root->append_rel_list = (List *)
preprocess_expression(root, (Node *) root->append_rel_list,
EXPRKIND_APPINFO);
/* Also need to preprocess expressions within RTEs */
foreach(l, parse->rtable)
{
RangeTblEntry *rte = (RangeTblEntry *) lfirst(l);
int kind;
ListCell *lcsq;
if (rte->rtekind == RTE_RELATION)
{
if (rte->tablesample)
rte->tablesample = (TableSampleClause *)
preprocess_expression(root,
(Node *) rte->tablesample,
EXPRKIND_TABLESAMPLE);
}
else if (rte->rtekind == RTE_SUBQUERY)
{
/*
* We don't want to do all preprocessing yet on the subquery's
* expressions, since that will happen when we plan it. But if it
* contains any join aliases of our level, those have to get
* expanded now, because planning of the subquery won't do it.
* That's only possible if the subquery is LATERAL.
*/
if (rte->lateral && root->hasJoinRTEs)
rte->subquery = (Query *)
flatten_join_alias_vars(root, (Node *) rte->subquery);
}
else if (rte->rtekind == RTE_FUNCTION)
{
/* Preprocess the function expression(s) fully */
kind = rte->lateral ? EXPRKIND_RTFUNC_LATERAL : EXPRKIND_RTFUNC;
rte->functions = (List *)
preprocess_expression(root, (Node *) rte->functions, kind);
}
else if (rte->rtekind == RTE_TABLEFUNC)
{
/* Preprocess the function expression(s) fully */
kind = rte->lateral ? EXPRKIND_TABLEFUNC_LATERAL : EXPRKIND_TABLEFUNC;
rte->tablefunc = (TableFunc *)
preprocess_expression(root, (Node *) rte->tablefunc, kind);
}
else if (rte->rtekind == RTE_VALUES)
{
/* Preprocess the values lists fully */
kind = rte->lateral ? EXPRKIND_VALUES_LATERAL : EXPRKIND_VALUES;
rte->values_lists = (List *)
preprocess_expression(root, (Node *) rte->values_lists, kind);
}
/*
* Process each element of the securityQuals list as if it were a
* separate qual expression (as indeed it is). We need to do it this
* way to get proper canonicalization of AND/OR structure. Note that
* this converts each element into an implicit-AND sublist.
*/
foreach(lcsq, rte->securityQuals)
{
lfirst(lcsq) = preprocess_expression(root,
(Node *) lfirst(lcsq),
EXPRKIND_QUAL);
}
}
/*
* Now that we are done preprocessing expressions, and in particular done
* flattening join alias variables, get rid of the joinaliasvars lists.
* They no longer match what expressions in the rest of the tree look
* like, because we have not preprocessed expressions in those lists (and
* do not want to; for example, expanding a SubLink there would result in
* a useless unreferenced subplan). Leaving them in place simply creates
* a hazard for later scans of the tree. We could try to prevent that by
* using QTW_IGNORE_JOINALIASES in every tree scan done after this point,
* but that doesn't sound very reliable.
*/
if (root->hasJoinRTEs)
{
foreach(l, parse->rtable)
{
RangeTblEntry *rte = lfirst_node(RangeTblEntry, l);
rte->joinaliasvars = NIL;
}
}
/*
* In some cases we may want to transfer a HAVING clause into WHERE. We
* cannot do so if the HAVING clause contains aggregates (obviously) or
* volatile functions (since a HAVING clause is supposed to be executed
* only once per group). We also can't do this if there are any nonempty
* grouping sets; moving such a clause into WHERE would potentially change
* the results, if any referenced column isn't present in all the grouping
* sets. (If there are only empty grouping sets, then the HAVING clause
* must be degenerate as discussed below.)
*
* Also, it may be that the clause is so expensive to execute that we're
* better off doing it only once per group, despite the loss of
* selectivity. This is hard to estimate short of doing the entire
* planning process twice, so we use a heuristic: clauses containing
* subplans are left in HAVING. Otherwise, we move or copy the HAVING
* clause into WHERE, in hopes of eliminating tuples before aggregation
* instead of after.
*
* If the query has explicit grouping then we can simply move such a
* clause into WHERE; any group that fails the clause will not be in the
* output because none of its tuples will reach the grouping or
* aggregation stage. Otherwise we must have a degenerate (variable-free)
* HAVING clause, which we put in WHERE so that query_planner() can use it
* in a gating Result node, but also keep in HAVING to ensure that we
* don't emit a bogus aggregated row. (This could be done better, but it
* seems not worth optimizing.)
*
* Note that both havingQual and parse->jointree->quals are in
* implicitly-ANDed-list form at this point, even though they are declared
* as Node *.
*/
newHaving = NIL;
foreach(l, (List *) parse->havingQual)
{
Node *havingclause = (Node *) lfirst(l);
if ((parse->groupClause && parse->groupingSets) ||
contain_agg_clause(havingclause) ||
contain_volatile_functions(havingclause) ||
contain_subplans(havingclause))
{
/* keep it in HAVING */
newHaving = lappend(newHaving, havingclause);
}
else if (parse->groupClause && !parse->groupingSets)
{
/* move it to WHERE */
parse->jointree->quals = (Node *)
lappend((List *) parse->jointree->quals, havingclause);
}
else
{
/* put a copy in WHERE, keep it in HAVING */
parse->jointree->quals = (Node *)
lappend((List *) parse->jointree->quals,
copyObject(havingclause));
newHaving = lappend(newHaving, havingclause);
}
}
parse->havingQual = (Node *) newHaving;
/* Remove any redundant GROUP BY columns */
remove_useless_groupby_columns(root);
/*
* If we have any outer joins, try to reduce them to plain inner joins.
* This step is most easily done after we've done expression
* preprocessing.
*/
if (hasOuterJoins)
reduce_outer_joins(root);
/*
* Do the main planning. If we have an inherited target relation, that
* needs special processing, else go straight to grouping_planner.
*/
if (parse->resultRelation &&
rt_fetch(parse->resultRelation, parse->rtable)->inh)
inheritance_planner(root);
else
grouping_planner(root, false, tuple_fraction);
/*
* Capture the set of outer-level param IDs we have access to, for use in
* extParam/allParam calculations later.
*/
SS_identify_outer_params(root);
/*
* If any initPlans were created in this query level, adjust the surviving
* Paths' costs and parallel-safety flags to account for them. The
* initPlans won't actually get attached to the plan tree till
* create_plan() runs, but we must include their effects now.
*/
final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
SS_charge_for_initplans(root, final_rel);
/*
* Make sure we've identified the cheapest Path for the final rel. (By
* doing this here not in grouping_planner, we include initPlan costs in
* the decision, though it's unlikely that will change anything.)
*/
set_cheapest(final_rel);
return root;
}
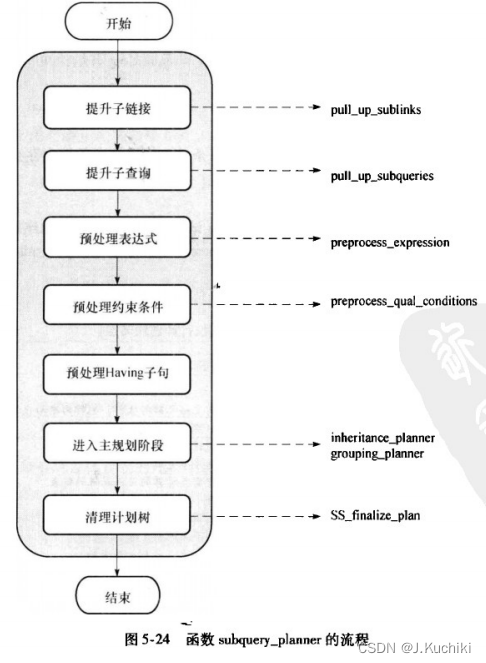
在subquery_planner函数中调用函数inheritance_planner和 grouping_planner生成计划树,用数据结构Plan存储和表示。
inheritance_planner函数
inheritance_planner 函数的作用是处理继承(inheritance)相关的操作,特别是处理分区表(partitioned table)的查询规划。它在 subquery_planner 函数中的调用关系如下:
- subquery_planner 函数首先会创建一个 PlannerInfo 结构体,并对其进行一些初始化工作。
- 接下来,subquery_planner 函数会根据查询中的表引用,调用 query_planner 函数为每个表生成查询规划。在 query_planner 函数中,如果遇到分区表,则会调用 inheritance_planner 函数。
- inheritance_planner 函数会根据分区表的继承关系,将分区表的各个分区加入到查询规划中,并进行必要的优化,以便将查询规划分配到正确的分区表上。

总的来说,inheritance_planner 函数负责处理分区表的查询规划,将查询计划分配到正确的分区表上,以实现分区表的查询优化和执行。
inheritance_planner的函数源码如下所示:(路径:src/backend/optimizer/plan/planner.c)
/*
* inheritance_planner
* Generate Paths in the case where the result relation is an
* inheritance set.
*
* We have to handle this case differently from cases where a source relation
* is an inheritance set. Source inheritance is expanded at the bottom of the
* plan tree (see allpaths.c), but target inheritance has to be expanded at
* the top. The reason is that for UPDATE, each target relation needs a
* different targetlist matching its own column set. Fortunately,
* the UPDATE/DELETE target can never be the nullable side of an outer join,
* so it's OK to generate the plan this way.
*
* Returns nothing; the useful output is in the Paths we attach to
* the (UPPERREL_FINAL, NULL) upperrel stored in *root.
*
* Note that we have not done set_cheapest() on the final rel; it's convenient
* to leave this to the caller.
*/
static void
inheritance_planner(PlannerInfo *root)
{
Query *parse = root->parse;
int parentRTindex = parse->resultRelation;
Bitmapset *subqueryRTindexes;
Bitmapset *modifiableARIindexes;
int nominalRelation = -1;
List *final_rtable = NIL;
int save_rel_array_size = 0;
RelOptInfo **save_rel_array = NULL;
List *subpaths = NIL;
List *subroots = NIL;
List *resultRelations = NIL;
List *withCheckOptionLists = NIL;
List *returningLists = NIL;
List *rowMarks;
RelOptInfo *final_rel;
ListCell *lc;
Index rti;
RangeTblEntry *parent_rte;
List *partitioned_rels = NIL;
Assert(parse->commandType != CMD_INSERT);
/*
* We generate a modified instance of the original Query for each target
* relation, plan that, and put all the plans into a list that will be
* controlled by a single ModifyTable node. All the instances share the
* same rangetable, but each instance must have its own set of subquery
* RTEs within the finished rangetable because (1) they are likely to get
* scribbled on during planning, and (2) it's not inconceivable that
* subqueries could get planned differently in different cases. We need
* not create duplicate copies of other RTE kinds, in particular not the
* target relations, because they don't have either of those issues. Not
* having to duplicate the target relations is important because doing so
* (1) would result in a rangetable of length O(N^2) for N targets, with
* at least O(N^3) work expended here; and (2) would greatly complicate
* management of the rowMarks list.
*
* To begin with, generate a bitmapset of the relids of the subquery RTEs.
*/
subqueryRTindexes = NULL;
rti = 1;
foreach(lc, parse->rtable)
{
RangeTblEntry *rte = (RangeTblEntry *) lfirst(lc);
if (rte->rtekind == RTE_SUBQUERY)
subqueryRTindexes = bms_add_member(subqueryRTindexes, rti);
rti++;
}
/*
* Next, we want to identify which AppendRelInfo items contain references
* to any of the aforesaid subquery RTEs. These items will need to be
* copied and modified to adjust their subquery references; whereas the
* other ones need not be touched. It's worth being tense over this
* because we can usually avoid processing most of the AppendRelInfo
* items, thereby saving O(N^2) space and time when the target is a large
* inheritance tree. We can identify AppendRelInfo items by their
* child_relid, since that should be unique within the list.
*/
modifiableARIindexes = NULL;
if (subqueryRTindexes != NULL)
{
foreach(lc, root->append_rel_list)
{
AppendRelInfo *appinfo = (AppendRelInfo *) lfirst(lc);
if (bms_is_member(appinfo->parent_relid, subqueryRTindexes) ||
bms_is_member(appinfo->child_relid, subqueryRTindexes) ||
bms_overlap(pull_varnos((Node *) appinfo->translated_vars),
subqueryRTindexes))
modifiableARIindexes = bms_add_member(modifiableARIindexes,
appinfo->child_relid);
}
}
/*
* If the parent RTE is a partitioned table, we should use that as the
* nominal relation, because the RTEs added for partitioned tables
* (including the root parent) as child members of the inheritance set do
* not appear anywhere else in the plan. The situation is exactly the
* opposite in the case of non-partitioned inheritance parent as described
* below.
*/
parent_rte = rt_fetch(parentRTindex, root->parse->rtable);
if (parent_rte->relkind == RELKIND_PARTITIONED_TABLE)
nominalRelation = parentRTindex;
/*
* And now we can get on with generating a plan for each child table.
*/
foreach(lc, root->append_rel_list)
{
AppendRelInfo *appinfo = (AppendRelInfo *) lfirst(lc);
PlannerInfo *subroot;
RangeTblEntry *child_rte;
RelOptInfo *sub_final_rel;
Path *subpath;
/* append_rel_list contains all append rels; ignore others */
if (appinfo->parent_relid != parentRTindex)
continue;
/*
* We need a working copy of the PlannerInfo so that we can control
* propagation of information back to the main copy.
*/
subroot = makeNode(PlannerInfo);
memcpy(subroot, root, sizeof(PlannerInfo));
/*
* Generate modified query with this rel as target. We first apply
* adjust_appendrel_attrs, which copies the Query and changes
* references to the parent RTE to refer to the current child RTE,
* then fool around with subquery RTEs.
*/
subroot->parse = (Query *)
adjust_appendrel_attrs(root,
(Node *) parse,
appinfo);
/*
* If there are securityQuals attached to the parent, move them to the
* child rel (they've already been transformed properly for that).
*/
parent_rte = rt_fetch(parentRTindex, subroot->parse->rtable);
child_rte = rt_fetch(appinfo->child_relid, subroot->parse->rtable);
child_rte->securityQuals = parent_rte->securityQuals;
parent_rte->securityQuals = NIL;
/*
* The rowMarks list might contain references to subquery RTEs, so
* make a copy that we can apply ChangeVarNodes to. (Fortunately, the
* executor doesn't need to see the modified copies --- we can just
* pass it the original rowMarks list.)
*/
subroot->rowMarks = copyObject(root->rowMarks);
/*
* The append_rel_list likewise might contain references to subquery
* RTEs (if any subqueries were flattenable UNION ALLs). So prepare
* to apply ChangeVarNodes to that, too. As explained above, we only
* want to copy items that actually contain such references; the rest
* can just get linked into the subroot's append_rel_list.
*
* If we know there are no such references, we can just use the outer
* append_rel_list unmodified.
*/
if (modifiableARIindexes != NULL)
{
ListCell *lc2;
subroot->append_rel_list = NIL;
foreach(lc2, root->append_rel_list)
{
AppendRelInfo *appinfo2 = (AppendRelInfo *) lfirst(lc2);
if (bms_is_member(appinfo2->child_relid, modifiableARIindexes))
appinfo2 = copyObject(appinfo2);
subroot->append_rel_list = lappend(subroot->append_rel_list,
appinfo2);
}
}
/*
* Add placeholders to the child Query's rangetable list to fill the
* RT indexes already reserved for subqueries in previous children.
* These won't be referenced, so there's no need to make them very
* valid-looking.
*/
while (list_length(subroot->parse->rtable) < list_length(final_rtable))
subroot->parse->rtable = lappend(subroot->parse->rtable,
makeNode(RangeTblEntry));
/*
* If this isn't the first child Query, generate duplicates of all
* subquery RTEs, and adjust Var numbering to reference the
* duplicates. To simplify the loop logic, we scan the original rtable
* not the copy just made by adjust_appendrel_attrs; that should be OK
* since subquery RTEs couldn't contain any references to the target
* rel.
*/
if (final_rtable != NIL && subqueryRTindexes != NULL)
{
ListCell *lr;
rti = 1;
foreach(lr, parse->rtable)
{
RangeTblEntry *rte = (RangeTblEntry *) lfirst(lr);
if (bms_is_member(rti, subqueryRTindexes))
{
Index newrti;
/*
* The RTE can't contain any references to its own RT
* index, except in its securityQuals, so we can save a
* few cycles by applying ChangeVarNodes to the rest of
* the rangetable before we append the RTE to it.
*/
newrti = list_length(subroot->parse->rtable) + 1;
ChangeVarNodes((Node *) subroot->parse, rti, newrti, 0);
ChangeVarNodes((Node *) subroot->rowMarks, rti, newrti, 0);
/* Skip processing unchanging parts of append_rel_list */
if (modifiableARIindexes != NULL)
{
ListCell *lc2;
foreach(lc2, subroot->append_rel_list)
{
AppendRelInfo *appinfo2 = (AppendRelInfo *) lfirst(lc2);
if (bms_is_member(appinfo2->child_relid,
modifiableARIindexes))
ChangeVarNodes((Node *) appinfo2, rti, newrti, 0);
}
}
rte = copyObject(rte);
ChangeVarNodes((Node *) rte->securityQuals, rti, newrti, 0);
subroot->parse->rtable = lappend(subroot->parse->rtable,
rte);
}
rti++;
}
}
/* There shouldn't be any OJ info to translate, as yet */
Assert(subroot->join_info_list == NIL);
/* and we haven't created PlaceHolderInfos, either */
Assert(subroot->placeholder_list == NIL);
/* hack to mark target relation as an inheritance partition */
subroot->hasInheritedTarget = true;
/* Generate Path(s) for accessing this result relation */
grouping_planner(subroot, true, 0.0 /* retrieve all tuples */ );
/*
* Set the nomimal target relation of the ModifyTable node if not
* already done. We use the inheritance parent RTE as the nominal
* target relation if it's a partitioned table (see just above this
* loop). In the non-partitioned parent case, we'll use the first
* child relation (even if it's excluded) as the nominal target
* relation. Because of the way expand_inherited_rtentry works, the
* latter should be the RTE representing the parent table in its role
* as a simple member of the inheritance set.
*
* It would be logically cleaner to *always* use the inheritance
* parent RTE as the nominal relation; but that RTE is not otherwise
* referenced in the plan in the non-partitioned inheritance case.
* Instead the duplicate child RTE created by expand_inherited_rtentry
* is used elsewhere in the plan, so using the original parent RTE
* would give rise to confusing use of multiple aliases in EXPLAIN
* output for what the user will think is the "same" table. OTOH,
* it's not a problem in the partitioned inheritance case, because the
* duplicate child RTE added for the parent does not appear anywhere
* else in the plan tree.
*/
if (nominalRelation < 0)
nominalRelation = appinfo->child_relid;
/*
* Select cheapest path in case there's more than one. We always run
* modification queries to conclusion, so we care only for the
* cheapest-total path.
*/
sub_final_rel = fetch_upper_rel(subroot, UPPERREL_FINAL, NULL);
set_cheapest(sub_final_rel);
subpath = sub_final_rel->cheapest_total_path;
/*
* If this child rel was excluded by constraint exclusion, exclude it
* from the result plan.
*/
if (IS_DUMMY_PATH(subpath))
continue;
/*
* If this is the first non-excluded child, its post-planning rtable
* becomes the initial contents of final_rtable; otherwise, append
* just its modified subquery RTEs to final_rtable.
*/
if (final_rtable == NIL)
final_rtable = subroot->parse->rtable;
else
final_rtable = list_concat(final_rtable,
list_copy_tail(subroot->parse->rtable,
list_length(final_rtable)));
/*
* We need to collect all the RelOptInfos from all child plans into
* the main PlannerInfo, since setrefs.c will need them. We use the
* last child's simple_rel_array (previous ones are too short), so we
* have to propagate forward the RelOptInfos that were already built
* in previous children.
*/
Assert(subroot->simple_rel_array_size >= save_rel_array_size);
for (rti = 1; rti < save_rel_array_size; rti++)
{
RelOptInfo *brel = save_rel_array[rti];
if (brel)
subroot->simple_rel_array[rti] = brel;
}
save_rel_array_size = subroot->simple_rel_array_size;
save_rel_array = subroot->simple_rel_array;
/* Make sure any initplans from this rel get into the outer list */
root->init_plans = subroot->init_plans;
/* Build list of sub-paths */
subpaths = lappend(subpaths, subpath);
/* Build list of modified subroots, too */
subroots = lappend(subroots, subroot);
/* Build list of target-relation RT indexes */
resultRelations = lappend_int(resultRelations, appinfo->child_relid);
/* Build lists of per-relation WCO and RETURNING targetlists */
if (parse->withCheckOptions)
withCheckOptionLists = lappend(withCheckOptionLists,
subroot->parse->withCheckOptions);
if (parse->returningList)
returningLists = lappend(returningLists,
subroot->parse->returningList);
Assert(!parse->onConflict);
}
if (parent_rte->relkind == RELKIND_PARTITIONED_TABLE)
{
partitioned_rels = get_partitioned_child_rels(root, parentRTindex);
/* The root partitioned table is included as a child rel */
Assert(list_length(partitioned_rels) >= 1);
}
/* Result path must go into outer query's FINAL upperrel */
final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
/*
* We don't currently worry about setting final_rel's consider_parallel
* flag in this case, nor about allowing FDWs or create_upper_paths_hook
* to get control here.
*/
/*
* If we managed to exclude every child rel, return a dummy plan; it
* doesn't even need a ModifyTable node.
*/
if (subpaths == NIL)
{
set_dummy_rel_pathlist(final_rel);
return;
}
/*
* Put back the final adjusted rtable into the master copy of the Query.
* (We mustn't do this if we found no non-excluded children.)
*/
parse->rtable = final_rtable;
root->simple_rel_array_size = save_rel_array_size;
root->simple_rel_array = save_rel_array;
/* Must reconstruct master's simple_rte_array, too */
root->simple_rte_array = (RangeTblEntry **)
palloc0((list_length(final_rtable) + 1) * sizeof(RangeTblEntry *));
rti = 1;
foreach(lc, final_rtable)
{
RangeTblEntry *rte = (RangeTblEntry *) lfirst(lc);
root->simple_rte_array[rti++] = rte;
}
/*
* If there was a FOR [KEY] UPDATE/SHARE clause, the LockRows node will
* have dealt with fetching non-locked marked rows, else we need to have
* ModifyTable do that.
*/
if (parse->rowMarks)
rowMarks = NIL;
else
rowMarks = root->rowMarks;
/* Create Path representing a ModifyTable to do the UPDATE/DELETE work */
add_path(final_rel, (Path *)
create_modifytable_path(root, final_rel,
parse->commandType,
parse->canSetTag,
nominalRelation,
partitioned_rels,
resultRelations,
subpaths,
subroots,
withCheckOptionLists,
returningLists,
rowMarks,
NULL,
SS_assign_special_param(root)));
}
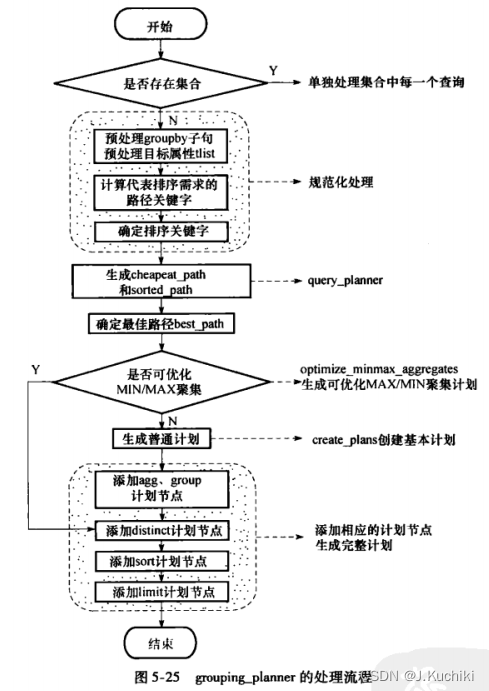
grouping_planner函数
grouping_planner 函数是用于处理 GROUP BY子句的查询规划 的关键部分。它负责生成针对包含聚合函数的查询语句的执行计划。
grouping_planner 函数的主要任务是 :
- 检查查询语句是否包含 GROUP BY 子句,以确定是否需要进行聚合操作。
- 如果需要进行聚合操作,则进行聚合表达式的处理,例如对聚合表达式进行计算、优化和归并等操作。
- 为 GROUP BY 子句中的每个表达式创建相关的数据结构,并构建执行计划的树状结构。
- 对查询的其他部分进行优化和处理,包括对 WHERE 子句的处理、索引的使用等。
- 最终生成一个 PlannedStmt 结构体,其中包含了查询的最优执行计划。
grouping_planner函数源码如下:(路径:src/backend/optimizer/plan/planner.c)
/*--------------------
* grouping_planner
* Perform planning steps related to grouping, aggregation, etc.
*
* This function adds all required top-level processing to the scan/join
* Path(s) produced by query_planner.
*
* If inheritance_update is true, we're being called from inheritance_planner
* and should not include a ModifyTable step in the resulting Path(s).
* (inheritance_planner will create a single ModifyTable node covering all the
* target tables.)
*
* tuple_fraction is the fraction of tuples we expect will be retrieved.
* tuple_fraction is interpreted as follows:
* 0: expect all tuples to be retrieved (normal case)
* 0 < tuple_fraction < 1: expect the given fraction of tuples available
* from the plan to be retrieved
* tuple_fraction >= 1: tuple_fraction is the absolute number of tuples
* expected to be retrieved (ie, a LIMIT specification)
*
* Returns nothing; the useful output is in the Paths we attach to the
* (UPPERREL_FINAL, NULL) upperrel in *root. In addition,
* root->processed_tlist contains the final processed targetlist.
*
* Note that we have not done set_cheapest() on the final rel; it's convenient
* to leave this to the caller.
*--------------------
*/
static void
grouping_planner(PlannerInfo *root, bool inheritance_update,
double tuple_fraction)
{
Query *parse = root->parse;
List *tlist = parse->targetList;
int64 offset_est = 0;
int64 count_est = 0;
double limit_tuples = -1.0;
bool have_postponed_srfs = false;
PathTarget *final_target;
List *final_targets;
List *final_targets_contain_srfs;
RelOptInfo *current_rel;
RelOptInfo *final_rel;
ListCell *lc;
/* Tweak caller-supplied tuple_fraction if have LIMIT/OFFSET */
if (parse->limitCount || parse->limitOffset)
{
tuple_fraction = preprocess_limit(root, tuple_fraction,
&offset_est, &count_est);
/*
* If we have a known LIMIT, and don't have an unknown OFFSET, we can
* estimate the effects of using a bounded sort.
*/
if (count_est > 0 && offset_est >= 0)
limit_tuples = (double) count_est + (double) offset_est;
}
/* Make tuple_fraction accessible to lower-level routines */
root->tuple_fraction = tuple_fraction;
if (parse->setOperations)
{
/*
* If there's a top-level ORDER BY, assume we have to fetch all the
* tuples. This might be too simplistic given all the hackery below
* to possibly avoid the sort; but the odds of accurate estimates here
* are pretty low anyway. XXX try to get rid of this in favor of
* letting plan_set_operations generate both fast-start and
* cheapest-total paths.
*/
if (parse->sortClause)
root->tuple_fraction = 0.0;
/*
* Construct Paths for set operations. The results will not need any
* work except perhaps a top-level sort and/or LIMIT. Note that any
* special work for recursive unions is the responsibility of
* plan_set_operations.
*/
current_rel = plan_set_operations(root);
/*
* We should not need to call preprocess_targetlist, since we must be
* in a SELECT query node. Instead, use the targetlist returned by
* plan_set_operations (since this tells whether it returned any
* resjunk columns!), and transfer any sort key information from the
* original tlist.
*/
Assert(parse->commandType == CMD_SELECT);
tlist = root->processed_tlist; /* from plan_set_operations */
/* for safety, copy processed_tlist instead of modifying in-place */
tlist = postprocess_setop_tlist(copyObject(tlist), parse->targetList);
/* Save aside the final decorated tlist */
root->processed_tlist = tlist;
/* Also extract the PathTarget form of the setop result tlist */
final_target = current_rel->cheapest_total_path->pathtarget;
/* The setop result tlist couldn't contain any SRFs */
Assert(!parse->hasTargetSRFs);
final_targets = final_targets_contain_srfs = NIL;
/*
* Can't handle FOR [KEY] UPDATE/SHARE here (parser should have
* checked already, but let's make sure).
*/
if (parse->rowMarks)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
/*------
translator: %s is a SQL row locking clause such as FOR UPDATE */
errmsg("%s is not allowed with UNION/INTERSECT/EXCEPT",
LCS_asString(((RowMarkClause *)
linitial(parse->rowMarks))->strength))));
/*
* Calculate pathkeys that represent result ordering requirements
*/
Assert(parse->distinctClause == NIL);
root->sort_pathkeys = make_pathkeys_for_sortclauses(root,
parse->sortClause,
tlist);
}
else
{
/* No set operations, do regular planning */
PathTarget *sort_input_target;
List *sort_input_targets;
List *sort_input_targets_contain_srfs;
PathTarget *grouping_target;
List *grouping_targets;
List *grouping_targets_contain_srfs;
PathTarget *scanjoin_target;
List *scanjoin_targets;
List *scanjoin_targets_contain_srfs;
bool have_grouping;
AggClauseCosts agg_costs;
WindowFuncLists *wflists = NULL;
List *activeWindows = NIL;
grouping_sets_data *gset_data = NULL;
standard_qp_extra qp_extra;
/* A recursive query should always have setOperations */
Assert(!root->hasRecursion);
/* Preprocess grouping sets and GROUP BY clause, if any */
if (parse->groupingSets)
{
gset_data = preprocess_grouping_sets(root);
}
else
{
/* Preprocess regular GROUP BY clause, if any */
if (parse->groupClause)
parse->groupClause = preprocess_groupclause(root, NIL);
}
/* Preprocess targetlist */
tlist = preprocess_targetlist(root, tlist);
if (parse->onConflict)
parse->onConflict->onConflictSet =
preprocess_onconflict_targetlist(parse->onConflict->onConflictSet,
parse->resultRelation,
parse->rtable);
/*
* We are now done hacking up the query's targetlist. Most of the
* remaining planning work will be done with the PathTarget
* representation of tlists, but save aside the full representation so
* that we can transfer its decoration (resnames etc) to the topmost
* tlist of the finished Plan.
*/
root->processed_tlist = tlist;
/*
* Collect statistics about aggregates for estimating costs, and mark
* all the aggregates with resolved aggtranstypes. We must do this
* before slicing and dicing the tlist into various pathtargets, else
* some copies of the Aggref nodes might escape being marked with the
* correct transtypes.
*
* Note: currently, we do not detect duplicate aggregates here. This
* may result in somewhat-overestimated cost, which is fine for our
* purposes since all Paths will get charged the same. But at some
* point we might wish to do that detection in the planner, rather
* than during executor startup.
*/
MemSet(&agg_costs, 0, sizeof(AggClauseCosts));
if (parse->hasAggs)
{
get_agg_clause_costs(root, (Node *) tlist, AGGSPLIT_SIMPLE,
&agg_costs);
get_agg_clause_costs(root, parse->havingQual, AGGSPLIT_SIMPLE,
&agg_costs);
}
/*
* Locate any window functions in the tlist. (We don't need to look
* anywhere else, since expressions used in ORDER BY will be in there
* too.) Note that they could all have been eliminated by constant
* folding, in which case we don't need to do any more work.
*/
if (parse->hasWindowFuncs)
{
wflists = find_window_functions((Node *) tlist,
list_length(parse->windowClause));
if (wflists->numWindowFuncs > 0)
activeWindows = select_active_windows(root, wflists);
else
parse->hasWindowFuncs = false;
}
/*
* Preprocess MIN/MAX aggregates, if any. Note: be careful about
* adding logic between here and the query_planner() call. Anything
* that is needed in MIN/MAX-optimizable cases will have to be
* duplicated in planagg.c.
*/
if (parse->hasAggs)
preprocess_minmax_aggregates(root, tlist);
/*
* Figure out whether there's a hard limit on the number of rows that
* query_planner's result subplan needs to return. Even if we know a
* hard limit overall, it doesn't apply if the query has any
* grouping/aggregation operations, or SRFs in the tlist.
*/
if (parse->groupClause ||
parse->groupingSets ||
parse->distinctClause ||
parse->hasAggs ||
parse->hasWindowFuncs ||
parse->hasTargetSRFs ||
root->hasHavingQual)
root->limit_tuples = -1.0;
else
root->limit_tuples = limit_tuples;
/* Set up data needed by standard_qp_callback */
qp_extra.tlist = tlist;
qp_extra.activeWindows = activeWindows;
qp_extra.groupClause = (gset_data
? (gset_data->rollups ? ((RollupData *) linitial(gset_data->rollups))->groupClause : NIL)
: parse->groupClause);
/*
* Generate the best unsorted and presorted paths for the scan/join
* portion of this Query, ie the processing represented by the
* FROM/WHERE clauses. (Note there may not be any presorted paths.)
* We also generate (in standard_qp_callback) pathkey representations
* of the query's sort clause, distinct clause, etc.
*/
current_rel = query_planner(root, tlist,
standard_qp_callback, &qp_extra);
/*
* Convert the query's result tlist into PathTarget format.
*
* Note: it's desirable to not do this till after query_planner(),
* because the target width estimates can use per-Var width numbers
* that were obtained within query_planner().
*/
final_target = create_pathtarget(root, tlist);
/*
* If ORDER BY was given, consider whether we should use a post-sort
* projection, and compute the adjusted target for preceding steps if
* so.
*/
if (parse->sortClause)
sort_input_target = make_sort_input_target(root,
final_target,
&have_postponed_srfs);
else
sort_input_target = final_target;
/*
* If we have window functions to deal with, the output from any
* grouping step needs to be what the window functions want;
* otherwise, it should be sort_input_target.
*/
if (activeWindows)
grouping_target = make_window_input_target(root,
final_target,
activeWindows);
else
grouping_target = sort_input_target;
/*
* If we have grouping or aggregation to do, the topmost scan/join
* plan node must emit what the grouping step wants; otherwise, it
* should emit grouping_target.
*/
have_grouping = (parse->groupClause || parse->groupingSets ||
parse->hasAggs || root->hasHavingQual);
if (have_grouping)
scanjoin_target = make_group_input_target(root, final_target);
else
scanjoin_target = grouping_target;
/*
* If there are any SRFs in the targetlist, we must separate each of
* these PathTargets into SRF-computing and SRF-free targets. Replace
* each of the named targets with a SRF-free version, and remember the
* list of additional projection steps we need to add afterwards.
*/
if (parse->hasTargetSRFs)
{
/* final_target doesn't recompute any SRFs in sort_input_target */
split_pathtarget_at_srfs(root, final_target, sort_input_target,
&final_targets,
&final_targets_contain_srfs);
final_target = (PathTarget *) linitial(final_targets);
Assert(!linitial_int(final_targets_contain_srfs));
/* likewise for sort_input_target vs. grouping_target */
split_pathtarget_at_srfs(root, sort_input_target, grouping_target,
&sort_input_targets,
&sort_input_targets_contain_srfs);
sort_input_target = (PathTarget *) linitial(sort_input_targets);
Assert(!linitial_int(sort_input_targets_contain_srfs));
/* likewise for grouping_target vs. scanjoin_target */
split_pathtarget_at_srfs(root, grouping_target, scanjoin_target,
&grouping_targets,
&grouping_targets_contain_srfs);
grouping_target = (PathTarget *) linitial(grouping_targets);
Assert(!linitial_int(grouping_targets_contain_srfs));
/* scanjoin_target will not have any SRFs precomputed for it */
split_pathtarget_at_srfs(root, scanjoin_target, NULL,
&scanjoin_targets,
&scanjoin_targets_contain_srfs);
scanjoin_target = (PathTarget *) linitial(scanjoin_targets);
Assert(!linitial_int(scanjoin_targets_contain_srfs));
}
else
{
/* initialize lists, just to keep compiler quiet */
final_targets = final_targets_contain_srfs = NIL;
sort_input_targets = sort_input_targets_contain_srfs = NIL;
grouping_targets = grouping_targets_contain_srfs = NIL;
scanjoin_targets = scanjoin_targets_contain_srfs = NIL;
}
/*
* Forcibly apply SRF-free scan/join target to all the Paths for the
* scan/join rel.
*
* In principle we should re-run set_cheapest() here to identify the
* cheapest path, but it seems unlikely that adding the same tlist
* eval costs to all the paths would change that, so we don't bother.
* Instead, just assume that the cheapest-startup and cheapest-total
* paths remain so. (There should be no parameterized paths anymore,
* so we needn't worry about updating cheapest_parameterized_paths.)
*/
foreach(lc, current_rel->pathlist)
{
Path *subpath = (Path *) lfirst(lc);
Path *path;
Assert(subpath->param_info == NULL);
path = apply_projection_to_path(root, current_rel,
subpath, scanjoin_target);
/* If we had to add a Result, path is different from subpath */
if (path != subpath)
{
lfirst(lc) = path;
if (subpath == current_rel->cheapest_startup_path)
current_rel->cheapest_startup_path = path;
if (subpath == current_rel->cheapest_total_path)
current_rel->cheapest_total_path = path;
}
}
/*
* Upper planning steps which make use of the top scan/join rel's
* partial pathlist will expect partial paths for that rel to produce
* the same output as complete paths ... and we just changed the
* output for the complete paths, so we'll need to do the same thing
* for partial paths. But only parallel-safe expressions can be
* computed by partial paths.
*/
if (current_rel->partial_pathlist &&
is_parallel_safe(root, (Node *) scanjoin_target->exprs))
{
/* Apply the scan/join target to each partial path */
foreach(lc, current_rel->partial_pathlist)
{
Path *subpath = (Path *) lfirst(lc);
Path *newpath;
/* Shouldn't have any parameterized paths anymore */
Assert(subpath->param_info == NULL);
/*
* Don't use apply_projection_to_path() here, because there
* could be other pointers to these paths, and therefore we
* mustn't modify them in place.
*/
newpath = (Path *) create_projection_path(root,
current_rel,
subpath,
scanjoin_target);
lfirst(lc) = newpath;
}
}
else
{
/*
* In the unfortunate event that scanjoin_target is not
* parallel-safe, we can't apply it to the partial paths; in that
* case, we'll need to forget about the partial paths, which
* aren't valid input for upper planning steps.
*/
current_rel->partial_pathlist = NIL;
}
/* Now fix things up if scan/join target contains SRFs */
if (parse->hasTargetSRFs)
adjust_paths_for_srfs(root, current_rel,
scanjoin_targets,
scanjoin_targets_contain_srfs);
/*
* Save the various upper-rel PathTargets we just computed into
* root->upper_targets[]. The core code doesn't use this, but it
* provides a convenient place for extensions to get at the info. For
* consistency, we save all the intermediate targets, even though some
* of the corresponding upperrels might not be needed for this query.
*/
root->upper_targets[UPPERREL_FINAL] = final_target;
root->upper_targets[UPPERREL_WINDOW] = sort_input_target;
root->upper_targets[UPPERREL_GROUP_AGG] = grouping_target;
/*
* If we have grouping and/or aggregation, consider ways to implement
* that. We build a new upperrel representing the output of this
* phase.
*/
if (have_grouping)
{
current_rel = create_grouping_paths(root,
current_rel,
grouping_target,
&agg_costs,
gset_data);
/* Fix things up if grouping_target contains SRFs */
if (parse->hasTargetSRFs)
adjust_paths_for_srfs(root, current_rel,
grouping_targets,
grouping_targets_contain_srfs);
}
/*
* If we have window functions, consider ways to implement those. We
* build a new upperrel representing the output of this phase.
*/
if (activeWindows)
{
current_rel = create_window_paths(root,
current_rel,
grouping_target,
sort_input_target,
tlist,
wflists,
activeWindows);
/* Fix things up if sort_input_target contains SRFs */
if (parse->hasTargetSRFs)
adjust_paths_for_srfs(root, current_rel,
sort_input_targets,
sort_input_targets_contain_srfs);
}
/*
* If there is a DISTINCT clause, consider ways to implement that. We
* build a new upperrel representing the output of this phase.
*/
if (parse->distinctClause)
{
current_rel = create_distinct_paths(root,
current_rel);
}
} /* end of if (setOperations) */
/*
* If ORDER BY was given, consider ways to implement that, and generate a
* new upperrel containing only paths that emit the correct ordering and
* project the correct final_target. We can apply the original
* limit_tuples limit in sort costing here, but only if there are no
* postponed SRFs.
*/
if (parse->sortClause)
{
current_rel = create_ordered_paths(root,
current_rel,
final_target,
have_postponed_srfs ? -1.0 :
limit_tuples);
/* Fix things up if final_target contains SRFs */
if (parse->hasTargetSRFs)
adjust_paths_for_srfs(root, current_rel,
final_targets,
final_targets_contain_srfs);
}
/*
* Now we are prepared to build the final-output upperrel.
*/
final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
/*
* If the input rel is marked consider_parallel and there's nothing that's
* not parallel-safe in the LIMIT clause, then the final_rel can be marked
* consider_parallel as well. Note that if the query has rowMarks or is
* not a SELECT, consider_parallel will be false for every relation in the
* query.
*/
if (current_rel->consider_parallel &&
is_parallel_safe(root, parse->limitOffset) &&
is_parallel_safe(root, parse->limitCount))
final_rel->consider_parallel = true;
/*
* If the current_rel belongs to a single FDW, so does the final_rel.
*/
final_rel->serverid = current_rel->serverid;
final_rel->userid = current_rel->userid;
final_rel->useridiscurrent = current_rel->useridiscurrent;
final_rel->fdwroutine = current_rel->fdwroutine;
/*
* Generate paths for the final_rel. Insert all surviving paths, with
* LockRows, Limit, and/or ModifyTable steps added if needed.
*/
foreach(lc, current_rel->pathlist)
{
Path *path = (Path *) lfirst(lc);
/*
* If there is a FOR [KEY] UPDATE/SHARE clause, add the LockRows node.
* (Note: we intentionally test parse->rowMarks not root->rowMarks
* here. If there are only non-locking rowmarks, they should be
* handled by the ModifyTable node instead. However, root->rowMarks
* is what goes into the LockRows node.)
*/
if (parse->rowMarks)
{
path = (Path *) create_lockrows_path(root, final_rel, path,
root->rowMarks,
SS_assign_special_param(root));
}
/*
* If there is a LIMIT/OFFSET clause, add the LIMIT node.
*/
if (limit_needed(parse))
{
path = (Path *) create_limit_path(root, final_rel, path,
parse->limitOffset,
parse->limitCount,
offset_est, count_est);
}
/*
* If this is an INSERT/UPDATE/DELETE, and we're not being called from
* inheritance_planner, add the ModifyTable node.
*/
if (parse->commandType != CMD_SELECT && !inheritance_update)
{
List *withCheckOptionLists;
List *returningLists;
List *rowMarks;
/*
* Set up the WITH CHECK OPTION and RETURNING lists-of-lists, if
* needed.
*/
if (parse->withCheckOptions)
withCheckOptionLists = list_make1(parse->withCheckOptions);
else
withCheckOptionLists = NIL;
if (parse->returningList)
returningLists = list_make1(parse->returningList);
else
returningLists = NIL;
/*
* If there was a FOR [KEY] UPDATE/SHARE clause, the LockRows node
* will have dealt with fetching non-locked marked rows, else we
* need to have ModifyTable do that.
*/
if (parse->rowMarks)
rowMarks = NIL;
else
rowMarks = root->rowMarks;
path = (Path *)
create_modifytable_path(root, final_rel,
parse->commandType,
parse->canSetTag,
parse->resultRelation,
NIL,
list_make1_int(parse->resultRelation),
list_make1(path),
list_make1(root),
withCheckOptionLists,
returningLists,
rowMarks,
parse->onConflict,
SS_assign_special_param(root));
}
/* And shove it into final_rel */
add_path(final_rel, path);
}
/*
* If there is an FDW that's responsible for all baserels of the query,
* let it consider adding ForeignPaths.
*/
if (final_rel->fdwroutine &&
final_rel->fdwroutine->GetForeignUpperPaths)
final_rel->fdwroutine->GetForeignUpperPaths(root, UPPERREL_FINAL,
current_rel, final_rel);
/* Let extensions possibly add some more paths */
if (create_upper_paths_hook)
(*create_upper_paths_hook) (root, UPPERREL_FINAL,
current_rel, final_rel);
/* Note: currently, we leave it to callers to do set_cheapest() */
}
我们再来详细看一看Plan结构体到底是什么样呢。(路径:src/include/nodes/plannodes.h)
typedef struct Plan
{
NodeTag type;
/*
* estimated execution costs for plan (see costsize.c for more info)
*/
Cost startup_cost; /* cost expended before fetching any tuples */
Cost total_cost; /* total cost (assuming all tuples fetched) */
/*
* planner's estimate of result size of this plan step
*/
double plan_rows; /* number of rows plan is expected to emit */
int plan_width; /* average row width in bytes */
/*
* information needed for parallel query
*/
bool parallel_aware; /* engage parallel-aware logic? */
bool parallel_safe; /* OK to use as part of parallel plan? */
/*
* Common structural data for all Plan types.
*/
int plan_node_id; /* unique across entire final plan tree */
List *targetlist; /* target list to be computed at this node */
List *qual; /* implicitly-ANDed qual conditions */
struct Plan *lefttree; /* input plan tree(s) */
struct Plan *righttree;
List *initPlan; /* Init Plan nodes (un-correlated expr
* subselects) */
/*
* Information for management of parameter-change-driven rescanning
*
* extParam includes the paramIDs of all external PARAM_EXEC params
* affecting this plan node or its children. setParam params from the
* node's initPlans are not included, but their extParams are.
*
* allParam includes all the extParam paramIDs, plus the IDs of local
* params that affect the node (i.e., the setParams of its initplans).
* These are _all_ the PARAM_EXEC params that affect this node.
*/
Bitmapset *extParam;
Bitmapset *allParam;
} Plan;

此时,可能会有小伙伴想问:Plan结构体和PlannerInfo结构体有什么关系呢?
解释:Plan 结构体和 PlannerInfo 结构体是 PostgreSQL 查询规划器中两个重要的数据结构。在查询规划的过程中,PlannerInfo 结构体起到了承上启下的作用,它存储了查询的所有信息,作为规划器的中间状态。而每个 Plan 结构体则表示了一个具体的执行计划,它们之间是一一对应的关系。在查询规划的过程中,规划器会根据 PlannerInfo 中的信息生成一个 Plan 结构体的树状结构,表示整个查询的最终执行计划。因此,PlannerInfo 结构体和 Plan 结构体是查询规划器中两个紧密相关的数据结构。
还不是很清楚?没关系,我们再详细的了解一下:
- Plan 结构体:
- Plan 结构体是用于表示查询的执行计划的数据结构。它是一个抽象的计划节点,包含了执行查询所需的所有信息,如执行方式、访问路径、筛选条件、聚合操作、排序方式等。
- Plan 结构体是一个抽象基类,具体的执行计划类型会继承自 Plan 结构体并包含额外的字段来存储特定类型的执行计划信息。
- 在查询规划的过程中,规划器会根据查询的结构和要求生成一个 Plan 结构体的树状结构,表示整个查询的执行计划。
- PlannerInfo 结构体:
- PlannerInfo 结构体是用于存储查询规划器的中间状态信息的数据结构。它包含了查询的所有信息,如查询树、目标列表、查询条件、关联表信息、约束条件等。
- PlannerInfo 结构体是在查询规划过程中创建的,用于在不同的查询规划函数之间传递信息,并记录查询规划的中间状态。
- PlannerInfo 结构体中的字段可以帮助规划器优化查询,例如选择最优的执行计划、使用合适的索引、处理连接操作等。
总结
到此,我们已经初步了解了查询规划中的基本处理流程。在后面的学习中,我们会拆分着学习查询规划中的具体模块。