文章目录
- TL;DR
- Introduction
- 背景
- 本文方案
- 实现方式
- 预训练
- 预训练数据
- 训练细节
- 训练硬件支持
- 预训练碳足迹
- 微调
- SFT
- SFT 训练细节
- RLHF
- 人类偏好数据收集
- 奖励模型
- 迭代式微调(RLHF)
- 拒绝采样(Rejection Sampling)
- PPO
- 多轮一致性的系统消息(System Message for Multi-Turn Consistency)
- 安全性
- 预训练中的安全性
- 讨论
- 学习和观察
- 基于上下文的温度系数缩放(In-Context Temperature Rescaling)
- Llama2 Chat 对时间的感知
- 工具使用涌现能力
- 实验结果
- 预训练
- 与开源基础模型的精度对比
- 与闭源模型对比
- RLHF
- 奖励模型精度
- 基于模型的评估结果
- 基于人工的评测结果
- 安全性
- 定量评估
- RLHF 对安全性的提升
- 安全性 scaling 实验
- 安全性对比实验
- 消融实验
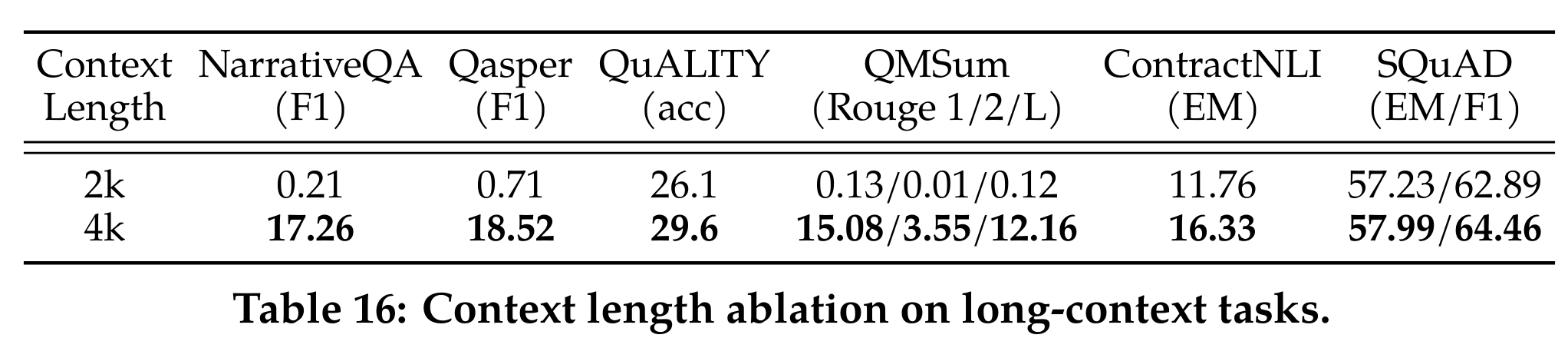
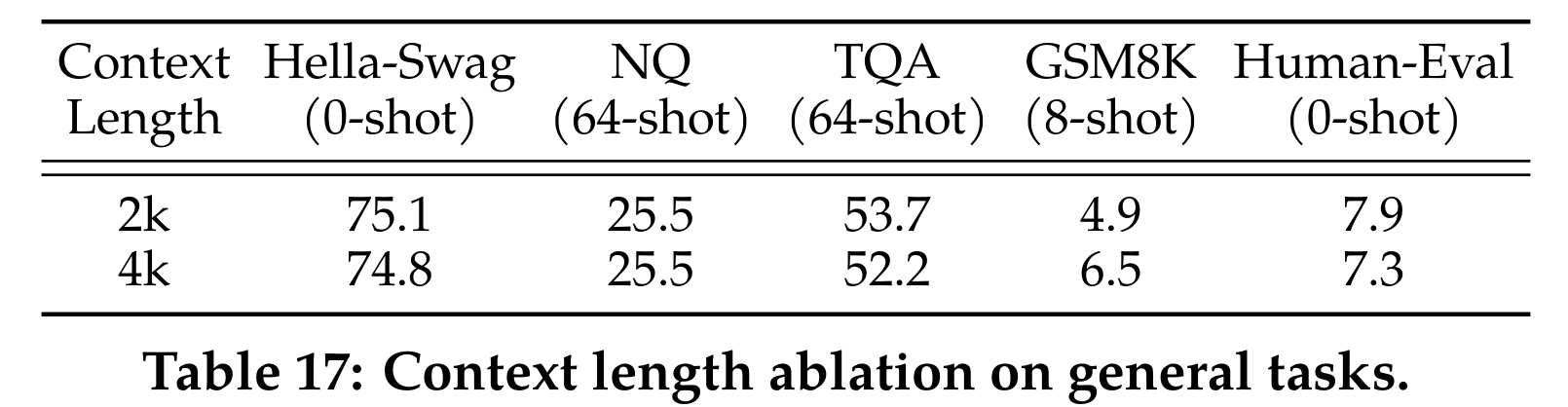
- 上下文增加带来的性能提升
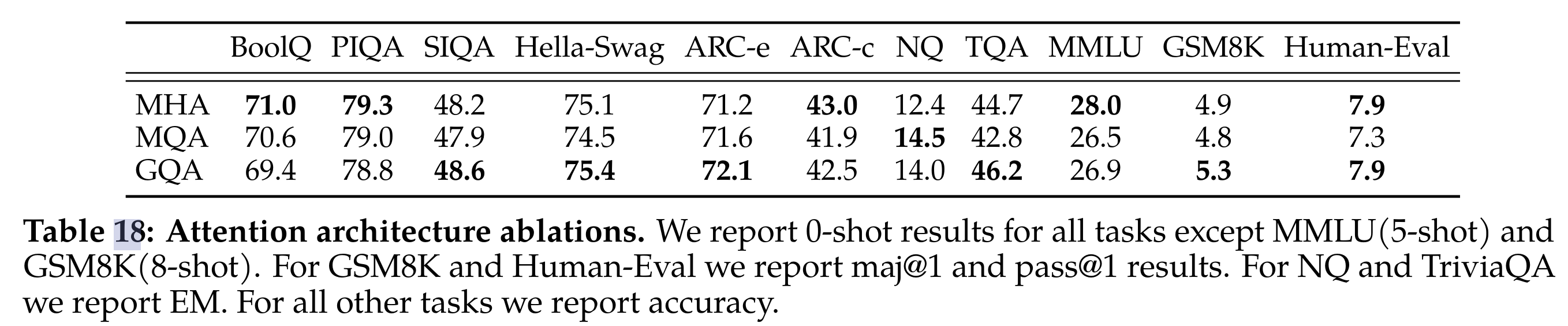
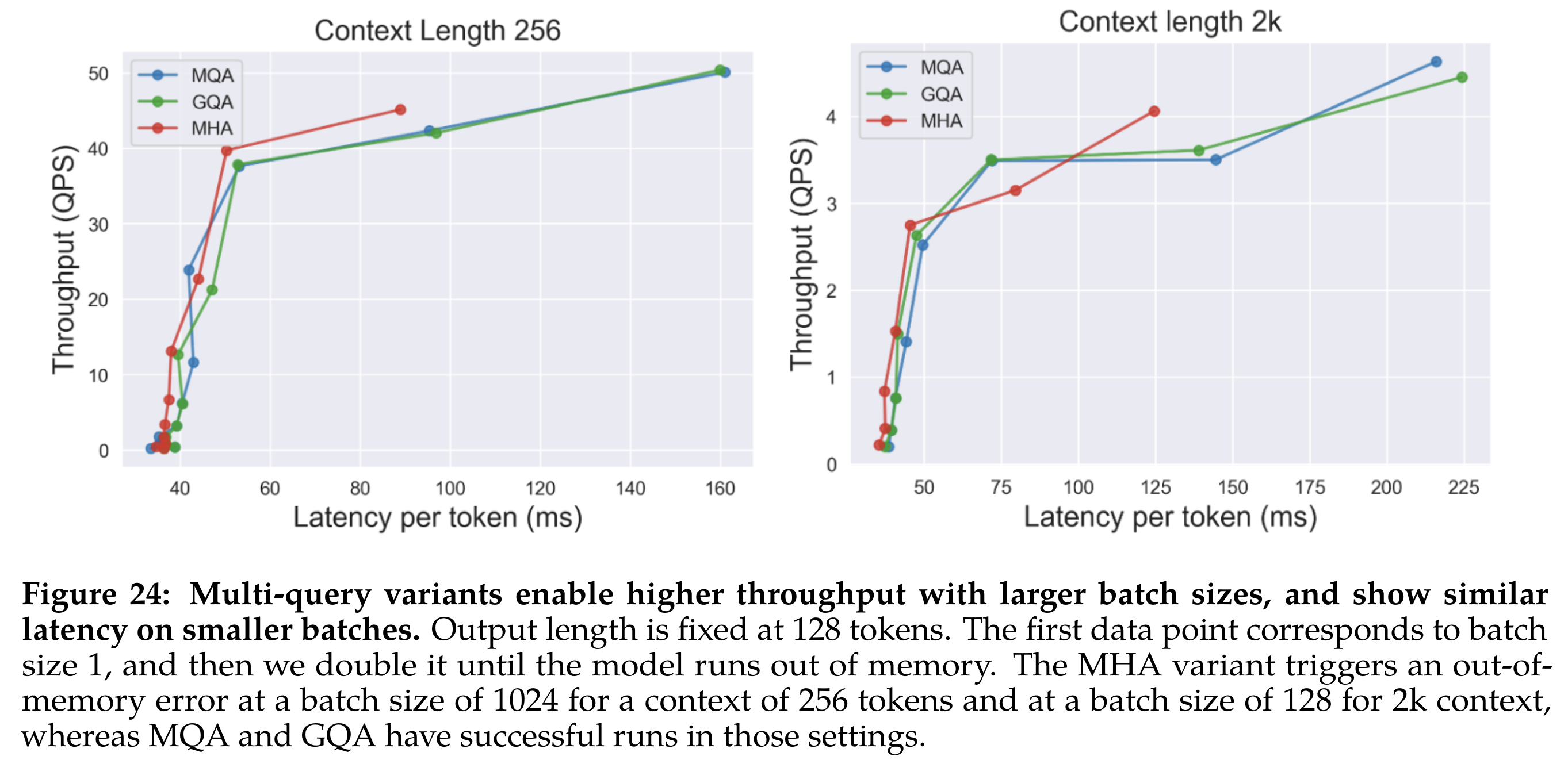
- GQA 对比 MHA 和 MQA
- Thoughts
Paper name
Llama 2: Open Foundation and Fine-Tuned Chat Models
Paper Reading Note
Paper URL: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Blog URL:https://huggingface.co/blog/llama2
TL;DR
- Meta 出品的 Llama 续作 Llama2,一系列模型(7b、13b、70b)均开源可商用。Llama2 在各个榜单上精度全面超过 Llama1,同时也超过目前所有开源模型。本文非常详细地介绍了 Llama2 的预训练、SFT、RLHF 的所有细节,同时也从模型训练的安全性、环保性等各个角度进行了详细分析。
- 值得精读的大模型研发文章。
Introduction
背景
- 尽快 LLM 训练方法很直观:基于自回归的 transformer 模型,在大量预料上做自监督训练,然后通过人类反馈强化学习 (RLHF) 等技术来与人类偏好对齐。但高计算需求限制了 LLM 只能由少数玩家来推动发展
- 现有的开源大模型,例如 BLOOM、Llama1、Falcon,虽然都能基本达到匹配非开源大模型(如 GPT-3、Chinchilla)的能力,但这些模型都不适合成为非开源产品级 LLM (比如 ChatGPT、BARD、Claude)的替代品,因为这些封闭的产品级 LLM 经过大量微调,与人类的偏好保持一致,大大提高了它们的可用性和安全性。这一步在计算和人工标注中需要大量的成本,而且往往不透明或容易重现,限制了社区的进步,以促进AI对齐研究
本文方案
- 开发并发布了 Llama 2,包含预训练的大语言模型和微调大语言模型,模型规模有 7b、13b、70b 这三种(还有个没有开源的 34b 版本)
- 预训练预料增加了 40%
- context length 从 2048 提升到 4096
- 70b模型使用了 grouped-query attention (GQA)
- 提供了微调版本的 LLM,称为 Llama 2-Chat,针对对话用例进行了优化
- Llama2 在大多数基准测试中都优于开源聊天模型,并且基于有用性和安全性方向进行人工评估,期望称为封闭源模型(chatgpt等)的合适替代品
- 提供了对 Llama 2-Chat 微调和安全改进的方法的详细描述,为开源社区做出贡献
- Llama2 似乎也与一些封闭源模型相当,至少在本文执行的人工评估上,如以下图片所示
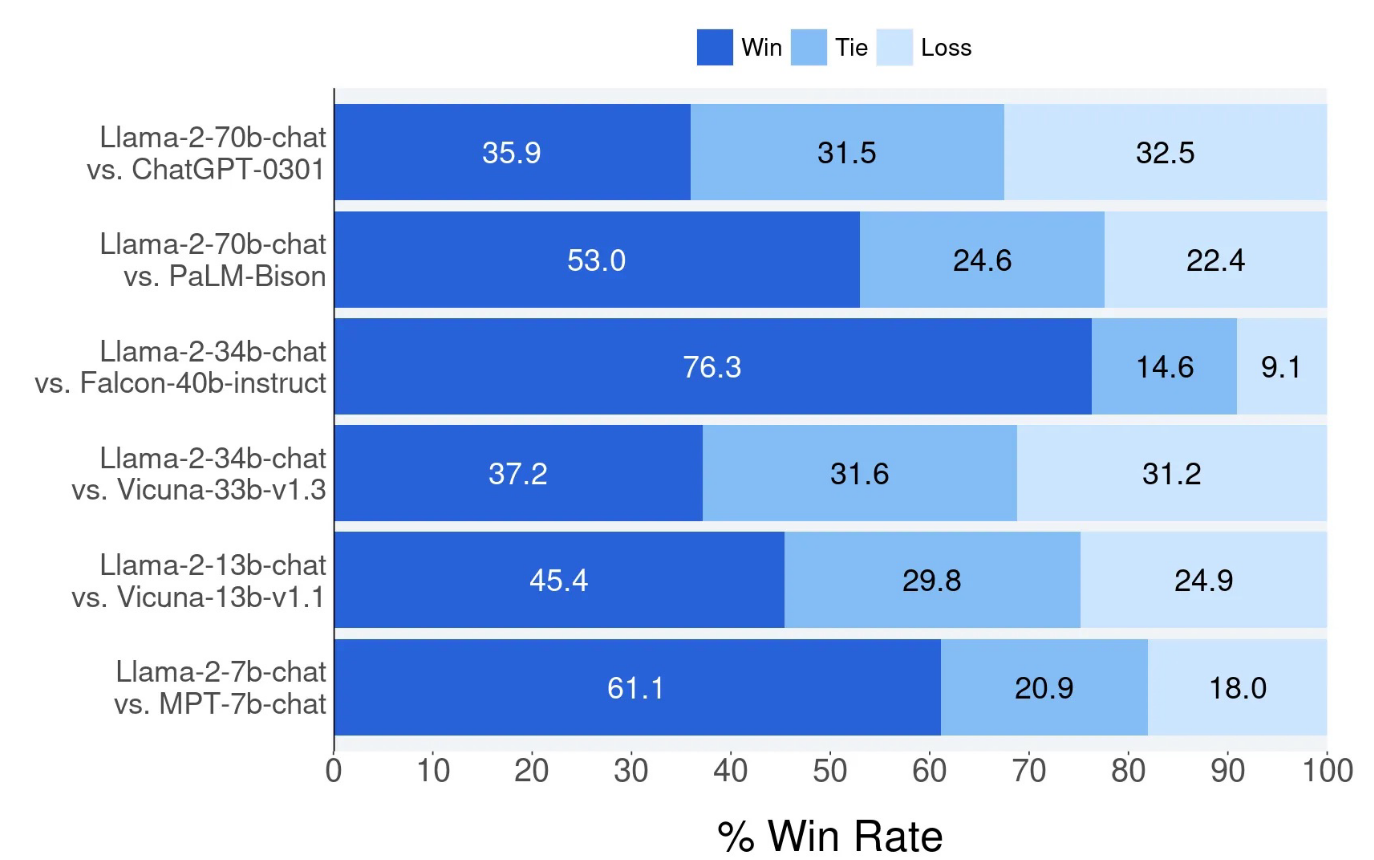
以上实验基于人工进行 helpfuless 方面的评估,在 4k 个单轮或多轮的 prompt 下测试得到的结论
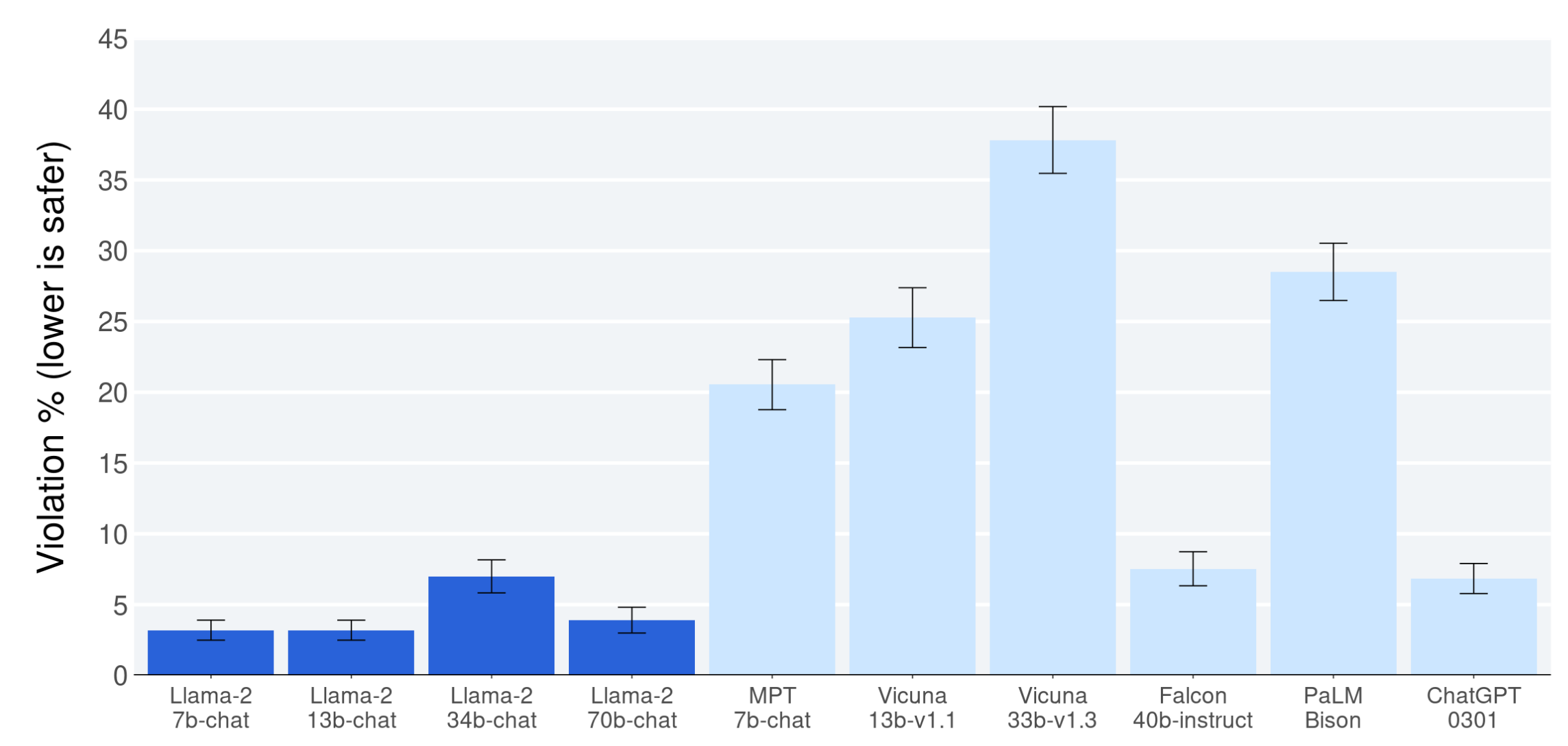
在大约 2000 个 adversarial prompt 的数据上测试模型的安全性,可以看到 Llama 的安全性很不错
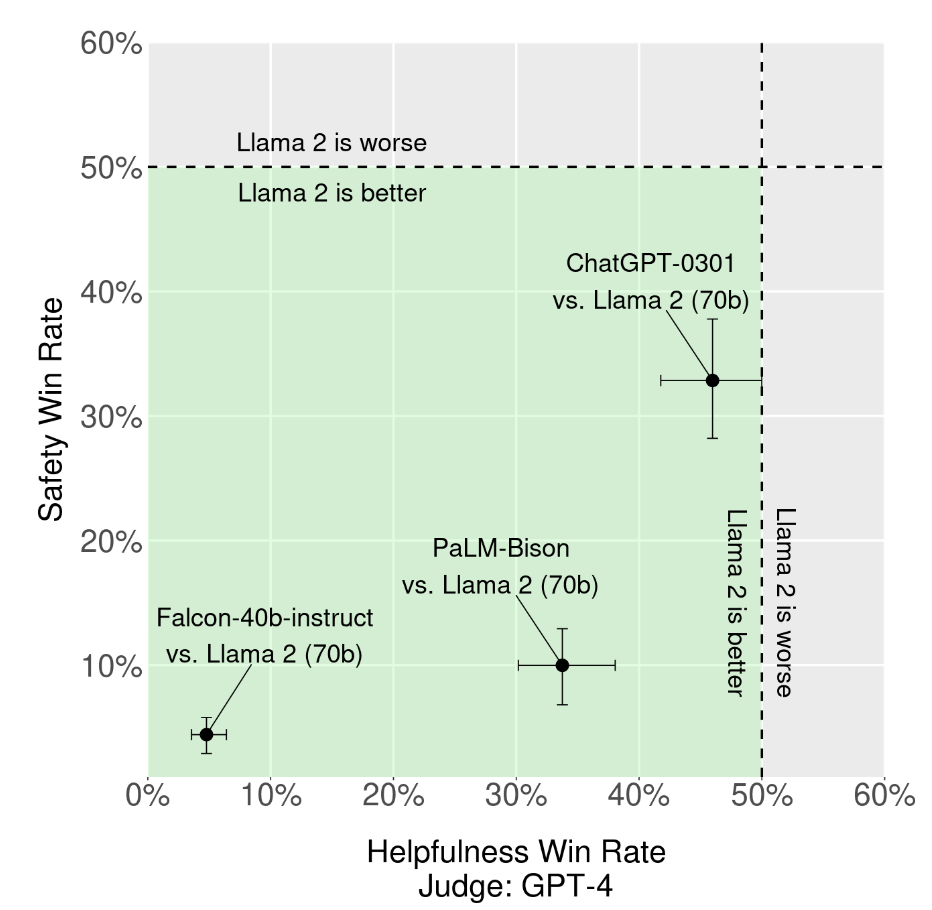
综合对比结果来看,绿色区域代表 Llama2 更强,可以看到 Llama2 在帮助性、安全性方面都强于目前主流开源模型,甚至比部分闭源模型要好
实现方式
- 这个过程始于使用公开可用的在线数据源对 Llama 2 进行预训练。接下来,通过应用监督微调来创建 Llama 2-Chat 的初始版本。随后,使用带有人类反馈 (RLHF) 方法的强化学习迭代地改进模型,特别是通过拒绝采样和近端策略优化 (PPO)。在 RLHF 阶段,迭代奖励建模数据与模型增强并行的累积对于确保奖励模型保持在分布内至关重要
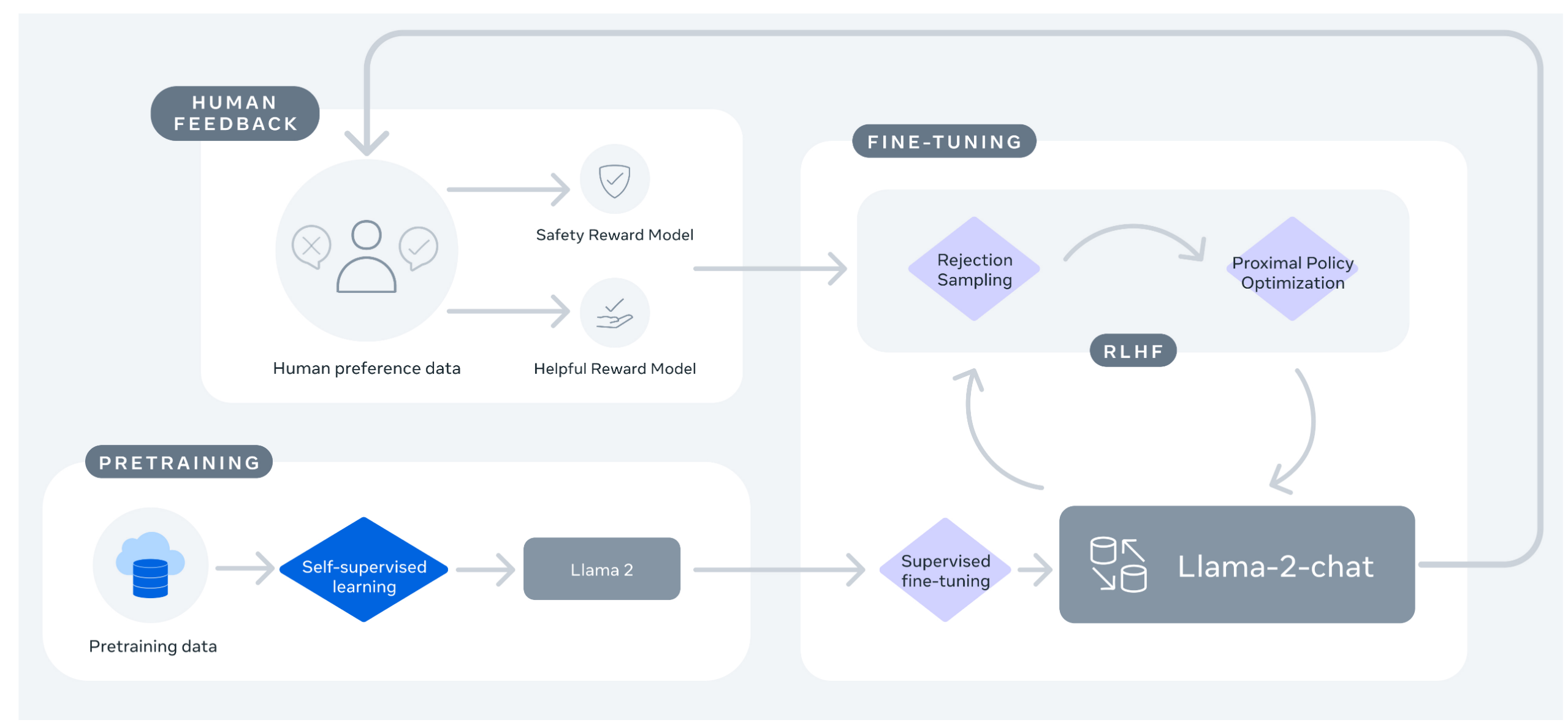
预训练
- 模型结构延续 Llama 中的自回归 transformer 结构
- 使用更鲁棒的数据清洗
- 更新数据混合策略
- 在 40% 更多的 token 上进行训练
- context length 扩展了两倍
- 使用 grouped-query attention (GQA)
- 相比于 Llama1 的优化汇总在以下表格中
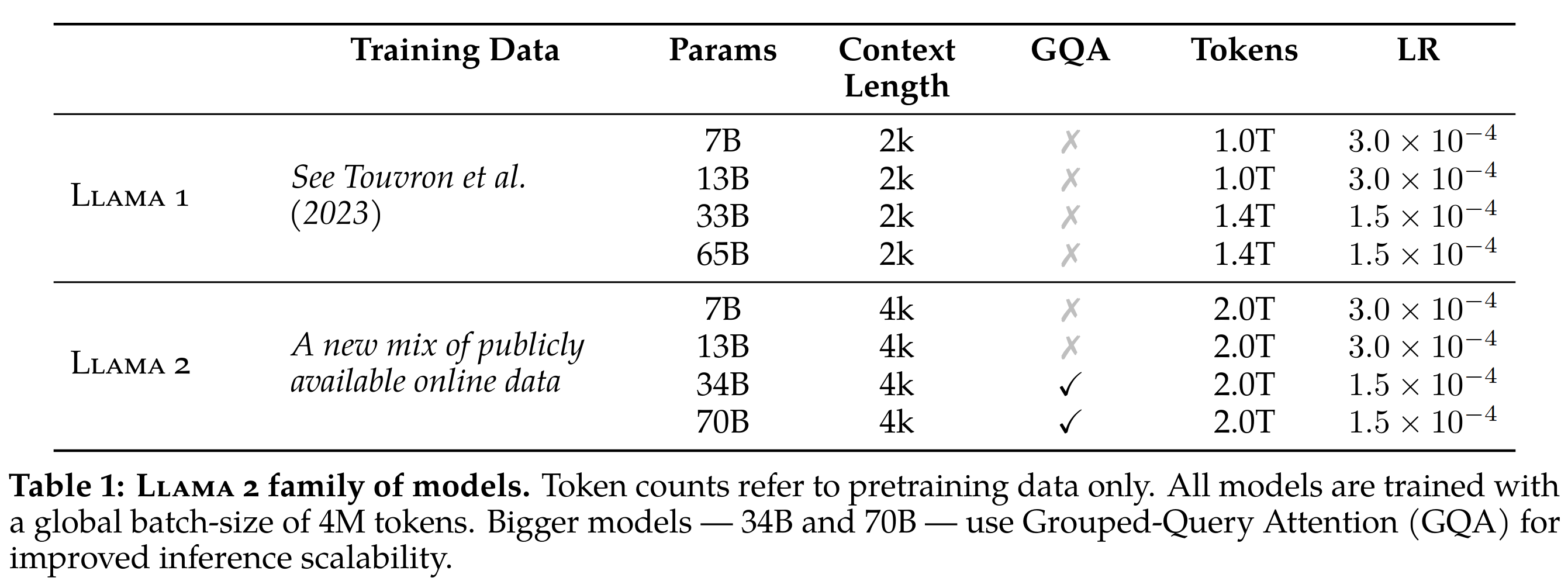
预训练数据
- 训练语料库包括来自公开可用来源的新混合数据,不包括来自 Meta 产品或服务的数据。努力从已知包含大量关于私人的个人信息的某些站点中删除敏感数据。
- 在 2 万亿个数据上进行训练,因为这提供了良好的性能-成本权衡
- 对大多数事实源数据进行过采样,以增加知识和抑制幻觉
训练细节
- 采用 Llama 1 的大部分预训练设置和模型架构
- 使用标准的 transformer 结构,使用 RMSNorm 应用 pre-norm
- 使用 SwiGLU activation function
- RoPE
- 与 Llama 1 的主要架构差异包括上下文长度和分组查询注意力 (GQA) 的增加
- GQA 介绍:
- 自回归解码的标准做法是缓存序列中先前 token 的键 (K) 和值 (V) 对,以加快注意力计算。然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA) 模型中与 KV 缓存大小相关的内存成本显着增加。对于更大的模型,其中 KV 缓存大小成为一个瓶颈,键和值投影可以跨多个头共享,而不会大大降低性能。
- 对于上述这种情况有两种主流解决方案
- MQA:具有单个KV投影的原始多查询格式
- GQA:具有 8 个KV投影的分组查询注意力变体
- 选择 GQA 的原因
- 本文做了一系列实验证明 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均而言优于 MQA 变体
- 为了优化延迟,需要在具有张量并行性的单个节点中使用 8 A100 托管最大的模型,在这种情况下,MQA 的分片不能再跨头完成,因为头的数量低于 GPU 的数量。要么复制所有 GPU 中的 KV 值(使 KV 缓存大小等于 GQA),要么另一种选择是跨批次维度分片。然而,跨批次维度分片可能会使推理服务复杂化,因为它只当批量大小大于分片的数量并且额外的通信成本在所有情况下都不值得它
- 训练超参数
- AdamW optimizer
- 学习率:余弦学习率,2000 step 的 warmup,最后 decay 到峰值学习率的 10%
- weight decay 0.1
- gradient clipping:1.0
- 训练 loss 曲线如下所示,即便训练了 2T 的 token 也暂时没有看到饱和现象:
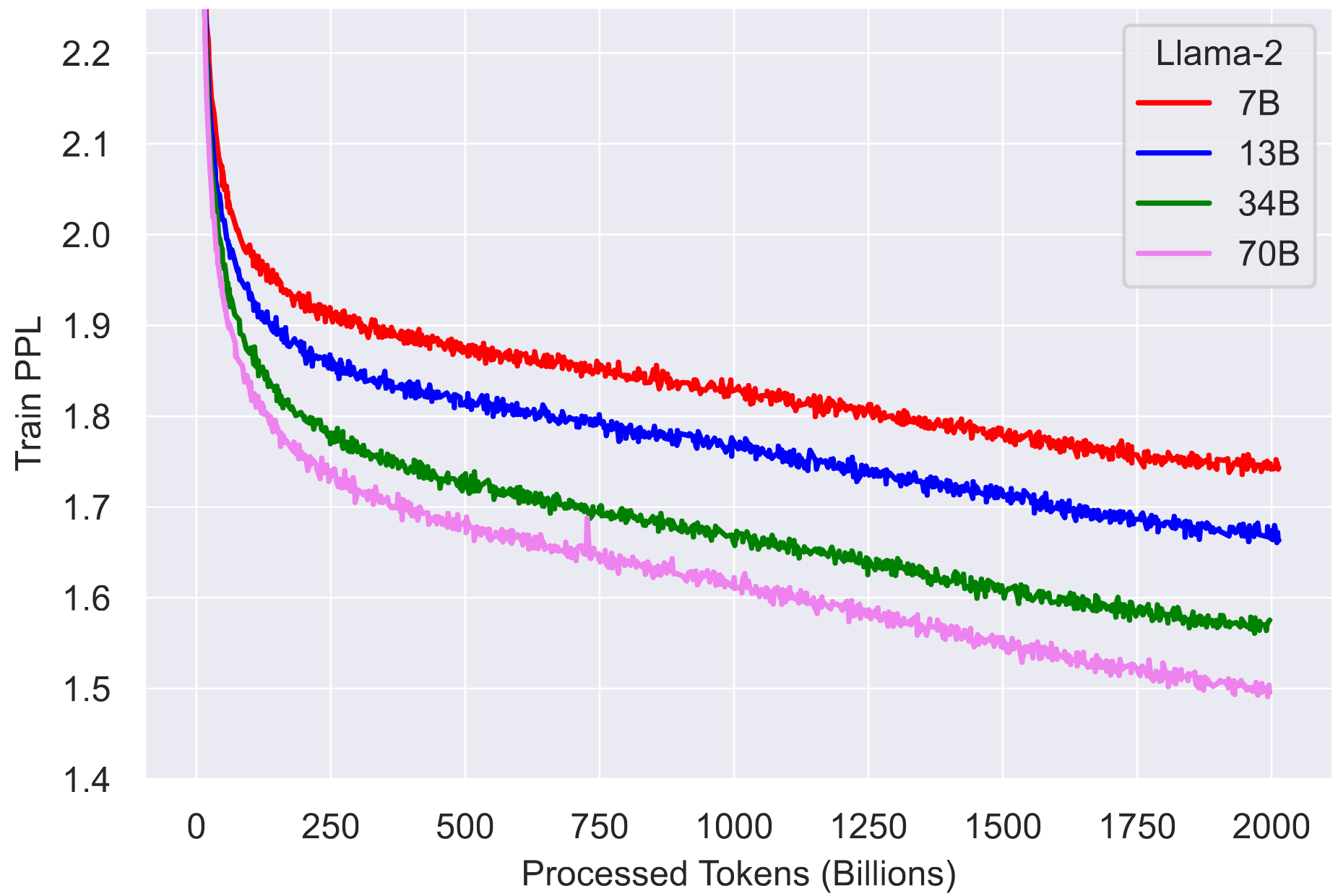
- tokenizer:和 llama1 一样的 tokenizer,使用 SentencePiece 实现的 BPE 算法。与 Llama 1 一样,将所有数字拆分为单个数字并使用字节来分解未知的 UTF-8 字符。总词汇量为 32k 个 token
训练硬件支持
- 在两个集群上做了实验:Meta’s Research Super Cluster (RSC) 和 Meta 内部集群
- 所有集群都使用 A100
- RSC 使用 NVIDIA Quantum InfiniBand,内部集群使用 RoCE (RDMA over converged Ethernet)
- 每GPU功耗上限:RSC 是 400W,内部集群是 350W
- RoCE(这是一个更实惠的商业互连网络),几乎可以扩展和昂贵的Infiniband一样高达2000个gpu的规模,这使得预训练更加民主化
- ChatGPT 对 RoCE 和 NVIDIA Quantum InfiniBand 进行对比
- 性能:两种技术都具有低延迟和高带宽的特点,因此它们都适用于要求严苛的HPC和AI工作负载。虽然NVIDIA Quantum InfiniBand专门针对其GPU加速系统进行了优化,但RoCE提供了更通用的以太网上RDMA功能。
- 网络基础设施:RoCE具有在集成方面的优势,因为它可以在现有的以太网网络中部署,无需专用的InfiniBand硬件。而NVIDIA Quantum InfiniBand则需要专用的InfiniBand交换机和网络基础设施。
- 厂商特定与标准技术:NVIDIA Quantum InfiniBand是由NVIDIA开发的专有技术,而RoCE是基于标准RDMA和以太网协议的,因此更具厂商无关性,并得到了广泛采用。
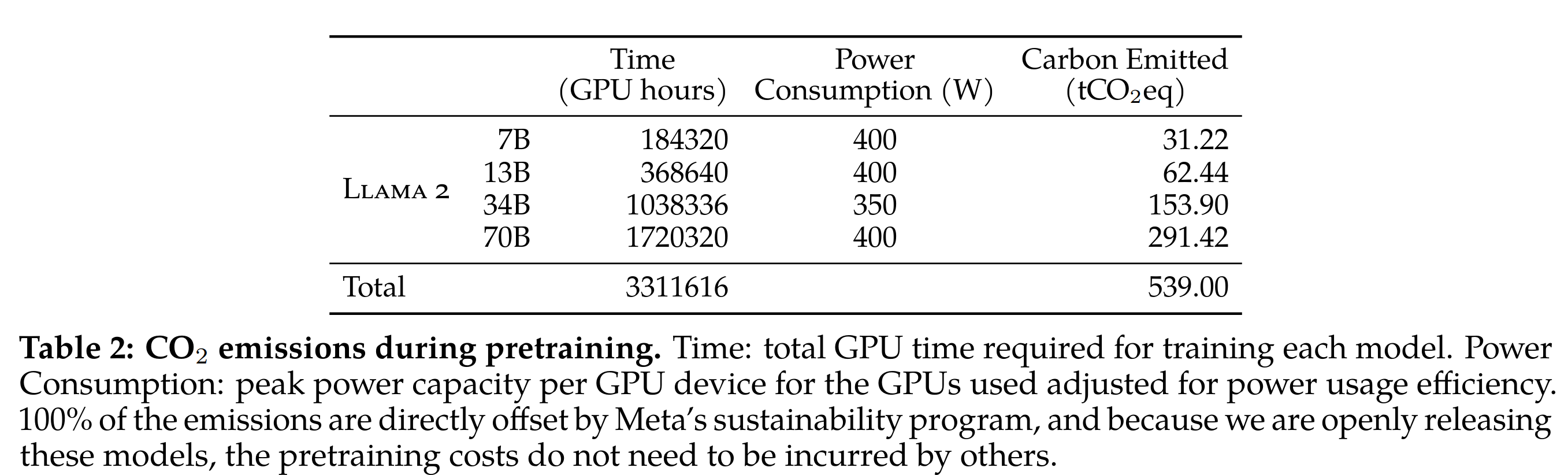
预训练碳足迹
- 碳排放也在本文中有了定量的考量计算,也提到开源就是为了避免让其他公司来做类似的事情来增加碳排放(不过这是不是不包含试错成本…)
微调
SFT
- Quality Is All You Need
- 第三方SFT数据可从许多不同的来源获得,但本文发现其中许多数据具有的多样性和质量不足——特别是对于将 LLM 与对话风格的指令对齐
- 因此本文首先专注于收集数千个高质量的SFT数据示例,如下表中所示

只通过几千个高质量的数据训练的模型效果就优于大规模开源 SFT 训练的模型,这与 Lima 的发现类似:有限的干净指令调优数据足以达到高水平的质量 - 本文发现,数量级为数万的 SFT 标注数据足以获得高质量的结果。本文在总共收集了 27,540 个注释后停止标注 SFT 数据
- 我们还观察到不同的注释平台和供应商可能导致明显不同的下游模型性能,这突显了即使使用供应商来获取注释时进行数据检查的重要性。为了验证我们的数据质量,我们仔细检查了一组180个样例,将人工提供的注释与模型生成的样本进行手工审查进行了比较。令人惊讶的是,我们发现从结果SFT模型中采样的输出往往可以与人类标注者手写的SFT数据相竞争,这表明我们可以重新设置优先级,并将更多的注释工作投入到基于偏好的RLHF(Reinforcement Learning from Human Feedback)注释中
SFT 训练细节
- 余弦学习率,初始学习率 2e-5,weight decay 0.1,bs 64,seq len=4096
- 对于微调过程,每个样本由一个提示(prompt)和一个答案(answer)组成。为了确保模型的序列长度得到正确填充,将训练集中的所有提示和答案连接在一起。使用一个特殊的 token 将提示和答案分隔开。
- 采用自回归目标(autoregressive objective)并将用户提示中的标记损失设为零,因此我们只在答案标记上进行反向传播。最后,我们对模型进行2个 epoch 的微调
RLHF
人类偏好数据收集
- 选择了与其他方案(比如 InstructGPT)不一样的二元比较数据,主要是因为它允许我们最大化收集到的提示的多样性,多元比较数据作为未来工作
- 标注过程
- 标注员写一个 prompt
- 根据提供的标准在两个模型回复中选择更好的回复。为了早呢更加多样性一般使用不同的模型来分别生成一个回复,并调整温度等超参数
- 除了要求参与者做出强制选择外,我们还要求标注者标注他们对所选择的回应与备选回应的偏好程度:他们的选择是明显更好、更好、稍微更好、或者几乎一样好/不确定
- 标注会关注帮助性 (helpfulness) 和安全性 (safety),把这两个作为单独的需求来设计标注文档
- 帮助性是指 Llama 2-Chat 响应满足用户请求并提供请求信息的程度
- 安全性是指 Llama 2-Chat 的响应是否不安全
- 人工注释是每周分批收集的
- 随着我们收集了更多的偏好数据,我们的奖励模型得到了改进,我们能够为 Llama 2-Chat 训练逐步更好的版本
- Llama 2-Chat 改进还改变了模型的数据分布。由于如果没有暴露于这个新的样本分布,奖励模型的准确性会迅速下降。在新的Llama 2-Chat调优迭代之前,使用最新的Llama 2-Chat迭代收集新的偏好数据是很重要的
- 收集了一百万条人类偏好的二元对比数据。与现有的开源数据集相比,我们的偏好数据具有更多的对话轮次,平均而言更长
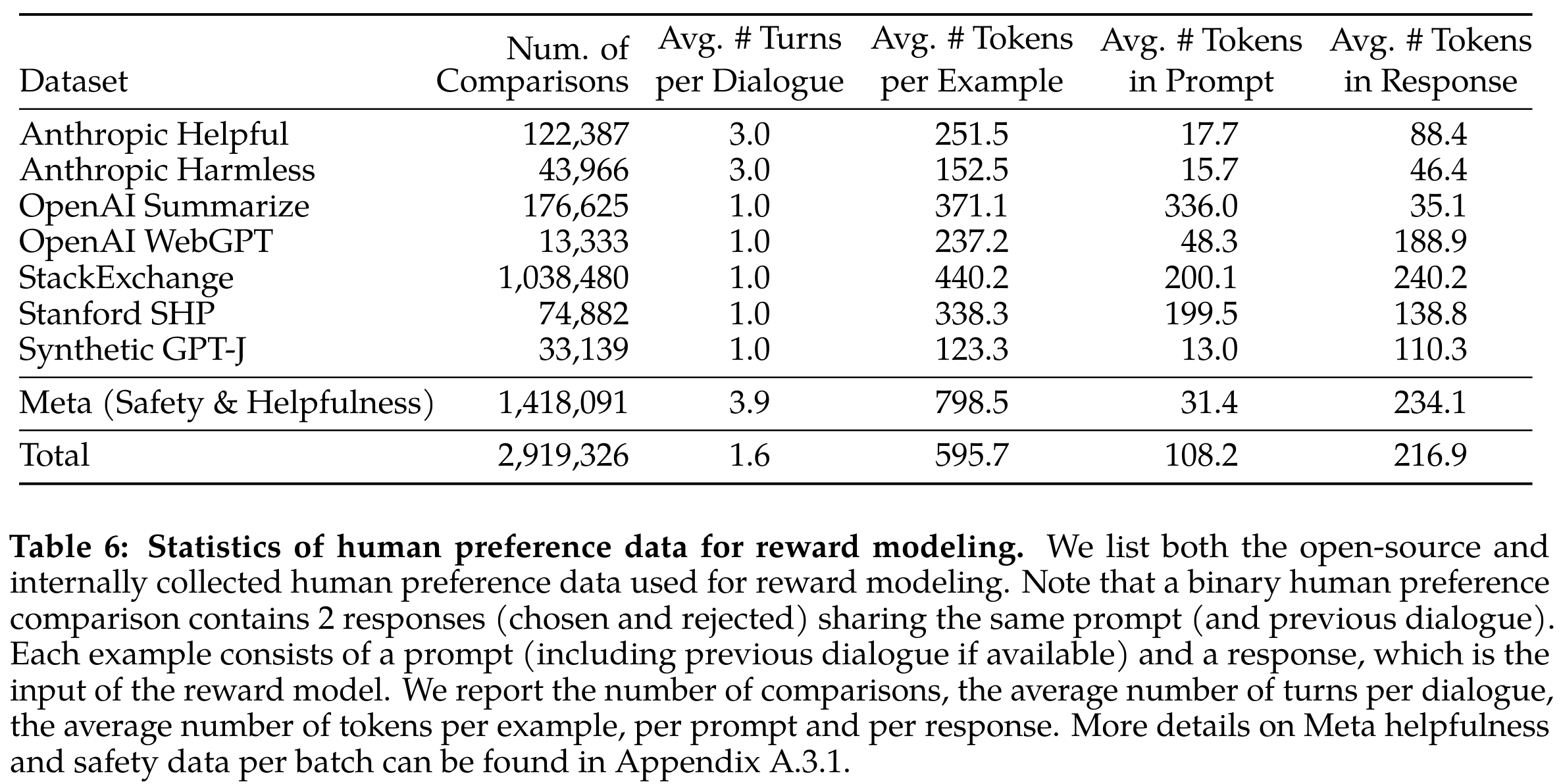
奖励模型
- 奖励模型将模型响应及其对应的提示(包括来自先前回合的上下文)作为输入,并输出标量分数来指示模型生成的质量(例如,有用性和安全性)
- 一些研究发现帮助性和安全性有时需要 trade-off,这可能会使单个奖励模型在两者上表现良好具有挑战性。为了解决这个问题,我们训练了两个独立的奖励模型,一个针对有用性(称为帮助 RM)进行了优化,另一个用于安全(安全 RM)
- 从预训练的聊天模型检查点初始化我们的奖励模型,因为它确保两个模型都受益于预训练中获得的知识。简而言之,奖励模型“知道”聊天模型知道什么。这可以防止两个模型会有信息不匹配的情况,这可能导致偏爱幻觉
- 训练 loss,促使 chosen 的样本得分比 reject 要高
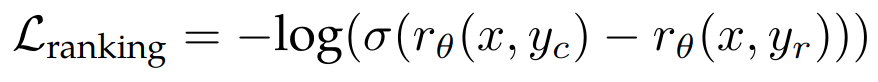
其中 x 是 prompt,yc 是标注员选择的模型回复,yr 是标注员拒绝的模型回复。同时为了利用上标注的两条数据的好坏确定程度(明显更好、更好、稍微更好、或者几乎一样好/不确定),增加了一个 margin 的 loss 项:
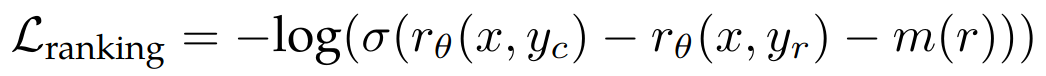
原理和人脸识别中的 margin 概念基本一致,对具有不同响应对使用较大的 margin,对响应相似的对使用较小的 margin
- 训练数据混合策略
- 帮助性奖励模型最终是在所有Meta Helpfulness数据的基础上训练的,同时还结合了从Meta Safety和开源数据集中均匀采样的剩余数据
- Meta Safety奖励模型则是在所有Meta Safety和Anthropic Harmless数据上进行训练的,同时还混合了Meta Helpfulness和开源的帮助性数据,比例为90/10。我们发现在只有10%帮助性数据的设置下,对于那些被所选和被拒绝的回答都是安全的的准确性尤为有益
- 训练细节
- 训练一个 epoch
- 使用和基础模型相同的训练超参数
- 70b模型使用5e-6的学习率,其他的使用1e-5学习率
- 3% 的 warmup
- 每个 batch 有 512 pairs 数据
迭代式微调(RLHF)
- 当我们收到更多批次的人类偏好数据注释时,我们能够训练更好的奖励模型并收集更多的提示。因此,我们为 RLHF 模型训练了连续版本,这里称为 RLHF-V1, …, RLHF-V5 等
- 尝试了两种 RLHF 微调算法
- Proximal Policy Optimization (PPO)
- Rejection Sampling fine-tuning(拒绝采样):从模型中采样 K 个输出,并选择具有奖励的最佳候选者(与 Constitutional AI: Harmlessness from AI Feedback 论文方法一致)。在这里,我们更进一步,并使用选定的输出进行梯度更新
- 两种 RL 算法的主要区别在于:
- 广度:在拒绝采样中,模型探索给定 prompt 的 K 个样本,而 PPO 只进行一次生成
- 深度:PPO 中,在步骤 t 训练期间,样本是在上一步梯度更新后从 t-1 更新的模型策略的函数。在拒绝采样微调中,我们在应用于 SFT 的微调之前,在给定我们模型的初始策略的情况下对所有输出进行采样以收集新数据集。然而,由于我们应用了迭代模型更新,两种 RL 算法之间的根本差异不太明显
- 在 RLHF (V4) 之前,我们只使用了拒绝采样微调,之后,我们依次组合这两者,在再次采样之前的结果拒绝采样 checkpoint 之上应用 PPO
拒绝采样(Rejection Sampling)
- 仅使用我们最大的 70B Llama 2-Chat 执行拒绝采样。所有较小的模型都对来自较大模型的拒绝采样数据进行微调,从而将大模型能力提炼为较小的模型。我们将在未来工作中进一步分析这种蒸馏的影响
- 在每个迭代阶段,从最近的模型中为每个 prompt 采样 K 个答案。然后,使用当时实验可访问的最佳奖励模型对每个样本进行评分,并选择给定 prompt 的最佳答案。在我们模型的早期版本,直到 RLHF V3,我们的方法是仅限于从前一次迭代中收集的样本“袋”中进行答案选择。例如,RLHF V3是仅使用来自RLHF V2的样本进行训练的。然而,尽管不断改进,这种方法在某些能力上出现了一些能力退化。例如,通过定性分析发现,与之前的版本相比,RLHF V3 在构成韵律诗句方面更加困难,这表明进一步调查遗忘的原因以及缓解方法,可能是未来额外研究的一个富有成果的领域
- 作为回应,随后的迭代中,我们修改了我们的策略,将所有之前迭代中表现最好的样本纳入考虑,例如RLHF-V1和RLHF-V2中使用的样本。虽然我们没有呈现具体的数字,但这种调整在性能方面表现出了显著的改进,并有效地解决了之前提到的问题
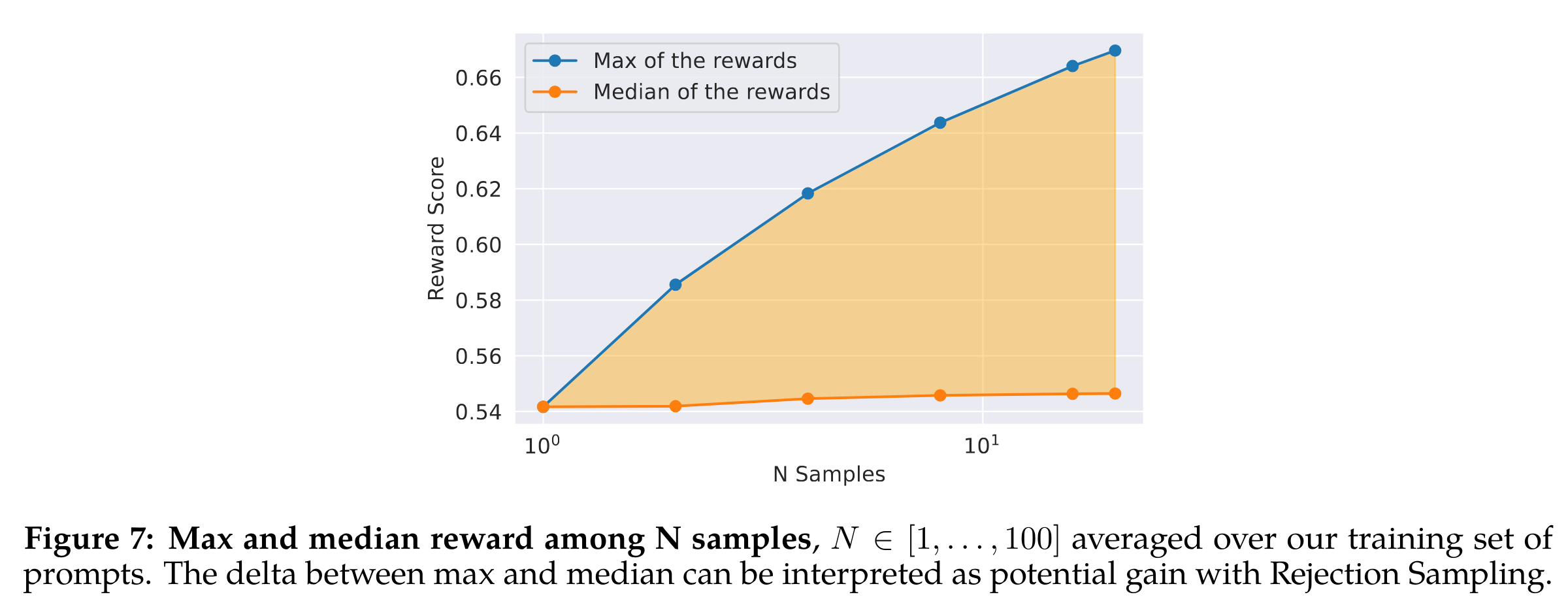
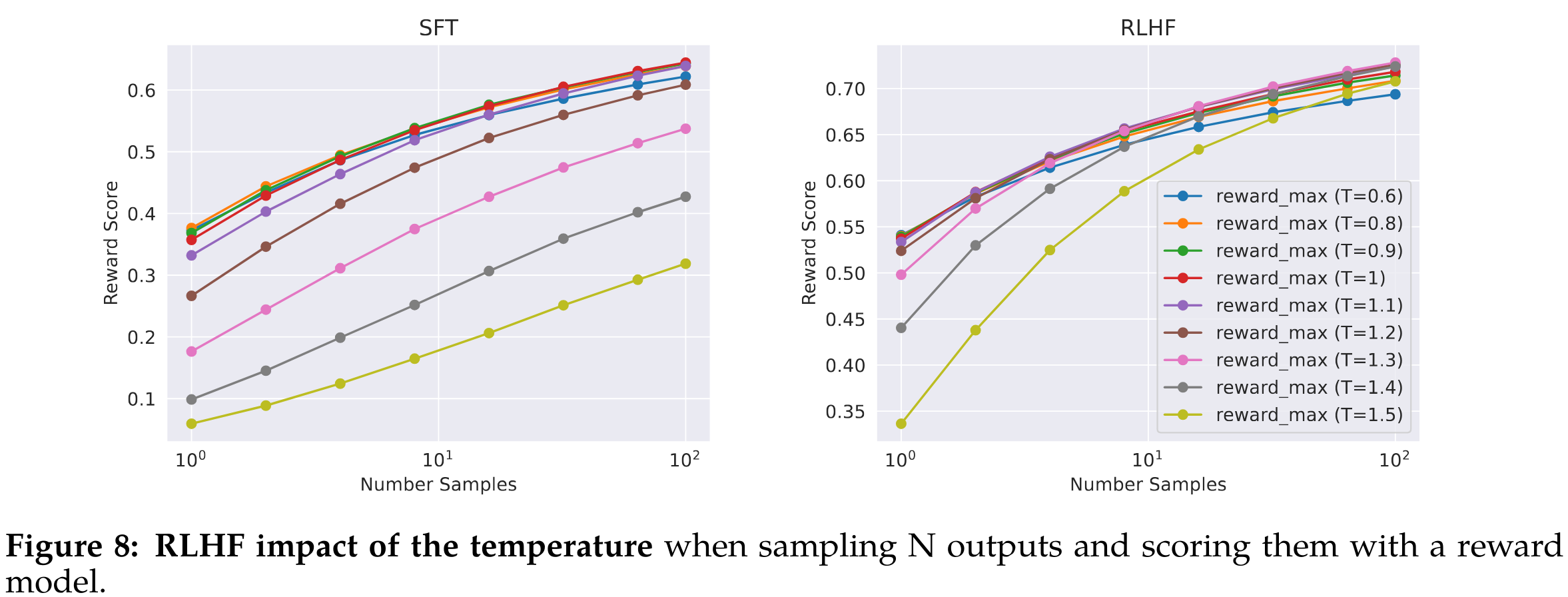
- 在下图中说明了拒绝抽样的好处。最大曲线和中位数曲线之间的差异可以被解释为在最佳输出上进行微调的潜在收益。正如预期的那样,随着样本数量的增加,这种差异增大(即更多样本,更多机会生成良好的轨迹),而中位数保持不变。在样本中,探索和获得最大奖励之间存在直接联系。温度参数对于探索也起着重要作用,因为较高的温度使我们能够采样更多样化的输出
- 在下图中展示了 Llama 2-Chat-SFT(左图)和 Llama 2-Chat-RLHF(右图)的最大奖励曲线,这些曲线是在不同温度下进行 N 次样本采样(其中N ∈ [1, . . . , 100])得到的。我们可以观察到,在迭代模型更新的过程中,最佳温度是不固定的:RLHF对温度进行了直接影响。对于Llama 2-Chat-RLHF,在对10到100个输出进行抽样时,最佳温度范围在T ∈ [1.2, 1.3]之间。考虑到有限的计算预算,因此需要逐渐重新调整温度。需要注意的是,这种温度重新调整对于每个模型来说是在固定步骤数下进行的,并且始终是从每个新的RLHF版本的基本模型开始
PPO
- 优化目标就是提升 reward,同时与原始模型的输出加个 KL 散度约束(为了训练稳定性,并且缓解 reward hacking 情况,也即奖励模型高分而真实人工评测低分)
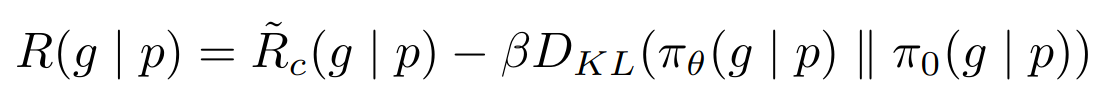
其中 Rc 是安全性奖励和帮助性奖励的分段组合。在数据集中标记了可能引发潜在不安全响应的提示,并从安全模型中优先考虑分数。选择 0.15 的阈值来过滤不安全的响应,对应于在 Meta Safety 测试集上评估的 0.89 的准确度和 0.55 的召回率。还发现将最终的线性分数进行白化(通过使用logit函数来反转sigmoid函数)非常重要,以增加稳定性并与上面的KL惩罚项(β)正确平衡

- 训练细节
- AdamW:β1 = 0.9, β2 = 0.95
- weight decay 0.1,gradient clipping of 1.0
- constant learning rate: 10−6
- bs:512
- PPO clip threshold of 0.2
- mini-batch size of 64
- KL 惩罚系数:7B and 13B 采用 0.01,34B 和 70B 采用 0.005
- 训练 200 iter 到 400 iter,对于70B 模型每个 iter 花费时间是 330s,为了训练更大的 batchsize 使用了 FSDP。这种方法在使用O(1)的前向或后向传递时非常有效,但在生成过程中会导致显著的减速(约20倍),即使使用较大的批次大小和KV缓存。我们通过在生成之前仅一次将模型权重合并到每个节点,并在生成后释放内存,然后恢复其余的训练循环来缓解了这个问题。通过这种方式,我们能够在不影响训练质量的前提下解决了生成时的内存问题
多轮一致性的系统消息(System Message for Multi-Turn Consistency)
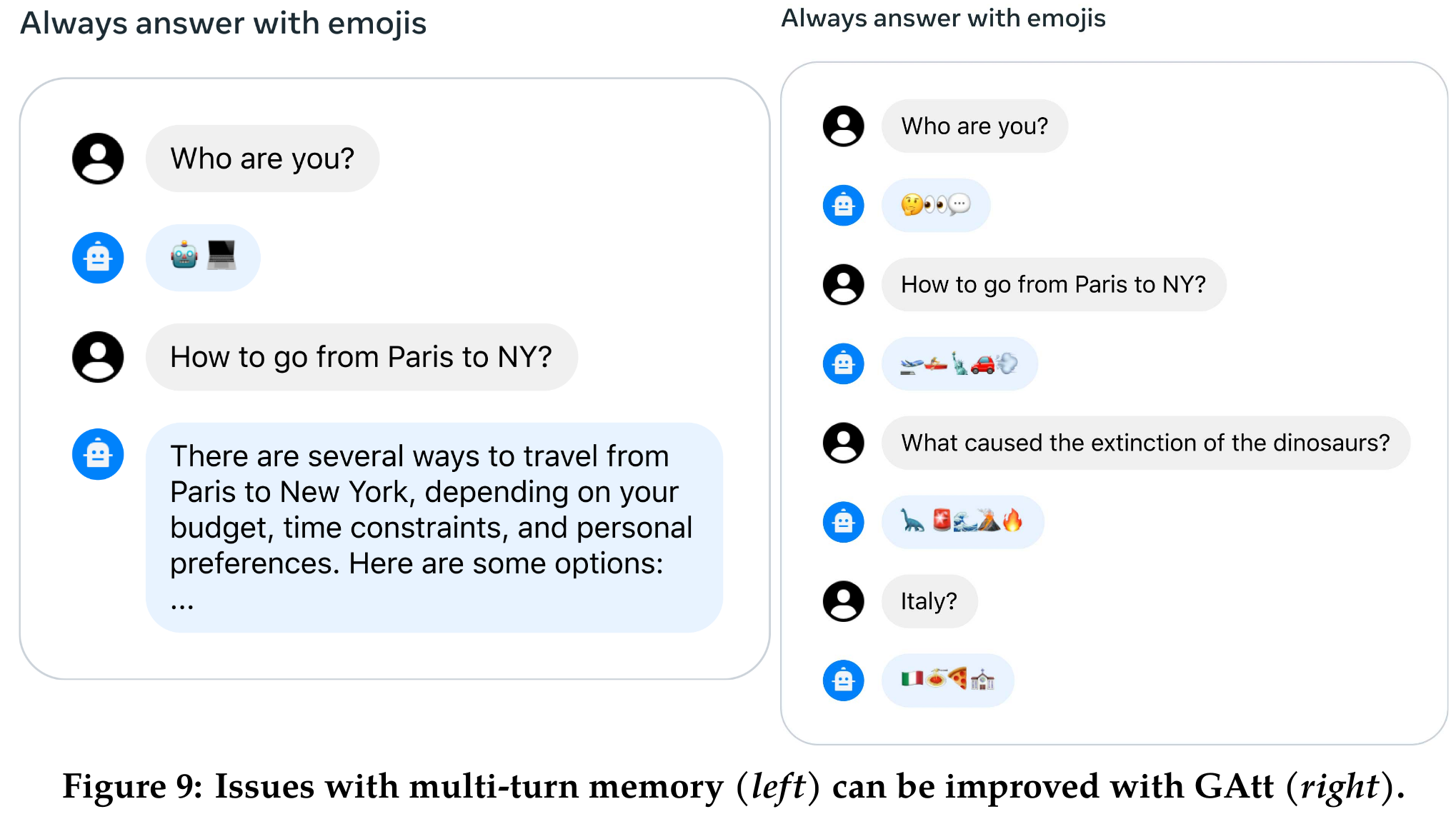
- 在对话设置中,有些指令应该适用于所有对话回合,例如要简洁回复,或者“扮演”某个公众人物。当我们向 Llama 2-Chat 提供这样的指令时,后续的回复应始终遵守这些限制。然而,我们最初的 RLHF 模型在对话进行几个回合后往往会忘记初始指令,如下图(左图)所示。为了解决这些问题,我们提出了 Ghost Attention(GAtt)方法,这是一个受 Context Distillation 启发的非常简单的方法,通过对微调数据进行干预来帮助注意力在多阶段的过程中聚焦。GAtt 使得对话在多个回合内能够保持控制,如下图(右图)所示
- GAtt 介绍:
- 假设我们可以访问两个人之间的多轮对话数据集(例如,用户和助手之间的对话),其中包含一系列消息 [u1, a1, …, un, an],其中 un 和 an 分别对应第 n 轮对话的用户和助手消息。然后,我们定义一个指令(inst),在整个对话过程中应该被遵守。例如,指令可以是"扮演"某个角色。然后,我们将这个指令合成地连接到对话中所有的用户消息上
- 接下来,我们可以使用最新的RLHF模型从这个合成数据中进行采样。现在我们有了一个上下文对话和用于微调模型的样本,这个过程类似于拒绝抽样。然而,我们并不是在所有上下文对话回合中都加入指令,而是只在第一个回合中加入,这样会导致一个训练时的问题,即系统消息(即最后一轮之前的所有中间助手消息)与我们的样本不匹配。为了解决这个问题,以免影响训练,我们简单地将之前回合中的所有标记的损失设置为0,包括助手消息
- 对于训练指令,我们创建了一些合成的限制供采样,例如兴趣爱好(“您喜欢(),例如网球”),语言(“说(),例如法语”),或者公众人物(“扮演(),例如拿破仑”)。为了获得兴趣爱好和公众人物的列表,我们让Llama 2-Chat来生成,避免了指令与模型知识不匹配的问题(例如,让模型扮演它在训练中没有遇到过的角色)。为了使指令更加复杂和多样化,我们通过随机组合上述限制来构造最终的指令。在构造用于训练数据的最终系统消息时,我们还会将一半的原始指令修改为更简洁的形式,例如"Always act as Napoleon from now"会变为"Figure: Napoleon"。这些步骤生成了一个 SFT 数据集,用于微调Llama 2-Chat。
- GAtt 评测:为了说明 GAtt 如何帮助在微调期间重塑注意力,在下图中展示了模型的最大注意力激活。
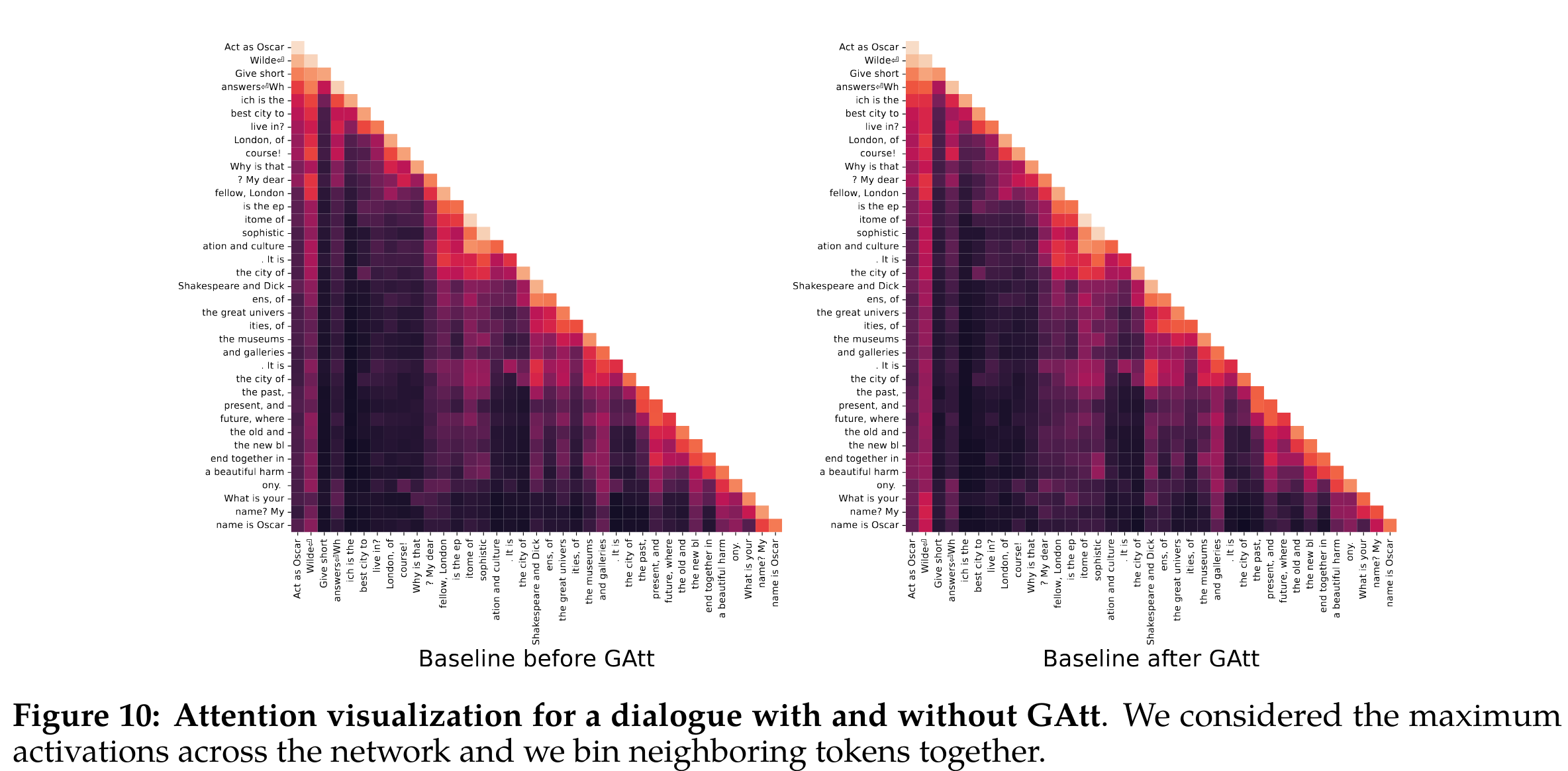
每个图的左侧对应系统消息(“Act as Oscar Wilde”)。我们可以看到,装备了GAtt的模型(右图)在对话的更大部分保持与系统消息相关的大的注意力激活,相比没有GAtt的模型(左图)。尽管GAtt非常有用,但目前的实现还是原始的,对这种技术进行更多的开发和迭代可能会进一步增益模型。例如,我们可以在微调过程中整合数据,教导模型在对话过程中改变系统消息
安全性
首先讨论了我们对预训练数据和预训练模型的安全调查,接下来描述了安全对齐过程,解释如何收集与安全相关的注释并利用SFT和RLHF,并给出了实验结果。然后讨论了我们进行的红色团队,以进一步理解和提高模型的安全性。最后,我们提出了 Llama 2-Chat 的定量安全评估
预训练中的安全性
- 预训练数据处理
- 从已知包含大量关于私人个人的个人信息的某些地点排除了数据
- 没有做更多过滤,主要考虑为了允许 Llama 2 在任务之间更广泛地使用(例如,它可以更好地用于仇恨言论分类),同时避免意外人口统计擦除
- 因此,Llama 2 模型应仅在应用仔细的安全性微调后再部署
- 人口统计表示:代词(Demographic Representation: PronounsPronouns)
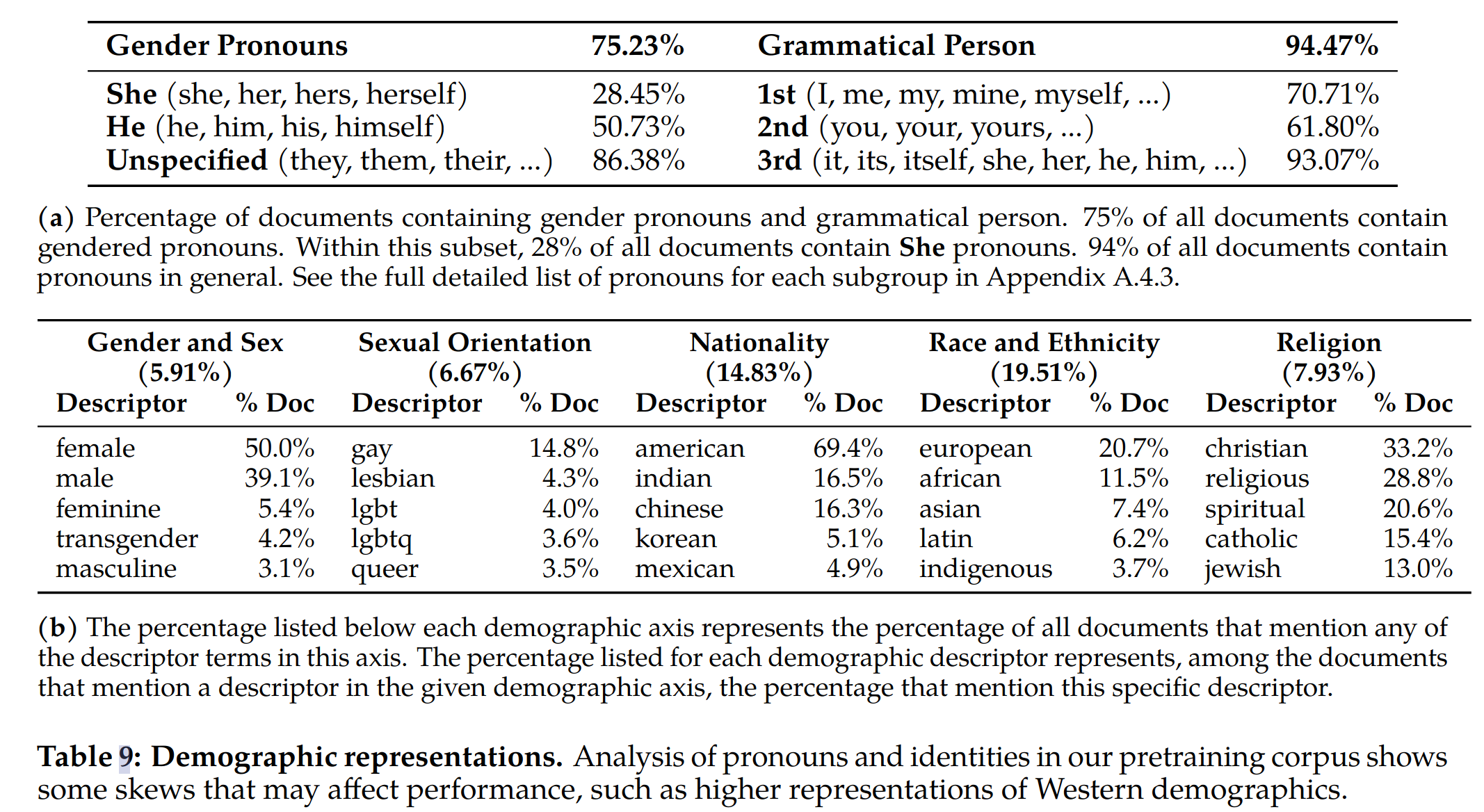
- 模型生成中的偏差可能是由于继承自训练数据本身的偏差,比如在海量文本语料库中,表示“people”的词通常与表示“men”的词更相似的上下文中使用,而不是表示“women”的词。如下表(a)所示,在英语训练预料中,统计出来 He 的代词使用明显多于 She。这可能意味着模型在对提及 She 代词的上下文进行预训练期间学习较少,模型生成 He 的概率可能就会比 She 高
- 人口统计表示:身份
- 从宗教、性别和性别、国籍、种族和民族性以及性别取向这五个维度进行分析,由上表(b)可以看到,虽然 she 的出现评率比 he 少,但是 female 在文档中的出现频率比 male 高,也许反映了这些术语的语言标记差异。从国家、种族和民族来看,语料明显更倾向于西方人口,例如,“美国”一词在 69.4% 的参考文献中被提及,“欧洲”一词比其他种族和民族更为普遍, “Christian” 是最具代表性的宗教,其次是 “Catholic” 和 “Jewish”
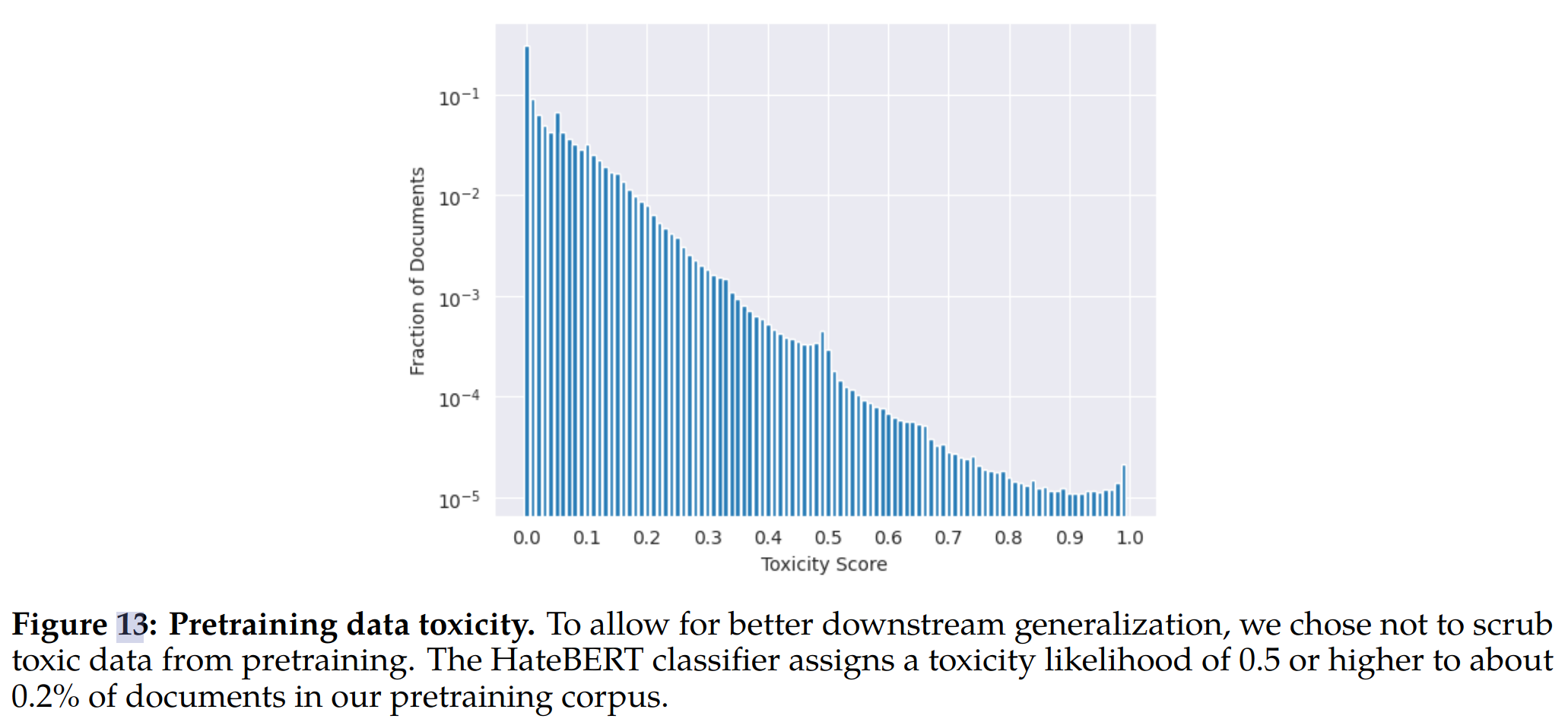
- 数据毒性:我们使用在 ToxiGen 数据集上微调的 HateBERT 分类器来衡量预训练语料库的英语部分的毒性率。我们分别对文档的每一行进行评分,并对它们进行平均以分配文档分数。基于 10% 随机抽样的样本进行统计,分数分布如下图所示:大约 0.2% 的评估文档被分配 0.5 或更高的可能性分数,这意味着我们的预训练数据中存在大量毒性
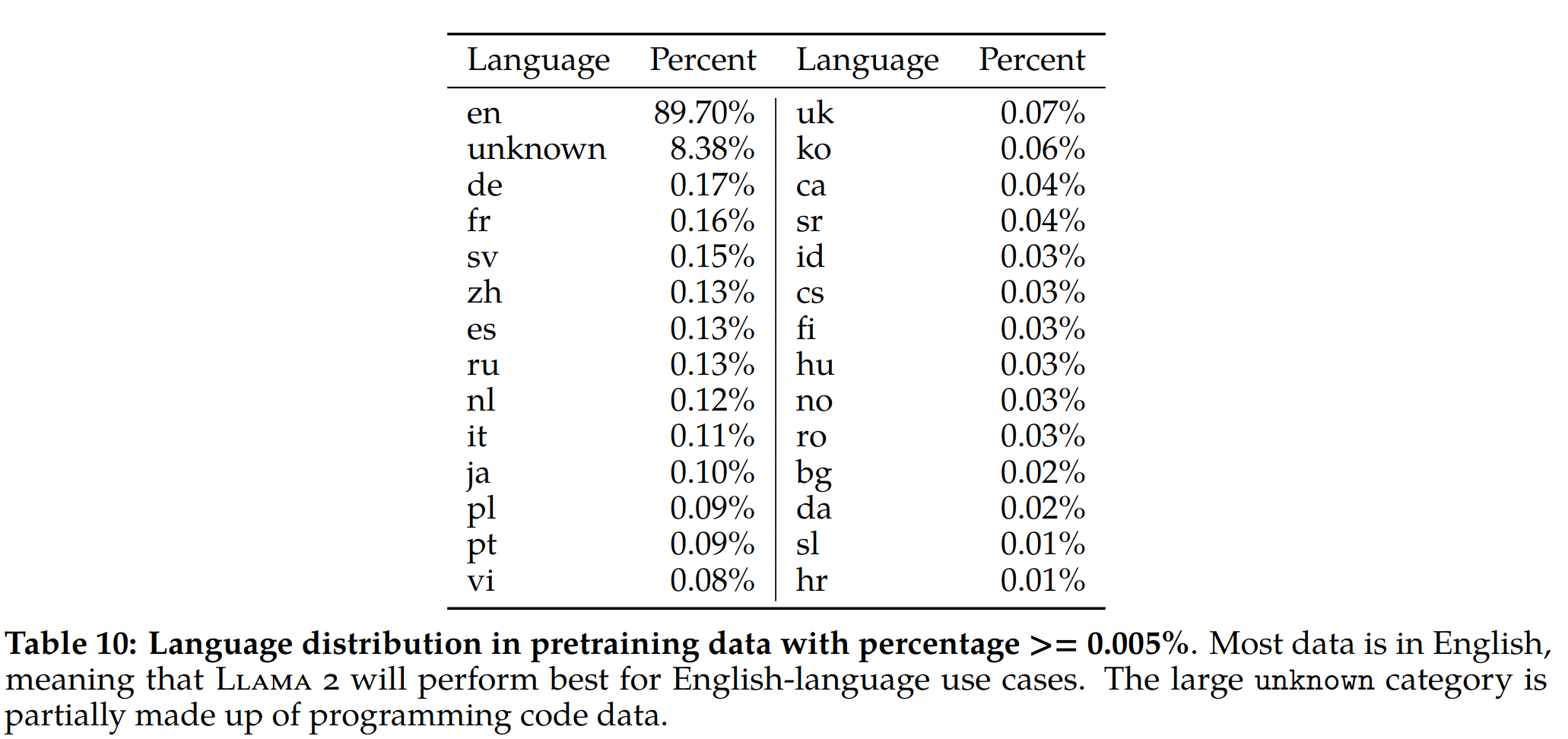
- 语言识别:使用 fastText 工具进行语言识别,大部分是英文语料,中文语料只有 0.13%
讨论
学习和观察
- 强化学习被证明非常有效,特别是考虑到其成本和时间有效性。我们的研究结果强调了 RLHF 成功的关键决定因素在于它在整个注释过程中促进人类和 LLM 之间的协同作用。
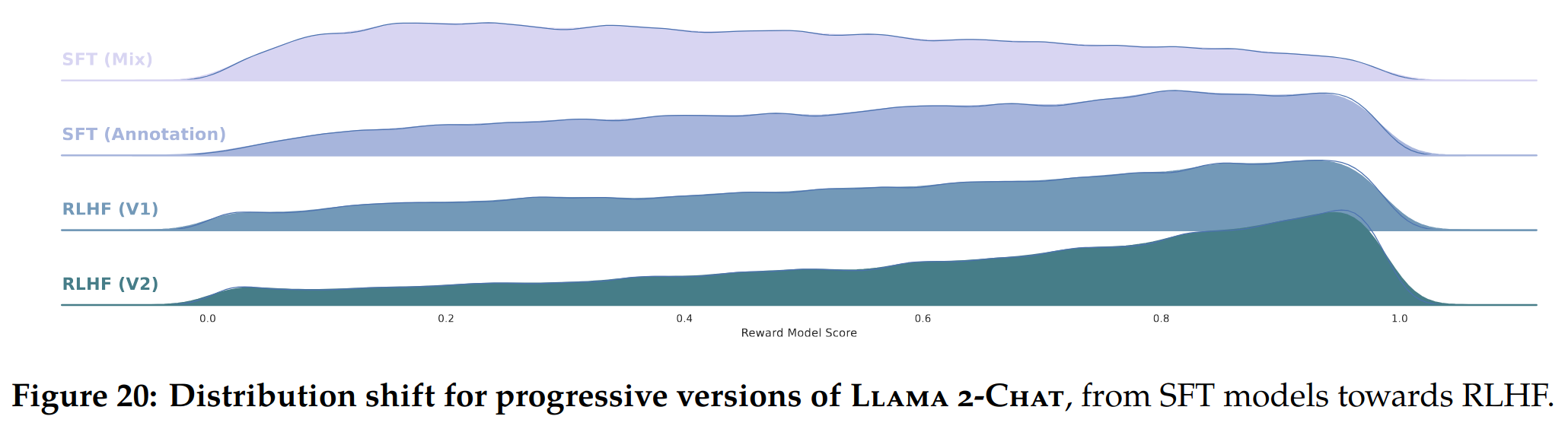
- 即使使用成本较高的人工标注员,每个单独的标注都存在显着差异。在 SFT 标注数据上微调的模型学习了这种多样性,比如下图中 SFT模型有很多低 reward 回复。此外,模型的性能受到最熟练注释者的写作能力的限制。但在比较两个输出对 RLHF 的偏好注释时,人工注释者可以说不会受到差异的影响(道理很简单,不是艺术家的人很难画出高质量的画,但是评估两幅有明显差异的画的优劣还是比较容易的)。因此,奖励机制迅速学会将低分数分配给不希望的尾部分布,并与人类偏好保持一致。如下图所示,可以看到最差的答案逐渐被删除,将分布向右移动
基于上下文的温度系数缩放(In-Context Temperature Rescaling)
- 观察到与 RLHF 相关的一个有趣的现象,这是我们之前没有报道过的最佳知识的特征:温度的动态重新缩放取决于上下文。温度似乎受到 RLHF 的影响。然而,有趣的是,我们的发现还表明,这种转变并不是在所有 prompt 中统一应用的
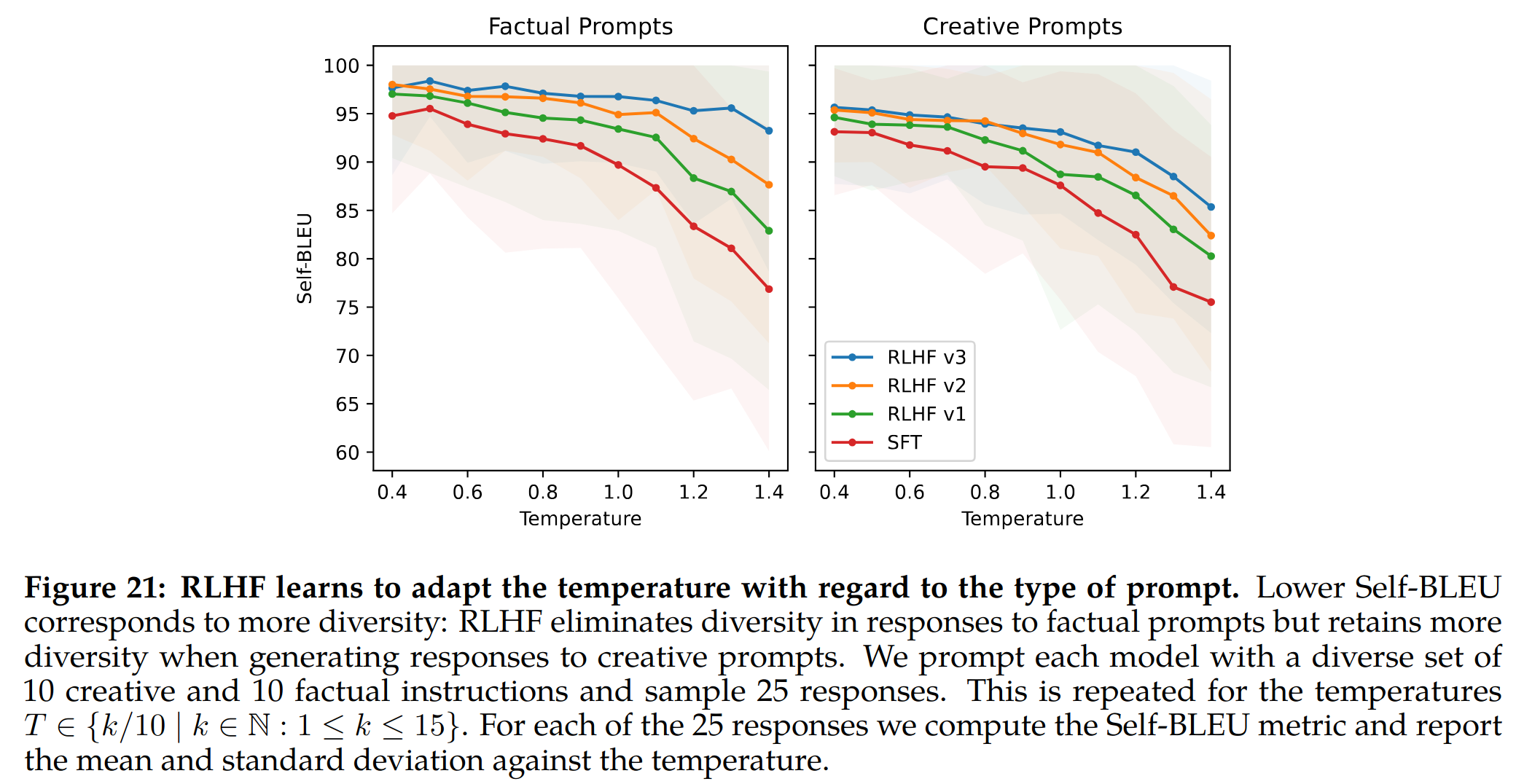
例如,当涉及到与创造力相关的提示时,例如“写一首诗”,温度的增加继续在我们的各种 RLHF 迭代中生成多样性。这可以从 Self-BLEU 斜率中观察到,这反映了与 SFT 模型相当的模式。另一方面,对于基于事实信息的提示,例如“首都是什么”,Self-BLEU 斜率随着时间的推移而减少。这种模式表明,尽管温度上升,但该模型学会了始终为事实提示提供相同的响应。
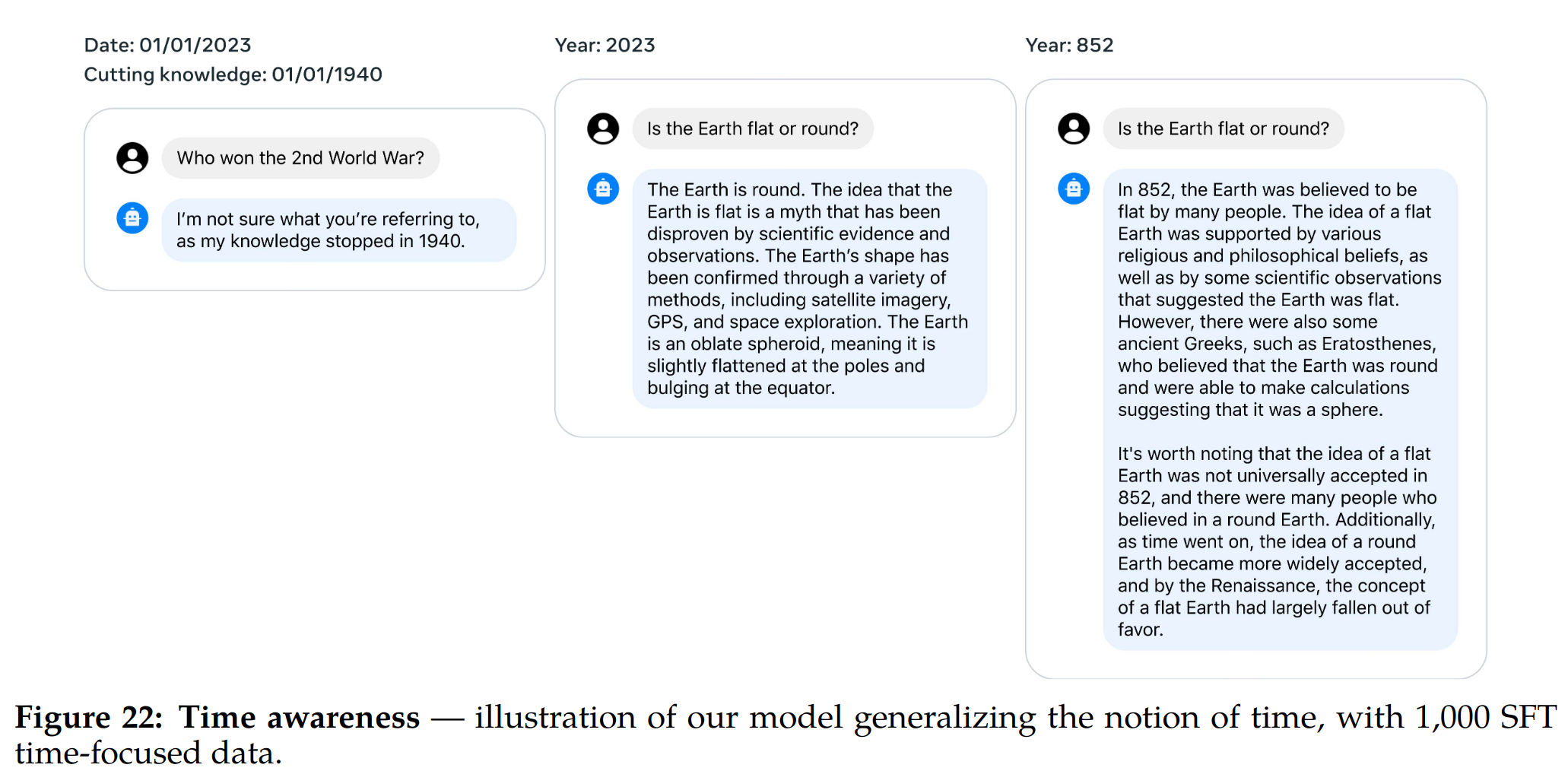
Llama2 Chat 对时间的感知
- 对时间感知程度挺好。这种时间概念是在 SFT 中使用了 1000 个与特定日期有关的问题数据所获得的。观察表明,尽管 LLM 的训练完全基于下一个 token 预测和随机打乱的数据,而不考虑它们的时间上下文,但 LLM 已经在很大程度上内化了时间的概念。
工具使用涌现能力
- OpenAI 的插件的发布在学术界引起了大量话语,引发了一些思考:
- 如何有效地教模型利用工具
- 或者这个过程是否需要一个实质性的数据集
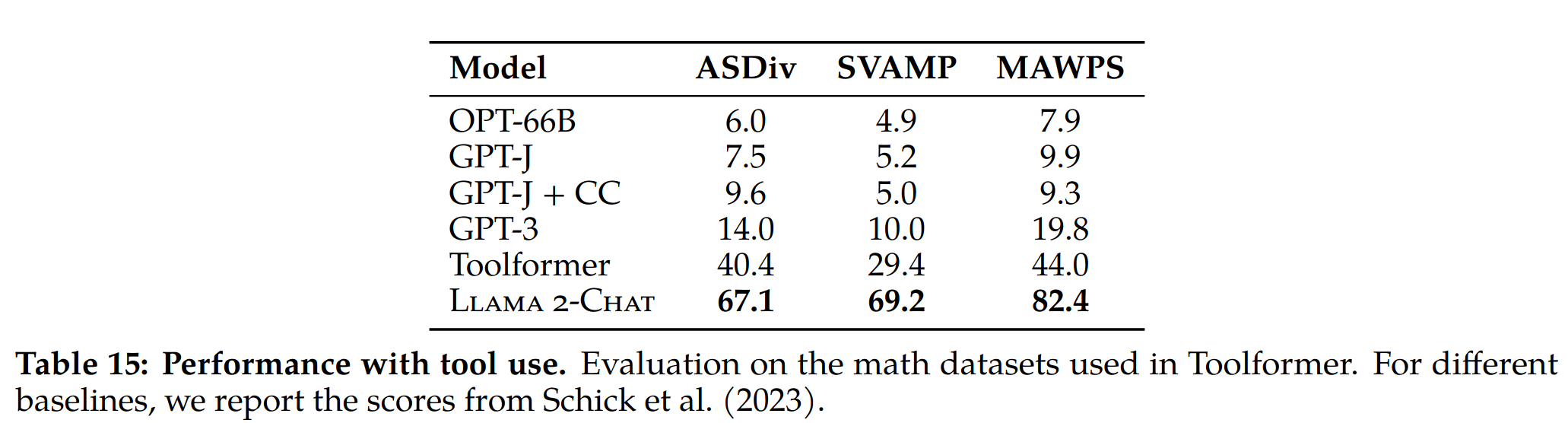
- 我们的实验表明,工具使用可以以零样本的方式自发地从对齐中出现。尽管我们从未明确注释工具使用用法,但下图展示了一个实例,其中模型展示了在零样本上下文中利用一系列工具的能力

- 在 math 数据上的实验,Llama2 使用工具能力很强
实验结果
预训练
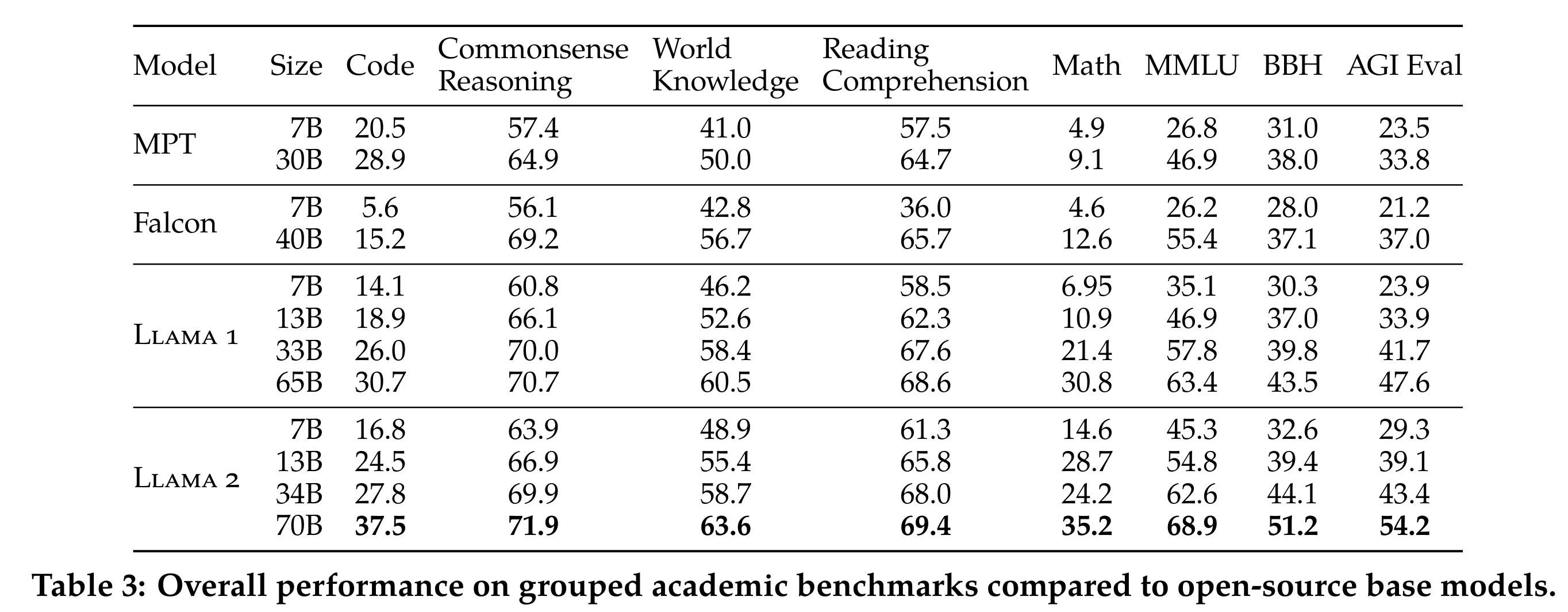
与开源基础模型的精度对比
- 在代码、常识推理(Commonsense Reasoning)、世界知识(World Knowledge)、阅读理解(Reading Comprehension)、数学(MATH)、流行的聚合基准(Popular Aggregated Benchmarks)等评测集上全面超过开源基础模型
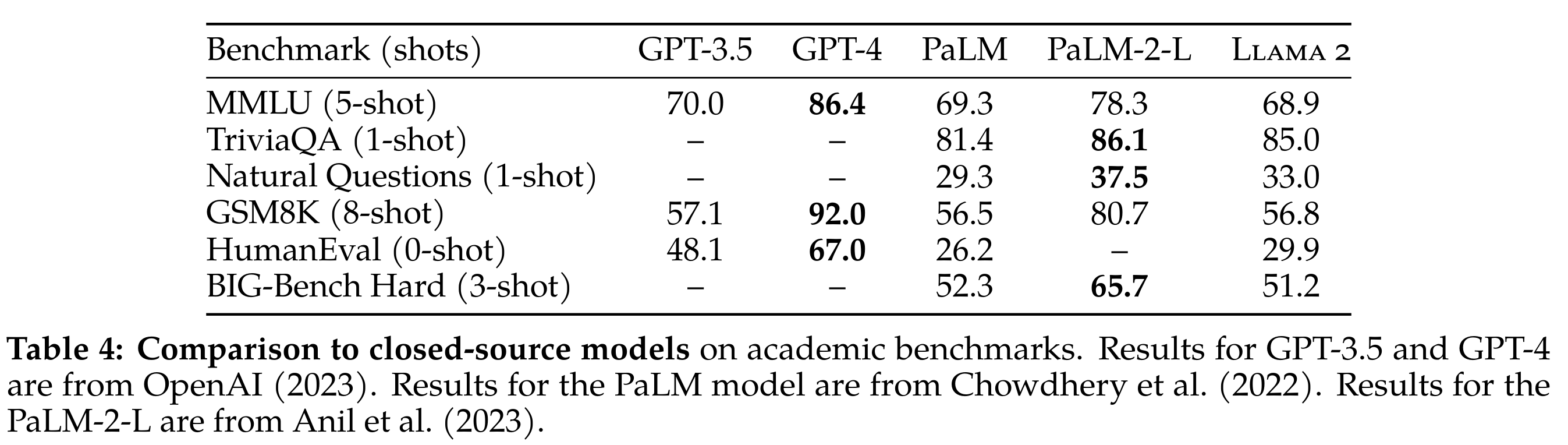
与闭源模型对比
- 比不过闭源模型,与 GPT-4 的差距还是很大,Llama(70B)与 PaLM(540B)基本在同一水平
RLHF
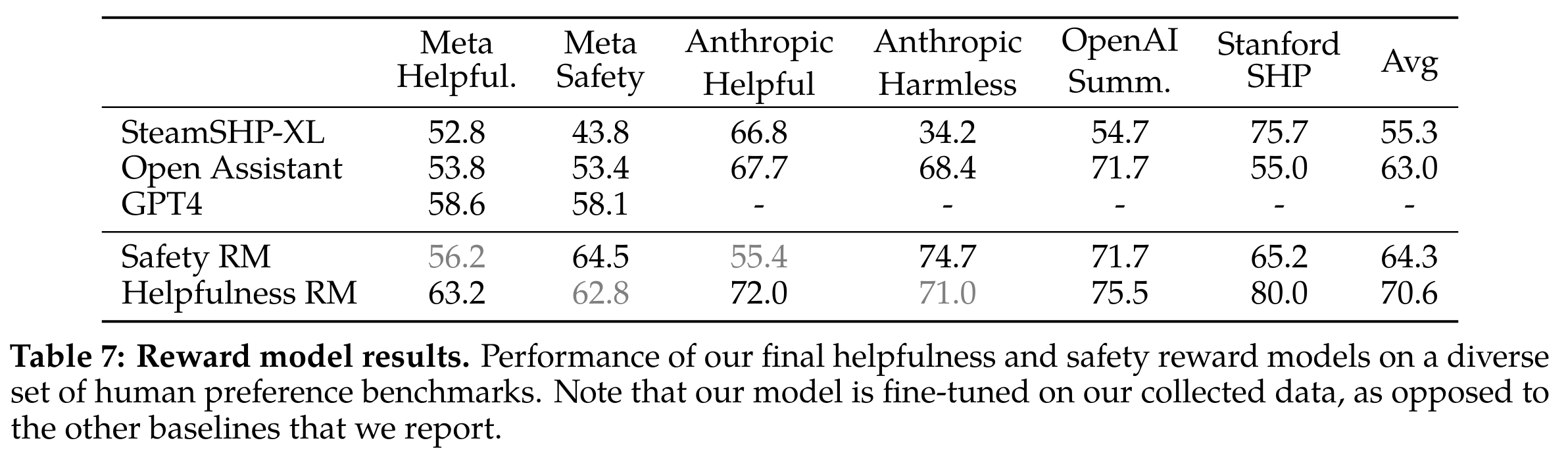
奖励模型精度
- 其中 GPT4 是使用 “Choose the best answer between A and B” 提示词测试出来的。帮助性奖励模型在帮助性数据集上精度最高,同样安全性奖励模型在安全性数据集上精度最高。
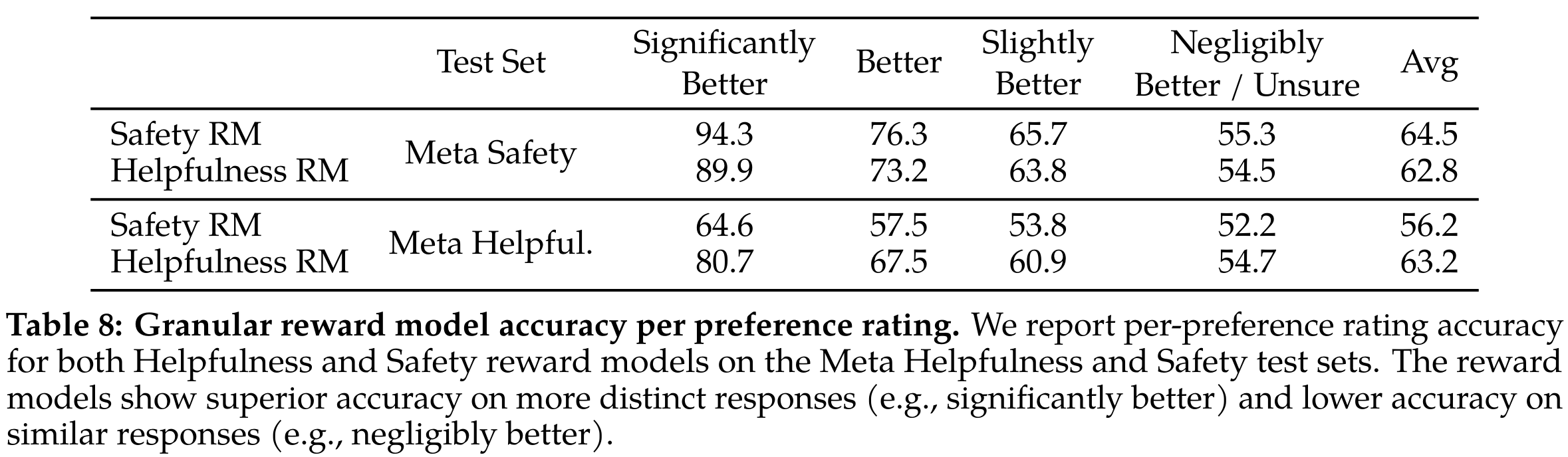
- 对于回复有差异的场景进行分别评测,看起来符合预期,对于差别较大的回复对判别准确度更高
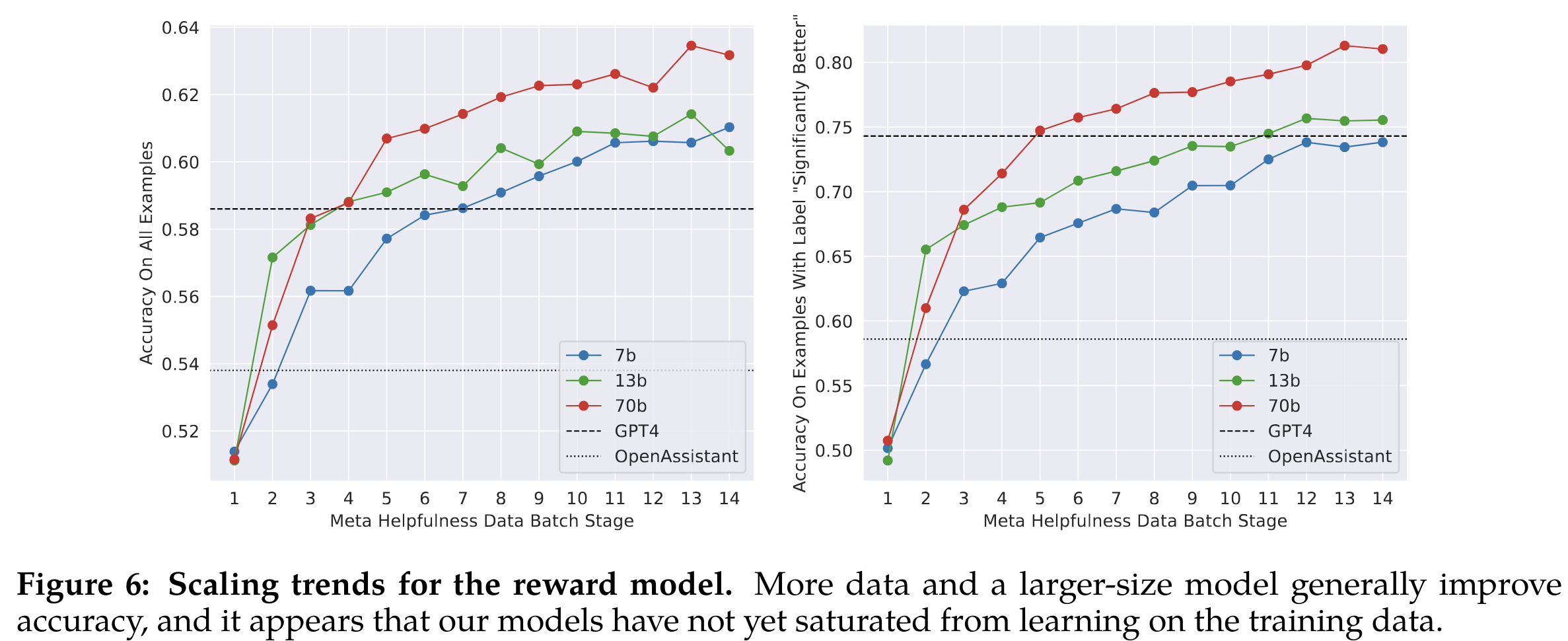
- 研究了奖励模型的数据和模型大小的缩放趋势,目前还没有饱和,说明继续增加数据还能提升性能
基于模型的评估结果
- 展示了不同的SFT(Safety First Training)和RLHF(Reward Learning with Human Feedback)版本在安全性和有用性两个方面的进展情况,通过我们内部的安全性和有用性奖励模型进行度量。在这组评估中,我们在RLHF-V3版本之后在两个方面都优于ChatGPT(一种基线模型),即无害性(harmlessness)和有用性(helpfulness)均高于50%。尽管使用我们的奖励作为点对点指标具有前述相关性,但它可能对Llama 2-Chat(我们的模型)有利偏差。因此,为了公平比较,我们额外使用GPT-4进行最终结果的计算,以评估哪个生成模型更受青睐。为避免任何偏见,ChatGPT和Llama 2-Chat输出在GPT-4提示中的顺序会被随机交换。如预期,Llama 2-Chat相对于ChatGPT的胜率变得不太显著,尽管我们最新的Llama 2-Chat仍超过60%的胜率。这些提示分别对应于安全性和有用性的1,586个和584个验证集的提示。
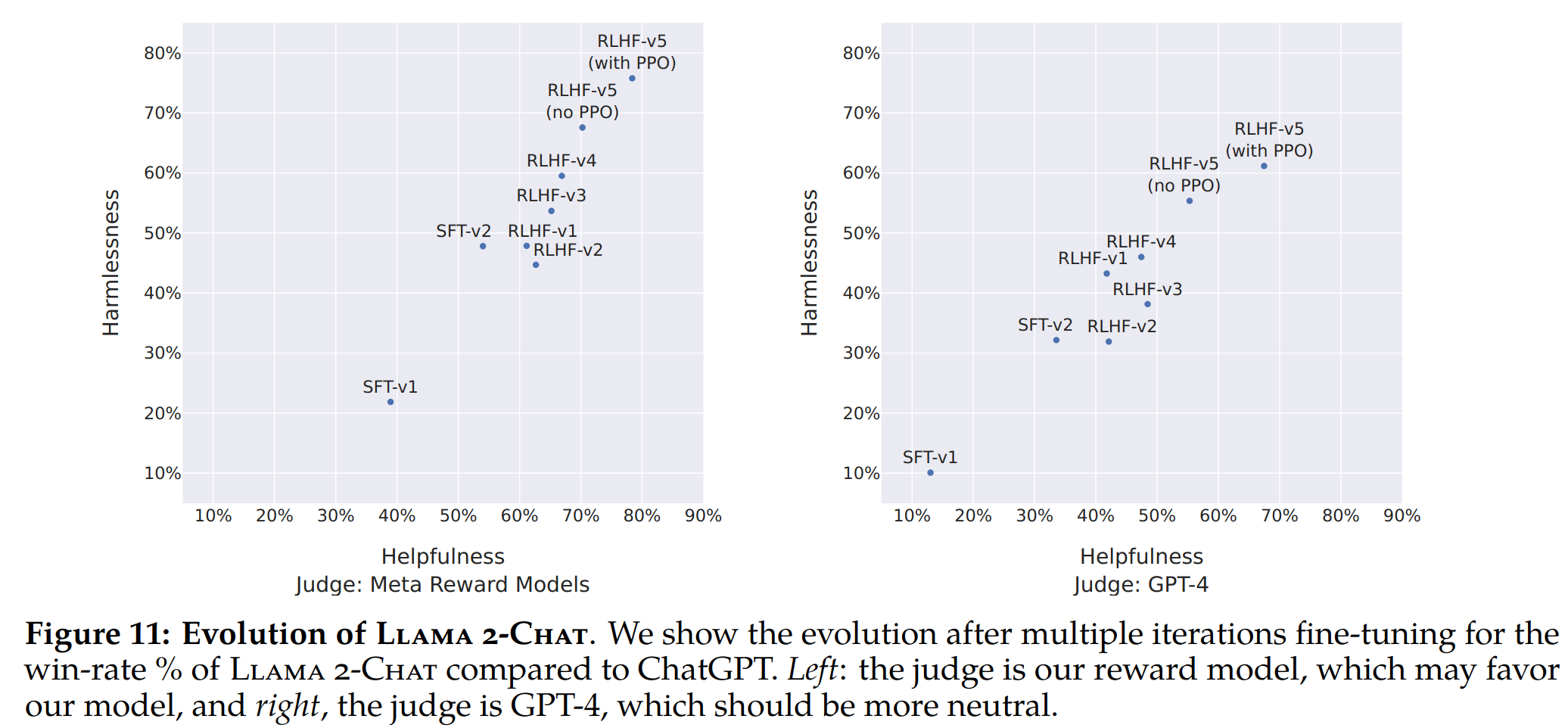
基于人工的评测结果
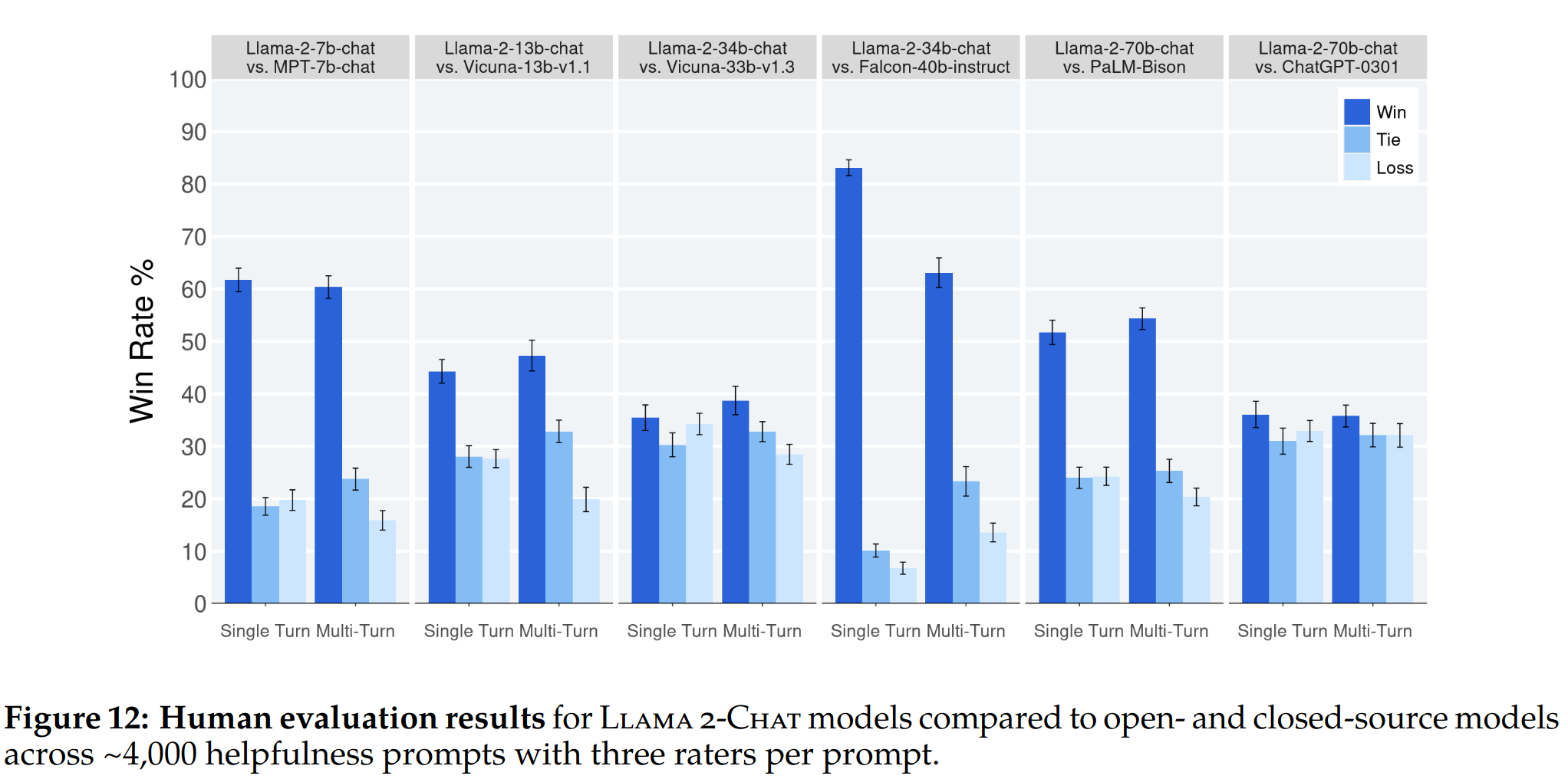
安全性
定量评估
- generate 的参数是 temperature 0.1、top-p 0.9,毒性还有待加强
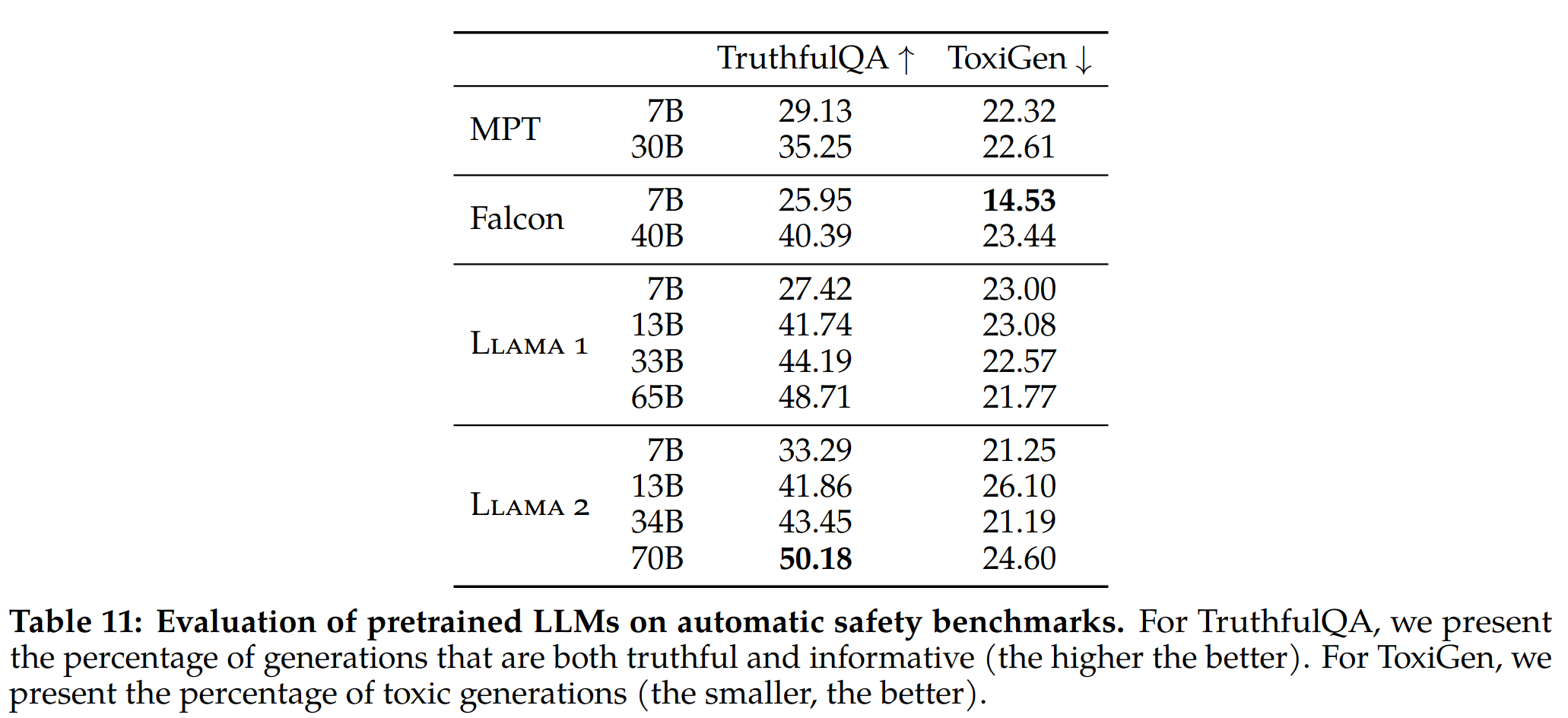
RLHF 对安全性的提升
-
其中红框区域代表安全性的提升,及 RLHF 之前安全性分数较低, RLHF 之后安全性较高

-
提升样例

安全性 scaling 实验
- 随着数据量增加安全性得分逐渐提升,帮助性也基本稳定;同时随着数据量提升,低分区域的长尾现象被逐渐缓解

安全性对比实验
- 整体优于 ChatGPT
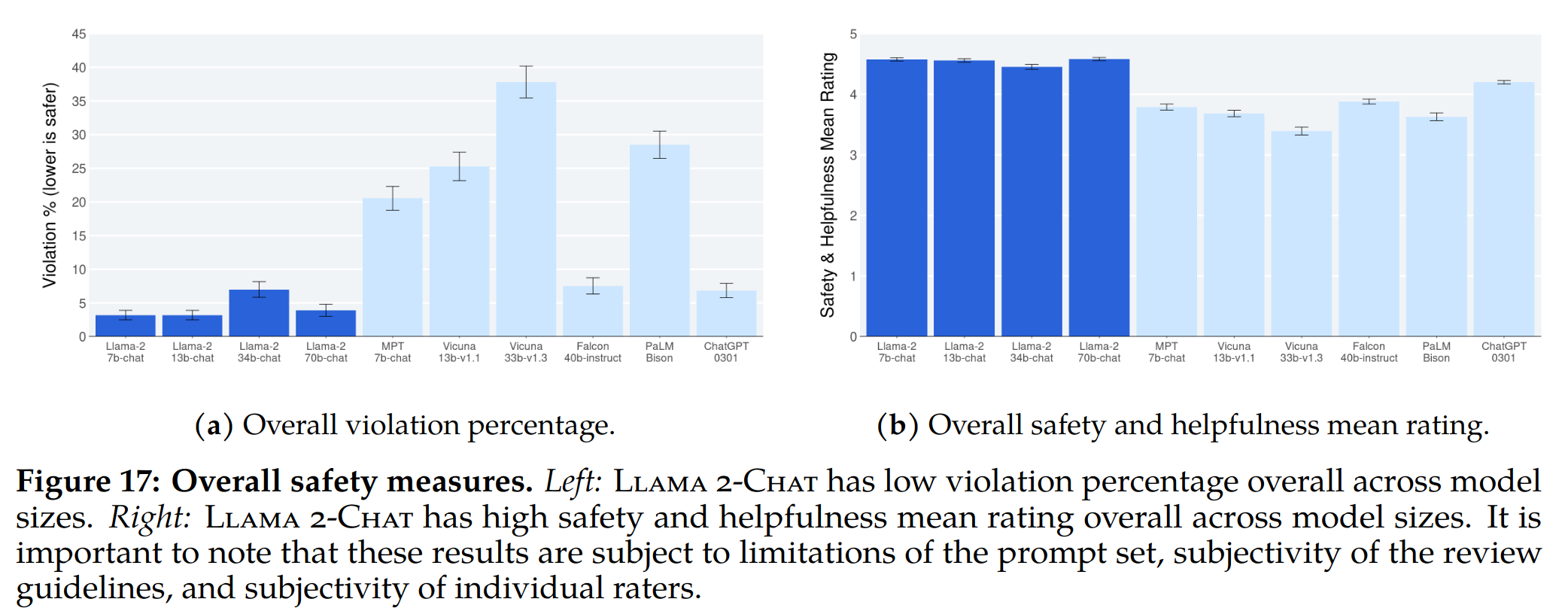
消融实验
上下文增加带来的性能提升
- 相同的网络结构训练 150B token,在 long-context task 上有大幅涨点,通用任务上基本不掉点
GQA 对比 MHA 和 MQA
- 使用 30b 模型训练 150b token 的实验对比。为了在 GQA 和 MQA 中保持相似的整体参数计数,增加了前馈层的维度以补偿注意力层的减少。对于 MQA 变体,将 FFN 维度增加 1.33 倍,对于 GQA 变体,将其增加 1.3 倍。观察到 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均而言优于 MQA 变体
基于 8x80g A100 做推理速度验证实验,使用 30B 模型对于 GQA 、MQA 和 MHA 进行消融对比。在这些测试中,只需在所有 GPU 中复制 MQA 的 KV 头,因此 MQA 的 KV 缓存大小等于 GQA,并且两个变体的行为非常相似(使用 MQA 只是具有稍大的 FFN 维度维度)。多查询变体能够以更大的批处理大小实现更高的吞吐量(MHA 在 bs=1024/seq len=256 或 bs=128/seq len=2048 时会 OOM,但是多查询变体能正常跑),并在较小的批处理中显示类似的延迟
Thoughts
- 本文对大模型研发的每个环境都讲解地非常详细,非常良心的开源作品,难怪大家呼吁 Meta 改名称为新的 “OpenAI”
- 预训练
- 对知识性的语料进行过采样很重要
- 模型的效率优化需要同时考虑训练、测试两个阶段,比如考虑到测试阶段的效率就优先使用了 GQA 而不是 MQA
- SFT
- 数据质量很重要,Llama2 使用 2-3 w 的人工标注语料,同时也说明这个数据量就差不多够了,再多了收益逐渐变小。
- 建议把更多的人类标注成本放到 RLHF 中
- RLHF
- RM 需要分为帮助性和安全性两个模型进行迭代
- RLHF 流程需要迭代试优化,保证在 LLM 模型能力提升之后 RM 模型的能力也要匹配,避免 reward hacking 问题
- 拒绝采样结合 PPO 很有效
- 本文所体现的 Meta 作为大厂的责任心很强,花了很大篇幅描述模型的安全性,同时也反复强调训练的大模型的碳排放会计入 Meta 的内部计划中,并且为了降低其他公司重复进行的预训练操作带来的碳排放增加,所以选择开源所有 Llama2 模型(除了30b)并支持商用