1、概要
传统电影推荐系统大多使用协同过滤算法实现电影推荐,主要实现机理是通过用户评分及用户观影历史数据抽象为多维向量利用欧式距离或其他向量计算公式实现推荐,本文中将采用常用的机器学习算法Kmeans聚类算法+协同过滤算法+word2vec搜索推荐模型多模型多维度实现电影推荐系统,系统主要使用python语言进行开发,使用django网站web开发框架实现,数据库使用mysql

2、算法介绍
Kmeans聚类模型通过用户多维度多特征的信息:用户性别,年龄,地域,角色(学生、上班族、待业)、地域、婚姻状态等进行特征化数据处理,使用python实现kmeans算法进行用户类别模型的划分,具体实现可参照我之前的文章《基于K-means的用户画像聚类模型》
word2vec模型实现搜索相似推荐,通过用户搜索的关键字词查询影片记录,推荐相似关键字的影片,具体训练和实现代码如下所示。
# -*- coding: utf-8 -*-
import gensim.models.word2vec as word2vec
import gensim
"""
https://www.jianshu.com/p/471d9bfbd72f
"""
# word2vec Text8 的训练
def train_save_model():
# 加载预料
sentences = word2vec.Text8Corpus('text8_')
model = word2vec.Word2Vec(sentences, vector_size=200, workers=3)
model.save('text.model')
# 加载模型
def predict(text):
model = word2vec.Word2Vec.load('text.model')
return model.wv.most_similar(text,topn=3)
# 训练模型
# train_save_model()
# 预测
print(predict("man"))3、实现及演示
电影推荐系统的目录结构如下:database是数据库sql文件,model文件夹是所有相关模型文件位置,static是图片及js的静态文件,templates是存放所有的前端界面html文件。运行命令:python manage.py runserver 启动成功后在浏览器输入http://127.0.0.1:8000/movie/即可进入电影推荐系统的界面。

首页会展示部分电影,热门电影会展示评分最高的前100部电影,你可以点击任意一部电影查看它的详细介绍你可以给电影评分,当你评分的电影超过10部,就可以查看网站对你的推荐结果使用分类或搜索功能可以帮助你找到电影。(默认未登录情况下只有两个选项功能:热门电影和电影分类)

点击右上角的注册按钮并实现注册用户即可进行系统的正常功能

注册成功并完成初始化信息后,权限如下图选项卡功能,热门电影、电影分类、推荐电影、用户画像推荐、搜索、影片的评价及评分历史、我的信息等。

登录成功后选择想查看的电影,可查看影片的详情信息并进行评价和评论以及评分。

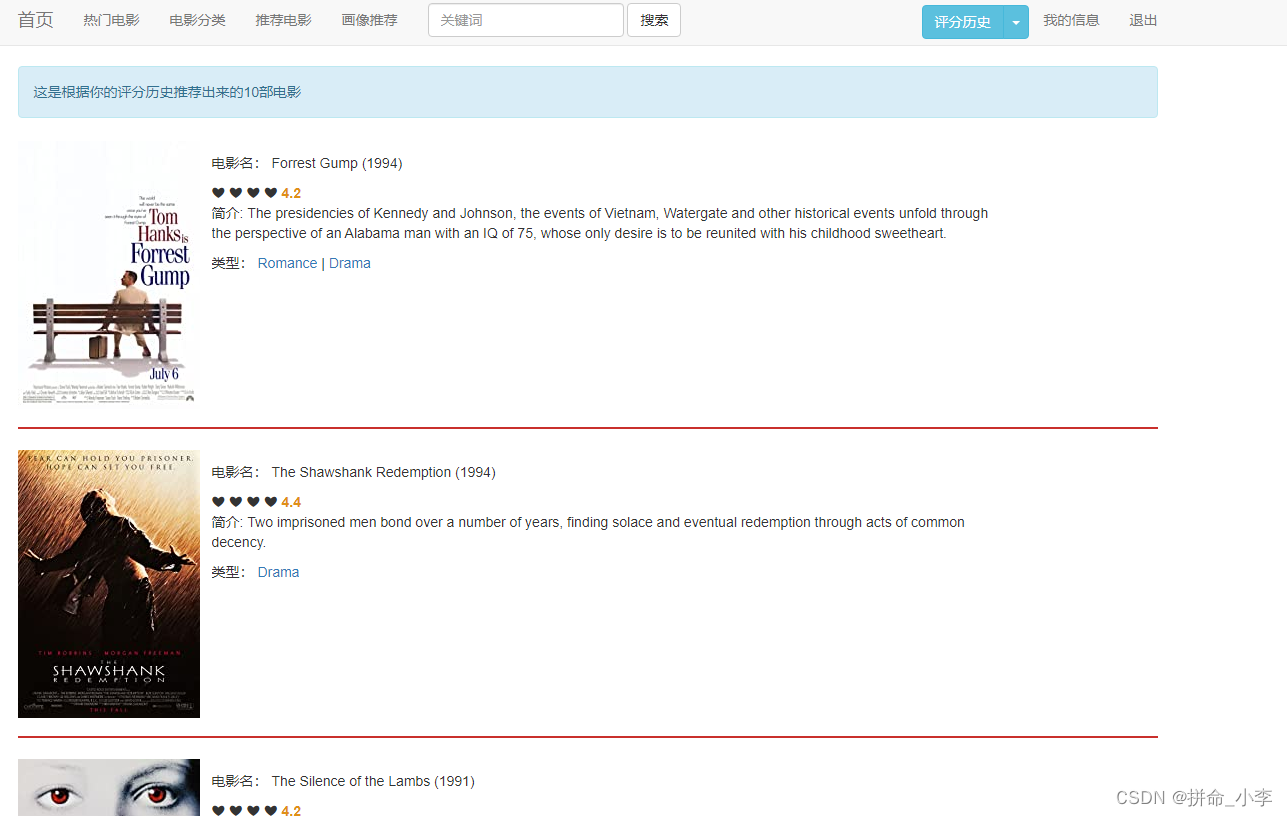
点击推荐电影可展示通过协同过滤算法进行推荐的10部影片
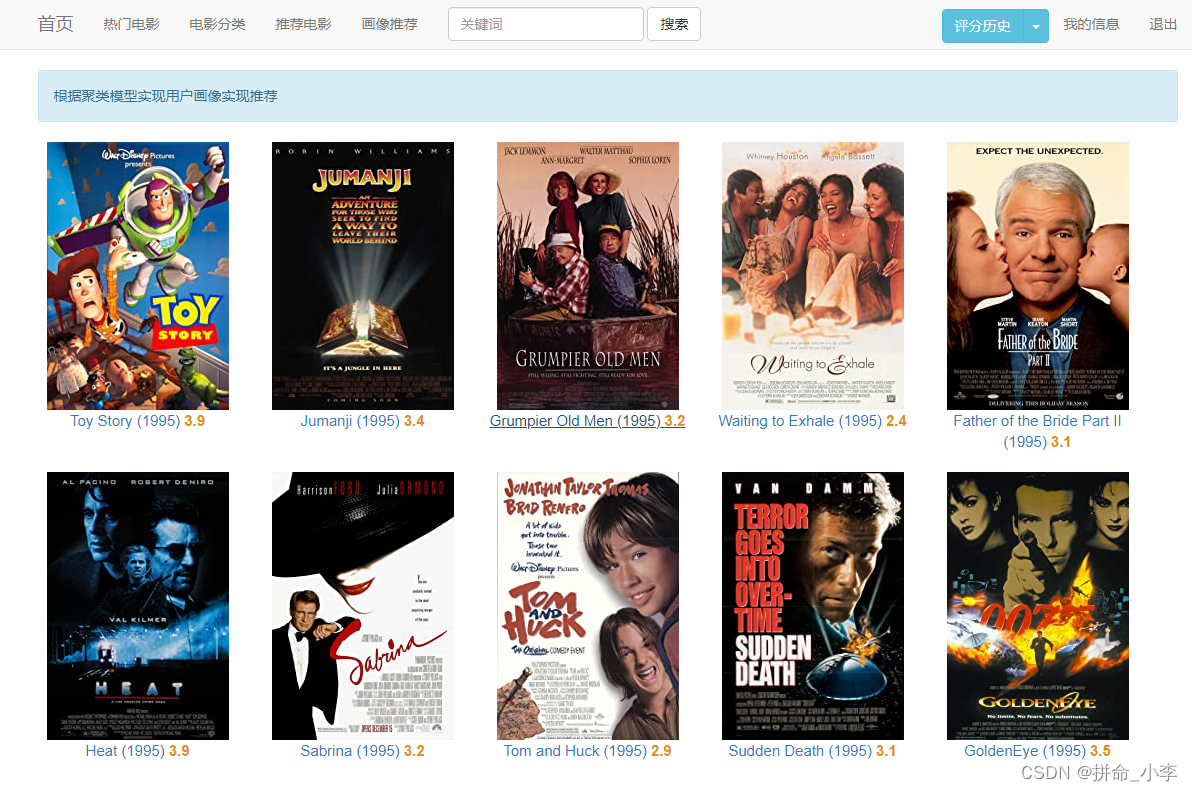
点击画像推荐会将和你相同类型的用户所看的电影推荐给你
代码
import csv
import time
import os.path
from math import sqrt
from django.contrib import messages
from django.db.models import Q
from django.db.models import Avg, Count, Max
from django.http import HttpResponse, request
from django.shortcuts import render, redirect, reverse
from .forms import RegisterForm, LoginForm, CommentForm,UserInfoForm
from django.views.generic import View, ListView, DetailView
from .models import User, Movie, Genre, Movie_rating, Movie_similarity, Movie_hot,UserType
import gensim.models.word2vec as word2vec
import gensim
# DO NOT MAKE ANY CHANGES
BASE = os.path.dirname(os.path.abspath(__file__))
# 加载用户聚类模型
from sklearn.externals import joblib
model_path = os.path.join(BASE,'model/model.pkl')
model_pre = joblib.load(model_path)
# 加载word2vec模型
model_vec_path = os.path.join(BASE,'model/text.model')
model_vec = word2vec.Word2Vec.load(model_vec_path)
'''!!! 导入电影相似度用'''
# 用户画像推荐
class PortrayView(ListView):
model = Movie
template_name = 'movie/portray.html'
paginate_by = 15
context_object_name = 'movies'
ordering = 'imdb_id'
page_kwarg = 'p'
def get_queryset(self):
try:
# 根据session获取用户
user_id = self.request.session.get('user_id')
# 查询用户
if user_id:
user_name = User.objects.get(pk=user_id).name
user_type = UserType.objects.get(name=user_name)
# 获取该登录用户的聚类类别
if user_type:
type1 = user_type.type
# 获取相同类别用户所看电影
users = UserType.objects.filter(type=type1)
movies = []
for user in users:
u = User.objects.get(name=user.name)
movie_id = Movie_rating.objects.filter(user=u).values_list('movie')
movies.extend(movie_id)
movies = [i[0] for i in movies]
return Movie.objects.filter(id__in=movies)
else:
return redirect(reverse('movie:info'))
except Exception as e:
# 如果session过期查不到用户则默认返回前1000部热门电影
return Movie.objects.filter(imdb_id__lte=1000)
def get_context_data(self, *, object_list=None, **kwargs):
context = super(PortrayView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
# print(context)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
class IndexView(ListView):
model = Movie
template_name = 'movie/index.html'
paginate_by = 15
context_object_name = 'movies'
ordering = 'imdb_id'
page_kwarg = 'p'
def get_queryset(self):
# 返回前1000部电影
return Movie.objects.filter(imdb_id__lte=1000)
def get_context_data(self, *, object_list=None, **kwargs):
context = super(IndexView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
# print(context)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
class PopularMovieView(ListView):
model = Movie_hot
template_name = 'movie/hot.html'
paginate_by = 15
context_object_name = 'movies'
# ordering = '-movie_hot__rating_number' # 没有效果
page_kwarg = 'p'
def get_queryset(self):
# 初始化 计算评分人数最多的100部电影,并保存到数据库中
# ######################
# movies = Movie.objects.annotate(nums=Count('movie_rating__score')).order_by('-nums')[:100]
# print(movies)
# print(movies.values("nums"))
# for movie in movies:
# print(movie,movie.nums)
# record = Movie_hot(movie=movie, rating_number=movie.nums)
# record.save()
# ######################
hot_movies=Movie_hot.objects.all().values("movie_id")
# print(hot_movies)
# for movie in hot_movies:
# print(movie)
# print(movie.imdb_id,movie.rating_number)
# Movie.objects.filter(movie_hot__rating_number=)
# 一个bug!这里filter出来虽然是正确的100部电影,但是会按照imdb_id排序,导致正确的结果被破坏了!也就是得不到100部热门电影的正确顺序!
# movies=Movie.objects.filter(id__in=hot_movies.values("imdb_id"))
# 找出100部热门电影,同时按照评分人数排序
# 因此我们必须要手动排序一次。另外也不太好用
movies=Movie.objects.filter(id__in=hot_movies).annotate(nums=Max('movie_hot__rating_number')).order_by('-nums')
return movies
def get_context_data(self, *, object_list=None, **kwargs):
context = super(PopularMovieView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
# print(context)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
class TagView(ListView):
model = Movie
template_name = 'movie/tag.html'
paginate_by = 15
context_object_name = 'movies'
# ordering = 'movie_rating__score'
page_kwarg = 'p'
def get_queryset(self):
if 'genre' not in self.request.GET.dict().keys():
movies = Movie.objects.all()
return movies[100:200]
else:
movies = Movie.objects.filter(genre__name=self.request.GET.dict()['genre'])
return movies[:100]
def get_context_data(self, *, object_list=None, **kwargs):
context = super(TagView, self).get_context_data(*kwargs)
if 'genre' in self.request.GET.dict().keys():
genre = self.request.GET.dict()['genre']
context.update({'genre': genre})
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
class SearchView(ListView):
model = Movie
template_name = 'movie/search.html'
paginate_by = 15
context_object_name = 'movies'
# ordering = 'movie_rating__score'
page_kwarg = 'p'
def get_queryset(self):
keyword = self.request.GET.dict()['keyword']
# try:
keys = list(dict(model_vec.wv.most_similar(keyword, topn=3)).keys())
movies = Movie.objects.filter(Q(name__icontains=keys[0]) | Q(name__icontains=keys[1])| Q(name__icontains=keys[2]))
# except Exception as e:
# movies = Movie.objects.filter(name__icontains=keyword)
return movies
def get_context_data(self, *, object_list=None, **kwargs):
# self.genre=self.request.GET.dict()['genre']
context = super(SearchView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
context.update({'keyword': self.request.GET.dict()['keyword']})
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
# 注册视图
class RegisterView(View):
def get(self, request):
return render(request, 'movie/register.html')
def post(self, request):
form = RegisterForm(request.POST)
if form.is_valid():
# 没毛病,保存
form.save()
return redirect(reverse('movie:index'))
else:
# 表单验证失败,重定向到注册页面
errors = form.get_errors()
for error in errors:
messages.info(request, error)
print(form.errors.get_json_data())
return redirect(reverse('movie:register'))
# 登录视图
class LoginView(View):
def get(self, request):
return render(request, 'movie/login.html')
def post(self, request):
print(request.POST)
form = LoginForm(request.POST)
if form.is_valid():
name = form.cleaned_data.get('name')
pwd = form.cleaned_data.get('password')
user = User.objects.filter(name=name, password=pwd).first()
# username = form.cleaned_data.get('name')
# print(username)
# pwd = form.cleaned_data.get('password')
if user:
# 登录成功,在session 里面加上当前用户的id,作为标识
request.session['user_id'] = user.id
return redirect(reverse('movie:index'))
if remember:
# 设置为None,则表示使用全局的过期时间
request.session.set_expiry(None)
else:
request.session.set_expiry(0)
else:
print('用户名或者密码错误')
# messages.add_message(request,messages.INFO,'用户名或者密码错误!')
messages.info(request, '用户名或者密码错误!')
return redirect(reverse('movie:login'))
else:
print("error!!!!!!!!!!!")
errors = form.get_errors()
for error in errors:
messages.info(request, error)
print(form.errors.get_json_data())
return redirect(reverse('movie:login'))
def UserLogout(request):
# 登出,立即停止会话
request.session.set_expiry(-1)
return redirect(reverse('movie:index'))
class UserInfo(View):
def get(self, request):
return render(request, 'movie/info.html')
def post(self, request):
print(request.POST)
form = UserInfoForm(request.POST)
if form.is_valid():
# kmeans做预测分类用户
name = request.POST.get('name')
user_type = model_pre.predict(form.get_value_list())
user = UserType.objects.filter(name=name)
if user.exists():
user.delete()
UserType(name=name, type=user_type).save()
return redirect(reverse('movie:portray'))
else:
print("error!!!!!!!!!!!")
errors = form.get_errors()
for error in errors:
messages.info(request, error)
print(form.errors.get_json_data())
return redirect(reverse('movie:info'))
class MovieDetailView(DetailView):
'''电影详情页面'''
model = Movie
template_name = 'movie/detail.html'
# 上下文对象的名称
context_object_name = 'movie'
def get_context_data(self, **kwargs):
# 重写获取上下文方法,增加评分参数
context = super().get_context_data(**kwargs)
# 判断是否登录用
login = True
try:
user_id = self.request.session['user_id']
except KeyError as e:
login = False # 未登录
# 获得电影的pk
pk = self.kwargs['pk']
movie = Movie.objects.get(pk=pk)
if login:
# 已经登录,获取当前用户的历史评分数据
user = User.objects.get(pk=user_id)
rating = Movie_rating.objects.filter(user=user, movie=movie).first()
# 默认值
score = 0
comment = ''
if rating:
score = rating.score
comment = rating.comment
context.update({'score': score, 'comment': comment})
similarity_movies = movie.get_similarity()
# 获取与当前电影最相似的电影
context.update({'similarity_movies': similarity_movies})
# 判断是否登录,没有登录则不显示评分页面
context.update({'login': login})
return context
# 接受评分表单,pk是当前电影的数据库主键id
def post(self, request, pk):
url = request.get_full_path()
form = CommentForm(request.POST)
if form.is_valid():
# 获取分数和评论
score = form.cleaned_data.get('score')
comment = form.cleaned_data.get('comment')
print(score, comment)
# 获取用户和电影
user_id = request.session['user_id']
user = User.objects.get(pk=user_id)
movie = Movie.objects.get(pk=pk)
# 更新一条记录
rating = Movie_rating.objects.filter(user=user, movie=movie).first()
if rating:
# 如果存在则更新
# print(rating)
rating.score = score
rating.comment = comment
rating.save()
# messages.info(request,"更新评分成功!")
else:
print('记录不存在')
# 如果不存在则添加
rating = Movie_rating(user=user, movie=movie, score=score, comment=comment)
rating.save()
messages.info(request, "评论成功!")
else:
# 表单没有验证通过
messages.info(request, "评分不能为空!")
return redirect(reverse('movie:detail', args=(pk,)))
class RatingHistoryView(DetailView):
'''用户详情页面'''
model = User
template_name = 'movie/history.html'
# 上下文对象的名称
context_object_name = 'user'
def get_context_data(self, **kwargs):
# 这里要增加的对象:当前用户过的电影历史
context = super().get_context_data(**kwargs)
user_id = self.request.session['user_id']
user = User.objects.get(pk=user_id)
# 获取ratings即可
ratings = Movie_rating.objects.filter(user=user)
context.update({'ratings': ratings})
return context
def delete_recode(request, pk):
print(pk)
movie = Movie.objects.get(pk=pk)
user_id = request.session['user_id']
print(user_id)
user = User.objects.get(pk=user_id)
rating = Movie_rating.objects.get(user=user, movie=movie)
print(movie, user, rating)
rating.delete()
messages.info(request, f"删除 {movie.name} 评分记录成功!")
# 跳转回评分历史
return redirect(reverse('movie:history', args=(user_id,)))
class RecommendMovieView(ListView):
model = Movie
template_name = 'movie/recommend.html'
paginate_by = 15
context_object_name = 'movies'
ordering = 'movie_rating__score'
page_kwarg = 'p'
def __init__(self):
super().__init__()
# 最相似的20个用户
self.K = 20
# 推荐出10电影
self.N = 10
# 存放当前用户评分过的电影querySet
self.cur_user_movie_qs = None
def get_user_sim(self):
# 用户相似度字典,格式为{ user_id1:val , user_id2:val , ... }
user_sim_dct = dict()
'''获取用户之间的相似度,存放在user_sim_dct中'''
# 获取当前用户
cur_user_id = self.request.session['user_id']
cur_user = User.objects.get(pk=cur_user_id)
# 获取其它用户
other_users = User.objects.exclude(pk=cur_user_id)
self.cur_user_movie_qs = Movie.objects.filter(user=cur_user)
# 计算当前用户与其他用户评分过的电影交集数
for user in other_users:
# 记录感兴趣的数量
user_sim_dct[user.id] = len(Movie.objects.filter(user=user) & self.cur_user_movie_qs)
# 按照key排序value,返回K个最相近的用户
print("user similarity calculated!")
# 格式是 [ (user, value), (user, value), ... ]
return sorted(user_sim_dct.items(), key=lambda x: -x[1])[:self.K]
def get_recommend_movie(self, user_lst):
# 电影兴趣值字典,{ movie:value, movie:value , ...}
movie_val_dct = dict()
# print(f'cur_user_movie_qs:{self.cur_user_movie_qs},type:{type(self.cur_user_movie_qs)}')
# print(Movie.objects.all() & self.cur_user_movie_qs)
# 用户,相似度
for user, _ in user_lst:
# 获取相似用户评分过的电影,并且不在前用户的评分列表中的,再加上score字段,方便计算兴趣值
movie_set = Movie.objects.filter(user=user).exclude(id__in=self.cur_user_movie_qs).annotate(
score=Max('movie_rating__score'))
for movie in movie_set:
movie_val_dct.setdefault(movie, 0)
# 累计用户的评分
movie_val_dct[movie] += movie.score
print('recommend movie list calculated!')
return sorted(movie_val_dct.items(), key=lambda x: -x[1])[:self.N]
def get_queryset(self):
s = time.time()
# 获得最相似的K个用户列表
user_lst = self.get_user_sim()
# 获得推荐电影的id
movie_lst = self.get_recommend_movie(user_lst)
print(movie_lst)
result_lst = []
for movie, _ in movie_lst:
result_lst.append(movie)
e = time.time()
print(f"用时:{e - s}")
return result_lst
def get_context_data(self, *, object_list=None, **kwargs):
context = super(RecommendMovieView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}